
Все организации, которые имеют хоть какое-то отношение к данным, рано или поздно сталкиваются с вопросом хранения реляционных и неструктурированных баз. Непросто найти одновременно удобный, эффективный и недорогой подход к этой проблеме. А еще сделать так, чтобы на данных смогли успешно работать дата-сайентисты с моделями машинного обучения. У нас получилось – и хотя пришлось повозиться, итоговый профит оказался даже больше ожидаемого. Обо всех подробностях расскажем ниже.

Со временем в любом банке скапливаются невероятные объемы корпоративных данных. Сравнимое количество хранится только в интернет-компаниях и телекоме. Так сложилось из-за высоких требований регулирующих органов. Эти данные без дела не лежат — руководители финансовых учреждений давно придумали, как извлечь из этого прибыль.
У нас все началось с управленческой и финансовой отчетности. На основе этих данных научились принимать бизнес-решения. Часто возникала необходимость получить данные из нескольких информационных систем банка, для чего мы создали сводные базы данных и системы подготовки отчетности. Из этого постепенно сформировалось то, что сейчас называется хранилищем данных. Вскоре на основе этого хранилища заработали и другие наши системы:
Решаются все эти задачи аналитическими приложениями, которые используют модели машинного обучения. Чем больше информации модели могут взять из хранилища, тем точнее они будут работать. Их потребность в данных растет экспоненциально.
Примерно к такой ситуации мы пришли два-три года назад. На тот момент у нас имелось хранилище на базе MPP СУБД Teradata с использованием ELT-инструмента SAS Data Integration Studio. Это хранилище мы строили с 2011 года вместе с компанией Glowbyte Consulting. В него интегрировали более 15 крупных банковских систем и при этом накопили достаточный объем данных для внедрения и развития аналитических приложений. Кстати, как раз в это время объем данных в основных слоях хранилища из-за множества разных задач начал расти нелинейно, а продвинутая клиентская аналитика стала одним из основных направлений развития банка. Да и наши дата-сайентисты горели желанием поддержать ее. В общем, для построения Data Research Platform звезды сложились как надо.
Здесь надо пояснить: промышленные ПО и сервера – дорогое удовольствие даже для крупного банка. Далеко не каждая организация может позволить себе хранение большого объема данных в топовых MPP СУБД. Всегда приходится делать выбор между ценой и скоростью, надежностью и объемом.
Чтобы по максимуму использовать имеющиеся возможности, решили поступить вот так:
Примерно в то время экосистема Hadoop стала не только модной, но и достаточной надежной, удобной для enterprise-применения. Нужно было выбрать дистрибутив. Можно было собрать свой собственный или использовать открытый Apache Hadoop. Но среди enterprise-решений на базе Hadoop себя больше зарекомендовали готовые дистрибутивы от других вендоров — Cloudera и Hortonworks. Поэтому мы тоже решили использовать готовый дистрибутив.
Так как нашей основной задачей было все-таки хранение структурированных больших данных, то в стеке Hadoop нас интересовали решения, максимально близкие к классическим SQL СУБД. Лидерами здесь являются Impala и Hive. Cloudera развивает и интегрирует решения Impala, Hortonworks – Hive.
Для углубленного исследования мы организовали для обеих СУБД нагрузочное тестирование, учитывающее профильную для нас нагрузку. Надо сказать, что движки обработки данных в Impala и Hive существенно отличаются — Hive вообще представляет несколько разных вариантов. Однако выбор пал на Impala – и, соответственно, дистрибутив от Cloudera.
Следующим по важности инструментом в стеке Hadoop стал для нас Sqoop. Он позволяет перебрасывать данные между реляционными СУБД (нас, конечно, интересовала Teradata) и HDFS в Hadoop-кластере в разных форматах, включая Parquet. В тестах Sqoop показал высокую гибкость и производительность, поэтому мы решили воспользоваться им — вместо разработки собственных инструментов захвата данных через ODBC/JDBC и сохранения в HDFS.
