
В данной статье рассмотрим архитектуры простых и эффективных KV-хранилищ с использованием цепной репликации (chain replication), которая активно исследуется и успешно применяется в различных системах.
Это — первая половина статьи о цепной репликации. Вторая часть находиться здесь. Сначала будет немного теории, затем несколько примеров использования с различными модификациями.
- Цель — постановка задачи и сравнение с primary/backup протоколом.
- Цепная репликация — базовый подход.
- Цепная репликация — распределённые запросы.
- FAWN: a Fast Array of Wimpy Nodes.
1. Введение
1.1 Цель
Предположим, что мы хотим спроектировать простую систему хранения данных (key-value store). У хранилища будет очень минимальный интерфейс:
- write(key, object): сохранить/обновить значение value по ключу key.
- read(key): вернуть сохранённое значение по ключу key.
Также мы знаем, что размер данных сравнительно небольшой (всё помещается на один сервер, нет необходимости в шардинге), а вот запросов на запись/чтение может быть очень и очень много.
Наша цель — выдерживать большое количество запросов (high throughput, HT), иметь высокую доступность (high availability, HA) и строгую согласованность (strong consistency, SC).
Во многих системах SC жертвуется ради HA + HT, потому что выполнение всех трёх свойств является нетривиальной задачей. Amazon Dynamo стало огромным скачком вперёд и породило ряд Dynamo-style баз данных, такие как Cassandra, Riak, Voldemort, и т. д.
1.2 Primary/Backup
Один из самых распространённых и простых подходов построения такой системы хранения данных является использование primary/backup репликации.
Имеем 1 primary сервер, несколько backup серверов, операции записи/чтения идут только через primary сервер.

Здесь на картинке изображён один из возможных протоколов взаимодействия (primary ждёт ack от всех backup перед отправкой ack клиенту), существуют и другие варианты (не взаимоисключающие), например:
- Primary строго упорядочивает запросы на запись.
- Primary шлёт ack как только один из backup ответил ack.
- Sloppy quorum and hinted handoff.
- И т.д.
Также необходим отдельный процесс, который мониторит состояние кластера (раздаёт конфигурацию участникам) и при падении ведущего сервера производит (инициирует) выборы нового, а также определяет что делать в случае split brain. Опять же, в зависимости от требований, часть этой логики может быть выполнена как часть алгоритма репликации, часть — как стороннее приложение (например, zookeeper для хранения конфигурации) и т.д.
