В данный момент инсталяция по данному мануалу работать не будет. Из за больших изменений API Kubemaster, в данный момент я готовлю новый цикл статей где будут рабочие версии мануалов
Первая из статей habr.com/ru/post/462473
Здравствуйте!
В данной публикации я хотел бы рассказать о кластере Kubernetes с высокой доступностью (HA).

Оглавление:
- Вступление
- Список используемого софта
- Список и назначение хостов
- Принцип работы и развертывания
- Подготовка ОС к развертыванию. Установка docker, kubeadm, kubelet и kubectl
- Подготовка конфигурационного скрипта
- Создание etcd кластера
- Инициализация мастера с помощью kubeadm
- Настройка CIDR
- Инициализация остальных мастернод
- Настройка keepalived и виртуального IP
- Добавление рабочих нод в кластер
- Установка ingress-nginx
- Дополнительно
Вступление
На новом месте работы пришлось столкнуться с интересной задачей, а именно: развернуть высокодоступный kubernetes кластер. Основной посыл задачи был добиться максимальной отказоустойчивости работы кластера при выходе из строя физических машин.
Небольшое вступление:
В работу мне достался проект с минимальным количеством документации и одним развернутым стендом, на котором в docker контейнерах «болтались» отдельные компоненты данного проекта. Так же на этом стенде работали четыре фронта для разных служб, запущенные через pm2.
После того, как я смог разобраться со схемой сервисов и логикой их работы, дело осталось за выбором инфраструктуры, на которой проект будет работать. После всех обсуждений остановились на двух вариантах развития событий. Первый — все запихать в lxc контейнеры и рулить всем с помощью ansible. Второй — оставить все в докере и попробовать в работе k8s
По первому варианту работает большинство проектов в нашей компании. Однако, в данном случае, мы все же решили оставить все в docker, но поместить проект в отказоустойчивый кластер при помощи kubernetes.
Для повышенной отказоустойчивости кластер было решено разворачивать с пятью мастер нодами.
Согласно таблице в документации etcd на сайте CoreOS,
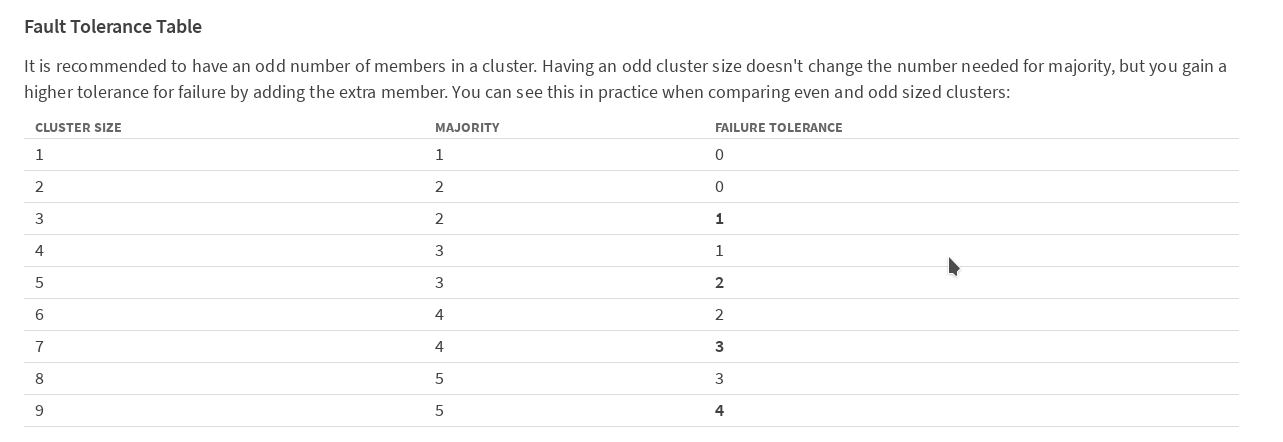
рекомендуется иметь нечетное число членов в кластере. Для того, чтобы кластер продолжал работать после выхода из строя одного члена (в нашем случае мастера kubernetes), нужно минимум 3 машины. Для того что бы кластер работал после потери 2 машин, их нужно иметь 5. Мы решили перестраховаться и развернуть вариант с 5 мастерами.
У kubernetes очень подробная официальная документация, хотя, на мой взгляд, достаточно запутанная; особенно, когда сталкиваешься с этим продуктом в первый раз.
