
Статья про противоположное применение рекомендательных систем - определение самого неподходящего товара для покупателей.
Статья про то, как определять спрос на новый товар, и как выявлять характеристики товара, из-за которых ритейл и интернет-площадки теряют продажи.
Статья про понимание, что нужно продавать и производить для потребителя.
Расскажу, как у меня появилась идея использовать алгоритмы машинного обучения для формирования ассортимента новой коллекции в ритейле.
Оглавление
Взгляд со стороны покупателя
Я человек, который обладает не изощренным чувством стиля, вкуса и который требователен к качеству товаров. Меня давно раздражают постоянные поиски хорошей вещи в масс-маркете, как в рознице, так и в онлайн.
Причиной длительных поисков я считаю - изобилие товаров плохого качества или товаров с непродуманными характеристиками.
Когда встречаю такие товары, задаюсь вопросами:
Кто такое покупает? Эта вещь своей цены не стоит
Не уже ли людям нужно такое разнообразие моделей?
Производители не понимают, что эту вещь никто не купит?
Думаю, многие этими вопросами задаются.
Ответы на них кроются в работе следующих бизнес-процессов:
составление бюджета на новую коллекцию;
планирование продаж;
формирование ассортимента товаров для новой коллекции;
формирование заказов поставщикам.
О них я кратко изложу в следующем разделе.
Взгляд со стороны бизнеса
Я проработала 5,5 лет системным аналитиком в ГК Спортмастер: это магазины Спортмастер, Demix, Skechers, O'stin, Funday и др. Я занималась разработкой информационной системы для планирования цепей поставок. Для её разработки также погружалась в процессы, связанные с исполнением цепей поставок и формированием товарного ассортимента.
Чтобы лучше сфокусироваться на устройстве процессов создания новой коллекции, предлагаю вспомнить советский мультик, по мотивам армянской сказки "Жадный Вартан".

Сама сказка
С овечьей шкурой к скорняку
Зашёл Вартан-сосед:
- Из этой шкуры шапку сшить
Ты можешь или нет?- Могу! - сказал в ответ скорняк,
На шкуру посмотрев.
- А выйдет две? - спросил Вартан,
На корточки присев.- И две сошью.
- А три?
- И три!
- Сошьёшь четыре?
- Да!
- А пять?
- Ну что ж, могу и пять,
Коль в этом есть нужда!- Быть может, выкроешь все шесть?
- Могу, раз надо так!
- Где шесть, там - семь! - сказал Вартан.
- Идёт! - сказал скорняк.Когда заказчик через день
За шапками пришёл,
Семь шапок выложил скорняк
На свой рабочий стол.- Да разве это мой заказ?
Вскричал в сердцах Вартан.
Когда ты шапки мне кроил,
Ты был, должно быть, пьян?Что с ними делать мне теперь?
Куда прикажешь деть?
Ведь ни одну из них нельзя
На голову надеть!- Но ты же сам того хотел!
Сказал в ответ скорняк.
Больших семь шапок из овцы
Не выкроишь никак!
А теперь я покажу как формально выглядит процесс создания новой коллекции:

1. Формирование бюджета на новую коллекцию
Наш богач - это топы ритейла, который дает исполнителям овчину - бюджет с продаж предыдущей коллекции. На его основе исполнители (скорняк и музыкант) распределяют этот бюджет по категориям товаров.
2. Планирование продаж
В мультфильме музыкант, подначивающий жадного богача сшить из одной шкурки 3-6 шапок, очень похож на плановиков-продажников в ритейле. Плановики анализируют продажи предыдущих коллекций, делают приблизительный прогноз продаж.
С результатами этого анализа плановики идут к топам и презентуют показатели маржи.
От размеров ожидаемого роста маржи сильно зависит здравость взгляда топов и плановиков на размер бюджета:
Есть ритейлеры, которые видят и понимают, что в предыдущей коллекции было доступно 200 овчинок, из которых было сшито и продано 200 шапок. А если для формирования новой коллекции доступно 100 овчинок, значит продать они смогут 100 шапок;
Есть ритейлеры, которые хотят получить маржу с 7 шапок из одной овчинки.
К сожалению, ритейлеры из второй категории в большинстве и в России, и в мире, поэтому покупатели возмущаются.
После встречи с топами, воодушевленные плановики идут с планом продаж к первым скорнякам - это продуктовые (категорийные) менеджеры в группе с дизайнерами и технологами.
3. Формирование ассортимента товаров
Простой обыватель думает, что все вещи на полках в магазине - это только дизайнерское решение. Это справедливо, если это бутики D&G, Louis Vuitton и пр.
У масс-маркета за ассортимент в коллекции отвечают продуктовые менеджеры. Они на основе бюджета и планов продаж могут принимать такие решения как:
Какие тренды моды использовать в новой коллекции;
Какие модели товара и в каком количестве включить в новую коллекцию;
Какие товары нужно выводить из разработки;
Какая характеристика или деталь товара, может привлечь покупателя.
Приняв подобные решения, продуктовый менеджер кооперируется с дизайнерами и технологами, чтобы определиться со стилем коллекции, материалами и додумать ассортимент.
Почему план продаж я упомянула во множественном числе. Продуктовые менеджеры кроме плана продаж на новую коллекцию смотрят еще на то, как шли продажи по конкретному товару в предыдущих коллекциях. Благодаря этому у них складывается приближенное к реальности представление о будущих продажах этого товара. По этой причине споры и конфликты с плановиками на этапе формирования коллекции являются частью ритуала.
Увы, продуктовым менеджерам приходится соглашаться с бюджетом и планом продаж, так как они одобрены высшим руководством. Чтобы оставаться в рамках ограничений им приходится в угоду разнообразия товаров экономить на их качестве, да так, чтобы товары пользовались спросом.
4. Формирование заказов поставщикам
Вторые скорники - это отделы планирования и формирования заказов поставщикам и производители товаров.
На данном этапе поставщики и производители получают заказы на производство/закупку семи шапочек товаров из сформированного ассортимента новой коллекции.
Выводы
- Жизнь становится проще, когда понимаешь, что и как происходит.
Ирада Зейналова
Из раскрытого занавеса мира ритейла выделяются две проблемы в принятии решения о составе коллекции:
У топов и плановиков - завышенные ожидания в высоких продажах;
У продуктовых менеджеров - разработать такой товар, который будет пользоваться спросом у покупателей и удовлетворять аппетиты первых. Для решения этой задачи им нужно понять на каких характеристиках товара можно сэкономить, а на каких нельзя.
Первая проблема больше связана с необходимостью удержания своих конкурентных позиций на рынке, чем с жадностью топ менеджмента.
Острота второй проблемы зависит от экспертизы продуктовых менеджеров и команды дизайнеров с технологами. Эксперты могут даже при малом бюджете создать коллекцию, которая будет пользоваться спросом.
Однако, если к ограниченному бюджету добавить внешние факторы - снижающийся спрос, пандемия, санкции, разрыв цепочек поставок, то тут даже эксперту трудно сформировать коллекцию и легко прогадать с её ассортиментом.
Не удачно сформированный ассортимент для коллекции приводит к следующей проблеме для ритейла - товар в своей коллекции полностью не реализовывается.
Что делает ритейлер с не реализованным товаром (касательно одежды/обуви):
1. возвращает товар из магазина обратно на склад, чтобы освободить место для новой коллекции (иногда могут оставить продаваться в новой коллекции) или
2. перевозит товар в стоковые магазины;
3. выделяют место на складе для длительного хранения товара;
4. если торговая сеть арендует склад , то платится аренда за хранение;
5. при переводе товара в новую коллекцию, его обратно везут в магазины со склада;
6. если товар N раз переходил из коллекцию в коллекцию, то его отправляют на переработку.
Для ритейла все перечисленные действия - это большие издержки, которые не идут на развитие бизнеса!
Вдобавок, эта проблема причиняет вред экологии.
Чтобы нивелировать эти проблемы - проводят акции, чаще отображают не популярный товар в блоках рекомендаций интернет-площадок. Только эти действия являются Failure Demand, т.е. они не устраняют первопричину проблемы - плохо сформированный ассортимент.
Failure Demand
Потери – действия, не являющиеся необходимыми для получения конечного результата для клиента, которых можно избежать или минимизировать, если иначе организовать технологический процесс
Решение проблемы
Решение заключается в моей системе (подходе), которая использует алгоритмы классического машинного обучения, NLP и инструменты для интерпретации результатов моделей.
С её помощью можно убить трех зайцев:
Спрогнозировать спрос на новый товар (Low/ Moderate/ High);
Определить характеристики товара, которые повышают или понижают спрос;
На основе пункта 1 и 2 изменить конфигурацию товара и скорректировать план продаж.
Далее будет приведен ход реализации системы.
RecSys и «Ошибка выжившего»

