В данном учебнике даются предельно простые и понятные ответы на следующие вопросы:
А начнём мы, пожалуй, с такой картинки:
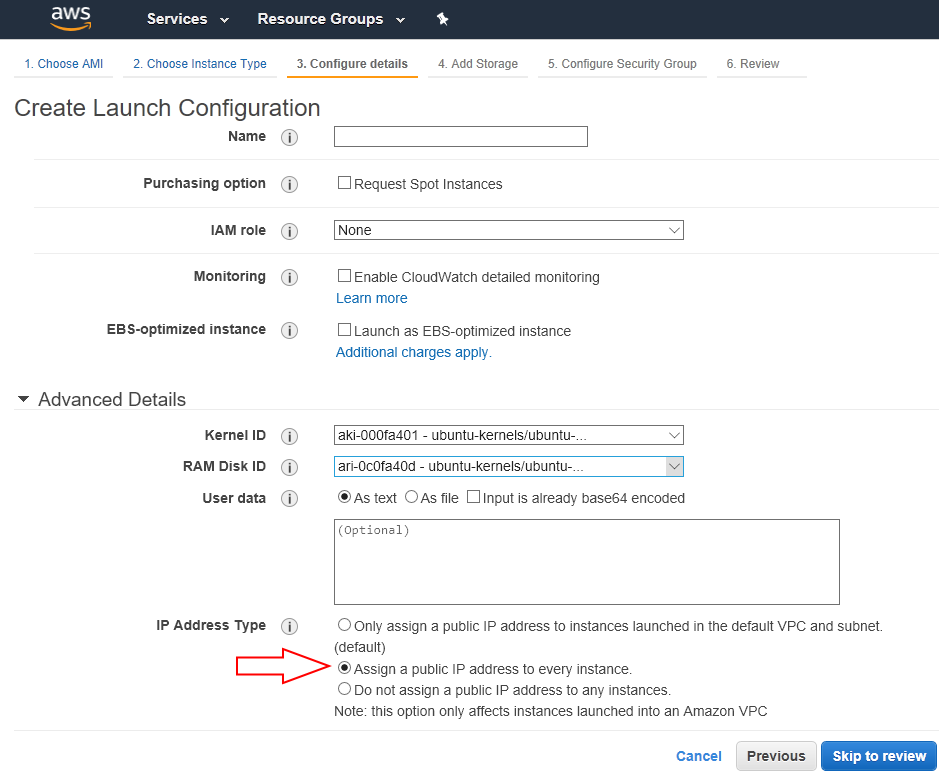
Когда запускаешь свой сервис на Амазоне, обычно это происходит так:
а) настраиваешь какую-то виртуальную машину,
б) устанавливаешь на неё свой сервис,
в) проверяешь, что всё работает, а потом
г) делаешь из неё AMI — полный слепок, образ твоего сервиса вместе с операционной системой и всем прочим, что там есть.
Он сохраняется в облаке, а затем при необходимости очень легко и просто (и, главное, автоматически) тиражируется в любом разумном масштабе с автоматической же донастройкой. На скриншоте как раз приведён интерфейс, в котором задаются некоторые дополнительные настройки для запуска множества экземпляров заранее сконфигурированного слепка.
Стрелочкой отмечена опция «Автоматически назначить внешние IP-адреса для каждого экземпляра».
Так вот. Когда запускаешь свой сервис в большом масштабе, Амазону можно указать, чтобы при определённой нагрузке на процессор виртуальной машины он разворачивал рядом ещё один экземпляр твоего сервиса. Или, например, сразу сто штук. Или не при нагрузке на процессор, а, допустим, при паре сотен одновременно активных сетевых соединений. Таких метрик для автоматического масштабирования очень много, и правила для автозапуска можно настроить тоже довольно гибко.
Посмотрим теперь на такой вот график:

Это аппроксимированное количество одновременно активных пользователей всемирных интернет-сервисов в рабочее время. В Тихом океане почти никто не живёт, в Китае интернет свой собственный, а наибольшее количество пользователей приходится на Европу, и — в особенности — запад США. Это верно почти для любого сервиса со всемирным охватом, хоть Стима, хоть Нетфликса, хоть Википедии, хоть Телеграма.
Как мы видим, разница между максимумом и минимумом раза в полтора. Буквально это значит, что если ты работаешь на весь мир, то примерно половину суток, пока в Западном полушарии день, тебе надо чуть ли не вдвое больше мощностей, чем другую половину суток, когда день в Азии. Вот и настраиваешь себе соответствующие правила автоматического масштабирования, чтобы не тратить процессорное время (и свои деньги — в облаках как нигде время=деньги) понапрасну в то время, когда оно не нужно.