Плохо, что в документах в основном описываются схемы работы, когда в кластере присутствует только одна нода с ролью master. В интернете также не очень много информации по работе кластера в режиме HA, а в русскоязычной его части, по моему, нет вообще. Поэтому я решил поделится своим опытом. Возможно, он кому -то пригодится. Итак, начну:
Основная идея была подсмотрена на githab у cookeem . В общем-то я ее и реализовал, исправив большинство недочетов в конфигах, увеличив количество мастер нод в кластере до пяти. Все нижеприведенные конфиги и скрипты можно скачать с моего репозитория на GitHub.
Краткая схема и описание архитектуры развертывания
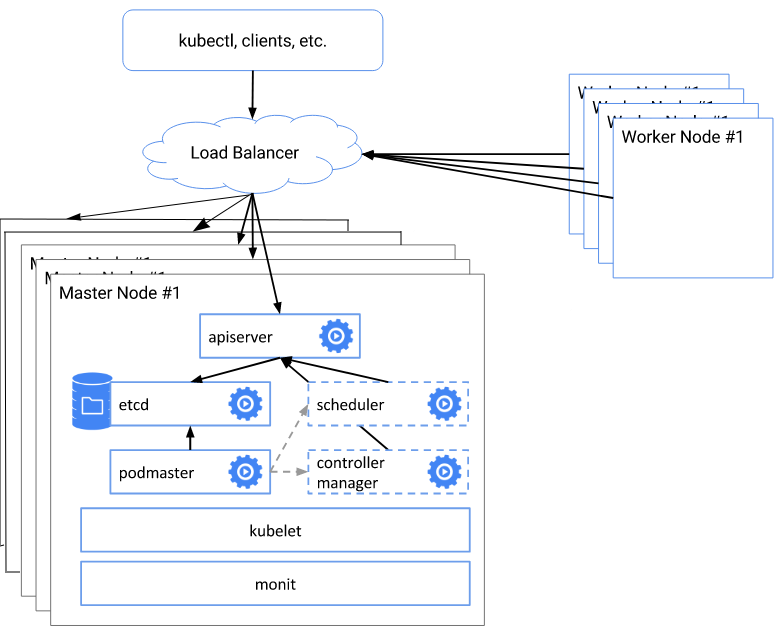
Вся суть схемы заключается в следующем:
- создаем etcd кластер
- при помощи kubeadm init создаем первого мастера сертификаты, ключи и.т.д.
- с помощью сгенерированых файлов конфигурации инициализируем остальные 4 мастер ноды
- конфигурируем балансировщик nginx на каждой мастер ноде для виртуального адреса
- меняем адрес и порт API сервера на выделенный виртуальный адрес
- Добавляем в кластер рабочие ноды
Список используемого софта
- linux:
Выбор операционной системы. Изначально хотели попробовать в работе CoreOS, но именно в момент нашего выбора компания, выпускавшая данную ОС, была приобретена RedHat. После приобретения CoreOS, RedHat не объявила свои дальнейшие планы на приобретенные разработки, поэтому мы побоялись использовать ее, в связи с возможными лицензионными ограничениями в будущем.
Я выбрал Debian 9.3 (Stretch) просто потому что больше привык с ней работать; в общем -то особой разницы в выборе ОС для Kubernetes нет. Вся нижеприведенная схема будет работать на любой поддерживаемой ОС, из списка в официальной документации к kubernetes
- Debian
- Ubuntu
- HypriotOS
- CentOS
- RHEL
- Fedora
- Container Linux
- контейнеры:
На момент написания статьи docker version 17.03.2-ce, build f5ec1e2 и docker-compose version 1.8.0, рекомендованная документацией. - Kubernetes v1.9.3
- networks add-ons: flannel
- Балансировщик: nginx
Виртуальный IP: keepalived Version: 1:1.3.2-1
Список хостов
| Имена хостов | IP адрес | Описание | Компоненты |
|---|---|---|---|
| hb-master01 ~ 03 | 172.26.133.21 ~ 25 | master nodes * 5 | keepalived, nginx, etcd, kubelet, kube-apiserver, kube-scheduler, kube-proxy, kube-dashboard, heapster |
| N\A | 172.26.133.20 | keepalived virtual IP | N\A |
| hb-node01 ~ 03 | 172.26.133.26 ~ 28 | Рабочие ноды * 3 | kubelet, kube-proxy |
Подготовка ОС к развертыванию. Установка docker, kubeadm, kubelet и kubectl
Прежде чем начать развертывание, на всех нодах кластера нужно подготовить систему, а именно: установить нужные пакеты, настроить фаервол, отключить swap Как говорится, before you begin.
