Эта статья не будет затрагивать основы hibernate (как определить entity или написать criteria query). Тут я постараюсь рассказать о более интересных моментах, действительно полезных в работе. Информацию о которых я не встречал в одной месте.

Сразу оговорюсь. Все ниже изложенное справедливо для Hibernate 5.2. Также возможны ошибки в силу того, что я что-то неправильно понял. Если обнаружите — пишите.
Но начнем все же с основ ORM. ORM — объектно-реляционное отображение — соответственно у нас есть реляционная и объектная модели. И при отображении одной в другую существуют проблемы, которые нам нужно решить самостоятельно. Давайте их разберем.
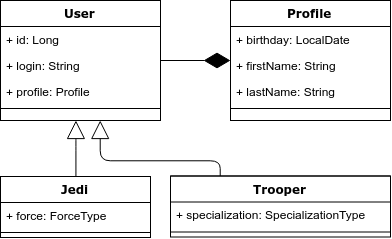
Для иллюстрации возьмем следующий пример: у нас есть сущность “Пользователь”, который может быть либо джедаем либо штурмовиком. У джедая обязательно должна быть сила, а у штурмовика специализация. Ниже приведена диаграмма классов.
В объектной модели есть наследование, а в реляционной нет. Соответственно это и первая проблема — как правильно отобразить наследование в реляционную модель.
Hibernate предлагает 3 варианта ее отображения такой объектной модели:
На всякий случай упомяну про аннотацию — @MappedSuperclass. Она используется когда вы хотите “спрятать” общие поля для нескольких сущностей объектной модели. При этом сам аннотированный класс не рассматривается как отдельная сущность.
Возвращаясь к нашему примеру заметим, что в объектной модели мы вынесли профиль пользователя в отдельную сущность — Profile. Но в реляционной модели мы не стали выделять под нее отдельную таблицу.
Отношение OneToOne чаще является плохой практикой, т.к. в селекте у нас появляется неоправданный JOIN (даже указав fetchType=LAZY в большинстве случаев у нас JOIN останется — эту проблему обсудим позже).
Для отображения композиции в общую таблицу существуют аннотации @Embedable и @Embeded. Первая ставится над полем, а вторая над классом. Они взаимозаменяемые.
Каждый экземпляр EntityManager-а (EM) определяет сеанс взаимодействия с базой данных. В рамках экземпляра EM-а, существует кэш первого уровня. Тут я выделю следующие значимые моменты:
Генераторы нужны для описания, каким способом первичные ключи наших сущностей будут получать значения. Давайте быстро пробежимся по вариантам:
Поговорим немного подробнее про sequence. С целью повысить скорость работы hibernate использует разные алгоритмы-оптимизаторы. Все они нацелены на уменьшение количества общений с БД (количество round-trip-ов). Давайте посмотрим на них чуть подробнее:
Теперь давайте разберемся, как выбирается оптимизатор. У hibernate есть несколько генераторов sequence. Нам будет интересно 2 из них:
Так же настроить генератор можно аннотацией @GenericGenerator.
Давайте разберем на примере псевдокода ситуацию, которая может привести к deadlock-у:
Для предотвращения таких проблем у hibernate есть механизм, который позволяет избежать deadlock-ов такого типа — параметр hibernate.order_updates. В этом случае все update-ы будут упорядочены по id и выполнены. Также еще раз упомяну, что hibernate старается “отсрочить” захват коннекшена и выполнение insert-ов и update-ов.
В hibernate есть 3 основных способа представить коллекцию связи OneToMany.
Для Bag в java core нет класса, который бы описывал такую структуру. Поэтому все List и Collection — являются bag-ом если не указана колонка, по которой наша коллекция будет сортироваться(аннотация OrderColumn. Не путать с SortBy). Использовать аннотацию OrderColumn крайне не рекомендую в силу плохой (на мой взгляд) реализации фичи — не оптимальные sql запросы, возможное наличие NULL-ов в листе.
