Привет, хабравчане! В этой статье я познакомлю вас с фреймворком Comedy — реализацией акторов в Node.JS. Акторы позволяют масштабировать отдельные модули вашего Node.JS приложения без изменения кода.
Об акторах
Хотя модель акторов довольно популярна сегодня, не все про неё знают. Несмотря на несколько устрашающую статью в Википедии, акторы — это очень просто.
Что такое актор? Это такая штука, которая умеет:
- принимать сообщения
- отправлять сообщения
- создавать дочерние акторы

Единственный способ что-либо сделать с актором — это отправить ему сообщение. Внутреннее состояние актора полностью изолировано от внешнего мира. Благодаря этому актор является универсальной единицей масштабирования приложения. А его способность порождать дочерние акторы позволяет сформировать понятную структуру модулей с чётким разделением обязанностей.
Понимаю, звучит несколько абстрактно. Чуть ниже мы разберём на конкретном живом примере, как происходит работа с акторами и Comedy. Но сперва...
Зачем это всё
… сперва мотивация.
Все, кто программируют на Node.JS (ваш покорный среди них) прекрасно знают, что Node.JS — однопоточный. С одной стороны, это хорошо, поскольку избавляет нас от целого класса очень стрёмных и трудновоспроизводимых багов — многопоточных багов. В наших приложениях таких багов быть принципиально не может, и это сильно удешевляет и ускоряет разработку.
С другой стороны, это ограничивает область применимости Node.JS. Он отлично подходит для network-intensive приложений с относительно небольшой вычислительной нагрузкой, а вот для CPU-intensive приложений подходит плохо, поскольку интенсивные вычисления блокируют наш драгоценный единственный поток, и всё встаёт колом. Мы это прекрасно знаем.
Знаем мы также и то, что любое реальное приложение какое-то количество CPU всё равно потребляет (даже если у нас совсем нет бизнес-логики, нам нужно обрабатывать сетевой трафик на уровне приложения — HTTP там, протоколы баз данных и прочее). И по мере роста нагрузки мы всё равно рано или поздно приходим к ситуации, когда наш единственный поток потребляет 100% мощности ядра. А что происходит в этом случае? Мы не успеваем обрабатывать сообщения, очередь задач накапливается, время отклика растёт, а потом бац! — out of memory.
И тут мы приходим к ситуации, когда нам нужно отмасштабировать наше приложение уже на несколько ядер CPU. И в идеале, мы не хотим себя ограничивать ядрами только на одной машине — нам может потребоваться несколько машин. И при этом мы хотим как можно меньше переписывать наше приложение. Здорово, если приложение будет масштабироваться простым изменением конфигурации. А ещё лучше — автоматически, в зависимости от нагрузки.
И вот тут нам на помощь приходят акторы.
Практический пример: сервис простых чисел
Для того, чтобы продемонстрировать, как работает Comedy, я набросал небольшой пример: микросервис, который находит простые числа. Доступ к сервису осуществляется через REST API.
Конечно, поиск простых чисел — это в чистом виде CPU-intensive задача. Если бы мы в реальной жизни проектировали такой сервис, нам бы стоило десять раз подумать, прежде чем выбрать Node.JS. Но в данном случае, мы как раз намеренно выбрали вычислительную задачу, чтобы было проще воспроизвести ситуацию, когда одного ядра не хватает.
Итак. Давайте начнём с самой сути нашего сервиса — реализуем актор, находящий простые числа. Вот его код:
/** * Actor that finds prime numbers. */ class PrimeFinderActor { /** * Finds next prime, starting from a given number (not inclusive). * * @param {Number} n Positive number to start from. * @returns {Number} Prime number next to n. */ nextPrime(n) { if (n < 1) throw new Error('Illegal input'); const n0 = n + 1; if (this._isPrime(n0)) return n0; return this.nextPrime(n0); } /** * Checks if a given number is prime. * * @param {Number} x Number to check. * @returns {Boolean} True if number is prime, false otherwise. * @private */ _isPrime(x) { for (let i = 2; i < x; i++) { if (x % i === 0) return false; } return true; } }
Метод nextPrime() находит простое число, следующее за указанным (не обязательно простым). В методе используется хвостовая рекурсия, которая точно поддерживается в Node.JS 8 (для запуска примера нужно будет взять Node.JS не ниже 8 версии, поскольку там ещё async-await будет). В методе используется вспомогательный метод _isPrime(), проверяющий число на простоту. Это не самый оптимальный алгоритм подобной проверки, но для нашего примера это только лучше.
