Здравствуй, Хабр. Меня зовут Виталий Котов, я работаю в отделе тестирования компании Badoo. Я пишу много UI-автотестов, но ещё больше работаю с теми, кто занимается этим не так давно и ещё не успел наступить на все грабли.
Итак, сложив свой собственный опыт и наблюдения за другими ребятами, я решил подготовить для вас коллекцию того, «как писать тесты не стоит». Каждый пример я подкрепил подробным описанием, примерами кода и скриншотами.
Статья будет интересна начинающим авторам UI-тестов, но и старожилы в этой теме наверняка узнают что-то новое, либо просто улыбнутся, вспомнив себя «в молодости». :)
Поехали!

Начнём с простого примера. Так как мы говорим о UI-тестах не последнюю роль в них играют локаторы. Локатор — это строка, составленная по определённому правилу и описывающая один или несколько XML- (в частности HTML-) элементов.
Существует несколько видов локаторов. Например, css-локаторы используются для каскадных таблиц стилей. XPath-локаторы используются для работы с XML-документами. И так далее.
Полный список типов локаторов, которые используются в Selenium, можно найти на seleniumhq.github.io.
В UI-тестах локаторы используются для описания элементов, с которыми драйвер должен взаимодействовать.
Практически в любом инспекторе браузера есть возможность выбрать интересующий нас элемент и скопировать его XPath. Выглядит это примерно так:

Получается такой вот локатор:
Кажется, что ничего плохого в таком локаторе нет. Ведь мы его можем сохранить в какую-то константу или поле класса, которые своим названием будут передавать суть элемента:
И обернуть соответствующим текстом ошибки на случай, если элемент не найдётся:
У такого подхода есть плюс: отпадает необходимость изучать XPath.
Однако есть и ряд минусов. Во-первых, при изменении вёрстки нет гарантии, что элемент по такому локатору останется прежним. Вполне возможно, что на его место встанет другой, что приведёт к непредвиденным обстоятельствам. Во-вторых, задача автотестов — баги искать, а не следить за изменениями вёрстки. Следовательно, добавление какого-нибудь враппера или ещё каких-то элементов выше по дереву не должно затрагивать наши тесты. В противном случаем у нас будет уходить довольно много времени на актуализацию локаторов.
Вывод: следует составлять локаторы, которые корректно описывают элемент и при этом устойчивы к изменению вёрстки вне тестируемой части нашего приложения. Например, можно привязываться к одному или нескольким атрибутам элемента:
Такой локатор и воспринимать в коде проще, и сломается он только в том случае, если пропадёт «rel».
Ещё один плюс такого локатора — возможность поиска в репозитории шаблона с указанным атрибутом. А что искать, если локатор выглядит как в первоначальном примере? :)
Если изначально в приложении у элементов нет никаких атрибутов или они выставляются автоматически (например, из-за обфускации классов), это стоит обсудить с разработчиками. Они должны быть не менее заинтересованы в автоматизации тестирования продукта и наверняка пойдут вам навстречу и предложат решение.
У каждого пользователя Badoo есть свой профиль. На нём расположена информация о пользователе: (имя, возраст, фотографии) и информацию о том, с кем пользователь хочет общаться. Помимо этого, есть возможность указать свои интересы.
Предположим, однажды у нас был баг ( хотя, конечно, это не так :) ). Пользователь в своём профиле выбирал интересы. Не найдя подходящего интереса из списка, он решил кликнуть «Ещё», чтобы обновить список.
Ожидаемое поведение: старые интересы должны пропасть, новые — появиться. Но вместо этого выскочила «Непредвиденная ошибка»:
Оказалось, на стороне сервера возникла проблема, ответ пришёл не тот, и клиент это дело обработал, показав соответствующее уведомление.
Наша задача — написать автотест, который будет проверять этот кейс.
Мы пишем примерно следующий сценарий:
Такой тест мы и запускаем. Однако происходит следующее: через несколько дней/месяцев/лет баг снова появляется, хотя тест ничего не ловит. Почему?
Всё довольно просто: за время успешного прохождения теста локатор элемента, по которому мы искали текст ошибки, изменился. Был рефакторинг темплейтов и вместо класса «error» у нас появился класс «error_new».
Во время рефакторинга тест ожидаемо продолжал работать. Элемент “div.error” не появлялся, причины для падения не было. Но теперь элемента “div.error” вообще не существует — следовательно, тест не упадёт никогда, чтобы ни происходило в приложении.
Вывод: лучше тестировать работоспособность интерфейса позитивными проверками. В нашем примере стоило ожидать, что список интересов изменился.
Бывают ситуации, когда негативную проверку нельзя заменить позитивной. Например, при взаимодействии с каким-то элементом в «хорошей» ситуации ничего не происходит, а в «плохой» — появляется ошибка. В этом случае стоит придумать способ симулировать «плохой» сценарий и на него тоже написать автотест. Таким образом мы проверим, что в негативном кейсе элемент ошибки появляется, и тем самым будем следить за актуальностью локатора.
Как убедиться, что взаимодействие теста с интерфейсом прошло удачно и всё работает? Чаще всего это видно по изменениям, которые в этом интерфейсе произошли.
Рассмотрим пример. Необходимо убедиться, что при отправке сообщения оно появляется в чате:
Сценарий выглядит примерно так:
Такой сценарий мы и описываем в нашем тесте. Предположим, что сообщению в чате соответствует локатор:
Вот так мы проверяем, что элемент появился:
Если наш wait работает, то всё в порядке: сообщения в чате отрисовываются.
Как вы уже догадались, через какое-то время отправка сообщений в чате ломается, но наш тест продолжает работать без перебоев. Давайте разбираться.
Оказывается, накануне в чате появился новый элемент: некий текст, который предлагает пользователю подсветить сообщение, если оно вдруг осталось незамеченным:
И, что самое забавное, он тоже попадает под наш локатор. Только у него есть дополнительный класс, который отличает его от отправленных сообщений:
Наш тест при появлении этого блока не сломался, но проверка «дождаться появления сообщения» перестала быть актуальной. Элемент, который был индикатором удачного события, теперь есть всегда.
Вывод: если логика теста строится на проверке появления какого-то элемента, обязательно надо проверять, чтобы такого элемента до нашего взаимодействия с UI не было.
Довольно часто UI-тесты работают с формами, в которые они вносят те или иные данные. Например, у нас есть форма регистрации:
Данные для таких тестов можно хранить в конфигах либо захардкодить в тесте. Но иногда приходит в голову мысль: а почему бы данные не рандомизировать? Это же хорошо, мы будем покрывать больше кейсов!
Мой совет: не надо. И сейчас я расскажу почему.
Предположим, наш тест регистрируется на Badoo. Мы решаем, что пол пользователя мы будем выбирать случайно. На момент написания теста флоу регистрации для девочки и для мальчика ничем не отличается, так что наш тест успешно проходит.
Теперь представим, что через некоторое время флоу регистрации становится разным. Например, девочке мы даём бесплатные бонусы сразу после регистрации, о чём уведомляем её специальным оверлеем.
