Привет, как вы уже поняли, это продолжение моей истории реверс-инжиниринга и портирования «Нейроманта».

Реверсим «Нейроманта». Часть 1: Спрайты
Реверсим «Нейроманта». Часть 2: Рендерим шрифт
Реверсим «Нейроманта». Часть 3: Добили рендеринг, делаем игру
Сегодня начнём с двух хороших новостей:
- во-первых, я больше не один — к проекту присоединился и уже успел внести ощутимый вклад пользователь viiri;
- во-вторых, теперь у нас есть открытый репозиторий на github.
В целом, дела идут очень неплохо и, возможно, скоро мы получим хоть сколько-то играбельный билд. А под катом, как обычно, поговорим о том, чего и каким образом удалось достичь на текущий момент.
Начал разбираться со звуком. Увы, но среди игровых ресурсов не оказалось ничего похожего на аудио, а поскольку я понятия не имел, как музыка работает в MS-DOS, было крайне непонятно, с чего начать. Почитав немного про всякие SoundBlaster-ы, лучшее, что я придумал, это скроллить дизассемблированный код в надежде увидеть какие-нибудь знакомые сигнатуры. А кто ищет, тот обычно находит, даже если и не совсем то, что искал (комментарии проставлены Идой):
sub_20416: ... mov ax, [si+8] out 42h, al ; 8253-5 (AT: 8254.2). mov al, ah out 42h, al ; Timer 8253-5 (AT: 8254.2). mov bx, [si+0Ah] and bl, 3 in al, 61h ; PC/XT PPI port B bits: ; 0: Tmr 2 gate ═╦═► OR 03H=spkr ON ; 1: Tmr 2 data ═╝ AND 0fcH=spkr OFF ; 3: 1=read high switches ; 4: 0=enable RAM parity checking ; 5: 0=enable I/O channel check ; 6: 0=hold keyboard clock low ; 7: 0=enable kbrd and al, 0FCh or al, bl out 61h, al ; PC/XT PPI port B bits: ; 0: Tmr 2 gate ═╦═► OR 03H=spkr ON ; 1: Tmr 2 data ═╝ AND 0fcH=spkr OFF ; 3: 1=read high switches ; 4: 0=enable RAM parity checking ; 5: 0=enable I/O channel check ; 6: 0=hold keyboard clock low ; 7: 0=enable kbrd
Прогуглив этот Timer 8253-5 я набрёл на статью, ставшую первым ключом к пониманию происходящего. Ниже я постараюсь объяснить, что к чему.
Так вот, в эпоху IBM-PC, до появления доступных звуковых карт, наиболее распространённым устройством воспроизведения звука был так называемый PC Speaker, также известный как «бипер». Это устройство есть не что иное, как обычный динамик, подключавшийся к материнской плате, в большинстве случаев, через четырёхпиновый разъём. Бипер, по задумке, позволял воспроизводить двухуровневый прямоугольный импульс (соответствующий двум уровням напряжения, обычно это 0V и +5V) и управлялся через 61-й порт контроллера PPI (Programmable Peripheral Interface). Конкретно за управление «спикером» отвечают первые два бита посылаемого в порт значения (смотри комментарии к строкам in al, 61h и out 61h, al).
Как я уже сказал (немного другими словами), наш динамик может находиться в двух состояниях — «in» и «out» («low»-«high», «off»-«on», «выкл»-«вкл», как угодно). Для создания одного импульса, необходимо изменить текущее состояние на противоположное и, через некоторое время, обратно. Это можно сделать напрямую, манипулируя первым битом (считаем с нуля) 61-го порта, например, так:
PULSE: in al, 61h ; получаем исходное значение and al, 11111100b ; зануляем первые два бита... or al, 00000010b ; и устанавливаем первый в единицу... ; ВАЖНО, что нулевой бит должен быть установлен в 0 out 61h, al ; пишем значение в 61-й порт mov cx, 100 ; заводим цикл DELAY: loop DELAY ; ждём некторое время in al, 61h ; получаем исходное значение and al, 11111100b ; зануляем первые два бита out 61h, al ; пишем значение в 61-й порт
Результат выполнения этого кода будет выглядеть cледующим образом:
loop DELAY +5V +----------------------+ ! ! 0V ---+ +-------------------------- or al, 00000010b and al, 11111100b out 61h, al out 61h, al
Повторяя PULSE с задержкой, мы получим прямоугольный сигнал:
mov dx, 100 ; генерируем 100 импульсов PULSE: ... mov cx, 100 WAIT: loop WAIT dec dx jnz PULSE PULSE +5V +---------+ +---------+ +---------+ ! ! ! ! ! ! 0V ---+ +---------+ +---------+ +--- loop WAIT
Если в первом случае мы бы вряд ли что-нибудь услышали, то во втором мы получим тон частоты, зависящей от скорости машины, на которой выполняется этот код. Это здорово, но связано с определёнными сложностями. В любом случае, есть и более удобный способ управления динамиком.
