I think that I shall never see
A graph more lovely than a tree.
A tree whose crucial propertyеу
Is loop-free connectivity.
A tree that must be sure to span
So packets can reach every LAN.
First, the root must be selected.
By ID, it is elected.
Least-cost paths from root are traced.
In the tree, these paths are placed.
A mesh is made by folks like me,
Then bridges find a spanning tree.
— Radia Joy Perlman
6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
5. Сети для самых маленьких: Часть пятая. NAT и ACL
4. Сети для самых маленьких: Часть четвёртая. STP
3. Сети для самых маленьких: Часть третья. Статическая маршрутизация
2. Сети для самых маленьких. Часть вторая. Коммутация
1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco
0. Сети для самых маленьких. Часть нулевая. Планирование
В прошлом выпуске мы остановились на статической маршрутизации. Теперь надо сделать шаг в сторону и обсудить вопрос стабильности нашей сети.
Однажды, когда вы — единственный сетевой админ фирмы “Лифт ми Ап” — отпросились на полдня раньше, вдруг упала связь с серверами, и директора не получили несколько важных писем. После короткой, но ощутимой взбучки вы идёте разбираться, в чём дело, а оказалось, по чьей-то неосторожности выпал из разъёма единственный кабель, ведущий к коммутатору в серверной. Небольшая проблема, которую вы могли исправить за две минуты, и даже вообще избежать, существенно сказалась на вашем доходе в этом месяце и возможностях роста.
Итак, сегодня обсуждаем:
Оборудование, работающее на втором уровне модели OSI (коммутатор), должно выполнять 3 функции: запоминание адресов, перенаправление (коммутация) пакетов, защита от петель в сети. Разберем по пунктам каждую функцию.
Запоминание адресов и перенаправление пакетов: Как мы уже говорили ранее, у каждого свича есть таблица сопоставления MAC-адресов и портов (aka CAM-table — Content Addressable Memory Table). Когда устройство, подключенное к свичу, посылает кадр в сеть, свич смотрит MAC-адрес отправителя и порт, откуда получен кадр, и добавляет эту информацию в свою таблицу. Далее он должен передать кадр получателю, адрес которого указан в кадре. По идее, информацию о порте, куда нужно отправить кадр, он берёт из этой же CAM-таблицы. Но, предположим, что свич только что включили (таблица пуста), и он понятия не имеет, в какой из его портов подключен получатель. В этом случае он отправляет полученный кадр во все свои порты, кроме того, откуда он был принят. Все конечные устройства, получив этот кадр, смотрят MAC-адрес получателя, и, если он адресован не им, отбрасывают его. Устройство-получатель отвечает отправителю, а в поле отправителя ставит свой адрес, и вот свич уже знает, что такой-то адрес находится на таком-то порту (вносит запись в таблицу), и в следующий раз уже будет переправлять кадры, адресованные этому устройству, только в этот порт. Чтобы посмотреть содержимое CAM-таблицы, используется команда show mac address-table. Однажды попав в таблицу, информация не остаётся там пожизненно, содержимое постоянно обновляется и если к определенному mac-адресу не обращались 300 секунд (по умолчанию), запись о нем удаляется.
Тут всё должно быть понятно. Но зачем защита от петель? И что это вообще такое?
Часто, для обеспечения стабильности работы сети в случае проблем со связью между свичами (выход порта из строя, обрыв провода), используют избыточные линки (redundant links) — дополнительные соединения. Идея простая — если между свичами по какой-то причине не работает один линк, используем запасной. Вроде все правильно, но представим себе такую ситуацию: два свича соединены двумя проводами (пусть будет, что у них соединены fa0/1 и fa0/24).

Одной из их подопечных — рабочих станций (например, ПК1) вдруг приспичило послать широковещательный кадр (например, ARP-запрос). Раз широковещательный, шлем во все порты, кроме того, с которого получили.

Второй свич получает кадр в два порта, видит, что он широковещательный, и тоже шлет во все порты, но уже, получается, и обратно в те, с которых получил (кадр из fa0/24 шлет в fa0/1, и наоборот).

Первый свич поступает точно также, и в итоге мы получаем широковещательный шторм (broadcast storm), который намертво блокирует работу сети, ведь свичи теперь только и занимаются тем, что шлют друг другу один и тот же кадр.

Как можно избежать этого? Ведь мы, с одной стороны, не хотим штормов в сети, а с другой, хотим повысить ее отказоустойчивость с помощью избыточных соединений? Тут на помощь нам приходит STP (Spanning Tree Protocol)
Основная задача STP — предотвратить появление петель на втором уровне. Как это сделать? Да просто отрубить все избыточные линки, пока они нам не понадобятся. Тут уже сразу возникает много вопросов: какой линк из двух (или трех-четырех) отрубить? Как определить, что основной линк упал, и пора включать запасной? Как понять, что в сети образовалась петля? Чтобы ответить на эти вопросы, нужно разобраться, как работает STP.
STP использует алгоритм STA (Spanning Tree Algorithm), результатом работы которого является граф в виде дерева (связный и без простых циклов)
Для обмена информацией между собой свичи используют специальные пакеты, так называемые BPDU (Bridge Protocol Data Units). BPDU бывают двух видов: конфигурационные (Configuration BPDU) и панические “ААА, топология поменялась!” TCN (Topology Change Notification BPDU). Первые регулярно рассылаются корневым свичом (и ретранслируются остальными) и используются для построения топологии, вторые, как понятно из названия, отсылаются в случае изменения топологии сети (проще говоря, подключении\отключении свича). Конфигурационные BPDU содержат несколько полей, остановимся на самых важных:
Что все это такое и зачем оно нужно, объясню чуть ниже. Так как устройства не знают и не хотят знать своих соседей, никаких отношений (смежности/соседства) они друг с другом не устанавливают. Они шлют BPDU из всех работающих портов на мультикастовый ethernet-адрес 01-80-c2-00-00-00 (по умолчанию каждые 2 секунды), который прослушивают все свичи с включенным STP.
Итак, как же формируется топология без петель?
Сначала выбирается так называемый корневой мост/свич (root bridge). Это устройство, которое STP считает точкой отсчета, центром сети; все дерево STP сходится к нему. Выбор базируется на таком понятии, как идентификатор свича (Bridge ID). Bridge ID это число длиной 8 байт, которое состоит из Bridge Priority (приоритет, от 0 до 65535, по умолчанию 32768+номер vlan или инстанс MSTP, в зависимости от реализации протокола), и MAC-адреса устройства. В начале выборов каждый коммутатор считает себя корневым, о чем и заявляет всем остальным с помощью BPDU, в котором представляет свой идентификатор как ID корневого свича. При этом, если он получает BPDU с меньшим Bridge ID, он перестает хвастаться своим и покорно начинает анонсировать полученный Bridge ID в качестве корневого. В итоге, корневым оказывается тот свич, чей Bridge ID меньше всех.
После того, как коммутаторы померились айдями и выбрали root bridge, каждый из остальных свичей должен найти один, и только один порт, который будет вести к корневому свичу. Такой порт называется корневым портом (Root port). Чтобы понять, какой порт лучше использовать, каждый некорневой свич определяет стоимость маршрута от каждого своего порта до корневого свича. Эта стоимость определяется суммой стоимостей всех линков, которые нужно пройти кадру, чтобы дойти до корневого свича. В свою очередь, стоимость линка определяется просто- по его скорости (чем выше скорость, тем меньше стоимость). Процесс определения стоимости маршрута связан с полем BPDU “Root Path Cost” и происходит так:
Если имеют место одинаковые стоимости (как в нашем примере с двумя свичами и двумя проводами между ними — у каждого пути будет стоимость 19) — корневым выбирается меньший порт.
Далее выбираются назначенные (Designated) порты. Из каждого конкретного сегмента сети должен существовать только один путь по направлению к корневому свичу, иначе это петля. В данном случае имеем в виду физический сегмент, в современных сетях без хабов это, грубо говоря, просто провод. Назначенным портом выбирается тот, который имеет лучшую стоимость в данном сегменте. У корневого свича все порты — назначенные.
И вот уже после того, как выбраны корневые и назначенные порты, оставшиеся блокируются, таким образом разрывая петлю.

*На картинке маршрутизаторы выступают в качестве коммутаторов. В реальной жизни это можно сделать с помощью дополнительной свитчёвой платы.