Возникает вопрос, а что все-таки лучше использовать bag или set? Начнем с того, что при использовании bag-а возможны следующие проблемы:
В случае, когда вы хотите добавить к связи @OneToMany еще одну сущность, выгоднее использовать Bag, т.к. он для этой операции не требует загрузки всех связанных сущностей. Давайте посмотрим пример:
Reference — это ссылка на объект, загрузку которого мы решили отложить. В случае отношения ManyToOne с fetchType=LAZY, мы получаем такой reference. Инициализация объекта происходит в момент обращения к полям сущности, за исключением id (т.к. значение этого поля нам известно).
Стоит отметить, что в случае Lazy Loading-а reference всегда ссылается на существующую строку в БД. Именно по этой причине большинство случаев Lazy Loading-а в отношениях OneToOne не работает — hibernate необходимо сделать JOIN для проверки существования связи и JOIN уже был, то hibernate загружает его в объектную модель. Если же мы укажем в OneToOne связи nullable=true, то LazyLoad должен заработать.
Мы можем и самостоятельно создать reference, используя метод em.getReference. Правда в таком случае нет гарантии, что reference ссылается на существующую строку в БД.
Давайте приведем пример использования такой ссылки:
На всякий случай напомню, что мы получим LazyInitializationException в случае закрытого EM-а или отсоединенной(detached) ссылки.
Не смотря на то что в java 8 появилось прекрасное API для работы с датой и временем, JDBC API по прежнему позволяет работать только со старым API дат. Поэтому разберем некоторые интересные моменты.
Во-первых, нужно четко понимать отличия LocalDateTime от Instant и от ZonedDateTime. (Не буду растягивать, а приведу отличные статьи на эту тему: первая и вторая)
Более интересный и важный момент — как даты сохраняется в базу данных. Если у нас проставлен тип TIMESTAMP WITH TIMEZONE то проблем быть не должно, если же стоит TIMESTAMP (WITHOUT TIMEZONE) то есть вероятность, что дата запишется/прочитается неверная. (за исключением LocalDate и LocalDateTime)
Давайте разберемся почему:
Когда мы сохраняем дату, используется метод со следующей сигнатурой:
Как видим тут используется старое API. Дополнительный аргумент Calendar нужен для того, чтобы преобразовать timestamp в строковое представление. т.е он хранит в себе timezone-у. Если Calendar не передается, то используется Calendar по-умолчанию с таймзоной JVM.
Решить эту проблему можно 3 способами:
Интересный вопрос, почему LocalDate и LocalDateTime не подпадают под такую проблему?
По-умолчанию запросы отправляются в БД по одному. При включении batching-а hibernate сможет в одном запросе к БД отправлять несколько statement-ов. (т.е. batching сокращает количество round-trip-ов к БД)
Для этого необходимо:
Так же напомню, про эффективность операции em.clear() — она отвязывает сущности от em-а, тем самым вы освобождаете память и сокращаете время на операцию dirty checking.
Если мы используем postgres, то можно так же сказать hibernate использовать multi-raw insert.
Это достаточно изъезженная тема, поэтому пробежимся по ней быстро.
N+1 проблема — это ситуация, когда вместо одного запроса на выбор N книг происходит по меньшей мере N+1 запрос.
Самый простой способ решения N+1 проблемы это сделать fetch связанных таблиц. В этом случае у нас может возникнуть несколько других проблем:
Есть и другие способы решения N+1 проблемы.
В идеале development окружение должно предоставлять как можно больше полезной информации о работе hibernate и о взаимодействии с БД. А именно:
Из полезных утилит можно выделить следующее:
Но еще раз повторюсь, что это только для development, на production это включать не стоит.
Сразу оговорюсь. Все ниже изложенное справедливо для Hibernate 5.2. Также возможны ошибки в силу того, что я что-то неправильно понял. Если обнаружите — пишите.
Проблемы отображения объектной модели в реляционную
Но начнем все же с основ ORM. ORM — объектно-реляционное отображение — соответственно у нас есть реляционная и объектная модели. И при отображении одной в другую существуют проблемы, которые нам нужно решить самостоятельно. Давайте их разберем.
Для иллюстрации возьмем следующий пример: у нас есть сущность “Пользователь”, который может быть либо джедаем либо штурмовиком. У джедая обязательно должна быть сила, а у штурмовика специализация. Ниже приведена диаграмма классов.
Проблема 1. Наследование и полиморфные запросы.
В объектной модели есть наследование, а в реляционной нет. Соответственно это и первая проблема — как правильно отобразить наследование в реляционную модель.