Для обучения моделей и смежных задач Data Science, которые удобнее выполнять прямо на кластере Hadoop, мы использовали Spark от Apache. В своей области он стал стандартным решением — и есть за что:
В качестве аппаратной платформы закупили сервера Oracle Big Data Appliance. Начинали с шести узлов в продуктивном контуре с 2x24-core CPU и 256 ГБ памяти на каждом. Текущая конфигурация содержит 18 таких же узлов с расширенной до 512 ГБ памятью.
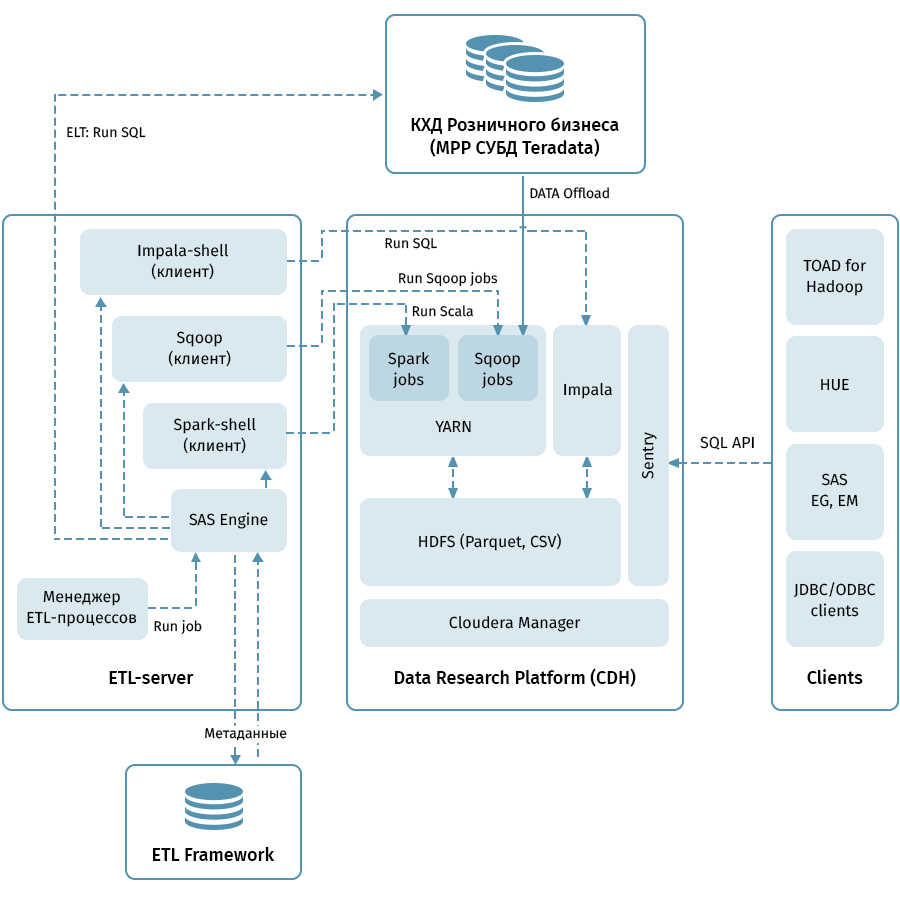
На схеме показана верхнеуровневая архитектура Data Research Platform и смежных систем. Центральное звено — кластер Hadoop на базе дистрибутива Cloudera (CDH). Он используется для как для получения с помощью Sqoop и хранения данных КХД в HDFS — в поколоночном формате Parquet, допускающем использование кодеков для сжатия, например, Snappy. Также кластер обрабатывает данные: Impala используется для ELT-подобных трансформаций, Spark — для Data Science задач. Для разделения доступа к данным используется Sentry.