И половина экземпляров твоего сервиса просто убивается самим облаком по расписанию, когда Америка ложится спать. А на следующий день при росте нагрузки оно услужливо тебе их снова поднимет.
Теперь ответим на вопрос 3). Стрелочка на скриншоте не просто так нарисована. Опция «Автоматически назначить внешние IP-адреса для каждого экземпляра» берёт адреса из доступного пула адресов — Амазону принадлежит несколько миллионов, и ещё несколько он арендует у других владельцев. Публичный IPv4-адрес штука ныне дефицитная, поэтому иметь для каждого виртуального экземпляра таковой на постоянной основе, работает он сейчас или нет, большая роскошь — и стоит денег (более того, в любом дата-центре Амазона постоянных адресов тебе дают всего 5 штук, и увеличивают этот лимит ну с очень большим скрипом).
И как только какой-то экземпляр убивается, адрес сразу же возвращается снова в общий пул. И так далее. Кому он попадёт в следующий раз? Да кому угодно. Может быть, тебе, а может быть другому клиенту, который тоже автоматически масштабирует свой сервис, а может и эфемерному экземпляру сервиса самого Амазона. Таким образом, ответ на вопрос 3) тривиален: потому что сегодня этот IP-шник твой, а через пару часов чей-то ещё. Если твой сервис кому-то неугоден, но автоматически масштабируется, то забанить его по IP можно, но только если запретить весь пул.
И на вопрос 2) ответ тоже тривиален: нисколько не стоит. Облако само назначит следующему экземпляру какой-то другой адрес из доступного ему пула, хочешь ты этого или нет.
Теперь про первый вопрос.
Ответ не так очевиден, но попробуем сделать то, что называется educated guess (не знаю, как это лучше сказать по-русски, «предположение на основании опыта», наверное?).
Амазон — это самое старое из больших облаков. Программная обвязка, которая занимается всеми этими автоматическими масштабированиями, написана ещё лет десять назад, и с тех пор работает как часы. Сам гигантский сервис Амазона работает ровно в том же самом облаке. Обвязка эта не сломана, её не надо чинить, а любые изменения, которые пишут люди, имеют риск внесения ошибок. Поэтому фича по изоляции пулов адресов под клиента, если начать её разрабатывать прямо сейчас, займёт до чёртиков времени, и если вдруг приведёт к большим изменениям, то цена возможных последствий будет исчисляться миллиардами долларов. В самом прямом смысле.
И ответ на 1) звучит так: Для Амазона попросту невыгодно переделывать свою инфраструктуру под требования спятившего надзорного органа государства, все клиенты из которого не приносят столько денег, чтобы скомпенсировать возможный риск для самого себя и клиентов из других стран. Звучит жёстко, но это, к сожалению, бизнес.
Кстати, с остальными облаками всё ровно то же самое. Ютюб оказался забаненым потому, что сервисы самого Гугля не отделены от сервисов клиентов Гугля, и работают в том же облачном пространстве с единым пулом адресов. И с сервисами Майкрософта аналогично.
Роскомнадзор, блокируя облачные сервисы, воюет с технологией, на которой строятся облака. Со скриптами. С алгоритмами. Это всё равно что воевать против законов физики, или пытаться дать пинка стихии: предельно глупо и бессмысленно. Невозможно победить облака и ветер, можно только уйти под землю, чтобы их никогда не видеть…
- Почему Амазон не идёт на сотрудничество с Роскомнадзором?
- Сколько стоит постоянный перенос серверов Телеграма на другие IP-адреса внутри облака?
- Почему невозможно банить сервисы, хостящиеся на Амазоне, конкретными IP, а не подсетями сразу?
А начнём мы, пожалуй, с такой картинки:
Когда запускаешь свой сервис на Амазоне, обычно это происходит так:
а) настраиваешь какую-то виртуальную машину,
б) устанавливаешь на неё свой сервис,
в) проверяешь, что всё работает, а потом
г) делаешь из неё AMI — полный слепок, образ твоего сервиса вместе с операционной системой и всем прочим, что там есть.
Он сохраняется в облаке, а затем при необходимости очень легко и просто (и, главное, автоматически) тиражируется в любом разумном масштабе с автоматической же донастройкой. На скриншоте как раз приведён интерфейс, в котором задаются некоторые дополнительные настройки для запуска множества экземпляров заранее сконфигурированного слепка.
Стрелочкой отмечена опция «Автоматически назначить внешние IP-адреса для каждого экземпляра».
