Обработка событий — одна из самых распространенных задач в области бессерверных технологий. Сегодня расскажем о том, как создать надежный обработчик сообщений, который сведет к нулю их потерю. Кстати, примеры написаны на C# с использованием библиотеки Polly, но показанные подходы будут работать с любыми языками (если не указано обратное).

Передаю слово автору.
Несколько недель назад я опубликовал статью о том, как обрабатывать события по порядку с помощью Functions. В сегодняшней публикации я в общих чертах расскажу, как создать надежный обработчик сообщений, который сведет к нулю их потерю. Эту статью можно было бы разбить на две или три части, но я решил объединить всю информацию в одном материале. Он получился большим, но зато охватывает широкий спектр задач: от простых до самых сложных, таких как использование шаблонов размыкателя цепи и фильтров исключений. Примеры написаны на C#, но показанные подходы будут работать с любыми языками (если не указано обратное).
Представьте систему, которая отправляет события с постоянной скоростью — например, 100 штук в секунду. Настроить прием этих событий в Azure Functions довольно просто. Всего за несколько минут можно подготовить множество параллельных экземпляров, которые будут обрабатывать эти 100 событий в секунду. Но что, если издатель отправит некорректно сформированное событие? Что если один из ваших экземпляров прекратит работу из-за сбоя? Или отключится одна из систем, осуществляющих дальнейшие этапы обработки? Как справиться с такими ситуациями, сохранив при этом общую целостность и пропускную способность вашего приложения?
Обеспечить надежность обработки сообщений при использовании очередей немного проще. В Azure Functions при обработке сообщения из очереди функция может «заблокировать» такое сообщение, попытаться обработать его, а в случае неудачи — снять блокировку, чтобы другой экземпляр мог принять его и повторить попытку. Эти попытки продолжаются до тех пор, пока сообщение не будет успешно обработано или пока не будет достигнуто предельное допустимое количество попыток (по умолчанию — 4). Во втором случае сообщение добавляется в очередь подозрительных сообщений. Когда сообщение из очереди проходит этот цикл попыток, параллельное извлечение из очереди других сообщений не прекращается. Поэтому одна ошибка почти не влияет на общую пропускную способность. Однако очереди хранения не гарантируют порядок и не оптимизированы для обеспечения высокой пропускной способности служб (как, например, концентраторы событий).
В потоках событий (например, в концентраторах событий Azure) блокировки не используются. Эти службы устроены так, чтобы обеспечить высокую пропускную способность, поддерживать несколько групп потребителей и возможность воспроизведения. При приеме событий они работают подобно ленточному накопителю. На каждый раздел в потоке приходится один указатель смещения. Считывать события можно в обоих направлениях. Допустим, при чтении потока событий возникает ошибка, и вы решаете оставить указатель на прежнем месте. Пока он не сдвинется, дальнейшая обработка данных из этого раздела будет невозможна. Другими словами, если в систему по-прежнему поступает 100 событий в секунду, но Azure Functions перестали перемещать указатель на новые события, пытаясь справиться с некорректным, то случится затор. Очень быстро у вас накопится огромное количество необработанных событий, которое будет постоянно расти.

Обрабатывайте исключения, но не задерживайте очередь.
Такое поведение указателя смещения и потребителей было учтено: Functions будут перемещать указатель по потоку вне зависимости от того, успешной ли была обработка. Это значит, что ваша система и ваши Functions должны уметь обрабатывать такие ситуации.
Azure Functions взаимодействуют с концентратором событий следующим образом:
Здесь следует обратить внимание на несколько вещей. Первая: если вы не обрабатываете исключения, то можете потерять сообщения, потому что даже если выполнение завершилось с исключением, указатель будет смещен. Вторая: Functions гарантируют по меньшей мере однократную доставку (это обычная ситуация в распределенных системах). Это значит, что ваш код и зависящие от него системы должны корректно работать в ситуациях, когда одно и то же сообщение было получено дважды. Ниже приводятся примеры этих двух ситуаций и кода, который позволяет с ними справиться.