В тесте нет логики закрытия оверлея, а он, в свою очередь, мешает каким-то дальнейшим действиям, прописанным в тесте. Мы получаем тест, который в 50% случаев падает. Любой автоматизатор подтвердит, что UI-тесты по своей природе и так не отличаются стабильностью. И это нормально, с этим приходится жить, постоянно лавируя между избыточной логикой «на все случаи жизни» (что заметно портит читабельность кода и усложняет его поддержку) и этой самой нестабильностью.
В следующий раз при падении теста у нас может не быть времени на то, чтобы с ним разбираться. Мы его просто перезапустим и увидим, что он прошёл. Решим, что в нашем приложении всё работает как надо и дело в нестабильном тесте. И успокоимся.
Теперь пойдём дальше. Что, если этот оверлей сломается? Тест продолжит проходить в 50% случаев, что существенно отдаляет нахождение проблемы.
И это хорошо, когда из-за рандомизации данных мы создаем ситуацию «50 на 50». Но бывает и по-другому. Например, раньше при регистрации приемлемым считался пароль не короче трёх символов. Мы пишем код, который придумывает нам случайный пароль не короче трёх символов ( иногда символов три, а иногда и больше). А потом правило меняется — и пароль должен содержать уже не менее четырёх символов. Какую вероятность падения мы получим в этом случае? И, если наш тест будет ловить настоящий баг, как быстро мы в этом разберёмся?
Особенно сложно работать с тестами где случайных данных вводится много: имя, пол, пароль и так далее… В этом случае различных комбинаций тоже много, и, если в какой-то из них происходит ошибка, обычно заметить это непросто.
Вывод. Как я писал выше, рандомизировать данные — плохо. Лучше покрыть больше кейсов за счёт дата-провайдеров, не забывая про классы эквивалентности, само собой. Прохождение тестов станет занимать больше времени, но с этим можно бороться. Зато мы будем уверены, что, если проблема есть, она будет обнаружена.
Давайте разберём следующий пример. Мы пишем тест, который проверяет счётчик пользователей в футере.

Сценарий простой:
Такой тест мы называем testFooterCounter и запускаем. Потом появляется необходимость проверять, что счётчик не показывает ноль. Эту проверку мы добавляем в уже существующий тест, почему нет?
А вот потом появляется необходимость проверять, что в футере есть ссылка на описание проекта (ссылка «О нас»). Написать новый тест или добавить в уже существующий? В случае нового теста нам придётся заново поднимать приложение, готовить пользователя (если мы проверяем футер на авторизованной странице), логиниться — в общем, тратить драгоценное время. В такой ситуации переименовать тест в testFooterCounterAndLinks кажется удачной идеей.
С одной стороны, плюсы у такого подхода есть: экономия времени, хранение всех проверок какой-то части нашего приложения (в данном случае футера) в одном месте.
Но есть и заметный минус. Если тест упадёт на первой же проверке, мы не проверим оставшуюся часть компонента. Предположим, тест упал в какой-то ветке не из-за нестабильности, а из-за бага. Что делать? Возвращать задачу, описав только эту проблему? Тогда мы рискуем получить задачу с фиксом только этого бага, запустить тест и обнаружить, что дальше компонент тоже сломан, в другом месте. И таких итераций может быть много. Пинание тикета туда-сюда в этом случае займёт много времени и будет неэффективно.
Вывод: стоит по возможности атомизировать проверки. В таком случае, даже имея проблему в одном кейсе, мы проверим все остальные. И, если придётся возвращать тикет, мы сможем сразу описать все проблемные места.
Рассмотрим ещё один пример. Мы пишем тест на чат, который проверяет следующую логику. Если у пользователей возникла взаимная симпатия, в чате появляется такой промоблок:

Сценарий выглядит следующим образом:
Какое-то время тест успешно работает, но потом происходит следующее… Нет, в этот раз тест не пропускает никакой баг. :)
Через какое-то время мы узнаём, что есть другой, не связанный с нашим тестом баг: если открыть чат, тут же закрыть и открыть снова, блок пропадает. Не самый очевидный кейс, и в тесте мы, само собой, его не предвидели. Но мы решаем, что покрыть его тоже надо.
Возникает тот же вопрос: написать ещё один тест или вставить проверку в уже существующий? Писать новый кажется нецелесообразным, ведь 99% времени он будет делать то же самое, что уже существующий. И мы решаем добавить проверку в тест, который уже есть:
Проблема может всплыть тогда, когда мы будем, например, рефакторить тест спустя много времени. Например, на проекте случится редизайн — и придётся переписывать много тестов.
Мы откроем тест и будем пытаться вспомнить, что же он проверяет. Например, тест называется testPromoAfterMutualAttraction. Поймём ли мы, зачем в конце прописано открытие и закрытие чата? Скорее всего, нет. Особенно если этот тест писали не мы. Оставим ли мы этот кусок? Может, и да, но, если с ним будут какие-то проблемы, велика вероятность, что мы его просто удалим. И проверка потеряется просто потому, что её смысл будет неочевиден.
Решения я тут вижу два. Первое: всё же сделать второй тест и назвать его testCheckBlockPresentAfterOpenAndCloseChat. С таким названием будет понятно, что мы не просто так совершаем какой-то набор действий, а делаем вполне осознанную проверку, поскольку был негативный опыт. Второе решение — написать в коде подробный комментарий о том, зачем мы делаем эту проверку именно в этом тесте. В комментарии желательно также указать номер бага.
Следующий пример подкинул мне bbidox, за что ему большой плюс в карму!
Бывает очень интересная ситуация, когда код тестов становится уже… фреймворком. Предположим, у нас есть такой метод:
В какой-то момент с этим методом начинает происходить что-то странное: тест падает при попытке кликнуть по кнопке. Мы открываем скриншот, сделанный в момент падения теста, и видим, что на скриншоте кнопка есть и метод waitForButtonToAppear сработал успешно. Вопрос: что не так с кликом?