Impala имеет интерфейсы для практически всех современных enterprise-средств аналитики. Помимо этого в качестве клиентов могут подключаться произвольные инструменты, поддерживающие ODBC/JDBC интерфейсы. Для работы с SQL мы в качестве основных клиентов рассматриваем Hue и TOAD for Hadoop.
Для управления всеми потоками, которые указаны на схеме стрелочками, предназначена ETL-подсистема, состоящая из средств SAS (Metadata Server, Data Integration Studio), и ETL фреймворк, написанный на базе SAS и shell-скриптов с использованием базы для хранения метаданных ETL-процессов. Руководствуясь правилами, заданными в метаданных, ETL-подсистема запускает процессы обработки данных как на КХД, так и на Data Research Platform. В итоге мы имеем сквозную систему мониторинга и управления потоками данных вне зависимости от используемой среды (Teradata, Impala, Spark и прочее, если в том будет потребность).
Разгрузить КХД вроде бы просто. На входе и выходе реляционные СУБД, бери да переливай данные через Sqoop. Судя по описанию выше, у нас все шло очень гладко, но, конечно же, без приключений не обошлось, и это, пожалуй, самая интересная часть всего проекта.

С нашим объемом переливать все данные целиком каждый день можно было не надеяться. Соответственно, из каждого объекта хранилища нужно было научиться выделять надежный инкремент, что не всегда просто, когда в таблице могут изменяться данные за исторические бизнес-даты. Для решения этой задачи мы систематизировали объекты в зависимости от способов загрузки и ведения истории. Потом для каждого типа определили правильный предикат для Sqoop и способ загрузки в приемник. И наконец, написали инструкцию для разработчиков новых объектов.
Sqoop – очень качественный инструмент, но не во всех случаях и комбинациях систем он работает абсолютно надежно. На наших объемах недостаточно оптимально работал коннектор к Teradata. Мы воспользовались открытостью кода Sqoop и внесли изменения в библиотеки коннектора. Стабильность соединения при перемещении данных увеличилась.
По какой-то причине при обращении Sqoop к Teradata предикаты не совсем правильно конвертируются в WHERE-условия. Из-за этого Sqoop иногда пытается вытащить огромную таблицу и зафильтровать ее уже позже. Здесь пропатчить коннектор не удалось, но мы нашли другой выход: принудительно создаем временную таблицу с наложенным предикатом для каждого выгружаемого объекта и просим Sqoop перелить именно ее.
Все MPP, и Teradata в частности, обладают особенностью, связанной с параллельным хранением данных и исполнением инструкций. Если эту особенность не принимать в расчет, то может оказаться, что всю работу возьмет на себя один логический узел кластера, из-за чего выполнение запроса станет гораздо медленнее, раз этак в 100-200. Мы, конечно, не могли этого допустить, поэтому написали специальный движок, который использует ETL-метаданные таблиц КХД и выбирает оптимальную степень параллелизации задач Sqoop.
Историчность в хранилище – дело тонкое, особенно если использовать SCD2, при том что в Impala не поддерживаются UPDATE и DELETE. Мы, конечно, хотим, чтобы исторические таблицы в Data Research Platform выглядели абсолютно так же, как в Teradata. Этого можно достигнуть, комбинируя получение инкремента через Sqoop, выделение обновляемых бизнес-ключей и удаление партиций в Impala. Чтобы эту вычурную логику не пришлось писать каждому разработчику, мы упаковали ее в специальную библиотеку (на нашем ETL-сленге «загрузчик»).
Напоследок — вопрос с типами данных. Impala достаточно свободно относится к конвертации типов, поэтому с какими-то затруднениями мы столкнулись только в типах TIMESTAMP и CHAR/VARCHAR. Для даты-времени мы решили хранить данные в Impala в текстовом (STRING) формате YYYY-MM-DD HH:MM:SS. Этот подход, как оказалось, вполне позволяет использовать функции трансформации даты и времени. Для строковых данных заданной длины оказалось, что хранение в формате STRING в Impala ничем им не уступает, поэтому мы тоже использовали его.