Hibernate предлагает 3 варианта ее отображения такой объектной модели:
- Все наследники лежат в одной таблице:
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)

В этом случае, общие поля и поля наследников лежат в одной таблице. Используя такую стратегию мы избегаем join-ов при выборе сущностей. Из минусов стоит отметить, что во-первых, мы не можем в реляционной модели задать “NOT NULL” ограничение для колонки “force” и во-вторых, мы теряем третью нормальную форму. (появляется транзитивная зависимость неключевых атрибутов: force и disc).
Кстати, в том числе и по этой причине есть 2 способа указать not null ограничение у поля — NotNull отвечает за валидацию; @Column(nullable = true) — отвечает за not null ограничение в базе данных.
На мой взгляд это лучший вариант отображения объектной модели в реляционную.
- Специфичные для сущности поля лежат в отдельной таблице.
@Inheritance(strategy = InheritanceType.JOINED)
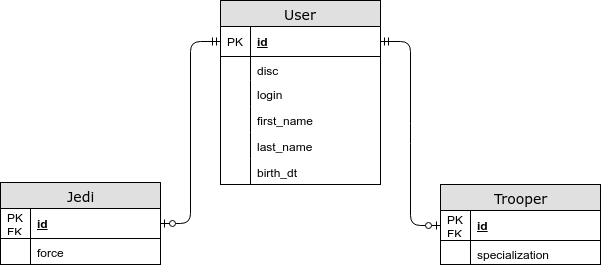
В этом случае общие поля хранятся в общей таблице, а специфичные для дочерних сущностей — в отдельных. Используя эту стратегию у нас появляется JOIN при выборе сущности, но теперь мы сохраняем третью нормальную форму, а также можем указать NOT NULL ограничение в базе данных. - Для каждой сущности есть своя таблица
@InheritanceType.TABLE_PER_CLASS

В этом случае у нас нет общей таблицы. Используя эту стратегию, при полиморфных запросах мы используется UNION. У нас появляеются проблемы с генераторами первичных ключей и другими ограничениями целостности. Данный тип отображения наследования строго не рекомендуется использовать.
На всякий случай упомяну про аннотацию — @MappedSuperclass. Она используется когда вы хотите “спрятать” общие поля для нескольких сущностей объектной модели. При этом сам аннотированный класс не рассматривается как отдельная сущность.
Проблема 2. Отношение композиции в ООП
Возвращаясь к нашему примеру заметим, что в объектной модели мы вынесли профиль пользователя в отдельную сущность — Profile. Но в реляционной модели мы не стали выделять под нее отдельную таблицу.
Отношение OneToOne чаще является плохой практикой, т.к. в селекте у нас появляется неоправданный JOIN (даже указав fetchType=LAZY в большинстве случаев у нас JOIN останется — эту проблему обсудим позже).
Для отображения композиции в общую таблицу существуют аннотации @Embedable и @Embeded. Первая ставится над полем, а вторая над классом. Они взаимозаменяемые.
Entity Manager
Каждый экземпляр EntityManager-а (EM) определяет сеанс взаимодействия с базой данных. В рамках экземпляра EM-а, существует кэш первого уровня. Тут я выделю следующие значимые моменты:
- Захват соединения с БД
Это просто интересный момент. Hibernate захватывает Connection не во время получения EM-а, а во время первого обращения к БД или открытия транзакции(хотя и эту проблему можно решить). Это сделано с целью сократить время занятого коннекшена. Во время получения EM-a проверяется наличие JTA транзакции. - У persisted сущности всегда есть id
- Сущности описывающие одну строчку в БД эквивалентны по ссылке
Как было сказано выше, у EM-а существует кэш первого уровня, объекты в нем сравниваются по ссылке. Соответственно возникает вопрос — какие поля использовать для переопределения equals и hashcode? Рассмотрим следующие варианты:
- Использовать все поля. Плохая идея, т.к. equals может затронуть LAZY поля. Кстати, это справедливо и для метода toString.