Самое сложное в этой ситуации то, что тест иногда может проходить успешно. :)
Давайте разбираться. Предположим, что рассматриваемая в примере кнопка расположена на таком оверлее:
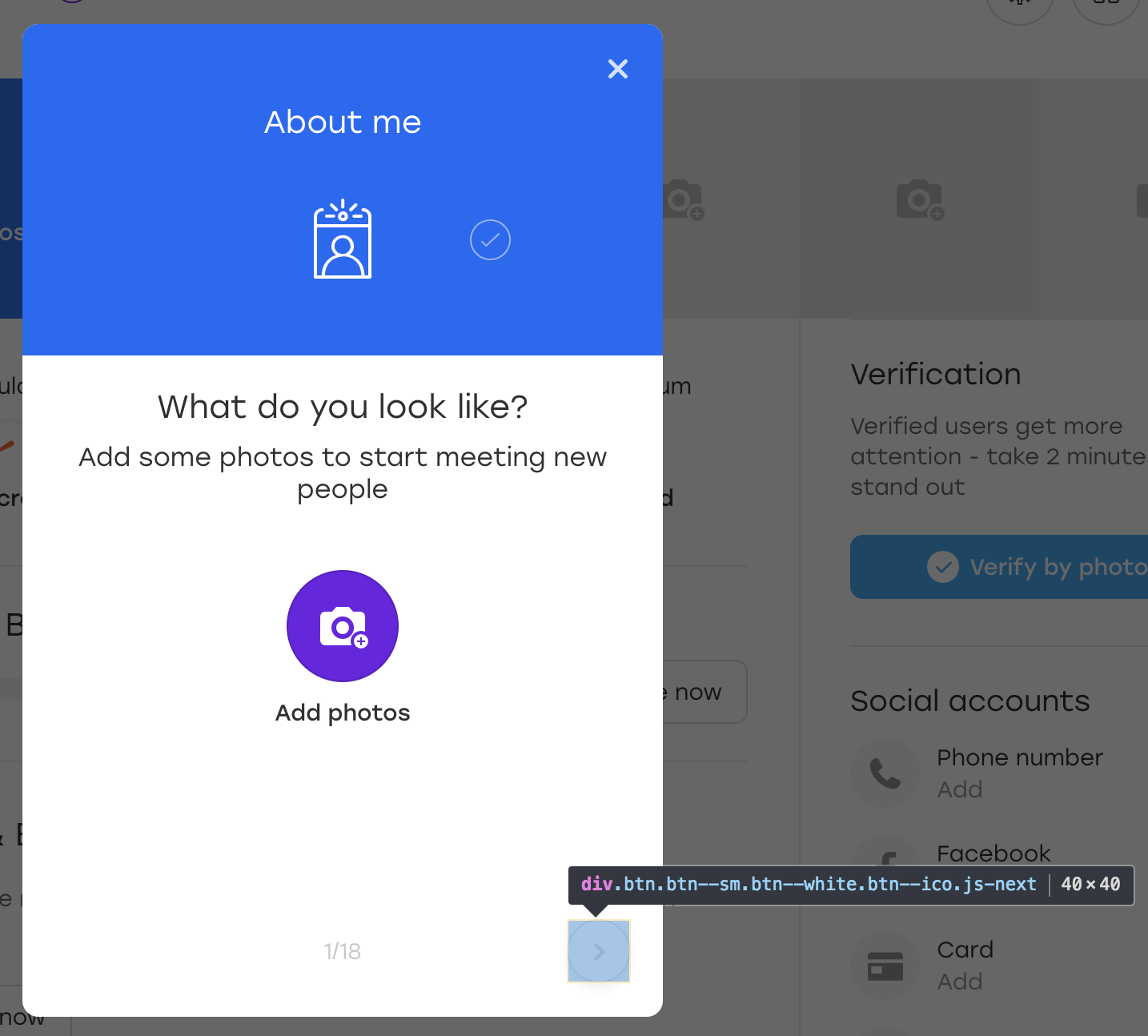
Это специальный оверлей, через который пользователь на нашем сайте может заполнять информацию о себе. При нажатии на выделенную кнопку оверлея появляется следующий блок для заполнения.
Ради интереса давайте добавим дополнительный класс OLOLO для этой кнопки:
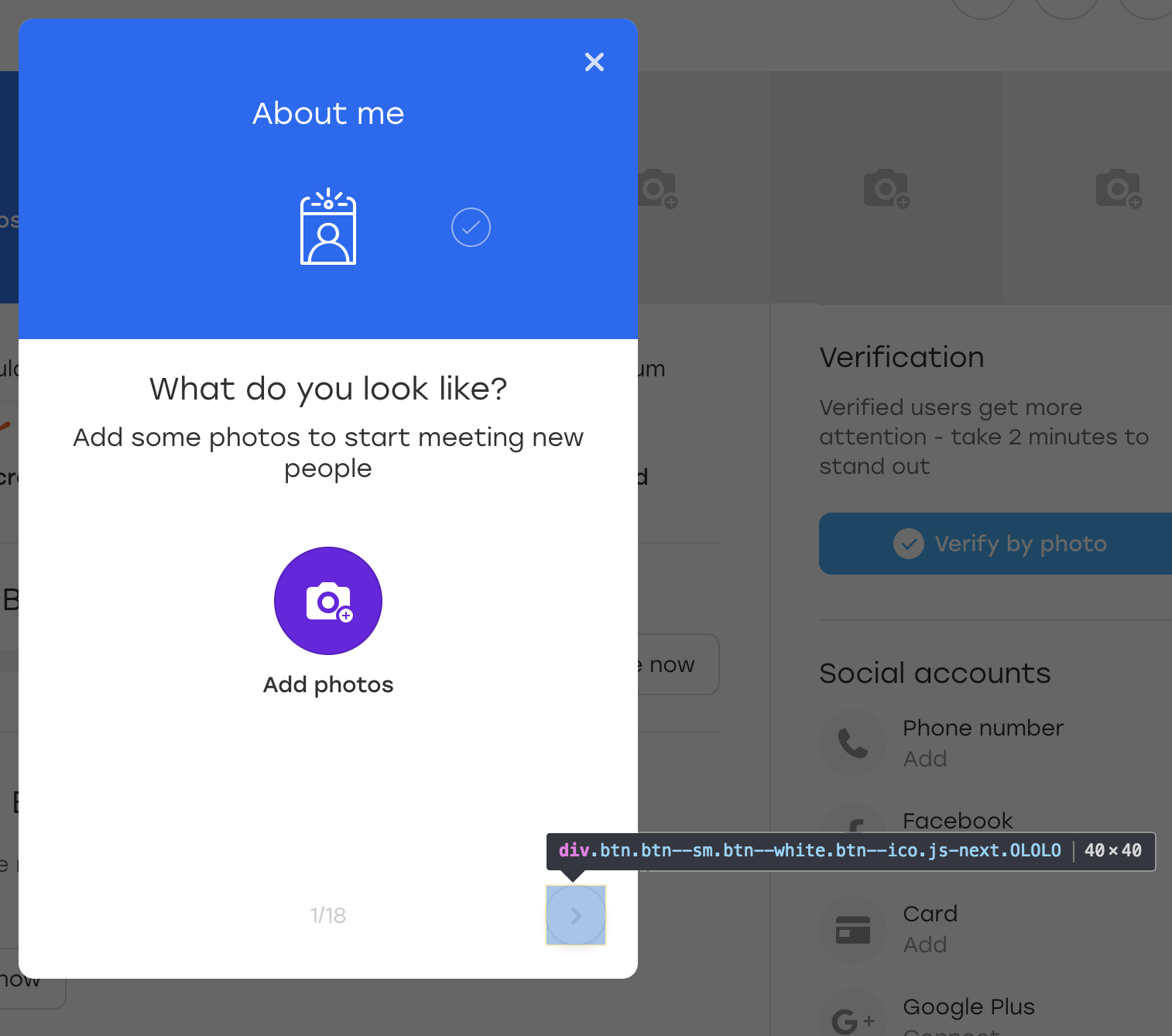
После чего мы кликаем на эту кнопку. Визуально ничего не изменилось, а сама кнопка осталась на месте:
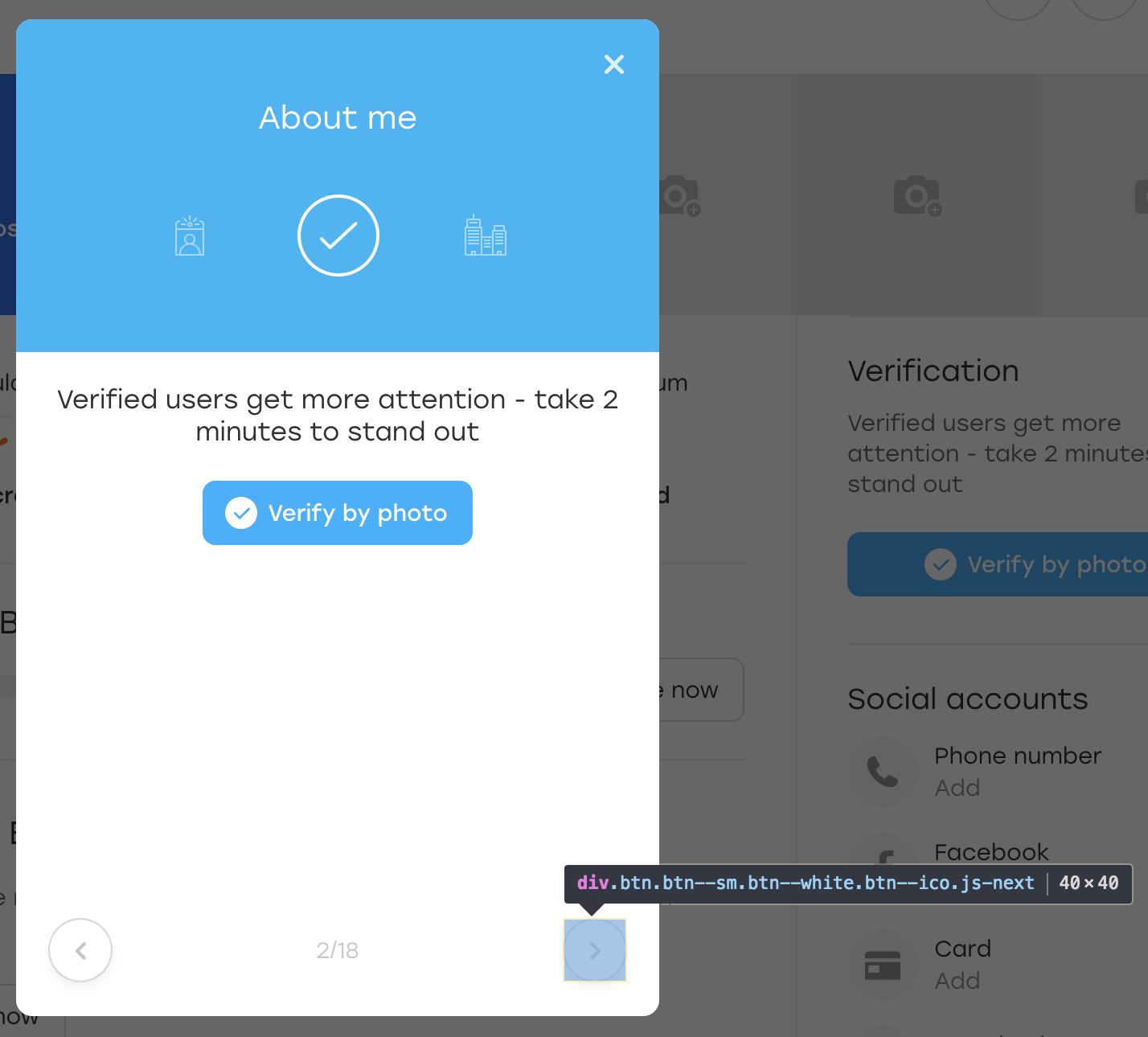
Что же произошло? По сути, когда JS перерисовывал нам блок, кнопку он перерисовал тоже. Она всё ещё доступна по тому же локатору, но это уже другая кнопка. Об этом говорит отсутствие добавленного нами класса OLOLO.
В коде выше мы сохраняем элемент в переменную $element. Если за это время элемент перегенерируется, визуально это может быть незаметно, но кликнуть по нему уже не получится — метод click() упадёт с ошибкой.
Вариантов решения несколько:
Напоследок простой, но не менее важный момент.
Данный пример касается не только UI-тестов, но и в них встречается очень часто. Обычно, когда пишешь тест, находишься в контексте происходящего: описываешь проверку за проверкой и понимаешь их значение. И тексты ошибок пишешь в том же контексте:
Что может быть непонятно в этом коде? Тест ожидает появления кнопки и, если её нет, закономерно падает.
Теперь представьте, что автор теста на больничном, а за тестами присматривает его коллега. И вот у него падает тест testQuestionsOnProfile и пишет такое сообщение: “Cannot find button”. Коллеге надо как можно быстрее разобраться в происходящем, потому что скоро релиз.

Что ему придётся делать?
