Немногим менее года назад была опубликована статья «Микропроцессор «из гаража»» и, возможно, сейчас наступил неплохой момент чтобы снова напомнить о проекте.
Пожалуй, главная новость это расширение системы команд, названное «Версия 1.1». Её отличие от предыдущей это расширенные возможности адресации. Но обо всём по порядку. Чтобы представить о чём идёт речь, взгляните на карту системы команд (картинка кликабельна):
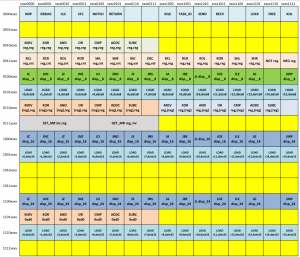
Прежде всего именно её хотелось вынести на ваш суд. При проектировании системы команд были определены два основных требования — хорошая расширяемость и высокая плотность кода. Желтым цветом на картинке помечены зарезервированные коды операций. Как видно из картинки, выполнить требования расширяемости нам удалось. Впрочем, желтые «клетки» это не единственная возможность для расширения — некоторый резерв заложен в неиспользованных битах у многобайтовых кодов операций. Помимо этого два префикса (NOTCH и KOL) могут расширять семантику кодов операций. Как видно из картинки, количество однобайтовых префиксов может быть безболезненно увеличено. Вот эти факторы позволяют заявить о выдающихся возможностях расширения. Но это ещё не всё. В настоящее время максимальная длина инструкции ограничена пятья байтами — этот размер был выбран исходя из возможностей нашей недорогой ПЛИС. Представьте, насколько можно расширить систему команд, если назначить коды операций в диапазоне с 0xf0 по 0xff для более длинных инструкций — шесть байт, семь… длина инструкции может быть ограничена лишь здравым смыслом. Итак, я надеюсь, что сомнений в возможностях расширения системы команд не возникло ни у кого, если они всё же есть — милости прошу обсудить их в комментариях.
А что же с плотностью кода? Да, Хабр суров и не любит выдуманных данных. По субъективным оценкам, текущая плотность кода может конкурировать по плотности кода с первыми версиями процессоров с архитектурой RISC. Например, если рассматривать самые первые версии ARM и MIPS, то, похоже, что версия 1.1 превосходит их по этому параметру. Что касается x86 и современных RISC, то благодаря богатству команд этих архитектур, плотность кода на них выше. Однако, если правильно эксплуатировать заложенные возможности расширения, то по праметру «Плотность кода» можно превзойти современные популярные архитектуры.
Я уверен что многим программистам, имеющим опыт написания на ассемблере x86, беглого взгляда на таблицу с инструкциями достаточно, чтобы заявить «Я умею писать на этом ассемблере». Не знаю, насколько названия ассемблерных мненмоник защищены патентами, но они по возможности выбраны совпадающими с x86. Отдельно хотелось бы сказать об инструкциях из дапазона 0xd0-0xd7. Это четырехбайтовые инструкции, второй байт которых определяет регистры общего назначения, а третий и четвёртый служат для расширенной адресации.
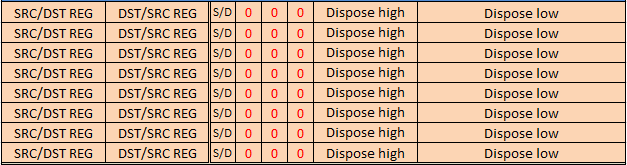
Бит S/D определяет какой из аргументов (четырехбитные коды регистров во втором байте) является указателем — первый или второй регистр. Три бита зарезервированы для дальнейших расширений и должны быть установлены в 0, оставшиеся биты определяют беззнаковое число, прибавляемое к указателю при косвенной адресации. Данные операции появились для упрощения работы со структурированными данными. Почитать об этом можно, например, вот здесь — everest.l4os.ru/aliases_for_registers
Что характерно, изначально код разрабатывался как полностью позиционно независимый и в системе команд вы не найдёте ни одной инструкции перехода по абсолютному адресу — ни условного, ни безусловного. Все адреса переходов представлены как смещения относительнос счётчика команд. Зачем? Это сделано чтобы на уровне архитектуры реализовать 100% позиционно независимый машинный код. Нужна константа? Выбирайте её по смещению относительно счётчика команд. Нужна статическая переменная, адресуйте относительно счётчика команд. Впрочем, детали реализации разных режимов адресации надёжно скрыты за макрокомандами ассемблера. Ответ на вопрос, как без абсолютной адресации вызывать системные функции — далее по тексту.