$ sudo -i :~#
Если используется swap, то его нужно отключить; kubeadm не поддерживает работу со swap. Я сразу ставил систему без раздела swap.
swapoff -a
Правим /etc/fstab. Либо в ручную
vim /etc/fstab # swap was on /dev/sda6 during installation #UUID=5eb7202b-68e2-4bab-8cd1-767dc5a2ee9d none swap sw 0 0
Лиибо через sed
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
В Debian 9 нет selinux. Если в вашем дистрибутиве он есть, то его нужно перевести в permissive mode
Если в iptables есть какие либо правила, то их желательно очистить. Во время установки и настройки, Docker и kubernetes пропишут свои правила фаервола.
На каждой ноде кластера обязательно указать правильный hostname.
vim /etc/hostname hb-master01
На этом подготовка закончена, выполним перезагрузку перед следующим шагом
reboot
На какждой машине кластера устанавливаем docker по инструкции из документации kubernetes:
apt-get update apt-get install -y \ apt-transport-https \ ca-certificates \ curl \ software-properties-common \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - add-apt-repository \ "deb https://download.docker.com/linux/$(. /etc/os-release; echo "$ID") \ $(lsb_release -cs) \ stable" apt-get update && apt-get install -y docker-ce=$(apt-cache madison docker-ce | grep 17.03 | head -1 | awk '{print $3}') docker-compose
Далее ставим kubeadm, kubelet и kubectl по той же инструкции.
apt-get update && apt-get install -y apt-transport-https curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl
Устанавливаем keepalived:
apt-get install keepalived systemctl enable keepalived && systemctl restart keepalived
Для корректной работы CNI (Container Network Interface) нужно установить /proc/sys/net/bridge/bridge-nf-call-iptables в значение 1
sysctl net.bridge.bridge-nf-call-iptables=1
Подготовка конфигурационного скрипта
git clone https://github.com/rjeka/kubernetes-ha.git cd kubernetes-ha
На каждой мастер ноде подготавливаем скрипт create-config.sh
vim create-config.sh #!/bin/bash # local machine ip address export K8SHA_IPLOCAL=172.26.133.21 # local machine etcd name, options: etcd1, etcd2, etcd3, etcd4, etcd5 export K8SHA_ETCDNAME=etcd1 # local machine keepalived state config, options: MASTER, BACKUP. One keepalived cluster only one MASTER, other's are BACKUP export K8SHA_KA_STATE=MASTER # local machine keepalived priority config, options: 102, 101, 100, 99, 98. MASTER must 102 export K8SHA_KA_PRIO=102 # local machine keepalived network interface name config, for example: eth0 export K8SHA_KA_INTF=ens18 ####################################### # all masters settings below must be same ####################################### # master keepalived virtual ip address export K8SHA_IPVIRTUAL=172.26.133.20 # master01 ip address export K8SHA_IP1=172.26.133.21 # master02 ip address export K8SHA_IP2=172.26.133.22 # master03 ip address export K8SHA_IP3=172.26.133.23 # master04 ip address export K8SHA_IP4=172.26.133.24 # master05 ip address export K8SHA_IP5=172.26.133.25 # master01 hostname export K8SHA_HOSTNAME1=hb-master01 # master02 hostname export K8SHA_HOSTNAME2=hb-master02 # master03 hostname export K8SHA_HOSTNAME3=hb-master03 # master04 hostname export K8SHA_HOSTNAME4=hb-master04 # master04 hostname export K8SHA_HOSTNAME4=hb-master05 # keepalived auth_pass config, all masters must be same export K8SHA_KA_AUTH=55df7dc334c90194d1600c483e10acfr # kubernetes cluster token, you can use 'kubeadm token generate' to get a new one export K8SHA_TOKEN=4ae6cb.9dbc7b3600a3de89 # kubernetes CIDR pod subnet, if CIDR pod subnet is "10.244.0.0/16" please set to "10.244.0.0\\/16" export K8SHA_CIDR=10.244.0.0\\/16 ############################## # please do not modify anything below ##############################
В самом файле конфигурации у cookeem оставлены достаточно подробные комментарии, но все же давайте пробежимся по основным пунктам:
Расшифровка create-config.sh
# настройки на локальной машине каждой из нод (на каждой ноде свои)
K8SHA_IPLOCAL — IP адрес ноды на которой настраивается скрипт
K8SHA_ETCDNAME — имя локальной машины в кластере ETCD, соответственно на master01 — etcd1, master02 — etcd2 и т.д.
K8SHA_KA_STATE — роль в keepalived. Одна нода MASTER, все остальные BACKUP.
K8SHA_KA_PRIO — приоритет keepalived, у мастера 102 у остальных 101, 100, .....98. При падении мастера с номером 102, его место занимает нода с номером 101 и так далее.
K8SHA_KA_INTF — keepalived network interface. Имя интерфейса который будет слушать keepalived
# общие настройки для всех мастернод одинаковые
K8SHA_IPVIRTUAL=172.26.133.20 — виртуальный IP кластера.