Открывать страницу, на которой тест упал, и проверять локатор “a.link” бессмысленно — элемента же нет. Следовательно, придётся внимательно изучать тест и разбираться, что же он проверяет.
Куда проще было бы с более подробным текстом ошибки: “Cannot find the submit button on the questions overlay”. С такой ошибкой можно сразу открывать оверлей и смотреть, куда делась кнопка.
Вывода два. Во-первых, в любой метод вашего тестового фреймворка стоит передавать текст ошибки, причём обязательным параметром, чтобы не было соблазна про него забыть. Во-вторых, текст ошибки стоит делать подробным. Это не всегда означает, что он должен быть длинным, — достаточно, чтобы по нему было понятно, что пошло не так в тесте.
Как понять, что текст ошибки написан хорошо? Очень просто. Представьте, что ваше приложение сломалось и вам надо подойти к разработчикам и объяснить, что и где сломалось. Если вы им скажете только то, что написано в тексте ошибки, им будет понятно?
Составление сценария теста зачастую бывает интересным занятием. Одновременно мы преследуем множество целей. Наши тесты должны:
Особенно интересно работать с тестами в постоянно развивающемся и меняющемся проекте, где их приходится постоянно актуализировать: что-то добавлять и что-то выпиливать. Вот почему стоит заранее продумывать некоторые моменты и не всегда спешить с решениями. :)
Надеюсь, мои советы помогут вам избежать некоторых проблем и заставят подходить к составлению кейсов более вдумчиво. Если статья понравится публике, я постараюсь собрать ещё несколько нескучных примеров. А пока — пока!
Итак, сложив свой собственный опыт и наблюдения за другими ребятами, я решил подготовить для вас коллекцию того, «как писать тесты не стоит». Каждый пример я подкрепил подробным описанием, примерами кода и скриншотами.