Тут в игру вступает программируемый трёхканальный таймер — Intel 8253, второй канал которого (начиная с нулевого) подключен к биперу. Этот таймер принимает сигнал от микросхемы тактового генератора Intel 8254, посылающей 1193180 импульсов в секунду (~1.193 МГц), и может быть запрограммирован на определённую реакцию по истечении задаваемого количества импульсов. Одна из таких реакций — отправка прямоугольного импульса на динамик. Иными словами, 8253 может работать в режиме генератора прямоугольного сигнала регулируемой частоты, это позволяет относительно просто синтезировать на спикере различные звуковые эффекты. И вот, что для этого нужно:
- Установить второй канал таймера в режим генерации прямоугольного сигнала. Для этого нужно записать специальное однобайтовое значение в порт 43 (8253 Mode/Command register). В моём случае — это
10110110B(подробнее здесь):
Bits Usage 6 and 7 Select channel : 1 0 = Channel 2 4 and 5 Access mode : 1 1 = Access mode: lobyte/hibyte 1 to 3 Operating mode : 0 1 1 = Mode 3 (square wave generator) 0 BCD/Binary mode: 0 = 16-bit binary
Задать на втором канале нужную частоту. Для этого побайтно, от младшего к старшему, отправляем в 42-й порт (8253 Channel 2 data port) значение, равное
1193180 / freq, гдеfreq— это требуемое значение частоты в Герцах.
Позволить динамику принимать импульсы от таймера. Для этого устанавливаем в единицу первые два бита значения в порту 61 (PPI). Дело в том, что, если нулевой бит установлен в 1, то первый интерпретируется как «переключатель»:
Bit 0 Effect ----------------------------------------------------------------- 0 The state of the speaker will follow bit 1 of port 61h 1 The speaker will be connected to PIT channel 2, bit 1 is used as switch ie 0 = not connected, 1 = connected.
В итоге, имеем следующую картину:
mov al, 10110110b out 43h, al ; инициализируем таймер mov ax, 02E9Bh ; 1193180 / 100Гц = ~0x2E9B out 42h, al ; пишем младший байт делителя частоты mov al, ah out 42h, al ; пишем старший байт делителя частоты in al, 61h ; получаем исходное значение or al, 00000011b ; устанавливаем первые два бита в 1 out 61h, al ; включаем динамик ... ; некоторое время слушаем тон на частоте ~100 Гц in al, 61h and al, 11111100b out 61h, al ; выключаем динамик
И это именно то, что делает код, который я привёл в самом начале (кроме инициализации, но её я нашёл в другой функции): по адресу si + 8 находится делитель частоты, отправляемый в 42-й порт, а по адресу si + 0Ah — состояние динамика («вкл»-«выкл»), записываемое в порт 61.
Механизм воспроизведения прост и понятен, но дальше нужно было разобраться с таймингами. Изучив близлежащий код, я увидел, что в той же функции, в которой инициализизируется таймер (sub_2037A, далее — init_8253), происходит подмена обработчика восьмого прерывания (Time of Day) на функцию sub_20416 (далее — play_sample). Вскоре выяснилось, что это прерывание генерируется примерно 18.2 раза в секунду и служит для обновления системного времени. Подмена обработчика этого прерывания — распространённая практика, если нужно выполнять некоторое действие 18 раз в секунду (на самом деле, внутри хука также необходимо вызывать оригинальный обработчик, иначе остановится системное время). Исходя из этого получается, что очередная частота заряжается в генератор каждые (1 / 18.2) * 1000 ~ 55мс.
План был такой:
- поставить брейкпоинт в функции
play_sample, на строчке, где извлекается очередной делитель частоты; - вычислить частоту по формуле
freq = 1193180 / divisor; - сгенерировать 55мс прямоугольного сигнала частоты
freqв каком-нибудь аудиоредакторе (я использовал Adobe Audition); - повторять первые три шага до накопления хотя бы 3-х секунд.
Так я получил начало мелодии из главного меню, но играющее раз эдак в 10 медленнее, чем нужно. Тогда я сократил длительность «сэмпла» с 55 мс до 5 мс — стало гораздо лучше, но всё ещё не то. Вопрос с таймингами оставался открытым, пока я не нашёл вот эту статью. Оказалось, что восьмое прерывание генерируется с подачи всё того же 8253, нулевой канал которого подключен к контроллеру прерываний (PIC). Во время загрузки машины BIOS настраивает нулевой канал на генерацию импульсов с частотой ~18.2 Гц (то есть прерывание генерируется каждые ~54.9 мс). Однако нулевой канал можно перепрограммировать так, чтобы он генерировал импульсы с большей частотой, для этого, по аналогии со вторым каналом, в 40-й порт нужно записать значение, равное 1193180 / freq, где freq — это требуемое значение частоты в Герцах. Это и происходит в функции init_8253, просто изначально я не обратил на это должного внимания:
init_8253: ... mov al, 0B6h ; 10110110b out 43h, al ; Timer 8253-5 (AT: 8254.2). mov ax, 13B1h out 40h, al ; Timer 8253-5 (AT: 8254.2). mov al, ah out 40h, al ; Timer 8253-5 (AT: 8254.2).
Значение 13B1h переводим в частоту: 1193180 / 13B1h ~ 236.7Гц, тогда получаем примерно (1 / 236.7) * 1000 ~ 4.2мс на «сэмпл». Пазл сложился.