- Использовать только id. Нормальная идея, но тоже есть нюансы. Так как чаще всего для новых сущностей id проставляет генератор в момент persist-а. Возможна следующая ситуация:
Entity foo = new Entity(); // создаем сущность (id = null) set.put(foo); // добавляем в hashset em.persist(foo); // persist сущности (id = some value) set.contains(foo) == false // т.к. hashCode вернул другое значение
- Использовать бизнес ключ (грубо говоря — поля, которые уникальные и NOT NULL). Но и этот вариант бывает не всегда удобен.
Кстати, раз уж заговорили о NOT NULL и UNIQUE, то иногда удобно сделать публичный конструктор с NOT NULL аргументами, а конструктор без аргументов protected. - Вообще не переопределять equals и hashcode.
- Как работает flush
Flush — выполняет накопившиеся insert-ы, update-ы и delete-ы в БД. По-умолчанию flush выполняется в случаях:
- Перед выполнением query (за исключением em.get) — это нужно чтобы соблюсти принцип ACID. Например: мы поменяли дату рождения у штурмовика, а потом захотели получить количество совершеннолетних штурмовиков.
Если мы говорим о CriteriaQuery или JPQL, то flush выполнится в случае если запрос затрагивает таблицу, чьи сущности есть в кэше первого уровня. - При коммите транзакции;
- Иногда при persist-е новой сущности — в случае когда мы можем получить ее id только через insert.
А теперь небольшой тест. Сколько операций UPDATE выполнится в этом случае?
val spaceCraft = em.find(SpaceCraft.class, 1L); spaceCraft.setCoords(...); spaceCraft.setCompanion( findNearestSpaceCraft(spacecraft) );
Под операцией flush скрывается интересная фича hibernate — он пытается снизить время блокировки строк в БД.
Также отмечу, что есть разные стратегии операции flush. Например можно запретить “сливать” изменения в БД — он называется MANUAL (он также отключает механизм dirty checking).
- Перед выполнением query (за исключением em.get) — это нужно чтобы соблюсти принцип ACID. Например: мы поменяли дату рождения у штурмовика, а потом захотели получить количество совершеннолетних штурмовиков.
- Dirty Checking
Dirty Checking — это механизм, выполняемый во время операции flush. Его цель найти сущности, которые изменились и обновить их. Чтобы реализовать такой механизм, hibernate должен хранить оригинальную копию объекта (то с чем будет сравниваться актуальный объект). Если быть точнее, то hibernate хранит копию полей объекта, а не сам объект.
Тут стоит отметить, что если граф сущностей большой, то операция dirty checking-а может стоить дорого. Не стоит забывать о том, что hibernate хранит 2 копии сущностей (грубо говоря).
С целью “удешевить” этот процесс пользуйтесь следующими фичами:
- em.detach / em.clear — открепляют сущности от EntityManager-а
- FlushMode=MANUAL- полезен в операциях чтения
- Immutable — также позволяет избежать операций dirty checking
- Транзакции
Как известно hibernate позволяет обновлять сущности только внутри транзакции. Больше свободы предлагают операции чтения — их мы можем выполнять не открывая явно транзакцию. Но в этом как раз и вопрос, стоит ли для операций чтения открывать транзакцию явно?
Приведу несколько фактов:
- Любой statement выполняется в БД внутри транзакции. Если даже мы ее явно не открыли. (auto-commit mode).
- Как правило мы не ограничиваемся одним запросом к БД. Например: для получения первых 10 записей вы вероятно захотите вернуть количество записей всего. А это уже почти всегда 2 запроса.
- Если мы говорим про spring data, то методы репозитория транзакционны по-умолчанию, при этом методы чтения — read-only.
- Спринговая аннотация @Transactional(readOnly=true) также влияет на FlushMode, точнее Spring переводит его в статус MANUAL, тем самым хибернейт не будет выполнять dirty-checking.
- Синтетические тесты с одним-двумя запросами к БД покажут, что auto-commit работает быстрее. Но в боевом режиме это может быть не так. (отличная статья на эту тему, + смотрите комментарии)
Если в двух словах: хорошей практикой является любое общение с БД выполнять в транзакции.
Генераторы
Генераторы нужны для описания, каким способом первичные ключи наших сущностей будут получать значения. Давайте быстро пробежимся по вариантам:
- GenerationType.AUTO — выбор генератора осуществляется на основе диалекта. Не самый лучший вариант, так как тут как раз действует правило “явное лучше неявного”.