Статья будет интересна начинающим авторам UI-тестов, но и старожилы в этой теме наверняка узнают что-то новое, либо просто улыбнутся, вспомнив себя «в молодости». :)
Поехали!
Содержание
- Локаторы без атрибутов
- Проверка отсутствия элемента
- Проверка появления элемента
- Случайные данные
- Атомарность тестов (часть 1)
- Атомарность тестов (часть 2)
- Ошибка клика по существующему элементу
- Текст ошибки
- Итог
Локаторы без атрибутов
Начнём с простого примера. Так как мы говорим о UI-тестах не последнюю роль в них играют локаторы. Локатор — это строка, составленная по определённому правилу и описывающая один или несколько XML- (в частности HTML-) элементов.
Существует несколько видов локаторов. Например, css-локаторы используются для каскадных таблиц стилей. XPath-локаторы используются для работы с XML-документами. И так далее.
Полный список типов локаторов, которые используются в Selenium, можно найти на seleniumhq.github.io.
В UI-тестах локаторы используются для описания элементов, с которыми драйвер должен взаимодействовать.
Практически в любом инспекторе браузера есть возможность выбрать интересующий нас элемент и скопировать его XPath. Выглядит это примерно так:
Получается такой вот локатор:
/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a
Кажется, что ничего плохого в таком локаторе нет. Ведь мы его можем сохранить в какую-то константу или поле класса, которые своим названием будут передавать суть элемента:
@FindBy(xpath = "/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a") public WebElement createAccountButton;
И обернуть соответствующим текстом ошибки на случай, если элемент не найдётся:
public void waitForCreateAccountButton() { By by = By.xpath(this.createAccountButton); WebDriverWait wait = new WebDriverWait(driver, timeoutInSeconds); wait .withMessage(“Cannot find Create Account button.”) .until( ExpectedConditions.presenceOfElementLocated(by) ); }
У такого подхода есть плюс: отпадает необходимость изучать XPath.
Однако есть и ряд минусов. Во-первых, при изменении вёрстки нет гарантии, что элемент по такому локатору останется прежним. Вполне возможно, что на его место встанет другой, что приведёт к непредвиденным обстоятельствам. Во-вторых, задача автотестов — баги искать, а не следить за изменениями вёрстки. Следовательно, добавление какого-нибудь враппера или ещё каких-то элементов выше по дереву не должно затрагивать наши тесты. В противном случаем у нас будет уходить довольно много времени на актуализацию локаторов.
Вывод: следует составлять локаторы, которые корректно описывают элемент и при этом устойчивы к изменению вёрстки вне тестируемой части нашего приложения. Например, можно привязываться к одному или нескольким атрибутам элемента:
//a[@rel=”createAccount”]
Такой локатор и воспринимать в коде проще, и сломается он только в том случае, если пропадёт «rel».
Ещё один плюс такого локатора — возможность поиска в репозитории шаблона с указанным атрибутом. А что искать, если локатор выглядит как в первоначальном примере? :)
Если изначально в приложении у элементов нет никаких атрибутов или они выставляются автоматически (например, из-за обфускации классов), это стоит обсудить с разработчиками. Они должны быть не менее заинтересованы в автоматизации тестирования продукта и наверняка пойдут вам навстречу и предложат решение.
Проверка отсутствия элемента
У каждого пользователя Badoo есть свой профиль. На нём расположена информация о пользователе: (имя, возраст, фотографии) и информацию о том, с кем пользователь хочет общаться. Помимо этого, есть возможность указать свои интересы.
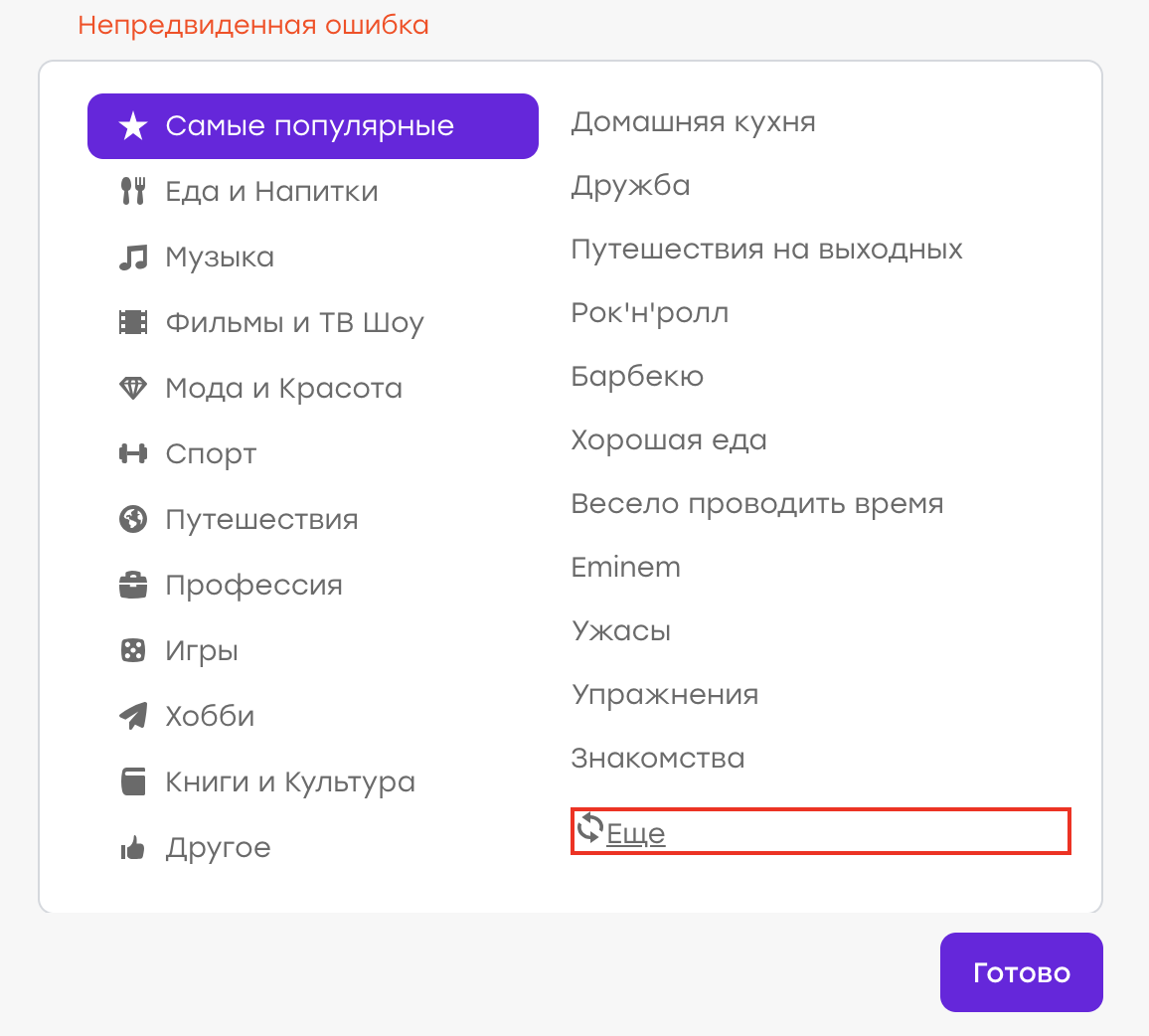
Предположим, однажды у нас был баг ( хотя, конечно, это не так :) ). Пользователь в своём профиле выбирал интересы. Не найдя подходящего интереса из списка, он решил кликнуть «Ещё», чтобы обновить список.