RecSys расшифровывается как рекомендательная система.
Посмотрим на определение рекомендательных систем и на значение слов Рекомендовать и Рекомендация из словаря Владимира Ивановича Даля:
Рекомендательные системы — программы, которые пытаются предсказать, какие объекты (фильмы, музыка, книги, новости, веб-сайты) будут интересны пользователю, имея определенную информацию о его профиле.
Wikipedia
Рекомендовать:
- представить, познакомить;
- поручать вниманию, заступничеству, замолвить за кого слово;
- хвалить, как годного, способного на какое-либо дело, одобрять;
- предлагать, приказывать, поручать исполнить.
Рекомендация:
- хороший отзыв, похвала, одобрение.
Рекомендательные системы работают в блоках рекомендаций, которые есть у каждой интернет-площадки.
Если следовать данным определениям, то блоки рекомендаций знакомят, предлагают покупателям товар, который хвалят и одобряют.
Есть еще важное условие - в рекомендациях должен быть самый подходящий товар для покупателя.
Для определения подходящего товара разработаны специальные алгоритмы машинного обучения:
Collaborative Filtering: Item based, User based
Content based и др.
Почитать про них можете в этой статье (на английском).
Также есть другие правила, о которых простой покупатель может и не догадываться, когда он видит товары в подборке рекомендаций:
по товару должен быть определенный уровень остатка для рекомендации;
товар плохо пользуется спросом;
у товара высокое количество просмотров или покупок;
товар-новинка;
продавец оплатил услугу продвижения товара в топе рекомендаций (распространено у площадок для размещения объявлений) и др.
Сочетание этих бизнес-правил с алгоритмами машинного обучения может сформировать удивительную подборку рекомендаций, на подобие обложки этого раздела.
Первую скрипку в формировании неудачных рекомендаций играет главный подход рекомендательных систем - определять самый популярный и самый подходящий товар.
С этим подходом мы совершаем «ошибку выжившего» - фокусируемся на положительных аспектах и не задумываемся почему другие товары не подходят или не пользуются популярностью у покупателей.
Такой односторонний подход побудил меня на исследование «тёмной стороны Луны» - применение алгоритмов рекомендательных систем для прогнозирования антирейтинга товаров и для выявления негативных характеристик товара.
В результате исследования, я создала подход NoRecSys.
NoRecSys

NoRecSys, в отличии от RecSys в интернет-площадках, является B2B решением. Это значит, что картинку с антирейтингом товаров должны видеть и изучать сотрудники ответственные за формирование ассортимента коллекции. Так они смогут не допустить эти товары до потребителя и снизить издержки на производство новой коллекции.
Разработка NoRecSys состояла из трёх этапов:
Составление антирейтинга товаров с низким спросом;
Сегментация товаров и прогнозирование спроса для товара;
Определение характеристик товара, которые негативно или положительно влияют на спрос.
Исследование и разработку я проводила над дата сетом компании H&M с соревнования на Kaggle.

Состав дата сета:
Транзакции:
Дата покупки
Id покупателя
Id товара
Цена
Товарный каталог:
Id товара
Код/Наименование товара
Код/ Наименование типа товара
Код/ Наименование графического рисунка
Код/ Наименование цветовой группы
Код/ Наименование воспринимаемого тона
Код/ Наименование воспринимаемого цвета
Код/ Наименование секции и департамента
Код/ Наименование группы одежды
Описание товара
Данные собраны за период: сентябрь 2018 - сентябрь 2020.
Для работы с данными мне потребовалось создать 4 новые фичи на основе транзакций:
Год-месяц совершения покупки
Коллекция – AW/SS
Цикл продаж по каждому товару
Количество проданного товара (спрос). Здесь я рассчитывала уникальное количество покупателей на товар.

Код для получения года-месяца, коллекции и цикла продаж из транзакций
### year-month, collection train = pd.read_csv('transactions_train.csv') trans = pd.DataFrame({'year': pd.to_datetime(train['t_dat']).dt.year, 'month': pd.to_datetime(train['t_dat']).dt.month, 't_dat': pd.to_datetime(train['t_dat']), 'article_id': train['article_id'], 'customer_id': train['customer_id'], 'price': train['price'], 'sales_channel_id': train['sales_channel_id'], 'collection': 'AWSS' }) transaction_aw19 = trans.query('(year == 2018 and month in (9,10,11,12)) or (year == 2019 and month in (1,2))').replace('AWSS','AW19') transaction_ss19 = trans.query('year == 2019 and month in (3,4,5,6,7,8)').replace('AWSS','SS19') transaction_aw20 = trans.query('(year == 2019 and month in (9,10,11,12)) or (year == 2020 and month in (1,2))').replace('AWSS','AW20') transaction_ss20 = trans.query('year == 2020 and month in (3,4,5,6,7,8)').replace('AWSS','SS20') transaction_sep20 = trans.query('year == 2020 and month == 9').replace('AWSS','SEP20') ### Sales cycle table_art_trans_aw19 = transaction_aw19.merge(train_art, on='article_id', how = 'inner').drop(columns = drop_columns) table_art_sc_aw19 = pd.pivot_table(table_art_trans_aw19, index=["article_id"], values=["t_dat", "customer_id", "price"], aggfunc={"t_dat": [np.min, np.max], "customer_id": len, "price": np.sum}) table_art_sc_aw19 = table_art_sc_aw19.reset_index() table_art_sc_aw19['sales_cycle'] = table_art_sc_aw19['t_dat']['amax'] - table_art_sc_aw19['t_dat']['amin'] table_art_sc_aw19['collection'] = table_art_trans_aw19['collection']
Теперь можно посмотреть на собранную статистику по транзакциям.
Количество проданного товара в каждой коллекции:
AW19 = 49523
SS19 = 53823
AW20 = 51511
SS20 = 50599
SEP20 = 26252
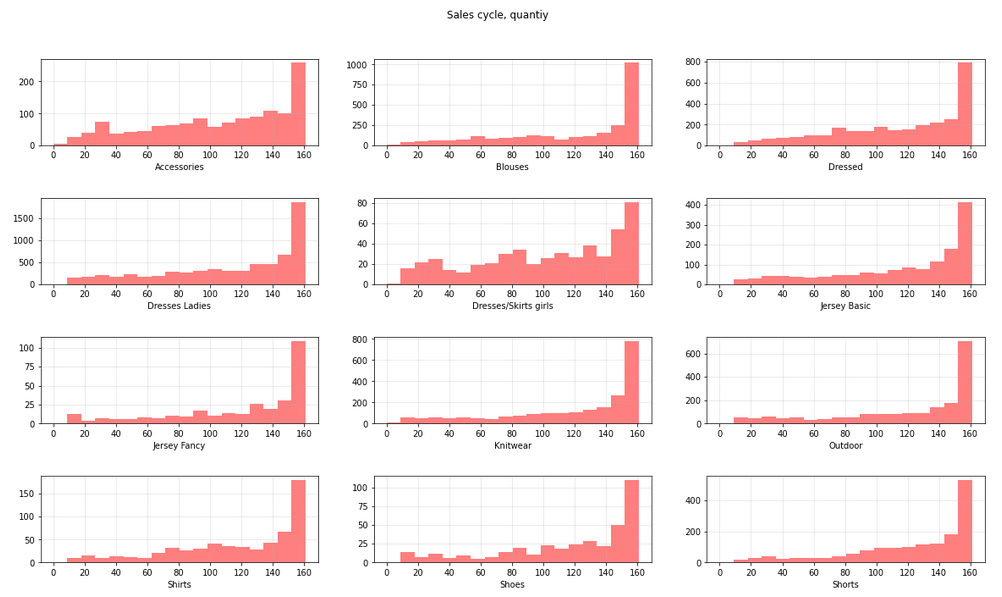
Гистограммы по циклу продаж для каждой группы одежды:
Гистограмма по количеству проданного товара для каждой группы одежды:
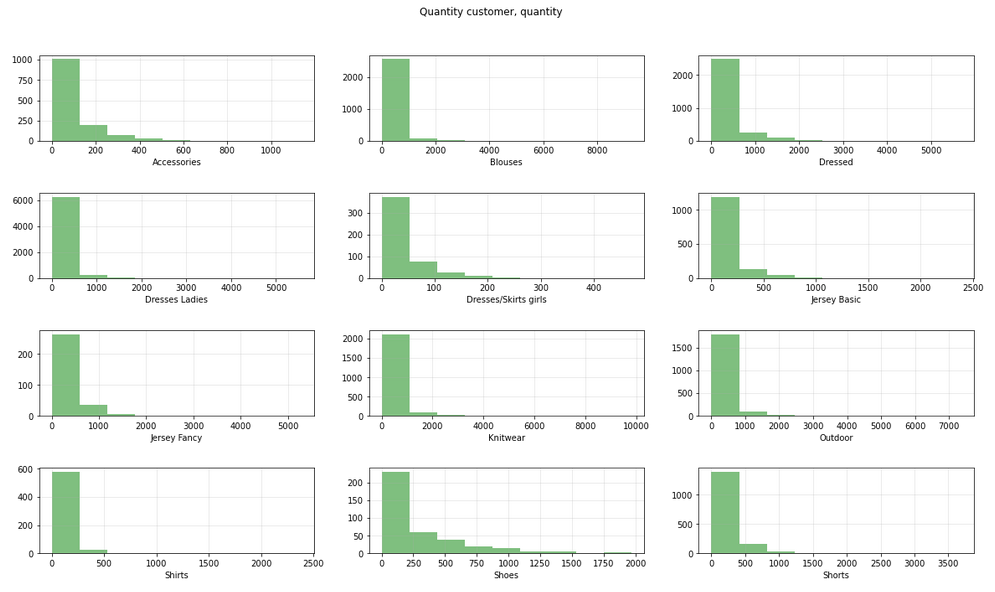
Товары с циклом продаж меньше 7 дней я исключила, чтобы они не вводили в заблуждение. В дата сете отсутствует информация о доступных остатках. Количество товара в остатке за определенный период может подсказать с какой скоростью продавался товар. Без этой информации, делать вывод, что товар хорошо продается, если его раскупили за неделю, безосновательно. Причиной может быть небольшое количество товара в остатках.
Антирейтинг
Для получения антирейтинга я отсортировала товары по убыванию цикла продаж и возрастанию количества проданного товара.
Таким способом я получила топ-20 товаров, которые в коллекции AW19 не пользовались спросом у покупателей целых 161 день:
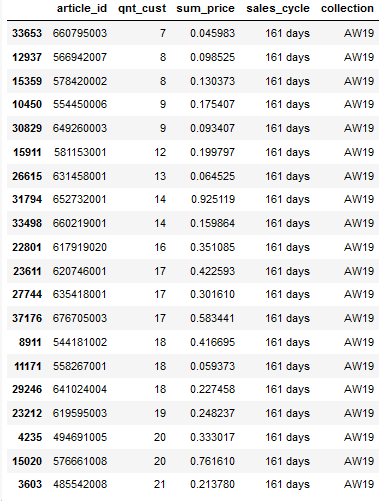
Изображение товаров из антирейтинга:

Этот антирейтинг я показала своим сокурсникам и преподавателю по курсу ML и спросила их какой товар им нравится. Итог - ни один из товаров антирейтинга не понравился и желания купить их не появилось. Мне интересно, а аудитории Habr какой-то товар понравился? Можете в комментариях к статье написать: понравился или нет.
Тут я поняла, что держу верный курс.
Переходим к следующему этапу - сегментация товаров.
Агломеративная кластеризация для сегментации товаров
Цель - разбить товары по спросу на 3 класса: низкий спрос (Low), умеренный спрос (Moderate) и высокий спрос (High).
Для этой цели я решила использовать иерархическую кластеризацию с агломеративным алгоритмом.
Такой тип кластеризации я выбрала по двум причинам:
Простота настройки параметров модели;
Получение «полосатых» кластеров.
Для меня «полосатые» кластеры - это четкое вертикальное выделение набора данных в разрезе цикла продаж и спроса, где фактором выделения данных от остальных является спрос.
Это условие выделения данных хорошо продемонстрируют графики рассеивания:

Думаю, Вы обратили внимание, что количество кластеров на графиках больше 3-х классов. Почему?
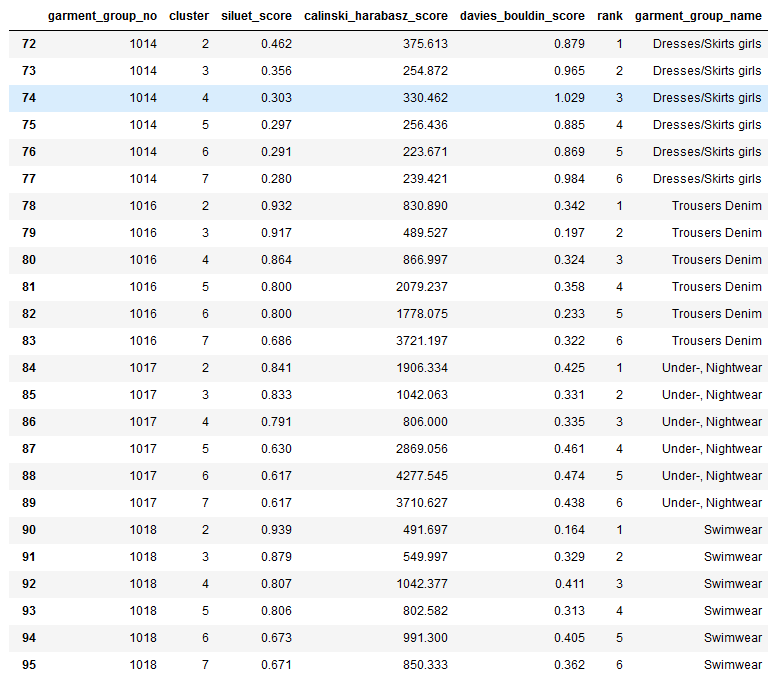
Для каждой группы одежды я подбирала оптимальное количество кластеров по метрикам качества кластеризации - Силуэт, индекс Дэвиса-Болдуина и индекс Калински-Харабаса.
Я собираюсь распределить кластеры между тремя классами так, чтобы по максимуму снизить несбалансированность классов.
Код функций для подбора оптимального количества кластеров
from sklearn.cluster import AgglomerativeClustering from collections import defaultdict def clusters_silhouette(affinity): silhouette = [] for gg in garment_group_list: split_data_aw19 = preproc_data_aw19.loc[preproc_data_aw19.garment_group_no == gg] k_max = 10 for k in range(2, k_max): agcl_aw19 = AgglomerativeClustering(n_clusters = k, linkage = "complete", affinity = affinity).fit(split_data_aw19) silhouette.append([gg, k, round(metrics.silhouette_score(split_data_aw19, agcl_aw19.labels_), 3)]) return silhouette def clusters_davies_bouldin(affinity): dv = [] for gg in garment_group_list: split_data_aw19 = preproc_data_aw19.loc[preproc_data_aw19.garment_group_no == gg] k_max = 10 for k in range(2, k_max): agcl_aw19 = AgglomerativeClustering(n_clusters = k, linkage = "complete", affinity = affinity).fit(split_data_aw19) dv.append([gg, k, round(metrics.davies_bouldin_score(split_data_aw19, agcl_aw19.labels_), 3)]) return dv def clusters_calinski_harabasz(affinity): ch = [] for gg in garment_group_list: split_data_aw19 = preproc_data_aw19.loc[preproc_data_aw19.garment_group_no == gg] k_max = 10 for k in range(2, k_max): agcl_aw19 = AgglomerativeClustering(n_clusters = k, linkage = "complete", affinity = affinity).fit(split_data_aw19) ch.append([gg, k, round(metrics.calinski_harabasz_score(split_data_aw19, agcl_aw19.labels_), 3)]) return ch ### Выов функций clusters_silhouette = clusters_silhouette('l1') clusters_davies_bouldin = clusters_davies_bouldin('l1') clusters_calinski_harabasz = clusters_calinski_harabasz('l1') ### Собираем метрики в DataFrame ## silhouette group = [] cluster = [] silhouette = [] for g, cl, s in clusters_silhouette: group.append(g) cluster.append(cl) silhouette.append(s) ds = {'garment_group_no': group, 'cluster': cluster, 'siluet_score': silhouette} optim_metric_s = pd.DataFrame(ds) ## davies_bouldin group = [] cluster = [] db = [] for g, cl, d in clusters_davies_bouldin: group.append(g) cluster.append(cl) db.append(d) ddb = {'garment_group_no': group, 'cluster': cluster, 'davies_bouldin_score': db} optim_metric_d = pd.DataFrame(ddb) ## calinski_harabasz group = [] cluster = [] ch = [] for g, cl, c in clusters_calinski_harabasz: group.append(g) cluster.append(cl) ch.append(c) dch = {'garment_group_no': group, 'cluster': cluster, 'calinski_harabasz_score': ch} optim_metric_ch = pd.DataFrame(dch) ## Делаем единый DataFrame с метриками и сортируем их, проставляя ранг table_optim_metric_cl = optim_metric_s.merge(optim_metric_ch, on=['garment_group_no','cluster'], how = 'inner').merge(optim_metric_d, on=['garment_group_no','cluster'], how = 'inner') table_optim_metric_cl = table_optim_metric_cl.sort_values(by=["garment_group_no", "siluet_score", "calinski_harabasz_score", "davies_bouldin_score", "cluster"], ascending = [True, False, False, True, False], kind = "mergesort") table_optim_metric_cl['rank'] = table_optim_metric_cl.groupby('garment_group_no')['garment_group_no'].cumcount().add(1) table_optim_metric_top_cl = table_optim_metric_cl.query('rank <=6').merge(data_aw19[['garment_group_no', 'garment_group_name']].drop_duplicates(), on=['garment_group_no'], how = 'inner') ## Вывод от ранжированных кластеров table_optim_metric_top_cl.loc[table_optim_metric_top_cl.garment_group_no > 1013]
В результате выполнения кода я получила перечень кластеров со значениями метрик и их рангами:
Разметка данных на классы Low, Moderate, High
Класс Low я присвоила товарам из самого левого кластера. Класс Moderate я установила следующим двум-трем кластерам, а остальным кластерам - High. В некоторых случаях я делила кластер пополам.
Например, для группы одежды Blouses:
кластер 6 - Low
кластеры 0 и 3 - Moderate
кластеры 1, 2, 4 и 5 - High
Для группы одежды Skirts:
кластер 3 - Low
кластеры 1 и 2 (qnt_cust < 1000) - Moderate
кластеры 0 и 2 (qnt_cust >= 1000) - High
После разметки данных обнаружила, что класс Low все равно преобладает над остальными классами на четверть. Чтобы уменьшить класс Low, я исключила в нем товары с циклом продаж <= 80 дней. У этих товаров причиной низкого спроса мог быть доступный остаток на 3 и менее месяца.
В результате, по всем группам одежды получилось такое соотношение классов:
Low = 15127 товаров
Moderate = 13335 товаров
High = 659 товаров
