На прошлой неделе на Хабре появилось 2 поста о фреймворке распределенных вычислений от Microsoft Research – Dryad. В частности, подробно были описаны концепции и архитектура ключевых компонентов Dryad – среды исполнения Dryad и языка запросов DryadLINQ.
Логическим завершением цикла статей о Dryad видится сравнение фреймворка Dryad с другими, знакомыми разработчикам MPP-приложений, инструментами: реляционными СУБД (в т.ч. параллельными), GPU-вычислениями и платформой Hadoop.
Я не предлагаю, как и не отговариваю использовать Dryad в своих исследовательских проектах (т.к. сейчас доступна только академическая лицензия).
Dryad это «внутренний» продукт всем нам известной корпорации
То, что Dryad — проприетарное ПО, не делают (говорю за себя) изучение принципов и архитектуры этой платформы менее интересным или полезным для профессионального развития (опять – за себя). Если у Вас что-то по-другому — то
В первой части, на примере Dryad, будет проведен общий обзор преимуществ фреймворков распределенных вычислений, предоставляющих разработчикам высокоуровневые абстракции, перед более низкоуровневыми инструментами параллелизации вычислений — MPI и вычислениями на GPU.
Такое cравнение в отрыве от контекста (т.е. конкретной задачи) некорректно, но является допустимым для нашей цели — показать кейсы уместного использования фреймворков распределенного выполнения приложений.
Во второй части пройдет сравнение с РСУБД и параллельными СУБД. Разумеется, объем публикации не позволяет сравнивать Dryad отдельно с MySQL и отдельно с SQL Server 2012 Parallel Data Warehouse (да и зачем?). Поэтому для анализа взята «средняя температура по больнице» СУБД: обсудим общие проблемы решений на основе реляционных баз данных и рассмотрим Dryad, как продолжение лучших идей мира СУБД.
В заключительной части, будет проведено сравнение с программной платформой Hadoop (последнюю можно либо не знать, либо восхищаться).
У Hadoop 2 больших достоинства (разумеется, больше) — новый фреймворк (о нем позже), предоставляющий API для реализации собственных распределенных алгоритмов, и богатая экосистема. Как не парадоксально, это же — основные недостатки Hadoop: новый фреймворк в beta (начало разработки — 2008 год), а без установки множества компонент из экосистемы Hadoop (установка, обучение, поддержка) использовать Hadoop в enterprise-сегменте — задача нетривиальная.
Поэтому сравнение Dryad идет с релизной веткой plain Hadoop и бесконечной оглядкой на возможности, предоставляемые экосистемой Hadoop, и то, как эта проблема (при ее наличии) будет решена в Hadoop v2.0.
1. Dryad vs GPU. Dryad vs MPI
Принимая во внимание наличие академической лицензии у Dryad, я заинтересовался возможностью применения фреймворка Dryad в расчетах для исследований (я — аспирант). Но исторически сложилось, что в академической среде (моего ВУЗа, точно) основными платформами для «scientific computing» являются MPI (Message Passing Interface) и GPU-вычисления.
В отличие от MPI, платформа Dryad основана на shared-nothing архитектуре, не имеющей разделяемых (различными процессами) данных и, как следствие, не нуждающаяся в использовании примитивов синхронизации. Это делает Dryad-кластер не только потенциально более масштабируемым, но и более эффективным по времени для решения задач, использующих параллельные по данным алгоритмы.
Кроме того, такие инфраструктурные задачи, как мониторинг выполнения, обработка отказов, обычно являются зоной ответственности MPI-разработчика, в то время как в Dryad перечисленные задачи входят в зону ответственности фреймворка.
Говоря о GPU-вычислениях, стоит отметить, что, в отличие от Dryad, разработка под GPU довольно сильно связана с аппаратным уровнем, на котором запускается приложение. NVidia и AMD предоставляют свои собственные SDK для разработки под свои графические карты (CUDA и APP, соответственно). Очевидно, что это различные несовместимые друг с другом платформы разработки.
Корпорация зла Microsoft предприняла попытку унифицировать процесс разработки под GPU, выпустив С++ AMP. Но этот факт — лишнее доказательством, что разрабатывая под GPU, разработчик должен «оглядываться» на аппаратное обеспечение графического адаптера. Причем «корни» аппаратного уровня проникают в код настолько глубоко, что могут возникнуть сложности запуска приложения даже при смене модели графической карты, не говоря уже про смену вендора. Естественно, это создает дополнительные сложности как при отладке, так и при миграции на более производительную/подходящую для конкретной задачи аппаратную платформу.