- GenerationType.IDENTITY — самый простой способ конфигурирования генератора. Он опирается на auto-increment колонку в таблице. Следовательно, чтобы получить id при persist-е нам нужно сделать insert. Именно поэтому он исключает возможность отложенного persist-а и следовательно batching-а.
- GenerationType.SEQUENCE — наиболее удобный случай, когда id мы получаем из sequence.
- GenerationType.TABLE — в этом случае hibernate эмулирует sequence через дополнительную таблицу. Не самый лучший вариант, т.к. в таком решении hibernate приходится юзать отдельную транзакцию и lock на строчку.
Поговорим немного подробнее про sequence. С целью повысить скорость работы hibernate использует разные алгоритмы-оптимизаторы. Все они нацелены на уменьшение количества общений с БД (количество round-trip-ов). Давайте посмотрим на них чуть подробнее:
- none — без оптимизаций. за каждым id дергаем sequence.
- pooled и pooled-lo — в этом случае наш сиквенс должен увеличиваться на некий интервал — N в БД(SequenceGenerator.allocationSize). А в приложении у нас появляется некий pool, значения из которого который мы можем присваивать новым сущностям не обращаясь к БД..
- hilo — для генерации ID алгоритм hilo использует 2 числа: hi (хранится в БД — значение, полученное от вызова sequence) и lo(хранится только в приложении — SequenceGenerator.allocationSize). На основе этих чисел интервал для генерации id рассчитывается так: [(hi — 1) * lo + 1, hi * lo + 1). По понятным причинам этот алгоритм считается устарелым и использовать его не рекомендуется.
Теперь давайте разберемся, как выбирается оптимизатор. У hibernate есть несколько генераторов sequence. Нам будет интересно 2 из них:
- SequenceHiLoGenerator — старый генератор, который использует hilo оптимизатор. Выбирается по-умолчанию, если у нас свойство hibernate.id.new_generator_mappings == false.
- SequenceStyleGenerator — используется по-умолчанию (если свойство hibernate.id.new_generator_mappings == true). Этот генератор поддерживает несколько оптимизаторов, но по-умолчанию используется pooled.
Так же настроить генератор можно аннотацией @GenericGenerator.
Deadlock
Давайте разберем на примере псевдокода ситуацию, которая может привести к deadlock-у:
Thread #1: update entity(id = 3) update entity(id = 2) update entity(id = 1) Thread #2: update entity(id = 1) update entity(id = 2) update entity(id = 3)
Для предотвращения таких проблем у hibernate есть механизм, который позволяет избежать deadlock-ов такого типа — параметр hibernate.order_updates. В этом случае все update-ы будут упорядочены по id и выполнены. Также еще раз упомяну, что hibernate старается “отсрочить” захват коннекшена и выполнение insert-ов и update-ов.
Set, Bag, List
В hibernate есть 3 основных способа представить коллекцию связи OneToMany.
- Set — неупорядоченное множество сущностей без повторений;
- Bag — неупорядоченное множество сущностей;
- List — упорядоченное множество сущностей.
Для Bag в java core нет класса, который бы описывал такую структуру. Поэтому все List и Collection — являются bag-ом если не указана колонка, по которой наша коллекция будет сортироваться(аннотация OrderColumn. Не путать с SortBy). Использовать аннотацию OrderColumn крайне не рекомендую в силу плохой (на мой взгляд) реализации фичи — не оптимальные sql запросы, возможное наличие NULL-ов в листе.
Возникает вопрос, а что все-таки лучше использовать bag или set? Начнем с того, что при использовании bag-а возможны следующие проблемы:
- Если ваша версия hibernate ниже 5.0.8, то существует довольно серьезный баг — HHH-5855 — при инсерте дочерней сущности возможно ее дублирование (в случае cascadType=MERGE and PERSIST);
- Если вы используете bag для отношения ManyToMany, то hibernate генерирует крайне не оптимальные запросы при удалении сущности из коллекции — он сначала удаляет все строки из связывающей таблицы, а потом выполняет insert;
- Hibernate не может выполнить одновременный fetch нескольких bag-ов для одной сущности.