K8SHA_IP1...K8SHA_IP5 — IP адреса мастеров
K8SHA_HOSTNAME1 ...K8SHA_HOSTNAME5 — имена хостов для мастернод. Важный пункт, по этим именам kubeadm будет генерировать сертификаты.
K8SHA_KA_AUTH — пароль для keepalived. Можно задать произвольный
K8SHA_TOKEN — токен кластера. Можно сгенерировать командой kubeadm token generate
K8SHA_CIDR — адрес подсети для подов. Я использую flannel поэтому CIDR 0.244.0.0/16. Обязательно экранировать — в конфиге должно быть K8SHA_CIDR=10.244.0.0\\/16
K8SHA_IPLOCAL — IP адрес ноды на которой настраивается скрипт
K8SHA_ETCDNAME — имя локальной машины в кластере ETCD, соответственно на master01 — etcd1, master02 — etcd2 и т.д.
K8SHA_KA_STATE — роль в keepalived. Одна нода MASTER, все остальные BACKUP.
K8SHA_KA_PRIO — приоритет keepalived, у мастера 102 у остальных 101, 100, .....98. При падении мастера с номером 102, его место занимает нода с номером 101 и так далее.
K8SHA_KA_INTF — keepalived network interface. Имя интерфейса который будет слушать keepalived
# общие настройки для всех мастернод одинаковые
K8SHA_IPVIRTUAL=172.26.133.20 — виртуальный IP кластера.
K8SHA_IP1...K8SHA_IP5 — IP адреса мастеров
K8SHA_HOSTNAME1 ...K8SHA_HOSTNAME5 — имена хостов для мастернод. Важный пункт, по этим именам kubeadm будет генерировать сертификаты.
K8SHA_KA_AUTH — пароль для keepalived. Можно задать произвольный
K8SHA_TOKEN — токен кластера. Можно сгенерировать командой kubeadm token generate
K8SHA_CIDR — адрес подсети для подов. Я использую flannel поэтому CIDR 0.244.0.0/16. Обязательно экранировать — в конфиге должно быть K8SHA_CIDR=10.244.0.0\\/16
После того, как все значения прописаны, на каждой мастерноде требуется запустить скрипт create-config.sh для создания конфигов
kubernetes-ha# ./create-config.sh
Создание etcd кластера
На основании полученных конфигов создаем etcd кластер
docker-compose --file etcd/docker-compose.yaml up -d
После того, как на всех мастерах поднялись контейнеры, проверяем статус etcd
docker exec -ti etcd etcdctl cluster-health member 3357c0f051a52e4a is healthy: got healthy result from http://172.26.133.24:2379 member 4f9d89f3d0f7047f is healthy: got healthy result from http://172.26.133.21:2379 member 8870062c9957931b is healthy: got healthy result from http://172.26.133.23:2379 member c8923ecd7d317ed4 is healthy: got healthy result from http://172.26.133.22:2379 member cd879d96247aef7e is healthy: got healthy result from http://172.26.133.25:2379 cluster is healthy
docker exec -ti etcd etcdctl member list 3357c0f051a52e4a: name=etcd4 peerURLs=http://172.26.133.24:2380 clientURLs=http://172.26.133.24:2379,http://172.26.133.24:4001 isLeader=false 4f9d89f3d0f7047f: name=etcd1 peerURLs=http://172.26.133.21:2380 clientURLs=http://172.26.133.21:2379,http://172.26.133.21:4001 isLeader=false 8870062c9957931b: name=etcd3 peerURLs=http://172.26.133.23:2380 clientURLs=http://172.26.133.23:2379,http://172.26.133.23:4001 isLeader=false c8923ecd7d317ed4: name=etcd2 peerURLs=http://172.26.133.22:2380 clientURLs=http://172.26.133.22:2379,http://172.26.133.22:4001 isLeader=true cd879d96247aef7e: name=etcd5 peerURLs=http://172.26.133.25:2380 clientURLs=http://172.26.133.25:2379,http://172.26.133.25:4001 isLeader=false
Если с кластером, все в порядке, то двигаемся дальше. Если что -то не так, то смотрим логи
docker logs etcd
Инициализация первой мастер ноды с помощью kubeadm
На hb-master01 используя kubeadm выполняем инициализацию кластера kubernetes.
kubeadm init --config=kubeadm-init.yaml
Если будет ошибка по версии Kubelet то к строке нужно добавить ключ
--ignore-preflight-errors=KubeletVersion
После того как мастер инициализируется, kubeadm выведет на экран служебную информацию. В ней будет указан token и хэш для инициализации других членов кластера. Обязательно сохраните строчку вида: kubeadm join --token XXXXXXXXXXXX 172.26.133.21:6443 --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXX, где нибудь отдельно, так как данная информация выводится один раз; если токены будут утеряны, их придется генерировать заново.