В рамках этих тестов я опубликовал 100 тысяч сообщений для последовательной обработки (на ключ раздела). Чтобы проверить и наглядно представить порядок и надежность, я буду регистрировать каждое сообщение в ходе его обработки в кеше Redis. В первом тесте каждое сотое сообщение приводит к генерации исключения, и обработка исключений не производится.
После передачи 100 тысяч сообщений в эту систему Redis показал следующее:

Как видите, я пропустил целую цепочку сообщений с 100-й по 112-ю. Что произошло? В какой-то момент один из экземпляров моих функций получил пакет сообщений для этого ключа раздела. Этот конкретный пакет закончился на 112-м сообщении, но на сотом было сгенерировано исключение. Выполнение было остановлено, но узел функций продолжил работу и считал следующий пакет. Технически эти сообщения сохранились в концентраторах событий, но чтобы обработать их повторно, мне нужно вручную запросить сообщения с 100-го по 112-е.
Проще всего решить эту проблему простым добавлением в код блока try/catch. Теперь в случае исключения я могу обработать его в рамках того же процесса до того, как указатель переместится дальше. После добавления блока catch в приведенный выше код и перезапуска теста все 100 тысяч сообщений появились в нужном порядке.
Рекомендация: во всех функциях концентратора событий должен быть блок catch.
В этом примере я использовал блок catch, чтобы предпринять дополнительную попытку вставки данных в Redis, но ему легко найти и другие разумные применения: например, отправка уведомления или помещение сообщения в очередь подозрительных или в концентратор событий для дальнейшей обработки.
Некоторые возникающие исключения могут проявляться лишь время от времени. Иногда для корректного выполнения операции ее достаточно просто повторить. В блоке catch в коде из предыдущего раздела выполнялась одна повторная попытка, но если бы она завершилась неудачей или привела к исключению, то я все так же потерял бы сообщения 100–112. Существует множество инструментов, которые позволяют настроить более гибкие политики повторных попыток с сохранением порядка обработки.
Для тестирования я воспользовался библиотекой C# для обработки ошибок, которая называется Polly. Она позволила мне задать как простые, так и продвинутые политики выполнения повторных попыток. Пример: «попытаться вставить это сообщение три раза (возможно, с задержкой между попытками). Если все попытки были неудачными, добавить сообщение в очередь, чтобы я мог продолжить обработку событий, а к необработанному или некорректному сообщению вернуться позже».
В этом коде я добавляю сообщение в кеш Redis с помощью фрагмента, который создает запись.
Итоговое состояние Redis:

При работе с более продвинутыми политиками перехвата исключений и повторных попыток стоит иметь в виду, что для предварительно скомпилированных библиотек классов C# доступна ознакомительная версия возможности, позволяющей задать «фильтры исключений» для вашей функции. С ее помощью вы сможете написать метод, который будет выполняться при генерации необработанного исключения во время работы функции. Более подробная информация и примеры доступны в этой публикации.
Мы рассмотрели случай генерации исключений в вашем коде. Но что, если экземпляр функции столкнется с перебоем в процессе работы?

Как мы уже говорили, если Function не завершает выполнения, то указатель смещения не передвигается дальше, а значит, при попытке принять сообщения новые экземпляры будут получать одни и те же данные. Чтобы сымитировать такую ситуацию, я вручную остановил, запустил и перезапустил мое приложение-функцию в ходе обработки 100 тысяч сообщений. Слева вы можете увидеть часть полученных результатов. Обратите внимание: все события были обработаны, все в порядке, но некоторые сообщения были обработаны несколько раз (после 700-го было повторно обработано 601-е и последующие). В целом это хорошо, поскольку такое поведение гарантирует по меньшей мере однократную доставку, но это значит, что мой код должен быть в определенной мере идемпотентным.
