
Быстрые, масштабируемые и надежные решения этих категорий все чаще рассматриваются как необходимые средства для обеспечения успешности бизнеса.
Разработчики H2O.ai стремятся создать быструю, масштабируемую и открытую платформу машинного обучения. В этой статье рассматриваются методы эффективной разработки и использования моделей машинного обучения на основе H2O.ai в Azure.
H2O.ai поддерживает несколько вариантов развертывания, в том числе на отдельном узле, на кластере из нескольких узлов, а также на кластерах Hadoop или Apache Spark. H2O.ai написана на Java и поэтому изначально поддерживает API Java. Поскольку сервер на языке Scala обычно работает на основе виртуальной машины Java VM, H2O.ai также поддерживает API Scala. Кроме того, доступны многофункциональные интерфейсы для Python и R. Программисты на R и Python могут воспользоваться алгоритмами и возможностями H2O.ai с помощью пакетов h2o R и h2o Python. Скрипты R и Python, в которых применяется библиотека h2o, взаимодействуют с кластерами H2O посредством вызовов REST API.
Ввиду растущей популярности Apache Spark был разработан интерфейс Sparkling Water, назначение которого — объединить функциональные возможности H2O и Apache Spark. Sparkling Water позволяет запустить службу H2O на каждом исполнителе Spark в кластере Spark и получить таким образом кластер H2O. Обычный способ совместного применения этих решений: преобразование данных в Apache Spark при обучении и оценке с использованием H2O.
Apache Spark изначально поддерживает Python благодаря интерфейсу PySpark, а программный пакет Pysparkling позволяет наладить обмен данными между Spark и H2O, чтобы запускать приложения Sparkling Water с помощью Python. Пакет Sparklyr служит интерфейсом R для Spark, а инструмент rsparkling позволяет наладить обмен данными между Spark и H2O, чтобы запускать приложения Sparkling Water с помощью R.
В таблице 1 и на рисунке 1 ниже представлена дополнительная информация о запуске приложений Sparkling Water в Spark с помощью R и Python.
| Артефакты | Использование |
|---|---|
| JAR-файл H2O | JAR-файл, содержащий библиотеку для запуска служб H2O |
| JAR-файл Sparkling Water | JAR-файл, содержащий библиотеку для запуска приложения Sparkling Water на кластере Spark |
| Пакет Python «h2o» | Интерфейс Python для H2O |
| Пакет Python «pyspark» | API Python для Spark |
| Пакет Python «h2o_pysparkling_{номер основной версии Spark}» | Интерфейс Python для Sparkling Water |
| Пакет R «h2o» | Интерфейс R для H2O |
| Пакет R «sparklyr» | Интерфейс R для Apache Spark |
| Пакет R «rsparkling» | Интерфейс R для пакета Sparkling Water |
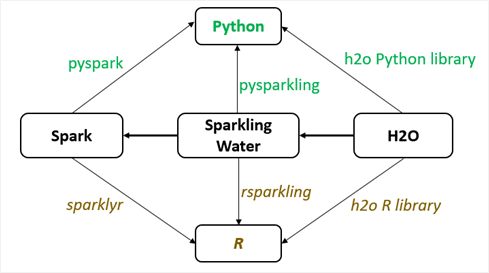
Рис. 1. Взаимодействие библиотек R и Python, JAR-файлов Sparkling Water и H2O при запуске приложений Sparkling Water на платформе Spark с помощью R и Python
Разработка моделей
Виртуальная машина для обработки и анализа данных (DSVM) — отличный инструмент для создания моделей машинного обучения в средах с одним узлом. DSVM поставляется с предустановленной средой H2O.ai для Python. Если вы используете R (в Ubuntu), скрипт из нашей предыдущей публикации в блоге поможет настроить среду. Если вы работаете с большими наборами данных, то может оказаться целесообразным использовать для разработки кластер. Ниже описаны два рекомендуемых варианта для разработки на основе кластеров.