Чуть раньше мы упомянули состояние блокировки порта, теперь поговорим о том, что это значит, и о других возможных состояниях порта в STP. Итак, в обычном (802.1D) STP существует 5 различных состояний:
Порядок перечисления состояний не случаен: при включении (а также при втыкании нового провода), все порты на устройстве с STP проходят вышеприведенные состояния именно в таком порядке (за исключением disabled-портов). Возникает закономерный вопрос: а зачем такие сложности? А просто STP осторожничает. Ведь на другом конце провода, который только что воткнули в порт, может быть свич, а это потенциальная петля. Вот поэтому порт сначала 15 секунд (по умолчанию) пребывает в состоянии прослушивания — он смотрит BPDU, попадающие в него, выясняет свое положение в сети — как бы чего ни вышло, потом переходит к обучению еще на 15 секунд — пытается выяснить, какие mac-адреса “в ходу” на линке, и потом, убедившись, что ничего он не поломает, начинает уже свою работу. Итого, мы имеем целых 30 секунд простоя, прежде чем подключенное устройство сможет обмениваться информацией со своими соседями. Современные компы грузятся быстрее, чем за 30 секунд. Вот комп загрузился, уже рвется в сеть, истерит на тему “DHCP-сервер, сволочь, ты будешь айпишник выдавать, или нет?”, и, не получив искомого, обижается и уходит в себя, извлекая из своих недр айпишник автонастройки. Естественно, после таких экзерсисов, в сети его слушать никто не будет, ибо “не местный” со своим 169.254.x.x. Понятно, что все это не дело, но как этого избежать?
Для таких случаев используется особый режим порта — portfast. При подключении устройства к такому порту, он, минуя промежуточные стадии, сразу переходит к forwarding-состоянию. Само собой, portfast следует включать только на интерфейсах, ведущих к конечным устройствам (рабочим станциям, серверам, телефонам и т.д.), но не к другим свичам.
STP довольно старый протокол, он создавался для работы в одном LAN-сегменте. А что делать, если мы хотим внедрить его в нашей сети, которая имеет несколько VLANов?
Стандарт 802.1Q, о котором мы упоминали в статье о коммутации, определяет, каким образом вланы передаются внутри транка. Кроме того, он определяет один процесс STP для всех вланов. BPDU по транкам передаются нетегированными (в native VLAN). Этот вариант STP известен как CST (Common Spanning Tree). Наличие только одного процесса для всех вланов очень облегчает работу по настройке и разгружает процессор свича, но, с другой стороны, CST имеет недостатки: избыточные линки между свичами блокируются во всех вланах, что не всегда приемлемо и не дает возможности использовать их для балансировки нагрузки.
Cisco имеет свой взгляд на STP, и свою проприетарную реализацию протокола — PVST (Per-VLAN Spanning Tree) — которая предназначена для работы в сети с несколькими VLAN. В PVST для каждого влана существует свой процесс STP, что позволяет независимую и гибкую настройку под потребности каждого влана, но самое главное, позволяет использовать балансировку нагрузки за счет того, что конкретный физический линк может быть заблокирован в одном влане, но работать в другом. Минусом этой реализации является, конечно, проприетарность: для функционирования PVST требуется проприетарный же ISL транк между свичами.
Также существует вторая версия этой реализации — PVST+, которая позволяет наладить связь между свичами с CST и PVST, и работает как с ISL- транком, так и с 802.1q. PVST+ это протокол по умолчанию на коммутаторах Cisco.
Все, о чем мы говорили ранее в этой статье, относится к первой реализация протокола STP, которая была разработана в 1985 году Радией Перлман (ее стихотворение использовано в качестве эпиграфа). В 1990 году эта реализации была включена в стандарт IEEE 802.1D. Тогда время текло медленнее, и перестройка топологии STP, занимающая 30-50 секунд (!!!), всех устраивала. Но времена меняются, и через десять лет, в 2001 году, IEEE представляет новый стандарт RSTP (он же 802.1w, он же Rapid Spanning Tree Protocol, он же Быстрый STP). Чтобы структурировать предыдущий материал и посмотреть различия между обычным STP (802.1d) и RSTP (802.1w), соберем таблицу с основными фактами:
Как мы видим, в RSTP остались такие роли портов, как корневой и назначенный, а роль заблокированного разделили на две новых роли: Alternate и Backup. Alternate — это резервный корневой порт, а backup — резервный назначенный порт. Как раз в этой концепции резервных портов и кроется одна из причин быстрого переключения в случае отказа. Это меняет поведение системы в целом: вместо реактивной (которая начинает искать решение проблемы только после того, как она случилась) система становится проактивной, заранее просчитывающей “пути отхода” еще до появления проблемы. Смысл простой: для того, чтобы в случае отказа основного переключится на резервный линк, RSTP не нужно заново просчитывать топологию, он просто переключится на запасной, заранее просчитанный.
Ранее, для того, чтобы убедиться, что порт может участвовать в передаче данных, требовались таймеры, т.е. свич пассивно ждал в течение означенного времени, слушая BPDU. Ключевой фичей RSTP стало введение концепции типов портов, основанных на режиме работы линка- full duplex или half duplex (типы портов p2p или shared, соответственно), а также понятия пограничный порт (тип edge p2p), для конечных устройств. Пограничные порты назначаются, как и раньше, командой spanning-tree portfast, и с ними все понятно- при включении провода сразу переходим к forwarding-состоянию и работаем. Shared-порты работают по старой схеме с прохождением через состояния BLK — LIS — LRN — FWD. А вот на p2p-портах RSTP использует процесс предложения и соглашения (proposal and agreement). Не вдаваясь в подробности, его можно описать так: свич справедливо считает, что если линк работает в режиме полного дуплекса, и он не обозначен, как пограничный, значит, на нем только два устройства- он и другой свич. Вместо того, чтобы ждать входящих BPDU, он сам пытается связаться со свичом на том конце провода с помощью специальных proposal BPDU, в которых, конечно, есть информация о стоимости маршрута к корневому свичу. Второй свич сравнивает полученную информацию со своей текущей, и принимает решение, о чем извещает первый свич посредством agreement BPDU. Так как весь этот процесс теперь не привязан к таймерам, происходит он очень быстро- только подключили новый свич- и он практически сразу вписался в общую топологию и приступил к работе (можете сами оценить скорость переключения в сравнении с обычным STP на видео). В Cisco-мире RSTP называется PVRST (Per-Vlan Rapid Spanning Tree).
Чуть выше, мы упоминали о PVST, в котором для каждого влана существует свой процесс STP. Вланы это довольно удобный инструмент для многих целей, и поэтому, их может быть достаточно много даже в некрупной организации. И в случае PVST, для каждого будет рассчитываться своя топология, тратиться процессорное время и память свичей. А нужно ли нам рассчитывать STP для всех 500 вланов, когда единственное место, где он нам нужен- это резервный линк между двумя свичами? Тут нас выручает MSTP. В нем каждый влан не обязан иметь собственный процесс STP, их можно объединять. Вот у нас есть, например, 500 вланов, и мы хотим балансировать нагрузку так, чтобы половина из них работала по одному линку (второй при этом блокируется и стоит в резерве), а вторая- по другому. Это можно сделать с помощью обычного STP, назначив один корневой свич в диапазоне вланов 1-250, а другой- в диапазоне 250-500. Но процессы будут работать для каждого из пятисот вланов по отдельности (хотя действовать будут совершенно одинаково для каждой половины). Логично, что тут хватит и двух процессов. MSTP позволяет создавать столько процесов STP, сколько у нас логических топологий (в данном примере- 2), и распределять по ним вланы. Думаем, нет особого смысла углубляться в теорию и практику MSTP в рамках этой статьи (ибо теории там ого-го), интересующиеся могут пройти по ссылке.
Но какой бы вариант STP мы не использовали, у нас все равно существует так или иначе неработающий линк. А возможно ли задействовать параллельные линки по полной и при этом избежать петель? Да, отвечаем мы вместе с циской, начиная рассказ о EtherChannel.
Иначе это называется link aggregation, link bundling, NIC teaming, port trunkinkg
Технологии агрегации (объединения) каналов выполняют 2 функции: с одной стороны, это объединение пропускной способности нескольких физических линков, а с другой — обеспечение отказоустойчивости соединения (в случае падения одного линка нагрузка переносится на оставшиеся). Объединение линков можно выполнить как вручную (статическое агрегирование), так и с помощью специальных протоколов: LACP (Link Aggregation Control Protocol) и PAgP (Port Aggregation Protocol). LACP, опеределяемый стандартом IEEE 802.3ad, является открытым стандартом, то есть от вендора оборудования не зависит. Соответственно, PAgP — проприетарная цисковская разработка.
В один такой канал можно объединить до восьми портов. Алгоритм балансировки нагрузки основан на таких параметрах, как IP/MAC-адреса получателей и отправителей и порты. Поэтому в случае возникновения вопроса: “Хей, а чего так плохо балансируется?” в первую очередь смотрите на алгоритм балансировки.
Тема агрегации каналов заслуживает отдельной статьи, а то и книги, поэтому углубляться не будем, интересующимся- ссылка.