Представленные выше закономерности и шаблоны поведения удобны для реализации повторных попыток и помогают приложить максимум усилий для обработки событий. Определенный уровень сбоев во многих случаях допустим. Но представим, что возникает множество ошибок, и я хочу остановить срабатывание на новых событиях до восстановления работоспособности системы. Этого можно достичь с помощью шаблона размыкателя цепи — элемента, который позволяет остановить цепь обработки событий и возобновить ее работу позже.
Polly (библиотека, с помощью которой я реализовал повторные попытки) поддерживает некоторые возможности размыкателя цепи. Однако эти шаблоны не очень подходят для использования в случае распределенных временных функций, когда цепь охватывает несколько экземпляров без отслеживания состояния. Существует несколько интересных подходов к решению этой проблемы с помощью Polly, но я пока добавлю нужные функции вручную. Для реализации размыкателя цепи при обработке событий необходимы два компонента:
В качестве первого компонента я использовал кэш Redis, а вторым стали приложения логики Azure. Обе эти роли могут выполнять множество других служб, но мне понравились эти две.
Параллельно обрабатывать события могут несколько экземпляров, поэтому для мониторинга работоспособности цепи мне нужно общее внешнее состояние. Я хотел реализовать следующее правило: «Если в течение 30 секунд по всем экземплярам в сумме зарегистрировано более 100 ошибок, разомкнуть цепь и прекратить срабатывание на новых сообщениях».
Я использовал доступные в Redis возможности отслеживания TTL и сортированные множества, чтобы получить скользящий интервал, регистрирующий количество ошибок за последние 30 секунд. (Если вас интересуют подробности, все эти примеры доступны в GitHub.) При появлении новой ошибки я обращался к скользящему интервалу. Если допустимое количество ошибок (более 100 за последние 30 секунд) было превышено, я отправлял событие в службу «Сетка событий Azure». Соответствующий код Redis доступен здесь. Так я мог обнаружить неполадки, отправить событие и разомкнуть цепь.
Для управления состоянием цепи я использовал приложения логики Azure, поскольку коннекторы и оркестрация с сохранением состояния отлично дополняют друг друга. Когда срабатывало условие размыкания цепи, я инициировал рабочий процесс (триггер службы «Сетка событий Azure»). Первый шаг — остановить Azure Functions (с помощью коннектора ресурса Azure) и отправить электронное письмо с уведомлением и вариантами реагирования. После этого я могу проверить работоспособность цепи и запустить ее снова, если все в порядке. В результате рабочий процесс будет возобновлен, функция запущена, а обработка сообщений — продолжена с последней контрольной точки концентратора событий.

Электронное письмо, которое я получил от приложений логики после остановки функции. Я могу нажать любую кнопку и возобновить работу цепи, когда потребуется.
Примерно 15 минут назад я отправил 100 тысяч сообщений и настроил систему так, чтобы каждое сотое сообщение приводило к ошибке. Примерно после 5000 сообщений был превышен допустимый порог, и событие было отправлено в службу «Сетка событий Azure». Мое приложение логики Azure сразу же сработало, остановило функцию и отправило мне электронное письмо (оно показано выше). Если взглянуть на содержимое Redis, мы увидим множество частично обработанных разделов:

Нижняя часть списка — обработка первых 200 сообщений для этого ключа раздела, после чего приложения логики остановили систему.
Я щелкнул по ссылке в электронном письме, чтобы возобновить работу цепи. Выполнив все тот же запрос в Redis, можно увидеть, что функция продолжила свою работу с последней контрольной точки концентратора событий. Ни одно сообщение не потерялось, все было обработано в строгом порядке, и цепь получилось сохранять разомкнутой столько, сколько требовалось — состоянием управляло мое приложение логики.

Семнадцатиминутная задержка перед командой на повторное замыкание цепи.
Надеюсь, эта публикация помогла вам узнать больше о методах и шаблонах надежной обработки потоков сообщений с помощью Azure Functions. Эти знания позволят вам воспользоваться преимуществами функций (в частности, их динамическим масштабированием и оплатой по мере потребления ресурсов) без ущерба для надежности решения.
