

Как вы могли слышать, после четырех лет разработки протоколы HTTP/3 и QUIC приблизились к официальной стандартизации. Предварительные версии уже доступны для тестирования на серверах и браузерах.
HTTP/3 обещает значительный прирост производительности по сравнению с HTTP/2, в основном благодаря смене транспортного протокола с TCP на QUIC over UDP. В этой статье мы подробно рассмотрим только одно улучшение, а именно — устранение проблемы блокировки начала очереди (Head-of-Line blocking, HOL blocking). Это будет полезно, так как я прочитал много заблуждений о том, насколько это решение полезно и как оно помогает на практике. Решение HOL blocking было основным мотивом не только HTTP/3 и QUIC, но и HTTP/2, и это дает фантастическое представление о причинах эволюции протокола.
Я расскажу о проблеме и ее формах на фоне истории протокола HTTP. Рассмотрим, как эта проблема влияет на системы приоритизации и контроля перегрузки сети. Цель данной статьи — помочь людям сделать правильные выводы об улучшении производительности в HTTP/3, которые (спойлер!) не всегда так хороши, как пишут в маркетинговых материалах.
Что такое блокировка начала очереди?
Достаточно сложно дать одно конкретное определение блокировки HOL, так как в данной статье рассматриваются четыре разные версии этой проблемы. Тем не менее, простое определение звучит так:
Когда один (медленный) объект мешает другим/следующим объектам двигаться.
Хорошая метафора из жизни — магазин с одной кассой. Один клиент с большим количеством покупок может задержать всех, кто стоит после него, так как обслуживание происходит в порядке очереди, то есть по принципу «первым пришел — первым ушел» (FIFO). Другой пример — скоростное шоссе с одной полосой. Одна авария на таком шоссе приведет к задержке движения транспорта на значительное время. Таким образом, проблема в начале приводит к блокировке всей очереди.
Эта ситуация — одна из сложнейших проблем производительности в Web. Чтобы понять это, рассмотрим старый добрый HTTP/1.1.
HOL blocking в HTTP/1.1
Протокол HTTP/1.1 — из тех времен, когда все было проще. Тогда протоколы были текстовыми и легко читались. Это иллюстрирует следующее изображение.
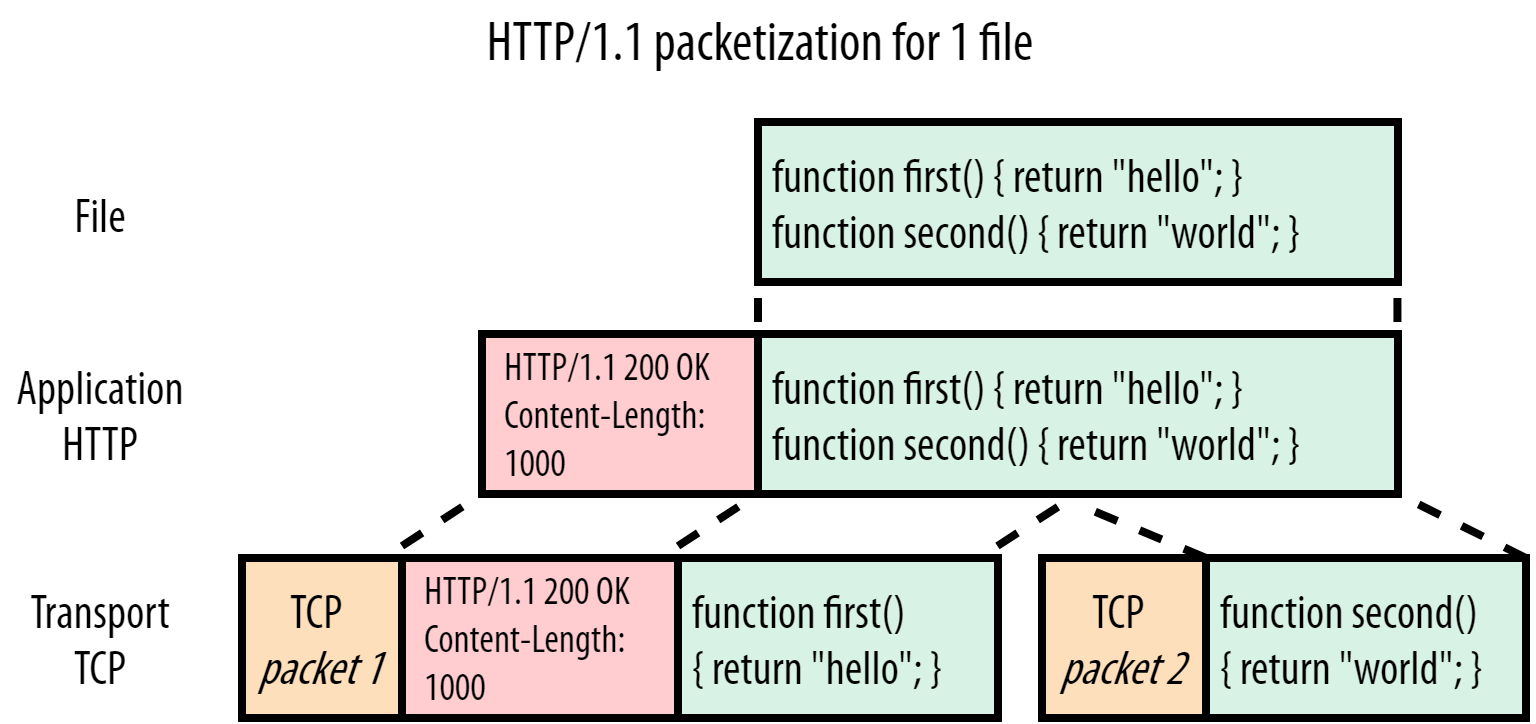
В этом случае браузер запрашивает файл script.js (зеленый) через HTTP/1.1, а рисунок 1 показывает, как сервер обрабатывает этот запрос. Мы видим, что HTTP просто добавляет текстовые заголовки (красные) в самое начало файла, то есть в начало полезной нагрузки («payload»). Заголовок и полезная нагрузка спускаются на транспортный уровень к TCP, чтобы отправиться к клиенту. В этом примере предположим, что весь файл не умещается в один TCP-пакет и должен быть разделен на две части.
Примечание: при использовании HTTPS между TCP и HTTP появляется дополнительный слой, обеспечивающий безопасность, где обычно используется протокол TLS. Мы не принимаем во внимание этот слой, чтобы не усложнять объяснение. Тем не менее, в бонусной части статьи я добавил подробности, связанные с TLS, и то, как QUIC решает возникающие проблемы.
Теперь давайте посмотрим, что происходит, когда браузер запрашивает еще один файл: style.css.

В этом случае мы отправляем style.css (фиолетовый) сразу после того, как script.js отправлен. Заголовки и содержимое style.css присоединяются в конец JavaScript(JS)-файла. Принимающая сторона использует заголовок Content-Length для определения конца ответа и начала нового. В нашем простом примере script.js занимает 1000 байт, а style.css — всего 600.
Все это кажется хорошим решением в простом примере с двумя маленькими файлами. Представьте случай, в котором JS-файл в разы больше файла CSS, скажем, 1 МБ вместо 1 КБ. В этом случае CSS-файл будет ждать, пока не скачается весь JS-файл, даже если он меньше и используется браузером раньше. Если визуализировать это цифрами, используя цифру 1 для large_script.js и 2 для style.css, то мы получим что-то такое:
11111111111111111111111111111111111111122
Это типичный пример проблемы блокировки начала очереди. Вы могли подумать, что это легко решается. Достаточно запрашивать CSS-файл раньше, чем JS-файл. Однако важно понимать, что браузер не может определить, какой из файлов больше, во время запроса. В HTML нет возможности указать размер файла (HTML Working Group, было бы прекрасно, если бы вы сделали что-то такое:
<img src="thisisfine.jpg" size="15000" />.