Очевидно, рано или поздно производительность primary/backup репликации будет ограничена двумя узкими местами:
- Производительность primary сервера.
- Количество backup серверов.
Чем больше требований надёжности/согласованности предъявляется к кластеру, тем быстрее этот момент наступит.
А есть ли другие способы достижения нашей цели?
1.3 Цепная репликация

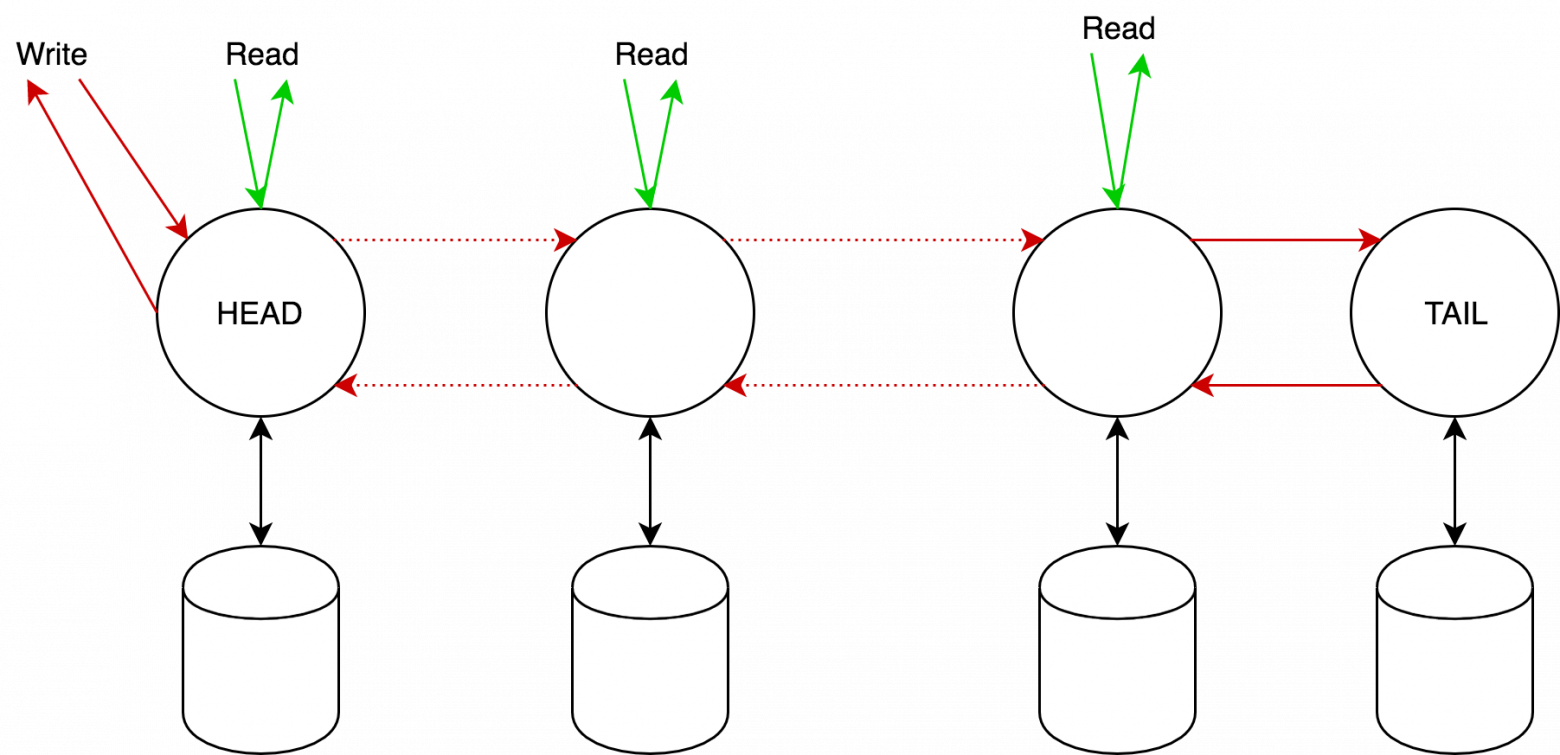
В общем виде цепная репликация состоит из последовательности (цепь) серверов, со специальными ролями HEAD (сервер, с которым общается клиент) и TAIL (конец цепи, гарантия SC). Цепь обладает как минимум следующими свойствами:
- Выдерживает падение до n — 1 серверов.
- Скорость на запись несущественно отличается от скорости SC Primary/Backup.
- Переконфигурация кластера в случае падения HEAD происходит значительно быстрее, чем Primary, остальные серверы — сравнительно или быстрее, чем в Primary/Backup.
Маленькое, но существенное замечание — требуется наличие надёжной FIFO связи между серверами.
Рассмотрим далее более детально различные способы построения цепной репликации.
2. Базовый подход

2.1 Алгоритм работы
Клиенты посылают write-запросы на head узел, а read-запросы — на tail узел. Ответ всегда приходит от tail. Head, получив запрос на изменение, вычисляет необходимое изменение состояния, применяет, и отсылает это следующему узлу. Как только tail его обработает, назад по цепочке рассылается ACK ответ. Очевидно, если запрос на чтение возвращает некоторое значение x, то оно сохранено на всех узлах.
2.2 Протокол репликации
Пронумеруем серверы от head к tail, тогда на каждом узле
 будем дополнительно хранить:
будем дополнительно хранить: — список полученных запросов узлом, которые ещё не были обработаны tail.
— список полученных запросов узлом, которые ещё не были обработаны tail.  — список запросов, отправленных сервером своему преемнику, которые ещё не были обработаны tail.
— список запросов, отправленных сервером своему преемнику, которые ещё не были обработаны tail. — история изменений значения ключа (можно хранить как историю, так и просто итоговое значение). Заметим, что:
— история изменений значения ключа (можно хранить как историю, так и просто итоговое значение). Заметим, что: 
- А также:

2.3 Обработка отказа серверов
Как было сказано во введении, нам нужен некий мастер-процесс который:
- Определяет отказавший сервер.
- Оповещает его предшественника и преемника об изменениях в цепи.
- Если сервер — tail или head, то оповещает клиентов об их изменении.