По ссылке вы найдете репозиторий GitHub с указателями на каждую из ветвей для разных опорных точек этого примера. Если у вас возникли вопросы, свяжитесь со мной через Twitter: @jeffhollan.
Передаю слово автору.
Надежная обработка событий с помощью Azure Functions
Несколько недель назад я опубликовал статью о том, как обрабатывать события по порядку с помощью Functions. В сегодняшней публикации я в общих чертах расскажу, как создать надежный обработчик сообщений, который сведет к нулю их потерю. Эту статью можно было бы разбить на две или три части, но я решил объединить всю информацию в одном материале. Он получился большим, но зато охватывает широкий спектр задач: от простых до самых сложных, таких как использование шаблонов размыкателя цепи и фильтров исключений. Примеры написаны на C#, но показанные подходы будут работать с любыми языками (если не указано обратное).
Проблемы, связанные с потоками событий в распределенных системах
Представьте систему, которая отправляет события с постоянной скоростью — например, 100 штук в секунду. Настроить прием этих событий в Azure Functions довольно просто. Всего за несколько минут можно подготовить множество параллельных экземпляров, которые будут обрабатывать эти 100 событий в секунду. Но что, если издатель отправит некорректно сформированное событие? Что если один из ваших экземпляров прекратит работу из-за сбоя? Или отключится одна из систем, осуществляющих дальнейшие этапы обработки? Как справиться с такими ситуациями, сохранив при этом общую целостность и пропускную способность вашего приложения?
Обеспечить надежность обработки сообщений при использовании очередей немного проще. В Azure Functions при обработке сообщения из очереди функция может «заблокировать» такое сообщение, попытаться обработать его, а в случае неудачи — снять блокировку, чтобы другой экземпляр мог принять его и повторить попытку. Эти попытки продолжаются до тех пор, пока сообщение не будет успешно обработано или пока не будет достигнуто предельное допустимое количество попыток (по умолчанию — 4). Во втором случае сообщение добавляется в очередь подозрительных сообщений. Когда сообщение из очереди проходит этот цикл попыток, параллельное извлечение из очереди других сообщений не прекращается. Поэтому одна ошибка почти не влияет на общую пропускную способность. Однако очереди хранения не гарантируют порядок и не оптимизированы для обеспечения высокой пропускной способности служб (как, например, концентраторы событий).
В потоках событий (например, в концентраторах событий Azure) блокировки не используются. Эти службы устроены так, чтобы обеспечить высокую пропускную способность, поддерживать несколько групп потребителей и возможность воспроизведения. При приеме событий они работают подобно ленточному накопителю. На каждый раздел в потоке приходится один указатель смещения. Считывать события можно в обоих направлениях. Допустим, при чтении потока событий возникает ошибка, и вы решаете оставить указатель на прежнем месте. Пока он не сдвинется, дальнейшая обработка данных из этого раздела будет невозможна. Другими словами, если в систему по-прежнему поступает 100 событий в секунду, но Azure Functions перестали перемещать указатель на новые события, пытаясь справиться с некорректным, то случится затор. Очень быстро у вас накопится огромное количество необработанных событий, которое будет постоянно расти.
Обрабатывайте исключения, но не задерживайте очередь.
Такое поведение указателя смещения и потребителей было учтено: Functions будут перемещать указатель по потоку вне зависимости от того, успешной ли была обработка. Это значит, что ваша система и ваши Functions должны уметь обрабатывать такие ситуации.
Как Azure Functions принимают события из концентратора событий
Azure Functions взаимодействуют с концентратором событий следующим образом:
- Для каждого раздела в концентраторе событий создается (и помещается в хранилище Azure) указатель (его можно увидеть в учетной записи хранения).
- При получении новых сообщений концентратора событий (по умолчанию оно выполняется в пакетном режиме) узел попытается запустить функцию, передав в нее пакет сообщений.