Дальше уже дело техники — реализовать функцию, извлекающую звуковые дорожки из игры. Но вот в чём дело, значения делителей частоты, записываемые в 42-й порт, не хранятся в явном виде. Они вычисляются неким хитрым алгоритмом, входные данные и рабочая область которого лежат прямо в исполняемом файле игры (в седьмом сегменте по версии Иды). Ещё, из особенностей, здесь не предусмотрено признака окончания трека, когда играть больше нечего, алгоритм бесконечно выдаёт нулевое состояние динамика. Но я не стал заморачиваться и, как и в случае с алгоритмом декомпрессии (первая часть), просто портировал на 64-битный ассемблер функцию установки трека на воспроизведение и алгоритм получения очередной частоты (а седьмой сегмент я забрал целиком).
И это сработало. После, я реализовал функции генерации звуковой дорожки для выбранного трека (PCM, 44100 Hz, 8 bit, mono; сделал нечто наподобие генератора, используемого в эмуляторе спикера в DosBox). Проблему с признаком окончания я решил простым счётчиком тишины: насчитали секунду — завершаем алгоритм. Завернув полученную дорожку в WAV-заголовок и сохранив результат в файл, я получил в точности трек из главного меню. И ещё 13 треков, которые вы можете прослушать ниже [или в просмотрщике ресурсов, в котором теперь есть встроенный плеер и возможность сохранить любой трек в .WAV]:
[Изучая вопрос, я узнал и про более продвинутые техники «игры на бипере», вроде использования широтно-импульсной модуляции для низкокачественного воспроизведения PCM-звука. В конце этой статьи я приведу список материалов, из которых можно узнать больше.]
Во второй части, когда рассматривались различные форматы ресурсов, я предположил, что в .ANH-файлах лежат анимации для бэкграундов локаций (то есть для изображений, хранящихся в .PIC). [Это так.] Закончив со звуком, я решил это проверить. Чисто исходя из предположения, что анимация применяется прямо на изображение задника, хранящееся в памяти (не в видеопамяти, а в спрайт-чейне), я решил сделать дампы этой памяти соответственно до и после применения анимации (смотрим туда, куда указывает курсор — на верхнюю строку буквы 'S'):



3DE6:0E26 03 B4 44 B3 ... ; первый кадр 3DE6:0E26 03 BC CC B3 ... ; второй кадр
Именно то, чего я ожидал — тёмно-красный цвет (0x4) сменился на ярко-красный (0xC). Теперь можно попробовать поставить брейкпоинт на изменение значения по адресу, например, 3DE6:0E28 и, если повезёт, провести обратную трассировку. [Мне повезло.] Точка останова привела меня к строке, непосредственно изменяющей значение по заданному адресу: xor es:[bx], al. Осмотрев окресности, я без особого труда построил цепочку вызовов от основного цикла уровня до этого момента: sub_1231E (xor es:[bx], al) <- sub_12222 <- sub_105F6 <- sub_1038F (основной цикл).
Я уже не буду вдаваться в подробности о том, как именно я реверсил процесс анимирования. Это достаточно рутинная и методичная работа, однако не очень сложная, если чётко очерчены границы (полученный бэктрейс и есть эти границы). Но я не могу не рассказать о том, что же получилось в итоге.
Сперва об .ANH-формате. По сути, он представляет из себя набор контейнеров, и первым вордом в .ANH-файле идёт количество контейнеров внутри:
typedef struct anh_hdr_t { uint16_t anh_entries; /* first entry hdr */ } anh_hdr_t;
Сам по себе контейнер — это отельно взятая анимация элемента заднего фона. У контейнера можно выделить заголовок, содержащий его байтовый размер и количество кадров в анимации, которую он представляет. Следом за заголовком попарно идут значения длительности (задержки) очередного кадра и смещение байтов самого кадра, относительно байтов первого кадра. Количество таких пар, очевидно, равно количеству кадров:
typedef struct anh_entry_hdr_t { uint16_t entry_size; uint16_t total_frames; /* anh_frame_data_t first_frame_data */ /* another frames data */ /* anh_frame_hdr first_frame_hdr */ /* another frames */ } anh_entry_hdr_t; typedef struct anh_frame_data_t { uint16_t frame_sleep; uint16_t frame_offset; } anh_frame_data_t; ... extern uint8_t *anh; anh_hdr_t *hdr = (anh_hdr_t*)anh; anh_entry_hdr_t *entry = (anh_entry_hdr_t*)(anh + sizeof(anh_hdr_t)); for (uint16_t u = 0; u < anh->anh_entries; u++) { uint8_t *p = (uint8_t*)entry; anh_frame_data_t *first_frame_data = (anh_frame_data_t*)(p + sizeof(anh_entry_hdr_t)); uint8_t *first_frame_bytes = p + (entry->total_frames * sizeof(anh_frame_data_t)); for (uint16_t k = 0; k < entry->total_frames; k++) { anh_frame_data_t *frame_data = first_frame_data + k; uint8_t *frame_bytes = first_frame_bytes + frame_data->frame_offset; ... } /* plus 2 bytes of padding */ p += (entry->entry_size + 2); entry = (anh_entry_hdr_t*)p; }
Отдельный же кадр состот из четырёхбайтного заголовка, содержащего его линейные размеры и смещения относительно изображения заднего фона, и пикселей кадра, закодированных уже знакомым мне Run Length алгоритмом:
typedef struct anh_frame_hdr { uint8_t bg_x_offt; uint8_t bg_y_offt; uint8_t frame_width; uint8_t frame_height; /* rle encoded frame bytes */ };
«Наложение» кадра на задник может выглядеть следующим образом:
extern uint8_t *level_bg; uint8_t frame_pix[8192]; anh_frame_hdr *hdr = (anh_frame_hdr*)frame_bytes; uint16_t frame_len = hdr->frame_width * hdr->frame_height; decode_rle(frame + sizeof(anh_frame_hdr), frame_len, frame_pix); /* 0xFB4E - some magic value, have no idea what is it */ uint16_t bg_offt = (hdr->bg_y_offt * 152) + hdr->bg_x_offt + 0xFB4E; uint16_t bg_skip = 152 - hdr->frame_width; uint8_t *p1 = frame_pix, *p2 = level_bg; for (uint16_t i = hdr->frame_height; i != 0; i--) { for (uint16_t j = hdr->frame_width; j != 0; j--) { *p2++ ^= *p1++; } p2 += bg_skip; }
Таков .ANH-формат, но есть ещё одна структура, заставляющая всё это работать:
typedef struct bg_animation_control_table_t { uint16_t total_frames; uint8_t *first_frame_data; uint8_t *first_frame_bytes; uint16_t sleep; uint16_t curr_frame; } bg_animation_control_table_t;
В самой игре глобально объявлен массив как минимум из четырёх структур такого вида. После загрузки очередного .ANH-файла, количество анимаций внутри также сохраняется в глобальную переменную, а элементы массива инициализируются следующим образом:
extern uint8_t *anh; uint16_t g_anim_amount = 0; bg_animation_control_table_t g_anim_ctl[4]; ... anh_hdr_t *hdr = (anh_hdr_t*)anh; anh_entry_hdr_t *entry = (anh_entry_hdr_t*)(anh + sizeof(anh_hdr_t)); g_anim_amount = hdr->anh_entries; for (uint16_t u = 0; u < g_anim_amount; u++) { uint8_t *p = (uint8_t*)entry; g_anim_ctl[u].total_frames = entry->total_frames; g_anim_ctl[u].first_frame_data = p + sizeof(anh_entry_hdr_t); g_anim_ctl[u].first_frame_bytes = g_anim_ctl[u].first_frame_data + (entry->total_frames * sizeof(anh_frame_data_t)); g_anim_ctl[u].sleep = *(uint16_t*)(g_animation_control[u].first_frame_data); g_anim_ctl[u].curr_frame = 0; /* plus 2 bytes of padding */ p += (entry->entry_size + 2); entry = (anh_entry_hdr_t*)p; }
Наконец, применяем анимации:
for (uint16_t u = 0; u < g_anim_amount; u++) { bg_animation_control_table_t *anim = &g_anim_ctl[u]; if (anim->sleep-- == 0) { anh_frame_data_t *data = (anh_frame_data_t*)anim->first_frame_data + anim->curr_frame; /* Накладываем очередной кадр */ ... if (++anim->curr_frame == anim->total_frames) { anim->curr_frame = 0; data = (anh_frame_data_t*)anim->first_frame_data; } else { data++; } anim->sleep = data->frame_sleep; } }
И получаем следующее [гораздо больше можно посмотреть в просмотрщике ресурсов]:
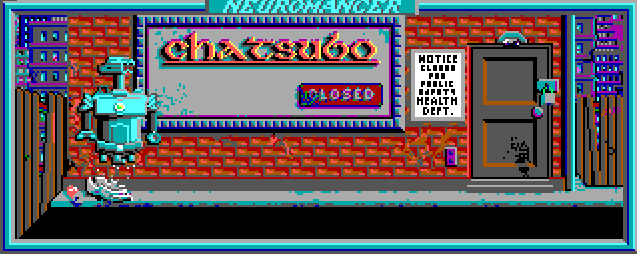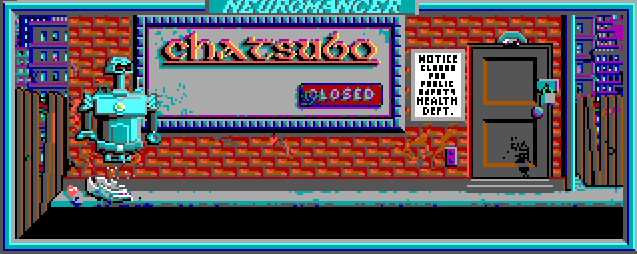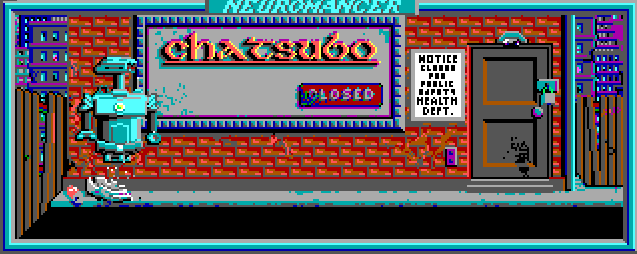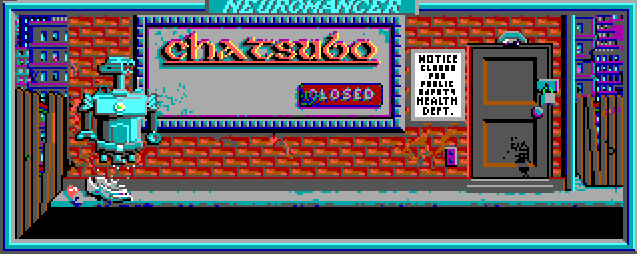

На данный момент с анимацией есть пара проблем. Первая заключается в том, что в своём коде я проигрываю все имеющиеся анимации, однако оригинал проверяет некие глобальные флаги, указывающие нужно ли прокручивать очередную. И вторая, связанная с тем, что некоторые анимации добавляют на экран объекты, которых изначально там нет. А поскольку кадры «ксорятся» на бэкграунд, то при циклическом прокручивании, на каждом втором круге объект просто пропадает. Вот, например, как это может выглядеть:

Но пока оставим всё как есть.