Мы полагаем, что мастер-процесс стабилен и никогда не падает. Выбор такого процесса остаётся за рамками данной статьи.
Второе очень важное допущение — мы полагаем, что сервера являются fail-stop:
- В случае какого-либо (внутреннего) отказа сервер прекращает работу, а не выдаёт некорректный результат.
- Отказ сервера всегда определяется мастер-процессом.
Рассмотрим, как происходит добавление нового сервера:
Теоретически, новый сервер можно добавить в любое место цепи, добавление в хвост видится наименее сложным — нужно только скопировать состояние текущего tail на новый сервер, оповестить мастер об изменении в цепи и оповестить старый tail о том, что запросы теперь нужно посылать далее.
Наконец, рассмотрим три возможных сценария отказа:
2.3.1 Падение head
Просто удаляем сервер из цепи и назначаем следующий новым head. Произойдёт только потеря тех запросов из
 , которые не были отправлены далее —
, которые не были отправлены далее — 
2.3.2 Падение tail
Удаляем сервер из цепи и назначаем предыдущий новым tail, перед этим
 очищается (все эти операции помечаются как обработанные tail), соответственно
очищается (все эти операции помечаются как обработанные tail), соответственно  уменьшается.
уменьшается.2.3.3 Падение промежуточного узла

Мастер информирует узлы
 и
и  об изменение порядка в цепи.
об изменение порядка в цепи.Возможна потеря
 , если узел не успел отправить их дальше своему преемнику, поэтому после удаления узла из цепи первым делом заново отсылаются и только после этого узел продолжает обрабатывать новые запросы.
, если узел не успел отправить их дальше своему преемнику, поэтому после удаления узла из цепи первым делом заново отсылаются и только после этого узел продолжает обрабатывать новые запросы.2.4 Сравнение с backup/primary протоколом
- В цепной репликации только один сервер (tail) участвует в выполнение read запросов, причём он выдаёт ответ сразу, тогда как в P/B primary может ждать подтверждения выполнения запросов на запись.
- В обоих подходах write запрос выполняется на всех серверах, P/B выполняет это быстрее за счёт параллельного выполнения.
Задержки chain replication при отказах:
- Head: выполнение запросов на чтение не прерывается, запросы на запись задерживаются на 2 сообщения — от мастера всем серверам о новом head и от мастера всем клиентам о новом head.
- Промежуточный сервер: выполнение запросов на чтение не прерывается. Запросы на запись могут быть задержаны на время выполнения , потерь обновлений нет.
- Tail: Задержка запросов на чтение и на запись на два сообщения — оповещение
 о новом tail и оповещение клиентов о новом tail.
о новом tail и оповещение клиентов о новом tail.
Задержки P/B при отказах:
- Primary: задержка на 5 сообщений для выбора нового primary и синхронизации состояния.
- Backup: нет задержек на чтение при условии отсутствия запросов на запись. При появлении запроса на запись возможна задержка на 1 сообщение.
Как видно, наихудший отказ (tail) для chain replication быстрее, чем наихудший для P/B (Primary).
Авторами данного подхода были произведены нагрузочные тесты, которые показали сравнимую производительность с P/B протоколом.
3. Распределённые запросы (Chain Replication with Apportioned Queries — CRAQ)
Базовый подход имеет очевидное слабое место — tail, которые обрабатывает все read запросы. Это может приводить к двум проблемам:
- Tail становится hotspot, т.е. сервером, который обрабатывает гораздо больше запросов, чем любой другой узел.
- При размещении цепи в нескольких дата-центрах tail может оказаться очень «далеко» что будет тормозить write запросы.
Идея CRAQ довольно проста — разрешим запросам на чтение приходить на все сервера, кроме tail, а для обеспечения согласованности будем хранить вектор версий объекта для write запросов, и в случае неоднозначности узлы будут делать запрос в tail для получения последней зафиксированной версии.
3.1 CRAQ
Формализуем архитектуру CRAQ:
Каждый узел, кроме tail, обрабатывает read запросы и возвращает ответ, а head возвращает ответ от write запросов (сравните с базовым подходом).
