В этом посте я хотелбы рассмотреть подход к резервному копирования данных на СХД NetApp серии FAS.
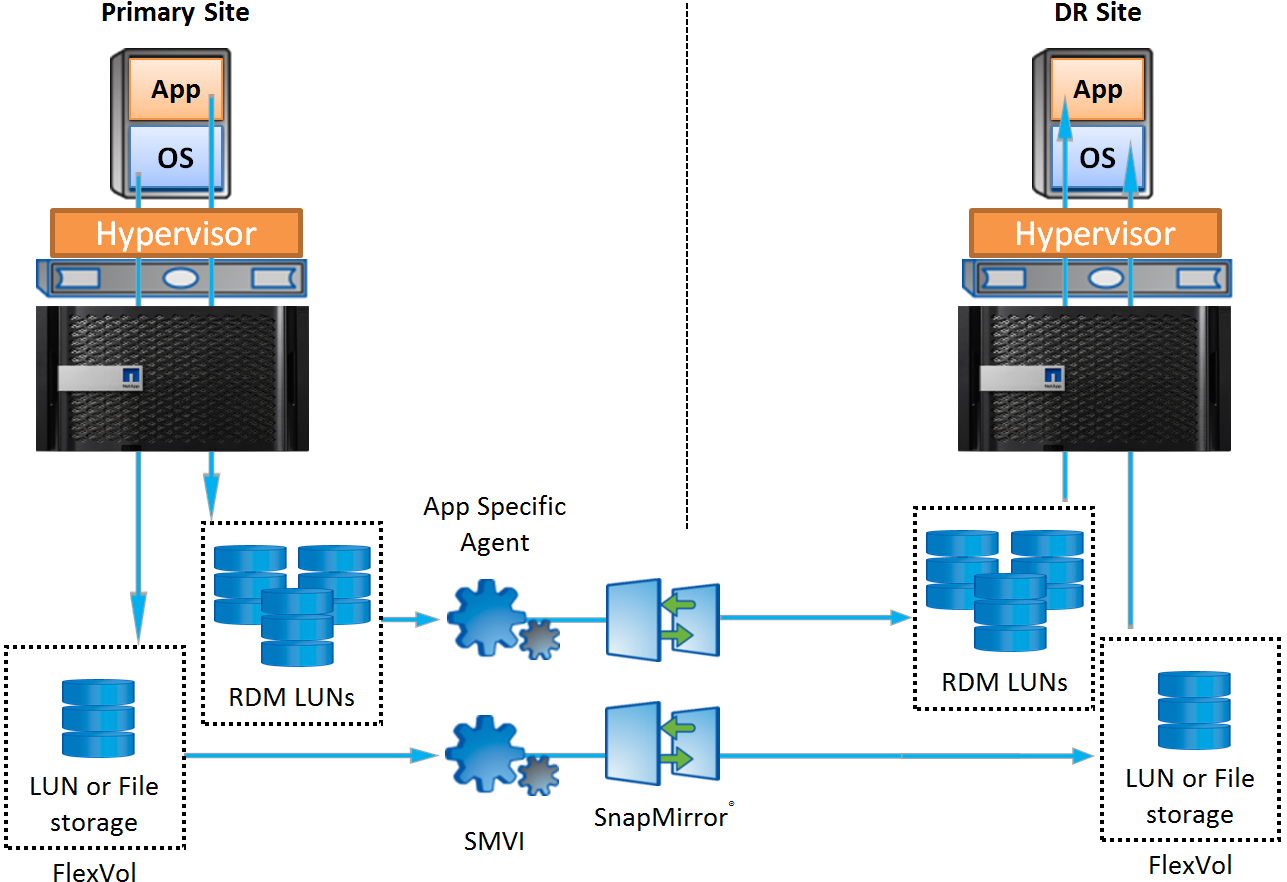
Архитектура резервного копирования
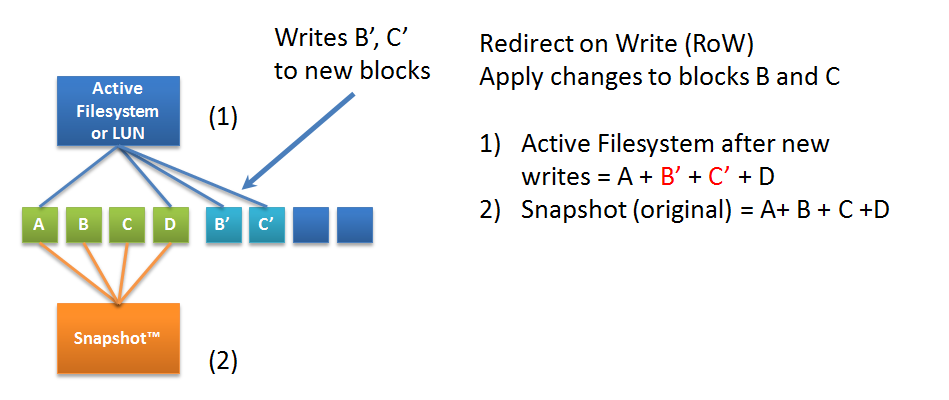
И начну я издали — со снепшотов. Технология снепшотов впервые была изобретена (и запатентирована) в 1993 году компанией NetApp, а само слово Snapshot является её торговой маркой. Технология снепшотирования логически проистекала из механизмов работы файловой структуры WAFL. Почему WAFL не файловая система смотрите здесь. Дело в том, что WAFL всегда пишет новые данные «в новое место» и просто переставляет указатель