То, что мы видим в коде выше, с одной стороны — обычный класс. С другой стороны, для нас, это, так называемое, определение актора, то есть описание поведения актора. Класс описывает, какие сообщения актор может принимать (каждый метод — обработчик сообщения с одноимённым топиком), что он делает, приняв эти сообщения (реализация метода) и какой выдаёт результат (возвращаемое значение).
При этом, поскольку это обычный класс, мы можем написать на него unit-тест и легко протестировать корректность его реализации.
describe('PrimeFinderActor', () => { it('should correctly find next prime', () => { const pf = new PrimeFinderActor(); expect(pf.nextPrime(1)).to.be.equal(2); expect(pf.nextPrime(2)).to.be.equal(3); expect(pf.nextPrime(3)).to.be.equal(5); expect(pf.nextPrime(30)).to.be.equal(31); }); it('should only accept positive numbers', () => { const pf = new PrimeFinderActor(); expect(() => pf.nextPrime(0)).to.throw(); expect(() => pf.nextPrime(-1)).to.throw(); }); });
Теперь у нас есть актор-искатель простых чисел.
Наш следующий шаг — реализовать актор REST-сервера. Вот как будет выглядеть его определение:
const restify = require('restify'); const restifyErrors = require('restify-errors'); const P = require('bluebird'); /** * Prime numbers REST server actor. */ class RestServerActor { /** * Actor initialization hook. * * @param {Actor} selfActor Self actor instance. * @returns {Promise} Initialization promise. */ async initialize(selfActor) { this.log = selfActor.getLog(); this.primeFinder = await selfActor.createChild(PrimeFinderActor); return this._initializeServer(); } /** * Initializes REST server. * * @returns {Promise} Initialization promise. * @private */ _initializeServer() { const server = restify.createServer({ name: 'prime-finder' }); // Set 10 minutes response timeout. server.server.setTimeout(60000 * 10); // Define REST method for prime number search. server.get('/next-prime/:n', (req, res, next) => { this.log.info(`Handling next-prime request for number ${req.params.n}`); this.primeFinder.sendAndReceive('nextPrime', parseInt(req.params.n)) .then(result => { this.log.info(`Handled next-prime request for number ${req.params.n}, result: ${result}`); res.header('Content-Type', 'text/plain'); res.send(200, result.toString()); }) .catch(err => { this.log.error(`Failed to handle next-prime request for number ${req.params.n}`, err); next(new restifyErrors.InternalError(err)); }); }); return P.fromCallback(cb => { server.listen(8080, cb); }); } }
Что в нём происходит? Главное и единственное — в нём есть метод initialize(). Этот метод будет вызван Comedy при инициализации актора. В него передаётся экземпляр актора. Это та самая штука, в которую можно передавать сообщения. У экземпляра есть ещё ряд полезных методов. getLog() возвращает логгер для актора (он нам пригодится), а с помощью метода createChild() мы создаём дочерний актор — тот самый PrimeFinderActor, который мы реализовали в самом начале. В createChild() мы передаём определение актора, а получаем в ответ промис, который разрешится, как только дочерний актор будет проинициализирован, и выдаст нам экземпляр созданного дочернего актора.
Как вы заметили, инициализация актора — асинхронная операция. Наш метод initialize() тоже асинхронный (он возвращает промис). Соответственно, наш RestServerActor будет считаться инициализированным только тогда, когда зарезолвится промис (ну не писать же "выполнится обещание"), отданный методом initialize().
Окей, мы создали дочерний PrimeFinderActor, дождались его инициализации и присвоили ссылку на экземпляр полю primeFinder. Осталась мелочёвка — сконфигурировать REST-сервер. Мы это делаем в методе _initializeServer() (он тоже асинхронный), используя библиотеку Restify.
Мы создаём один-единственный обработчик запроса ("ручку") — для метода GET /next-prime/:n, который вычисляет следующее за указанным целое число, отправляя сообщение дочернему PrimeFinderActor актору и получая от него ответ. Сообщение мы отправляем с помощью метода sendAndReceive(), первым параметром идёт название топика (nextPrime, по имени метода) следующим параметром — сообщение. В данном случае сообщением является просто число, но там может быть и строка, и объект с данными, и массив. Метод sendAndReceive() асинхронный, возвращает промис с результатом.