Все это, в конечном итоге, заставляет исследователя заниматься решением инфраструктурных вопросов, связанных с аппаратным обеспечением, отладкой, развертыванием и поддержкой, вместо решения прикладных вопросов предметной области исследования.
Фреймворк Dryad, в отличие от GPU, скрывает от разработчиков распределенных приложений аппаратный уровень, хотя и предъявляет довольно специфические требования к аппаратной платформе для запуска распределенного приложения (требования были рассмотрены в первой статье цикла).
2. Dryad vs Parallel DB
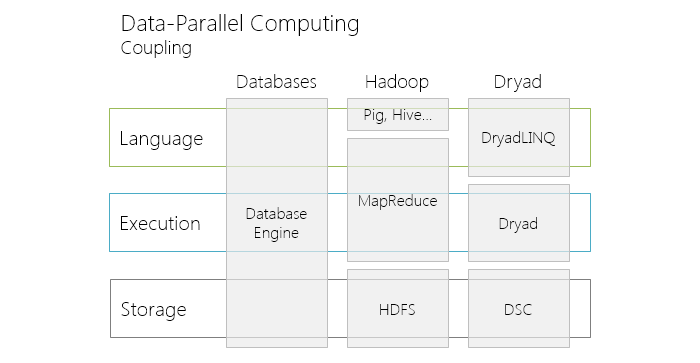
Основное фундаментальное отличие Dryad от СУБД – отсутствие сильной связанности между слоями хранения, слоем исполнения и программной моделью у Dryad и наличие такой связанности у СУБД. Это различие продемонстрировано на
иллюстрации во введении.
Тем не менее Dryad «впитал» в себя многие идеи мира как традиционных, так и параллельных СУБД.
Так, как и многие параллельные СУБД (Teradata, IBM DB2 Parallel Edition), Dryad использует shared-nothing архитектуру, шардинг (горизонтальное партицирование), динамическое репартицирование, стратегии партицирования: hash-partitioning, range partitioning и round-robin.
Из мира традиционных СУБД, были взяты концепции оптимизатора запросов и плана исполнения. Эти концепции крайне сильно трансформировались: результатом работы планировщика DryadLINQ является граф исполнения (EPG, Execution Plan Graph), изменяемый динамически на основе политик и собираемой во время исполнения статистики.
Как все СУБД, Dryad используют язык запросов к данным. В Dryad роль языка для написания запросов исполняет программная модель DryadLINQ. Но в отличие от SQL, DryadLINQ:
+ изначально создавалась для работы со структурами данным и сложными типами;
+ является высокоуровневой абстракцией, не связывающей уровень приложения с уровнем
хранения;
+ имеет нативную поддержку общих паттернов программирования, таких как итерации;
— не поддерживает транзакции и update-операции.
Кроме того, SQL принципиально не подходит для описания алгоритмов машинного обучения, парсинга последовательностей фактов (логов, геномных баз), анализа графов. Также как Dryad неэффективен для решения задач на основе алгоритмов, требующих random-access доступа к данным.
Ниже приведена таблица сравнения решений на основе реляционных СУБД и на основе фреймворков распределенных вычислений.

В заключении сравнения отмечу: наибольшее препятствие широкого распространения решений на основе параллельных СУБД – стоимость решении, которая, в общем случае, составляет сотни тысяч долларов. Сколько бы стоило решение на основе Dryad-кластера можно только предположить; по моему мнению, речь идет у сумме на порядок ниже.
3. Dryad vs Hadoop
Парадигма map/reduce – крайне изящный способ описания алгоритмов параллельных по данным. Возникновение Hadoop, предоставившей инфраструктуру исполнения и программную модель написания map/reduce-приложений, стало революционным скачком в решении проблем Больших Данных.

* Направленный ациклический граф (англ. Directed Acyclic Graph).
** Доступна только beta-версия (на июнь 2013).
*** Любой CLS-совместимый ЯП со статической типизацией.
**** Инфраструктура для развертывания Hadoop-кластера и исполнения Hadoop-задач.
***** Доступно только при установке сторонних компонент экосистемы Hadoop.
3.1. Hadoop
Идеологи и разработчики Hadoop, отбросив все лишнее, сделали простую, понятную максимальному кругу разработчиков, крайне эффективную и столь же ограниченную платформу разработки MPP-приложений.