на содержимое новых данных в новое место, а старые данные не удаляются, эти блоки данных, на которые нет указателей, считаются высвобожденными для новых записей. Благодаря этой особенности записи, «всегда в новое место», механизм снепшотирования был легко интегрирован в WAFL, из-за чего такие снепшоты называют Redirect on Write (RoW). Подробнее про WAFL.
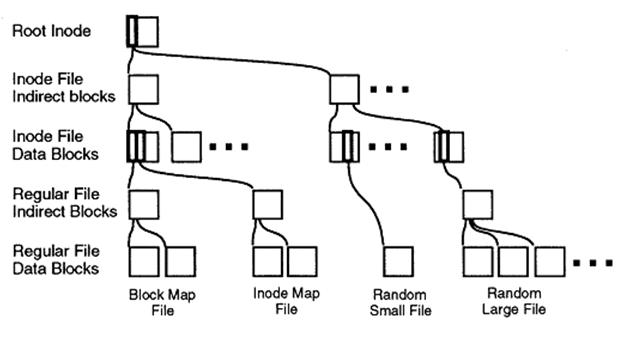
Внутреннее устройство WAFL
Благодаря тому, что снепшоты это копии инодов (ссылок) на блоки данных, а не самих данных, а система никогда не пишет в старое место, снепшоты в системах NetApp вообще не влияют на производительность WAFL.