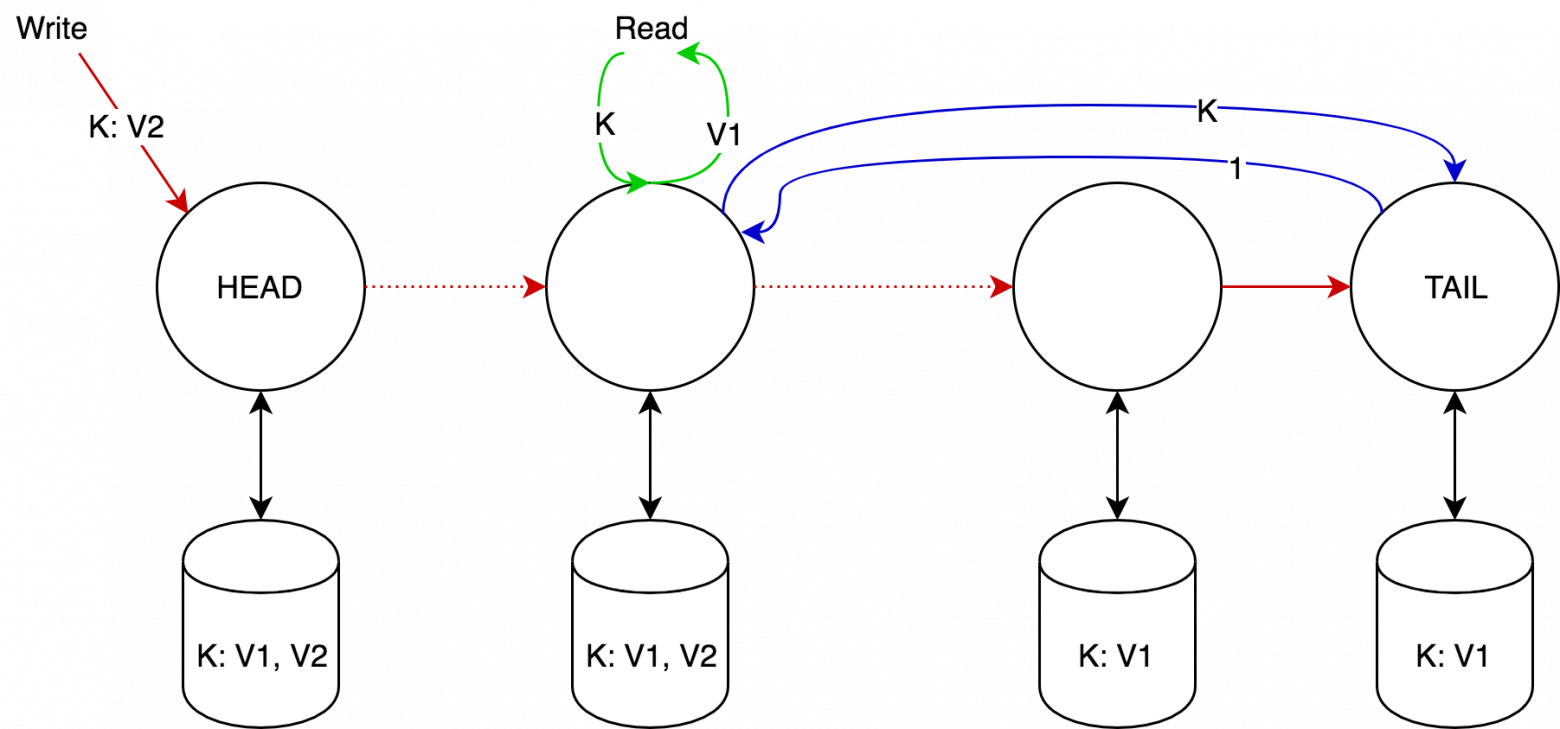
На каждом не-tail узле может храниться несколько версий одного и того же объекта, причём версии образуют строго монотонно возрастающую последовательность. К каждой версии добавляется дополнительный атрибут «чистая» или «грязная». Изначально все версии чистые.
Как только узел получает write запрос, он добавляет полученную версию к списку версий, а дальше:
- Если узел — tail, то он помечает версию как чистую, в этот момент версия считается зафиксированной, и отправляет подтверждение назад по цепочке.
- Иначе — помечает версию как грязную и отправляет запрос дальше по цепочке.
Как только узел получает подтверждение от преемника, он помечает версию как чистую и удаляет все предыдущие версии.
Как только узел получает запрос на чтение:
- Если последняя известная узлу версия объекта — чистая, то он возвращает её.
