Нагрузочное тестирование не так сильно востребовано и распространено, как иные виды тестирования — инструментов, позволяющих, провести такое тестирование, не так много а простых и удобных вообще можно пересчитать на пальцах одной руки.
Когда речь заходить о тестировании производительности — в первую очередь все думают о JMeter’е — он бесспорно остается самым известным инструментом с самым большим количеством плагинов. Мне же JMeter никогда не нравился из-за неочевидного интерфейса и высокого порога вхождения, как только возникает необходимость протестировать не Hello World приложение.
И вот, окрыленный успехом проведения тестирования в двух различных проектах, решил поделится информацией об относительно простом и удобном софте — Locust
Для тех, кому лень идти под кат, записал видео:
Опенсорс тул, позволяющий задать сценарии нагрузки Python кодом, поддерживающий распределенную нагрузку и, как уверяют авторы, использовался для нагрузочного тестирования Battlelog для серии игр Battlefild (сразу подкупает)
Из плюсов:
Из минусов:
Любое тестирование — комплексная задача, требующая планирования, подготовки, контроля выполнения и анализа результатов. При нагрузочном тестировании, если есть возможность, можно и нужно собирать все возможные данные, которые могут повлиять на результат:
Описанные далее примеры можно классифицировать как black-box функциональное нагрузочное тестирование. Даже не зная ничего о тестируемом приложении и не доступа к логам, мы можем измерить его производительность.
Для того, чтобы на практике проверять нагрузочные тесты, я развернул локально простой веб сервер https://github.com/typicode/json-server. Почти все следующие примеры я буду приводить для него. Данные для сервера я взял из развернутого онлайн примера — https://jsonplaceholder.typicode.com/
Для его запуска необходим nodeJS.
Очевидный спойлер: как и с тестированием безопасности — эксперименты с нагрузочным тестированием лучше проводить на кошках локально, не нагружая онлайн сервисы, чтобы вас не забанили
Для того, чтобы начать, также необходим Python — во всех примерах я буду использовать версию 3.6, а также сам locust (на момент написания статьи — версия 0.9.0). Его можно установить командой
Подробности установки можно подсмотреть в официальной документации.
Далее нам нужен файл теста. Я взял пример из документации, так как он очень прост и понятен:
Все! Этого реально достаточно, чтобы начать тест! Давайте разберем пример, прежде чем перейдем к запуску.
Пропуская импорты, в самом начале мы видим 2 почти одинаковые функции логина и логаута, состоящие из одной строчки. l.client — объект HTTP сессии, с помощью которой мы будем создавать нагрузку. Мы используем метод POST, почти идентичный такому же в библиотеке requests. Почти — потому что в данном примере мы передаем в качестве первого аргумента не полный URL, а только его часть — конкретный сервис.
Вторым аргументом передаются данные — и не могу не заметить, что очень удобно использовать словари Python, которые автоматически конвертируются в json
Также можно обратить внимание, что мы никак не обрабатываем результат запроса — если он будет успешен, результаты (например cookie), будут сохранены в этой сессии. Если произойдет ошибка — она будет записана и добавлена в статистику о нагрузке
Если нам захочется узнать, правильно ли мы написали запрос, можно всегда проверить его следующим образом:
Я добавил только переменную base_url, которая должна содержать полный адрес тестируемого ресурса.
Следующее несколько функций — запросы, за счет которых будет создаваться нагрузка. Опять же, нам не нужно обрабатывать ответ сервера — результаты пойдут сразу в статистику.
Дальше — класс UserBehavior (название класса может быть любое). Как видно из названия, в нем будет описано поведение сферического пользователя в вакууме тестируемого приложения. Свойству tasks мы передаем словарь методов, которые будет вызывать пользователь и их частоту вызовов. Теперь, несмотря на то, что мы не знаем, какую функцию и в каком порядке будет вызывать каждый пользователь — они выбираются случайно, мы гарантируем, что функция index вызовется в среднем в 2 раза чаще, чем функция profile.
Кроме поведения, родительский класс TaskSet позволяет задать 4 функции, которые можно выполнить до и после тестов. Порядок вызовов будет следующим:
Здесь же стоит упомянуть, что есть 2 способа объявления поведения пользователя: первый уже указан в примере выше — функции объявлены заранее. Второй способ — объявления методов прямо внутри класса UserBehavior:
В этом примере функции пользователя и частота их вызова задана с помощью аннотации task. Функционально же ничего не изменилось
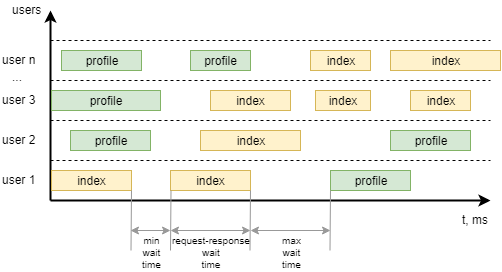
Последний класс из примера — WebsiteUser (название класса может быть любое). В этом классе мы задаем модель поведений пользователя UserBehavior***+, а также минимальное и максимальное время ожидания между вызовами отдельных task каждым пользователем. Чтобы было понятнее, вот как это можно визуализировать:
Запустим сервер, производительность которого мы будем тестировать:
Так же модифицируем файл примера, чтобы он соответствовал мог тестировать сервис, уберем логин и логаут, зададим поведение пользователя:
Для запуска в командной строке надо выполнить команду
где host — адрес тестируемого ресурса. Именно к нему будут добавлены адреса сервисов, указанные в тесте.