Почти готово. Нам осталась ещё одна мелочь: запустить всё это. Мы добавляем в наш пример ещё пару строк:
const actors = require('comedy'); actors({ root: RestServerActor });
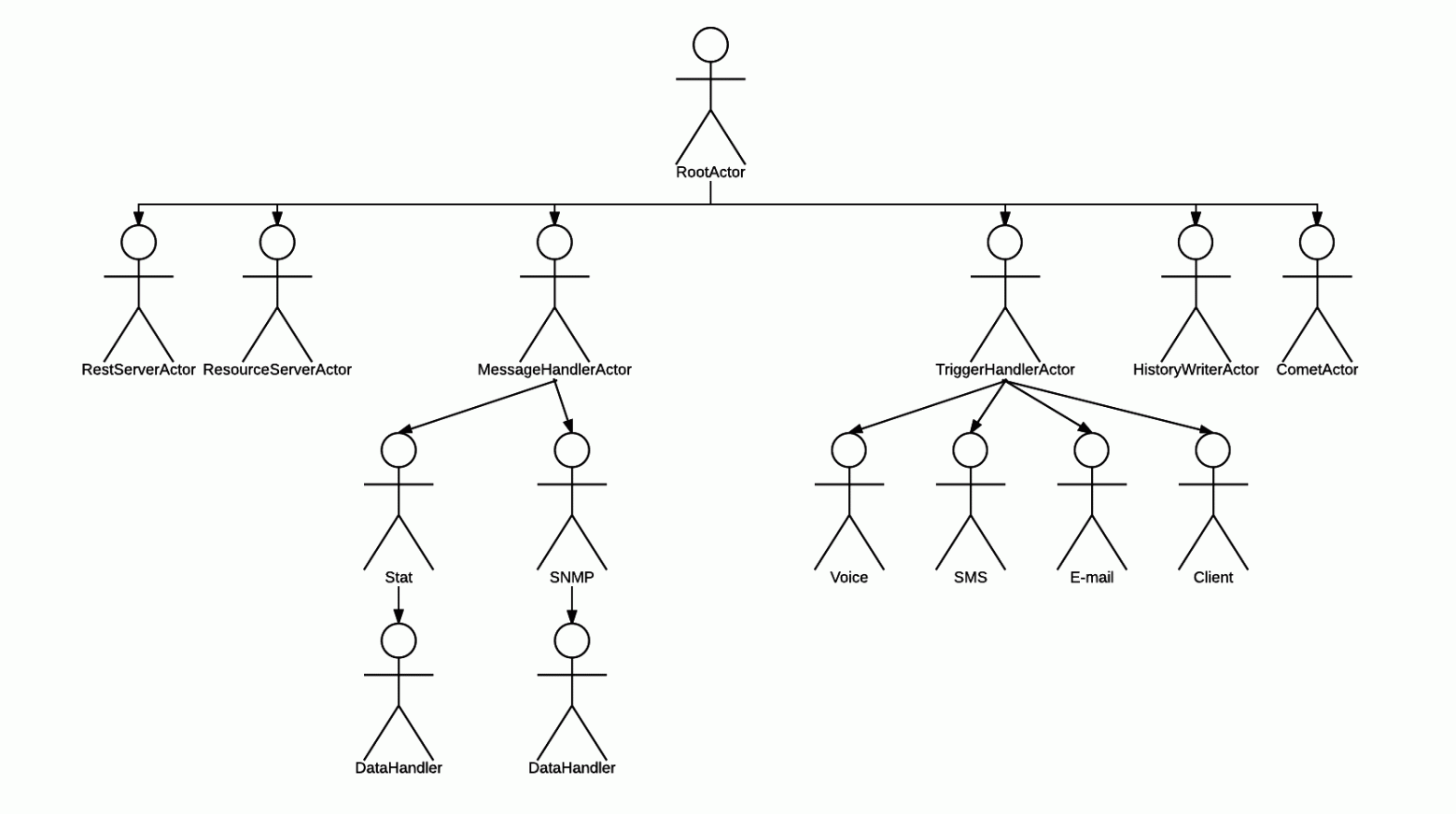
Здесь мы создаём систему акторов. В качестве параметров мы указываем определение корневого (самого родительского) актора. Им у нас является RestServerActor.
Получается вот такая иерархия:

С иерархией нам повезло, она довольно простая!
Ну что, запускаем приложение и тестируем?
