Добрый день. Прошло уже 2 года с момента написания последней статьи про парсинг Хабра, и некоторые моменты изменились.
Когда я захотел иметь у себя копию хабра, я решил написать парсер, который бы сохранил весь контент авторов в базу данных. Как это вышло и с какими ошибками я встретился — можете прочитать под катом.
Первая версия парсера. Один поток, много проблем
Для начала, я решил сделать прототип скрипта, в котором бы сразу при скачивании статья парсилась и помещалась в базу данных. Недолго думав, использовал sqlite3, т.к. это было менее трудозатратно: не нужно иметь локальный сервер, создал-посмотрел-удалил и все в таком духе.
from bs4 import BeautifulSoup
import sqlite3
import requests
from datetime import datetime
def main(min, max):
conn = sqlite3.connect('habr.db')
c = conn.cursor()
c.execute('PRAGMA encoding = "UTF-8"')
c.execute("CREATE TABLE IF NOT EXISTS habr(id INT, author VARCHAR(255), title VARCHAR(255), content TEXT, tags TEXT)")
start_time = datetime.now()
c.execute("begin")
for i in range(min, max):
url = "https://m.habr.com/post/{}".format(i)
try:
r = requests.get(url)
except:
with open("req_errors.txt") as file:
file.write(i)
continue
if(r.status_code != 200):
print("{} - {}".format(i, r.status_code))
continue
html_doc = r.text
soup = BeautifulSoup(html_doc, 'html.parser')
try:
author = soup.find(class_="tm-user-info__username").get_text()
content = soup.find(id="post-content-body")
content = str(content)
title = soup.find(class_="tm-article-title__text").get_text()
tags = soup.find(class_="tm-article__tags").get_text()
tags = tags[5:]
except:
author,title,tags = "Error", "Error {}".format(r.status_code), "Error"
content = "При парсинге этой странице произошла ошибка."
c.execute('INSERT INTO habr VALUES (?, ?, ?, ?, ?)', (i, author, title, content, tags))
print(i)
c.execute("commit")
print(datetime.now() - start_time)
main(1, 490406)Всё по классике — используем Beautiful Soup, requests и быстрый прототип готов. Вот только…
Скачивание страницы идет в один поток
Если оборвать выполнение скрипта, то вся база уйдет в никуда. Ведь выполнение коммита только после всего парсинга.
Конечно, можно закреплять изменения в базе после каждой вставки, но тогда и время выполнения скрипта увеличится в разы.
Парсинг первых 100 000 статей у меня занял 8 часов.
Дальше я нахожу статью пользователя cointegrated, которую я прочитал и нашел несколько лайфхаков, позволяющих ускорить сей процесс:
- Использование многопоточности ускоряет скачивание в разы.
- Можно получать не полную версию хабра, а его мобильную версию.
Например, если статья cointegrated в десктопной версии весит 378 Кб, то в мобильной уже 126 Кб.
Вторая версия. Много потоков, временный бан от Хабра
Когда я прошерстил интернет на тему многопоточности в python, выбрал наиболее простой вариант с multiprocessing.dummy, то я заметил, что вместе с многопоточностью появились проблемы.
SQLite3 не хочет работать с более чем одним потоком.
Фиксится check_same_thread=False, но эта ошибка не единственная, при попытке вставки в базу иногда возникают ошибки, которые я так и не смог решить.
Поэтому я решаю отказаться от мгновенной вставки статей сразу в базу и, вспоминая решение cointegrated, решаю использовать файлы, т.к никаких проблем с многопоточной записью в файл нет.
Хабр начинает банить за использование более чем трех потоков.
Особо рьяные попытки достучаться до Хабра могут закончится баном ip на пару часов. Так что приходится использовать лишь 3 потока, но и это уже хорошо, так время перебора 100 статей уменьшается с 26 до 12 секунд.