Hadoop прекрасно подходит для map/reduce и пока не выдерживает никакой критики при разработке под другие распределенные алгоритмы (ждем YARN). Отсюда и огромное количество вспомогательных инструментов Hadoop, базирующихся как на вычислительном фреймворке Hadoop MapReduce (таких как, Pig), так и представляющий отдельные вычислительные фреймворки (Hive, Storm, Apache Giraph). И все эти инструменты предоставляют зачастую дублирующиеся решения для задач узкого характера (по сути, обхода ограничений) вместо предоставления единого универсального инструмента решения как парсинга логов, так и подсчета PageRank и анализа графов.
Естественно, установка, настройка и поддержка всей экосистемы Hadoop, необходимой для решения повседневных задач аналитики — это немалые временные и, как следствие, финансовые затраты, которые уходят на решение задач инфраструктурного характера, а не задач бизнеса и/или исследователя. Как частичное решение этой проблемы появились дистрибьюторы платформы Hadoop в «собранном виде» (крупнейшие из них — Cloudera и Hortonworks). Но это все же не решение проблемы — это лишнее подтверждение ее наличия.
Эволюционным скачком станет (пока что в будущем времени) программный фреймворк YARN, предоставляющий разработчикам компоненты и API, необходимые для разработки распределенных алгоритмов, отличных от map/reduce. YARN также решает многие проблемы Hadoop v1.0, в числе которых низкая утилизация ресурсов и порог масштабируемости, находящихся сейчас на уровне ~4K вычислительных узлов (в то время как у Dryad еще в 2011 году уже работал на 10K нод).
На май 2013 года YARN пока не в release-версии. Учитывая «неторопливость» Apache-community, необходимо принимать во внимание высокую вероятность того, что промежуток времени между выходом release-версии YARN и release-версий распределенных алгоритмов, отличных от map/reduce, написанных с использованием YARN API, может составлять года.
3.2. Dryad
Фреймворк Dryad же изначально позволял разработчикам реализовывать произвольные распределенные алгоритмы. Таким образом, программная модель Hadoop MapReduce (v1.0) — лишь частный случай более общей программной модели Dryad.
Не будем углубляться в проблемы Hadoop с операциями Join, эффективностью расчета PageRank, другие ограничения платформы Hadoop и способами их решения, так как это явно входит за рамки статьи. Вместо этого обсудим возможности фреймворка Dryad, аналогов которых нет у платформы Hadoop.
Dryad имеет внушительный список инструментов по планированию процесса выполнения распределенного приложения, описанные в предыдущих статьях цикла. Так есть параллельный компилятор, преобразующий выражения, написанные на DryadLINQ, в граф выполнения — EPG. EPG проходит стадию оптимизации как перед выполнением (статический оптимизатор), так и во время исполнения (динамическая оптимизация на основе политик и собранной во время исполнения статистики).
Параллельный компилятор, граф выполнения и возможность по статической/динамической оптимизации графа делают планирование/выполнение распределенного приложения открытым для улучшений и оптимизаций.
Концепция направленного ациклического графа позволяет решать множество проблем, связанных с отказоустойчивостью, мониторингом, планирование и управлением ресурсов, значительно более элегантными путями, чем это реализовано в Hadoop (об этом я писал в первой статье цикла).
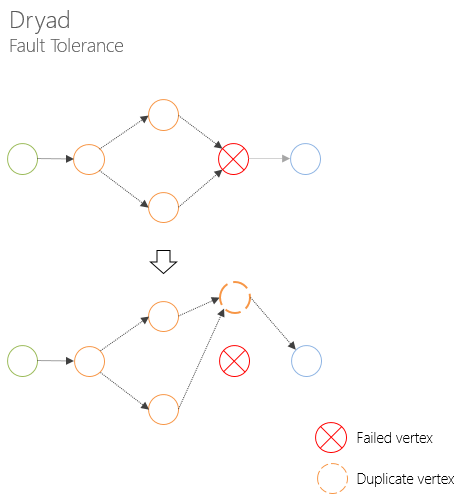
Обработка отказов вычислительных узлов позволяет не перезапускать все стадию заново.