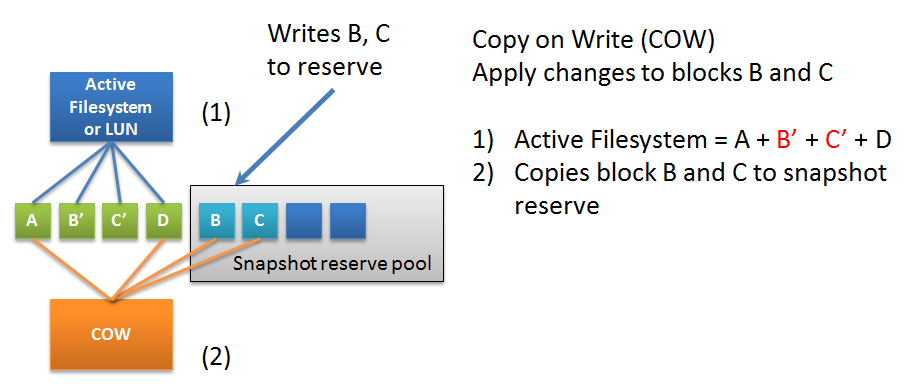
Спустя время функционал «локальных моментальных копий» оказался востребован другими производителями оборудования, так была изобретена технология снепшотирования COW. Отличие этой технологии заключается в основном в том, что все другие файловые системы и блочные устройства, как правило, не обладали встроенным механизмом записи «в новое место», т.е. старые блоки данных в момент их перезаписи реально перезаписываются: оригинальные данные затираются, а на их место записываются новые данные. И чтобы предотвратить повреждение снепшота после такой перезаписи предусматривается выделенная область для безопасного хранения снепшотов. Так в случае перезаписи блоков данных в файловой системе которые относятся к снепшоту, такой блок сначала копируется в зарезервированное для снепшотов пространство, а на их место записываются новые данные. Чем больше таких снепшотов тем больше дополнительных паразитических операций, тем больше нагрузка на файловую систему или блочное устройство, а как следствие всю дисковую подсистему и возможно, всю СХД.
В связи с чем у большинства производителей СХД и программного обеспечения как правило есть рекомендации иметь не более 1-5 снепшотов. А на высоконагруженных приложениях вообще рекомендуется не иметь снепшотов или удалять тот единственный необходимый для бекапа, сразу же как только он перестанет быть нужными.
Есть два подхода в резервном копироровании: «чисто софтверный» и «Hardware Assistant». Отличие между двумя заключается в том, на каком уровне будет выполнен снепшот: на уровне хоста (софтверный) или на уровне СХД (HW Assistant).
«Софтверные» снепшоты выполняются «на уровне хоста» и в момент копирования данных из снепшота, хост может испытывать нагрузку на дисковую подсистему, CPU и сетевые интерфейсы. Такие снепшоты как правило стараются выполнять во «внепиковые» часы. Cофтверные снепшоты также могут использовать стратегию COW, которая часто реализована на уровне файловой системы или некой файловой структуры, доступной для управления из ОС самого хоста. Примером тому могут быть ext3cow, BTRFS, VxFS, LVM, снепшоты VMware и др.
Снепшоты в СХД часто являются базовым функционалам для резервного копирования. И не смотря на недостаток COW, в применении с Hardware Assistant снепшотами на уровне СХД, с этим можно кое-как жить, нагружая только СХД, а не весь хост в момент выполнения резервной копии, а потом сразу же удалять снепшот чтобы тот не нагружал СХД.
Так вот. Все познаётся в сравнении.
Так как у NetApp нет проблем с производительностью из-за снепшотов, снепшоты стали основой для парадигмы резервного копирования для СХД серии FAS. Так как FAS системы могут хранить до 255 снепшотов на вольюм, мы можем восстанавливаться намного быстрее если наши данные находятся локально. Ведь очень удобно и быстро можно восстановиться если данные для восстановления находятся локально, а восстановление это не копирование данных, а всего-лишь перезапись указателей в «старое место». Стоит отметить, что у других производителей теоретически возможное количество снепшотов может достигать тысяч, но вчитавшись в документацию по эксплуатации можно удостовериться, что использовать COW снепшоты на высоконагруженных системах не рекомендуется.
Так в чём же отличие между подходами NetApp и остальными производителями, которые также используют снепшоты как основу для резервного копирования? NetApp в серьёз использует локальные снепшоты, как часть стратегии резервного копирования и восстановления, а также для репликации, в то время как остальные производители не могут себе этого позволить из-за накладных расходов в виде ухудшения производительности. Это вносит существенные изменения в архитектуру резервного копирования.