Собственно, всё вышесказанное относится к системе команд. Вероятно, вы оценили её, возможно с чем-то даже согласились, но… она опоздала лет на 20. Основные области применения микропроцессоров уже поделены между архитектурами x86, arm, mips и простыми микроконтоллерами. Расширяемость и плотность кода это самые последние вещи, на которые посмотрит разработчик устройства при выборе микропроцессора. Что же даёт надежду, на то что проект окажется интересным разработчикам? Раз уж речь идёт о системе команд, то присмотритесь к однобайтовым инструкциям IDLE, TASK_ID, SEND, RECV, LOCK, FREE.
Фишка процессора в том, что внутри него спрятана небольшая часть операционной системы, управляющая задачами и само понятие задача «зашито» в микропроцессоре. Новые инструкции как раз и служат для поддержки многозадачности. Инструкция IDLE выполняет безусловный вход в планировщик. Фактически ненужная инструкция, полезная лишь для отладки самого планировщика. Инструкция TASK_ID вернёт идентификатор активной задачи и количество тактов до следующей плановой операции распределения времени. Парные инструкции LOCK и FREE служат для захвата и освобождения буфера сообщения. В данном случае, несмотря на совпадение название инструкции LOCK с инструкцией x86, она выполняет совершенно другие функции. Поскольку процессор оперирует понятием задача, то нужны средства для взаимодействия задач. С помощью инструкции LOCK задача захватывает буфер сообщения, а с помощью инструкции FREE освободжает его. Буфер сообщения это 64 регистра, обмен с которыми происходит при помощи инструкций SET_MR (запись регистра сообщений значением из РОН) и GET_MR и (чтение регистра сообщений в РОН).
Конечно же самые важные инструкции, ради которых и затевался весь проект, это инструкции SEND и RECV — инструкции передачи и приёма сообщений. Эти инструкции имеют два аргумента — номер задачи для взаимодействия и таймаут операции (задаются в регистрах). Простейший способ отдать время задачи системе или реализовать задержку, это послать сообщение самой себе или ждать сообщение от себя — планировщик просто не будет передавать управление блокированной задаче ранее истечения таймаута сообщения.
Операции SEND и RECV синхронные — чтобы произошёл процесс передачи сообщения между задачами, одна из задач должна выполнить RECV, а другая SEND. В большинстве случаев это означает что первая задача, выполнившая одну из этих инструкций, заблокируется в ожидании готовности другой задачи. Если по какой-то причине блокировка нежелательна, то устанавливается нулевой таймаут и в случае неготовности одной из сторон, вместо блокировки задача получает статус, сигнализирующий о таймауте.
В момент передачи сообщения буфер сообщения, который ранее был захвачен инструкцией LOCK, коммутируется задаче принимающей сообщения. Задача, принявшая сообщение, после работы с буфером должна его освободить. Например, вызов библиотечной функции puts мог бы выглядеть так:
Этот код максимально упрощён для простоты понимания. В этом примере инструкция FREE освобождает буфер сообщений, полученный инструкцией RECV, поскольку буфер, захваченный инструкцией LOCK, делегирован задаче-приёмнику при передаче сообщения.
Несмотря на кажущуюся сложность и необычность решения, с точки зрения прикладного программиста ничего не меняется — библиотечные функции тщательно скрывают детали реализации. А вот системным программистам и разработчикам библиотек придётся постараться — начать придётся с того, что любое взаимодействие программ необходимо описать в виде протокола, описывающего формат запросов и ответов — сложный программный комплекс описывается как набор взаимодействующих субъектов, которые через взаимодействие решают определённые задачи.