Теперь расскажем вкратце, как обеспечить безопасность сети на втором уровне OSI. В этой части статьи теория и практическая конфигурация совмещены. Увы, Packet Tracer не умеет ничего из упомянутых в этом разделе команд, поэтому все без иллюстраций и проверок.
Для начала, следует упомянуть команду конфигурации интерфейса switchport port-security, включающую защиту на определенном порту свича. Затем, с помощью switchport port-security maximum 1 мы можем ограничить количество mac-адресов, связанных с данным портом (т.е., в нашем примере, на данном порту может работать только один mac-адрес). Теперь указываем, какой именно адрес разрешен: его можно задать вручную switchport port-security mac-address адрес, или использовать волшебную команду switchport port-security mac-address sticky, закрепляющую за портом тот адрес, который в данный момент работает на порту. Далее, задаем поведение в случае нарушения правила switchport port-security violation {shutdown | restrict | protect}: порт либо отключается, и потом его нужно поднимать вручную (shutdown), либо отбрасывает пакеты с незарегистрированного мака и пишет об этом в консоль (restrict), либо просто отбрасывает пакеты (protect).
Помимо очевидной цели — ограничение числа устройств за портом — у этой команды есть другая, возможно, более важная: предотвращать атаки. Одна из возможных — истощение CAM-таблицы. С компьютера злодея рассылается огромное число кадров, возможно, широковещательных, с различными значениями в поле MAC-адрес отправителя. Первый же коммутатор на пути начинает их запоминать. Одну тысячу он запомнит, две, но память-то оперативная не резиновая, и среднее ограничение в 16000 записей будет довольно быстро достигнуто. При этом дальнейшее поведение коммутатора может быть различным. И самое опасное из них с точки зрения безопасности: коммутатор может начать все кадры, приходящие на него, рассылать, как широковещательные, потому что MAC-адрес получателя не известен (или уже забыт), а запомнить его уже просто некуда. В этом случае сетевая карта злодея будет получать все кадры, летающие в вашей сети.
Другая возможная атака нацелена на DHCP сервер. Как мы знаем, DHCP обеспечивает клиентские устройства всей нужной информацией для работы в сети: ip-адресом, маской подсети, адресом шюза по умолчанию, DNS-сервера и прочим. Атакующий может поднять собственный DHCP, который в ответ на запрос клиентского устройства будет отдавать в качестве шлюза по умолчанию (а также, например, DNS-сервера) адрес подконтрольной атакующему машины. Соответственно, весь трафик, направленный за пределы подсети обманутыми устройствами, будет доступен для изучения атакующему — типичная man-in-the-middle атака. Либо такой вариант: подлый мошенник генерируют кучу DHCP-запросов с поддельными MAC-адресами и DHCP-сервер на каждый такой запрос выдаёт IP-адрес до тех пор, пока не истощится пул.
Для того, чтобы защититься от подобного вида атак, используется фича под названием DHCP snooping. Идея совсем простая: указать свичу, на каком порту подключен настоящий DHCP-сервер, и разрешить DHCP-ответы только с этого порта, запретив для остальных. Включаем глобально командой ip dhcp snooping, потом говорим, в каких вланах должно работать ip dhcp snooping vlan номер(а). Затем на конкретном порту говорим, что он может пренаправлять DHCP-ответы (такой порт называется доверенным): ip dhcp snooping trust.
После включения DHCP Snooping’а, он начинает вести у себя базу соответствия MAC и IP-адресов устройств, которую обновляет и пополняет за счет прослушивания DHCP запросов и ответов. Эта база позволяет нам противостоять еще одному виду атак — подмене IP-адреса (IP Spoofing). При включенном IP Source Guard, каждый приходящий пакет может проверяться на:
Включается IP Source Guard командой ip verify source на нужном интерфейсе. В таком виде проверяется только привязка IP-адреса, чтобы добавить проверку MAC, используем ip verify source port-security. Само собой, для работы IP Source Guard требуется включенный DHCP snooping, а для контроля MAC-адресов должен быть включен port security.
Как мы уже знаем, для того, чтобы узнать MAC-адрес устройства по его IP-адресу, используется проткол ARP: посылается широковещательный запрос вида “у кого ip-адрес 172.16.1.15, ответьте 172.16.1.1”, устройство с айпишником 172.16.1.15 отвечает. Подобная схема уязвима для атаки, называемой ARP-poisoning aka ARP-spoofing: вместо настоящего хоста с адресом 172.16.1.15 отвечает хост злоумышленника, заставляя таким образом трафик, предназначенный для 172.16.1.15 следовать через него. Для предотвращения такого типа атак используется фича под названием Dynamic ARP Inspection. Схема работы похожа на схему DHCP-Snooping’а: порты делятся на доверенные и недоверенные, на недоверенных каждый ARP-ответ подвергаются анализу: сверяется информация, содержащаяся в этом пакете, с той, которой свич доверяет (либо статически заданные соответствия MAC-IP, либо информация из базы DHCP Snooping). Если не сходится- пакет отбрасывается и генерируется сообщение в syslog. Включаем в нужном влане (вланах): ip arp inspection vlan номер(а). По умолчанию все порты недоверенные, для доверенных портов используем ip arp inspection trust.
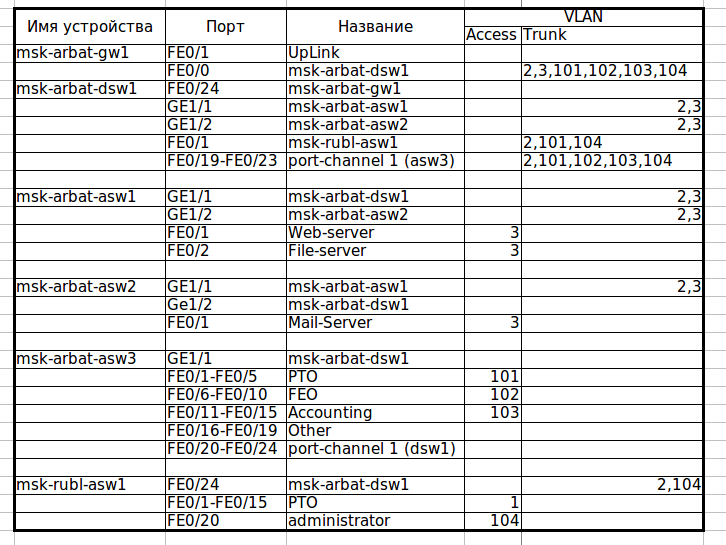
Итак, переходим к практике. Для начала внесем некоторые изменения в топологию — добавим избыточные линки. Учитывая сказанное в самом начале, вполне логично было бы сделать это в московском офисе в районе серверов — там у нас свич msk-arbat-asw2 доступен только через asw1, что не есть гуд. Мы отбираем (пока, позже возместим эту потерю) гигабитный линк, который идет от msk-arbat-dsw1 к msk-arbat-asw3, и подключаем через него asw2. Asw3 пока подключаем в порт Fa0/2 dsw1. Перенастраиваем транки:
Не забываем вносить все изменения в документацию!
Скачать актуальную версию документа.
Теперь посмотрим, как в данный момент у нас самонастроился STP. Нас интересует только VLAN0003, где у нас, судя по схеме, петля.
Разбираем по полочкам вывод команды

Итак, какую информацию мы можем получить? Так как по умолчанию на современных цисках работает PVST+ (т.е. для каждого влана свой процесс STP), и у нас есть более одного влана, выводится информация по каждому влану в отдельности, каждая запись предваряется номером влана. Затем идет вид STP: ieee значит PVST, rstp — Rapid PVST, mstp то и значит. Затем идет секция с информацией о корневом свиче: установленный на нем приоритет, его mac-адрес, стоимость пути от текущего свича до корневого, порт, который был выбран в качестве корневого (имеет лучшую стоимость), а также настройки таймеров STP. Далее- секция с той же информацией о текущем свиче (с которого выполняли команду). Затем- таблица состояния портов, которая состоит из следующих колонок (слева направо):
Итак, мы видим, что Gi1/1 корневой порт, это дает некоторую вероятность того, что на другом конце линка корневой свич. Смотрим по схеме, куда ведет линк: ага, некий msk-arbat-asw1.
И что же мы видим?
Вот он, наш корневой свич для VLAN0003.