Использование мультиплексирования было бы «настоящим» решением этой проблемы. Если разделить полезную нагрузку каждого файла на маленькие кусочки (чанки), то мы бы могли смешивать (чередовать) их при отправке. Отправляем кусочек JS-файла, затем кусочек CSS-файла, потом снова кусочек JS-файла и так далее, пока все файлы не будут переданы. При таком подходе маленький CSS будет скачан (и использован) значительно раньше, практически не задерживая большой JS-файл. Визуализация цифрами выглядит так:
12121111111111111111111111111111111111111
К сожалению, мультиплексирование невозможно в HTTP/1.1 из-за некоторых фундаментальных ограничений протокола. Для понимания этого не нужен пример с большим и маленьким файлом, достаточно примера с двумя маленькими. Рассмотрим рисунок 3, где чередуется четыре чанка для двух ресурсов.

Основная проблема здесь в том, что HTTP/1.1 — текстовый протокол, добавляющий заголовки исключительно в начало полезной нагрузки. Он не различает фрагменты ресурсов друг от друга. Давайте я расскажу, к чему это приводит. На рисунке 3 браузер начинает разбирать заголовки для файла script.js и ожидает 1000 байт полезной нагрузки следом, как указано в заголовке Content-Length. Браузер получает только 450 байт файла (первый чанк). Следом браузер читает заголовки для файла style.css, содержимое файла style.css, интерпретируя их как содержимое script.js и останавливается где-то в середине второго чанка script.js. Далее браузер не находит заголовков HTTP и отбрасывает остатки третьего пакета. Файл script.js передается парсеру JS, который выводит ошибку, так как следующий файл не является корректным JavaScript:
function first() { return "hello"; } HTTP/1.1 200 OK Content-Length: 600 .h1 { font-size: 4em; } func
Опять же, вы можете сказать, что есть простое решение: браузер должен обрабатывать последовательность HTTP/1.1 {statusCode} {statusString}\n как начало нового блока. Это сработает для второго TCP-пакета, но приведет к ошибке в третьем: как браузер узнает, где заканчивается зеленый чанк и начинается фиолетовый?
Это фундаментальное ограничение протокола HTTP/1.1. Если у вас есть одно подключение HTTP/1.1, то запрашиваемый ресурс должен быть доставлен полностью, прежде чем вы сможете перейти к отправке следующего. Это приводит к тяжелым формам HOL блокировки, если ресурсы, запрашиваемые в первую очередь, долго создаются или являются большими файлами.
Именно поэтому браузеры запускают несколько параллельных TCP-подключений (обычно 6) для каждой страницы, загружаемой с помощью HTTP/1.1. В этом случае запросы распределяются между соединениями, и блокировки не происходит. Конечно, если у вас не более шести ресурсов на страницу… Что обычно не так. Отсюда и возникла практика «прятать» ресурсы по разным доменам (img.mysite.com, static.mysite.com и так далее) и сетям доставки контента (CDN). Так как для каждого домена создается по шесть подключений, браузер может создавать до 30 TCP-подключений при загрузке каждой страницы. Это, конечно, работает, но требует значительных накладных расходов, так как организация TCP-подключения может быть дорогой (как в контексте памяти в сервере, так и в плане вычислений для организации TLS-шифрования) и занимает значительное время, особенно в HTTPS.
Так как проблема не решается в HTTP/1.1, а заплатка из параллельных TCP-подключений плохо масштабируется, стала очевидна потребность в новом подходе, каким стал HTTP/2.
Примечание: старая гвардия, читающая эту статью, может воскликнуть про конвейер HTTP/1.1. Я предпочту не рассказывать об этом, чтобы сохранить общую историю, но заинтересованные люди могут почитать об этом в конце статьи.
HOL blocking в HTTP/2 поверх TCP
Подведем итоги. HTTP/1.1 имел проблему блокировки начала очереди, когда большой файл или медленный ответ задерживал остальные ответы в очереди. Это потому что протокол текстовый и не имеет разделителей между фрагментами ресурсов. В качестве обходного пути браузеры открывают несколько параллельных TCP-подключений, которые неэффективны и не масштабируются.
Таким образом, цель HTTP/2 достаточно понятна: сделать так, чтобы можно было вернуться к одному TCP-подключению, решив проблему HOL блокировок. Иначе говоря, мы хотим использовать мультиплексирование фрагментов ресурсов. Это было невозможно в HTTP/1.1, так как не было способа определить принадлежность фрагмента, его конец и начало нового. HTTP/2 решает эту проблему достаточно элегантно. Перед каждым фрагментом ресурса вводится небольшое управляющее сообщение, именуемое фреймом (frame). Это продемонстрировано на рисунке 4.
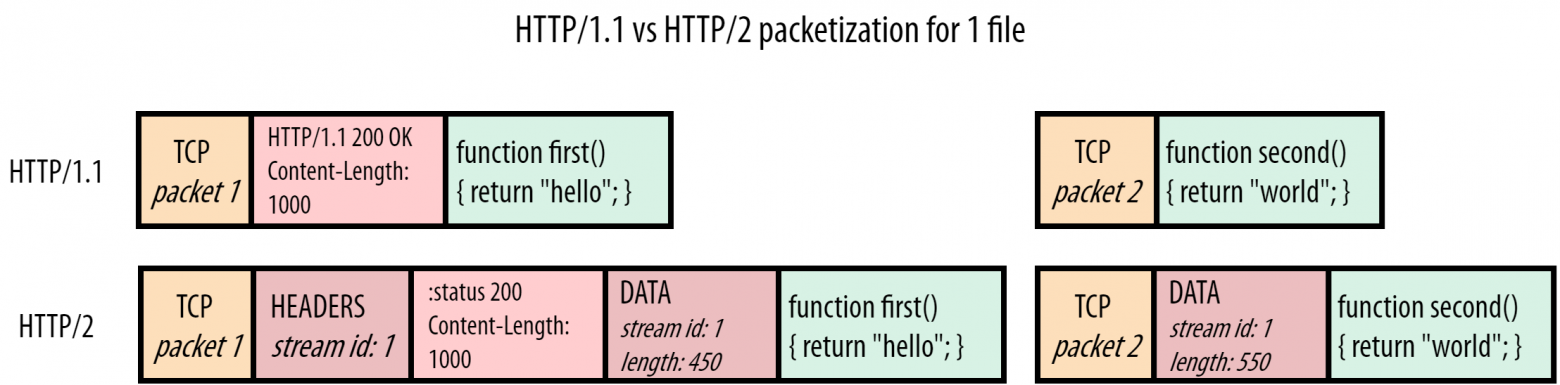
HTTP/2 добавляет фрейм с названием DATA перед каждым фрагментом ресурса. Эти фреймы содержат два важных момента. Во-первых, идентифицируется ресурс, которому принадлежит этот фрагмент. Каждый «поток байтов» ресурсов имеет свой уникальный номер, stream id. Во-вторых, мы знаем размер файла. Протокол также имеет множество других типов фреймов, например, рисунок 5 показывает фрейм типа HEADERS. Он также содержит stream id, который указывает, к какому запросу относится данный ответ. Таким образом, заголовки могут идти отдельно от полезной нагрузки ответа.
Из этого следует, что HTTP/2 позволяет правильно мультиплексировать несколько ресурсов внутри одного подключения, как показано на рисунке 5.

В сравнении с примером на рисунке 3 браузер отлично обрабатывает такое мультиплексирование. Сперва он обрабатывает фрейм HEADERS для файла script.js, а затем первый DATA-фрейм для первого фрагмента JS-файла с stream id = 1. Из длины, записанной во фрейме, браузер знает, что фрагмент заканчивается в конце первого TCP-пакета, а дальше необходимо ждать новый фрейм. Во втором TCP-пакете браузер находит фрейм HEADERS для файла style.css. Следующий за ним DATA-фрейм имеет stream id равное 2. Таким образом, браузер различает, что DATA-фреймы относятся к разным ресурсам. Аналогично обрабатывается третий TCP-пакет, где stream id используется для демультиплексирования фрагментов и формирования корректного ресурса.