Ожидаемое поведение: старые интересы должны пропасть, новые — появиться. Но вместо этого выскочила «Непредвиденная ошибка»:
Оказалось, на стороне сервера возникла проблема, ответ пришёл не тот, и клиент это дело обработал, показав соответствующее уведомление.
Наша задача — написать автотест, который будет проверять этот кейс.
Мы пишем примерно следующий сценарий:
- Открыть профиль
- Открыть список интересов
- Кликнуть кнопку «Ещё»
- Убедиться, что ошибка не появилась (например, нет элемента «div.error»)
Такой тест мы и запускаем. Однако происходит следующее: через несколько дней/месяцев/лет баг снова появляется, хотя тест ничего не ловит. Почему?
Всё довольно просто: за время успешного прохождения теста локатор элемента, по которому мы искали текст ошибки, изменился. Был рефакторинг темплейтов и вместо класса «error» у нас появился класс «error_new».
Во время рефакторинга тест ожидаемо продолжал работать. Элемент “div.error” не появлялся, причины для падения не было. Но теперь элемента “div.error” вообще не существует — следовательно, тест не упадёт никогда, чтобы ни происходило в приложении.
Вывод: лучше тестировать работоспособность интерфейса позитивными проверками. В нашем примере стоило ожидать, что список интересов изменился.
Бывают ситуации, когда негативную проверку нельзя заменить позитивной. Например, при взаимодействии с каким-то элементом в «хорошей» ситуации ничего не происходит, а в «плохой» — появляется ошибка. В этом случае стоит придумать способ симулировать «плохой» сценарий и на него тоже написать автотест. Таким образом мы проверим, что в негативном кейсе элемент ошибки появляется, и тем самым будем следить за актуальностью локатора.
Проверка появления элемента
Как убедиться, что взаимодействие теста с интерфейсом прошло удачно и всё работает? Чаще всего это видно по изменениям, которые в этом интерфейсе произошли.
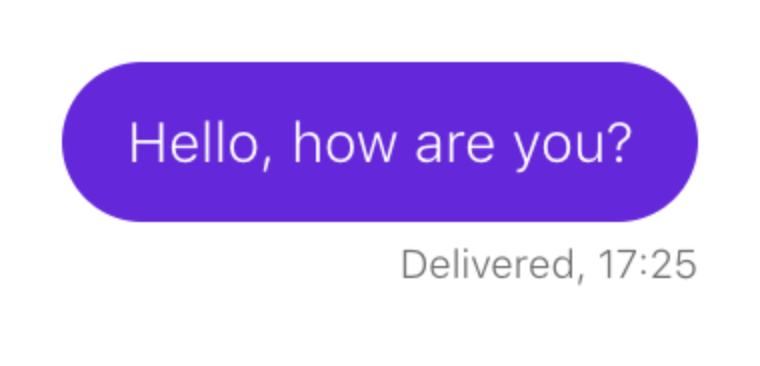
Рассмотрим пример. Необходимо убедиться, что при отправке сообщения оно появляется в чате:
Сценарий выглядит примерно так:
- Открыть профиль пользователя
- Открыть чат с ним
- Написать сообщение
- Отправить
- Дождаться появления сообщения
Такой сценарий мы и описываем в нашем тесте. Предположим, что сообщению в чате соответствует локатор:
p.message_text
Вот так мы проверяем, что элемент появился:
this.waitForPresence(By.css(‘p.message_text’), "Cannot find sent message.");
Если наш wait работает, то всё в порядке: сообщения в чате отрисовываются.
Как вы уже догадались, через какое-то время отправка сообщений в чате ломается, но наш тест продолжает работать без перебоев. Давайте разбираться.
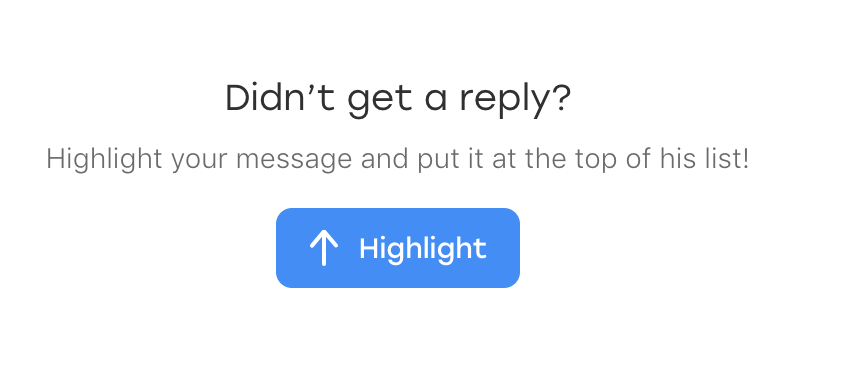
Оказывается, накануне в чате появился новый элемент: некий текст, который предлагает пользователю подсветить сообщение, если оно вдруг осталось незамеченным:
И, что самое забавное, он тоже попадает под наш локатор. Только у него есть дополнительный класс, который отличает его от отправленных сообщений:
p.message_text.highlight
Наш тест при появлении этого блока не сломался, но проверка «дождаться появления сообщения» перестала быть актуальной. Элемент, который был индикатором удачного события, теперь есть всегда.
Вывод: если логика теста строится на проверке появления какого-то элемента, обязательно надо проверять, чтобы такого элемента до нашего взаимодействия с UI не было.