Обычно для организации Data Lake копируют данные источников в полуструктурированных форматах в специальную stage-область в Hadoop, после чего средствами Hive или Impala устанавливают схему десериализации этих данных для использования их в SQL-запросах. Мы пошли по тому же пути. Важно отметить, что не все и не всегда имеет смысл тащить в хранилище данных, так как разработка процессов копирования файликов и установка схемы значительно дешевле загрузки бизнес-атрибутов в модель КХД с помощью ETL-процессов. Когда еще непонятно, в каком объеме, на какой срок и с какой периодичностью нужны данные источника, Data Lake в описанном подходе является простым и дешевым решением. Сейчас мы регулярно загружаем в Data Lake прежде всего источники, генерирующие пользовательские события: данные анализа заявок, логи и сценарии перехода автозвонилки и автоответчика Avaya, карточные транзакции.
Мы не забыли о еще одной цели всего проекта — дать возможность аналитикам пользоваться всем этим богатством. Вот основные принципы, которыми мы здесь руководствовались:
И вот на чем остановились:
Сейчас в Data Lake находится порядка 100 Тб данных из розничного хранилища плюс около 50 Тб из ряда OLTP-источников. Озеро обновляется ежедневно в инкрементальном режиме. В дальнейшем мы собираемся повышать удобство для пользователей, выводить ELT-нагрузку на Impala, увеличивать количество источников, загружаемых в Data Lake, и расширять возможности для продвинутой аналитики.
В заключение хотелось бы дать несколько общих советов коллегам, которые только начинают свой путь в создании больших хранилищ:
Кстати, о том, как наши аналитики использовали машинное обучение и данные банка для работы с кредитными рисками, вы можете почитать в отдельном посте.
Со временем в любом банке скапливаются невероятные объемы корпоративных данных. Сравнимое количество хранится только в интернет-компаниях и телекоме. Так сложилось из-за высоких требований регулирующих органов. Эти данные без дела не лежат — руководители финансовых учреждений давно придумали, как извлечь из этого прибыль.
У нас все началось с управленческой и финансовой отчетности. На основе этих данных научились принимать бизнес-решения. Часто возникала необходимость получить данные из нескольких информационных систем банка, для чего мы создали сводные базы данных и системы подготовки отчетности. Из этого постепенно сформировалось то, что сейчас называется хранилищем данных. Вскоре на основе этого хранилища заработали и другие наши системы:
- аналитическая CRM, позволяющая предлагать клиенту более удобные для него продукты;
- кредитные конвейеры, помогающие быстро и точно принимать решение о выдаче кредита;
- системы лояльности, рассчитывающие кэшбек или бонусные баллы согласно механикам разной сложности.
Решаются все эти задачи аналитическими приложениями, которые используют модели машинного обучения. Чем больше информации модели могут взять из хранилища, тем точнее они будут работать. Их потребность в данных растет экспоненциально.
Примерно к такой ситуации мы пришли два-три года назад. На тот момент у нас имелось хранилище на базе MPP СУБД Teradata с использованием ELT-инструмента SAS Data Integration Studio. Это хранилище мы строили с 2011 года вместе с компанией Glowbyte Consulting. В него интегрировали более 15 крупных банковских систем и при этом накопили достаточный объем данных для внедрения и развития аналитических приложений. Кстати, как раз в это время объем данных в основных слоях хранилища из-за множества разных задач начал расти нелинейно, а продвинутая клиентская аналитика стала одним из основных направлений развития банка. Да и наши дата-сайентисты горели желанием поддержать ее. В общем, для построения Data Research Platform звезды сложились как надо.
Планируем решение
Здесь надо пояснить: промышленные ПО и сервера – дорогое удовольствие даже для крупного банка. Далеко не каждая организация может позволить себе хранение большого объема данных в топовых MPP СУБД. Всегда приходится делать выбор между ценой и скоростью, надежностью и объемом.