Использование «обрамления» каждого сообщения делает HTTP/2 более гибким, чем HTTP/1.1. Такой подход позволяет множеству ресурсов использовать одно TCP-подключение и чередовать фрагменты ресурсов при отправке. Это решает проблему блокировки начала очереди в случае с медленным ресурсом. Сервер может начать отправлять данные других ресурсов, пока ожидает генерации сложного index.html.
Важным следствием такого подхода HTTP/2 является то, что нам необходим способ, с помощью которого браузер может сообщать серверу о желаемом распределении пропускной способности между ресурсами. Другими словами, как блоки ресурсов должны планироваться к отправке и чередоваться. Если мы визуализируем это с помощью цифр 1 и 2, то мы увидим, что для HTTP/1.1 есть только один, последовательный, способ — 11112222. HTTP/2 предлагает выбор побольше:
- честное мультиплексирование (например, для двух JPEG-изображений): 12121212.
- мультиплексирование по приоритету (2 — более важный, чем 1): 221221221.
- обратное последовательное планирование (2 — ресурс, который размещен сервером): 22221111.
- частичное планирование: (поток 1 отменен и не отправляет все данные): 112222.
Выбор способа отправки определяется системой приоритизации в HTTP/2, что может влиять на производительность сети. Однако это сложная тема и вам не обязательно разбираться в ней для прочтения статьи, поэтому я оставлю объяснения. Тем более на эту тему у меня есть подробная лекция на YouTube.
Я думаю, вы согласны с тем, что использование фреймов и приоритизации в HTTP/2 решает проблему блокировки начала очереди, возникшей в HTTP/1.1. Это значит, что моя работа на этом завершена и можно идти домой? Не тут-то было! Да, мы решили проблему блокировок в HTTP/1.1, но как насчет TCP?
TCP HOL blocking
Как оказалось, HTTP/2 решает проблему HOL blocking только на уровне HTTP, то есть на уровне приложений. Но в сетевой модели есть и другие уровни. Вы можете это видеть на рисунке 6.
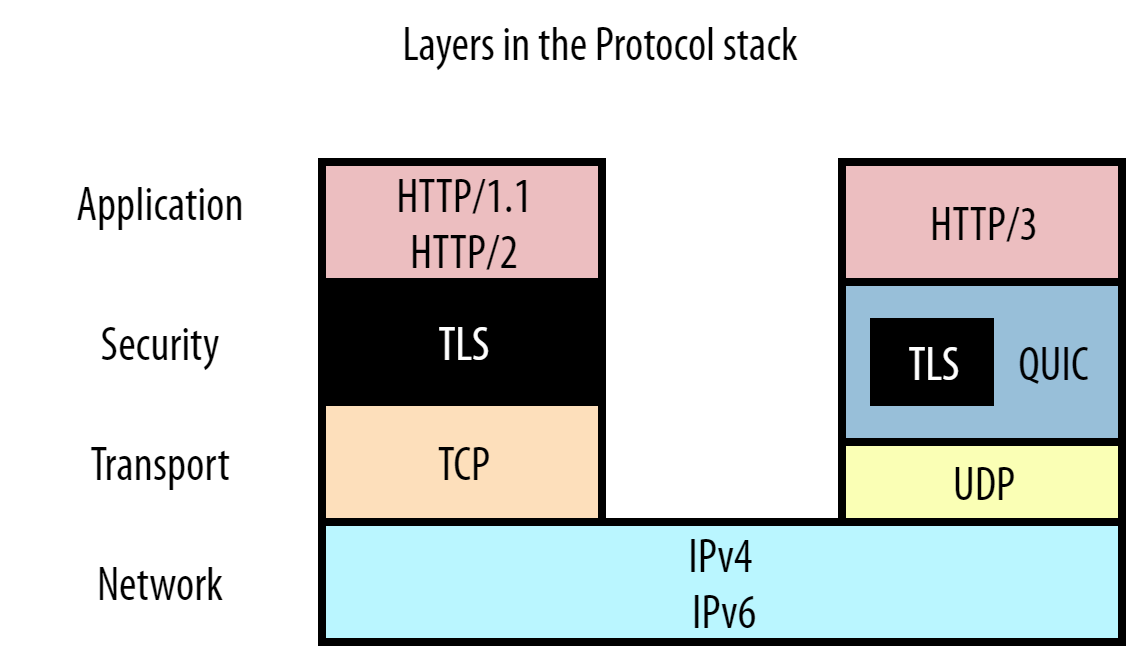
Протокол HTTP на самом верху, затем идет TLS на уровне безопасности и далее — TCP на транспортном уровне. Каждый из этих протоколов «оборачивает» данные с уровня выше и дополняет собственной мета-информацией. Например, заголовок TCP-пакета добавляется к нашим HTTP(S)-данным, которые затем помещаются в IP-пакет. Это позволяет разделять протоколы вне зависимости от передаваемых данных. Например, протокол транспортного уровня, такой как TCP, не должен заботиться о том, какой тип данных он передает: HTTP, FTP, SSH или что-то еще. А протокол сетевого уровня IP отлично работает как с TCP, так и с UDP.
Однако это имеет значимые последствия, если мы используем мультиплексирование ресурсов HTTP/2 через TCP. Рассмотрим рисунок 7.
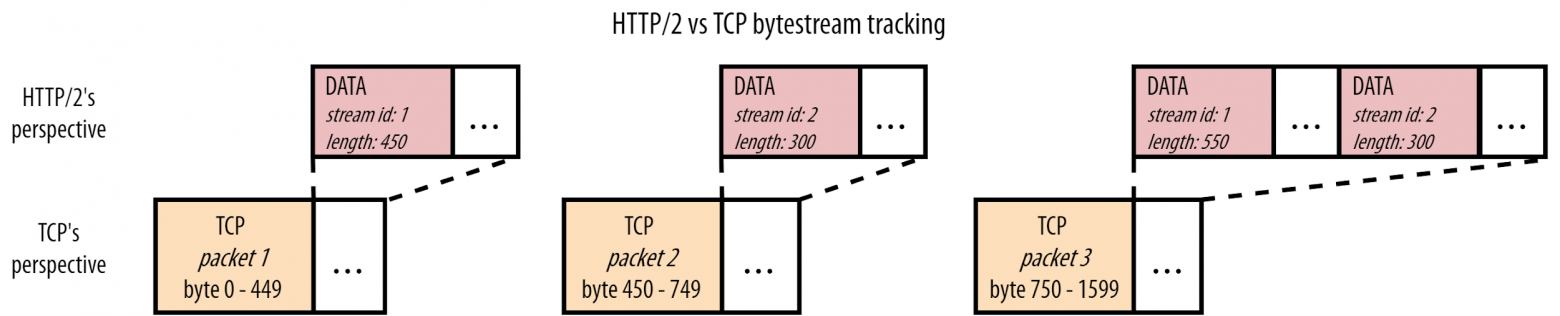
Хотя мы и браузер понимаем, что работаем с CSS и JavaScript-файлами, HTTP/2 об этом не знает (и ему не нужно знать). Он знает только о том, что мы работаем с фрагментами файлов из потоков с разными идентификаторами. Тем временем TCP не знает о том, что передает HTTP. TCP знает только то, что у него есть последовательность байт, которые необходимо передать от одного компьютера к другому. Для этого обычно используются пакеты, максимальный размер которых обычно составляет около 1450 байт. Каждый пакет отслеживает, какую часть данных он переносит, чтобы принимающая сторона могла восстановить данные в правильном порядке.