Снепшоты снятые «сами по себе» обеспечивают Crash Consistent восстановление, т.е. откатившись на такой когда-то снятый снепшот, эффект будет, как если бы вы нажали кнопку Reset на сервере с вашим приложением и загрузились. Для того, чтобы обеспечить Application Consistent Backup, необходимо взаимодействие СХД с приложением, чтобы оно должным образом подготовило данные перед снепшотом. Взаимодействие между СХД и приложением может быть обеспечено при помощи агентов установленных на тот же хост, где живет само приложение.

Существует целый ряд ПО для резервного копирования, которые умеют взаимодействовать с большим набором приложений (SAP, Oracle DB, ESXi, Hyper-V, MS SQL, Exchange, Sharepoint), поддерживающие HW Snapshoots на системах NetApp FAS:
Для обеспечения физической отказоустойчивости, существует множество механизмов понижающих вероятность выхода из строя локального бекапа — RIAD, дублирование компонент, дублирование путей и т.д. Почему бы не задействовать аппаратную отказоустойчивость которая уже присутствует? Другими словами снепшоты это бекапы защищающие от логической ошибки данных, от случайного удаления, порчи информации вирусом и т.д. Снепшоты не защиащают от физического выхода из строя самой СХД.
Для защиты от физического уничтожения (пожар, потоп, землетрясение, конфискация) данные всё-равно нужно резервировать на запасную площадку. Стандартный подход резервного копирования заключается в том, что полный объем данных будет передан на удалённую площадку. Чуть позже придумали сжимать эти данные. Стоит отметить что механизм компресии (и извлечения) данных требует значительных затрат ресурсов CPU. Потом передавать только инкременты, ещё чуть позже придумали обратные инкрементальные бекапы (чтобы не тратить время на сбор инкрементов в полный бекап в момент восстановления), а для надёжности переодически передавать полный набор данных.
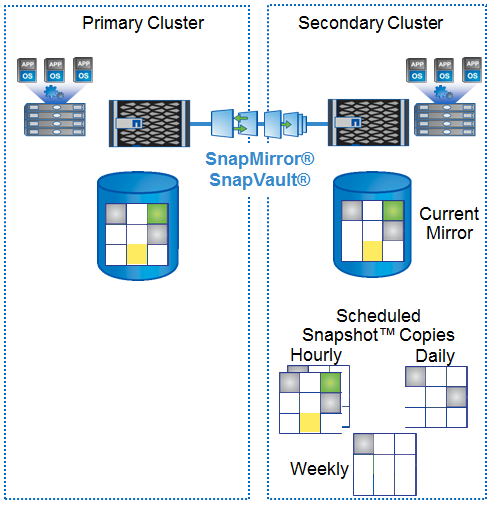
И здесь тоже приходят на помошь снепшоты. Их можно сравнить с обратными инкриментальными бекапами не требующими длительного времени на их создание. Так системы NetApp первый раз передают полный набор данных, а потом, всегда, только снепшот (инкремент) на удалённую систему, увеличивая скорость выполнения резервного копирования и восстановления. Попутно есть возможность включить сжатие передаваемыех данных.
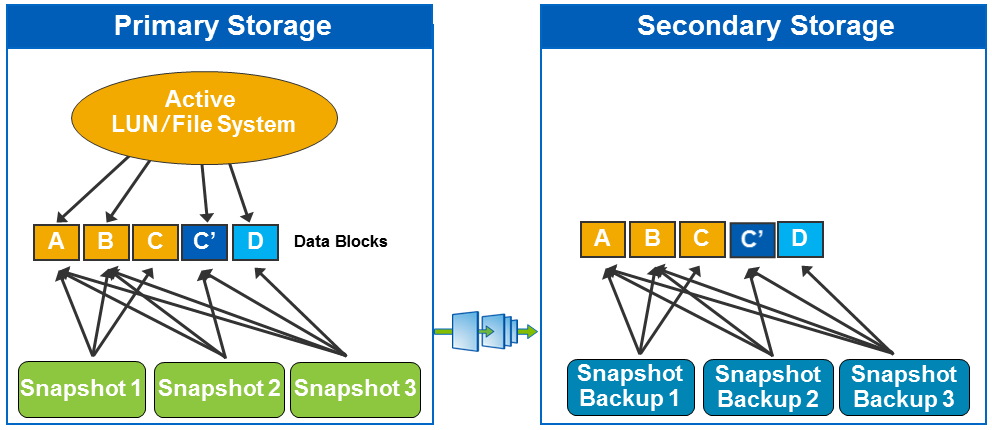
Использование одних и тех же данных для нескольких задач, таких тестирование резервных копий при помощи клонирования (и др.) начала набирать популярность и носит название Copy Data Management (CDM). На «не продуктивном» сайте из клона также удобно выполнять катологизацию, проверку бекапов, а также тестирование и разработку на базе тонких клонов зарезервированных данных.