Все эксперименты проводятся вот с этим чудом — платой Марсоход2:

Спасибо за внимание. Прежде всего хотелось бы обсудить систему команд, поскольку она уже работает в железе. Что касается аппаратных расширений для многозадачности, то они ещё не готовы — информация о поддержке многозадачности предоставлена в ознакомительных целях, а фактическая реализация может не соответствовать материалу в статье.
Пожалуй, главная новость это расширение системы команд, названное «Версия 1.1». Её отличие от предыдущей это расширенные возможности адресации. Но обо всём по порядку. Чтобы представить о чём идёт речь, взгляните на карту системы команд (картинка кликабельна):

Прежде всего именно её хотелось вынести на ваш суд. При проектировании системы команд были определены два основных требования — хорошая расширяемость и высокая плотность кода. Желтым цветом на картинке помечены зарезервированные коды операций. Как видно из картинки, выполнить требования расширяемости нам удалось. Впрочем, желтые «клетки» это не единственная возможность для расширения — некоторый резерв заложен в неиспользованных битах у многобайтовых кодов операций. Помимо этого два префикса (NOTCH и KOL) могут расширять семантику кодов операций. Как видно из картинки, количество однобайтовых префиксов может быть безболезненно увеличено. Вот эти факторы позволяют заявить о выдающихся возможностях расширения. Но это ещё не всё. В настоящее время максимальная длина инструкции ограничена пятья байтами — этот размер был выбран исходя из возможностей нашей недорогой ПЛИС. Представьте, насколько можно расширить систему команд, если назначить коды операций в диапазоне с 0xf0 по 0xff для более длинных инструкций — шесть байт, семь… длина инструкции может быть ограничена лишь здравым смыслом. Итак, я надеюсь, что сомнений в возможностях расширения системы команд не возникло ни у кого, если они всё же есть — милости прошу обсудить их в комментариях.
А что же с плотностью кода? Да, Хабр суров и не любит выдуманных данных. По субъективным оценкам, текущая плотность кода может конкурировать по плотности кода с первыми версиями процессоров с архитектурой RISC. Например, если рассматривать самые первые версии ARM и MIPS, то, похоже, что версия 1.1 превосходит их по этому параметру. Что касается x86 и современных RISC, то благодаря богатству команд этих архитектур, плотность кода на них выше. Однако, если правильно эксплуатировать заложенные возможности расширения, то по праметру «Плотность кода» можно превзойти современные популярные архитектуры.
Я уверен что многим программистам, имеющим опыт написания на ассемблере x86, беглого взгляда на таблицу с инструкциями достаточно, чтобы заявить «Я умею писать на этом ассемблере». Не знаю, насколько названия ассемблерных мненмоник защищены патентами, но они по возможности выбраны совпадающими с x86. Отдельно хотелось бы сказать об инструкциях из дапазона 0xd0-0xd7. Это четырехбайтовые инструкции, второй байт которых определяет регистры общего назначения, а третий и четвёртый служат для расширенной адресации.
Бит S/D определяет какой из аргументов (четырехбитные коды регистров во втором байте) является указателем — первый или второй регистр. Три бита зарезервированы для дальнейших расширений и должны быть установлены в 0, оставшиеся биты определяют беззнаковое число, прибавляемое к указателю при косвенной адресации. Данные операции появились для упрощения работы со структурированными данными. Почитать об этом можно, например, вот здесь — everest.l4os.ru/aliases_for_registers
Что характерно, изначально код разрабатывался как полностью позиционно независимый и в системе команд вы не найдёте ни одной инструкции перехода по абсолютному адресу — ни условного, ни безусловного. Все адреса переходов представлены как смещения относительнос счётчика команд. Зачем? Это сделано чтобы на уровне архитектуры реализовать 100% позиционно независимый машинный код. Нужна константа? Выбирайте её по смещению относительно счётчика команд. Нужна статическая переменная, адресуйте относительно счётчика команд. Впрочем, детали реализации разных режимов адресации надёжно скрыты за макрокомандами ассемблера. Ответ на вопрос, как без абсолютной адресации вызывать системные функции — далее по тексту.