$ nodejs prime-finder.js Mon Aug 07 2017 15:34:37 GMT+0300 (MSK) - info: Resulting actor configuration: {}
$ curl http://localhost:8080/next-prime/30; echo 31
Работает! Давайте ещё поэкспериментируем:
$ time curl http://localhost:8080/next-prime/30 31 real 0m0.015s user 0m0.004s sys 0m0.000s $ time curl http://localhost:8080/next-prime/3000000 3000017 real 0m0.045s user 0m0.008s sys 0m0.000s $ time curl http://localhost:8080/next-prime/300000000 300000007 real 0m2.395s user 0m0.004s sys 0m0.004s $ time curl http://localhost:8080/next-prime/3000000000 3000000019 real 5m11.817s user 0m0.016s sys 0m0.000s
По мере возрастания стартового числа время обработки запроса растёт. Особенно впечатляет переход с трёхсот миллионов до трёх миллиардов. Давайте попробуем параллельные запросы:
$ curl http://localhost:8080/next-prime/3000000000 & [1] 32440 $ curl http://localhost:8080/next-prime/3000000000 & [2] 32442
В top-е видим, что одно ядро полностью занято.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 32401 weekens 20 0 955664 55588 20956 R 100,0 0,7 1:45.19 node
В логе сервера видим:
Mon Aug 07 2017 16:05:45 GMT+0300 (MSK) - info: InMemoryActor(5988659a897e307e91fbc2a5, RestServerActor): Handling next-prime request for number 3000000000
То есть первый запрос выполняется, а второй просто ждёт.
$ jobs [1]- Выполняется curl http://localhost:8080/next-prime/3000000000 & [2]+ Выполняется curl http://localhost:8080/next-prime/3000000000 &
Это в точности та ситуация, которая и была описана: нам не хватает одного ядра. Нам нужно больше ядер!
Showtime!
Итак, настало время мастшабироваться. Все наши дальнейшие действия не потребуют модификации кода.
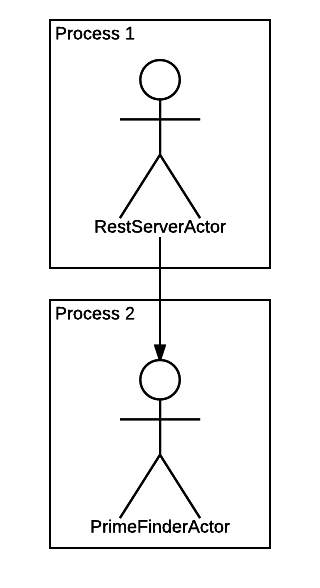
Давайте вначале выделим PrimeFinderActor в отдельный подпроцесс. Само по себе это действие довольно бесполезно, но хочется вводить вас в курс дела постепенно.
Мы создаём в корневой директории проекта файл actors.json вот с таким содержимым:
{ "PrimeFinderActor": { "mode": "forked" } }
И перезапускаем пример. Что произошло? Смотрим в список процессов:
$ ps ax | grep nodejs 12917 pts/19 Sl+ 0:00 nodejs prime-finder.js 12927 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor $ pstree -a -p 12917 nodejs,12917 prime-finder.js ├─nodejs,12927 /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor │ ├─{V8 WorkerThread},12928 │ ├─{V8 WorkerThread},12929 │ ├─{V8 WorkerThread},12930 │ ├─{V8 WorkerThread},12931 │ └─{nodejs},12932 ├─{V8 WorkerThread},12918 ├─{V8 WorkerThread},12919 ├─{V8 WorkerThread},12920 ├─{V8 WorkerThread},12921 ├─{nodejs},12922 ├─{nodejs},12923 ├─{nodejs},12924 ├─{nodejs},12925 └─{nodejs},12926
Мы видим, что процессов теперь два. Один — наш главный, "пусковой" процесс. Второй — дочерний процесс, в котором теперь крутится PrimeFinderActor, поскольку он теперь работает в режиме "forked". Мы это сконфигурировали с помощью файла actors.json, ничего не меняя в коде.