Иными словами, между двумя уровнями существует несоответствие в перспективе. HTTP/2 видит несколько независимых потоков байтов ресурсов, а TCP — один общий. В примере на рисунке 7 третий пакет TCP знает, что переносит байты 750-1599 каких-то данных. HTTP/2, в свою очередь, понимает, что это два фрагмента двух независимых ресурсов. (Примечание: Каждый фрейм HTTP/2, будь то DATA или HEADERS, содержит несколько байт информации. Я не учитывал размер этих фреймов, чтобы сделать числа более интуитивно понятными).
Это все может показаться ненужными деталями, до тех пор пока не придет осознание, что Интернет — это фундаментально ненадежная сеть. Пакеты могут и будут теряться и задерживаться при пересылке из точки А в точку Б. Это одна из причин, почему протокол TCP пользуется популярностью: он гарантирует надежность, используя только ненадежный IP. Он добивается этого путем повторной отправки копий потерянных пакетов.
Теперь мы можем понять, как это может привести к блокировки начала очереди на транспортном уровне. Посмотрите на рисунок 7 еще раз и задайте себе вопрос: что произойдет, если пакет 2 потеряется в сети, а пакеты 1 и 3 каким-то образом будут доставлены? Помните, что TCP не знает о том, что обслуживает HTTP/2, ему нужно просто доставить пакеты в правильном порядке. Таким образом, он видит промежуток между первым и третьим пакетом и потому не может передать третий пакет в браузер. TCP хранит третий пакет в буфере до тех пор, пока не придет копия пакета 2 (что требует как минимум одного полного круга клиент-сервер), и только после этого передаст оба пакета браузеру в правильном порядке. Проще говоря, потерянный пакет 2 блокирует пакет 3!
Может быть не до конца понятно, почему это проблема, поэтому заглянем глубже в TCP-пакеты на рисунке 7. Мы можем заметить, что TCP-пакет 2 содержит данные исключительно для потока с идентификатором 2 (CSS-файл), а пакет 3 содержит данные для потоков 1 (JS-файл) и 2. На уровне HTTP данные потоки независимы и явно размечены фреймами DATA. Таким образом, в теории мы можем передать пакет 3 в браузер, не дожидаясь доставки пакета 2. Браузер увидит фрейм DATA для потока с номером 1 и сможет его использовать. Только поток 2 будет задержан в ожидании повторной передачи пакета 2. Это будет более эффективно, чем блокировка потоков 1 и 2, которую предоставляет нам TCP.
Другой пример — это ситуация, когда пакет 1 потерялся, а пакеты 2 и 3 дошли успешно. TCP поставит на ожидание пакеты 2 и 3 и будет ждать переотправки пакета 1. Как мы можем заметить на уровне HTTP/2, данные потока с номер 2 (CSS-файл) полностью содержатся в пакетах 2 и 3 и им не нужно ждать пакета 1. Браузер уже может разбирать/обрабатывать/использовать CSS-файл, но он завис в ожидании повторной отправки JS-файла.
Протокол TCP не знает о независимости потоков в HTTP/2, и это означает, что проблема HOL blocking на уровне TCP из-за потерянных или задержанных пакетов превращается в проблему блокировки начала очереди для HTTP.
Теперь вы можете спросить себя: а в чем был смысл? Зачем вообще HTTP/2, если у нас есть блокировки HOL на уровне TCP? Ну, основная причина в том, что потери пакетов относительно редки. Потери пакетов составляют порядка 0.01%, особенно на высокоскоростных кабельных сетях. Даже в худших мобильных сетях редко увидишь больше 2% потерь. Потеря 2% пакетов не означает, что всегда каждые 2 пакета из 100 будут потеряны, например, пакеты 42 и 96. На практике более вероятно, что потеряются 10 последовательных пакетов из 500, скажем, с номера 255 по 265. Потеря пакетов в большинстве случаев вызвана временным переполнением памяти буферов у маршрутизаторов на пути следования пакета. Маршрутизаторы начинают отбрасывать пакеты, которые они не могут поместить в буфер. Опять же, детали этого процесса не важны здесь (но доступны в другом месте, если хотите узнать больше). Важно то, что блокировка HOL в TCP действительно существует, но имеет меньшее влияние на производительность, чем блокировка HOL HTTP/1.1, которая встречается практически каждый раз. Более того, HTTP/1.1 также подвержен блокировкам HOL TCP!
Однако наиболее справедливо сравнивать HTTP/2 с одним подключением и HTTP/1.1 с одним подключением. Но, как мы успели заметить, на практике все работает иначе, и HTTP/1.1 обычно открывает множество подключений. Это позволяет HTTP/1.1 не только преодолевать блокировка уровня HTTP, но и блокировки уровня TCP. Как следствие, в некоторых случаях HTTP/2 с одним соединением с трудом превосходит по скорости HTTP/1.1 с шестью соединениями. Это достигается в основном из-за механизма контроля перегрузки сети (congestion control). Это еще одна тонкая тема, которая не относится к проблеме HOL blocking, и поэтому я переместил ее в бонусную секцию в конце статьи.
В общем, на практике мы можем видеть, что HTTP/2, который используется в браузерах и серверах в большинстве случаев, по скорости не отстает от HTTP/1.1, а иногда немного превосходит. На мой взгляд, это происходит частично потому, что веб-сайты оптимизируются под HTTP/2, и частично потому, что браузеры открывают множественные HTTP/2-соединения, так как сайты размещают ресурсы на разных серверах или из-за побочных эффектов, связанных с безопасностью. В общем, берут лучшее из двух миров.
Впрочем, в некоторых случаях, в частности на медленных сетях с большими потерями, HTTP/1.1 с шестью подключениями будет превосходить HTTP/2 с одним подключением. Это происходит в основном из-за блокировок HOL на транспортном уровне. Этот факт — отличная мотивация разрабатывать новый транспортный протокол под замену TCP.
HOL blocking в HTTP/3 поверх QUIC
После всего прочитанного мы наконец готовы поговорить о новых разработках. Но сначала давайте резюмируем изученное.
- HTTP/1.1 имеет блокировки начала очереди, потому что ему необходимо отправлять ответы целиком, а мультиплексирование не поддерживается.
- HTTP/2 решил эту проблему введением «фреймов» для обозначения «потоков», к которым принадлежит каждый фрагмент ресурса.
- TCP не знает про независимые «потоки» и видит все как один большой поток.
- Если пакет TCP теряется, то все следующие пакеты ждут переотправки, даже если они содержат не связанную информацию с других потоков. На транспортном уровне тоже есть блокировки начала очереди.
Я уверен, что сейчас вы можете предсказать, как решить проблемы TCP. Я прав, да? В конце концов, решение достаточно простое: нам «всего лишь» нужно, чтобы транспортный уровень знал о разных, независимых потоках! В таком случае если данные одного потока потеряются, то транспортный уровень знает, что нет необходимости задерживать остальные потоки.
Даже несмотря на то, что идея достаточна проста, ее сложно реализовать на практике. По разным причинам невозможно изменить TCP так, чтобы он знал о потоках. Была выбрана альтернатива разработать совершенно новый протокол транспортного уровня в виде QUIC. Чтобы QUIC можно было использовать в Интернете, он был построен на базе ненадежного протокола UDP. Более того, важный момент: использование UDP не делает QUIC ненадежным! Во многих отношениях QUIC следует рассматривать как TCP 2.0. Он включает в себя лучшие стороны TCP: надежность, контроль перегрузки сети, контроль потока и много чего еще. В QUIC интегрирован TLS (см. рисунок 6) и не позволяет устанавливать незашифрованные соединения. Так как QUIC значительно отличается от TCP, это значит, что HTTP/2 не может быть запущен поверх него. Поэтому пришлось разработать HTTP/3. Эта статья уже и так достаточно длинная, без детального разбора QUIC (ознакомьтесь с другими источниками на эту тему), поэтому я сфокусируюусь на конкретных особенностях, необходимых для понимания в контексте нашего разговора о блокировках HOL. Рассмотрим рисунок 8.