В рамках решения Azure HDInsight доступно множество удобных конфигураций полностью управляемых кластеров. Azure HDInsight позволяет пользователям создавать кластеры Spark с H2O.ai. Все необходимые компоненты на них изначально установлены. Пользователи Python могут поэкспериментировать с ними, воспользовавшись примерами Jupyter, которые поставляются вместе с кластером.
Программисты R могут обратиться к нашей предыдущей публикации — там описана настройка среды для разработки с использованием RStudio. После того как вы создадите и обучите модель, ее можно будет сохранить для проведения оценки. H2O позволяет сохранить обученную модель в виде файла MOJO. Также при сохранении модели создается JAR-файл h2o-genmodel.jar. Он используется для загрузки вашей обученной модели при работе с кодом Java или Scala. Код Python и R способен загрузить обученную модель напрямую с помощью API H2O.
Если вам нужны недорогие кластеры, вы можете воспользоваться набором инструментов Azure Distributed Data Engineering Toolkit (AZTK) для запуска кластера Spark на основе Docker в пакетной службе Azure Batch с низкоприоритетными виртуальными машинами.
К кластеру, созданному с помощью AZTK, при разработке можно обращаться посредством SSH или блокнотов Jupyter. По сравнению с Jupyter Notebooks на кластерах Azure HDInsight, блокнот Jupyter обеспечивает меньшую функциональность и не содержит готовых настроек для разработки моделей H2O.ai. Кроме того, пользователям необходимо сохранять наработки в надежной внешней среде, потому что Spark-кластер AZTK нельзя восстановить после отключения.
Особенности использования перечисленных трех сред для разработки моделей представлены в таблице 2.
| Одна виртуальная машина | HDInsight Cluster SPARK | Azure Batch с Azure Distributed Data Engineering Toolkit | |
| Объем данных | Маленький | Большой | Большой |
| Стоимость | Низкая | Зависит от размера кластера и виртуальной машины | Оплата только потребленных ресурсовe |
| Контейнезированный кластер | Нет | Нет | Да, под управлением пользователей |
| Горизонтальное масштабирование | Нет | Да | Да |
| Готовый набор инструментов | Многофункциональный набор инструментов с примерами настроек для выполнения H2O.ai в Jupyter | Многофункциональный набор инструментов с примерами настроек для выполнения H2O.ai в Jupyter | Limited (С ограничениями (по умолчанию выполняется перенаправление портов пользовательского интерфейса Spark Web на localhost:8080, интерфейса Spark Jobs UI — на localhost:4040, а Jupyter — на localhost:8888).) |
Пакетная оценка и переобучение моделей
Пакетную оценку также называют автономной оценкой. Обычно она применяется в случае больших объемов данных и может занять много времени. Переобучение позволяет восстановить работоспособность модели, которая перестала корректно регистрировать закономерности в новых наборах данных. Пакетная оценка и переобучение моделей считаются операциями пакетной обработки, и реализовать их можно похожим образом.
Пакетная служба Azure отлично подходит для управления множеством параллельных задач, каждая из которых может быть обработана одной виртуальной машиной. Инструмент Azure Batch Shipyard позволяет создавать и настраивать задания в пакетной службе Azure с использованием контейнеров Docker без написания программного кода. Apache Spark и H2O.ai можно с легкостью добавить в образ Docker и использовать их с Azure Batch Shipyard.
В Azure Batch Shipyard каждую процедуру переобучения модели или пакетной оценки можно настроить в виде задачи. Такие задания, состоящие из нескольких параллельных задач, иногда называют «чрезвычайно параллельной» нагрузкой. Они принципиально отличаются от распределенных вычислений, в рамках которых выполнение задания требует обмена информацией между задачами. Более подробная информация приводится на этой wiki-странице.
Если заданию пакетной обработки нужен кластер для распределенных операций (например, в случае большого объема данных или экономической целесообразности такого решения), вы можете создать кластер Spark на основе Docker с помощью AZTK. H2O.ai можно с легкостью добавить в образ Docker, а процессы создания кластера, отправки задания и удаления кластера можно автоматизировать и запускать с помощью приложения-функции Azure.