Собственно, всё вышесказанное относится к системе команд. Вероятно, вы оценили её, возможно с чем-то даже согласились, но… она опоздала лет на 20. Основные области применения микропроцессоров уже поделены между архитектурами x86, arm, mips и простыми микроконтоллерами. Расширяемость и плотность кода это самые последние вещи, на которые посмотрит разработчик устройства при выборе микропроцессора. Что же даёт надежду, на то что проект окажется интересным разработчикам? Раз уж речь идёт о системе команд, то присмотритесь к однобайтовым инструкциям IDLE, TASK_ID, SEND, RECV, LOCK, FREE.
Фишка процессора в том, что внутри него спрятана небольшая часть операционной системы, управляющая задачами и само понятие задача «зашито» в микропроцессоре. Новые инструкции как раз и служат для поддержки многозадачности. Инструкция IDLE выполняет безусловный вход в планировщик. Фактически ненужная инструкция, полезная лишь для отладки самого планировщика. Инструкция TASK_ID вернёт идентификатор активной задачи и количество тактов до следующей плановой операции распределения времени. Парные инструкции LOCK и FREE служат для захвата и освобождения буфера сообщения. В данном случае, несмотря на совпадение название инструкции LOCK с инструкцией x86, она выполняет совершенно другие функции. Поскольку процессор оперирует понятием задача, то нужны средства для взаимодействия задач. С помощью инструкции LOCK задача захватывает буфер сообщения, а с помощью инструкции FREE освободжает его. Буфер сообщения это 64 регистра, обмен с которыми происходит при помощи инструкций SET_MR (запись регистра сообщений значением из РОН) и GET_MR и (чтение регистра сообщений в РОН).
Конечно же самые важные инструкции, ради которых и затевался весь проект, это инструкции SEND и RECV — инструкции передачи и приёма сообщений. Эти инструкции имеют два аргумента — номер задачи для взаимодействия и таймаут операции (задаются в регистрах). Простейший способ отдать время задачи системе или реализовать задержку, это послать сообщение самой себе или ждать сообщение от себя — планировщик просто не будет передавать управление блокированной задаче ранее истечения таймаута сообщения.
Операции SEND и RECV синхронные — чтобы произошёл процесс передачи сообщения между задачами, одна из задач должна выполнить RECV, а другая SEND. В большинстве случаев это означает что первая задача, выполнившая одну из этих инструкций, заблокируется в ожидании готовности другой задачи. Если по какой-то причине блокировка нежелательна, то устанавливается нулевой таймаут и в случае неготовности одной из сторон, вместо блокировки задача получает статус, сигнализирующий о таймауте.
В момент передачи сообщения буфер сообщения, который ранее был захвачен инструкцией LOCK, коммутируется задаче принимающей сообщения. Задача, принявшая сообщение, после работы с буфером должна его освободить. Например, вызов библиотечной функции puts мог бы выглядеть так:
LOCK ; Захват буфера сообщения SET_MR MR0, R2 ; установка идентификатора сообщения SET_MR MR1, R3 ; установка аргумента сообщения SEND ; передача сообщения RECV ; ожидание ответа на сообщение GET_MR R0, MR0 ; чтение кода возврата FREE ; освобождение буфера сообщения
Этот код максимально упрощён для простоты понимания. В этом примере инструкция FREE освобождает буфер сообщений, полученный инструкцией RECV, поскольку буфер, захваченный инструкцией LOCK, делегирован задаче-приёмнику при передаче сообщения.
Несмотря на кажущуюся сложность и необычность решения, с точки зрения прикладного программиста ничего не меняется — библиотечные функции тщательно скрывают детали реализации. А вот системным программистам и разработчикам библиотек придётся постараться — начать придётся с того, что любое взаимодействие программ необходимо описать в виде протокола, описывающего формат запросов и ответов — сложный программный комплекс описывается как набор взаимодействующих субъектов, которые через взаимодействие решают определённые задачи.
Все эксперименты проводятся вот с этим чудом — платой Марсоход2:
Спасибо за внимание. Прежде всего хотелось бы обсудить систему команд, поскольку она уже работает в железе. Что касается аппаратных расширений для многозадачности, то они ещё не готовы — информация о поддержке многозадачности предоставлена в ознакомительных целях, а фактическая реализация может не соответствовать материалу в статье.