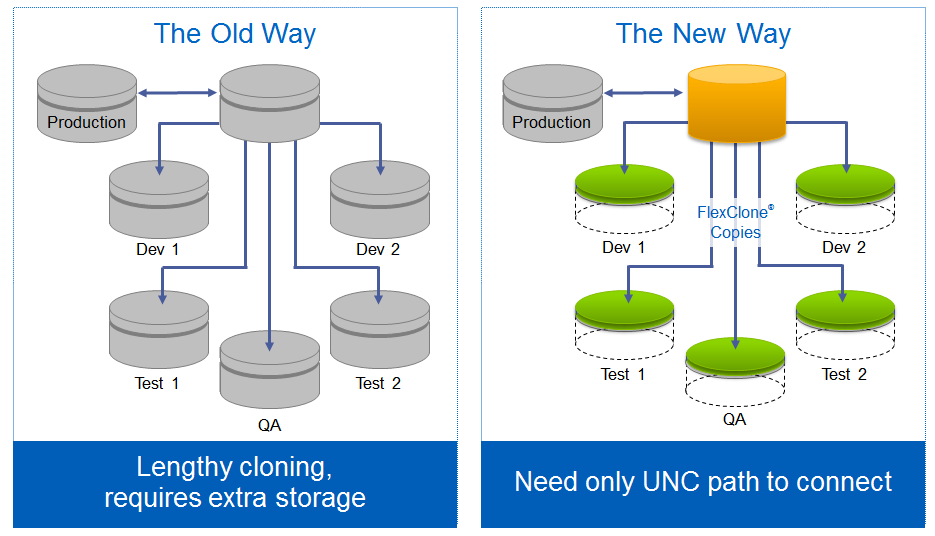
Таким образом парадигма резервного копирования в СХД NetApp FAS состоит из совокупностей подходов к:
Перечисленное позволяет не иметь проблем с производительностью, более быстро и консистентно снимать (уменьшить окно резервного копирования) и реплицировать данные (а как следствие иметь возможность снимать резервные копии чаще) без приостановки в обслуживании даже в рабочее время. Восстановление из удалённой площадки выполняется намного быстрее, при помощи снепшотов передавая только «разницу» между данными, а не полную копию. А локальные снепшоты в случае логического повреждения данных, позволяют уменьшить окно восстановления до пары секунд.

Сообщения по ошибкам в тексте прошу направлять в ЛС.
Замечания и дополнения напротив прошу в комментарии
Архитектура резервного копирования
WAFL
И начну я издали — со снепшотов. Технология снепшотов впервые была изобретена (и запатентирована) в 1993 году компанией NetApp, а само слово Snapshot является её торговой маркой. Технология снепшотирования логически проистекала из механизмов работы файловой структуры WAFL. Почему WAFL не файловая система смотрите здесь. Дело в том, что WAFL всегда пишет новые данные «в новое место» и просто переставляет указатель на содержимое новых данных в новое место, а старые данные не удаляются, эти блоки данных, на которые нет указателей, считаются высвобожденными для новых записей. Благодаря этой особенности записи, «всегда в новое место», механизм снепшотирования был легко интегрирован в WAFL, из-за чего такие снепшоты называют Redirect on Write (RoW). Подробнее про WAFL.