Your Kubernetes master has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of machines by running the following on each node as root: kubeadm join --token XXXXXXXXXXXX 172.26.133.21:6443 --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXX
Далее нужно установить переменную окружения, для возможности работать с кластером от root
vim ~/.bashrc export KUBECONFIG=/etc/kubernetes/admin.conf
source ~/.bashrc
Если нужно работать под обычным пользователем, то следуем инструкции, которая появилась на экране при инициализации мастера.
To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
Проверяем, что все сделали правильно:
kubectl get node NAME STATUS ROLES AGE VERSION hb-master01 NotReady master 22m v1.9.5 Мастер будет находится в статусе NotReady до того как мы не поднимем сеть cidr, это нормально.
Настройка CIDR
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.9.1/Documentation/kube-flannel.yml clusterrole "flannel" created clusterrolebinding "flannel" created serviceaccount "flannel" created configmap "kube-flannel-cfg" created daemonset "kube-flannel-ds" created
Проверяем, что все ОК
kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system kube-apiserver-hb-master01 1/1 Running 0 1h kube-system kube-controller-manager-hb-master01 1/1 Running 0 1h kube-system kube-dns-6f4fd4bdf-jdhdk 3/3 Running 0 1h kube-system kube-flannel-ds-hczw4 1/1 Running 0 1m kube-system kube-proxy-f88rm 1/1 Running 0 1h kube-system kube-scheduler-hb-master01 1/1 Running 0 1h
Инициализация остальных мастернод
Теперь после того, как наш кластер работает с одной нодой, настало время ввести в кластер оставшиеся мастерноды.
Для этого с hb-master01 нужно скопировать каталог /etc/kubernetes/pki в удаленный каталог /etc/kubernetes/ каждого мастера. Для копирования в настройках ssh я временно разрешил подключение руту. После копирования файлов, естественно, данную возможность отключил.
На каждой из оставшихся мастернод настраиваем ssh сервер
vim /etc/ssh/sshd_config PermitRootLogin yes systemctl restart ssh
Копируем файлы
scp -r /etc/kubernetes/pki 172.26.133.22:/etc/kubernetes/ \ && scp -r /etc/kubernetes/pki 172.26.133.23:/etc/kubernetes/ \ && scp -r /etc/kubernetes/pki 172.26.133.24:/etc/kubernetes/ \ && scp -r /etc/kubernetes/pki 172.26.133.25:/etc/kubernetes/
Теперь на hb-master02 используйте kubeadm для запуска кластера, убедитесь, что pod kube-apiserver- находится в рабочем состоянии.
kubeadm init --config=kubeadm-init.yaml Your Kubernetes master has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of machines by running the following on each node as root: kubeadm join --token xxxxxxxxxxxxxx 172.26.133.22:6443 --discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxx
Повторяем на hb-master03, hb-master04, hb-master05
Проверяем, что все мастера инициализировались и работают в кластере
kubectl get nodes NAME STATUS ROLES AGE VERSION hb-master01 Ready master 37m v1.9.5 hb-master02 Ready master 33s v1.9.5 hb-master03 Ready master 3m v1.9.5 hb-master04 Ready master 17m v1.9.5 hb-master05 Ready master 19m v1.9.5
kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system kube-apiserver-hb-master01 1/1 Running 0 6m kube-system kube-apiserver-hb-master02 1/1 Running 0 1m kube-system kube-apiserver-hb-master03 1/1 Running 0 1m kube-system kube-apiserver-hb-master04 1/1 Running 0 1m kube-system kube-apiserver-hb-master05 1/1 Running 0 10s kube-system kube-controller-manager-hb-master01 1/1 Running 0 6m kube-system kube-controller-manager-hb-master02 1/1 Running 0 1m kube-system kube-controller-manager-hb-master03 1/1 Running 0 1m kube-system kube-controller-manager-hb-master04 1/1 Running 0 1m kube-system kube-controller-manager-hb-master05 1/1 Running 0 9s kube-system kube-dns-6f4fd4bdf-bnxl8 3/3 Running 0 7m kube-system kube-flannel-ds-j698p 1/1 Running 0 6m kube-system kube-flannel-ds-mf9zc 1/1 Running 0 2m kube-system kube-flannel-ds-n5vbm 1/1 Running 0 2m kube-system kube-flannel-ds-q7ztg 1/1 Running 0 1m kube-system kube-flannel-ds-rrrcq 1/1 Running 0 2m kube-system kube-proxy-796zl 1/1 Running 0 1m kube-system kube-proxy-dz25s 1/1 Running 0 7m kube-system kube-proxy-hmrw5 1/1 Running 0 2m kube-system kube-proxy-kfjst 1/1 Running 0 2m kube-system kube-proxy-tpkbt 1/1 Running 0 2m kube-system kube-scheduler-hb-master01 1/1 Running 0 6m kube-system kube-scheduler-hb-master02 1/1 Running 0 1m kube-system kube-scheduler-hb-master03 1/1 Running 0 1m kube-system kube-scheduler-hb-master04 1/1 Running 0 48s kube-system kube-scheduler-hb-master05 1/1 Running 0 29s
Создадим реплики службы kube-dns. На hb-master01 выполнить
kubectl scale --replicas=5 -n kube-system deployment/kube-dns
На всех мастернодах в файл конфигурации внести строчку с количеством api серверов
Если вы используете kubernetes версии больше 1.9 этот шаг можно пропустить.