- Когда функция завершает работу (неважно, с исключениями или нет), указатель перемещается дальше, и его позиция сохраняется в хранилище.
- Если что-то мешает функции завершиться, то узел не сможет передвинуть указатель, и при последующих проверках будут получены те же сообщения (с предыдущей контрольной точки).
- Этапы 2–4 повторяются.
Здесь следует обратить внимание на несколько вещей. Первая: если вы не обрабатываете исключения, то можете потерять сообщения, потому что даже если выполнение завершилось с исключением, указатель будет смещен. Вторая: Functions гарантируют по меньшей мере однократную доставку (это обычная ситуация в распределенных системах). Это значит, что ваш код и зависящие от него системы должны корректно работать в ситуациях, когда одно и то же сообщение было получено дважды. Ниже приводятся примеры этих двух ситуаций и кода, который позволяет с ними справиться.
В рамках этих тестов я опубликовал 100 тысяч сообщений для последовательной обработки (на ключ раздела). Чтобы проверить и наглядно представить порядок и надежность, я буду регистрировать каждое сообщение в ходе его обработки в кеше Redis. В первом тесте каждое сотое сообщение приводит к генерации исключения, и обработка исключений не производится.
[FunctionName("EventHubTrigger")] public static async Task RunAsync([EventHubTrigger("events", Connection = "EventHub")] EventData[] eventDataSet, TraceWriter log) { log.Info($"Triggered batch of size {eventDataSet.Length}"); foreach (var eventData in eventDataSet) { // For every 100th message, throw an exception if (int.Parse((string)eventData.Properties["counter"]) % 100 == 0) { throw new SystemException("Some exception"); } // Insert the current count into Redis await db.ListRightPushAsync("events:" + eventData.Properties["partitionKey"], (string)eventData.Properties["counter"]); } }
После передачи 100 тысяч сообщений в эту систему Redis показал следующее:
Как видите, я пропустил целую цепочку сообщений с 100-й по 112-ю. Что произошло? В какой-то момент один из экземпляров моих функций получил пакет сообщений для этого ключа раздела. Этот конкретный пакет закончился на 112-м сообщении, но на сотом было сгенерировано исключение. Выполнение было остановлено, но узел функций продолжил работу и считал следующий пакет. Технически эти сообщения сохранились в концентраторах событий, но чтобы обработать их повторно, мне нужно вручную запросить сообщения с 100-го по 112-е.
Добавление блока try-catch
Проще всего решить эту проблему простым добавлением в код блока try/catch. Теперь в случае исключения я могу обработать его в рамках того же процесса до того, как указатель переместится дальше. После добавления блока catch в приведенный выше код и перезапуска теста все 100 тысяч сообщений появились в нужном порядке.
Рекомендация: во всех функциях концентратора событий должен быть блок catch.
В этом примере я использовал блок catch, чтобы предпринять дополнительную попытку вставки данных в Redis, но ему легко найти и другие разумные применения: например, отправка уведомления или помещение сообщения в очередь подозрительных или в концентратор событий для дальнейшей обработки.
Механизмы и политики повторных попыток
Некоторые возникающие исключения могут проявляться лишь время от времени. Иногда для корректного выполнения операции ее достаточно просто повторить. В блоке catch в коде из предыдущего раздела выполнялась одна повторная попытка, но если бы она завершилась неудачей или привела к исключению, то я все так же потерял бы сообщения 100–112. Существует множество инструментов, которые позволяют настроить более гибкие политики повторных попыток с сохранением порядка обработки.