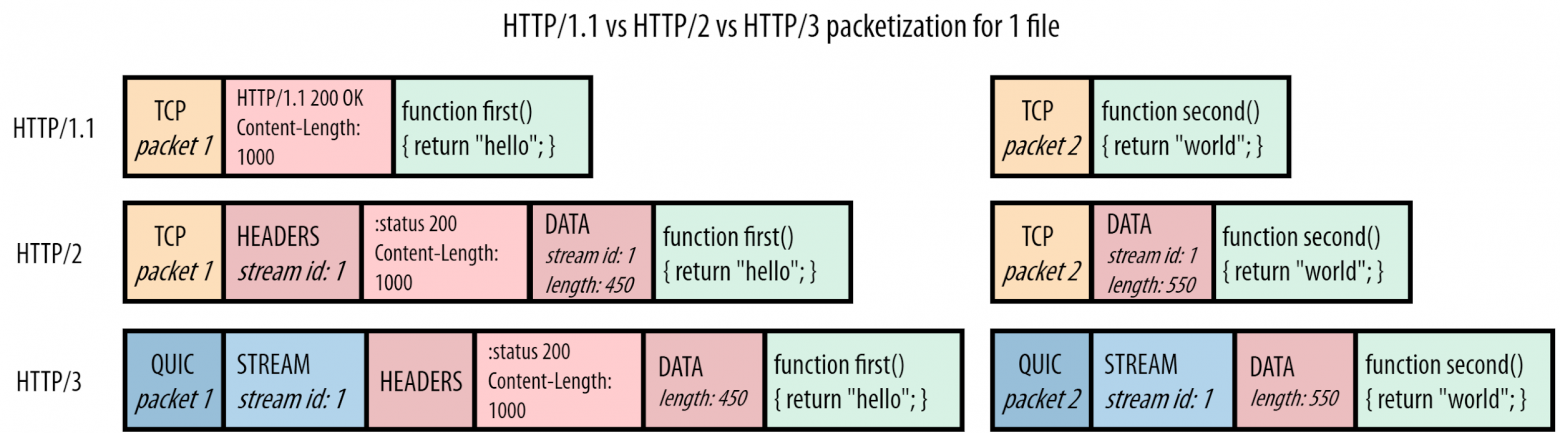
Заметим, что сообщать QUIC о разных потоках оказалось достаточно просто. QUIC вдохновлялся подходом HTTP/2 и поэтому реализовал собственные фреймы, в нашем случае используется STREAM-фрейм. Идентификатор потока, stream id, который в HTTP/2 был фреймом с типом DATA, теперь располагается на транспортном уровне в STREAM-фрейме QUIC. Это одно из объяснений, почему нам требуется новая версия HTTP, если мы хотим использовать QUIC. При использовании HTTP/2 у нас появляются два потенциально конфликтующих слоя с потоками. HTTP/3 удалил идею потоков из уровня HTTP и использует эту функциональность на уровне QUIC.
Примечание: это не значит, что QUIC внезапно знает о JS- или CSS-файлах или даже о том, что он передает HTTP. Как и TCP, QUIC должен быть универсальным протоколом. Он просто знает, что существуют разные потоки, которые можно обрабатывать по отдельности, без знания об их содержимом.
Теперь, когда мы знаем про STREAM-фреймы в QUIC, легко заметить, как они помогают решить проблему блокировок начала очереди на транспортном уровне.

Как и в DATA-фреймах HTTP/2, STREAM-фреймы QUIC отслеживают байты для каждого потока в отдельности. Для сравнения, TCP объединяет все потоки данных в один большой. А теперь давайте рассмотрим, что будет, если второй пакет QUIC потеряется, а первый и третий дойдут. Первый пакет с данными для первого потока будет передан в браузер, как и в случае с TCP. Однако в случае с третьим пакетом QUIC поступит умнее. Он посмотрит на данные для первого потока и поймет, что пришедший STREAM-фрейм является продолжением данных из первого пакета (байт 450 идет после 449, то есть нет разрывов в данных). Поэтому данные можно сразу же отдавать в браузер. Что касается второго потока, то QUIC видит, что часть данных отсутствует (байты 0-299 из второго пакета не были получены), и данные второго потока будут ждать переотправки второго пакета.
Аналогично обрабатывается ситуация, когда потерялся первый пакет, но второй и третий дошли. QUIC знает, что он получил все данные потока 2 и передал их браузеру, а первый поток стоит в ожидании. На этом примере мы видим, что QUIC решает проблему HOL blocking на уровне TCP.
Однако у этого подхода есть несколько важных следствий. Самое главное, что данные в QUIC могут быть доставлены не в том порядке, в котором они были отправлены. Отправка пакетов 1, 2 и 3 в TCP гарантирует, что они придут именно в таком порядке, но именно это вызывает блокировку начала очереди. Во втором примере выше при потере пакета 1 браузер первым получит содержимое потока 2 и уже потом, после переотправки потерянного пакета, содержимое потока 1. Иначе говоря, QUIC сохраняет порядок байт в одном потоке, но не порядок следования потоков.
Вторая и самая важная причина необходимости HTTP/3: некоторые системы HTTP/2 полагаются на детерминированное упорядочивание разных потоков в TCP. Например, система приоритизации в HTTP/2 отправляет операции, которые изменяют древовидную структуру данных, например, отмечает ресурс 5 как дочерний для ресурса 6. Если операции применять в порядке, отличном от порядка отправки, то клиент может получить не то, что хотел сообщить сервер. Аналогично для системы сжатия заголовков HPACK HTTP/2. Не нужно понимать особенности работы, важно только то, что, оказывается, сложно адаптировать системы HTTP/2 к QUIC. Поэтому для HTTP/3 используют радикально другие подходы. Например, QPACK — версия HPACK для HTTP/3 — позволяет выбирать компромисс между потенциальной блокировкой HOL и степенью сжатия. Система приоритизации HTTP/2 полностью удалена и, возможно, будет заменена значительно упрощенной модификацией для HTTP/3. Все потому что QUIC, в отличие от TCP, не гарантирует, что данные, которые отправлены первыми, будут получены первыми.
Итак, вся работа с QUIC и новой версией HTTP была просто для того, чтобы удалить блокировку начала очереди на транспортном уровне. Надеюсь, оно того стоило…
Действительно ли QUIC и HTTP/3 решают проблему HOL blocking?
Это немного плохой тон, но я процитирую себя:
QUIC сохраняет порядок байт в одном потоке.
Если подумать, это логично. Проще говоря, если у вас есть JavaScript-файл, то файл должен быть собран из фрагментов именно в том виде, в котором его создал программист, вернее WebPack, или код не заработает. То же самое справедливо и для других типов файлов. Если собирать изображения из фрагментов в случайном порядке, то можно получить аналог странной рождественской открытки от вашей тетушки, а может быть, даже более странной. Это означает, что HOL blocking остается в QUIC в некотором виде. Если внутри потока есть пробел, то остальные данные потока будут ожидать до тех пор, пока пробел не будет заполнен.
Это имеет решающее значение. QUIC решает проблему блокировок HOL только при обращении к нескольким ресурсам одновременно. Таким образом, если в одном из потоков происходит потеря пакетов, то другие могут продолжать работать. Мы видели это в примерах на рисунке 9. Однако, если активен только один поток и в нем происходят потери, то блокировка начала очереди актуальна, даже в QUIC. Итак, вот вопрос: как часто мы используем несколько потоков одновременно?
Как объяснялось ранее, в HTTP/2 (и HTTP/3) есть вещи, которые можно настраивать с помощью планировщика ресурсов. Потоки 1 и 2 могут быть отправлены как 1122, 2121, 1221 и так далее. Браузер может выбирать схему, по которой сервер станет отправлять ресурсы. То есть браузер может сказать: «Хэй! Я заметил серьезную потерю пакетов на этом соединении. Мне хочется, чтобы сервер отправлял пакеты в последовательности 121212 вместо 111222». В этом случае потеря одного пакета для 1 не будет влиять на прогресс 2. Но проблема заключается в том, что последовательность 121212 и аналогичные часто не оптимальны для производительности.