vim /etc/kubernetes/manifests/kube-apiserver.yaml - --apiserver-count=5 systemctl restart docker && systemctl restart kubelet
Настройка keepalived и виртуального IP
На всех мастернодах настраиваем keepalived и nginx в качестве балансировщика
systemctl restart keepalived docker-compose -f nginx-lb/docker-compose.yaml up -d
Тестируем работу
curl -k https://172.26.133.21:16443 | wc -1 wc: invalid option -- '1' Try 'wc --help' for more information. % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 233 100 233 0 0 15281 0 --:--:-- --:--:-- --:--:-- 15533
Если 100 % — то все ОК.
После того, как мы получили работающий виртуальный адрес, укажем его как адрес API сервера.
На hb-master01
kubectl edit -n kube-system configmap/kube-proxy server: https://172.26.133.20:16443
Удалим все kube-proxy pod для их рестарта с новыми параметрами.
kubectl get pods --all-namespaces -o wide | grep proxy kubectl delete pod -n kube-system kube-proxy-XXX
Проверим, что все рестартанули
kubectl get pods --all-namespaces -o wide | grep proxy kube-system kube-proxy-2q7pz 1/1 Running 0 28s 172.26.133.22 hb-master02 kube-system kube-proxy-76vnw 1/1 Running 0 10s 172.26.133.23 hb-master03 kube-system kube-proxy-nq47m 1/1 Running 0 19s 172.26.133.24 hb-master04 kube-system kube-proxy-pqqdh 1/1 Running 0 35s 172.26.133.21 hb-master01 kube-system kube-proxy-vldg8 1/1 Running 0 32s 172.26.133.25 hb-master05
Добавление рабочих нод в кластер
На каждой рабочей ноде устанавливаем docke, kubernetes и kubeadm, по аналогии с мастерами.
Добавляем ноду в кластер, используя токены сгенерированные при инициализации hb-master01
kubeadm join --token xxxxxxxxxxxxxxx 172.26.133.21:6443 --discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx [preflight] Running pre-flight checks. [WARNING FileExisting-crictl]: crictl not found in system path [discovery] Trying to connect to API Server "172.26.133.21:6443" [discovery] Created cluster-info discovery client, requesting info from "https://172.26.133.21:6443" [discovery] Requesting info from "https://172.26.133.21:6443" again to validate TLS against the pinned public key [discovery] Cluster info signature and contents are valid and TLS certificate validates against pinned roots, will use API Server "172.26.133.21:6443" [discovery] Successfully established connection with API Server "172.26.133.21:6443" This node has joined the cluster: * Certificate signing request was sent to master and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the master to see this node join the cluster.
Проверяем, что все рабочие ноды вошли в кластер и они доступны.
kubectl get nodes NAME STATUS ROLES AGE VERSION hb-master01 Ready master 20h v1.9.5 hb-master02 Ready master 20h v1.9.5 hb-master03 Ready master 20h v1.9.5 hb-master04 Ready master 20h v1.9.5 hb-master05 Ready master 20h v1.9.5 hb-node01 Ready <none> 12m v1.9.5 hb-node02 Ready <none> 4m v1.9.5 hb-node03 Ready <none> 31s v1.9.5
Только на рабочих нодах в файлах /etc/kubernetes/bootstrap-kubelet.conf и /etc/kubernetes/kubelet.conf меняем
значение переменной server на наш виртуальный IP
vim /etc/kubernetes/bootstrap-kubelet.conf server: https://172.26.133.20:16443
vim /etc/kubernetes/kubelet.conf server: https://172.26.133.20:16443
systemctl restart docker kubelet
Далее Вы можете увеличивать производительность Вашего кластера добавляя новые рабочие ноды, по мере надобности.