Получилась вот такая картина:
Запускаем тест снова:
$ curl http://localhost:8080/next-prime/3000000000 & [1] 13240 $ curl http://localhost:8080/next-prime/3000000000 & [2] 13242
Смотрим лог:
Tue Aug 08 2017 08:54:41 GMT+0300 (MSK) - info: InMemoryActor(5989504694b4a23275ba5d29, RestServerActor): Handling next-prime request for number 3000000000 Tue Aug 08 2017 08:54:43 GMT+0300 (MSK) - info: InMemoryActor(5989504694b4a23275ba5d29, RestServerActor): Handling next-prime request for number 3000000000
Хорошая новость: всё по-прежнему работает. Плохая новость: всё работает, почти как и раньше. Ядро по-прежнему не справляется, и запросы встают в очередь. Только теперь ядро нагружено нашим дочерним процессом (обратите внимание на PID):
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 12927 weekens 20 0 907160 40892 20816 R 100,0 0,5 0:20.05 nodejs
Давайте сделаем больше процессов: кластеризуем PrimeFinderActor до 4-х экземпляров. Меняем actors.json:
{ "PrimeFinderActor": { "mode": "forked", "clusterSize": 4 } }
Перезапускаем сервис. Что видим?
$ ps ax | grep nodejs 15943 pts/19 Sl+ 0:01 nodejs prime-finder.js 15953 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor 15958 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor 15963 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor 15968 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor
Дочерних процессов стало 4. Всё как мы и хотели. Простым изменением конфигурации мы поменяли иерархию, которая теперь выглядит так:
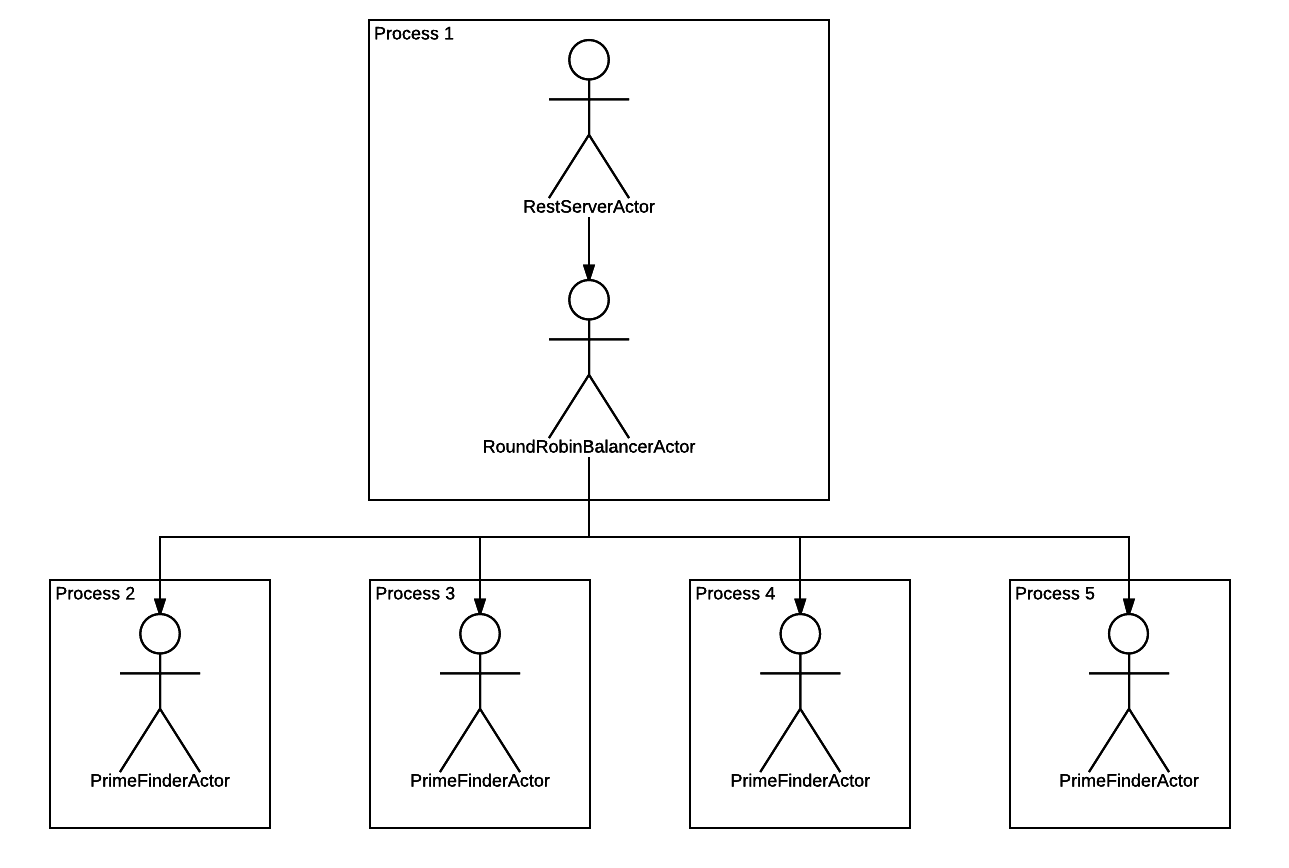
То есть Comedy размножил PrimeFinderActor до количества 4-х штук, каждый запустил в отдельном процессе, и между этими акторами и родительским RestServerActor-ом воткнул промежуточный актор, который будет раскидывать запросы по дочерним акторам раунд-робином.