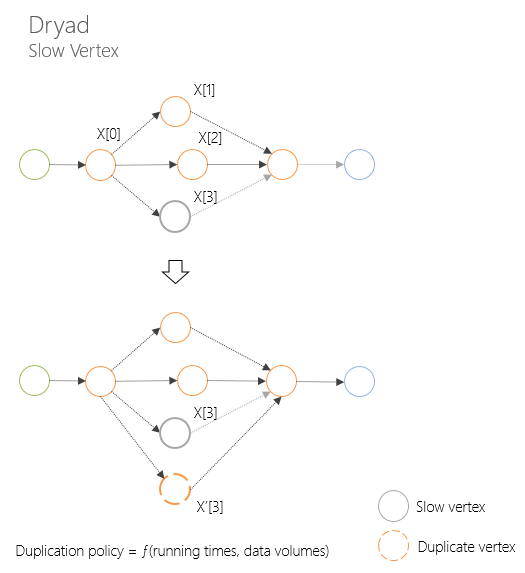
Обработка «медленных» вычислительных узлов позволяет не «ждать» узлам, «окончившим» работу, самый медленный узел (например, для начала фазы Reduce)
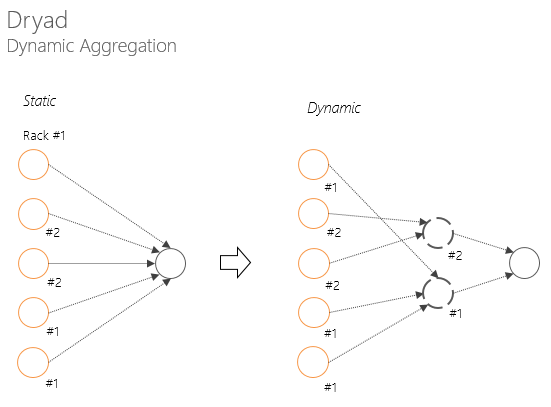
Динамическая агрегация в Dryad позволяет избежать деградации пропускной способности сети перед началом следующей стадии (например, свертки).
Еще одна интересная возможность, которой не хватает Hadoop — абстракции понятия канал. Благодаря введенной абстракции, каналом в Dryad может выступать как TCP, так и временный файл и shared memory FIFO. Что позволяет в таких алгоритмах, как расчет PageRank, осуществлять обмен данных между итерациями по каналам с низкой латентностью (например, shared memory FIFO). В то время как в Hadoop передача данных между итерациями всегда будет идти по TCP-каналам, имеющим довольно высокую латентность по сравнению с shared memory. (Есть информация, что в YARN такое поведение исправили, но работающего подтверждения я еще не видел.)

Источник иллюстрации [7]
Некоторые архитектурные решения Dryad (одно из них, обсуждаемое в прошлой статье, «прикрепление» метаданных к графам выполнения) и нативная поддержка фреймворком высокоуровневых ЯП со статической типизацией, позволили при разработке Dryad-приложений оперировать исключительно строго типизированными данными. В тот время как для разработчиков под Hadoop, привычной практикой является парсинг входных данных и дальнейшее (не самого безопасное) приведение к ожидаемому типу.
3.3. Практика
Ниже приведены листинги приложений, рассчитывающих среднее арифметическое, для Hadoop и Dryad с использованием низкоуровневых API.
Листинг 1. Расчет среднего арифметического в Hadoop (Java). Источник [1].
// InitialReduce: input is a sequence of raw data tuples; // produces a single intermediate result as output static public class Initial extends EvalFunc<Tuple> { @Override public void exec(Tuple input, Tuple output) throws IOException { try { output.appendField(new DataAtom(sum(input))); output.appendField(new DataAtom(count(input))); } catch(RuntimeException t) { throw new RuntimeException([...]); } } } // Combiner: input is a sequence of intermediate results; // produces a single (coalesced) intermediate result static public class Intermed extends EvalFunc<Tuple> { @Override public void exec(Tuple input, Tuple output) throws IOException { combine(input.getBagField(0), output); } } // FinalReduce: input is one or more intermediate results; // produces final output of aggregation function static public class Final extends EvalFunc<DataAtom> { @Override public void exec(Tuple input, DataAtom output) throws IOException { Tuple combined = new Tuple(); if(input.getField(0) instanceof DataBag) { combine(input.getBagField(0), combined); } else { throw new RuntimeException([...]); } double sum = combined.getAtomField(0).numval(); double count = combined.getAtomField(1).numval(); double avg = 0; if (count > 0) { avg = sum / count; } output.setValue(avg); } } static protected void combine(DataBag values, Tuple output) throws IOException { double sum = 0; double count = 0; for (Iterator it = values.iterator(); it.hasNext();) { Tuple t = (Tuple) it.next(); sum += t.getAtomField(0).numval(); count += t.getAtomField(1).numval(); } output.appendField(new DataAtom(sum)); output.appendField(new DataAtom(count)); } static protected long count(Tuple input) throws IOException { DataBag values = input.getBagField(0); return values.size(); } static protected double sum(Tuple input) throws IOException { DataBag values = input.getBagField(0); double sum = 0; for (Iterator it = values.iterator(); it.hasNext();) { Tuple t = (Tuple) it.next(); sum += t.getAtomField(0).numval(); } return sum; }
Листинг 2. Расчет среднего арифметического в Dryad (C#). Источник [1].
public static IntPair InitialReduce(IEnumerable<int> g) { return new IntPair(g.Sum(), g.Count()); } public static IntPair Combine(IEnumerable<IntPair> g) { return new IntPair(g.Select(x => x.first).Sum(), g.Select(x => x.second).Sum()); } [AssociativeDecomposable("InitialReduce", "Combine")] public static IntPair PartialSum(IEnumerable<int> g) { return InitialReduce(g); } public static double Average(IEnumerable<int> g) { IntPair final = g.Aggregate(x => PartialSum(x)); if (final.second == 0) return 0.0; return (double)final.first / (double)final.second; }
3.4. Доступность для разработчиков
Dryad является довольно закрытой от профессионального сообщества проприетарной системой с туманным будущим (точнее совсем без такого). В противовес этому, Hadoop является open-source проектом с огромным community-сообществом, ясным способом лицензирования и несколькими крупными дистрибуторами (Cloudera, Hortonworks, etc.).
В заключении главы сравнения с Hadoop отмечу, что получить Hadoop-кластер в свое использование на текущем уровне развития облачных сервисов не представляет труда: Amazon Web Services предоставляют Hadoop-кластер через свой сервис Amazon Elastic MapReduce, а облачная платформа Windows Azure – через сервис Microsoft HDInsight.
С появлением связки «Hadoop + { WA | AWS }» доступность платформы Hadoop для стартапов и исследователей стала крайне высокой. О доступности Dryad говорить не приходиться: коммерческих лицензий нет, про академическое использование — почти нигде не рассказывали.
Hadoop — дефакто стандарт для работы с Big Data. Есть ожидание, что после будущего релиза YARN ни у кого не останется сомнений, что платформа стала этим стандартом заслужено. У Dryad же как у проекта похоже есть «реинкарнации», одна из них — Naiad (incremental Dryad); а принципы, заложенные в Dryad, наверняка, нашли свое продолжение не только в проектах Microsoft Research, но и open-source сообщества.
Заключение
Фреймворк Dryad, имея в своей основе концепцию направленного ациклического графа, наложил на эту концепцию последние идеи мира фреймворков распределенного исполнения приложений, традиционных и параллельных СУБД. Разделение ответственностей, связанных со средой исполнения, распределенным хранилищем и программной моделью, между отдельными модулями позволило Dryad остаться крайне гибкой системой; а тесная интеграции с существующим программным стеком для .NET-разработчиков (.NET Framework, C#, Visual Studio) существенно снижает время, необходимое для начала работы с фреймворком.
Простая и изящная концепция, инновационные идеи, прекрасная архитектура и знакомый стек технологий делают Dryad эффективным инструментом для работы с Big Data. Более эффективным, чем аппаратно-привязанные GPU-вычисления; плохо масштабируемые решения на основе традиционных СУБД; дорогие и ограниченные примитивностью языка SQL решения на основе параллельных СУБД. Dryad превосходит «зацикленный» на модели map/reduce Hadoop, страдающий до появления YARN, то от единичных точек отказа, то от низкой утилизации ресурсов, то элементарно от инертности собственного сообщества.
В то же время все очевидные достоинства Dryad с легкость нивелируются природой этого продукта – это проприетарный продукт Microsoft для внутреннего использования, судьбу которого Microsoft решает единолично.
Но это не мешает Dryad быть тем, чем он является – новый интересный взгляд, инновационное виденье на системы распределенного выполнения приложений от Microsoft Research.
Список источников
[1] Y. Yu, P. K. Gunda, M. Isard. Distributed Aggregation for Data-Parallel Computing: Interfaces and Implementations, 2009.
[2] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: Distributed data-parallel programs from sequential building blocks. In Proceedings of European Conference on Computer Systems (EuroSys), 2007.
[3] Tom White. Hadoop: The Definitive Guide, 3rd Edition. O'Reilly Media / Yahoo Press, 2012.
[4] Arun C Murthy. The Next Generation of Apache Hadoop MapReduce. Yahoo, 2011.
[5] D. DeWitt and J. Gray. Parallel database systems: The future of high performance database processing. Communications of the ACM, 36(6), 1992.
[6] David Tarditi, Sidd Puri, and Jose Oglesby. Accelerator: using data-parallelism to program GPUs for general-purpose uses. In International Conference on Architectural Support for Programming Languages and Operating Systems ASPLOS), Boston, MA, October 2006.
[7] Jinyang Li. Dryad / DryadLINQ Slides adapted from those of Yuan Yu and Michael Isard, 2009.


{kind=link}