Установка ingress-nginx
Ntgthm нам осталось установить ingress.
В документации kubernetes про Ingress написано следующее:
Объект API, который управляет внешним доступом к службам в кластере, обычно HTTP.
Ingress может обеспечивать балансировку нагрузки, завершение SSL и виртуальный хостинг на основе имен.
В общем то более подробно я вряд ли смогу описать. Настройка ingress это материал для отдельной статьи, в контексте установки кластера я лишь опишу его установку.
kubectl apply -f kube-ingress/mandatory.yaml namespace "ingress-nginx" created deployment.extensions "default-http-backend" created service "default-http-backend" created configmap "nginx-configuration" created configmap "tcp-services" created configmap "udp-services" created serviceaccount "nginx-ingress-serviceaccount" created clusterrole.rbac.authorization.k8s.io "nginx-ingress-clusterrole" configured role.rbac.authorization.k8s.io "nginx-ingress-role" created rolebinding.rbac.authorization.k8s.io "nginx-ingress-role-nisa-binding" created clusterrolebinding.rbac.authorization.k8s.io "nginx-ingress-clusterrole-nisa-binding" configured deployment.extensions "nginx-ingress-controller" created
kubectl apply -f kube-ingress/service-nodeport.yaml service "ingress-nginx" created
Проверяем что ingress поднялся:
kubectl get all -n ingress-nginx NAME READY STATUS RESTARTS AGE pod/default-http-backend-5c6d95c48-j8sd4 1/1 Running 0 5m pod/nginx-ingress-controller-58c9df5856-vqwst 1/1 Running 0 5m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/default-http-backend ClusterIP 10.109.216.21 <none> 80/TCP 5m service/ingress-nginx NodePort 10.96.229.115 172.26.133.20 80:32700/TCP,443:31211/TCP 4m NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/default-http-backend 1 1 1 1 5m deployment.apps/nginx-ingress-controller 1 1 1 1 5m NAME DESIRED CURRENT READY AGE replicaset.apps/default-http-backend-5c6d95c48 1 1 1 5m replicaset.apps/nginx-ingress-controller-58c9df5856 1 1 1 5m
На этом шаге настройка кластера закончена. Если вы все сделали правильно, то должны получить отказоустойчивый, рабочий кластер Kubernetes c отказоустойчивой точкой входа и балансировщиком на виртуальном адресе.
Спасибо за внимание, буду рад комментариям, или указаниям на неточности. Также можно создавать issue на github, я постараюсь оперативно реагировать на них.
С уважением,
Евгений Родионов
Дополнительно
|Установка панели управления Kubernetes Dashboard
У Kubernetes кроме cli, имеется не плохая панель инструментов. Устанавливается она очень просто, инструкция и документация есть на GitHub
Команды можно выполнять на любом из 5 мастеров. Я работаю с hb-master01
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
Проверяем:
kubectl get pods --all-namespaces -o wide | grep kubernetes-dashboard kube-system kubernetes-dashboard-5bd6f767c7-cz55w 1/1 Running 0 1m 10.244.7.2 hb-node03
Панель теперь доступна по адресу:
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/Но чтобы на нее попасть, нужно пробрасывать proxy c локальной машины с помощью команды
kubectl proxy
Мне это не удобно, поэтому я использую NodePort и размещу панель по адресу https://172.26.133.20:30000 на первый доступный порт из диапазона, выделенного для NodePort.
kubectl -n kube-system edit service kubernetes-dashboard
Заменяем значение type: ClusterIP на type: NodePort и в секцию port: добавляем значение nodePort: 30000

Далее создадим пользователя с именем admin-user и полномочиями администратора кластера.
kubectl apply -f kube-dashboard/dashboard-adminUser.yaml serviceaccount "admin-user" created clusterrolebinding "admin-user" created
Получаем токен для пользователя admin-user
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') Name: admin-user-token-p8cxl Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name=admin-user kubernetes.io/service-account.uid=0819c99c-2cf0-11e8-a281-a64625c137fc Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 11 bytes token: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Копируем token и переходим по адресу:
https://172.26.133.20:30000/Теперь нам доступна панель управления Kubernetes кластера c полномочиями админа.