Внутреннее устройство WAFL
Snapshots
Благодаря тому, что снепшоты это копии инодов (ссылок) на блоки данных, а не самих данных, а система никогда не пишет в старое место, снепшоты в системах NetApp вообще не влияют на производительность WAFL.
COW
Спустя время функционал «локальных моментальных копий» оказался востребован другими производителями оборудования, так была изобретена технология снепшотирования COW. Отличие этой технологии заключается в основном в том, что все другие файловые системы и блочные устройства, как правило, не обладали встроенным механизмом записи «в новое место», т.е. старые блоки данных в момент их перезаписи реально перезаписываются: оригинальные данные затираются, а на их место записываются новые данные. И чтобы предотвратить повреждение снепшота после такой перезаписи предусматривается выделенная область для безопасного хранения снепшотов. Так в случае перезаписи блоков данных в файловой системе которые относятся к снепшоту, такой блок сначала копируется в зарезервированное для снепшотов пространство, а на их место записываются новые данные. Чем больше таких снепшотов тем больше дополнительных паразитических операций, тем больше нагрузка на файловую систему или блочное устройство, а как следствие всю дисковую подсистему и возможно, всю СХД.
В связи с чем у большинства производителей СХД и программного обеспечения как правило есть рекомендации иметь не более 1-5 снепшотов. А на высоконагруженных приложениях вообще рекомендуется не иметь снепшотов или удалять тот единственный необходимый для бекапа, сразу же как только он перестанет быть нужными.
Подходы к резервному копированию
Есть два подхода в резервном копироровании: «чисто софтверный» и «Hardware Assistant». Отличие между двумя заключается в том, на каком уровне будет выполнен снепшот: на уровне хоста (софтверный) или на уровне СХД (HW Assistant).
«Софтверные» снепшоты выполняются «на уровне хоста» и в момент копирования данных из снепшота, хост может испытывать нагрузку на дисковую подсистему, CPU и сетевые интерфейсы. Такие снепшоты как правило стараются выполнять во «внепиковые» часы. Cофтверные снепшоты также могут использовать стратегию COW, которая часто реализована на уровне файловой системы или некой файловой структуры, доступной для управления из ОС самого хоста. Примером тому могут быть ext3cow, BTRFS, VxFS, LVM, снепшоты VMware и др.
Снепшоты в СХД часто являются базовым функционалам для резервного копирования. И не смотря на недостаток COW, в применении с Hardware Assistant снепшотами на уровне СХД, с этим можно кое-как жить, нагружая только СХД, а не весь хост в момент выполнения резервной копии, а потом сразу же удалять снепшот чтобы тот не нагружал СХД.
Так вот. Все познаётся в сравнении.
Так как у NetApp нет проблем с производительностью из-за снепшотов, снепшоты стали основой для парадигмы резервного копирования для СХД серии FAS. Так как FAS системы могут хранить до 255 снепшотов на вольюм, мы можем восстанавливаться намного быстрее если наши данные находятся локально. Ведь очень удобно и быстро можно восстановиться если данные для восстановления находятся локально, а восстановление это не копирование данных, а всего-лишь перезапись указателей в «старое место». Стоит отметить, что у других производителей теоретически возможное количество снепшотов может достигать тысяч, но вчитавшись в документацию по эксплуатации можно удостовериться, что использовать COW снепшоты на высоконагруженных системах не рекомендуется.
Отличие в подходах
Так в чём же отличие между подходами NetApp и остальными производителями, которые также используют снепшоты как основу для резервного копирования? NetApp в серьёз использует локальные снепшоты, как часть стратегии резервного копирования и восстановления, а также для репликации, в то время как остальные производители не могут себе этого позволить из-за накладных расходов в виде ухудшения производительности. Это вносит существенные изменения в архитектуру резервного копирования.