Помните неизвестный алгоритм декомпрессии из первой части? Едва только подключившись к разработке, viiri не только определил, что именно это за алгоритм, но и написал свой вариант декодера, заменивший в кодовой базе ужасный трёхсотстрочный кусок Ассемблера. В связи с этим, я попросил viiri написать небольшой очерк о проделанной работе. Что и было сделано, но перед тем, как я его приведу, пару слов нужно сказать о теории.
Для сжатия ресурсов разработчики «Нейроманта» использовали код Хаффмана. Это один из первых эффективных методов кодирования информации, использующий префиксные коды. В теории кодирования префиксными называют коды со словом переменной длины и такие, в которых ни одно кодовое слово не является префиксом другого. То есть, если в состав префиксного кода входит слово «a», то слова «ab» в коде не существует. Это свойство позволяет однозначно разбивать на слова сообщение, закодированное таким кодом.
Идея алгоритма Хаффмана состоит в том, что, зная вероятности появления символов некоторого алфавита в сообщении, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью появления ставятся в соответствие более короткие коды, а символам с меньшей вероятностью — наоборот, более длинные. В целом, процедура кодирования сводится к построению оптимального кодового дерева и, на его основе, отображению символа сообщения на соответствующий код. Свойство префиксности полученного кода позволяет однозначно декодировать сжатое им собщение.
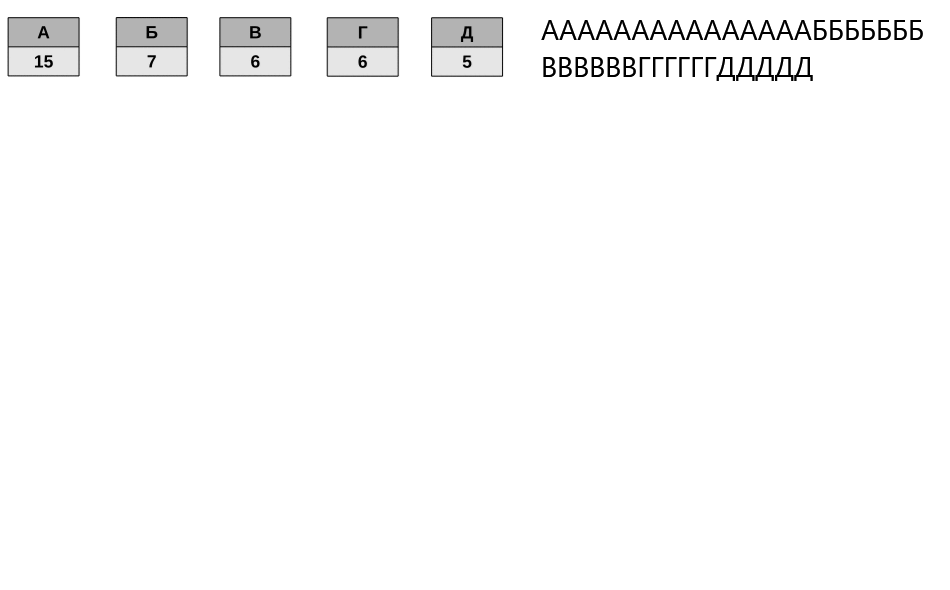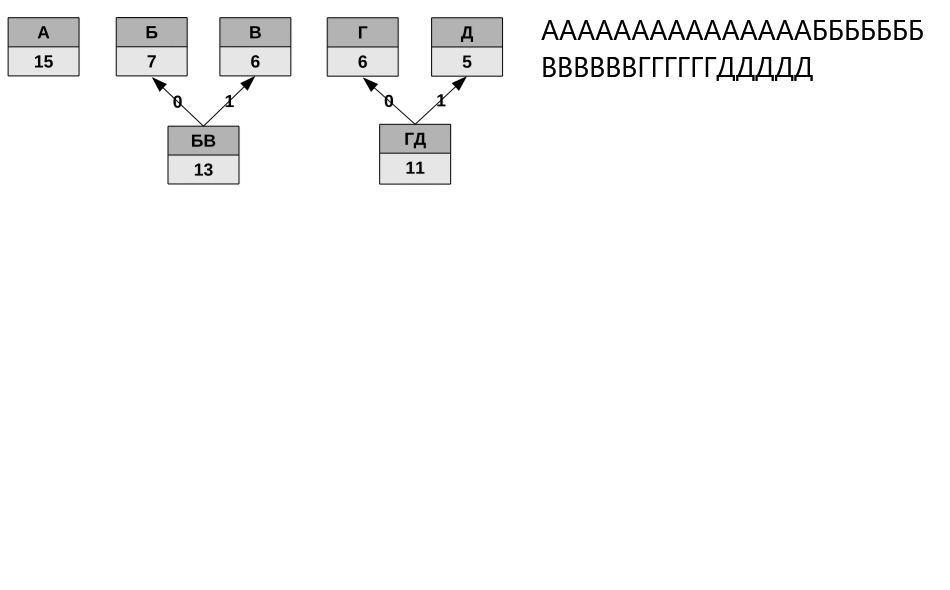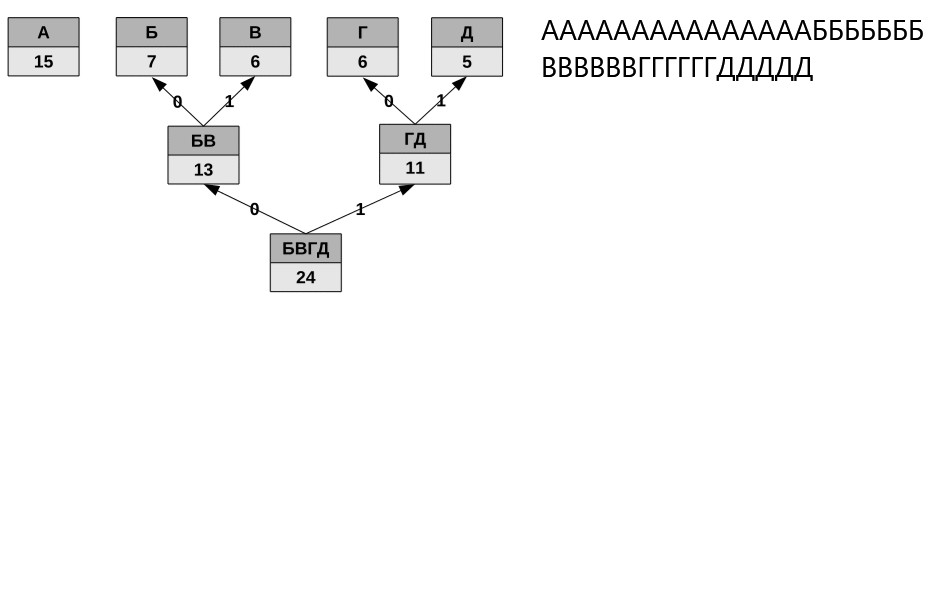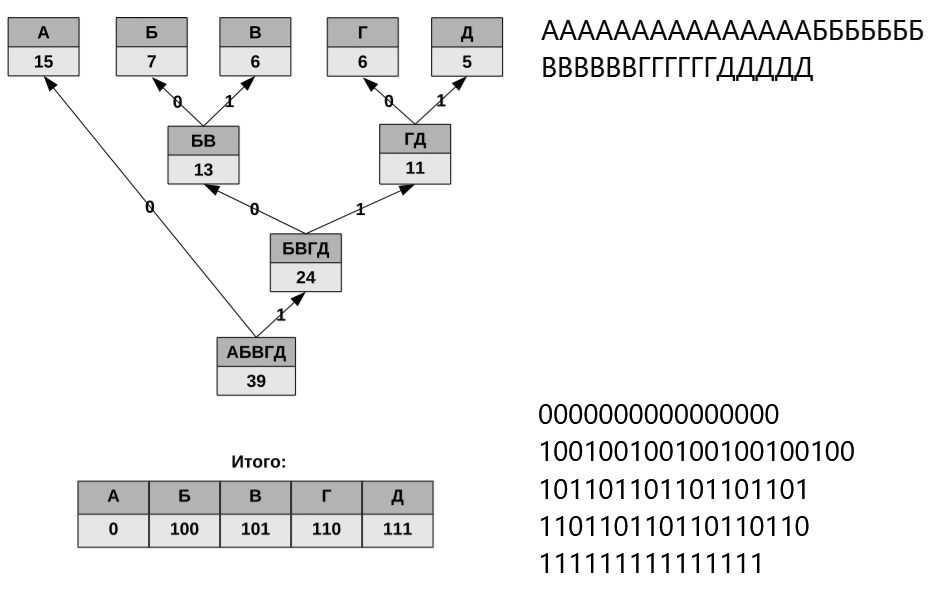
У алгоритма есть один существенный недостаток (на самом деле не один, но сейчас важен только этот). Дело в том, что для того, чтобы восстановить содержимое сжатого сообщения, декодер должен знать таблицу частот появления символов, которой пользовался кодер. В связи с этим, вместе с закодированным сообщением должна передаваться либо таблица вероятностей, либо само кодовое дерево (вариант, используемый в игре). Размеры дополнительных данных могут быть относительно велики, а это существенно бъёт по эффективности сжатия.
Кое-что о том, как с этим можно бороться, а так же про свой декодер и тот, который реализован в игре, рассказывает viiri:
Сразу стоит упомянуть, что вся игра была полностью написана на Ассемблере, руками, поэтому код содержит интересные решения, трюки и оптимизации.