Однако при таком подходе пользователям необходимо настраивать кластер и управлять образами контейнеров. Если вам нужен полностью управляемый кластер с возможностями детального мониторинга, обратите внимание на Azure HDInsight. Сейчас для отправки пакетных заданий на кластер можно использовать элемент Spark Activity фабрики данных Azure. Однако для этого нужен постоянно работающий кластер HDInsight, поэтому такой вариант больше подходит для случаев, в которых пакетная обработка выполняется часто.
В таблице 3 приводится сравнение трех способов пакетной обработки данных в Spark. H2O.ai можно с легкостью интегрировать в среду любого из этих типов.
| Приложение-функция Azure + пакетная служба Azure с Azure Batch Shipyard |
Фабрика данных Azure + Spark-кластер HDInsight |
Приложение-функция Azure + пакетная служба Azure с набором инструментов Azure Distributed |
|
| Тип пула вычислительных ресурсов |
Предоставляются по запросу |
Предоставляются пользователем |
Предоставляются по запросу |
| Режим заданий Spark |
Локальный; несколько узлов независимо работают над задачами, которые входят в состав задания |
Кластер; несколько узлов работают как кластер, выполняя отдельное задание |
Кластер; несколько узлов работают как кластер, выполняя отдельное задание |
| Объем данных |
Маленький |
Большой |
Большой |
| Стоимость |
Оплачивается только время работы пакетного пула; на низкоприоритетные узлы предоставляется скидка |
Более высокие расходы на вычислительный узел, простаивающие кластеры также оплачиваются |
Оплачивается только время работы пакетного пула; на низкоприоритетные узлы предоставляется скидка |
| Контейнеризированные задания |
Да |
Нет |
Да |
| Насколько подходит для чрезвычайно параллельных вычислений |
Идеально |
Неидеально |
Неидеально |
| Насколько подходит для распределенных вычислений |
Неидеально |
Идеально для частой пакетной обработки данных |
Идеально для нечастой пакетной обработки данных |
| Задержки |
Около 5 |
Только на отправку задания (кластер всегда включен) |
Около 5 |
| Горизонтальное масштабирование |
Да; автоматическое масштабирование при увеличении количества задач |
Да, без автоматического масштабирования |
Да, без автоматического масштабирования |
Онлайн-оценка
Онлайн-оценка подразумевает малое время отклика, поэтому ее также называют оценкой в реальном времени. В общем случае онлайн-оценка используется для составления прогнозов для отдельных точек или небольших наборов. При возможности такая оценка должна строиться на предварительно вычисленных кешированных признаках. Мы можем загрузить модели машинного обучения, а также соответствующие библиотеки и запустить оценку в любом приложении. Если для разделения ответственности и уменьшения зависимостей используется архитектура микрослужб, рекомендуется реализовать онлайн-оценку в виде веб-службы с REST API.
Веб-службы для оценки с использованием моделей машинного обучения H2O обычно пишутся на Java, Scala или Python. Как мы упоминали в разделе «Разработка моделей», модель H2O сохраняется в формате MOJO, при этом также формируется файл h2o-genmodel.jar. Веб-службы, написанные на Java или Scala, могут использовать этот файл JAR для загрузки сохраненной модели и проведения оценки. Веб-службы, написанные на Python, могут загружать сохраненную модель непосредственно с помощью API для Python.
В рамках Azure доступно множество способов размещения веб-служб.
Веб-приложение Azure — предложение Azure в формате PaaS, предназначенное для размещения веб-приложений. Это полностью управляемая платформа, которая помогает пользователю сосредоточиться на функциональности своих приложений. Недавно для размещения контейнеризованых веб-приложений была выпущена служба веб-приложений Azure для контейнеров, основанная на веб-приложении Azure на Linux. Служба контейнеров Azure с Kubernetes (AKS) — удобное средство создания и настройки кластера виртуальных машин для выполнения контейнеризированных приложений.