В случае, когда вы хотите добавить к связи @OneToMany еще одну сущность, выгоднее использовать Bag, т.к. он для этой операции не требует загрузки всех связанных сущностей. Давайте посмотрим пример:
// используем bag spaceCraft.getCrew().add( luke ); // весь экипаж не загружается из бд // используем set spaceCraft.getCrew().put( luke ); // весь экипаж загружается из бд // хотя вышеописанный вариант связывания мне не очень нравится. На мой взгляд связь ManyToOne удобнее указывать так: luke.setCurrentSpaceCraft( spaceCraft );
Сила References
Reference — это ссылка на объект, загрузку которого мы решили отложить. В случае отношения ManyToOne с fetchType=LAZY, мы получаем такой reference. Инициализация объекта происходит в момент обращения к полям сущности, за исключением id (т.к. значение этого поля нам известно).
Стоит отметить, что в случае Lazy Loading-а reference всегда ссылается на существующую строку в БД. Именно по этой причине большинство случаев Lazy Loading-а в отношениях OneToOne не работает — hibernate необходимо сделать JOIN для проверки существования связи и JOIN уже был, то hibernate загружает его в объектную модель. Если же мы укажем в OneToOne связи nullable=true, то LazyLoad должен заработать.
Мы можем и самостоятельно создать reference, используя метод em.getReference. Правда в таком случае нет гарантии, что reference ссылается на существующую строку в БД.
Давайте приведем пример использования такой ссылки:
// используем bag spaceCraft.getCrew().add( em.getReference( User.class, 1L ) ); // весь экипаж не загружается из бд, пользователь тоже не будет загружен
На всякий случай напомню, что мы получим LazyInitializationException в случае закрытого EM-а или отсоединенной(detached) ссылки.
Дата и время
Не смотря на то что в java 8 появилось прекрасное API для работы с датой и временем, JDBC API по прежнему позволяет работать только со старым API дат. Поэтому разберем некоторые интересные моменты.
Во-первых, нужно четко понимать отличия LocalDateTime от Instant и от ZonedDateTime. (Не буду растягивать, а приведу отличные статьи на эту тему: первая и вторая)
Если вкратце
LocalDateTime и LocalDate представляют обычный кортеж чисел. Они не привязаны к конкретному времени. Т.е. время посадки самолета хранить в LocalDateTime нельзя. А дату рождения через LocalDate вполне нормально. Instant же представляет точку во времени, относительно которой мы можем получить локальное время в любой точке на планете.
Более интересный и важный момент — как даты сохраняется в базу данных. Если у нас проставлен тип TIMESTAMP WITH TIMEZONE то проблем быть не должно, если же стоит TIMESTAMP (WITHOUT TIMEZONE) то есть вероятность, что дата запишется/прочитается неверная. (за исключением LocalDate и LocalDateTime)
Давайте разберемся почему:
Когда мы сохраняем дату, используется метод со следующей сигнатурой:
setTimestamp(int i, Timestamp t, java.util.Calendar cal)
Как видим тут используется старое API. Дополнительный аргумент Calendar нужен для того, чтобы преобразовать timestamp в строковое представление. т.е он хранит в себе timezone-у. Если Calendar не передается, то используется Calendar по-умолчанию с таймзоной JVM.
Решить эту проблему можно 3 способами:
- Устанавливать нужную timezone JVM
- Использовать параметр hibernate — hibernate.jdbc.time_zone (добавлена в 5.2) — починит только ZonedDateTime и OffsetDateTime
- Использовать тип TIMESTAMP WITH TIMEZONE
Интересный вопрос, почему LocalDate и LocalDateTime не подпадают под такую проблему?
Ответ
Для ответа на этот вопрос нужно понимать структуру класса java.util.Date (java.sql.Date и java.sql.Timestamp его наследники и их отличия в данном случае нас не волнуют). Date хранит дату в миллисекундах c 1970 года грубо говоря в UTC, но метод toString преобразует дату согласно системной timeZone.
Соответственно, когда мы получаем из базы данных дату без таймзоны, она отображатеся в объект Timestamp, так чтобы метод toString отобразил ее желаемое значение. При этом количество миллисекунд с 1970-го года может отличаться (в зависимости от временной зоны). Именно поэтому только локальное время отображается всегда корректно.