Запускаем тест:
$ curl http://localhost:8080/next-prime/3000000000 & [1] 20076 $ curl http://localhost:8080/next-prime/3000000000 & [2] 20078
И видим, что теперь занято два ядра:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 15953 weekens 20 0 909096 38336 20980 R 100,0 0,5 0:13.52 nodejs 15958 weekens 20 0 909004 38200 21044 R 100,0 0,5 0:12.75 nodejs
В логе приложения видим два параллельно обрабатывающихся запроса:
Tue Aug 08 2017 11:51:51 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handling next-prime request for number 3000000000 Tue Aug 08 2017 11:51:52 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handling next-prime request for number 3000000000 Tue Aug 08 2017 11:57:24 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handled next-prime request for number 3000000000, result: 3000000019 Tue Aug 08 2017 11:57:24 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handled next-prime request for number 3000000000, result: 3000000019
Масштабирование работает!
Ещё больше ядер!
Наш сервис сейчас может обрабатывать параллельно 4 запроса на нахождение простого числа. Остальные запросы встают в очередь. На моей машине всего 4 ядра. Если я хочу обрабатывать больше параллельных запросов, мне надо масштабироваться на соседние машины. Давайте сделаем это!
Вначале немного теории. В прошлом примере мы перевели PrimeFinderActor в режим "forked". Каждый актор может находиться в одном из трёх режимов:
"in-memory"(по-умолчанию): актор работает в том же процессе, что и создавший его код. Отправка сообщений такому актору сводится к вызову его методов. Накладные расходы на коммуникацию с"in-memory"актором нулевые (или близкие к нулевым);"forked": актор запускается в отдельном процессе на той же машине, где работает создавший его код. Коммуникация с актором осуществляется через IPC (Unix pipes в Unix-е, named pipes в Windows)."remote": актор запускается в отдельном процессе на удалённой машине. Коммуникация с актором осуществляется через TCP/IP.
Как вы поняли, теперь нам нужно перевести PrimeFinderActor из "forked" режима в "remote". Мы хотим получить такую схему:

Давайте отредактируем файл actors.json. Просто указать режим "remote" в данном случае недостаточно: нужно ещё указать хост, на котором мы хотим запустить актор. У меня есть по соседству машинка с адресом 192.168.1.101. Её я и использую:
{ "PrimeFinderActor": { "mode": "remote", "host": "192.168.1.101", "clusterSize": 4 } }
Только вот беда: эта самая соседняя машинка не знает ничего про Comedy. Нам нужно запустить на ней специальный процесс слушатель на известном порту. Делается это так:
$ ssh weekens@192.168.1.101 ... weekens@192.168.1.101 $ mkdir comedy weekens@192.168.1.101 $ cd comedy weekens@192.168.1.101 $ npm install comedy ... weekens@192.168.1.101 $ node_modules/.bin/comedy-node Thu Aug 10 2017 19:29:51 GMT+0300 (MSK) - info: Listening on :::6161
Теперь процесс-слушатель готов принимать запросы на создание акторов по известному порту 6161. Пробуем:
$ nodejs prime-finder.js
$ curl http://localhost:8080/next-prime/3000000000 & $ curl http://localhost:8080/next-prime/3000000000 &
Смотрим top на локальной машине. Никакой активности (если не считать Chromium):
$ top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 25247 weekens 20 0 1978768 167464 51652 S 13,6 2,2 32:34.70 chromium-browse
Смотрим на удалённой машине:
weekens@192.168.1.101 $ top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 27956 weekens 20 0 908612 40764 21072 R 100,1 0,1 0:14.97 nodejs 27961 weekens 20 0 908612 40724 21020 R 100,1 0,1 0:11.59 nodejs
Идёт вычисление целых чисел, всё как мы и хотели.