Если никаких ошибок в тесте нет, нагрузочный сервер запустится и будет доступен по адресу http://localhost:8089/
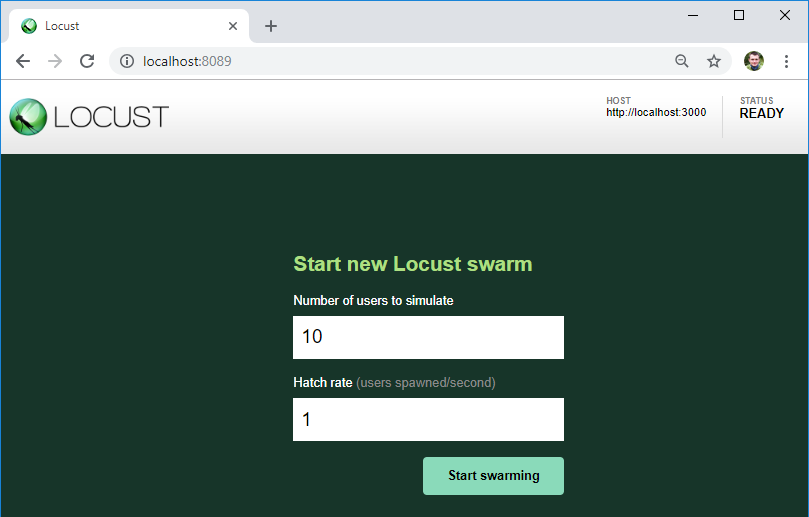
Как видим, здесь указан сервер, который мы будем тестировать — именно к этому URL будут добавлятся адреса сервисов из файла теста.
Также здесь мы можем указать количество пользователей для нагрузки и их прирост в секунду.
По кнопке начинаем нагрузку!

Через определенное время остановим тест и взглянем на первые результаты:
На второй вкладке можно посмотреть графики нагрузки в режиме реального времени. В случае, если сервер падает при определенной нагрузке или его поведение меняется, на графике это будет сразу видно.

На третей вкладке можно посмотреть ошибки — в моем случае это ошибка клиента. Но если сервер вернет 4ХХ или 5ХХ ошибку — ее текст будет записан именно здесь
Если ошибка случится в коде вашего текста — она попадет во вкладку Exceptions. Пока что у меня самая частая ошибка связана с использованием команды print() в коде — это не лучший способ логирования :)
На последней вкладке можно загрузить все результаты теста в формате csv
Эти результаты релевантны? Давайте разберемся. Чаще всего требования к производительности (если такие вообще заявляются) звучат примерно так: среднее время загрузки страницы (ответа сервера) должно быть меньше N секунд при нагрузке M пользователей. Не особо уточняя, что должны делать пользователи. И этим мне нравится locust — он создает активность конкретного числа пользователей, которые в случайном порядке выполняют предполагаемые действия, которые ожидают от пользователей.
Если нам нужно провести benchmark — измерить поведение системы при разной нагрузке, мы может создать несколько классов поведения и провести несколько тестов при разных нагрузках.
Для начала этого достаточно. Если вам понравилась статья, я в ближайшее время планирую написать о:
Когда речь заходить о тестировании производительности — в первую очередь все думают о JMeter’е — он бесспорно остается самым известным инструментом с самым большим количеством плагинов. Мне же JMeter никогда не нравился из-за неочевидного интерфейса и высокого порога вхождения, как только возникает необходимость протестировать не Hello World приложение.
И вот, окрыленный успехом проведения тестирования в двух различных проектах, решил поделится информацией об относительно простом и удобном софте — Locust
Для тех, кому лень идти под кат, записал видео:
Что это?
Опенсорс тул, позволяющий задать сценарии нагрузки Python кодом, поддерживающий распределенную нагрузку и, как уверяют авторы, использовался для нагрузочного тестирования Battlelog для серии игр Battlefild (сразу подкупает)
Из плюсов:
- простая документация, включая copy-paste пример. Можно начать тестить, даже почти не умея программировать
- “Под капотом” использует библиотеку requests (HTTP для людей). Ее документацию можно использовать как расширенную шпаргалку и дебажить тесты
- поддержка Python — мне просто нравится язык
- Предыдущий пункт дает кроссплатформенность для запуска тестов
- Собственный веб сервер на Flask для отображения результатов тестирования
Из минусов:
- Никаких Capture & Replay — все руками
- Результат предыдущего пункта — нужен мозг. Как и в случае с использованием Postman, необходимо понимание работы HTTP
- Нужны минимальные навыки программирования
- Линейная модель нагрузки — что сразу расстраивает любителей генерировать пользователей “по Гауссу”
Процесс тестирования
Любое тестирование — комплексная задача, требующая планирования, подготовки, контроля выполнения и анализа результатов. При нагрузочном тестировании, если есть возможность, можно и нужно собирать все возможные данные, которые могут повлиять на результат:
- Hardware сервера (CPU, RAM, ROM)
- Software сервера (OS, версии сервера, JAVA, .NET, и пр., база данных и количество самих данных, логи сервера и тестируемого приложения)
- Пропускная способность сети
- Наличие прокси серверов, балансировщиков нагрузки и DDOS защиты
- Данные нагрузочного тестирования (количество пользователей, среднее время отклика, количество запросов в секунду)
Описанные далее примеры можно классифицировать как black-box функциональное нагрузочное тестирование. Даже не зная ничего о тестируемом приложении и не доступа к логам, мы можем измерить его производительность.
Перед началом
Для того, чтобы на практике проверять нагрузочные тесты, я развернул локально простой веб сервер https://github.com/typicode/json-server. Почти все следующие примеры я буду приводить для него. Данные для сервера я взял из развернутого онлайн примера — https://jsonplaceholder.typicode.com/
Для его запуска необходим nodeJS.
Очевидный спойлер: как и с тестированием безопасности — эксперименты с нагрузочным тестированием лучше проводить на кошках локально, не нагружая онлайн сервисы, чтобы вас не забанили
Для того, чтобы начать, также необходим Python — во всех примерах я буду использовать версию 3.6, а также сам locust (на момент написания статьи — версия 0.9.0). Его можно установить командой
python -m pip install locustio
Подробности установки можно подсмотреть в официальной документации.
Разбор примера
Далее нам нужен файл теста. Я взял пример из документации, так как он очень прост и понятен:
from locust import HttpLocust, TaskSet def login(l): l.client.post("/login", {"username":"ellen_key", "password":"education"}) def logout(l): l.client.post("/logout", {"username":"ellen_key", "password":"education"}) def index(l): l.client.get("/") def profile(l): l.client.get("/profile") class UserBehavior(TaskSet): tasks = {index: 2, profile: 1} def on_start(self): login(self) def on_stop(self): logout(self) class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 5000 max_wait = 9000
Все! Этого реально достаточно, чтобы начать тест! Давайте разберем пример, прежде чем перейдем к запуску.
Пропуская импорты, в самом начале мы видим 2 почти одинаковые функции логина и логаута, состоящие из одной строчки. l.client — объект HTTP сессии, с помощью которой мы будем создавать нагрузку. Мы используем метод POST, почти идентичный такому же в библиотеке requests. Почти — потому что в данном примере мы передаем в качестве первого аргумента не полный URL, а только его часть — конкретный сервис.
Вторым аргументом передаются данные — и не могу не заметить, что очень удобно использовать словари Python, которые автоматически конвертируются в json
Также можно обратить внимание, что мы никак не обрабатываем результат запроса — если он будет успешен, результаты (например cookie), будут сохранены в этой сессии. Если произойдет ошибка — она будет записана и добавлена в статистику о нагрузке
Если нам захочется узнать, правильно ли мы написали запрос, можно всегда проверить его следующим образом:
import requests as r response=r.post(base_url+"/login",{"username":"ellen_key","password":"education"}) print(response.status_code)
Я добавил только переменную base_url, которая должна содержать полный адрес тестируемого ресурса.
Следующее несколько функций — запросы, за счет которых будет создаваться нагрузка. Опять же, нам не нужно обрабатывать ответ сервера — результаты пойдут сразу в статистику.
Дальше — класс UserBehavior (название класса может быть любое). Как видно из названия, в нем будет описано поведение сферического пользователя в вакууме тестируемого приложения. Свойству tasks мы передаем словарь методов, которые будет вызывать пользователь и их частоту вызовов. Теперь, несмотря на то, что мы не знаем, какую функцию и в каком порядке будет вызывать каждый пользователь — они выбираются случайно, мы гарантируем, что функция index вызовется в среднем в 2 раза чаще, чем функция profile.
Кроме поведения, родительский класс TaskSet позволяет задать 4 функции, которые можно выполнить до и после тестов. Порядок вызовов будет следующим:
- setup — вызывается 1 раз при старте UserBehavior(TaskSet) — его нет в примере
- on_start — вызывается 1 раз каждым новым пользователем нагрузки при старте работы
- tasks — выполнение самих задач
- on_stop — вызывается 1 раз каждым пользователем, когда тест заканчивает работу
- teardown — вызывается 1 раз, когда TaskSet завершает работу — его тоже нет в примере
Здесь же стоит упомянуть, что есть 2 способа объявления поведения пользователя: первый уже указан в примере выше — функции объявлены заранее. Второй способ — объявления методов прямо внутри класса UserBehavior:
from locust import HttpLocust, TaskSet, task class UserBehavior(TaskSet): def on_start(self): self.client.post("/login", {"username":"ellen_key", "password":"education"}) def on_stop(self): self.client.post("/logout", {"username":"ellen_key", "password":"education"}) @task(2) def index(self): self.client.get("/") @task(1) def profile(self): self.client.get("/profile") class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 5000 max_wait = 9000
В этом примере функции пользователя и частота их вызова задана с помощью аннотации task. Функционально же ничего не изменилось
Последний класс из примера — WebsiteUser (название класса может быть любое). В этом классе мы задаем модель поведений пользователя UserBehavior***+, а также минимальное и максимальное время ожидания между вызовами отдельных task каждым пользователем. Чтобы было понятнее, вот как это можно визуализировать:
Начало работы
Запустим сервер, производительность которого мы будем тестировать:
json-server --watch sample_server/db.json
Так же модифицируем файл примера, чтобы он соответствовал мог тестировать сервис, уберем логин и логаут, зададим поведение пользователя:
- Открыть главную страницу 1 раз при начале работы
- Получить список всех постов х2
- Написать комментарий к первому посту х1
from locust import HttpLocust, TaskSet, task class UserBehavior(TaskSet): def on_start(self): self.client.get("/") @task(2) def posts(self): self.client.get("/posts") @task(1) def comment(self): data = { "postId": 1, "name": "my comment", "email": "test@user.habr", "body": "Author is cool. Some text. Hello world!" } self.client.post("/comments", data) class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Для запуска в командной строке надо выполнить команду
locust -f my_locust_file.py --host=http://localhost:3000
где host — адрес тестируемого ресурса. Именно к нему будут добавлены адреса сервисов, указанные в тесте.
Если никаких ошибок в тесте нет, нагрузочный сервер запустится и будет доступен по адресу http://localhost:8089/
Как видим, здесь указан сервер, который мы будем тестировать — именно к этому URL будут добавлятся адреса сервисов из файла теста.
Также здесь мы можем указать количество пользователей для нагрузки и их прирост в секунду.
По кнопке начинаем нагрузку!
Результаты
Через определенное время остановим тест и взглянем на первые результаты:
- Как и ожидалось, каждый из 10 созданных пользователей при старте зашел на главную страницу
- Список постов в среднем открывался в 2 раза чаще, чем писался комментарий
- Есть среднее и медианное время отклика для каждой операции, количество операций в секунду — это уже полезные данные, хоть сейчас бери и сравнивай их с ожидаемым результатом из требований
На второй вкладке можно посмотреть графики нагрузки в режиме реального времени. В случае, если сервер падает при определенной нагрузке или его поведение меняется, на графике это будет сразу видно.
На третей вкладке можно посмотреть ошибки — в моем случае это ошибка клиента. Но если сервер вернет 4ХХ или 5ХХ ошибку — ее текст будет записан именно здесь
Если ошибка случится в коде вашего текста — она попадет во вкладку Exceptions. Пока что у меня самая частая ошибка связана с использованием команды print() в коде — это не лучший способ логирования :)
На последней вкладке можно загрузить все результаты теста в формате csv
Эти результаты релевантны? Давайте разберемся. Чаще всего требования к производительности (если такие вообще заявляются) звучат примерно так: среднее время загрузки страницы (ответа сервера) должно быть меньше N секунд при нагрузке M пользователей. Не особо уточняя, что должны делать пользователи. И этим мне нравится locust — он создает активность конкретного числа пользователей, которые в случайном порядке выполняют предполагаемые действия, которые ожидают от пользователей.
Если нам нужно провести benchmark — измерить поведение системы при разной нагрузке, мы может создать несколько классов поведения и провести несколько тестов при разных нагрузках.
Для начала этого достаточно. Если вам понравилась статья, я в ближайшее время планирую написать о:
- сложных сценариях тестирования, в которых результаты одного шага используются в следующих
- обработке ответа сервера, т.к. он может быть неправильным, даже если пришел HTTP 200 OK
- неочевидных сложностях, с которыми можно столкнутся и как их обойти
- тестировании без использования UI
- распределенном нагрузочном тестировании