- Иначе — он делает запрос к tail на получение последней зафиксированной версии объекта, которую он и возвращает клиенту. (По построению такая версия всегда будет на узле).
Для приложений с преобладанием read запросов производительность CRAQ растёт линейно с ростом узлов, в случае с преобладанием write запросов — производительность будет не хуже, чем у базового подхода.
CRAQ может быть расположена как в одном, так и в нескольких дата-центрах. Это даёт возможность клиентам выбирать ближайшие узлы для повышения скорости read запросов.
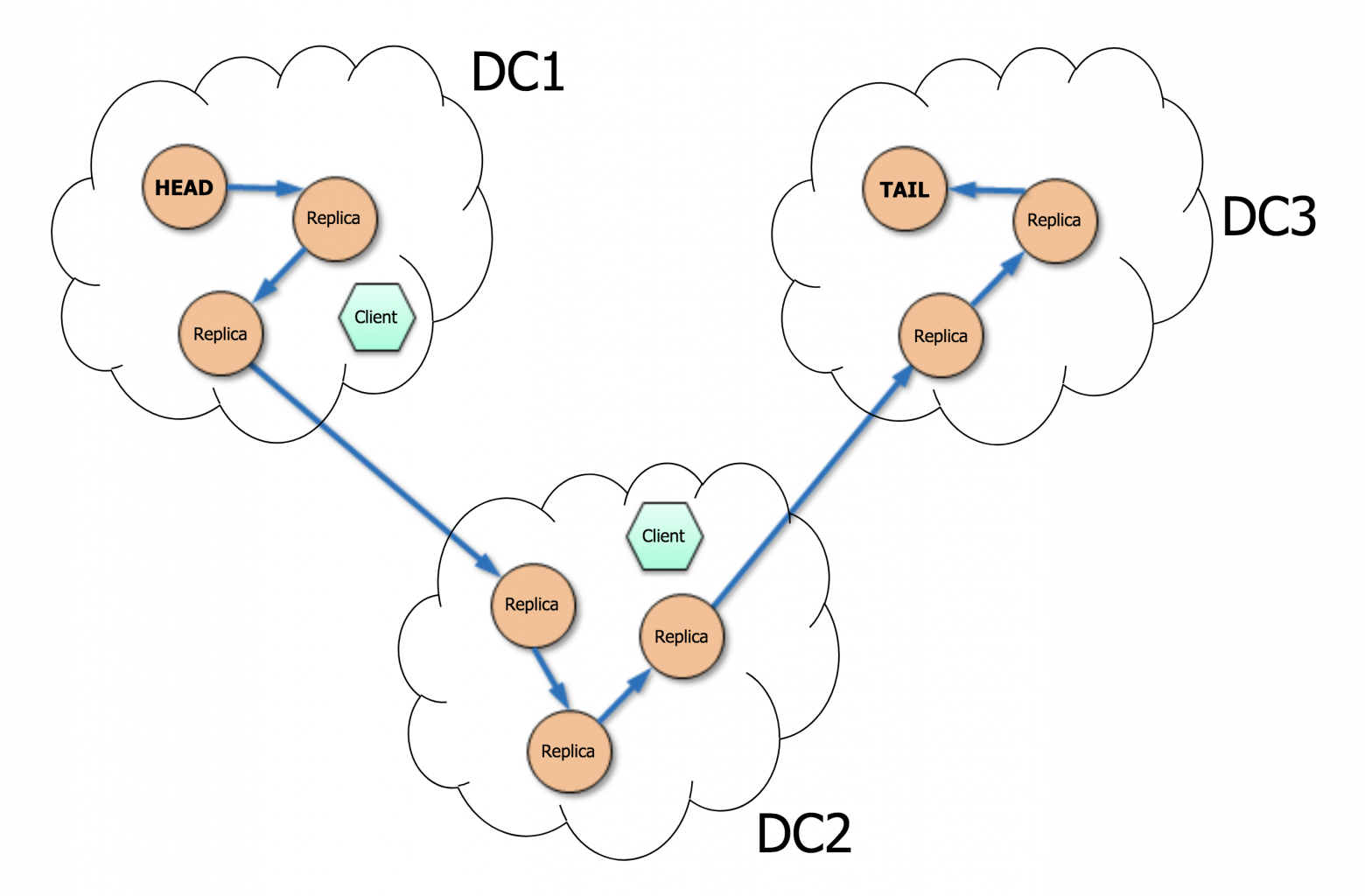
3.2 Согласованность в CRAQ
CRAQ обеспечивает strong consistency, кроме одного случая: когда узел получает последнюю зафиксированную версию у tail, tail может зафиксировать новую версию до того, как узел ответил клиенту. В этой ситуации CRAQ обеспечивает монотонное чтение (последовательные read запросы не будут уходить в прошлое, но могут вернуть старые данные) на всей цепи.