Для тестирования я воспользовался библиотекой C# для обработки ошибок, которая называется Polly. Она позволила мне задать как простые, так и продвинутые политики выполнения повторных попыток. Пример: «попытаться вставить это сообщение три раза (возможно, с задержкой между попытками). Если все попытки были неудачными, добавить сообщение в очередь, чтобы я мог продолжить обработку событий, а к необработанному или некорректному сообщению вернуться позже».
foreach (var eventData in eventDataSet) { var result = await Policy .Handle<Exception>() .RetryAsync(3, onRetryAsync: async (exception, retryCount, context) => { await db.ListRightPushAsync("events:" + context["partitionKey"], (string)context["counter"] + $"CAUGHT{retryCount}"); }) .ExecuteAndCaptureAsync(async () => { if (int.Parse((string)eventData.Properties["counter"]) % 100 == 0) { throw new SystemException("Some Exception"); } await db.ListRightPushAsync("events:" + eventData.Properties["partitionKey"], (string)eventData.Properties["counter"]); }, new Dictionary<string, object>() { { "partitionKey", eventData.Properties["partitionKey"] }, { "counter", eventData.Properties["counter"] } }); if(result.Outcome == OutcomeType.Failure) { await db.ListRightPushAsync("events:" + eventData.Properties["partitionKey"], (string)eventData.Properties["counter"] + "FAILED"); await queue.AddAsync(Encoding.UTF8.GetString(eventData.Body.Array)); await queue.FlushAsync(); } }
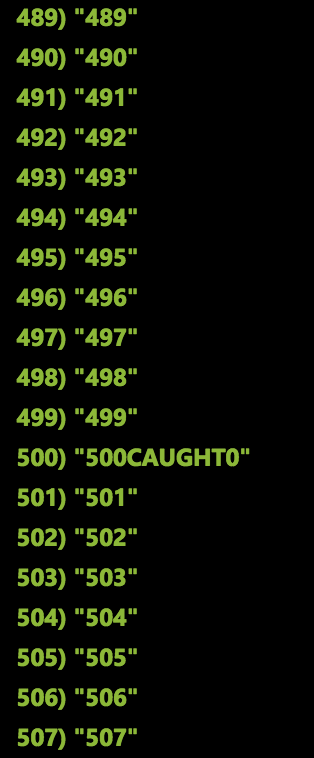
В этом коде я добавляю сообщение в кеш Redis с помощью фрагмента, который создает запись.
Итоговое состояние Redis:
При работе с более продвинутыми политиками перехвата исключений и повторных попыток стоит иметь в виду, что для предварительно скомпилированных библиотек классов C# доступна ознакомительная версия возможности, позволяющей задать «фильтры исключений» для вашей функции. С ее помощью вы сможете написать метод, который будет выполняться при генерации необработанного исключения во время работы функции. Более подробная информация и примеры доступны в этой публикации.
Ошибки и проблемы, не являющиеся исключениями
Мы рассмотрели случай генерации исключений в вашем коде. Но что, если экземпляр функции столкнется с перебоем в процессе работы?
Как мы уже говорили, если Function не завершает выполнения, то указатель смещения не передвигается дальше, а значит, при попытке принять сообщения новые экземпляры будут получать одни и те же данные. Чтобы сымитировать такую ситуацию, я вручную остановил, запустил и перезапустил мое приложение-функцию в ходе обработки 100 тысяч сообщений. Слева вы можете увидеть часть полученных результатов. Обратите внимание: все события были обработаны, все в порядке, но некоторые сообщения были обработаны несколько раз (после 700-го было повторно обработано 601-е и последующие). В целом это хорошо, поскольку такое поведение гарантирует по меньшей мере однократную доставку, но это значит, что мой код должен быть в определенной мере идемпотентным.
Размыкатель цепи и остановка конвейера
Представленные выше закономерности и шаблоны поведения удобны для реализации повторных попыток и помогают приложить максимум усилий для обработки событий. Определенный уровень сбоев во многих случаях допустим. Но представим, что возникает множество ошибок, и я хочу остановить срабатывание на новых событиях до восстановления работоспособности системы. Этого можно достичь с помощью шаблона размыкателя цепи — элемента, который позволяет остановить цепь обработки событий и возобновить ее работу позже.