Стоит заметить, что эта версия довольно нестабильна, и на большом количестве статей скачивание периодически отваливается.
from bs4 import BeautifulSoup
import requests
import os, sys
import json
from multiprocessing.dummy import Pool as ThreadPool
from datetime import datetime
import logging
def worker(i):
currentFile = "files\\{}.json".format(i)
if os.path.isfile(currentFile):
logging.info("{} - File exists".format(i))
return 1
url = "https://m.habr.com/post/{}".format(i)
try: r = requests.get(url)
except:
with open("req_errors.txt") as file:
file.write(i)
return 2
# Запись заблокированных запросов на сервер
if (r.status_code == 503):
with open("Error503.txt", "a") as write_file:
write_file.write(str(i) + "\n")
logging.warning('{} / 503 Error'.format(i))
# Если поста не существует или он был скрыт
if (r.status_code != 200):
logging.info("{} / {} Code".format(i, r.status_code))
return r.status_code
html_doc = r.text
soup = BeautifulSoup(html_doc, 'html5lib')
try:
author = soup.find(class_="tm-user-info__username").get_text()
timestamp = soup.find(class_='tm-user-meta__date')
timestamp = timestamp['title']
content = soup.find(id="post-content-body")
content = str(content)
title = soup.find(class_="tm-article-title__text").get_text()
tags = soup.find(class_="tm-article__tags").get_text()
tags = tags[5:]
# Метка, что пост является переводом или туториалом.
tm_tag = soup.find(class_="tm-tags tm-tags_post").get_text()
rating = soup.find(class_="tm-votes-score").get_text()
except:
author = title = tags = timestamp = tm_tag = rating = "Error"
content = "При парсинге этой странице произошла ошибка."
logging.warning("Error parsing - {}".format(i))
with open("Errors.txt", "a") as write_file:
write_file.write(str(i) + "\n")
# Записываем статью в json
try:
article = [i, timestamp, author, title, content, tm_tag, rating, tags]
with open(currentFile, "w") as write_file:
json.dump(article, write_file)
except:
print(i)
raise
if __name__ == '__main__':
if len(sys.argv) < 3:
print("Необходимы параметры min и max. Использование: async_v1.py 1 100")
sys.exit(1)
min = int(sys.argv[1])
max = int(sys.argv[2])
# Если потоков >3
# то хабр банит ipшник на время
pool = ThreadPool(3)
# Отсчет времени, запуск потоков
start_time = datetime.now()
results = pool.map(worker, range(min, max))
# После закрытия всех потоков печатаем время
pool.close()
pool.join()
print(datetime.now() - start_time)Третья версия. Финальная
Отлаживая вторую версию, я обнаружил, что у Хабра, внезапно, есть API, к которому обращается мобильная версия сайта. Загружается оно быстрее, чем мобильная версия, так как это просто json, который даже парсить особо не нужно. В итоге я решил заново переписать мой скрипт.
Итак, обнаружив по этой ссылке API, можно приступать к его парсингу.
import requests
import os, sys
import json
from multiprocessing.dummy import Pool as ThreadPool
from datetime import datetime
import logging
def worker(i):
currentFile = "files\\{}.json".format(i)
if os.path.isfile(currentFile):
logging.info("{} - File exists".format(i))
return 1
url = "https://m.habr.com/kek/v1/articles/{}/?fl=ru%2Cen&hl=ru".format(i)
try:
r = requests.get(url)
if r.status_code == 503:
logging.critical("503 Error")
return 503
except:
with open("req_errors.txt") as file:
file.write(i)
return 2
data = json.loads(r.text)
if data['success']:
article = data['data']['article']
id = article['id']
is_tutorial = article['is_tutorial']
time_published = article['time_published']
comments_count = article['comments_count']
lang = article['lang']
tags_string = article['tags_string']
title = article['title']
content = article['text_html']
reading_count = article['reading_count']
author = article['author']['login']
score = article['voting']['score']
data = (id, is_tutorial, time_published, title, content, comments_count, lang, tags_string, reading_count, author, score)
with open(currentFile, "w") as write_file:
json.dump(data, write_file)
if __name__ == '__main__':
if len(sys.argv) < 3:
print("Необходимы параметры min и max. Использование: asyc.py 1 100")
sys.exit(1)
min = int(sys.argv[1])
max = int(sys.argv[2])
# Если потоков >3
# то хабр банит ipшник на время
pool = ThreadPool(3)
# Отсчет времени, запуск потоков
start_time = datetime.now()
results = pool.map(worker, range(min, max))
# После закрытия всех потоков печатаем время
pool.close()
pool.join()
print(datetime.now() - start_time)
В нем присутствует поля, относящиеся как к самой статье, так и к автору, который её написал.
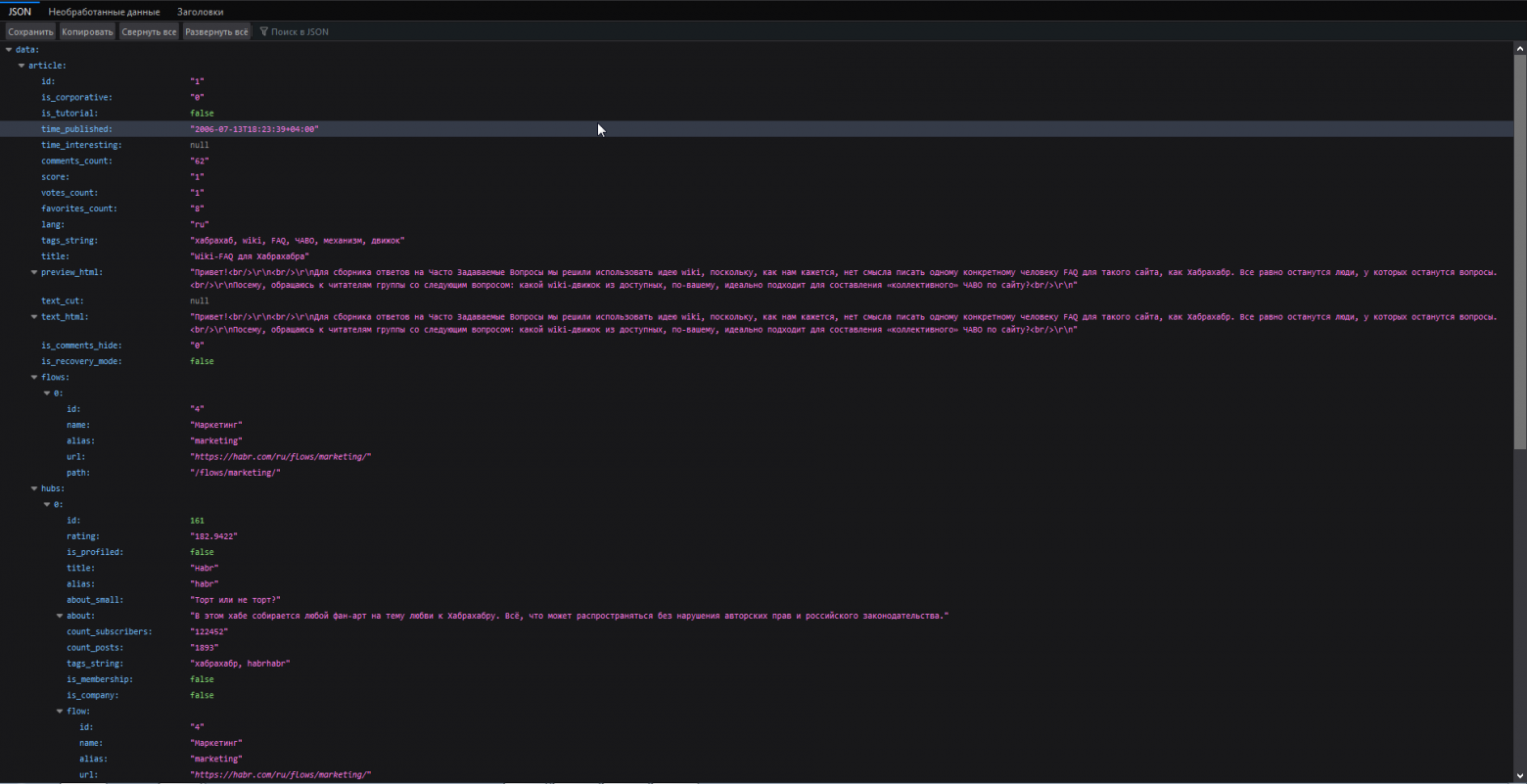
Я не стал дампить полный json каждой статьи, а сохранял лишь нужные мне поля:
- id
- is_tutorial
- time_published
- title
- content
- comments_count
- lang — язык, на котором написана статья. Пока что в ней только en и ru.