Также привожу в пример код, ответственный за преобразование Timesamp в LocalDateTime и Instant:
Соответственно, когда мы получаем из базы данных дату без таймзоны, она отображатеся в объект Timestamp, так чтобы метод toString отобразил ее желаемое значение. При этом количество миллисекунд с 1970-го года может отличаться (в зависимости от временной зоны). Именно поэтому только локальное время отображается всегда корректно.
Также привожу в пример код, ответственный за преобразование Timesamp в LocalDateTime и Instant:
// LocalDateTime LocalDateTime.ofInstant( ts.toInstant(), ZoneId.systemDefault() ); // Instant ts.toInstant();
Batching
По-умолчанию запросы отправляются в БД по одному. При включении batching-а hibernate сможет в одном запросе к БД отправлять несколько statement-ов. (т.е. batching сокращает количество round-trip-ов к БД)
Для этого необходимо:
- Включить batching и задать максимальное количество statement-ов:
hibernate.jdbc.batch_size (Рекомендуется от 5 до 30) - Включить сортировку insert-ов и update-ов:
hibernate.order_inserts
hibernate.order_updates
- Если мы используем версионирование, то нам также нужно включить
hibernate.jdbc.batch_versioned_data — тут будьте аккуратны, нужно чтобы jdbc driver умел отдавать количество строк, затронутых при update-е.
Так же напомню, про эффективность операции em.clear() — она отвязывает сущности от em-а, тем самым вы освобождаете память и сокращаете время на операцию dirty checking.
Если мы используем postgres, то можно так же сказать hibernate использовать multi-raw insert.
N+1 проблема
Это достаточно изъезженная тема, поэтому пробежимся по ней быстро.
N+1 проблема — это ситуация, когда вместо одного запроса на выбор N книг происходит по меньшей мере N+1 запрос.
Самый простой способ решения N+1 проблемы это сделать fetch связанных таблиц. В этом случае у нас может возникнуть несколько других проблем:
- Пагинация. в случае отношений OneToMany hibernate не сможет указать offset и limit. Поэтому пагинация будет происходить in-memory.
- Проблема декартова произведения — это ситуация, когда на выбор N книг с M главами и K авторами база данных возвращает N*M*K строк.
Есть и другие способы решения N+1 проблемы.
- FetchMode — позволяет изменить алгоритм загрузки дочерних сущностей. В нашем случае нас интересуют следующие:
- FetchType.SUBSELECT — загружает дочерние записи отдельным запросом. Минус в том, что вся сложность основного запроса повторяется в subselect-е.
- BATCH (FetchType.SELECT + аннотация BatchSize) — так же загружает записи отдельным запросом, но вместе subquery делает условие типа WHERE parent_id IN (?, ?, ?, …, N)
- JPA EntityGraph и Hibernate FetchProfile — позволяют вынести правила загрузки сущностей в отдельную абстракцию — на мой взгляд обе реализации неудобны.
Тестирование
В идеале development окружение должно предоставлять как можно больше полезной информации о работе hibernate и о взаимодействии с БД. А именно:
- Логирование
- org.hibernate.SQL: debug
- org.hibernate.type.descriptor.sql: trace
- Статистика
- hibernate.generate_statistics
Из полезных утилит можно выделить следующее:
- DBUnit — позволяет описывать состояние БД в XML формате. Иногда бывает удобно. Но лучше еще раз подумайте надо ли оно вам.
- DataSource-proxy
- p6spy — одно из самых старых решений. предлагает расширенное логирование запросов, время выполнения, итд
- com.vladmihalcea:db-util:0.0.1 — удобная утилита для поиска N+1 проблем. Также она позволяет логировать запросы. В состав входит интересная аннотация Retry, которая повторяет попытку выполнить транзакцию в случае OptimisticLockException.
- Sniffy — позволяет сделать assert на количество запросов через аннотацию. В некотором плане изящнее, чем решение от Влада.
Но еще раз повторюсь, что это только для development, на production это включать не стоит.
Литература
- Доклад Николая Алименков — Сделаем Hibernate снова быстрым — именно этот доклад меня вдохновил изучить hibernate глубже. Ниже представлены ресурсы, которые я использовал.
- Книга “Java Persistence API и Hibernate”
- Официальная документация
- Блог Влада М.
- Java Weakly Digest — ежедневный дайджест (косвенно относится к теме)