Служба веб-приложений Azure для контейнеров и служба контейнеров Azure обеспечивают высокую переносимость веб-приложений и позволяют гибко настраивать среду их работы. Интерфейс командной строки и API управления моделями машинного обучения Azure (AML) — еще более простые инструменты для управления веб-службами в ACS с использованием Kubernetes. Сравнение трех служб Azure, позволяющих размещать системы онлайн-оценки, приводится в таблице 4.
| Веб-приложение Azure |
Служба веб-приложений Azure для контейнеров |
Служба контейнеров Azure с Kubernetes (AKS) |
|
| Возможность модификации среды выполнения |
Нет |
Да, посредством контейнеров |
Да, посредством контейнеров |
| Стоимость |
Зависит от плана служб приложений |
Зависит от плана служб приложений |
Стоимость узла виртуальной машины зависит от пользовательских параметров |
| Поддержка виртуальной сети или балансировщика нагрузки |
Да |
Да |
Да |
| Развертывание служб |
Управляется пользователями |
Управляется пользователями |
Управляется пользователями или выполняется автоматически посредством интерфейса командной строки или API для управления моделями AML |
| Время создания службы |
Небольшое |
Небольшое |
Около 20 минут посредством интерфейса командной строки или API для управления моделями AML; также создаются дополнительные ресурсы: балансировщик нагрузки и т. п. |
| Промежуточное развертывание |
Да, посредством слотов развертывания |
Да, посредством слотов развертывания |
Да; Kubernetes поддерживает управляемое промежуточное обновление |
| Поддержка нескольких приложений |
Нет, но в рамках одного плана служб приложений можно использовать несколько приложений |
Нет, но в рамках одного плана служб приложений можно использовать несколько приложений |
Да, на одном кластере можно запустить несколько приложений |
| Горизонтальное масштабирование |
Автоматическое масштабирование на всех планах служб, кроме базовых |
Автоматическое масштабирование на всех планах служб, кроме базовых |
Управляется пользователями |
| Средство мониторинга |
App Insight |
App Insight |
Log Analytics |
| Непрерывная интеграция |
Да |
Управляется пользователями |
Управляется пользователями |
| QPS (пропускная способность) |
Зависит от плана служб приложений |
Зависит от плана служб приложений |
Управляется пользователями |
Оценка на пограничных устройствах
Этот метод подразумевает выполнение оценки на устройствах «Интернета вещей» (IoT). При таком подходе устройства анализируют информацию и принимают решения на основе результатов сразу после сбора данных, не передавая их в центр обработки. Оценка на пограничных устройствах очень удобна в случаях жестких ограничений, связанных с конфиденциальностью данных, или при необходимости получать оценку максимально быстро.
Благодаря технологии контейнеров службы машинного обучение Azure и Azure IoT Edge предоставляют простые способы для развертывания моделей машинного обучения на пограничных IoT-устройствах Azure. Использование контейнеров AML максимально упрощает применение H2O.ai на пограничных устройствах. Более подробные сведения об анализе данных на пограничных устройствах приводятся в недавней публикации Artificial Intelligence and Machine Learning on the Cutting Edge в нашем блоге.
Заключение
В этой статье мы обсудили способы подготовки и развертывания решений на основе H2O.ai с помощью служб Azure, изучили разработку и переобучение моделей, пакетную оценку, онлайн-оценку и оценку на пограничных устройствах. В этой публикации о разработке систем искусственного интеллекта мы в основном рассматривали H2O.ai. Однако полученные выводы относятся не только к этой среде: они в равной мере применимы ко всем решениям на платформе Spark.
В Spark добавляется поддержка все новых платформ, таких как TensorFlow и Microsoft Cognitive Toolkit (CNTK), поэтому мы уверены, что ценность полученных результатов будет только расти. Для того чтобы успешно реализовать любой проект, необходимо выбрать подходящий продукт, учитывая при этом потребности с точки зрения бизнеса и технологий. Мы надеемся, что наша статья поможет вам решить эту задачу.