А теперь посмотрим на схему. Ранее, мы увидели в состоянии портов, что dsw1 блокирует порт Gi1/2, разрывая таким образом петлю. Но является ли это оптимальным решением? Нет, конечно. Сейчас наша новая сеть работает точь-в-точь как старая- трафик от asw2 идет только через asw1. Выбор корневого маршрутизатора никогда не нужно оставлять на совесть глупого STP. Исходя из схемы, наиболее оптимальным будет выбор в качестве корневого свича dsw1- таким образом, STP заблокирует линк между asw1 и asw2. Теперь это все надо объяснить недалекому протоколу. А для него главное что? Bridge ID. И он неслучайно складывается из двух чисел. Приоритет- это как раз то слагаемое, которое отдано на откуп сетевому инженеру, чтобы он мог повлиять на результат выбора корневого свича. Итак, наша задача сводится к тому, чтобы уменьшить (меньше-лучше, думает STP) приоритет нужного свича, чтобы он стал Root Bridge. Есть два пути:
1) вручную установить приоритет, заведомо меньший, чем текущий:
Теперь он стал корневым для влана 3, так как имеет меньший Bridge ID:
2) дать умной железке решить все за тебя:
Проверяем:
Мы видим, что железка поставила какой-то странный приоритет. Откуда взялась эта круглая цифра, спросите вы? А все просто- STP смотрит минимальный приоритет (т.е. тот, который у корневого свича), и уменьшает его на два шага инкремента (который составляет 4096, т.е. в итоге 8192). Почему на два? А чтобы была возможность на другом свиче дать команду spanning-tree vlan n root secondary (назначает приоритет=приоритет корневого-4096), что позволит нам быть уверенными, что, если с текущим корневым свичом что-то произойдет, его функции перейдут к этому, “запасному”. Вероятно, вы уже видите на схеме, как лампочка на линке между asw2 и asw1 пожелтела? Это STP разорвал петлю. Причем именно в том месте, в котором мы хотели. Sweet! Зайдем проверим: лампочка — это лампочка, а конфиг — это факт.
Теперь полюбуемся, как работает STP: заходим в командную строку на ноутбуке PTO1 и начинаем бесконечно пинговать наш почтовый сервер (172.16.0.4). Пинг сейчас идет по маршруту ноутбук-asw3-dsw1-gw1-dsw1(ну тут понятно, зачем он крюк делает — они из разных вланов)-asw2-сервер. А теперь поработаем Годзиллой из SimСity: нарушим связь между dsw1 и asw2, вырвав провод из порта (замечаем время, нужное для пересчета дерева).
Пинги пропадают, STP берется за дело, и за каких-то 30 секунд коннект восстанавливается. Годзиллу прогнали, пожары потушили, связь починили, втыкаем провод обратно. Пинги опять пропадают на 30 секунд! Мда-а-а, как-то не очень быстро, особенно если представить, что это происходит, например, в процессинговом центре какого-нибудь банка.
Но у нас есть ответ медленному PVST+! И ответ этот — Быстрый PVST+ (так и называется, это не шутка: Rapid-PVST). Посмотрим, что он нам дает. Меняем тип STP на всех свичах в москве командой конфигурационного режима: spanning-tree mode rapid-pvst
Снова запускаем пинг, вызываем Годзиллу… Эй, где пропавшие пинги? Их нет, это же Rapid-PVST. Как вы, наверное, помните из теоретической части, эта реализация STP, так сказать, “подстилает соломку” на случай падения основного линка, и переключается на дополнительный (alternate) порт очень быстро, что мы и наблюдали. Ладно, втыкаем провод обратно. Один потерянный пинг. Неплохо по сравнению с 6-8, да?
Помните, мы отобрали у офисных работников их гигабитный линк и отдали его в пользу серверов? Сейчас они, бедняжки, сидят, на каких-то ста мегабитах, прошлый век! Попробуем расширить канал, и на помощь призовем EtherChannel. В данный момент у нас соединение идет от fa0/2 dsw1 на Gi1/1 asw3, отключаем провод. Смотрим, какие порты можем использовать на asw3: ага, fa0/20-24 свободны, кажется. Вот их и возьмем. Со стороны dsw1 пусть будут fa0/19-23. Соединяем порты для EtherChannel между собой. На asw3 у нас на интерфейсах что-то настроено, обычно в таких случаях используется команда конфигурационного режима default interface range fa0/20-24, сбрасывающая настройки порта (или портов, как в нашем случае) в дефолтные. Packet tracer, увы, не знает такой хорошей команды, поэтому в ручном режиме убираем каждую настройку, и тушим порты (лучше это сделать, во избежание проблем)
ну а теперь волшебная команда
то же самое на dsw1:
поднимаем интерфейсы asw3, и вуаля: вот он, наш EtherChannel, раскинулся аж на 5 физических линков. В конфиге он будет отражен как interface Port-channel 1. Настраиваем транк (повторить для dsw1):
Как и с STP, есть некая трудность при работе с etherchannel в Packet Tracer’e. Настроить-то мы, в принципе, можем по вышеописанному сценарию, но вот проверка работоспособности под большим вопросом: после отключения одного из портов в группе, трафик перетекает на следующий, но как только вы вырубаете второй порт — связь теряется и не восстанавливается даже после включения портов.
Отчасти в силу только что озвученной причины, отчасти из-за ограниченности ресурсов мы не сможем раскрыть в полной мере эти вопросы и посему оставляем бОльшую часть на самоизучение.
Новый план коммутации
Файл PT с лабораторной.
Конфигурация устройств
STP или STP
Безопасность канального уровня
Агрегация каналов
По сложившейся традиции все неотвеченные вопросы безымянными читателями хабра задаются в блоге цикла в ЖЖ.
За видео и помощь в подготовке статьи спасибо eucariot
A graph more lovely than a tree.
A tree whose crucial propertyеу
Is loop-free connectivity.
A tree that must be sure to span
So packets can reach every LAN.
First, the root must be selected.
By ID, it is elected.
Least-cost paths from root are traced.
In the tree, these paths are placed.
A mesh is made by folks like me,
Then bridges find a spanning tree.
— Radia Joy Perlman
Все выпуски
6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
5. Сети для самых маленьких: Часть пятая. NAT и ACL
4. Сети для самых маленьких: Часть четвёртая. STP
3. Сети для самых маленьких: Часть третья. Статическая маршрутизация
2. Сети для самых маленьких. Часть вторая. Коммутация
1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco
0. Сети для самых маленьких. Часть нулевая. Планирование
В прошлом выпуске мы остановились на статической маршрутизации. Теперь надо сделать шаг в сторону и обсудить вопрос стабильности нашей сети.
Однажды, когда вы — единственный сетевой админ фирмы “Лифт ми Ап” — отпросились на полдня раньше, вдруг упала связь с серверами, и директора не получили несколько важных писем. После короткой, но ощутимой взбучки вы идёте разбираться, в чём дело, а оказалось, по чьей-то неосторожности выпал из разъёма единственный кабель, ведущий к коммутатору в серверной. Небольшая проблема, которую вы могли исправить за две минуты, и даже вообще избежать, существенно сказалась на вашем доходе в этом месяце и возможностях роста.
Итак, сегодня обсуждаем:
- проблему широковещательного шторма
- работу и настройку протокола STP и его модификаций (RSTP, MSTP, PVST, PVST+)
- технологию агрегации интерфейсов и перераспределения нагрузки между ними
- некоторые вопросы стабильности и безопасности
- как изменить схему существующей сети, чтобы всем было хорошо
Оборудование, работающее на втором уровне модели OSI (коммутатор), должно выполнять 3 функции: запоминание адресов, перенаправление (коммутация) пакетов, защита от петель в сети. Разберем по пунктам каждую функцию.
Запоминание адресов и перенаправление пакетов: Как мы уже говорили ранее, у каждого свича есть таблица сопоставления MAC-адресов и портов (aka CAM-table — Content Addressable Memory Table). Когда устройство, подключенное к свичу, посылает кадр в сеть, свич смотрит MAC-адрес отправителя и порт, откуда получен кадр, и добавляет эту информацию в свою таблицу. Далее он должен передать кадр получателю, адрес которого указан в кадре. По идее, информацию о порте, куда нужно отправить кадр, он берёт из этой же CAM-таблицы. Но, предположим, что свич только что включили (таблица пуста), и он понятия не имеет, в какой из его портов подключен получатель. В этом случае он отправляет полученный кадр во все свои порты, кроме того, откуда он был принят. Все конечные устройства, получив этот кадр, смотрят MAC-адрес получателя, и, если он адресован не им, отбрасывают его. Устройство-получатель отвечает отправителю, а в поле отправителя ставит свой адрес, и вот свич уже знает, что такой-то адрес находится на таком-то порту (вносит запись в таблицу), и в следующий раз уже будет переправлять кадры, адресованные этому устройству, только в этот порт. Чтобы посмотреть содержимое CAM-таблицы, используется команда show mac address-table. Однажды попав в таблицу, информация не остаётся там пожизненно, содержимое постоянно обновляется и если к определенному mac-адресу не обращались 300 секунд (по умолчанию), запись о нем удаляется.
Тут всё должно быть понятно. Но зачем защита от петель? И что это вообще такое?
Широковещательный шторм
Часто, для обеспечения стабильности работы сети в случае проблем со связью между свичами (выход порта из строя, обрыв провода), используют избыточные линки (redundant links) — дополнительные соединения. Идея простая — если между свичами по какой-то причине не работает один линк, используем запасной. Вроде все правильно, но представим себе такую ситуацию: два свича соединены двумя проводами (пусть будет, что у них соединены fa0/1 и fa0/24).
Одной из их подопечных — рабочих станций (например, ПК1) вдруг приспичило послать широковещательный кадр (например, ARP-запрос). Раз широковещательный, шлем во все порты, кроме того, с которого получили.
Второй свич получает кадр в два порта, видит, что он широковещательный, и тоже шлет во все порты, но уже, получается, и обратно в те, с которых получил (кадр из fa0/24 шлет в fa0/1, и наоборот).
Первый свич поступает точно также, и в итоге мы получаем широковещательный шторм (broadcast storm), который намертво блокирует работу сети, ведь свичи теперь только и занимаются тем, что шлют друг другу один и тот же кадр.
Как можно избежать этого? Ведь мы, с одной стороны, не хотим штормов в сети, а с другой, хотим повысить ее отказоустойчивость с помощью избыточных соединений? Тут на помощь нам приходит STP (Spanning Tree Protocol)
STP
Основная задача STP — предотвратить появление петель на втором уровне. Как это сделать? Да просто отрубить все избыточные линки, пока они нам не понадобятся. Тут уже сразу возникает много вопросов: какой линк из двух (или трех-четырех) отрубить? Как определить, что основной линк упал, и пора включать запасной? Как понять, что в сети образовалась петля? Чтобы ответить на эти вопросы, нужно разобраться, как работает STP.
STP использует алгоритм STA (Spanning Tree Algorithm), результатом работы которого является граф в виде дерева (связный и без простых циклов)
Для обмена информацией между собой свичи используют специальные пакеты, так называемые BPDU (Bridge Protocol Data Units). BPDU бывают двух видов: конфигурационные (Configuration BPDU) и панические “ААА, топология поменялась!” TCN (Topology Change Notification BPDU). Первые регулярно рассылаются корневым свичом (и ретранслируются остальными) и используются для построения топологии, вторые, как понятно из названия, отсылаются в случае изменения топологии сети (проще говоря, подключении\отключении свича). Конфигурационные BPDU содержат несколько полей, остановимся на самых важных:
- идентификатор отправителя (Bridge ID)
- идентификатор корневого свича (Root Bridge ID)
- идентификатор порта, из которого отправлен данный пакет (Port ID)
- стоимость маршрута до корневого свича (Root Path Cost)
Что все это такое и зачем оно нужно, объясню чуть ниже. Так как устройства не знают и не хотят знать своих соседей, никаких отношений (смежности/соседства) они друг с другом не устанавливают. Они шлют BPDU из всех работающих портов на мультикастовый ethernet-адрес 01-80-c2-00-00-00 (по умолчанию каждые 2 секунды), который прослушивают все свичи с включенным STP.
Итак, как же формируется топология без петель?
Сначала выбирается так называемый корневой мост/свич (root bridge). Это устройство, которое STP считает точкой отсчета, центром сети; все дерево STP сходится к нему. Выбор базируется на таком понятии, как идентификатор свича (Bridge ID). Bridge ID это число длиной 8 байт, которое состоит из Bridge Priority (приоритет, от 0 до 65535, по умолчанию 32768+номер vlan или инстанс MSTP, в зависимости от реализации протокола), и MAC-адреса устройства. В начале выборов каждый коммутатор считает себя корневым, о чем и заявляет всем остальным с помощью BPDU, в котором представляет свой идентификатор как ID корневого свича. При этом, если он получает BPDU с меньшим Bridge ID, он перестает хвастаться своим и покорно начинает анонсировать полученный Bridge ID в качестве корневого. В итоге, корневым оказывается тот свич, чей Bridge ID меньше всех.
Такой подход таит в себе довольно серьезную проблему. Дело в том, что, при равных значениях Priority (а они равные, если не менять ничего) корневым выбирается самый старый свич, так как мак адреса прописываются на производстве последовательно, соответственно, чем мак меньше, тем устройство старше (естественно, если у нас все оборудование одного вендора). Понятное дело, это ведет к падению производительности сети, так как старое устройство, как правило, имеет худшие характеристики. Подобное поведение протокола следует пресекать, выставляя значение приоритета на желаемом корневом свиче вручную, об этом в практической части.
Роли портов
После того, как коммутаторы померились айдями и выбрали root bridge, каждый из остальных свичей должен найти один, и только один порт, который будет вести к корневому свичу. Такой порт называется корневым портом (Root port). Чтобы понять, какой порт лучше использовать, каждый некорневой свич определяет стоимость маршрута от каждого своего порта до корневого свича. Эта стоимость определяется суммой стоимостей всех линков, которые нужно пройти кадру, чтобы дойти до корневого свича. В свою очередь, стоимость линка определяется просто- по его скорости (чем выше скорость, тем меньше стоимость). Процесс определения стоимости маршрута связан с полем BPDU “Root Path Cost” и происходит так:
- Корневой свич посылает BPDU с полем Root Path Cost, равным нулю
- Ближайший свич смотрит на скорость своего порта, куда BPDU пришел, и добавляет стоимость согласно таблице
Скорость порта Стоимость STP (802.1d) 10 Mbps 100 100 Mbps 19 1 Gbps 4 10 Gbps 2 - Далее этот второй свич посылает этот BPDU нижестоящим коммутаторам, но уже с новым значением Root Path Cost, и далее по цепочке вниз
Если имеют место одинаковые стоимости (как в нашем примере с двумя свичами и двумя проводами между ними — у каждого пути будет стоимость 19) — корневым выбирается меньший порт.
Далее выбираются назначенные (Designated) порты. Из каждого конкретного сегмента сети должен существовать только один путь по направлению к корневому свичу, иначе это петля. В данном случае имеем в виду физический сегмент, в современных сетях без хабов это, грубо говоря, просто провод. Назначенным портом выбирается тот, который имеет лучшую стоимость в данном сегменте. У корневого свича все порты — назначенные.
И вот уже после того, как выбраны корневые и назначенные порты, оставшиеся блокируются, таким образом разрывая петлю.
*На картинке маршрутизаторы выступают в качестве коммутаторов. В реальной жизни это можно сделать с помощью дополнительной свитчёвой платы.
Состояния портов
Чуть раньше мы упомянули состояние блокировки порта, теперь поговорим о том, что это значит, и о других возможных состояниях порта в STP. Итак, в обычном (802.1D) STP существует 5 различных состояний:
- блокировка (blocking): блокированный порт не шлет ничего. Это состояние предназначено, как говорилось выше, для предотвращения петель в сети. Блокированный порт, тем не менее, слушает BPDU (чтобы быть в курсе событий, это позволяет ему, когда надо, разблокироваться и начать работать)
- прослушивание (listening): порт слушает и начинает сам отправлять BPDU, кадры с данными не отправляет.
- обучение (learning): порт слушает и отправляет BPDU, а также вносит изменения в CAM- таблицу, но данные не перенаправляет.
- перенаправление\пересылка (forwarding): этот может все: и посылает\принимает BPDU, и с данными оперирует, и участвует в поддержании таблицы mac-адресов. То есть это обычное состояние рабочего порта.
- отключен (disabled): состояние administratively down, отключен командой shutdown. Понятное дело, ничего делать не может вообще, пока вручную не включат.
Порядок перечисления состояний не случаен: при включении (а также при втыкании нового провода), все порты на устройстве с STP проходят вышеприведенные состояния именно в таком порядке (за исключением disabled-портов). Возникает закономерный вопрос: а зачем такие сложности? А просто STP осторожничает. Ведь на другом конце провода, который только что воткнули в порт, может быть свич, а это потенциальная петля. Вот поэтому порт сначала 15 секунд (по умолчанию) пребывает в состоянии прослушивания — он смотрит BPDU, попадающие в него, выясняет свое положение в сети — как бы чего ни вышло, потом переходит к обучению еще на 15 секунд — пытается выяснить, какие mac-адреса “в ходу” на линке, и потом, убедившись, что ничего он не поломает, начинает уже свою работу. Итого, мы имеем целых 30 секунд простоя, прежде чем подключенное устройство сможет обмениваться информацией со своими соседями. Современные компы грузятся быстрее, чем за 30 секунд. Вот комп загрузился, уже рвется в сеть, истерит на тему “DHCP-сервер, сволочь, ты будешь айпишник выдавать, или нет?”, и, не получив искомого, обижается и уходит в себя, извлекая из своих недр айпишник автонастройки. Естественно, после таких экзерсисов, в сети его слушать никто не будет, ибо “не местный” со своим 169.254.x.x. Понятно, что все это не дело, но как этого избежать?
Portfast
Для таких случаев используется особый режим порта — portfast. При подключении устройства к такому порту, он, минуя промежуточные стадии, сразу переходит к forwarding-состоянию. Само собой, portfast следует включать только на интерфейсах, ведущих к конечным устройствам (рабочим станциям, серверам, телефонам и т.д.), но не к другим свичам.
Есть очень удобная команда режима конфигурации интерфейса для включения нужных фич на порту, в который будут включаться конечные устройства: switchport host. Эта команда разом включает PortFast, переводит порт в режим access (аналогично switchport mode access), и отключает протокол PAgP (об этом протоколе подробнее в разделе агрегация каналов).
Виды STP
STP довольно старый протокол, он создавался для работы в одном LAN-сегменте. А что делать, если мы хотим внедрить его в нашей сети, которая имеет несколько VLANов?
Стандарт 802.1Q, о котором мы упоминали в статье о коммутации, определяет, каким образом вланы передаются внутри транка. Кроме того, он определяет один процесс STP для всех вланов. BPDU по транкам передаются нетегированными (в native VLAN). Этот вариант STP известен как CST (Common Spanning Tree). Наличие только одного процесса для всех вланов очень облегчает работу по настройке и разгружает процессор свича, но, с другой стороны, CST имеет недостатки: избыточные линки между свичами блокируются во всех вланах, что не всегда приемлемо и не дает возможности использовать их для балансировки нагрузки.
Cisco имеет свой взгляд на STP, и свою проприетарную реализацию протокола — PVST (Per-VLAN Spanning Tree) — которая предназначена для работы в сети с несколькими VLAN. В PVST для каждого влана существует свой процесс STP, что позволяет независимую и гибкую настройку под потребности каждого влана, но самое главное, позволяет использовать балансировку нагрузки за счет того, что конкретный физический линк может быть заблокирован в одном влане, но работать в другом. Минусом этой реализации является, конечно, проприетарность: для функционирования PVST требуется проприетарный же ISL транк между свичами.
Также существует вторая версия этой реализации — PVST+, которая позволяет наладить связь между свичами с CST и PVST, и работает как с ISL- транком, так и с 802.1q. PVST+ это протокол по умолчанию на коммутаторах Cisco.
RSTP
Все, о чем мы говорили ранее в этой статье, относится к первой реализация протокола STP, которая была разработана в 1985 году Радией Перлман (ее стихотворение использовано в качестве эпиграфа). В 1990 году эта реализации была включена в стандарт IEEE 802.1D. Тогда время текло медленнее, и перестройка топологии STP, занимающая 30-50 секунд (!!!), всех устраивала. Но времена меняются, и через десять лет, в 2001 году, IEEE представляет новый стандарт RSTP (он же 802.1w, он же Rapid Spanning Tree Protocol, он же Быстрый STP). Чтобы структурировать предыдущий материал и посмотреть различия между обычным STP (802.1d) и RSTP (802.1w), соберем таблицу с основными фактами:
| STP (802.1d) | RSTP (802.1w) |
| В уже сложившейся топологии только корневой свич шлет BPDU, остальные ретранслируют | Все свичи шлют BPDU в соответствии с hello-таймером (2 секунды по умолчанию) |
| Состояния портов | |
| — блокировка (blocking) — прослушивание (listening) — обучение (learning) — перенаправление\пересылка (forwarding) — отключен (disabled) |
— отбрасывание (discarding), заменяет disabled, blocking и listening — learning — forwarding |
| Роли портов | |
| — корневой (root), участвует в пересылке данных, ведет к корневому свичу — назначенный (designated), тоже работает, ведет от корневого свича — неназначенный (non-designated), не участвует в пересылке данных |
— корневой (root), участвует в пересылке данных — назначенный (designated), тоже работает — дополнительный (alternate), не участвует в пересылке данных — резервный (backup), тоже не участвует |
| Механизмы работы | |
| Использует таймеры: Hello (2 секунды) Max Age (20 секунд) Forward delay timer (15 секунд) |
Использует процесс proposal and agreement (предложение и соглашение) |
| Свич, обнаруживший изменение топологии, извещает корневой свич, который, в свою очередь, требует от всех остальных очистить их записи о текущей топологии в течение forward delay timer | Обнаружение изменений в топологии влечет немедленную очистку записей |
| Если не-корневой свич не получает hello- пакеты от корневого в течение Max Age, он начинает новые выборы | Начинает действовать, если не получает BPDU в течение 3 hello-интервалов |
| Последовательное прохождение порта через состояния Blocking (20 сек) — Listening (15 сек) — Learning (15 сек) — Forwarding | Быстрый переход к Forwarding для p2p и Edge-портов |
Как мы видим, в RSTP остались такие роли портов, как корневой и назначенный, а роль заблокированного разделили на две новых роли: Alternate и Backup. Alternate — это резервный корневой порт, а backup — резервный назначенный порт. Как раз в этой концепции резервных портов и кроется одна из причин быстрого переключения в случае отказа. Это меняет поведение системы в целом: вместо реактивной (которая начинает искать решение проблемы только после того, как она случилась) система становится проактивной, заранее просчитывающей “пути отхода” еще до появления проблемы. Смысл простой: для того, чтобы в случае отказа основного переключится на резервный линк, RSTP не нужно заново просчитывать топологию, он просто переключится на запасной, заранее просчитанный.
Ранее, для того, чтобы убедиться, что порт может участвовать в передаче данных, требовались таймеры, т.е. свич пассивно ждал в течение означенного времени, слушая BPDU. Ключевой фичей RSTP стало введение концепции типов портов, основанных на режиме работы линка- full duplex или half duplex (типы портов p2p или shared, соответственно), а также понятия пограничный порт (тип edge p2p), для конечных устройств. Пограничные порты назначаются, как и раньше, командой spanning-tree portfast, и с ними все понятно- при включении провода сразу переходим к forwarding-состоянию и работаем. Shared-порты работают по старой схеме с прохождением через состояния BLK — LIS — LRN — FWD. А вот на p2p-портах RSTP использует процесс предложения и соглашения (proposal and agreement). Не вдаваясь в подробности, его можно описать так: свич справедливо считает, что если линк работает в режиме полного дуплекса, и он не обозначен, как пограничный, значит, на нем только два устройства- он и другой свич. Вместо того, чтобы ждать входящих BPDU, он сам пытается связаться со свичом на том конце провода с помощью специальных proposal BPDU, в которых, конечно, есть информация о стоимости маршрута к корневому свичу. Второй свич сравнивает полученную информацию со своей текущей, и принимает решение, о чем извещает первый свич посредством agreement BPDU. Так как весь этот процесс теперь не привязан к таймерам, происходит он очень быстро- только подключили новый свич- и он практически сразу вписался в общую топологию и приступил к работе (можете сами оценить скорость переключения в сравнении с обычным STP на видео). В Cisco-мире RSTP называется PVRST (Per-Vlan Rapid Spanning Tree).
MSTP
Чуть выше, мы упоминали о PVST, в котором для каждого влана существует свой процесс STP. Вланы это довольно удобный инструмент для многих целей, и поэтому, их может быть достаточно много даже в некрупной организации. И в случае PVST, для каждого будет рассчитываться своя топология, тратиться процессорное время и память свичей. А нужно ли нам рассчитывать STP для всех 500 вланов, когда единственное место, где он нам нужен- это резервный линк между двумя свичами? Тут нас выручает MSTP. В нем каждый влан не обязан иметь собственный процесс STP, их можно объединять. Вот у нас есть, например, 500 вланов, и мы хотим балансировать нагрузку так, чтобы половина из них работала по одному линку (второй при этом блокируется и стоит в резерве), а вторая- по другому. Это можно сделать с помощью обычного STP, назначив один корневой свич в диапазоне вланов 1-250, а другой- в диапазоне 250-500. Но процессы будут работать для каждого из пятисот вланов по отдельности (хотя действовать будут совершенно одинаково для каждой половины). Логично, что тут хватит и двух процессов. MSTP позволяет создавать столько процесов STP, сколько у нас логических топологий (в данном примере- 2), и распределять по ним вланы. Думаем, нет особого смысла углубляться в теорию и практику MSTP в рамках этой статьи (ибо теории там ого-го), интересующиеся могут пройти по ссылке.
Агрегация каналов
Но какой бы вариант STP мы не использовали, у нас все равно существует так или иначе неработающий линк. А возможно ли задействовать параллельные линки по полной и при этом избежать петель? Да, отвечаем мы вместе с циской, начиная рассказ о EtherChannel.
Иначе это называется link aggregation, link bundling, NIC teaming, port trunkinkg
Технологии агрегации (объединения) каналов выполняют 2 функции: с одной стороны, это объединение пропускной способности нескольких физических линков, а с другой — обеспечение отказоустойчивости соединения (в случае падения одного линка нагрузка переносится на оставшиеся). Объединение линков можно выполнить как вручную (статическое агрегирование), так и с помощью специальных протоколов: LACP (Link Aggregation Control Protocol) и PAgP (Port Aggregation Protocol). LACP, опеределяемый стандартом IEEE 802.3ad, является открытым стандартом, то есть от вендора оборудования не зависит. Соответственно, PAgP — проприетарная цисковская разработка.
В один такой канал можно объединить до восьми портов. Алгоритм балансировки нагрузки основан на таких параметрах, как IP/MAC-адреса получателей и отправителей и порты. Поэтому в случае возникновения вопроса: “Хей, а чего так плохо балансируется?” в первую очередь смотрите на алгоритм балансировки.
Тема агрегации каналов заслуживает отдельной статьи, а то и книги, поэтому углубляться не будем, интересующимся- ссылка.
Port security
Теперь расскажем вкратце, как обеспечить безопасность сети на втором уровне OSI. В этой части статьи теория и практическая конфигурация совмещены. Увы, Packet Tracer не умеет ничего из упомянутых в этом разделе команд, поэтому все без иллюстраций и проверок.
Для начала, следует упомянуть команду конфигурации интерфейса switchport port-security, включающую защиту на определенном порту свича. Затем, с помощью switchport port-security maximum 1 мы можем ограничить количество mac-адресов, связанных с данным портом (т.е., в нашем примере, на данном порту может работать только один mac-адрес). Теперь указываем, какой именно адрес разрешен: его можно задать вручную switchport port-security mac-address адрес, или использовать волшебную команду switchport port-security mac-address sticky, закрепляющую за портом тот адрес, который в данный момент работает на порту. Далее, задаем поведение в случае нарушения правила switchport port-security violation {shutdown | restrict | protect}: порт либо отключается, и потом его нужно поднимать вручную (shutdown), либо отбрасывает пакеты с незарегистрированного мака и пишет об этом в консоль (restrict), либо просто отбрасывает пакеты (protect).
Помимо очевидной цели — ограничение числа устройств за портом — у этой команды есть другая, возможно, более важная: предотвращать атаки. Одна из возможных — истощение CAM-таблицы. С компьютера злодея рассылается огромное число кадров, возможно, широковещательных, с различными значениями в поле MAC-адрес отправителя. Первый же коммутатор на пути начинает их запоминать. Одну тысячу он запомнит, две, но память-то оперативная не резиновая, и среднее ограничение в 16000 записей будет довольно быстро достигнуто. При этом дальнейшее поведение коммутатора может быть различным. И самое опасное из них с точки зрения безопасности: коммутатор может начать все кадры, приходящие на него, рассылать, как широковещательные, потому что MAC-адрес получателя не известен (или уже забыт), а запомнить его уже просто некуда. В этом случае сетевая карта злодея будет получать все кадры, летающие в вашей сети.
DHCP Snooping
Другая возможная атака нацелена на DHCP сервер. Как мы знаем, DHCP обеспечивает клиентские устройства всей нужной информацией для работы в сети: ip-адресом, маской подсети, адресом шюза по умолчанию, DNS-сервера и прочим. Атакующий может поднять собственный DHCP, который в ответ на запрос клиентского устройства будет отдавать в качестве шлюза по умолчанию (а также, например, DNS-сервера) адрес подконтрольной атакующему машины. Соответственно, весь трафик, направленный за пределы подсети обманутыми устройствами, будет доступен для изучения атакующему — типичная man-in-the-middle атака. Либо такой вариант: подлый мошенник генерируют кучу DHCP-запросов с поддельными MAC-адресами и DHCP-сервер на каждый такой запрос выдаёт IP-адрес до тех пор, пока не истощится пул.
Для того, чтобы защититься от подобного вида атак, используется фича под названием DHCP snooping. Идея совсем простая: указать свичу, на каком порту подключен настоящий DHCP-сервер, и разрешить DHCP-ответы только с этого порта, запретив для остальных. Включаем глобально командой ip dhcp snooping, потом говорим, в каких вланах должно работать ip dhcp snooping vlan номер(а). Затем на конкретном порту говорим, что он может пренаправлять DHCP-ответы (такой порт называется доверенным): ip dhcp snooping trust.
IP Source Guard
После включения DHCP Snooping’а, он начинает вести у себя базу соответствия MAC и IP-адресов устройств, которую обновляет и пополняет за счет прослушивания DHCP запросов и ответов. Эта база позволяет нам противостоять еще одному виду атак — подмене IP-адреса (IP Spoofing). При включенном IP Source Guard, каждый приходящий пакет может проверяться на:
- соответствие IP-адреса источника адресу, полученному из базы DHCP Snooping (иными словами, айпишник закрепляется за портом свича)
- соответствие MAC-адреса источника адресу, полученному из базы DHCP Snooping
Включается IP Source Guard командой ip verify source на нужном интерфейсе. В таком виде проверяется только привязка IP-адреса, чтобы добавить проверку MAC, используем ip verify source port-security. Само собой, для работы IP Source Guard требуется включенный DHCP snooping, а для контроля MAC-адресов должен быть включен port security.
Dynamic ARP Inspection
Как мы уже знаем, для того, чтобы узнать MAC-адрес устройства по его IP-адресу, используется проткол ARP: посылается широковещательный запрос вида “у кого ip-адрес 172.16.1.15, ответьте 172.16.1.1”, устройство с айпишником 172.16.1.15 отвечает. Подобная схема уязвима для атаки, называемой ARP-poisoning aka ARP-spoofing: вместо настоящего хоста с адресом 172.16.1.15 отвечает хост злоумышленника, заставляя таким образом трафик, предназначенный для 172.16.1.15 следовать через него. Для предотвращения такого типа атак используется фича под названием Dynamic ARP Inspection. Схема работы похожа на схему DHCP-Snooping’а: порты делятся на доверенные и недоверенные, на недоверенных каждый ARP-ответ подвергаются анализу: сверяется информация, содержащаяся в этом пакете, с той, которой свич доверяет (либо статически заданные соответствия MAC-IP, либо информация из базы DHCP Snooping). Если не сходится- пакет отбрасывается и генерируется сообщение в syslog. Включаем в нужном влане (вланах): ip arp inspection vlan номер(а). По умолчанию все порты недоверенные, для доверенных портов используем ip arp inspection trust.
Практика
Наверное, большинство ошибок в Packet Tracer допущено в части кода, отвечающего за симуляцию STP, будте готовы. В случае сомнения сохранитесь, закройте PT и откройте заново
Итак, переходим к практике. Для начала внесем некоторые изменения в топологию — добавим избыточные линки. Учитывая сказанное в самом начале, вполне логично было бы сделать это в московском офисе в районе серверов — там у нас свич msk-arbat-asw2 доступен только через asw1, что не есть гуд. Мы отбираем (пока, позже возместим эту потерю) гигабитный линк, который идет от msk-arbat-dsw1 к msk-arbat-asw3, и подключаем через него asw2. Asw3 пока подключаем в порт Fa0/2 dsw1. Перенастраиваем транки:
msk-arbat-dsw1(config)#interface gi1/2
msk-arbat-dsw1(config-if)#description msk-arbat-asw2
msk-arbat-dsw1(config-if)#switchport trunk allowed vlan 2,3
msk-arbat-dsw1(config-if)#int fa0/2
msk-arbat-dsw1(config-if)#description msk-arbat-asw3
msk-arbat-dsw1(config-if)#switchport mode trunk
msk-arbat-dsw1(config-if)#switchport trunk allowed vlan 2,101-104
msk-arbat-asw2(config)#int gi1/2
msk-arbat-asw2(config-if)#description msk-arbat-dsw1
msk-arbat-asw2(config-if)#switchport mode trunk
msk-arbat-asw2(config-if)#switchport trunk allowed vlan 2,3
msk-arbat-asw2(config-if)#no shutdown
Не забываем вносить все изменения в документацию!
Скачать актуальную версию документа.