Чтобы по максимуму использовать имеющиеся возможности, решили поступить вот так:
- ELT-нагрузку и наиболее востребованную часть исторических данных ХД оставить на СУБД Teradata;
- полную историю отгружать в Hadoop, позволяющий хранить информацию значительно дешевле.
Примерно в то время экосистема Hadoop стала не только модной, но и достаточной надежной, удобной для enterprise-применения. Нужно было выбрать дистрибутив. Можно было собрать свой собственный или использовать открытый Apache Hadoop. Но среди enterprise-решений на базе Hadoop себя больше зарекомендовали готовые дистрибутивы от других вендоров — Cloudera и Hortonworks. Поэтому мы тоже решили использовать готовый дистрибутив.
Так как нашей основной задачей было все-таки хранение структурированных больших данных, то в стеке Hadoop нас интересовали решения, максимально близкие к классическим SQL СУБД. Лидерами здесь являются Impala и Hive. Cloudera развивает и интегрирует решения Impala, Hortonworks – Hive.
Для углубленного исследования мы организовали для обеих СУБД нагрузочное тестирование, учитывающее профильную для нас нагрузку. Надо сказать, что движки обработки данных в Impala и Hive существенно отличаются — Hive вообще представляет несколько разных вариантов. Однако выбор пал на Impala – и, соответственно, дистрибутив от Cloudera.
Чем понравилась Impala
- Высокая скорость выполнения аналитических запросов за счет альтернативного подхода по отношению к MapReduce. Промежуточные результаты вычислений не скидываются в HDFS, что существенно ускоряет обработку данных.
- Эффективная работа с поколоночным хранением данных в Parquet. Для аналитических задач часто используются так называемые широкие таблицы с множеством колонок. Все колонки используются редко — возможность поднимать из HDFS только нужные для работы позволяет экономить оперативную память и значительно ускорять запрос.
- Изящное решение с runtime-фильтрами, включающими bloom-фильтрацию. И Hive, и Impala существенно ограничены в использовании индексов, обычных для классических СУБД — из-за особенностей файловой системы хранения HDFS. Поэтому для оптимизации исполнения SQL-запроса движок СУБД должен эффективно воспользоваться доступным партиционированием даже когда оно не задано явно в условиях запроса. Кроме того, ему нужно попытаться предсказать, какое минимальное количество данных из HDFS нужно поднять для гарантированной обработки всех строк. В Impala это работает очень хорошо.
- Impala использует LLVM – компилятор на виртуальной машине с RISC-подобными инструкциями – для генерации оптимального кода выполнения SQL-запроса.
- Поддерживаются ODBC и JDBC интерфейсы. Это позволяет почти из коробки интегрировать данные Impala с аналитическими инструментами и приложениями.
- Есть возможность использования Kudu – чтобы обойти часть ограничений HDFS, и, в частности, писать конструкции UPDATE и DELETE в SQL-запросах.
Sqoop и остальная архитектура
Следующим по важности инструментом в стеке Hadoop стал для нас Sqoop. Он позволяет перебрасывать данные между реляционными СУБД (нас, конечно, интересовала Teradata) и HDFS в Hadoop-кластере в разных форматах, включая Parquet. В тестах Sqoop показал высокую гибкость и производительность, поэтому мы решили воспользоваться им — вместо разработки собственных инструментов захвата данных через ODBC/JDBC и сохранения в HDFS.
Для обучения моделей и смежных задач Data Science, которые удобнее выполнять прямо на кластере Hadoop, мы использовали Spark от Apache. В своей области он стал стандартным решением — и есть за что:
- библиотеки машинного обучения Spark ML;
- поддержка четырех языков программирования (Scala, Java, Python, R);
- интеграция с аналитическими инструментами;
- in-memory обработка данных дает отличную производительность.
В качестве аппаратной платформы закупили сервера Oracle Big Data Appliance. Начинали с шести узлов в продуктивном контуре с 2x24-core CPU и 256 ГБ памяти на каждом. Текущая конфигурация содержит 18 таких же узлов с расширенной до 512 ГБ памятью.