По процедурам. Функцияsub_1ff94(build_code_table) нужна для загрузки из файла сжатого дерева Хаффмана. Для декодирования статического Хаффмана (бывает и динамический, и на него это требование не распространяется) вместе с сообщением нужно передать кодовое дерево, которое представляет из себя сопоставление кодов Хаффмана реальным кодам символов. Это дерево достаточно большое и поэтому неплохо бы и его как-нибудь эффективно хранить. Наиболее правильный способ — использование канонических кодов (MOAR). Благодаря их свойствам, существует очень интересный и эффективный способ хранения дерева (используется в реализации метода сжатия Deflate архиватора PKZip). Но в игре канонические коды не используются, вместо этого осуществляется прямой обход дерева и для каждой вершины в выходной поток записывается бит 0, если узел не является листом, или бит 1, если узел является листом, и тогда следующие 8 бит являются кодом символа в этом узле. При декодировании осуществляется аналогичный обход дерева, который мы и видим в игре. Тут есть пример и некоторое объяснение.
build_code_table proc near call getbit ; читаем бит из потока jb short loc_1FFA9 ; нашли листовой узел... shl dx, 1 inc bx call build_code_table ; вызываем build_code_table для левого поддерева or dl, 1 call build_code_table ; вызываем build_code_table для правого поддерева shr dx, 1 dec bx ret loc_1FFA9: call sub_1FFC2 ; читаем код символа из потока (8 бит) ... ; сохраняем значение в таблице ret sub_1FF94 endp sub_1FFC2 proc near sub di, di mov ch, 8 loc_1FFC6: call getbit rcl di, 1 dec ch jnz short loc_1FFC6 retn sub_1FFC2 endp
getbit(sub_1ffd0) осуществляет чтение бита из потока входных данных. Её анализ позволяет заключить, что отдельные биты выделяются из 16-битного регистраax, значение в который загружается из памяти инструкциейlodsw, которая грузит два байта из потока, но так как процессор Intel имеет порядок байт little-endian, тоxchgпереставляет половины регистра. Далее, порядок битов в потоке на вид несколько нелогичен — первым является не младший, а старший бит. Это сделано потому, что инструкцияshlвыталкивает старший бит во флаг переноса, который потом удобно проверять командой условного переходаjb.
getbit proc near or cl, cl jz short loc_1FFD9 dec cl shl ax, 1 retn loc_1FFD9: cmp si, 27B6h jz short loc_1FFE7 ; закончились данные lodsw xchg al, ah mov cl, 0Fh shl ax, 1 retn loc_1FFE7: call sub_202FC ; дочитываем из файла очередную порцию lodsw xchg al, ah mov cl, 0Fh shl ax, 1 retn getbit endp
На этой основе viiri реализовал простой, но отлично работающий декодер:
typedef struct node_t { uint8_t value; struct node_t *left, *right; } node_t; static uint8_t *g_src = NULL; static int getbits(int numbits) { ... } static uint32_t getl_le() { /* размер декодированного файла хранится в первых 4-х байтах входного потока */ } static node_t* build_tree(void) { node_t *node = (node_t*)calloc(1, sizeof(node_t)); if (getbits(1)) { node->right = NULL; node->left = NULL; node->value = getbits(8); } else { node->right = build_tree(); node->left = build_tree(); node->value = 0; } return node; } int huffman_decompress(uint8_t *src, uint8_t *dst) { int length, i = 0; node_t *root, *node; g_src = src; length = getl_le(); node = root = build_tree(); while (i < length) { node = getbits(1) ? node->left : node->right; if (!node->left) { dst[i++] = node->value; node = root; } } ... }
Однако в самой игре всё гораздо интереснее:
На самом делеbuild_code_tableрекурсивно строит таблицу Хаффмана. Это очень удобно при кодировании, потому что кодируемый символ является индексом этой самой таблицы, и за константное время для любого символа можно получить его префиксный код и длину этого кода. При декодировании таблица не эффективна, так как при получении из потока каждого бита необходимо перебирать все записи таблицы в поисках совпавшего кода. Для декодирования больше подходит дерево, так как с каждым новым битом из входного потока можно определять, в какой узел идти, и как только он окажется листом — символ декодирован (что и сделано вhuffman_decompress).
Зачем же тогда декодеру таблица? Правильно! Чтобы по ней построить ещё одну таблицу! Суть идеи проста, но несколько неочевидна. Алгоритм основан на свойстве префиксных кодов (условие Фано): никакое кодовое слово не может быть началом другого кодового слова. Допустим, что длина слова некоторого префиксного кода не превышает 3-х бит, в этом случае три бита входного потока содержат N бит кода, а (3 — N) бит являются началом следующего слова.