Так вот. Когда запускаешь свой сервис в большом масштабе, Амазону можно указать, чтобы при определённой нагрузке на процессор виртуальной машины он разворачивал рядом ещё один экземпляр твоего сервиса. Или, например, сразу сто штук. Или не при нагрузке на процессор, а, допустим, при паре сотен одновременно активных сетевых соединений. Таких метрик для автоматического масштабирования очень много, и правила для автозапуска можно настроить тоже довольно гибко.
Посмотрим теперь на такой вот график:
Это аппроксимированное количество одновременно активных пользователей всемирных интернет-сервисов в рабочее время. В Тихом океане почти никто не живёт, в Китае интернет свой собственный, а наибольшее количество пользователей приходится на Европу, и — в особенности — запад США. Это верно почти для любого сервиса со всемирным охватом, хоть Стима, хоть Нетфликса, хоть Википедии, хоть Телеграма.
Как мы видим, разница между максимумом и минимумом раза в полтора. Буквально это значит, что если ты работаешь на весь мир, то примерно половину суток, пока в Западном полушарии день, тебе надо чуть ли не вдвое больше мощностей, чем другую половину суток, когда день в Азии. Вот и настраиваешь себе соответствующие правила автоматического масштабирования, чтобы не тратить процессорное время (и свои деньги — в облаках как нигде время=деньги) понапрасну в то время, когда оно не нужно.
И половина экземпляров твоего сервиса просто убивается самим облаком по расписанию, когда Америка ложится спать. А на следующий день при росте нагрузки оно услужливо тебе их снова поднимет.
Теперь ответим на вопрос 3). Стрелочка на скриншоте не просто так нарисована. Опция «Автоматически назначить внешние IP-адреса для каждого экземпляра» берёт адреса из доступного пула адресов — Амазону принадлежит несколько миллионов, и ещё несколько он арендует у других владельцев. Публичный IPv4-адрес штука ныне дефицитная, поэтому иметь для каждого виртуального экземпляра таковой на постоянной основе, работает он сейчас или нет, большая роскошь — и стоит денег (более того, в любом дата-центре Амазона постоянных адресов тебе дают всего 5 штук, и увеличивают этот лимит ну с очень большим скрипом).
И как только какой-то экземпляр убивается, адрес сразу же возвращается снова в общий пул. И так далее. Кому он попадёт в следующий раз? Да кому угодно. Может быть, тебе, а может быть другому клиенту, который тоже автоматически масштабирует свой сервис, а может и эфемерному экземпляру сервиса самого Амазона. Таким образом, ответ на вопрос 3) тривиален: потому что сегодня этот IP-шник твой, а через пару часов чей-то ещё. Если твой сервис кому-то неугоден, но автоматически масштабируется, то забанить его по IP можно, но только если запретить весь пул.
И на вопрос 2) ответ тоже тривиален: нисколько не стоит. Облако само назначит следующему экземпляру какой-то другой адрес из доступного ему пула, хочешь ты этого или нет.
Теперь про первый вопрос.
Ответ не так очевиден, но попробуем сделать то, что называется educated guess (не знаю, как это лучше сказать по-русски, «предположение на основании опыта», наверное?).
Амазон — это самое старое из больших облаков. Программная обвязка, которая занимается всеми этими автоматическими масштабированиями, написана ещё лет десять назад, и с тех пор работает как часы. Сам гигантский сервис Амазона работает ровно в том же самом облаке. Обвязка эта не сломана, её не надо чинить, а любые изменения, которые пишут люди, имеют риск внесения ошибок. Поэтому фича по изоляции пулов адресов под клиента, если начать её разрабатывать прямо сейчас, займёт до чёртиков времени, и если вдруг приведёт к большим изменениям, то цена возможных последствий будет исчисляться миллиардами долларов. В самом прямом смысле.
И ответ на 1) звучит так: Для Амазона попросту невыгодно переделывать свою инфраструктуру под требования спятившего надзорного органа государства, все клиенты из которого не приносят столько денег, чтобы скомпенсировать возможный риск для самого себя и клиентов из других стран. Звучит жёстко, но это, к сожалению, бизнес.
Кстати, с остальными облаками всё ровно то же самое. Ютюб оказался забаненым потому, что сервисы самого Гугля не отделены от сервисов клиентов Гугля, и работают в том же облачном пространстве с единым пулом адресов. И с сервисами Майкрософта аналогично.
Роскомнадзор, блокируя облачные сервисы, воюет с технологией, на которой строятся облака. Со скриптами. С алгоритмами. Это всё равно что воевать против законов физики, или пытаться дать пинка стихии: предельно глупо и бессмысленно. Невозможно победить облака и ветер, можно только уйти под землю, чтобы их никогда не видеть…