- Открыть профиль пользователя
- Открыть чат с ним
- Убедиться, что отправленных сообщений нет
- Написать сообщение
- Отправить
- Дождаться появления сообщения
Случайные данные
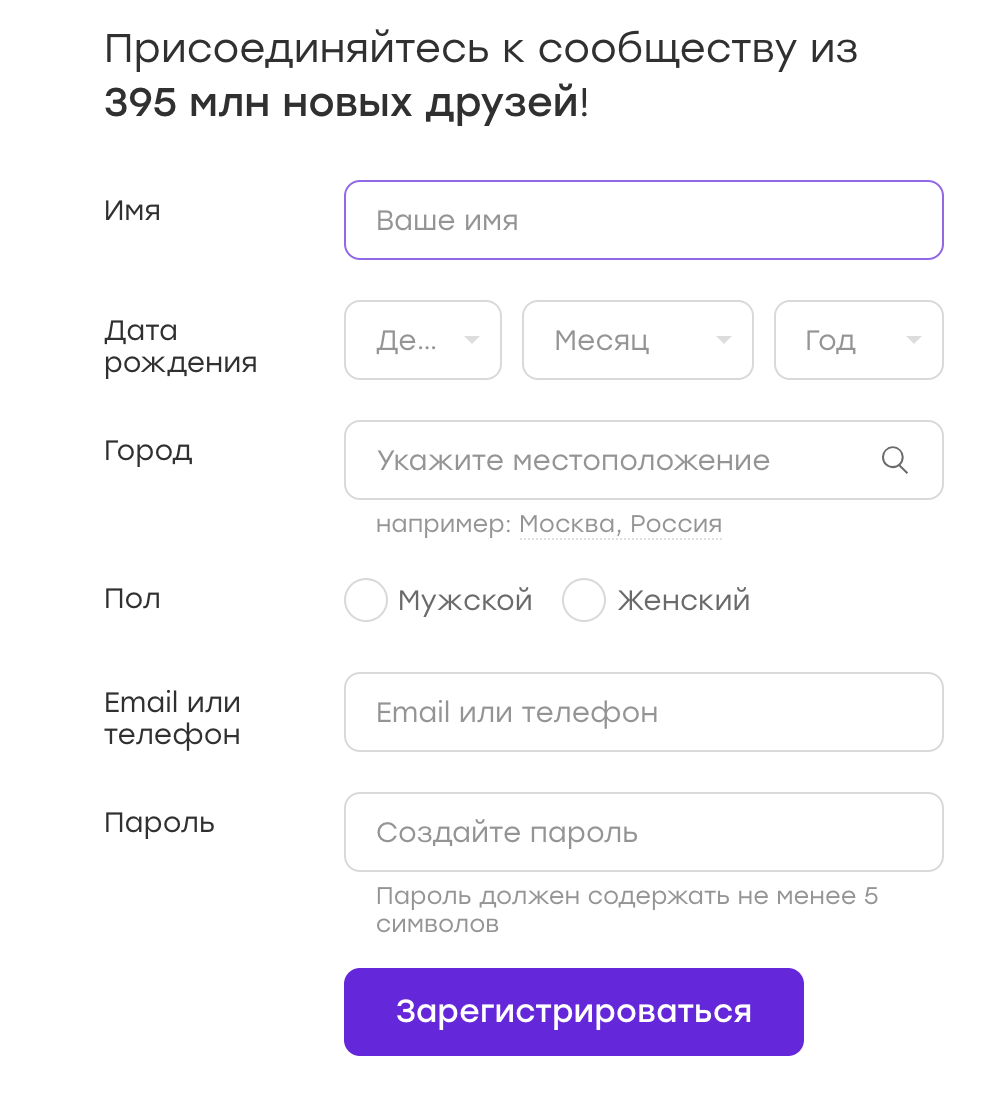
Довольно часто UI-тесты работают с формами, в которые они вносят те или иные данные. Например, у нас есть форма регистрации:
Данные для таких тестов можно хранить в конфигах либо захардкодить в тесте. Но иногда приходит в голову мысль: а почему бы данные не рандомизировать? Это же хорошо, мы будем покрывать больше кейсов!
Мой совет: не надо. И сейчас я расскажу почему.
Предположим, наш тест регистрируется на Badoo. Мы решаем, что пол пользователя мы будем выбирать случайно. На момент написания теста флоу регистрации для девочки и для мальчика ничем не отличается, так что наш тест успешно проходит.
Теперь представим, что через некоторое время флоу регистрации становится разным. Например, девочке мы даём бесплатные бонусы сразу после регистрации, о чём уведомляем её специальным оверлеем.
В тесте нет логики закрытия оверлея, а он, в свою очередь, мешает каким-то дальнейшим действиям, прописанным в тесте. Мы получаем тест, который в 50% случаев падает. Любой автоматизатор подтвердит, что UI-тесты по своей природе и так не отличаются стабильностью. И это нормально, с этим приходится жить, постоянно лавируя между избыточной логикой «на все случаи жизни» (что заметно портит читабельность кода и усложняет его поддержку) и этой самой нестабильностью.
В следующий раз при падении теста у нас может не быть времени на то, чтобы с ним разбираться. Мы его просто перезапустим и увидим, что он прошёл. Решим, что в нашем приложении всё работает как надо и дело в нестабильном тесте. И успокоимся.
Теперь пойдём дальше. Что, если этот оверлей сломается? Тест продолжит проходить в 50% случаев, что существенно отдаляет нахождение проблемы.
И это хорошо, когда из-за рандомизации данных мы создаем ситуацию «50 на 50». Но бывает и по-другому. Например, раньше при регистрации приемлемым считался пароль не короче трёх символов. Мы пишем код, который придумывает нам случайный пароль не короче трёх символов ( иногда символов три, а иногда и больше). А потом правило меняется — и пароль должен содержать уже не менее четырёх символов. Какую вероятность падения мы получим в этом случае? И, если наш тест будет ловить настоящий баг, как быстро мы в этом разберёмся?
Особенно сложно работать с тестами где случайных данных вводится много: имя, пол, пароль и так далее… В этом случае различных комбинаций тоже много, и, если в какой-то из них происходит ошибка, обычно заметить это непросто.
Вывод. Как я писал выше, рандомизировать данные — плохо. Лучше покрыть больше кейсов за счёт дата-провайдеров, не забывая про классы эквивалентности, само собой. Прохождение тестов станет занимать больше времени, но с этим можно бороться. Зато мы будем уверены, что, если проблема есть, она будет обнаружена.
Атомарность тестов (часть 1)
Давайте разберём следующий пример. Мы пишем тест, который проверяет счётчик пользователей в футере.
Сценарий простой:
- Открыть приложение
- Найти счётчик на футере
- Убедиться, что он видимый
Такой тест мы называем testFooterCounter и запускаем. Потом появляется необходимость проверять, что счётчик не показывает ноль. Эту проверку мы добавляем в уже существующий тест, почему нет?
А вот потом появляется необходимость проверять, что в футере есть ссылка на описание проекта (ссылка «О нас»). Написать новый тест или добавить в уже существующий? В случае нового теста нам придётся заново поднимать приложение, готовить пользователя (если мы проверяем футер на авторизованной странице), логиниться — в общем, тратить драгоценное время. В такой ситуации переименовать тест в testFooterCounterAndLinks кажется удачной идеей.
С одной стороны, плюсы у такого подхода есть: экономия времени, хранение всех проверок какой-то части нашего приложения (в данном случае футера) в одном месте.
Но есть и заметный минус. Если тест упадёт на первой же проверке, мы не проверим оставшуюся часть компонента. Предположим, тест упал в какой-то ветке не из-за нестабильности, а из-за бага. Что делать? Возвращать задачу, описав только эту проблему? Тогда мы рискуем получить задачу с фиксом только этого бага, запустить тест и обнаружить, что дальше компонент тоже сломан, в другом месте. И таких итераций может быть много. Пинание тикета туда-сюда в этом случае займёт много времени и будет неэффективно.