На схеме показана верхнеуровневая архитектура Data Research Platform и смежных систем. Центральное звено — кластер Hadoop на базе дистрибутива Cloudera (CDH). Он используется для как для получения с помощью Sqoop и хранения данных КХД в HDFS — в поколоночном формате Parquet, допускающем использование кодеков для сжатия, например, Snappy. Также кластер обрабатывает данные: Impala используется для ELT-подобных трансформаций, Spark — для Data Science задач. Для разделения доступа к данным используется Sentry.
Impala имеет интерфейсы для практически всех современных enterprise-средств аналитики. Помимо этого в качестве клиентов могут подключаться произвольные инструменты, поддерживающие ODBC/JDBC интерфейсы. Для работы с SQL мы в качестве основных клиентов рассматриваем Hue и TOAD for Hadoop.
Для управления всеми потоками, которые указаны на схеме стрелочками, предназначена ETL-подсистема, состоящая из средств SAS (Metadata Server, Data Integration Studio), и ETL фреймворк, написанный на базе SAS и shell-скриптов с использованием базы для хранения метаданных ETL-процессов. Руководствуясь правилами, заданными в метаданных, ETL-подсистема запускает процессы обработки данных как на КХД, так и на Data Research Platform. В итоге мы имеем сквозную систему мониторинга и управления потоками данных вне зависимости от используемой среды (Teradata, Impala, Spark и прочее, если в том будет потребность).
Через грабли к звездам
Разгрузить КХД вроде бы просто. На входе и выходе реляционные СУБД, бери да переливай данные через Sqoop. Судя по описанию выше, у нас все шло очень гладко, но, конечно же, без приключений не обошлось, и это, пожалуй, самая интересная часть всего проекта.
С нашим объемом переливать все данные целиком каждый день можно было не надеяться. Соответственно, из каждого объекта хранилища нужно было научиться выделять надежный инкремент, что не всегда просто, когда в таблице могут изменяться данные за исторические бизнес-даты. Для решения этой задачи мы систематизировали объекты в зависимости от способов загрузки и ведения истории. Потом для каждого типа определили правильный предикат для Sqoop и способ загрузки в приемник. И наконец, написали инструкцию для разработчиков новых объектов.
Sqoop – очень качественный инструмент, но не во всех случаях и комбинациях систем он работает абсолютно надежно. На наших объемах недостаточно оптимально работал коннектор к Teradata. Мы воспользовались открытостью кода Sqoop и внесли изменения в библиотеки коннектора. Стабильность соединения при перемещении данных увеличилась.
По какой-то причине при обращении Sqoop к Teradata предикаты не совсем правильно конвертируются в WHERE-условия. Из-за этого Sqoop иногда пытается вытащить огромную таблицу и зафильтровать ее уже позже. Здесь пропатчить коннектор не удалось, но мы нашли другой выход: принудительно создаем временную таблицу с наложенным предикатом для каждого выгружаемого объекта и просим Sqoop перелить именно ее.
Все MPP, и Teradata в частности, обладают особенностью, связанной с параллельным хранением данных и исполнением инструкций. Если эту особенность не принимать в расчет, то может оказаться, что всю работу возьмет на себя один логический узел кластера, из-за чего выполнение запроса станет гораздо медленнее, раз этак в 100-200. Мы, конечно, не могли этого допустить, поэтому написали специальный движок, который использует ETL-метаданные таблиц КХД и выбирает оптимальную степень параллелизации задач Sqoop.
Историчность в хранилище – дело тонкое, особенно если использовать SCD2, при том что в Impala не поддерживаются UPDATE и DELETE. Мы, конечно, хотим, чтобы исторические таблицы в Data Research Platform выглядели абсолютно так же, как в Teradata. Этого можно достигнуть, комбинируя получение инкремента через Sqoop, выделение обновляемых бизнес-ключей и удаление партиций в Impala. Чтобы эту вычурную логику не пришлось писать каждому разработчику, мы упаковали ее в специальную библиотеку (на нашем ETL-сленге «загрузчик»).