Теперь посмотрим, как в данный момент у нас самонастроился STP. Нас интересует только VLAN0003, где у нас, судя по схеме, петля.
msk-arbat-dsw1>en
msk-arbat-dsw1#show spanning-tree vlan 3
Разбираем по полочкам вывод команды
Итак, какую информацию мы можем получить? Так как по умолчанию на современных цисках работает PVST+ (т.е. для каждого влана свой процесс STP), и у нас есть более одного влана, выводится информация по каждому влану в отдельности, каждая запись предваряется номером влана. Затем идет вид STP: ieee значит PVST, rstp — Rapid PVST, mstp то и значит. Затем идет секция с информацией о корневом свиче: установленный на нем приоритет, его mac-адрес, стоимость пути от текущего свича до корневого, порт, который был выбран в качестве корневого (имеет лучшую стоимость), а также настройки таймеров STP. Далее- секция с той же информацией о текущем свиче (с которого выполняли команду). Затем- таблица состояния портов, которая состоит из следующих колонок (слева направо):
- собственно, порт
- его роль (Root- корневой порт, Desg- назначенный порт, Altn- дополнительный, Back- резервный)
- его статус (FWD- работает, BLK- заблокирован, LIS- прослушивание, LRN- обучение)
- стоимость маршрута до корневого свича
- Port ID в формате: приоритет порта.номер порта
- тип соединения
Итак, мы видим, что Gi1/1 корневой порт, это дает некоторую вероятность того, что на другом конце линка корневой свич. Смотрим по схеме, куда ведет линк: ага, некий msk-arbat-asw1.
msk-arbat-asw1#show spanning-tree vlan 3
И что же мы видим?
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 32771
Address 0007.ECC4.09E2
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Вот он, наш корневой свич для VLAN0003.
А теперь посмотрим на схему. Ранее, мы увидели в состоянии портов, что dsw1 блокирует порт Gi1/2, разрывая таким образом петлю. Но является ли это оптимальным решением? Нет, конечно. Сейчас наша новая сеть работает точь-в-точь как старая- трафик от asw2 идет только через asw1. Выбор корневого маршрутизатора никогда не нужно оставлять на совесть глупого STP. Исходя из схемы, наиболее оптимальным будет выбор в качестве корневого свича dsw1- таким образом, STP заблокирует линк между asw1 и asw2. Теперь это все надо объяснить недалекому протоколу. А для него главное что? Bridge ID. И он неслучайно складывается из двух чисел. Приоритет- это как раз то слагаемое, которое отдано на откуп сетевому инженеру, чтобы он мог повлиять на результат выбора корневого свича. Итак, наша задача сводится к тому, чтобы уменьшить (меньше-лучше, думает STP) приоритет нужного свича, чтобы он стал Root Bridge. Есть два пути:
1) вручную установить приоритет, заведомо меньший, чем текущий:
msk-arbat-dsw1>enable
msk-arbat-dsw1#configure terminal
msk-arbat-dsw1(config)#spanning-tree vlan 3 priority?
<0-61440> bridge priority in increments of 4096
msk-arbat-dsw1(config)#spanning-tree vlan 3 priority 4096
Теперь он стал корневым для влана 3, так как имеет меньший Bridge ID:
msk-arbat-dsw1#show spanning-tree vlan 3
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 4099
Address 000B.BE2E.392C
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
2) дать умной железке решить все за тебя:
msk-arbat-dsw1(config)#spanning-tree vlan 3 root primary
Проверяем:
msk-arbat-dsw1#show spanning-tree vlan 3
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 24579
Address 000B.BE2E.392C
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Мы видим, что железка поставила какой-то странный приоритет. Откуда взялась эта круглая цифра, спросите вы? А все просто- STP смотрит минимальный приоритет (т.е. тот, который у корневого свича), и уменьшает его на два шага инкремента (который составляет 4096, т.е. в итоге 8192). Почему на два? А чтобы была возможность на другом свиче дать команду spanning-tree vlan n root secondary (назначает приоритет=приоритет корневого-4096), что позволит нам быть уверенными, что, если с текущим корневым свичом что-то произойдет, его функции перейдут к этому, “запасному”. Вероятно, вы уже видите на схеме, как лампочка на линке между asw2 и asw1 пожелтела? Это STP разорвал петлю. Причем именно в том месте, в котором мы хотели. Sweet! Зайдем проверим: лампочка — это лампочка, а конфиг — это факт.
msk-arbat-asw2#show spanning-tree vlan 3 VLAN0003 Spanning tree enabled protocol ieee Root ID Priority 24579 Address 000B.BE2E.392C Cost 4 Port 26(GigabitEthernet1/2) Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Bridge ID Priority 32771 (priority 32768 sys-id-ext 3) Address 000A.F385.D799 Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec Aging Time 20 Interface Role Sts Cost Prio.Nbr Type ---------------- ---- --- --------- -------- -------------------------------- Fa0/1 Desg FWD 19 128.1 P2p Gi1/1 Altn BLK 4 128.25 P2p Gi1/2 Root FWD 4 128.26 P2p
Теперь полюбуемся, как работает STP: заходим в командную строку на ноутбуке PTO1 и начинаем бесконечно пинговать наш почтовый сервер (172.16.0.4). Пинг сейчас идет по маршруту ноутбук-asw3-dsw1-gw1-dsw1(ну тут понятно, зачем он крюк делает — они из разных вланов)-asw2-сервер. А теперь поработаем Годзиллой из SimСity: нарушим связь между dsw1 и asw2, вырвав провод из порта (замечаем время, нужное для пересчета дерева).
Пинги пропадают, STP берется за дело, и за каких-то 30 секунд коннект восстанавливается. Годзиллу прогнали, пожары потушили, связь починили, втыкаем провод обратно. Пинги опять пропадают на 30 секунд! Мда-а-а, как-то не очень быстро, особенно если представить, что это происходит, например, в процессинговом центре какого-нибудь банка.
Но у нас есть ответ медленному PVST+! И ответ этот — Быстрый PVST+ (так и называется, это не шутка: Rapid-PVST). Посмотрим, что он нам дает. Меняем тип STP на всех свичах в москве командой конфигурационного режима: spanning-tree mode rapid-pvst
Снова запускаем пинг, вызываем Годзиллу… Эй, где пропавшие пинги? Их нет, это же Rapid-PVST. Как вы, наверное, помните из теоретической части, эта реализация STP, так сказать, “подстилает соломку” на случай падения основного линка, и переключается на дополнительный (alternate) порт очень быстро, что мы и наблюдали. Ладно, втыкаем провод обратно. Один потерянный пинг. Неплохо по сравнению с 6-8, да?
EtherChannel
Помните, мы отобрали у офисных работников их гигабитный линк и отдали его в пользу серверов? Сейчас они, бедняжки, сидят, на каких-то ста мегабитах, прошлый век! Попробуем расширить канал, и на помощь призовем EtherChannel. В данный момент у нас соединение идет от fa0/2 dsw1 на Gi1/1 asw3, отключаем провод. Смотрим, какие порты можем использовать на asw3: ага, fa0/20-24 свободны, кажется. Вот их и возьмем. Со стороны dsw1 пусть будут fa0/19-23. Соединяем порты для EtherChannel между собой. На asw3 у нас на интерфейсах что-то настроено, обычно в таких случаях используется команда конфигурационного режима default interface range fa0/20-24, сбрасывающая настройки порта (или портов, как в нашем случае) в дефолтные. Packet tracer, увы, не знает такой хорошей команды, поэтому в ручном режиме убираем каждую настройку, и тушим порты (лучше это сделать, во избежание проблем)
msk-arbat-asw3(config)#interface range fa0/20-24
msk-arbat-asw3(config-if-range)#no description
msk-arbat-asw3(config-if-range)#no switchport access vlan
msk-arbat-asw3(config-if-range)#no switchport mode
msk-arbat-asw3(config-if-range)#shutdown
ну а теперь волшебная команда
msk-arbat-asw3(config-if-range)#channel-group 1 mode on
то же самое на dsw1:
msk-arbat-dsw1(config)#interface range fa0/19-23
msk-arbat-dsw1(config-if-range)#channel-group 1 mode on
поднимаем интерфейсы asw3, и вуаля: вот он, наш EtherChannel, раскинулся аж на 5 физических линков. В конфиге он будет отражен как interface Port-channel 1. Настраиваем транк (повторить для dsw1):
msk-arbat-asw3(config)#int port-channel 1
msk-arbat-asw3(config-if)#switchport mode trunk
msk-arbat-asw3(config-if)#switchport trunk allowed vlan 2,101-104
Как и с STP, есть некая трудность при работе с etherchannel в Packet Tracer’e. Настроить-то мы, в принципе, можем по вышеописанному сценарию, но вот проверка работоспособности под большим вопросом: после отключения одного из портов в группе, трафик перетекает на следующий, но как только вы вырубаете второй порт — связь теряется и не восстанавливается даже после включения портов.
Отчасти в силу только что озвученной причины, отчасти из-за ограниченности ресурсов мы не сможем раскрыть в полной мере эти вопросы и посему оставляем бОльшую часть на самоизучение.
Материалы выпуска
Новый план коммутации
Файл PT с лабораторной.
Конфигурация устройств
STP или STP
Безопасность канального уровня
Агрегация каналов
По сложившейся традиции все неотвеченные вопросы безымянными читателями хабра задаются в блоге цикла в ЖЖ.
За видео и помощь в подготовке статьи спасибо eucariot