Это еще одна сложная тема, в которую я не хочу сейчас погружаться, но у меня есть видео на YouTube для заинтересованных. Впрочем, основную мысль легко понять на нашем простом примере файлов CSS и JS. Как вы знаете, браузер должен получить файл JS или CSS полностью, прежде чем он сможет выполнить или применить его. Хотя некоторые браузеры могут начать компиляцию или анализ частично загруженных файлов, им все равно необходимо дожидаться полной загрузки файла до начала использования. Мультиплексирование фрагментов ресурсов приведет к замедлению загрузки обоих файлов.
С мультиплексированием (медленнее): ----------------------------------- Поток 1 готов к использованию ▼ 12121212121212121212121212121212 ▲ Поток 2 завершил загрузку Без мультиплексирования/последовательно (быстрее для потока 1): --------------------------------------------------------------- Поток 1 загрузился и готов к использованию раньше ▼ 11111111111111111122222222222222 ▲ Поток 2 загрузился здесь
В этой теме много нюансов. Безусловно, бывают ситуации, когда использование мультиплексирования оправдано, например, если один из файлов намного больше другого. Но, в целом, для большинства ресурсов и страниц можно утверждать, что последовательный подход работает лучше. Опять же, смотрите видео на YouTube по ссылке выше, там много информации по теме.
Хорошо, но что это значит? Это значит, что у нас есть конфликт двух рекомендаций для оптимизации производительности:
- Для получения выгоды от решения проблемы блокировок начала очереди: мультиплексировать отправленные ресурсы (12121212).
- Быстро доставлять ресурсы браузеру, чтобы он быстрее их обрабатывал: отправлять ресурсы последовательно (11112222).
Итак, что выбрать? Или какой из способов должен иметь более высокий приоритет? К сожалению, я не могу дать вам окончальный ответ, поскольку я все еще занимаюсь исследованием этого вопроса. Основная проблема заключается в том, что сложно предсказать потери пакетов.
Как мы обсуждали ранее, пакеты теряются внезапно и целыми группами. Это значит, что наш пример с 12121212 слишком прост. Рисунок 10 представляет более реалистичную картину. Мы подразумеваем, что происходит один случай потери восьми пакетов во время загрузки двух потоков — зеленого и фиолетового.
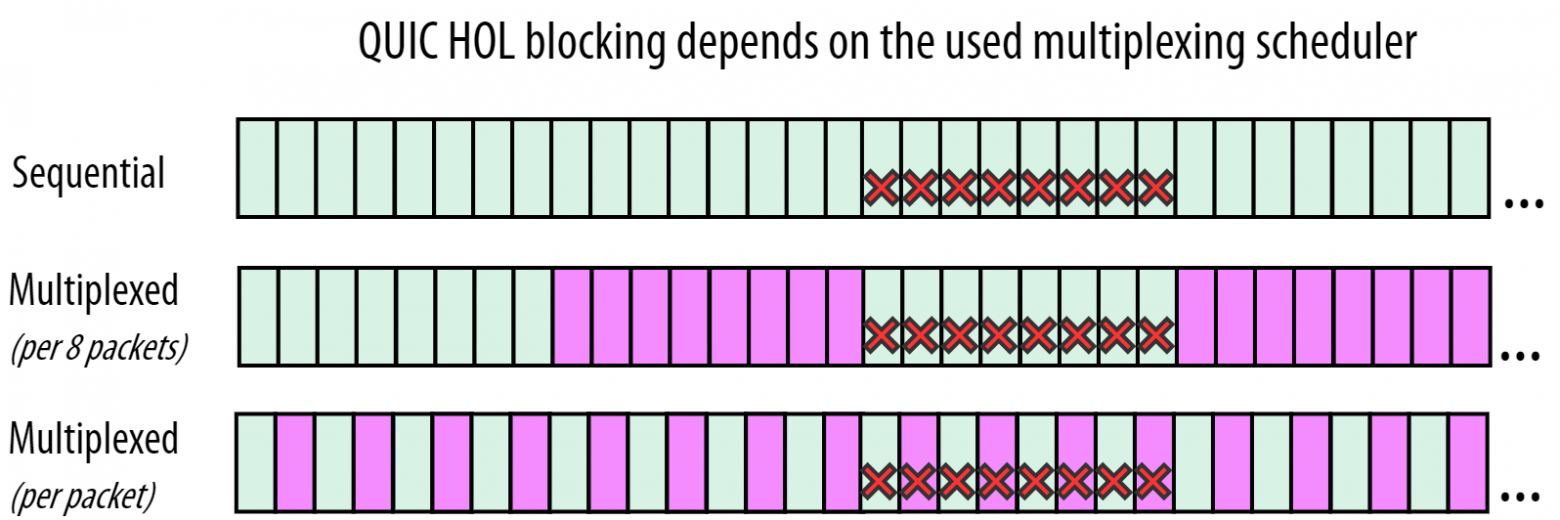
В верхней строчке рисунка 10 можно видеть последовательный подход, который обычно лучше с точки зрения скорости загрузки. Легко заметить, что решение QUIC для предотвращения блокировок начала очереди здесь не помогает совсем. Пакеты, полученные после потерянных, принадлежат к одному потоку, и потому зеленый поток не может быть передан браузеру. Второй, фиолетовый поток, не начал загрузку, а потому тоже не может быть передан браузеру.
Это отличается от средней строчки, где по счастливому стечению обстоятельств все восемь потерянных пакетов относятся к зеленому потоку. Значит, все фиолетовые пакеты пришли и поток может быть передан браузеру. Но, как обсуждалось ранее, браузер не сильно выиграет, если поток фиолетовых данных будет продолжаться. Таким образом, у нас есть преимущество из-за решенной проблемы блокировок: зеленый поток не блокирует фиолетовый. Однако использование мультиплексирования приводит к более долгой загрузке файла.
Нижний ряд демонстрирует практически худший случай. Восемь потерянных пакетов распределены между двумя потоками. Это значит, что оба потока попали в состояние блокировки начала очереди, но не потому что они ждут друг друга, как это было в TCP, а потому что каждый поток должен упорядочить данные внутри себя.
Примечание: вот почему большинство реализаций QIUC очень редко создают пакеты, содержащие данные больше, чем для одного потока. Если хоть один из таких пакетов потеряется, то это приведет к блокировке всех потоков, упоминающихся в потерянном пакете.
Итак, мы видим, что потенциально существует «золотая середина», изображенная на средней строке. Компромисс между предотвращением блокировок и производительностью может быть оправдан. Но потерю пакетов сложно предсказать. Это не всегда будет 8 пакетов, это не всегда будут пакеты из одного потока. Если потерянные пакеты сдвинутся всего на один влево, то у нас окажется один потерянный пакет фиолетового потока, что в какой-то степени приводит нас к нижнему случаю…
Думаю, вы согласитесь, что это звучит сложно. Возможно, даже слишком сложно. Возникает вопрос, насколько это оправданно. Как обсуждалось ранее, потеря пакетов во многих сетях встречается достаточно редко. Достаточно редко, чтобы увидеть какое-то влияние от решения проблемы блокировок. С другой стороны, известно, что мультиплексирование ресурсов по одному пакету, как на нижней строчке рисунка 10, одинаково плохо влияет на производительность как в HTTP/2, так и в HTTP/3.
Таким образом, HTTP/3 и QUIC не страдают от блокировок HOL на транспортном и прикладном уровнях, на практике это не так важно. Я не утверждаю это со стопроцентной уверенностью, потому что у нас еще нет готовых реализаций QUIC и HTTP/3, потому мы не можем провести экспериментов. Однако мое личное чутье, которое подтверждается несколькими ранними экспериментами, говорит о том, что решение проблемы HOL блокировок в QUIC не сильно помогает производительности, так как мы не хотим мультиплексировать потоки ради повышения производительности. И если вы действительно хотите, чтобы это работало хорошо, вам придется поработать над настройкой мультиплексирования в зависимости от типа соединения. Так, вы, определенно, не захотите мультиплексировать на быстрых сетях с низким количеством потерянных пакетов, так как в таких сетях блокировки HOL не случаются. По крайней мере, я не наблюдал.
Примечание: в конце я хочу отметить про небольшое противоречие в моей истории. Вначале я говорил, что проблема HTTP/1.1 — в невозможности мультиплексирования. В конце я говорю, что мультиплексирование не имеет значимой важности. Чтобы разрешить это противоречие, я добавил бонусную секцию в конце статьи.
Заключение
В этой очень длинной статье мы увидели проблему блокировок начала очереди через призму времени. Мы обсудили, почему HTTP/1.1 страдает от блокировок на прикладном уровне. В основном, конечно, из-за невозможности определять принадлежность фрагментов к ресурсам. HTTP/2 использует фреймы, чтобы помечать фрагменты и позволить мультиплексирование. Это решает проблему HTTP/1.1, но проблема актуальна также и для нижележащего TCP. Из-за абстракций TCP представляет данные HTTP/2 как единый и упорядоченный поток данных. Это позволяет встрять в блокировку начала очереди из-за потерянных или припозднившихся пакетов. QUIC решает эту проблему, перенося некоторые решения HTTP/2 на транспортный уровень. Это, в свою очередь, имеет серьезные последствия, и потоки больше не упорядочены между собой. Это привело к необходимости создавать протокол HTTP/3, который работает исключительно поверх QUIC, тогда как HTTP/2 работает исключительно поверх TCP, как показано на рисунке 6.
Нам нужно было изучить это все, чтобы критически осмыслить, насколько удаление блокировок HOL в QUIC и HTTP/3 действительно поможет для производительности интернета. Мы увидели, что это, скорее всего, окажет влияние на сети с большими потерями пакетов. Обсудили, когда нужно мультиплексировать ресурсы и почему это может принести больше вреда, чем пользы, на обычных сетях. Пришли к выводу, что, хотя еще рано говорить наверняка, удаление блокировок HOL в QUIC и HTTP/3 не сильно повлияет на производительность в интернете.
Итак, что же нам, поклонникам производительности Web, делать? Игнорировать QUIC и HTTP/3 и придерживаться HTTP/2 и TCP? Я надеюсь, что нет. Я верю, что в общем случае HTTP/3 будет быстрее, чем HTTP/2, ровно как и QUIC внесет свою лепту в улучшение производительности. Например, у него меньше накладных расходов, чем у TCP, он более гибкий с точки зрения контроля перегрузки сети и, что самое важное, имеет возможность устанавливать соединения 0-RTT (Zero Round Trip Time Resumption — прим.пер). Мне кажется, что именно 0-RTT принесет повышение производительности Интернета, хотя здесь есть достаточно проблем. В будущем я напишу еще один пост про 0-RTT, но если вам не терпится узнать про предотвращение атак с амплификацией, атак повторного воспроизведения и так далее, то ознакомьтесь с моими лекциями на YouTube или прочтите недавнюю статью.
Вы можете найти версию этого документа на github. Дайте мне знать, если хотите улучшить статью.
Бонус: конвейер HTTP/1.1
В HTTP/1.1 есть особенность под названием «конвейер», которую часто понимают неправильно. Я видел множество статей и даже книг, авторы которых утверждают, что конвейер в HTTP/1.1 решает проблему блокировок начала очереди. Я видел людей, которые утверждают, что конвейеризация — это то же самое, что и мультиплексирование. Но оба высказывания ложны.
Я нашел простой способ проиллюстрировать суть конвейера в HTTP/1.1.

Без конвейеризации (левая часть бонусного рисунка 1) браузер дожидается полного ответа на первый запрос и только после этого отправляет второй запрос. Такой подход увеличивает время загрузки каждого запроса на время прохождения одного запроса туда-обратно (Round-Trip-Time, RTT), что плохо для производительности Интернета.
С конвейеризацией (середина бонусного рисунка 1) браузеру не нужно дожидаться ответа от сервера, и он может отправлять запросы подряд. Это экономит некоторое количество времени, делая загрузку быстрее.
Примечание: Посмотрите на рисунок 2. Вы заметите, что конвейеризация работает, так как сервер отправил данные script.js и style.css в одном TCP-пакете. Конечно, это возможно, только если сервер получил оба запроса примерно в одно время.
Важно, что эта конвейеризация применима только к запросам из браузера. Спецификация HTTP/1.1 говорит следующее:
A server MUST send its responses to those [pipelined] requests in the same order that the requests were received. (Сервер ДОЛЖЕН отправлять ответы на запросы в том же самом порядке, в котором пришли запросы).
Таким образом, мы можем видеть, что настоящее мультиплексирование, изображенное на правой стороне бонусного рисунка 1 недостижимо с конвейерами HTTP/1.1. Другими словами, конвейеризация решает проблему блокировок начала очереди для запросов, но не для ответов. К сожалению, вероятно, блокировка HOL ответов больше влияет на производительность.
Что еще хуже, большинство браузеров не используют конвейеры HTTP/1.1 на практике, потому что это может сделать блокировку HOL более непредсказуемой при использовании нескольких параллельных TCP-подключений. Чтобы лучше понять это, давайте представим ситуацию с тремя файлами:
- А, большой;
- Б, маленький;
- В, маленький.
Данные файлы запрашиваются через два TCP-подключения. A и Б запрошены на разных подключениях. А теперь вопрос: какое подключение должен использовать браузер для запроса файла В? Как мы говорили ранее, браузер не знает, какой из файлов окажется самым большим или самым медленным.
Если он угадает верно и выберет подключение с файлом Б, то браузер сможет скачать файлы Б и В за время, которое необходимо для загрузки файла А, что будет неплохим ускорением. Однако, если выбор будет неправильным (А), то соединение с файлом Б будет простаивать, пока файл В заблокирован в очереди файлом А. Это потому что в HTTP/1.1, по сравнению с HTTP/2 и HTTP/3, нет механизма «отмены» отправленного запроса. Браузер не может отправить запрос на файл С через подключение с файлом Б, когда становится понятно, что так будет быстрее. Вместо этого браузеру приходится запрашивать файл В второй раз.
Чтобы не сталкиваться с этим, современные браузеры не используют конвейерную обработку и даже будут задерживать некоторые обнаруженные ресурсы, например изображения, на некоторое время. Это позволит убедиться, что более приоритетные файлы, такие как JS и CSS, не попали в блокировку HOL.
Очевидно, что провал конвейеризации HTTP/1.1 подтолкнул HTTP/2 выбрать совершенно другой подход. Тем не менее, система приоритизации HTTP/2 часто сбоит на практике и поэтому некоторые браузеры откладывают запросы HTTP/2 для достижения оптимальной производительности.
Бонус: HOL blocking в TLS
Как отмечалось ранее, протокол TLS обеспечивает шифрование (и не только) для протоколов прикладного уровня, таких как HTTP. Он «оборачивает» данные, полученные от HTTP в TLS-записи, которые идейно близки к фреймам HTTP/2 и пакетам TCP. Записи, например, содержат немного метаинформации в начале, чтобы указать их размер. Затем запись и ее содержимое шифруются и передаются TCP для отправки.
Шифрование — дорогая операция в терминах центрального процессора, поэтому наиболее эффективно шифровать сразу большие объемы данных за один подход. На практике TLS может шифровать ресурсы блоками до 16 КБ, чего достаточно для заполнения 11 обычных пакетов TCP.
Важно то, что TLS может расшифровывать только целые записи, поэтому может возникнуть TLS-версия блокировки HOL. Представьте, что TLS-запись распределена по 11 TCP-пакетам и последний из них потерялся. Так как запись не является полной, она не может быть быть расшифрована и ждет переотправки последнего пакета. Обратите внимание, что в этом случае нет блокировки HOL на уровне TCP: нет пакетов после 11, которые застряли в очереди из-за повторной передачи. Иными словами, если бы мы использовали простой HTTP вместо HTTPS, то данные из первых 10 пакетов уже были бы перемещены в браузер для обработки. Однако поскольку нам нужны все 11 пакетов для расшифровки, то возникает новая форма блокировки HOL.