Heapster
Далее установим Heapster. Это инструмент для мониторинга ресурсов всех составляющих кластера. Страничка проекта на GitHub
Установка:
git clone https://github.com/kubernetes/heapster.git cd heapster kubectl create -f deploy/kube-config/influxdb/ deployment "monitoring-grafana" created service "monitoring-grafana" created serviceaccount "heapster" created deployment "heapster" created service "heapster" created deployment "monitoring-influxdb" created service "monitoring-influxdb" created
kubectl create -f deploy/kube-config/rbac/heapster-rbac.yaml clusterrolebinding "heapster" created
Через пару минут должна пойти информация. Проверяем:
kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% hb-master01 166m 4% 1216Mi 31% hb-master02 135m 3% 1130Mi 29% hb-master03 142m 3% 1091Mi 28% hb-master04 193m 4% 1149Mi 29% hb-master05 144m 3% 1056Mi 27% hb-node01 41m 1% 518Mi 3% hb-node02 38m 0% 444Mi 2% hb-node03 45m 1% 478Mi 2%
Также метрики доступны в web интерфейсе
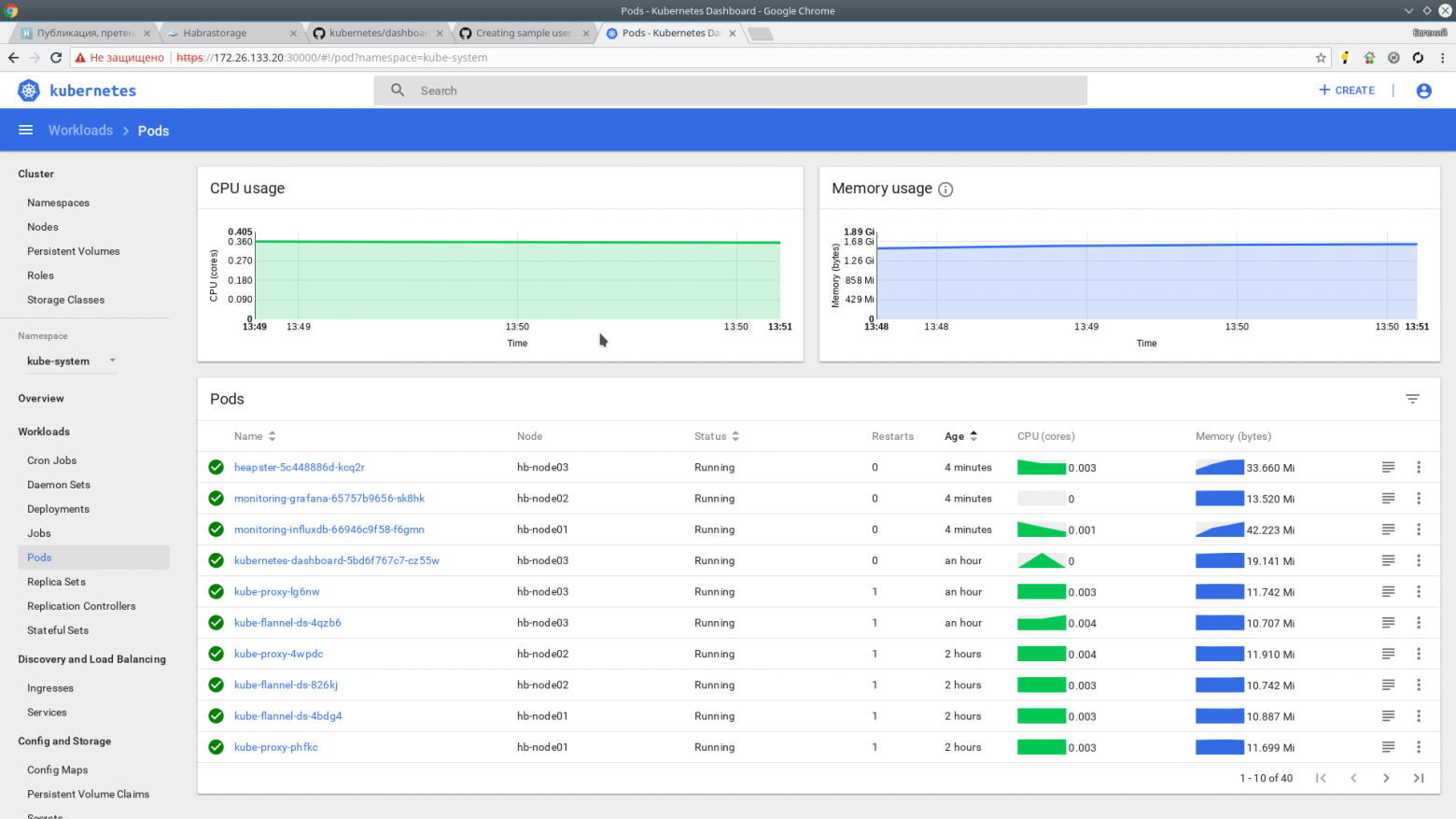
Спасибо за внимание.
Использование материалы:

