
Продолжаем рассматривать примеры использования цепной репликации. Базовые определения и архитектуры были даны в первой части, рекомендую ознакомиться с ней перед прочтением второй части.
В этой статье мы изучим следующие системы:
- Hibari — распределённое отказоустойчивое хранилище, написанное на эрланге.
- HyperDex — распределённое key-value хранилище с поддержкой быстрого поиска по вторичным атрибутам и поиска по диапазону.
- ChainReaction — Causal+ согласованность и гео-репликация.
- Построение распределённой системы без использования дополнительных внешних процессов мониторинга/переконфигурации.
5. Hibari
Hibari — распределённое отказоустойчивое KV-хранилище, написанное на эрланге. Использует цепную репликацию (базовый подход), т.о. достигает строгой согласованности. В тестах Hibari показывает высокую производительность — на двухюнитовых серверах достигается несколько тысяч апдейтов в секунду (запросы по 1Kb)
5.1 Архитектура
Для размещения данных используется consistent hashing. Основой хранилища являются физические и логические блоки. Физический блок (physical brick) — это сервер с линуксом, может быть и EC2 инстанс и вообще VM в целом. Логический блок (logical brick) — это инстанс хранилища, с которым работают основные процессы кластера и каждый блок является узлом какой-либо одной цепи. В примере ниже кластер сконфигурирован с размещением 2 логических блоков на каждом физическом блоке и с длиной цепи 2. Заметим, что узлы цепи “размазываются” по физическим блокам для повышения надёжности.
Мастер-процесс (см определение в первой части) называется Admin server.
Данные хранятся в “таблицах”, которые служат просто разделением на неймспейсы, каждая таблица хранится как минимум в одной цепи, а каждая цепь хранит данные только одной таблицы.
Клиент Hibari получает обновления от Admin server со списком всех head и tail всех цепей (и всех таблиц). Таким образом, клиенты знают сразу на какой логический узел посылать запрос.

5.2 Хеширование
Hibari использует пару
 для определения имени цепи, которая хранит ключ
для определения имени цепи, которая хранит ключ  в таблице
в таблице  : ключ отображается на интервал
: ключ отображается на интервал  (с помощью MD5), который разбит на участки, за которые отвечает какая-то одна цепь. Участки могут быть разной ширины, в зависимости от «веса» цепи, например:
(с помощью MD5), который разбит на участки, за которые отвечает какая-то одна цепь. Участки могут быть разной ширины, в зависимости от «веса» цепи, например: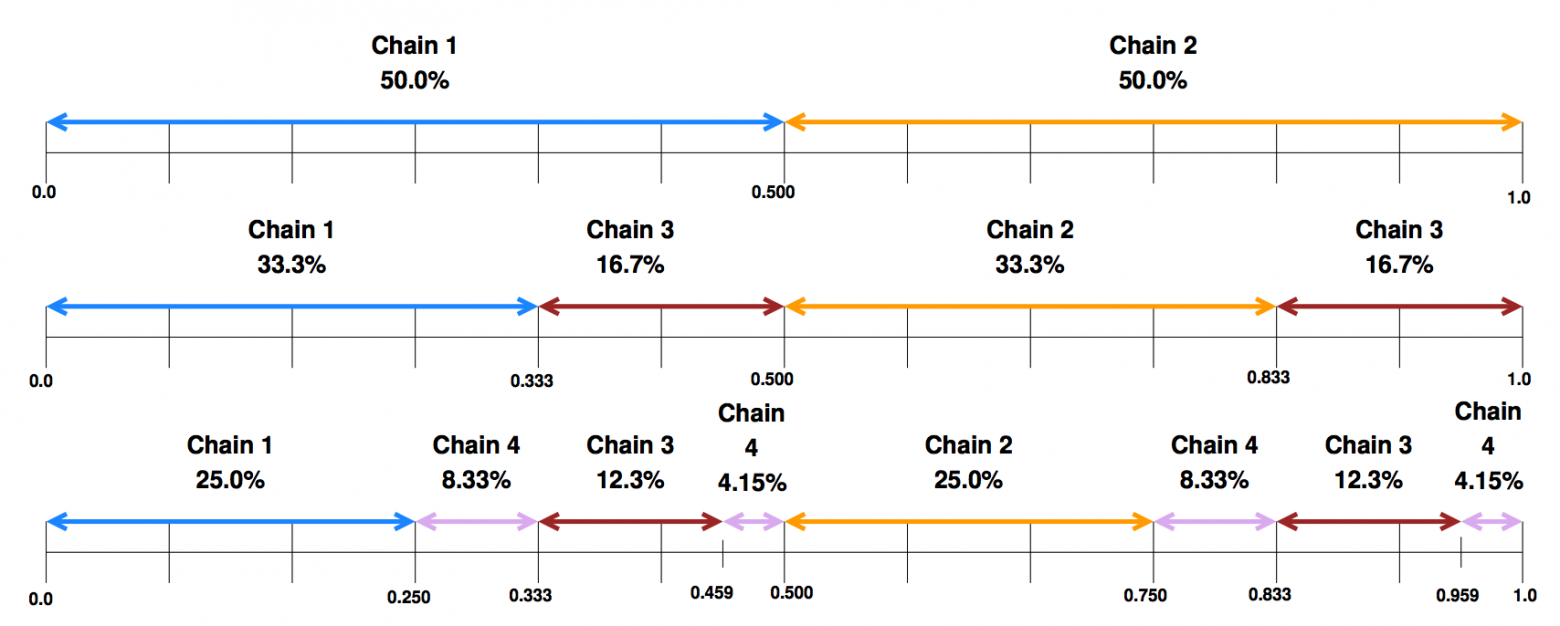
Таким образом, если какие-то физические блоки очень мощные, то расположенным на ним цепям можно выдать более широкие участки (тогда на них будет попадать больше ключей).
6. HyperDex
Целью этого проекта являлось построение распределённого key-value хранилища, которое, в отличие от других популярных решений (BigTable, Cassandra, Dynamo), будет поддерживать быстрый поиск по вторичным атрибутам и сможет быстро выполнять поиск по диапазону. К примеру, в ранее рассмотренных системах, для поиска всех значений в некотором диапазоне придётся пройтись по всем серверам, что, очевидно, неприемлемо. HyperDex решает эту задачу используя Hyperspace Hashing.
6.1 Архитектура
Идея hyperspace hashing состоит в построении
 -мерного пространства где каждый атрибут соответствует одной координатной оси. Например, для объектов (first-name, last-name, phone-number) пространство может выглядеть вот так:
-мерного пространства где каждый атрибут соответствует одной координатной оси. Например, для объектов (first-name, last-name, phone-number) пространство может выглядеть вот так:
Серая гиперплоскость проходит по всем ключам, где last-name = Smith, жёлтая — по всем ключам, где first-name = John. Пересечение этих плоскостей образует ответ на запрос поиска номеров телефонов людей с именем John и фамилией Smith. Таким образом, запрос на
 атрибутах возвращает
атрибутах возвращает  -мерное подпространство.
-мерное подпространство.Поисковое пространство разбивается на
-мерные непересекающиеся регионы, и каждый регион назначается какому-то одному серверу. Объект с координатами из региона хранится на сервере этого региона. Таким образом строится хеш между объектами и серверами.Запрос поиска (по диапазону) определит регионы, входящие в результирующую гиперплоскость и, таким образом, сократит количество опрашиваемых серверов до минимума.
В таком подходе есть одна проблема — количество требуемых серверов растёт экспоненциально от количества атрибутов, т.е. если атрибутов
, то нужно  серверов. Для решения этой проблемы в HyperDex применяется разбиение гиперпространства на подпространства (с меньшей размерностью) с, соответственно, подмножеством атрибутов:
серверов. Для решения этой проблемы в HyperDex применяется разбиение гиперпространства на подпространства (с меньшей размерностью) с, соответственно, подмножеством атрибутов: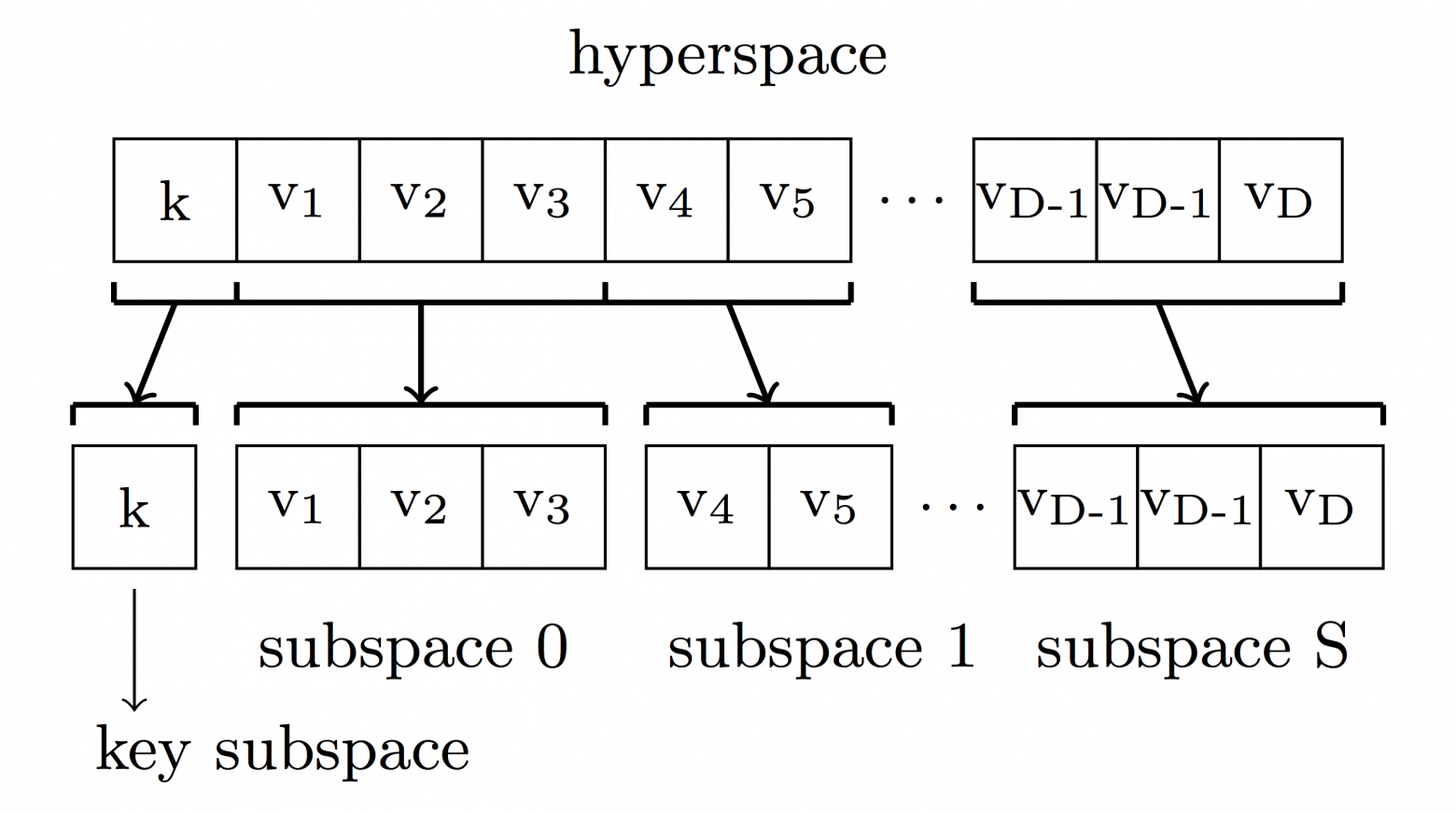
6.2 Репликация
Для обеспечения строгой согласованности авторы разработали специальный подход, основанный на цепной репликации — value dependent chaining, где каждый следующий узел определяется хешированием соответствующего атрибута. Например, ключ
 сначала будет захеширован в пространство ключей (получим head цепи, также называемый point leader), далее хеш от
сначала будет захеширован в пространство ключей (получим head цепи, также называемый point leader), далее хеш от  в координату на соответствующей оси и так далее. (Смотри картинку ниже на примере обновления
в координату на соответствующей оси и так далее. (Смотри картинку ниже на примере обновления  ).
).Все обновления проходят через point leader, который упорядочивает запросы (линеаризуемость).

Если обновление приводит к изменению региона, то сначала новая версия записывается сразу за старой (см обновление
 ), а после получения ACK от tail ссылка на старую версию с предыдущего сервера будет изменена. Чтобы одновременные запросы (например, и
), а после получения ACK от tail ссылка на старую версию с предыдущего сервера будет изменена. Чтобы одновременные запросы (например, и  ) не нарушили согласованность point leader добавляет версионность и другую мета-информацию, чтобы сервера, в случае получения раньше могли определить, что порядок нарушен и нужно подождать .
) не нарушили согласованность point leader добавляет версионность и другую мета-информацию, чтобы сервера, в случае получения раньше могли определить, что порядок нарушен и нужно подождать .7. ChainReaction
Используется causal+ модели сходимости, которая добавляет условие бесконфликтной сходимости к causal (причинной) сходимости. Для выполнения causal сходимости к каждому запросу добавляются метаданные, в которых указываются версии всех причинно-зависимых ключей. ChainReaction позволяет делать гео-репликацию в нескольких датацентрах и является дальнейшим развитием идеи CRAQ.
7.1 Архитектура
Используется архитектура из FAWN с небольшими изменениями — каждый ДЦ состоит из data servers — бэкенды (хранение данных, репликация, образуют DHT кольцо) и client proxies — фронтенды (направляют запрос на конкретный узел). Каждый ключ реплицируется на R последовательных узлов, образуя цепь. Запросы на чтение обрабатываются tail, запись — head.
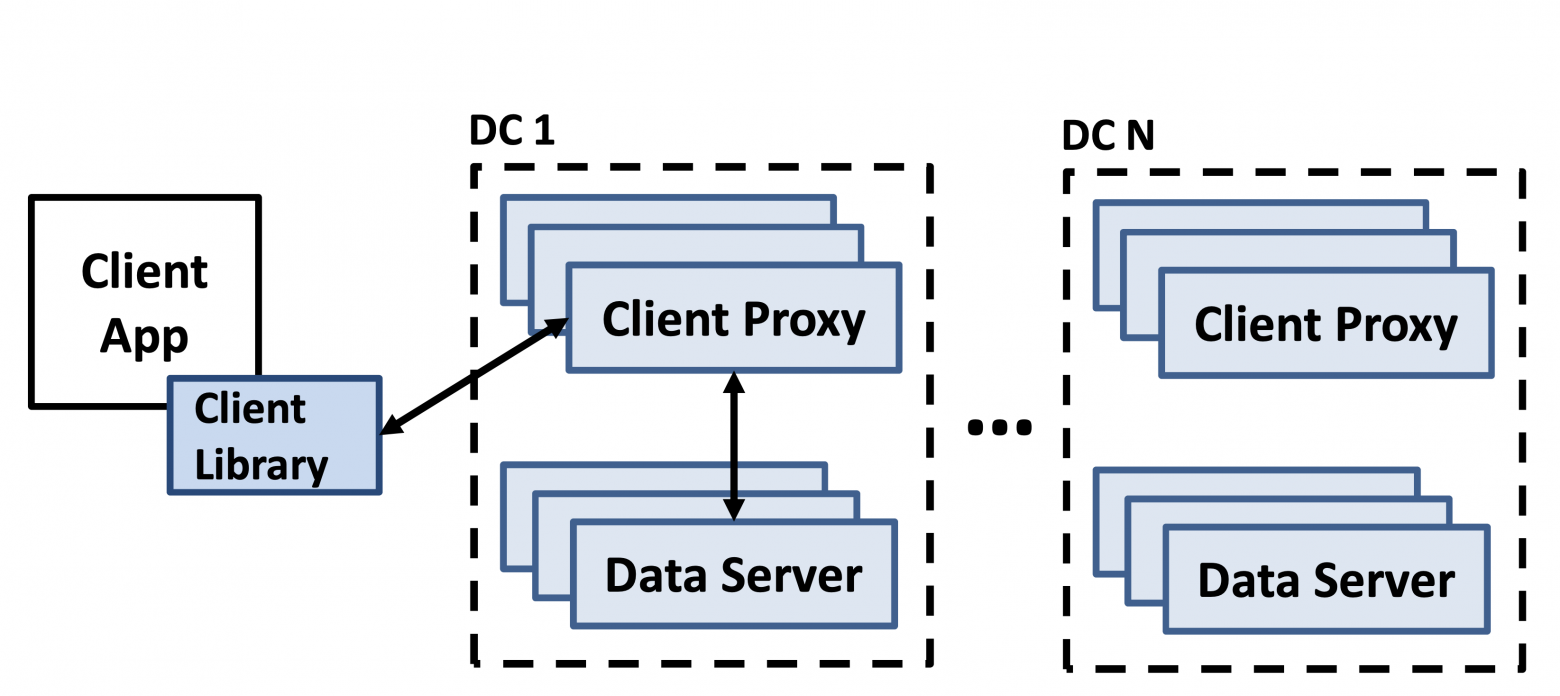
7.2 Один дата-центр
Отметим одно важное свойство, вытекающее из цепной репликации — если узел
causal-согласован с какими-то клиентскими операциями, то все предыдущие узлы — тоже. Таким образом, если операция  была замечена нами последний раз на узле
была замечена нами последний раз на узле  , то все causal-зависимые (от ) операции чтения могут быть выполнены только на узлах от head до . Как только будет выполнена на tail — ограничения на чтения не будет. Обозначим операции записи, которые были выполнены tail в ДЦ
, то все causal-зависимые (от ) операции чтения могут быть выполнены только на узлах от head до . Как только будет выполнена на tail — ограничения на чтения не будет. Обозначим операции записи, которые были выполнены tail в ДЦ  , как DC-Write-Stable(d).
, как DC-Write-Stable(d).На каждом клиенте хранится список (метадата) всех запрошенных клиентом ключей в формате (key, version, chainIndex), где chainIndex — позиция узла в цепи, который ответил на последний запрос про ключ key. Метадата хранится только для ключей, о которых клиенту неизвестно, являются ли он DC-Write-Stable(d) или нет.
7.2.1 Выполнение операции записи
Заметим, что как только операция стала DC-Write-Stable(d), то никакой запрос на чтение не может прочитать предыдущие версии.
На каждый запрос записи добавляется список всех ключей, на которые были выполнены операции чтения до последней операции записи. Как только client proxy получает запрос, он выполняет блокирующие операции чтения на tails всех ключей из метадаты (ждём подтверждения наличия такой же или более новой версии, иными словами выполняем условие causal consistency). Как только подтверждения получены, запрос на запись направляется на head соответствующей цепи.
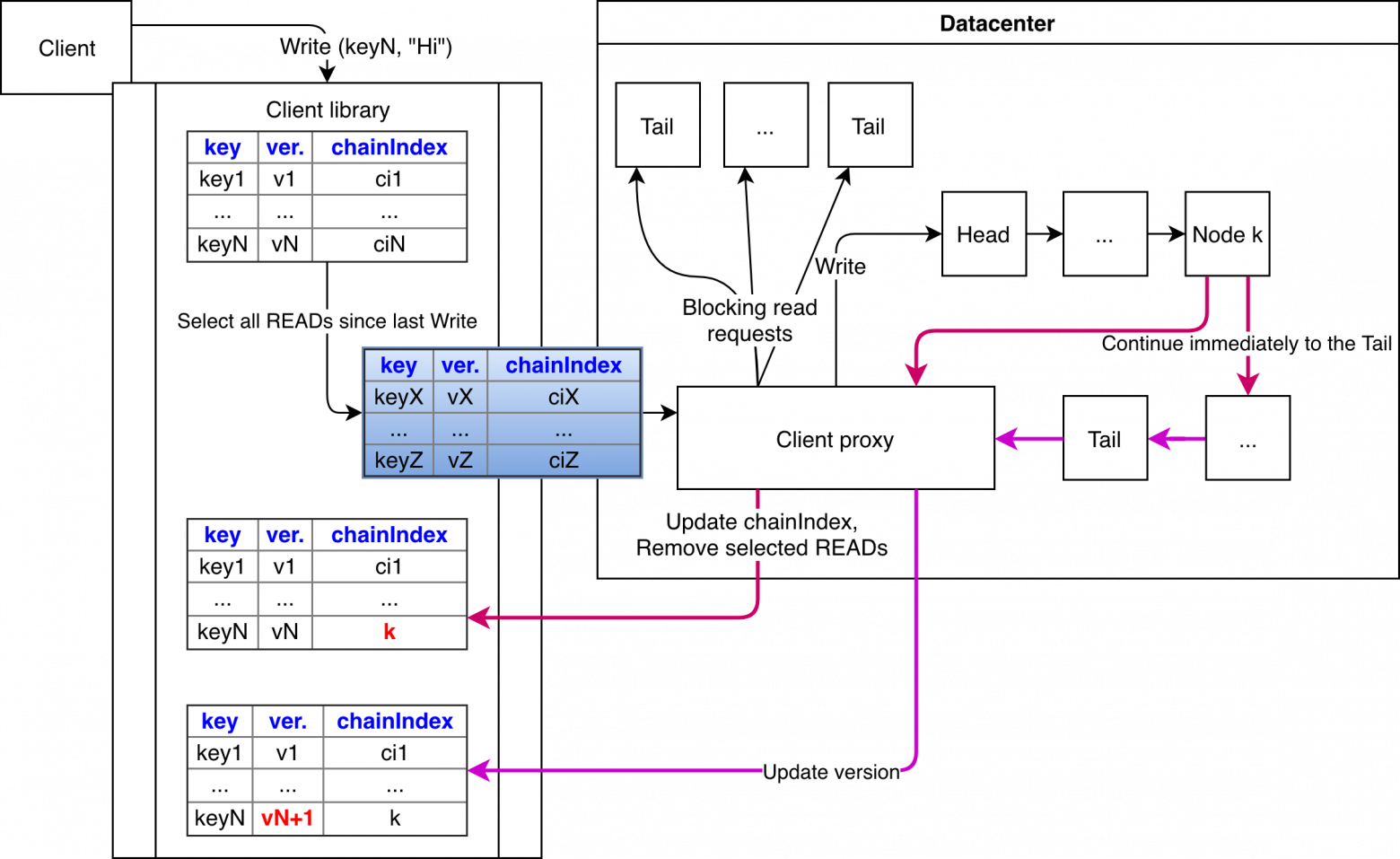
Как только новое значение сохранено на
узлах цепи, уведомление пересылается на клиент (с индексом последнего узла). Клиент обновляет chainIndex и удаляет метадату отправленных ключей, т.к. про них стало известно, что они DC-Write-Stable(d). Параллельно этому запись продолжается дальше — lazy propagation. Таким образом приоритет отдаётся операциям записи на первых узлах. Как только tail сохранит новую версию ключа, уведомление пересылается на клиент и передаётся всем узлам цепи, чтобы они пометили ключ, как стабильный.7.2.2 Выполнение операции чтения
Client proxy отправляет запрос на чтение на
 узел в цепи, распределяя при этом нагрузку. В ответ узел посылает значение и версию этого значения. Ответ отправляется клиенту, при этом:
узел в цепи, распределяя при этом нагрузку. В ответ узел посылает значение и версию этого значения. Ответ отправляется клиенту, при этом:- Если версия — стабильная, то новый chainIndex равен размеру цепи.
- Если версия — более новая, то новый chainIndex = index.
- Иначе chainIndex не изменяется.
7.2.3 Обработка отказов узлов
Почти полностью идентично базовому подходу, с некоторыми отличиями в том, что в некоторых случаях chainIndex на клиенте становится невалиден — это легко определяется при выполнении запросов (нет ключа с такой версией) и запрос перенаправляется на head цепи для поиска узла с нужной версией.
7.3 Несколько ( ) дата-центров (гео-репликация)
) дата-центров (гео-репликация)
Возьмём за основу алгоритмы из односерверной архитектуры и адаптируем их по-минимум. Для начала, в метадате вместо просто значений версии и chainIndex нам потребуются версионные векторы размерностей N.
Определим Global-Write-Stable похожим образом с DC-Write-Stable(d) — операция записи считается Global-Write-Stable если она была выполнена на tails во всех ДЦ.
В каждом ДЦ появляется новый компонент — remote_proxy, в его задачу входит приём/отправка обновлений из других ДЦ.
7.3.1 Выполнение операции записи (на сервере  )
)
Начало аналогично односерверной архитектуре — выполняем блокирующие чтения, записываем на первые
узлов цепи. В этот момент client proxy отправляет клиенту новый вектор chainIndex, где везде нули, кроме позиции — там значение . Далее — как обычно. Дополнительная операция в самом конце — обновление пересылается remote_proxy, который накапливает несколько запросов и затем все рассылает.Здесь возникает две проблемы:
- Как обеспечить зависимости между разными обновлениями, пришедшими из разных ДЦ?
Каждый remote_proxy хранит локальный вектор версий размерности , в котором хранится количество отправленных и полученных обновлений, и отправляет его в каждом обновлении. Таким образом, при получении обновления из другого ДЦ, remote_proxy сверяет счётчики, и если локальный счётчик меньше — операция блокируется до получения соответствующего обновления.
размерности , в котором хранится количество отправленных и полученных обновлений, и отправляет его в каждом обновлении. Таким образом, при получении обновления из другого ДЦ, remote_proxy сверяет счётчики, и если локальный счётчик меньше — операция блокируется до получения соответствующего обновления. - Как обеспечить зависимости для данной операции в других ДЦ?
Это достигается использованием фильтра Блума. При выполнении операций записи/ чтения от client proxy в дополнение к метадате также присылается фильтр блума на каждый ключ (называются фильтры ответа). Эти фильтры хранятся в списке AccessedObjects, и, при запросе операций записи/чтения, в метадате также отправляется OR по фильтрам отправляемый ключей (называется фильтр зависимостей). Аналогично, после выполнения операции записи соответствующие фильтры удаляются. При отправке операции записи в другой ДЦ также отправляются фильтр зависимостей и фильтр ответа этого запроса.
Далее, удалённый ДЦ, получив всю эту информацию, проверяет — если установленные биты фильтра ответа совпадают с установленными битами нескольких фильтров запроса — то такие операции потенциально casual-зависимы. Потенциально — потому что фильтр блума.
7.3.2 Выполнение операции чтения
Аналогично односерверной архитектуре с поправкой на использование вектора chainIndex вместо скаляра и возможность отсутствия ключа в ДЦ (т.к. обновления асинхронные) — тогда либо ждать, либо перенаправлять запрос в другой ДЦ.
7.3.3 Разрешение конфликтов
Благодаря метадате causal-завиисмые операции всегда выполняются в корректном порядке (иногда приходится блокировать процесс ради этого). А вот конкурентные изменения в разных ДЦ могут приводить к конфликтам. Для разрешения таких ситуаций применяется Last Write Wins, для чего в каждой операции обновления присутствует пара
 , где
, где  — часы на proxy, а
— часы на proxy, а  — id ДЦ.
— id ДЦ.7.3.4 Обработка отказов узлов
Аналогично односерверной архитектуре.
8. Leveraging Sharding in the Design of Scalable Replication Protocols
Целью исследования является построение распределённой системы с шардами и с репликацией без использования внешнего мастер-процесса для переконфигурации/мониторинга кластера.
В основных текущих подходах авторы видят следующие недостатки:
Репликация:
- Primary/Backup — приводит к расхождению состояния, если Primary по ошибке был определён как сбойный.
- Quorum Intersection — может приводить к расхождению состояния во время переконфигурации кластера.
Строгая согласованность:
- Протоколы полагаются на алгоритмы голосования с выбором большинства (например, Paxos), где требуется
 узлов для выдерживания падения узлов.
узлов для выдерживания падения узлов.
Выявление отказов узлов:
- P/B и CR подразумевает наличие идеального детектирования отказавших узлов с моделью fail-stop, что на практике недостижимо и приходится выбирать удовлетворяющий интервал сканирования.
- ZooKeeper подвержен тем же проблемам — при большом количестве клиентов необходимо существенное количество времени (>1 секунды), чтобы они обновили конфигурацию.
Предложенный авторами подход, названный Elastic replication, лишён этих недостатков, и обладает следующими характеристиками:
- Строгая согласованность.
- Для выдерживания падения узлов надо иметь
 узел.
узел. - Переконфигурация без потери согласованности.
- Нет необходимости в протоколах консенсуса, основанных на голосовании большинства.
Сводная табличка:

8.1 Организация реплик
На каждом шарде определяется последовательность конфигураций
 , например новая конфигурация не содержит какую-то упавшую реплику
, например новая конфигурация не содержит какую-то упавшую реплику 
Каждый элемент последовательности конфигурации состоит из:
- replicas — набор реплик.
- orderer — id реплики со специальной ролью (см ниже).
Каждый шард представляется набором реплик (по построению —
), т.о. мы не разделяем на роли «шард» и «реплика».Каждая реплика хранит следующие данные:
- conf — id конфигурации, которой принадлежит эта реплика.
- orderer — какая реплика является orderer данной конфигурации.
- mode — режим реплики, один из трёх:
 (все реплики из не-
(все реплики из не- ),
),  (все реплики из ),
(все реплики из ),  .
. - history — последовательность операций над собственно данными реплики
 (или просто состояние).
(или просто состояние). - stable — максимальная длина префикса history, который зафиксирован данной репликой. Очевидно, что
 .
.
Основная задачи orderer реплики — рассылать запросы остальным репликам и поддерживать наибольший префикс history:

8.2 Организация шардов
Шарды объединяются в кольца, называемые elastic bands. Каждый шард принадлежит только одному кольцу. Предшественник каждого шарда
 выполняет специальную роль — он является sequencer для него. Задача sequencer — выдавать его преемнику новую конфигурацию в случае отказов реплик.
выполняет специальную роль — он является sequencer для него. Задача sequencer — выдавать его преемнику новую конфигурацию в случае отказов реплик.
Требуется выполнение двух условий:
- В каждом elastic band есть как минимум один шард и одна рабочая реплика.
- В каждом elastic band есть как минимум один шард, у которого все реплики — рабочие.
Второе условие кажется чересчур строгим, однако оно эквивалентно «традиционному» условию о том, что мастер-процесс никогда не падает.
8.3 Использование Chain replication
Как вы уже могли догадаться, реплики организуются как цепь (базовый подход) — orderer будет head, с небольшими отличиями:
- В случае отказа в CR узел выкидывается из цепи (и заменяется новым), в ER — создаётся новая цепь.
- Read запросы в CR обрабатываются tail, в ER — проходят через всю цепь аналогично write-запросам.
8.5 Переконфигурация в случае отказа
- Реплики мониторятся как репликами своего шарда, так и репликами sequencer шарда.
- Как только обнаруживается отказ — репликами рассылается команда об этом.
- Sequencer высылает новую конфигурацию (без отказавшей реплики).
- Создаётся новая реплика, которая синхронизирует своё состояние с elastic band.
- После этого sequencer высылает новую конфигурацию с добавленной репликой.
Ссылки
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Уровень сложности статьи
0%Сложный0
87.5%Приемлемый7
12.5%Лёгкий1
0%Другое (напишу в комментариях)0
Проголосовали 8 пользователей. Воздержались 7 пользователей.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Длина статьи
22.22%Коротковата2
66.67%Самое то6
11.11%Большая1
0%Другое (напишу в комментариях)0
Проголосовали 9 пользователей. Воздержались 7 пользователей.