Возьмём следующий префиксный код для алфавита ABCD: A - 0b, B - 10b, C - 110b, D - 111b. Сдвинем коды символов до упора влево (в трёхбитном слове), и занесём в таблицу получившийся код, длину кода и соответсвующий символ:
| Код | Длина | Символ |
|---|---|---|
| 000b | 1 | A |
| 100b | 2 | B |
| 110b | 3 | C |
| 111b | 3 | D |
Считывая по три бита из входного потока, мы можем использовать итоговое значение как индекс в этой таблице для быстрого получения соответствующего символа. Но что, если, например, мы прочитаем из потока значение 010b — такого кода в таблице нет. И вот тут себя проявляет свойство префиксности. Ведь то, что символу 'A' соответсвует код 0b означает, что оставшимся символам алфавита не может соответствовать код, начинающийся с нулевого бита. Тогда таблица дополняется следующим образом:
| Индекс | Код | Длина | Символ |
|---|---|---|---|
| 0 | 000b | 1 | A |
| 1 | 001b | 1 | A |
| 2 | 010b | 1 | A |
| 3 | 011b | 1 | A |
| 4 | 100b | 2 | B |
| 5 | 101b | 2 | B |
| 6 | 110b | 3 | C |
| 7 | 111b | 3 | D |
Допустим, есть входная последовательность 011010111b:
- считываем три бита в буфер:
011b; - из таблицы, по индексу
011b (3), получаем символA, записываем его в выходной поток; - длина кода
011bпо таблице равна 1, значит, сдвигаем значение в буфере на один бит влево и дочитываем в освободившийся разряд один бит из потока:110b; - из таблицы, по индексу
110b (6), получаем символС, записываем его в выходной поток; - и так далее, пока входной поток не опустеет.
В «Нейроманте» в качестве индекса используется 8-битное значение. То есть генерируется таблица из 256 элементов. Однако максимальная длина слова в используемом коде значительно превышает 8 бит. В этом случае, с целью экономии памяти, используются подтаблицы:
В случае наличия кодов с длиной больше байта тоже всё просто: введём дополнительное поле в таблицу — номер подтаблицы, в которую нужно перейти для декодирования оставшейся части длинного кода. Чем длиннее коды, тем больше подтаблиц понадобится. Игра использует 4 — хватит для 32-битных кодов.
Вот примерно так работает декодер, представленный в игре. Дело закрыто.
Как и было сказано в самом начале, исходники проекта теперь доступны на github. Для просто интересующихся и тех, кто захочет принять участие в его развитии, я расскажу немного о том, что же всё-таки там лежит [немного подробнее, чем написано в README.md].
По факту, там лежат три проекта, объединённые в один солюшен 2015-й студии:
- LibNeuroRoutines (Си, MASM) — библиотека, вмещающая в себя различные алгоритмы общего назначения, реверснутые из оригинальной игры. Заголовочный файл библиотеки (
neuro_routines.h) постоянно пополняется и содержит все известные на сегодняшний день структуры данных, используемые в игре. Там же объявлены экспортируемые функции, реализующие:
- декомпрессию ресурсов (
huffman_decompression.c,decompression.c); - работу с текстом (
cp437.c); - работу с диалоговыми окнами (
dialog.c); - работу со звуком (
audio.c).
- декомпрессию ресурсов (
- NeuromancerWin64 (Си) — собственно движок и сама игра. На данный момент имеет мало общего с оригиналом в плане внутренней организации и является лишь прототипом. В дальнейшем планируется уточнять реализацию, сделав её максимально близкой к настоящему «Нейроманту», но с некоторыми допущениями, вроде плавной анимации и более удобного управления. В качестве мультимедийного бэкенда сейчас используется CSFML (биндинги SFML для языка C).
- ResourceBrowser (C++) — просмотрщик ресурсов. Представляет из себя MFC-приложение, позволяющее просматривать и экспортировать различные ресурсы из оригинальных .DAT-файлов. Прямо сейчас оно позволяет:
- просматривать и экспортировать в BMP (8bpp) графику (вкладки IMH, PIC);
- просматривать анимации (вкладка ANH);
- прослушивать и экспортировать в WAV (PCM, 44100Hz, 8bps, mono) аудиодорожки (вкладка SOUND).
Из вышеперечисленного только LibNeuroRoutines является самостоятельным проектом. Остальные зависят от LibNeuroRoutines и CSFML (в ResourceBrowser с помощью SFML сделан встроенный аудиоплеер).
Пока проект может работать только под 64-битной Windows и на то есть причина. Дело в том, что исходники LibNeuroRoutines содержат 64-битный MASM (Microsoft Macro Assembler). Этот код — куски листинга из дизассемблера, подогнанные до рабочего состояния на 64-битной системе. Да, я бы мог использовать кроссплатформенный NASM или FASM, но мне было важно, чтобы этот код без лишних телодвижений можно было отлаживать прямо в среде разработки. А поскольку я работаю в VS 2015 — MASM был единственной опцией.
На самом деле это временная мера, просто чтобы работало. В дальнейшем весь Ассемблер должен быть переписан на C. И как только это случится, уже ничего не будет препятствовать портированию проекта на другие платформы (кроме просмотрщика ресурсов, он на MFC).
Пока это всё, что я хотел рассказать по этому поводу. Если есть какие-либо вопросы, то я постараюсь на них ответить.
С выходом этой статьи я очень сильно опередил свой обычный темп. Когда следующая? Вероятно, не скоро. Сейчас мы планируем сосредоточиться на разработке и довести до ума те вещи, которые уже сделаны. Но если появятся что-то интересное, то мы обязательно об этом расскажем. Ниже, как я и обещал, список материалов по программированию спикера, а под ним небольшой опрос. До (не)скорого.