Остался лишь один маленький штрих: использовать ядра и на локальной, и на удалённой машине. Это очень просто: мы указываем в actors.json не один хост, а несколько:
{ "PrimeFinderActor": { "mode": "remote", "host": ["127.0.0.1", "192.168.1.101"], "clusterSize": 4 } }
Comedy распределит акторы равномерно между указанными хостами и будет раздавать им сообщения round robin-ом. Давайте проверим.
Сперва запустим процесс слушатель дополнительно на локальной машине:
$ node_modules/.bin/comedy-node Fri Aug 11 2017 15:37:26 GMT+0300 (MSK) - info: Listening on :::6161
Теперь запустим пример:
$ nodejs prime-finder.js
Посмотрим список процессов на локальной машине:
$ ps ax | grep nodejs 22869 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor 22874 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor
И на удалённой машине:
192.168.1.101 $ ps ax | grep node 5925 pts/4 Sl+ 0:00 /usr/bin/nodejs /home/weekens/comedy/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor 5930 pts/4 Sl+ 0:00 /usr/bin/nodejs /home/weekens/comedy/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor
По два на каждой, как и хотели (понадобится больше — увеличим clusterSize). Отправляем запросы:
$ curl http://localhost:8080/next-prime/3000000000 & [1] 23000 $ curl http://localhost:8080/next-prime/3000000000 & [2] 23002
Смотрим загрузку на локальной машине:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 22869 weekens 20 0 908080 40344 21724 R 106,7 0,5 0:07.40 nodejs
Смотрим загрузку на удалённой машине:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 5925 weekens 20 0 909000 40912 21044 R 100,2 0,1 0:14.17 nodejs
Загружено по одному ядру на каждой машине. То есть мы теперь распределяем нагрузку равномерно по обеим машинам. Заметьте, мы добились этого, не поменяв ни одной строчки кода. И нам помог в этом Comedy и модель акторов.
Заключение
Мы рассмотрели пример гибкого масштабирования приложения с помощью модели акторов и её реализации в Node.JS — Comedy. Алгоритм наших действий выглядел следующим образом:
- Описать наше приложение в терминах акторов.
- Сконфигурировать акторы таким образом, чтобы равномерно распределить нагрузку по множеству доступных нам ядер CPU.
Как описывать приложение в терминах акторов? Это аналог вопроса "Как описать приложение в терминах объектов и классов?". Программирование на акторах очень похоже на ООП. Можно сказать, что это ООП++. В ООП есть различные устоявшиеся и успешные паттерны проектирования. Аналогичным образом, и для модели акторов есть свои паттерны. Вот книга по ним. Эти паттерны можно использовать, и они вам наверняка помогут, но, если вы уже владеете ООП, у вас точно не будет с акторами проблем.
Что если ваше приложение уже написано? Нужно ли "переписывать его на акторы"? Конечно, модификация кода в этом случае потребуется. Но не обязательно делать масштабный рефакторинг. Можно выделить несколько основных, "крупных" акторов, и после этого вы уже можете масштабироваться. "Крупные" акторы можно со временем раздробить на более мелкие. Опять же, если ваше приложение уже описано в терминах ООП, переход на акторы будет, скорее всего, безболезненным. Единственный момент, с которым, возможно, придётся поработать: акторы полностью изолированы друг от друга, в отличие от простых объектов.
Насчёт зрелости фреймворка. Первая рабочая версия Comedy была разработана внутри проекта SAYMON в июне 2016 года. Фреймворк с самой первой версии работал в продакшене в боевых условиях. В апреле 2017 года библиотека была выпущена в Open Source под Eclipse Public License. Comedy при этом продолжает быть частью SAYMON и используется для масштабирования системы и обеспечения её отказоустойчивости.
Список планируемых фич здесь.
В этой статье я не упомянул о целом ряде функциональных возможностей Comedy: о fault tolerance ("respawn" акторов), об инъекции ресурсов в акторы, об именованных кластерах, о маршаллинге пользовательских классов, о поддержке TypeScript. Но большую часть вышеперечисленного вы найдёте в документации, а то, что в ней ещё не описано — в тестах и примерах. Плюс, возможно, я напишу ещё статьи о Comedy и акторах в Node.JS, если тема пойдёт в массы.
Используйте Comedy! Создавайте issues! Жду ваших комментариев!