Напоследок — вопрос с типами данных. Impala достаточно свободно относится к конвертации типов, поэтому с какими-то затруднениями мы столкнулись только в типах TIMESTAMP и CHAR/VARCHAR. Для даты-времени мы решили хранить данные в Impala в текстовом (STRING) формате YYYY-MM-DD HH:MM:SS. Этот подход, как оказалось, вполне позволяет использовать функции трансформации даты и времени. Для строковых данных заданной длины оказалось, что хранение в формате STRING в Impala ничем им не уступает, поэтому мы тоже использовали его.
Обычно для организации Data Lake копируют данные источников в полуструктурированных форматах в специальную stage-область в Hadoop, после чего средствами Hive или Impala устанавливают схему десериализации этих данных для использования их в SQL-запросах. Мы пошли по тому же пути. Важно отметить, что не все и не всегда имеет смысл тащить в хранилище данных, так как разработка процессов копирования файликов и установка схемы значительно дешевле загрузки бизнес-атрибутов в модель КХД с помощью ETL-процессов. Когда еще непонятно, в каком объеме, на какой срок и с какой периодичностью нужны данные источника, Data Lake в описанном подходе является простым и дешевым решением. Сейчас мы регулярно загружаем в Data Lake прежде всего источники, генерирующие пользовательские события: данные анализа заявок, логи и сценарии перехода автозвонилки и автоответчика Avaya, карточные транзакции.
Инструментарий аналитиков
Мы не забыли о еще одной цели всего проекта — дать возможность аналитикам пользоваться всем этим богатством. Вот основные принципы, которыми мы здесь руководствовались:
- Удобство инструмента в использовании и поддержке
- Применимость в задачах Data Science
- Максимальная возможность использования вычислительных ресурсов кластера Hadoop, а не серверов приложений или компьютера исследователя
И вот на чем остановились:
- Python + Anaconda. В качестве среды используется iPython/Jupyter
- R + Shiny. Исследователь работает в desktop или web-версии R Studio, Shiny применяется для разработки web-приложений, которые заточены на использование алгоритмов, разработанных в R.
- Spark. Для работы с данными используются интерфейсы для Python (pyspark) и R, настроенные в средах разработки, указанных в предыдущих пунктах. Оба интерфейса позволяют задействовать библиотеку Spark ML, которая дает возможность обучать ML-модели на кластере Hadoop/Spark.
- Данные в Impala доступны через Hue, Spark и из сред разработки с помощью стандартного интерфейса ODBC и специальных библиотек типа implyr
Сейчас в Data Lake находится порядка 100 Тб данных из розничного хранилища плюс около 50 Тб из ряда OLTP-источников. Озеро обновляется ежедневно в инкрементальном режиме. В дальнейшем мы собираемся повышать удобство для пользователей, выводить ELT-нагрузку на Impala, увеличивать количество источников, загружаемых в Data Lake, и расширять возможности для продвинутой аналитики.
В заключение хотелось бы дать несколько общих советов коллегам, которые только начинают свой путь в создании больших хранилищ:
- Используйте лучшие практики. Если бы мы не имели ETL-подсистемы, метаданных, версионного хранения и понятной архитектуры, то не осилили бы эту задачу. Лучшие практики окупают себя, хотя и не сразу.
- Помните об объемах данных. Большие данные могут создавать технические сложности в совсем неожиданных местах.
- Следите за новыми технологиями. Новые решения появляются часто, не все они полезны, но иногда встречаются настоящие жемчужины.
- Больше экспериментируйте. Не стоит доверять только маркетинговым описаниям решений – пробуйте сами.
Кстати, о том, как наши аналитики использовали машинное обучение и данные банка для работы с кредитными рисками, вы можете почитать в отдельном посте.