- tags_string — все теги из поста
- reading_count
- author
- score — рейтинг статьи.
Таким образом, используя API, я уменьшил время выполнения скрипта до 8 секунд на 100 url.
После того, как мы скачали нужные нам данные, нужно их обработать и внести в базу данных. С этим тоже не возникло проблем:
import json
import sqlite3
import logging
from datetime import datetime
def parser(min, max):
conn = sqlite3.connect('habr.db')
c = conn.cursor()
c.execute('PRAGMA encoding = "UTF-8"')
c.execute('PRAGMA synchronous = 0') # Отключаем подтверждение записи, так скорость увеличивается в разы.
c.execute("CREATE TABLE IF NOT EXISTS articles(id INTEGER, time_published TEXT, author TEXT, title TEXT, content TEXT, \
lang TEXT, comments_count INTEGER, reading_count INTEGER, score INTEGER, is_tutorial INTEGER, tags_string TEXT)")
try:
for i in range(min, max):
try:
filename = "files\\{}.json".format(i)
f = open(filename)
data = json.load(f)
(id, is_tutorial, time_published, title, content, comments_count, lang,
tags_string, reading_count, author, score) = data
# Ради лучшей читаемости базы можно пренебречь читаемостью кода. Или нет?
# Если вам так кажется, можно просто заменить кортеж аргументом data. Решать вам.
c.execute('INSERT INTO articles VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)', (id, time_published, author,
title, content, lang,
comments_count, reading_count,
score, is_tutorial,
tags_string))
f.close()
except IOError:
logging.info('FileNotExists')
continue
finally:
conn.commit()
start_time = datetime.now()
parser(490000, 490918)
print(datetime.now() - start_time)
Статистика
Ну и традиционно, напоследок можно извлечь немного статистики из данных:
- Из ожидаемых 490 406 было скачано лишь 228 512 статей. Получается, что более половины(261894) статей на хабре было скрыто или удалено.
- Вся база, состоящая из почти полумиллиона статей, весит 2.95 Гб. В сжатом виде — 495 Мб.
- Всего на Хабре авторами являются 37804 человек. Напоминаю, что это статистика только из живых постов.
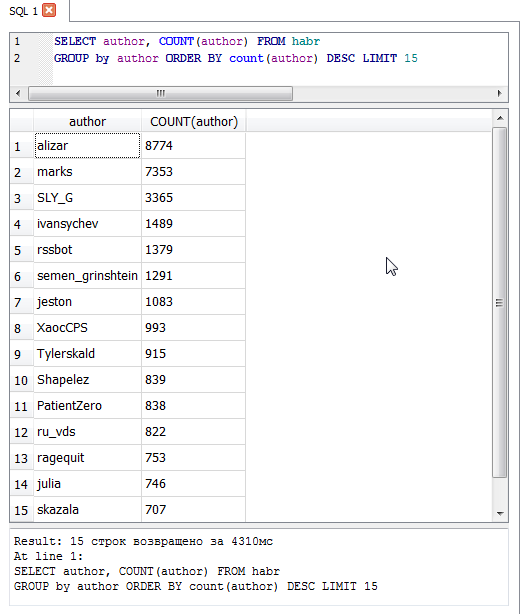
- Самый продуктивный автор на Хабре — alizar — 8774 статьи.
- Статья с самым большим рейтингом — 1448 плюсов
- Самая читаемая статья — 1660841 просмотров
- Самая обсуждаемая статья — 2444 комментария