Application & Crash Consistent Backups
Снепшоты снятые «сами по себе» обеспечивают Crash Consistent восстановление, т.е. откатившись на такой когда-то снятый снепшот, эффект будет, как если бы вы нажали кнопку Reset на сервере с вашим приложением и загрузились. Для того, чтобы обеспечить Application Consistent Backup, необходимо взаимодействие СХД с приложением, чтобы оно должным образом подготовило данные перед снепшотом. Взаимодействие между СХД и приложением может быть обеспечено при помощи агентов установленных на тот же хост, где живет само приложение.
Существует целый ряд ПО для резервного копирования, которые умеют взаимодействовать с большим набором приложений (SAP, Oracle DB, ESXi, Hyper-V, MS SQL, Exchange, Sharepoint), поддерживающие HW Snapshoots на системах NetApp FAS:
- Veeam Backup & Replication
- CommVault Simpana
- NetApp SnapManager/SnapCenter. О SnapManager for Oracle для SAN сети можно почтитать в соответствующей статье
- NetApp SnapProtect.
- NetApp SnapCreator (бесплатный фреймворк)
- Symantec NetBackup
- Symantec BackupExec
- SyncSort
- Acronis
Защита от катастрофы
Для обеспечения физической отказоустойчивости, существует множество механизмов понижающих вероятность выхода из строя локального бекапа — RIAD, дублирование компонент, дублирование путей и т.д. Почему бы не задействовать аппаратную отказоустойчивость которая уже присутствует? Другими словами снепшоты это бекапы защищающие от логической ошибки данных, от случайного удаления, порчи информации вирусом и т.д. Снепшоты не защиащают от физического выхода из строя самой СХД.
«Тонкая» репликация
Для защиты от физического уничтожения (пожар, потоп, землетрясение, конфискация) данные всё-равно нужно резервировать на запасную площадку. Стандартный подход резервного копирования заключается в том, что полный объем данных будет передан на удалённую площадку. Чуть позже придумали сжимать эти данные. Стоит отметить что механизм компресии (и извлечения) данных требует значительных затрат ресурсов CPU. Потом передавать только инкременты, ещё чуть позже придумали обратные инкрементальные бекапы (чтобы не тратить время на сбор инкрементов в полный бекап в момент восстановления), а для надёжности переодически передавать полный набор данных.
И здесь тоже приходят на помошь снепшоты. Их можно сравнить с обратными инкриментальными бекапами не требующими длительного времени на их создание. Так системы NetApp первый раз передают полный набор данных, а потом, всегда, только снепшот (инкремент) на удалённую систему, увеличивая скорость выполнения резервного копирования и восстановления. Попутно есть возможность включить сжатие передаваемыех данных.
Copy Data Management
Использование одних и тех же данных для нескольких задач, таких тестирование резервных копий при помощи клонирования (и др.) начала набирать популярность и носит название Copy Data Management (CDM). На «не продуктивном» сайте из клона также удобно выполнять катологизацию, проверку бекапов, а также тестирование и разработку на базе тонких клонов зарезервированных данных.
Парадигма резервного копирования
Таким образом парадигма резервного копирования в СХД NetApp FAS состоит из совокупностей подходов к:
- Снятию консистентных снепшотов длительно хранимых, как локально на той же СХД, так и удалённо
- «Тонкая репликация» для архивирования/резервного копирования и восстановления
- «Тонкое клонирование» для тестирования
Перечисленное позволяет не иметь проблем с производительностью, более быстро и консистентно снимать (уменьшить окно резервного копирования) и реплицировать данные (а как следствие иметь возможность снимать резервные копии чаще) без приостановки в обслуживании даже в рабочее время. Восстановление из удалённой площадки выполняется намного быстрее, при помощи снепшотов передавая только «разницу» между данными, а не полную копию. А локальные снепшоты в случае логического повреждения данных, позволяют уменьшить окно восстановления до пары секунд.
Сообщения по ошибкам в тексте прошу направлять в ЛС.
Замечания и дополнения напротив прошу в комментарии
