
Все мы помним хрестоматийное объяснение «что такое индексы в БД и как они облегчают задачи поиска нужных строк». Уверен, у большинства из вас перед глазами встаёт нечто подобное:
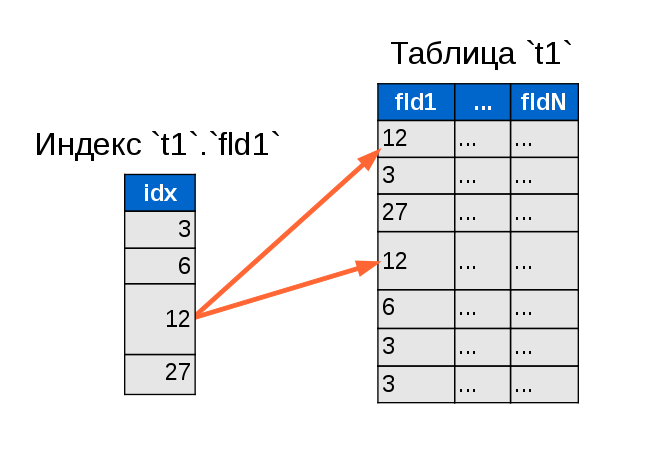
И сразу становится очевидно, насколько меньше данных нужно перелопатить для поиска двух-трёх нужных строк. Гениально. Просто. Понятно.
И лично мне всегда казалось, что улучшать эту схему некуда… Пока я не познакомился с кластерными индексами. Оказалось, что всё не так уж радужно с «обычными» индексами.
Итак, что же такое кластерный индекс, чем он лучше некластерного, и как с ним обстоит дело у MySQL.
И сразу становится очевидно, насколько меньше данных нужно перелопатить для поиска двух-трёх нужных строк. Гениально. Просто. Понятно.
И лично мне всегда казалось, что улучшать эту схему некуда… Пока я не познакомился с кластерными индексами. Оказалось, что всё не так уж радужно с «обычными» индексами.
Итак, что же такое кластерный индекс, чем он лучше некластерного, и как с ним обстоит дело у MySQL.