Также возможны более слабые согласованности:
- Eventual Consistency: узел не будет запрашивать последнюю зафиксированную версию у tail. Это нарушит монотонное чтение на всей цепи, но сохранит монотонное чтение на одном узле. Кроме того, это позволяет выдерживать разделение сети (partitioning tolerance).
- Bounded Eventual Consistency: возвращать грязную версию только до определённого момента. Например, разница между грязной и чистой версиями не должна превышать N ревизий. Или ограничение по времени.
3.3 Обработка отказов серверов
Аналогично базовому подходу.
3.4 Дополнительно
CRAQ обладает одной интересной особенностью — при операции записи можно использовать мультикаст. Предположим, head рассылает изменение мультикастом и посылает далее по цепочке лишь некоторый идентификатор этого события. Если до узла не пришло само обновление, то он может подождать и получить его от следующего узла когда Tail разошлёт подтверждение фиксации изменения. Аналогично, tail может разослать мультикастом подтверждение фиксации.
4. FAWN: a Fast Array of Wimpy Nodes
Очень интересное исследование, напрямую не относящееся к теме данной статьи, но служит примером использования цепной репликации.
Высокопроизводительные key-value хранилища (Dynamo, memcached, Voldemort) обладают общими характеристиками — требовательны к I/O, минимум вычислений, параллельный независимый доступ к рандомным ключам в больших количествах, значения ключей небольшого размера — до 1Kb.
Сервера с HDD не подходят для таких кластеров из-за долгой операции seek (времени случайного доступа), а сервера с большим количеством DRAM потребляют на удивление большое количество мощности — 2GB DRAM эквивалентно 1Tb HDD.
Построение эффективного (по пропускной способности) кластера с минимальным потреблением мощности и является целью оригинального исследования. 50% стоимости сервера за три года составляют затраты на электричество, а современные режимы энергосбережения не так уж и эффективны, как их рекламируют — в тестах при 20% нагрузке потребление CPU оставалось на уровне 50%, плюс остальные компоненты сервера вовсе не имеют режимов энергосбережения (DRAM, например, и так работает на минимуме). Важно отметить, что в таких кластерах увеличивается разрыв между CPU и I/O — мощный CPU вынужден ждать выполнения I/O операции.
4.1 Архитектура
FAWN кластер строится на старых серверах по $250 (Цены 2009 года), со встроенным CPU 500MHz, 512Mb RAM, 32Gb SSD. Если вы знакомы с архитектурой Amazon Dynamo или с consistent hashing, то архитектура FAWN вам будем знакома:
- Каждый физический сервер содержит несколько виртуальных узлов, каждый имеет свой VID.
- VID образуют кольцо (ring), каждый VID отвечает за диапазон “позади себя” (например, A1 отвечает за ключи в диапазоне R1).
- Для повышения надёжности данные реплицируются на R следующих узлов по часовой стрелке. (например, при R=2 ключ на A1 реплицируется на B1 и C1), таким образом мы получаем цепную репликацию (базовый подход).
- Запросы на чтение идут на tail цепи, т.е. Чтение ключа с A1 уйдёт на C1.
- Запросы на запись идут на head цепи и проходят до конце.

Карта серверов хранится на кластере frontend-серверов, каждый из которых отвечает за свой определённый список VID, и может перенаправить запрос на другой frontend-сервер.
4.2 Результаты тестирования
В нагрузочном тестировании FAWN достигает QPS (Queries per second) равным 90% от QPS на random read флеш-диска.
В следующей таблице сравнивается Total Cost of Ownership (TCO) различных конфигураций, где основой для Traditional является $1000 сервер с потреблением 200W (Цены 2009 года):

Таким образом, если:
- Большое количество данных, мало запросов: FAWN + 2Tb 7200 RPM
- Небольшое количество данных, много запросов: FAWN + 2GB DRAM
- Средние значения: FAWN + 32GB SSD