Polly (библиотека, с помощью которой я реализовал повторные попытки) поддерживает некоторые возможности размыкателя цепи. Однако эти шаблоны не очень подходят для использования в случае распределенных временных функций, когда цепь охватывает несколько экземпляров без отслеживания состояния. Существует несколько интересных подходов к решению этой проблемы с помощью Polly, но я пока добавлю нужные функции вручную. Для реализации размыкателя цепи при обработке событий необходимы два компонента:
- Общее для всех экземпляров состояние для отслеживания и мониторинга работоспособности цепи.
- Главный процесс, который способен управлять состоянием цепи (размыкать или замыкать ее).
В качестве первого компонента я использовал кэш Redis, а вторым стали приложения логики Azure. Обе эти роли могут выполнять множество других служб, но мне понравились эти две.
Предельно допустимое количество ошибок по всем экземплярам
Параллельно обрабатывать события могут несколько экземпляров, поэтому для мониторинга работоспособности цепи мне нужно общее внешнее состояние. Я хотел реализовать следующее правило: «Если в течение 30 секунд по всем экземплярам в сумме зарегистрировано более 100 ошибок, разомкнуть цепь и прекратить срабатывание на новых сообщениях».
Я использовал доступные в Redis возможности отслеживания TTL и сортированные множества, чтобы получить скользящий интервал, регистрирующий количество ошибок за последние 30 секунд. (Если вас интересуют подробности, все эти примеры доступны в GitHub.) При появлении новой ошибки я обращался к скользящему интервалу. Если допустимое количество ошибок (более 100 за последние 30 секунд) было превышено, я отправлял событие в службу «Сетка событий Azure». Соответствующий код Redis доступен здесь. Так я мог обнаружить неполадки, отправить событие и разомкнуть цепь.
Управление состоянием цепи с помощью приложений логики
Для управления состоянием цепи я использовал приложения логики Azure, поскольку коннекторы и оркестрация с сохранением состояния отлично дополняют друг друга. Когда срабатывало условие размыкания цепи, я инициировал рабочий процесс (триггер службы «Сетка событий Azure»). Первый шаг — остановить Azure Functions (с помощью коннектора ресурса Azure) и отправить электронное письмо с уведомлением и вариантами реагирования. После этого я могу проверить работоспособность цепи и запустить ее снова, если все в порядке. В результате рабочий процесс будет возобновлен, функция запущена, а обработка сообщений — продолжена с последней контрольной точки концентратора событий.
Электронное письмо, которое я получил от приложений логики после остановки функции. Я могу нажать любую кнопку и возобновить работу цепи, когда потребуется.
Примерно 15 минут назад я отправил 100 тысяч сообщений и настроил систему так, чтобы каждое сотое сообщение приводило к ошибке. Примерно после 5000 сообщений был превышен допустимый порог, и событие было отправлено в службу «Сетка событий Azure». Мое приложение логики Azure сразу же сработало, остановило функцию и отправило мне электронное письмо (оно показано выше). Если взглянуть на содержимое Redis, мы увидим множество частично обработанных разделов:
Нижняя часть списка — обработка первых 200 сообщений для этого ключа раздела, после чего приложения логики остановили систему.
Я щелкнул по ссылке в электронном письме, чтобы возобновить работу цепи. Выполнив все тот же запрос в Redis, можно увидеть, что функция продолжила свою работу с последней контрольной точки концентратора событий. Ни одно сообщение не потерялось, все было обработано в строгом порядке, и цепь получилось сохранять разомкнутой столько, сколько требовалось — состоянием управляло мое приложение логики.
Семнадцатиминутная задержка перед командой на повторное замыкание цепи.
Надеюсь, эта публикация помогла вам узнать больше о методах и шаблонах надежной обработки потоков сообщений с помощью Azure Functions. Эти знания позволят вам воспользоваться преимуществами функций (в частности, их динамическим масштабированием и оплатой по мере потребления ресурсов) без ущерба для надежности решения.
По ссылке вы найдете репозиторий GitHub с указателями на каждую из ветвей для разных опорных точек этого примера. Если у вас возникли вопросы, свяжитесь со мной через Twitter: @jeffhollan.