При всех стараниях класс High все равно оказывается в меньшинстве. Напрашивается включить товары этого класса в класс Moderate. Но этого я делать не буду по двум причинам:
Среди одежды/обуви/аксессуаров не так много товаров и категорий, чтобы их производили и покупали в размере от 2-3 тысяч штук;
Класс High мне нужен, чтобы выявлять характеристики товаров, которые повышают шансы товара пользоваться большим спросом у покупателей.
Переходим к этапу построения модели, которая прогнозирует спрос по товару и указывает какие характеристики повлияли на выбор класса.
Использование описания товара для прогнозирования спроса
На данном этапе для товаров из тренировочной выборки (коллекция AW19) и для тестовой выборки (коллекция AW20) создала матрицу с TF-IDF векторами на основе текстового описания товаров. Для построения векторов использовала триграммы (словосочетания из трех слов). Количество триграмм = 87722.
TF-IDF — статистический показатель, применяемый для оценки важности слова в контексте категории, документа или коллекции документов. Используется при анализе текстовых данных.
Как правило, TF-IDF определяется для каждого слова. Чем выше значение данного показателя, тем значимее слово в контексте категории, документа, коллекции. При этом данный показатель также позволяет учесть и широко употребляемые слова, понизив их значимость в контексте объекта для анализа.
Более подробная информация по TF-IDF в источнике.
Матрицы TF-IDF векторов я использовала для двух моделей классификации:
Первая модель - kNN
Я сделала свою реализацию kNN, с использованием косинусного расстояния и количеством ближайших соседей = 100.
Реализация kNN на Python
import numpy as np import pandas as pd from sklearn.metrics.pairwise import cosine_similarity from sklearn.feature_extraction.text import TfidfVectorizer, TfidfTransformer import ipyplot ## Отбор данных по группе одежды и типу товара def select_sku(garment_group_name, product_type_name): return data.loc[(data.garment_group_name == garment_group_name)&(data.product_type_name == product_type_name)] ## Получение текстовых описаний товаров supdir = select_sku('Dresses Ladies', 'Dress') desc = supdir['description'] ## TF-IDF tfidf = TfidfVectorizer(analyzer='word', stop_words='english', ngram_range = (3,3), lowercase=False) tfidf_matrix = tfidf.fit_transform(desc) ## Измеряем косинусное расстояние между векторами cosine_similarities = cosine_similarity(tfidf_matrix) similarities = {} ## Отбираем для каждого товара 100 ближайших товаров for i in range(len(cosine_similarities)): # сортировка по схожести и запись индексов similar_indices = cosine_similarities[i].argsort()[:-100:-1] # список самых похожих товаров similarities[supdir['article_code'].iloc[i]] = [(cosine_similarities[i][x], supdir.iloc[x]['description'], supdir.iloc[x]['collection'], supdir.iloc[x]['Demand'], supdir.iloc[x]['sales_cycle'], supdir.iloc[x]['article_code'], supdir.iloc[x]['qnt_cust']) for x in similar_indices][1:] if i == 500 or i == 1000 or i == 1500 or i == 2000 or i == 2500 or i == 3000 or i == 3500 or i == 4000: print('qnt rows processed:',i) ## Отчет для отображения результатов классификации def antireiting(art_new): # распечатаем параметры для нового артикула print(f'-------- Parametrs for new article:{art_new} ------------') print('True qnt_cust', aw20.loc[aw20.article_id == art_new]['qnt_cust'].values) print('collection', aw20.loc[aw20.article_id == art_new]['collection'].values) print('True sales_cycle', aw20.loc[aw20.article_id == art_new]['sales_cycle'].values) print('Description', supdir.loc[supdir.article_code == art_new]['description'].values) print('----------------------------------------------------------') a, c, sc, dem, cus, sim, des = [], [], [], [], [], [], [] for i in range(len(similarities[art_new])): if similarities[art_new][i][2] == 'AW19' and similarities[art_new][i][4] >= 100: #art a.append(similarities[art_new][i][5]) #collection c.append(similarities[art_new][i][2]) #sales_cycle sc.append(similarities[art_new][i][4]) #demand dem.append(similarities[art_new][i][3]) #qnt_cust cus.append(similarities[art_new][i][6]) #similarities sim.append(round(similarities[art_new][i][0], 5)) #description des.append(similarities[art_new][i][1]) d = {"art_old": a, "collection": c, "similarities": sim, "qnt_cust": cus, "sales_cycle": sc, "demand": dem, "description": des} tab = pd.DataFrame(d).sort_values(by = 'similarities', ascending = False).head(15) demand = list(np.unique(tab['demand'])) q = tab['art_old'].nunique pivot = pd.pivot_table(tab, index=["demand"], values=["art_old"], aggfunc= len ) pivot.plot.pie(y='art_old', title = 'Expected type of demand', colormap = 'Set3', autopct ='%1.1f%%', figsize=(5, 5)) return tab ## Вывод отчета по двум артикулам antireiting('710108002AW20') antireiting('735226004AW20')


По отчету и изображениям видим, что у ближайших соседей из AW19 платья 710108002 из AW20 преобладает класс Low. Данный класс предсказан верно, так как действительно за всю коллекцию AW20 его было куплено 14 штук.
Это не удивительно. Для осени и зимы летний фасон, ткань и принт не уместны.
Теперь давайте посмотрим на мужские джинсы:


У мужских джинсов 735226004 коллекции AW20 тоже большинство соседей с низким спросом в AW19. Прогноз верный - в AW20 джинсы с лампасами купило 5 человек.
Здесь аналогичная причина низкого спроса - укороченные, зауженные и светлые джинсы не для осени и зимы. Красные лампасы на любителя.
Давайте посмотрим на товары из класса Moderate (умеренный спрос).


В коллекции AW20 мужские джинсы 616598022 продали 455 штук, что соответствует умеренному спросу. Прогноз верный.
Причиной умеренного спроса мог послужить темный цвет и подходящий фасон для осени.
На первый взгляд kNN хорошо делает прогноз. Но говорить гоп рано. Посмотрим какой будет прогноз для платья 835247002, которое купили в AW20 869 шт.


Прогноз низкого спроса на платье не совпал с фактом.
kNN для большинства товаров с фактическим спросом Modarate был классифицирован некорректно.
Возможная причина в ошибке прогноза - это недостаточное количество ближайших соседей. У алгоритма kNN один из основных недостатков - подбор оптимального k, отсюда и чувствительность к дисбалансу в классах.
По этой причине я решила сменить kNN на другую модель классификации более точную, простую в настройке и быструю - Наивный байесовский классификатор.
Вторая модель - Наивный байесовский классификатор
Для выбора классификатора я воспользовалась bencmark для классификации текстовых документов:
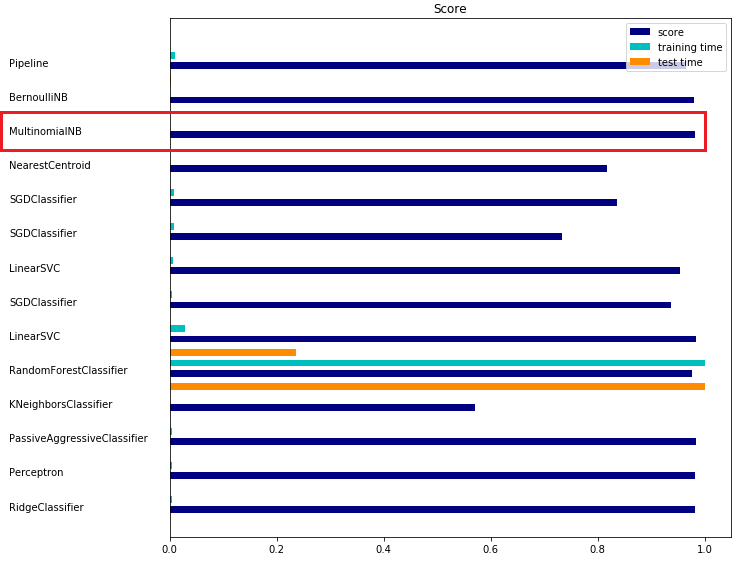
Для второй модели изменила формат дата сета. Собрала все характеристики товара (кроме цикла продаж, и различные идентификаторы) и объединила их с текстовым описание товара. В результате получила следующий набор данных:
article_id | text |
681933001 | price_81, product_type_name_T_shirt, product_group_name_Garment_Upper_body, graphical_appearance_name_Solid, colour_group_name_White, perceived_colour_value_name_Light, perceived_colour_master_name_White, department_name_Woven_Premium, index_name_Ladieswear, index_group_name_Ladieswear, section_name_Womens_Premium, Silk top with a V_neck and spaghetti straps. Lined. |
628593001 | price_48, product_type_name_Jacket, product_group_name_Garment_Upper_body, graphical_appearance_name_All_over_pattern, colour_group_name_Dark_Grey, perceived_colour_value_name_Dark, perceived_colour_master_name_Grey, department_name_Ladies_Sport_Woven, index_name_Sport, index_group_name_Sport, section_name_Ladies_H&M_Sport, Outdoor jacket in fast_drying, functional rustle fabric with a drawstring hood, stand_up collar and zip down the front. Long sleeves with elasticated cuffs, side pockets with a press_stud and a ribbed, elasticated hem. Unlined. |
Затем я преобразовала эти данные в TF-IDF векторы.
Добавила характеристики для улучшения прогноза и для выявления их влияния на прогноз.
Код для обучения наивного байесовского классификатора и получения прогнозов для коллекции AW20:
import numpy as np import pandas as pd from sklearn.metrics import classification_report from sklearn.naive_bayes import MultinomialNB from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder from sklearn.feature_extraction.text import TfidfVectorizer, TfidfTransformer label_encoder = LabelEncoder() # Метки классов для train aw19 y = label_encoder.fit_transform(Y) # Метки классов для test aw20 y_test = label_encoder.transform(Y_test) ## TF-IDF vectorizer = TfidfVectorizer(analyzer='word', stop_words='english', ngram_range = (3,3), lowercase=False) train = X['text'] test = X20['text'] train_vectors = vectorizer.fit_transform(train) test_vectors = vectorizer.transform(test) ################# Staking def StackingClas(model, train, y, test, n_fold): i = 0 folds = StratifiedKFold(n_splits = n_fold, random_state = 42, shuffle = True) train_pred = np.empty((train.shape[0], 3), float) for trn_idx, val_idx in folds.split(train, y): x_train, x_val = train[trn_idx], train[val_idx] y_train, y_val = y[trn_idx], y[val_idx] model.fit(X = x_train, y = y_train) train_pred_p = pd.DataFrame(model.predict_proba(x_train)) pred_tr = model.predict(x_train) train_accuracy = model.score(x_train, y_train) f1_train = f1_score(y_train, pred_tr, average='weighted') val_pred_p = pd.DataFrame(model.predict_proba(x_val)) pred_val = model.predict(x_val) val_accuracy = model.score(x_val, y_val) f1_val = f1_score(y_val, pred_val, average='weighted') train_pred = np.append(train_pred_p, val_pred_p, axis=0) print(f'------------------------------ Fold {i+1} ----------------------------------------') print(f'F1 score for train: {round(f1_train, 4)}, for val: {round(f1_val, 4)}') print(f'R2 score for train: {round(train_accuracy, 4)}, for val: {round(val_accuracy, 4)}') i+=1 ################## ## Model nb = MultinomialNB(alpha=0.1) ## Получение скоров по фолдам StackingClas(model = nb, n_fold = 7, train = train_vectors, test = test_vectors, y = y) ## F1-score и classification_report по всему train pred_aw19 = nb.predict(train_vectors) print(f1_score(y, pred_aw19, average='weighted')) target_names = ['High', 'Low', 'Moderate'] print(classification_report(y, pred_aw19, target_names=target_names)) ## F1-score и classification_report для test pred_aw20 = nb.predict(test_vectors) print(f1_score(y_test, pred_aw20, average='weighted')) print(classification_report(y_test, pred_aw20, target_names=target_names))
Результаты выполнения кода:

F1-score:
AW19 - 0.8406384968724525
AW20 - 0.6868815751425601
Classification report:
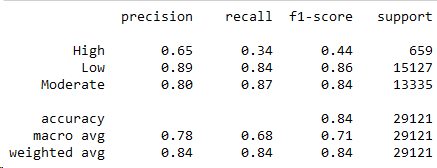
AW19
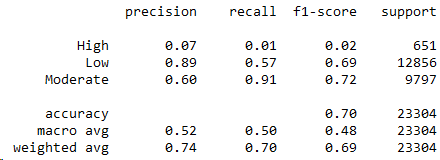
AW20
Скоры у модели хорошие для двух коллекций, но делает ошибки в прогнозировании спроса. Для AW20 скор даже ухудшился. Чтобы разобраться в каких классах модель ошибается, а в каких нет рассмотрим матрицу ошибок для коллекций AW19 и AW20.
Интерпретация матрицы ошибок для коллекции AW19
Код на Python формирования матрицы ошибок для трех классов
import seaborn as sns import matplotlib.pyplot as plt import matplotlib as mpl fig = plt.figure(figsize=(12, 12)) cf_matrix = confusion_matrix(y, pred_фц19, labels=[0, 1, 2]) group_counts = ["{0:0.0f}".format(value) for value in cf_matrix.flatten()] group_percentages = ["{0:.2%}".format(value) for value in cf_matrix.flatten()/np.sum(cf_matrix)] labels = [f"{v1}\n{v2}\n" for v1, v2 in zip(group_counts,group_percentages)] labels = np.asarray(labels).reshape(3,3) ax = sns.heatmap(cf_matrix, annot=labels, fmt='', cmap='PiYG') ax.set_title('Confusion Matrix with labels\n\n'); ax.set_xlabel('\nPredicted class Demand') ax.set_ylabel('Actual class Demand '); ## Ticket labels - List must be in alphabetical order ax.xaxis.set_ticklabels(['High','Low', 'Moderate']) ax.yaxis.set_ticklabels(['High','Low', 'Moderate']) ## Display the visualization of the Confusion Matrix. plt.show()
Не заглядывая в матрицу ошибок, сразу скажу, что модель сильно ошибается в прогнозировании класса High. Причина - очень маленькое количество товаров высокого спроса по сравнению с другими классами. 659 товаров (High) против 15 тыс. товаров (Low) и 13 тыс. товаров (Moderate).

Матрица ошибок мое предположение подтверждает - прогноз спроса High совпал с фактом лишь для 221 товара из 651 (34%). Также модель ложно предсказала класс High для 55 товаров с низким спросом и 62 товара с умеренным спросом.
Также есть ошибки классификации I и II рода.
Ошибка I рода - ошибка, в результате которой отрицательный класс (низкий спрос) был распознан как положительный (умеренный или высокий спрос).
Ошибка II рода - ошибка, в результате которой положительный класс (умеренный или высокий спрос) был распознан как отрицательный (низкий спрос).
Ошибка I рода составила 16% среди товаров с фактическим низким спросом и 8.43% среди всех товаров.
Ошибка II рода составила 12% среди товаров с фактическим низким спросом и 5.64% среди всех товаров.
Не смотря на ошибки, модель довольно хорошо себя проявила на сбалансированных классах Low и Moderate:
84% товаров низкого спроса были предсказаны как Low.
87% товаров умеренного спроса предсказаны как Moderate.
Считаю, что хорошая точность и чувствительность модели к классам Low и Moderate покрывают издержки для ритейла связанные с ошибками I и II рода.
Интерпретация матрицы ошибок для коллекции AW20
Здесь модель столкнулась с суровой реальностью - коллекция AW20 попала в период (декабрь 2019 - февраль 2020), когда началась пандемия кронавируса. Длительных локдаунов в мире еще не было, но во многих странах уже вводили карантинные меры из-за роста заболеваемости.
Карантин негативно повлиял на покупательскую способность непродовольственных товаров. Во время разметки классов для коллекции AW20 я выявила около 30 тыс. товаров низкого спроса. Напомню, что в коллекции AW19 товаров низкого спроса было 15 тыс. Число товаров умеренного спроса в AW20 тоже сократилось - 9797 против 13335 в AW19.
Я снова столкнулась с преобладанием класса Low над остальными классами. Чтобы сбалансировать Low я из тестовой выборки исключила товары с циклом продаж < 121 день. В результате количество товаров низкого спроса получилось 12856.
Не смотря на попытку сбалансировать классы, F1-score в AW20 снизился до 68.8%. Ищем причину падения скора в матрице ошибок для AW20.

Из матрицы ошибок видим, что выросла ошибка I рода - 43% товаров низкого спроса были классифицированы как Moderate. В AW19 таких товаров было 16%.
Дополнительно, у модели снизилась чувствительность к прогнозированию класса Low. Количество товаров, у которых не совпал прогноз Low с фактическим низким спросом, составило 43% среди товаров низкого спроса.
Если обобщить - модель была не готова к тому, что товар, который в добрые времена хорошо продавался, стал меньше пользоваться спросом или товар стали продавать в меньшем количестве из-за перебоя в цепочках поставок.
Еще я думаю, что причина потери в точности и чувствительности у модели - это разметка классов в AW19 и AW20. Информация о заказанных количествах, остатках, даты ввода товара в продажу и даты вывода из продажи мне в разметке гарантировано помогла.
Положительная сторона в работе данной модели тоже есть:
57% товаров низкого спроса были предсказаны как Low.
91% товаров умеренного спроса предсказаны как Moderate.
Среди всего ассортимента AW20 модель правильно спрогнозировала низкий спрос для 31.32% товаров и умеренный спрос для 38.46% товаров.
Если бы H&M владел данной информацией до формирования коллекции AW20 он смог бы отказаться от производства 1/3 товаров из класса Low. Тем самым, сократить себе убытки в пандемийный период.
Или продуктовые менеджеры H&M могли поступить по-другому:
Выявить характеристики/детали товара, которые снижают и повышают спрос;
На их основе доработать товар так, чтобы он попал в умеренный спрос.
Выявление характеристик товара, которые влияют на спрос

Продуктовые менеджеры собирают товар, как конструктор, из характеристик и деталей, которые привлекают покупателей.
Например, одна мужская модель джинсов - пять карманов из 100% хлопка, темного синего цвета с потертостями, средней посадкой, прямого кроя с застежкой на молнии, а вторая модель - пять карманов из 100% хлопка, однотонного синего цвета, средней посадкой, прямого кроя с застежкой на пуговицах.
На первый взгляд, эти модели джинсов одинаковы, однако их стоимость производства и цена будет отличаться - первые джинсы будут стоить дороже чем вторые. Причина простая - купить/пришить молнию и потереть ткань стоит дороже чем однотонная ткань и заклепать металлические пуговицы.
Такие факты используют продуктовые менеджеры, когда ограничен бюджет и амбициозен план продаж. И формируют ассортимент для новой коллекции, надеясь, что каждая модель найдет своего покупателя.
Как думаете, джинсы с застежкой на пуговицах пользуются большим спросом у мужчин? Женщины нейтрально к ней относятся?
Предлагаю сверить свое мнение с мнением модели.
Для выявления характеристик и деталей, которые влияют на выбор спроса, я воспользовалась Python библиотекой Lime. Lime может показать, как сильно слово или словосочетание из описания объекта влияет на выбор моделью того или иного класса.
from lime import lime_text, lime_tabular from sklearn.pipeline import make_pipeline vectorizer = TfidfVectorizer(analyzer='word', stop_words='english', ngram_range = (3,3), lowercase=False) nb = MultinomialNB(alpha=0.1) c = make_pipeline(vectorizer, nb) ## Вывод графика положительного и негативного влияния характеристики/детали на класс спроса по артикулу def predict_raiting_art(art): low_tab = X20.loc[X20.article_id == art] low_tab_supdir = low_tab.merge(supdir_aw20.loc[supdir_aw20.article_id == art], on='article_id', how = 'inner') low_tab_supdir = low_tab_supdir[['article_id', 'true_demand', 'predict', 'qnt_cust_x', 'detail_desc', 'text']] text = str(low_tab_supdir.loc[low_tab_supdir.article_id == art]['text'].astype('string').values) ## Текстовое описание артикула добавляем в explainer и отбираем 15 самых влиятельных характеристик по каждому классу ## 0 - High, 1 - Low, 2 - Moderate exp = explainer.explain_instance(text, c.predict_proba, num_features=15, labels=[0, 1, 2]) predict_class = low_tab_supdir['predict'].values true_class = low_tab_supdir['true_demand'].values qnt_cust = int(low_tab_supdir.loc[low_tab_supdir.article_id == art]['qnt_cust_x']) desc = str(low_tab_supdir.loc[low_tab_supdir.article_id == art]['detail_desc'].values) fig = plt.figure(figsize=(20, 20)) print(f'art: {art} \n Predicted class = {predict_class} \n True class = {true_class} \n True qnt qustomers = {qnt_cust} \n Description: {desc}') exp.as_pyplot_figure(label=1) exp.as_pyplot_figure(label=0) exp.as_pyplot_figure(label=2) plt.show(); exp.show_in_notebook(text=text, labels=(0,)) exp.show_in_notebook(text=text, labels=(1,)) exp.show_in_notebook(text=text, labels=(2,))
Рассмотрим три модели мужских джинсов:
с застежкой на пуговицах - Артикулы 662696002AW20 и 662696007AW20,
с застежкой на молнии - Артикул 730863014AW20

и три модели женских джинсов:
с застежкой на пуговицах - Артикулы 771964002AW20 и 771964001AW20,
с застежкой на молнии - Артикул 800390001AW20

Топ-15 характеристик, которые положительно или негативно влияют на Low/ Moderate/ High.
1) Мужские джинсы на пуговицах - 662696002AW20


2) Мужские джинсы на пуговицах - 662696007AW20


3) Мужские джинсы на молнии - 730863014AW20
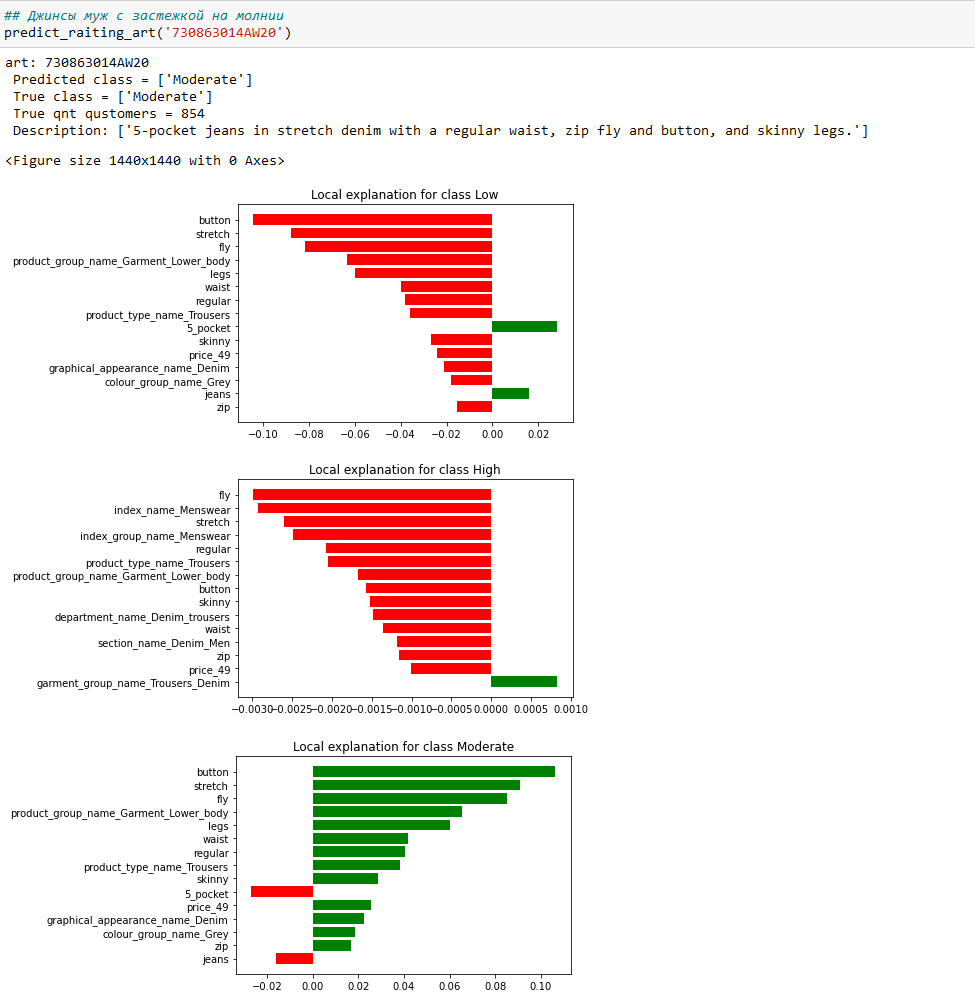

button fly - застежка на пуговицах
zip fly and button - застежка на молнии и пуговице
Обратите внимание как влияют на спрос каждой модели слова button fly и zip fly.
Для модели джинсов 662696007AW20 прогноз класса Low совпал с фактическим низким спросом, так как характеристики - department_name_Denim_trousers (19%), index_name_Menswear (8%) и button (8%) положительно влияют на прогноз спроса Low.
Также для джинсов 662696002AW20 сочетание характеристик - button (9%), perceived_colour_value_name_Medium (6%) и department_name_Denim_trousers (3%) повышает шансы классифицировать джинсы как Low. Но в итоге прогноз Moderate не совпал с фактическим низким спросом.
А для джинсов 730863014AW20 прогноз Moderate совпал с фактом, благодаря сочетанию характеристик - button (11%), fly (9%), stretch (9%) и zip (2%).
Подытожу. Модель считает, что мужчины больше предпочитают покупать джинсы на молнии чем джинсы с застежкой на пуговицах.
Теперь посмотрим какие характеристики у джинсов важны для женщин.
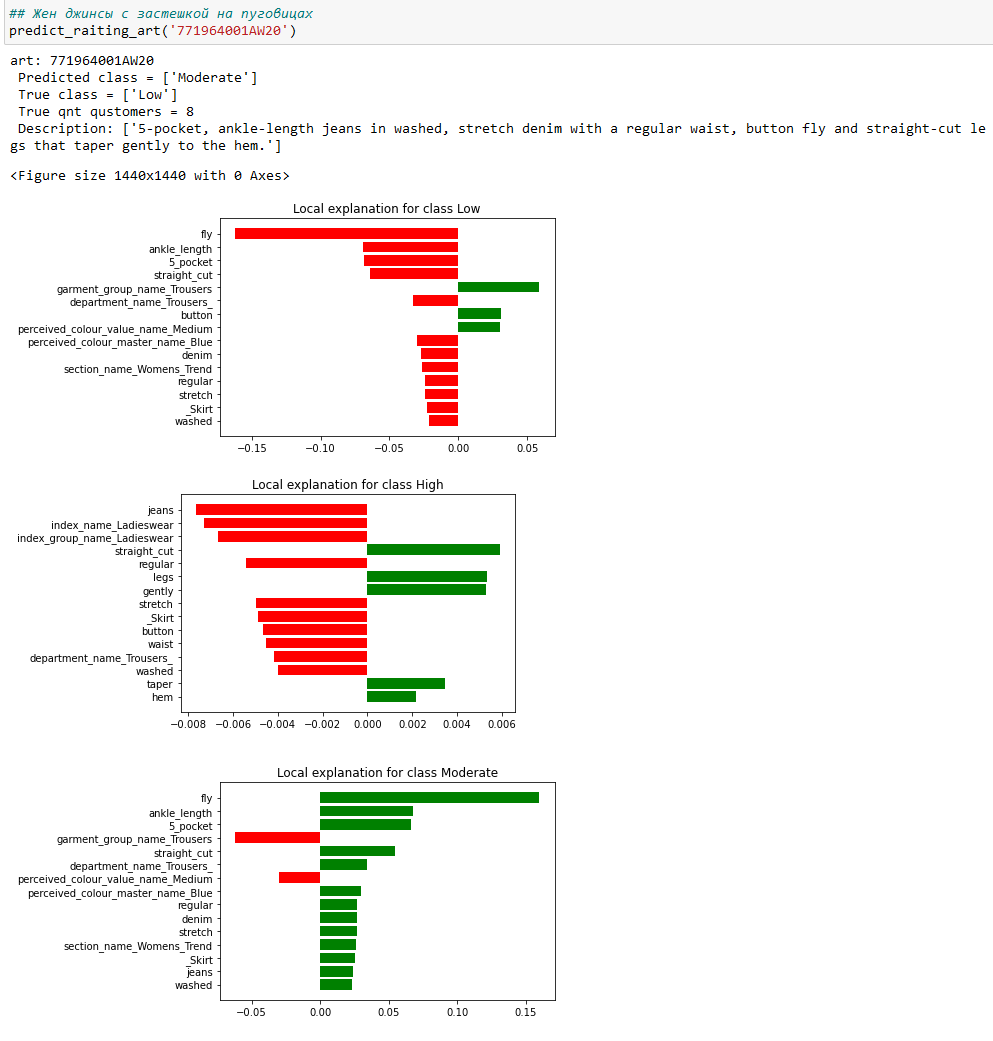
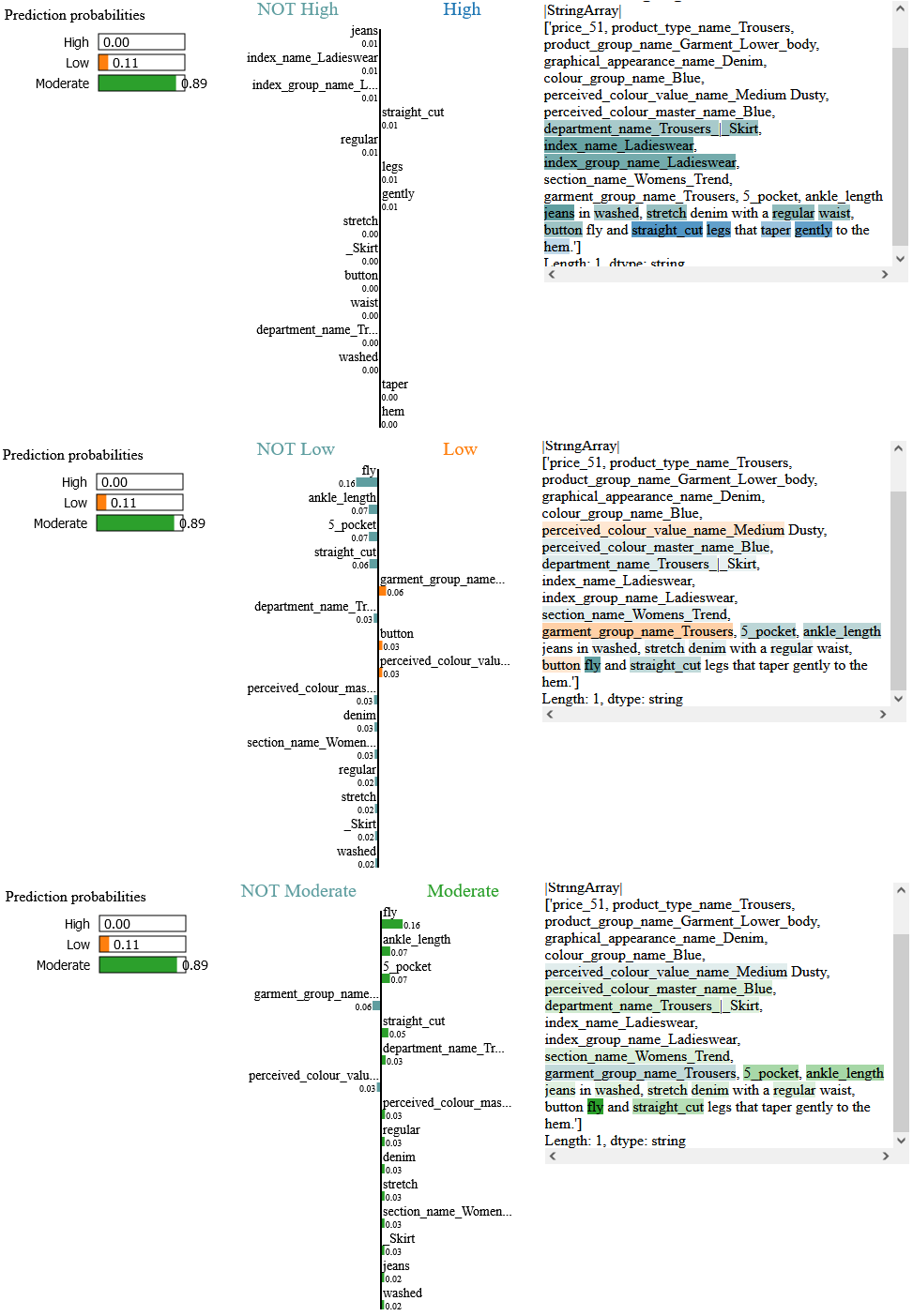
1) Женские джинсы на пуговицах - 771964002AW20


2) Женские джинсы на пуговицах - 771964001AW20
3) Женские джинсы на молнии - 800390001AW20
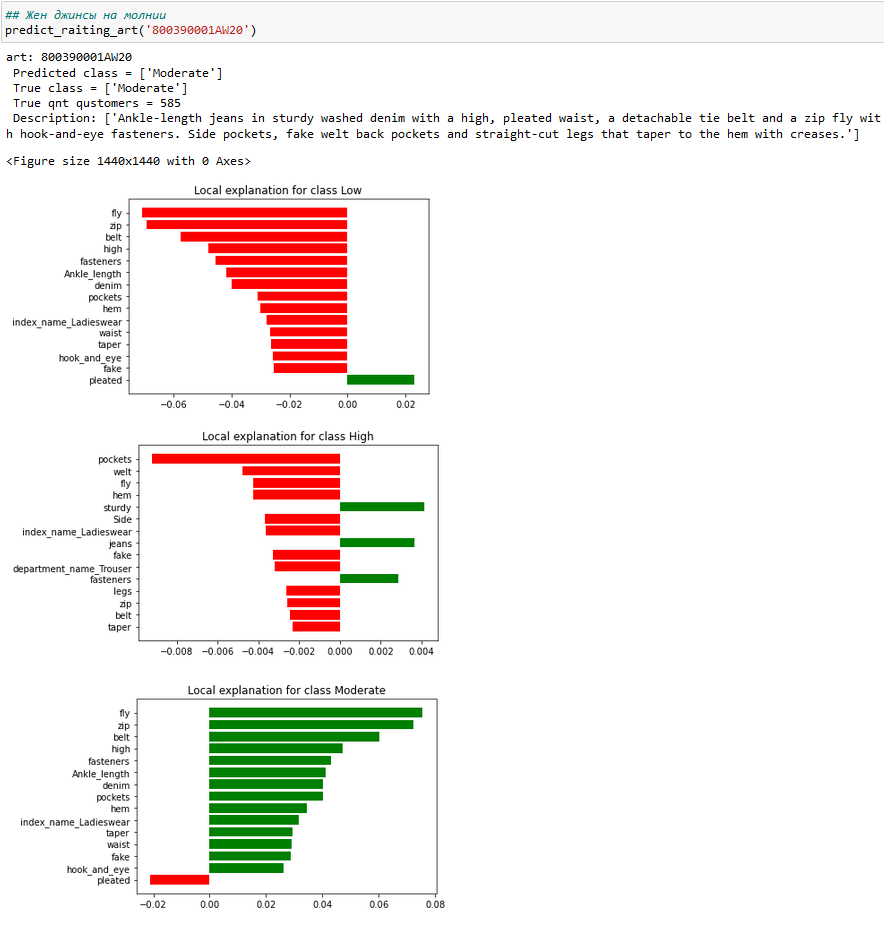

Для женских джинсов на пуговицах характеристика button также понижает спрос у покупательниц. Хочу отметить эта характеристика положительно влияет на спрос Low только на 3-4%. Напомню у мужских джинсов эта характеристика составляет 8-11%.
Это можно интерпретировать так - женщины не так критичны к джинсам на пуговицах, как мужчины. Но если у таких джинсов не будет характеристик, которые сильнее влияют на рост к умеренному или высокому спросу, то у женщин они не будут пользоваться спросом.
Вывод - чтобы повысить продажи джинсов лучше создать небольшой модельный ряд с застежкой на молнии и заказать больше экземпляров, чем заказать модели джинсов на пуговицах и думать что делать с нереализованными остатками.
Вывод рекомендаций от NoRecSys
Я реализовала отчет, по которому можно узнать прогноз спроса для топ-N артикулов из выбранной категории и узнать какие характеристики повлияли на прогноз. Отчет показывает для каждого артикула какие товары из умеренного и высокого спроса похожи на данный товар.
def predict_raiting(garment_group_name, index_group_name, demand, n): demand_dict = {'High': 0, 'Low': 1, 'Moderate': 2} low_tab = X20.loc[X20.predict == demand] low_tab_supdir = low_tab.merge(supdir_aw20.loc[(supdir_aw20.garment_group_name == garment_group_name)&(supdir_aw20.index_group_name == index_group_name)], on='article_id', how = 'inner').sort_values(by = ['sales_cycle', 'qnt_cust_x'], ascending = [False, True]) low_tab_supdir = low_tab_supdir[['article_id', 'qnt_cust_x', 'predict', 'price', 'sales_cycle', 'product_type_name', 'graphical_appearance_name', 'colour_group_name', 'perceived_colour_value_name', 'perceived_colour_master_name', 'text']].head(n) features = [] similar = [] neg = [] pos = [] for i in range(len(low_tab_supdir)): negative = [] positive = [] features.append('price='+str(int(low_tab_supdir.iloc[i]['price']))+', '+'product_type_name='+low_tab_supdir.iloc[i]['product_type_name']+', '+'graphical_appearance_name='+low_tab_supdir.iloc[i]['graphical_appearance_name']+', '+'colour_group_name='+low_tab_supdir.iloc[i]['colour_group_name']+', '+'perceived_colour_value_name='+low_tab_supdir.iloc[i]['perceived_colour_value_name']+', '+'perceived_colour_master_name='+low_tab_supdir.iloc[i]['perceived_colour_master_name']) # explainer text text = str(low_tab_supdir.iloc[i]['text']) exp = explainer.explain_instance(text, c.predict_proba, num_features=10, labels=[demand_dict[demand]]) # выделяем положительное и отрицательное влияние на класс for fet, w in exp.as_list(label= demand_dict[demand]): if w <=0: negative.append(fet) if w > 0: positive.append(fet) neg.append(str(negative)) pos.append(str(positive)) # подбор похожих артикулов с High или Moderate demand vector = TfidfVectorizer(analyzer='word', stop_words='english', ngram_range = (3,3), lowercase=False) tab_tfif = X20.merge(supdir_aw20.loc[(supdir_aw20.garment_group_name == garment_group_name)&(supdir_aw20.index_group_name == index_group_name)], on='article_id', how = 'inner').sort_values(by = ['sales_cycle', 'qnt_cust_x'], ascending = [False, True]) tf_matrix = vector.fit_transform(tab_tfif['text']) cosine_similarities = cosine_similarity(tf_matrix) similarities = {} dem = ['High', 'Low', 'Moderate'] for i in range(len(cosine_similarities)): # сортировка по схожести и запись индексов similar_indices = cosine_similarities[i].argsort()[:-50:-1] demand_idx = [] for x in similar_indices: if tab_tfif.iloc[x]['predict'] != 1: demand_idx.append(x) # список самых похожих товаров similarities[tab_tfif.iloc[i]['article_id']] = [(round(cosine_similarities[i][x],5), tab_tfif.iloc[x]['article_id'], tab_tfif.iloc[x]['predict']) for x in demand_idx][1:5] if i == 100 or i == 500 or i == 1000 or i == 1500 or i == 2000 or i == 2500 or i == 3000 or i == 3500 or i == 4000: print('qnt rows processed similarities:',i) for i in range(len(low_tab_supdir)): similar.append(similarities[low_tab_supdir.iloc[i]['article_id']]) tab = pd.DataFrame({'article_id': low_tab_supdir['article_id'], 'true_qnt_cust': low_tab_supdir['qnt_cust_x'], 'predict_demand': demand, 'sales_cycle': low_tab_supdir['sales_cycle'], 'features': features, 'negative_features_for_predict': neg, 'positive_features_for_predict': pos, 'similar items': similar, 'text': low_tab_supdir['text'] }) tab.to_excel('Predict_raiting.xlsx') return tab

Заключение
Я раскрыла узкие места в процессе формирования новой коллекции и указала на «ошибку выжившего» в работе классических рекомендательных систем, которые рекомендуют не совсем подходящие товары.
Я продемонстрировала как подход NoRecSys может помочь сократить издержки в формировании ассортимента товаров. Показала, как NoRecSys позволяет лучше понимать, что предпочитают покупатели.
В рамках разработки NoRecSys я сделала для себя несколько открытий:
Сочетание простых методов классификации и NLP (kNN+TF-IDF) позволяет хорошо подбирать похожие товары как по текстовому описанию, так и по изображению. Интересно, Computer vision так же хорошо справится с этой задачей?
Модель на основе методов наивный Байесовский классификатор+TF-IDF+LIME не просто прогнозирует спрос и указывает характеристики, влияющие на спрос на товар. Она отражает единые предпочтения большого количества покупателей. К таким предпочтениям относится разумное соотношение качества, функциональности и цены товара.
Что нужно улучшить / Планы развития
Найти такой способ разметки данных, чтобы добиться баланса для 3-х классов, не используя информацию о заказах поставщикам, остатках и квотировании;
Попробовать другой метод векторизации описания товара - Word2vec;
Доработать отчет для отображения рекомендаций по категориям товара;
Разработать инструмент, который заменяет негативные характеристики товара на положительные для повышения спроса и демонстрирует образ товара после изменений характеристик;
Сделать реализацию подхода NoRecSys для prodaction и выкатить NoRecSys на доступные ML market place.
Благодарности
Знания по NLP и рекомендательным системам я получила на курсе ML pro от OTUS. Мария (@mashkka_t), спасибо! Кстати, 5 сентября Мария проведет бесплатный вебинар, на котором расскажет про алгоритмы и подходы, которые сегодня применяются в NLP, начиная от самых простых и заканчивая трансформерными моделями, являющимися стандартом в области. Регистрируйтесь, будет интересно.
О соревновании в Kaggle от H&M я узнала в рамках командного марафона от Aleron-а. Саша (@Aleron75 ), спасибо!