Вывод: стоит по возможности атомизировать проверки. В таком случае, даже имея проблему в одном кейсе, мы проверим все остальные. И, если придётся возвращать тикет, мы сможем сразу описать все проблемные места.
Атомарность тестов (часть 2)
Рассмотрим ещё один пример. Мы пишем тест на чат, который проверяет следующую логику. Если у пользователей возникла взаимная симпатия, в чате появляется такой промоблок:
Сценарий выглядит следующим образом:
- Проголосовать юзером А за юзера Б
- Проголосовать юзером Б за юзера А
- Юзером А открыть чат с юзером Б
- Подтвердить, что блок на месте
Какое-то время тест успешно работает, но потом происходит следующее… Нет, в этот раз тест не пропускает никакой баг. :)
Через какое-то время мы узнаём, что есть другой, не связанный с нашим тестом баг: если открыть чат, тут же закрыть и открыть снова, блок пропадает. Не самый очевидный кейс, и в тесте мы, само собой, его не предвидели. Но мы решаем, что покрыть его тоже надо.
Возникает тот же вопрос: написать ещё один тест или вставить проверку в уже существующий? Писать новый кажется нецелесообразным, ведь 99% времени он будет делать то же самое, что уже существующий. И мы решаем добавить проверку в тест, который уже есть:
- Проголосовать юзером А за юзера Б
- Проголосовать юзером Б за юзера А
- Юзером А открыть чат с юзером Б
- Подтвердить, что блок на месте
- Закрыть чат
- Открыть чат
- Подтвердить, что блок на месте
Проблема может всплыть тогда, когда мы будем, например, рефакторить тест спустя много времени. Например, на проекте случится редизайн — и придётся переписывать много тестов.
Мы откроем тест и будем пытаться вспомнить, что же он проверяет. Например, тест называется testPromoAfterMutualAttraction. Поймём ли мы, зачем в конце прописано открытие и закрытие чата? Скорее всего, нет. Особенно если этот тест писали не мы. Оставим ли мы этот кусок? Может, и да, но, если с ним будут какие-то проблемы, велика вероятность, что мы его просто удалим. И проверка потеряется просто потому, что её смысл будет неочевиден.
Решения я тут вижу два. Первое: всё же сделать второй тест и назвать его testCheckBlockPresentAfterOpenAndCloseChat. С таким названием будет понятно, что мы не просто так совершаем какой-то набор действий, а делаем вполне осознанную проверку, поскольку был негативный опыт. Второе решение — написать в коде подробный комментарий о том, зачем мы делаем эту проверку именно в этом тесте. В комментарии желательно также указать номер бага.
Ошибка клика по существующему элементу
Следующий пример подкинул мне bbidox, за что ему большой плюс в карму!
Бывает очень интересная ситуация, когда код тестов становится уже… фреймворком. Предположим, у нас есть такой метод:
public void clickSomeButton() { WebElement button_element = this.waitForButtonToAppear(); button_element.click(); }
В какой-то момент с этим методом начинает происходить что-то странное: тест падает при попытке кликнуть по кнопке. Мы открываем скриншот, сделанный в момент падения теста, и видим, что на скриншоте кнопка есть и метод waitForButtonToAppear сработал успешно. Вопрос: что не так с кликом?
Самое сложное в этой ситуации то, что тест иногда может проходить успешно. :)
Давайте разбираться. Предположим, что рассматриваемая в примере кнопка расположена на таком оверлее:
Это специальный оверлей, через который пользователь на нашем сайте может заполнять информацию о себе. При нажатии на выделенную кнопку оверлея появляется следующий блок для заполнения.
Ради интереса давайте добавим дополнительный класс OLOLO для этой кнопки:
После чего мы кликаем на эту кнопку. Визуально ничего не изменилось, а сама кнопка осталась на месте:
Что же произошло? По сути, когда JS перерисовывал нам блок, кнопку он перерисовал тоже. Она всё ещё доступна по тому же локатору, но это уже другая кнопка. Об этом говорит отсутствие добавленного нами класса OLOLO.
В коде выше мы сохраняем элемент в переменную $element. Если за это время элемент перегенерируется, визуально это может быть незаметно, но кликнуть по нему уже не получится — метод click() упадёт с ошибкой.
Вариантов решения несколько:
- Оборачивать click в try-блок и в catch пересобирать элемент
- Добавлять кнопке какой-то атрибут, чтобы сигнализировать, что она изменилась
Текст ошибки
Напоследок простой, но не менее важный момент.
Данный пример касается не только UI-тестов, но и в них встречается очень часто. Обычно, когда пишешь тест, находишься в контексте происходящего: описываешь проверку за проверкой и понимаешь их значение. И тексты ошибок пишешь в том же контексте:
WebElement element = this.waitForPresence(By.css("a.link"), "Cannot find button");
Что может быть непонятно в этом коде? Тест ожидает появления кнопки и, если её нет, закономерно падает.
Теперь представьте, что автор теста на больничном, а за тестами присматривает его коллега. И вот у него падает тест testQuestionsOnProfile и пишет такое сообщение: “Cannot find button”. Коллеге надо как можно быстрее разобраться в происходящем, потому что скоро релиз.
Что ему придётся делать?
Открывать страницу, на которой тест упал, и проверять локатор “a.link” бессмысленно — элемента же нет. Следовательно, придётся внимательно изучать тест и разбираться, что же он проверяет.
Куда проще было бы с более подробным текстом ошибки: “Cannot find the submit button on the questions overlay”. С такой ошибкой можно сразу открывать оверлей и смотреть, куда делась кнопка.
Вывода два. Во-первых, в любой метод вашего тестового фреймворка стоит передавать текст ошибки, причём обязательным параметром, чтобы не было соблазна про него забыть. Во-вторых, текст ошибки стоит делать подробным. Это не всегда означает, что он должен быть длинным, — достаточно, чтобы по нему было понятно, что пошло не так в тесте.
Как понять, что текст ошибки написан хорошо? Очень просто. Представьте, что ваше приложение сломалось и вам надо подойти к разработчикам и объяснить, что и где сломалось. Если вы им скажете только то, что написано в тексте ошибки, им будет понятно?
Итог
Составление сценария теста зачастую бывает интересным занятием. Одновременно мы преследуем множество целей. Наши тесты должны:
- покрывать как можно больше кейсов
- работать как можно быстрее
- быть понятными
- просто расширяться
- легко поддерживаться
- заказывать пиццу
- и так далее…
Особенно интересно работать с тестами в постоянно развивающемся и меняющемся проекте, где их приходится постоянно актуализировать: что-то добавлять и что-то выпиливать. Вот почему стоит заранее продумывать некоторые моменты и не всегда спешить с решениями. :)
Надеюсь, мои советы помогут вам избежать некоторых проблем и заставят подходить к составлению кейсов более вдумчиво. Если статья понравится публике, я постараюсь собрать ещё несколько нескучных примеров. А пока — пока!