Хотя это достаточно специфический случай, который, вероятно, не очень часто происходит на практике, он был принят во внимание при разработке протокола QUIC. Поскольку целью было решить все проявления блокировок начала очереди, то даже этот крайний случай был обработан. Это одна из причин, почему TLS интегрирован в QUIC. Шифрование не использует TLS-записи, а вместо этого шифрует пакеты напрямую. Такой подход требует больше процессорного времени и является менее эффективным, а это, в свою очередь, одна из основных причин, почему QUIC может быть медленнее TCP.
Бонус: Контроль перегрузок сети на транспортном уровне
Протоколы транспортного уровня, такие как TCP и QUIC, включают в себя механизм, который называется контроль перегрузок. Основная работа контроллера перегрузок — гарантировать, что сеть не перегружена избыточным количеством данных в каждый момент времени. Если происходит перегрузка, то буферы маршрутизаторов начинают переполняться, что приводит к отбрасыванию пакетов, которые не помещаются, а мы наблюдает потери пакетов. Обычно все начинается с отправки небольшого количества данных, примерно 14 КБ, с целью проверить, все ли будет хорошо. Если данные поступают, получатель отправляет подтверждение отправителю. Пока приходят подтверждения, отправитель удваивает свою скорость после каждого цикла «отправка-прием» (RTT) до тех пор, пока не произойдет первая потеря пакетов. Это означает, что сеть перегружена и нужно немного замедлиться. Вот так TCP «проверяет» доступную ему пропускную способность сети.
Примечание: приведенное выше описание является лишь одним из способов контроля перегрузок. В настоящее время набирают популярность другие методы, главным из которых является алгоритм BBR. Вместо того чтобы смотреть непосредственно на потерю пакетов, BBR учитывает колебания RTT, чтобы определить, не перегружается ли сеть и тем сама вызывает меньшие потери пакетов при проверки пропускной способности.
Важно: механизм контроля перегрузок работает независимо для каждого подключения TCP и QUIC! Это в свою очередь влияет на производительность сети на уровне HTTP. Во-первых, это означает, что первое соединение HTTP/2 в начале отправляет только 14 КБ данных. Но каждое из шести соединений HTTP/1.1 также отправляет по 14 КБ первый раз, что суммарно составляет 84 КБ. Со временем каждое соединение HTTP/1.1 будет удваивать количество данных с каждым RTT. Во-вторых, скорость соединения будет снижена только при потерях пакетов. Для одного соединения HTTP/2 потеря пакета означает снижение скорости в дополнение к блокировке начала очереди. Тем временем в HTTP/1.1 потеря одного пакета на одном соединении не замедлит пять остальных.
Это проясняет одну вещь: мультиплексирование HTTP/2 — это не одно и тоже с параллельной загрузкой ресурсов в HTTP/1.1, хотя я иногда встречаю людей, которые утверждают обратное. Доступная полоса пропускания одиночного HTTP/2 соединения просто распределяется между разными файлами, но блоки по-прежнему отправляются последовательно. Это отличает HTTP/2 от HTTP/1.1. где данные отправляются по-настоящему параллельно.
Вы можете спросить, как тогда HTTP/2 может быть быстрее, чем HTTP/1.1? Это хороший вопрос, который я задавал себе долгое время. Очевидный ответ: в случаях, когда у вас больше шести файлов. Именно так рекламировали HTTP/2 в свое время. Изображение разделяли на маленькие квадраты и загружали их, сравнивая быстродействие HTTP/1.1 и HTTP/2, но в основном это демонстрировало решение проблемы блокировок HOL в HTTP/2. Впрочем, загрузка обычных веб-сайтов имеет множество нюансов. Все зависит от количества ресурсов, их размеров, используемой политики приоритизации и схемы мультиплексирования, сколько и как часто происходят потери пакетов, сколько трафика в канале, как работает контроллер перегрузок и так далее. Один пример, где HTTP/1.1 проигрывает, — это сети с ограниченной пропускной способностью. Шесть подключений HTTP/1.1, каждый из которых увеличивает свою скорость самостоятельно, достаточно быстро приводят к перегрузке сети, вынуждая снижать скорость и выяснять пропускную способность методом проб и ошибок. До HTTP/2 считалось, что параллельные подключения HTTP/1.1 — это главная причина возникновения потерь пакетов в Интернете. Одиночное подключение HTTP/2 наращивает скорость медленнее, но быстрее восстанавливается после потерь пакетов и, соответственно, находит оптимальную пропускную способность быстрее. Более подробный пример с аннотациями, где HTTP/2 быстрее, можно увидеть на этом изображении. Слабонервным не смотреть.
QUIC и HTTP/3 используют одно соединение и потому столкнутся с теми же проблемами, что и HTTP/2. Вы можете сказать, что одно QUIC-подключение ведет себя как несколько TCP-подключений, по одному на каждый QUIC-поток, потому что определение потерь фиксируется на каждом потоке. Однако контроль перегрузки в QUIC осуществляется на уровне соединения. Это означает, что даже несмотря на концептуальную независимость потоков, все они влияют на один контроллер, вызывая замедление всего подключения при потерях в одном потоке. Другими словами, одно подключение QUIC и HTTP/3 не будет так же быстро наращивать скорость, как 6 соединений HTTP/1.1.
Бонус: Важно ли мультиплексирование?
Как отмечалось выше и как объяснено в деталях этой презентации, в большинстве случаев рекомендуется отправлять ресурсы веб-страницы последовательно, не используя мультиплексирование. Другими словами, если у вас есть два файла, то обычно лучше отправлять их 11112222, а не 12121212. Это особенно актуально для ресурсов, которые должны быть загружены полностью, прежде чем смогут быть применены, например, JS, CSS и шрифты.
В этом случае мы можем задать себе вопрос: а зачем нам нужно мультиплексирование? Более того, HTTP/2 и HTTP/3 представляют мультиплексирование как особенность, которой у HTTP/1.1 нет. Во-первых, некоторые файлы можно обрабатывать/рендерить постепенно, тем самым извлекая выгоду из мультиплексирования. Это, например, справедливо для современных форматов изображений. Во-вторых, как обсуждалось выше, если один из файлов намного меньше, чем другие, то он может быть загружен раньше, не сильно задерживая при этом другие файлы. В-третьих, мультиплексирование позволяет изменять порядок ответов и прерывать ответ с низким приоритетом для отправки ответа с более высоким приоритетом.
Хороший пример из практики: использование CDN-кэша. Допустим, браузер запрашивает два файла с CDN. Первый (1) не кэшируется и его нужно получить из первоисточника, что займет некоторое время. Второй ресурс (2) кэшируется в CDN и поэтому может быть получен браузером сразу.
При использовании HTTP/1.1 с одним подключением из-за блокировке HOL нам придется ждать полной загрузки (1), прежде чем мы сможем отправить (2). То есть отправка будет выглядеть так: 11112222, но с очень долгим временем ожидания. При использовании HTTP/2 файл (2) может быть загружен мгновенно, заполняя время, пока CDN и контроллер перегрузок «разогревается» первоисточником. Важно отметить, что если (1) начнет поступать до того, как (2) будет полностью загружен, то мы можем вводить данные (1) в поток ответа. Это будет выглядеть как 22111122 с значительно меньшим временем ожидания. Это может быть использовано в самом начале подключения с помощью функций Server Push или ранних подсказок HTTP 103.
Таким образом, полное «циклическое» мультиплексирование, такое как 12121212, редко бывает подходящим, само по себе мультиплексирование является полезной функцией.


{kind=link}
{kind=link}
{kind=link}