
Всем привет!
На сегодняшний день данные и всё связанное с ними (ML, AI, DataMining, etc) это самый хайповый тренд в IT-индустрии. Все - от ритейлеров до компаний Илона Маска - работают (или пытаются работать) с данными. Нас в Леруа Мерлен эта волна не обошла стороной - data-driven подход к принятию решений является одним из основных в компании. Следуя ему, мы создали свою платформу данных, которой на данный момент пользуется около 2 тыс.человек, а в минуту обрабатывается примерно 1800 запросов. В этой статье мы (Data-команда Леруа Мерлен Россия) расскажем, как за 2 года построили платформу данных в компании с большим количеством оффлайн-процессов, про ее архитектуру и опыт, который мы получили в процессе создания.
С чего все начиналось
В 2016 году, задолго до появления платформы, был нужен инструмент, чтобы строить отчеты, проводить аналитику и рисовать графики. Тогда решили просто связать DB-link’ами все основные базы данных компании. Решение оказалось не масштабируемым, при этом потребность в аналитических отчетах росла, как и требования к ним, при этом влияли они на все бизнес-процессы компании.
В 2017 мы решили пойти к большому вендору: купить у него один или два шкафа железа, точно также залить туда свои данные и продолжать строить отчеты. Но это оказалось тоже проблемно с точки зрения масштабируемости, так как место заканчивается, и нужно снова идти к вендору, покупать новый шкаф и платить за него кучу денег. Прежде чем отдавать эти деньги, хотелось посмотреть, а что вообще в мире делают большие data-driven компании, которые не только принимают основанные на данных решения, но и занимаются предсказанием. Посмотрев на них, компания приняла решение о создании своей платформы данных.
Первые шаги к своей платформе
Чтобы это сделать, нужно было сначала собрать все данные в единое хранилище и пустить в него дата-инженеров, дата-аналитиков и дата-сайентистов, чтобы они смогли построить в нем свои модели, обучить их, нарисовать витрины, построить и написать сервисы для работы с данными. Короче говоря, извлечь пользу для наших пользователей (= сотрудников компании).
Мы ожидали, что это будет стоить очень дорого. Чтобы избежать очередной покупки нового железа, нам нужно было разработать стратегию наших действий и понять, как мы будем двигаться дальше.
Прежде всего мы выработали 3 основных принципа работы над нашей будущей платформой:
Экспертиза внутри компании. Все знания, полученные при создании платформы, должны консолидироваться у команды Леруа Мерлен;
Использование opensource. По максимуму использовать наработки сообщества и развивать их, а не тратиться на проприетарные продукты;
Cloud native & cloud agnostic. Мы должны строить платформу, которую можно разворачивать в облаках, но не завязываться на конкретное облачное решение.
Тут можно долго дискутировать и обсуждать тезисы из каждого пункта, но мы – технари, а бизнес нам дал руль и позволил полностью управлять процессом создания платформы. И нам, как техническим специалистам, было ясно, что, придерживаясь этих правил, мы можем сами создавать и развивать платформу с той скоростью, которая нам необходима:
Мы не завязаны на вендорах - если нам что-то нужно, мы можем сами это написать и законтрибьютить.
Мы не завязаны на подрядчиков – мы сами знаем, что, как и где писать.
Мы не завязаны на инфраструктуру – не нужно заказывать оборудование и ждать по полгода, пока его привезут и установят.
Платформа данных за 2 года
Так в 2019 году мы начали работать над созданием платформы данных.
Для начала нужно было определиться с хранилищем. Если вы еще на этапе выбора хранилища, можем вам посоветовать посмотреть доклад от Максима Стаценко из Я.Go (Обзор технологий хранения больших данных).
У нас тут выбора было не так много – Hadoop Stack (Kudu, Druid, Hive, etc), Clickhouse или Greenplum. Остальные решения (Vertica, Teradata, Exasol) не подходили из-за своей проприетарности и требованиям к железной инфраструктуре. В итоге мы остановились на GP – из-за его возможностей работать с ANSI-sql и прозрачности для пользователей – для них это просто большой Postgres, в котором все их отчеты, построенные на прежних решениях, работали сразу из коробки, а для CH и Hive пришлось бы всё переписывать.
На первом этапе нам необходимо было проинтегрировать реляционки в платформу, чтобы дать пользователям возможность строить их отчеты не на базах источников, а у нас. Мы посчитали их и поняли, что в нашей компании более 350 реляционных баз данных. На базах-источников настроили механизм CDC и с помощью Debezium начали сгружать эти данные в Kafka, которую мы разгребали ETL-инструментом NiFi и грузили все в raw-слой GreenPlum.

MVP мы проводили на виртуалках в облаке.
Так как MVP показал хорошие результаты, мы нащупали вектор движения. У нас оставалось ощущение, что на облака мы потратим очень много денег из-за того, что у нас огромное количество обрабатываемых данных, и оно растет каждый день. Поэтому мы закупили железные серваки и поехали в onprem.
Железные конфигурации
Какие там были конфигурации?
Там было 24 сервера HP DL380, мы воткнули в каждый сервер по 12 винтов в 2 ТБ, собрали кластер на 220 ТБ (получилось уложить в него 110 ТБ полезных данных), у него было 800 ядер CPU и больше 5 ТБ оперативки:
HPE DL380 Gen10 5115 Xeon-G (Intel(R) Xeon(R) Gold 5115 CPU @ 2.40GHz)
256GB Memory (HPE 32GB 2Rx4 PC4-2666V-R)
10TB RAID10 software array (HPE 1.8TB SAS 10K SFF SC 512e)
4x10GB bonded network interfaces
Но, прежде чем запускаться, мы решили сравнить виртуалки в облаке с тем, что мы можем выжать на железе.
Мы прогнали на 3 разных компонентах 3 теста. GreenPlum мы прогоняли тестом TPC-DS, для Kafka мы прогнали бенчмарки consumer/produser-perf-test, а Object Storage мы тестировали с помощью Warp.
Про Object Storage
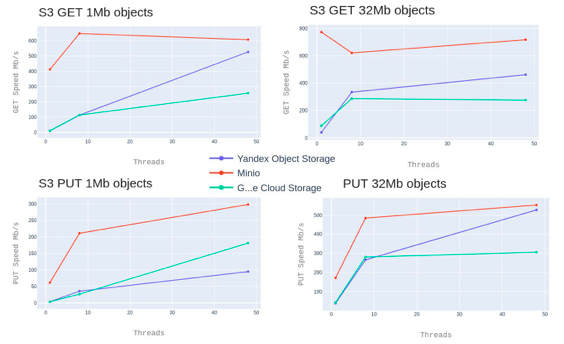
По оси X – количество потоков (сколько мы запускали тест на запись и на прочтение). По оси Y – итоговая скорость. Максимальная производительность достигается на 40 потоках при размере объектов больше 32 МБ.
Для тестов GreenPlum по итогу мы получили около 20% прироста производительности на железе (при одинаковых конфигурациях). Также проверяли различные версии GP (6.х против 5.х), и тестировали различные системные конфигурации.
Про Greenplum
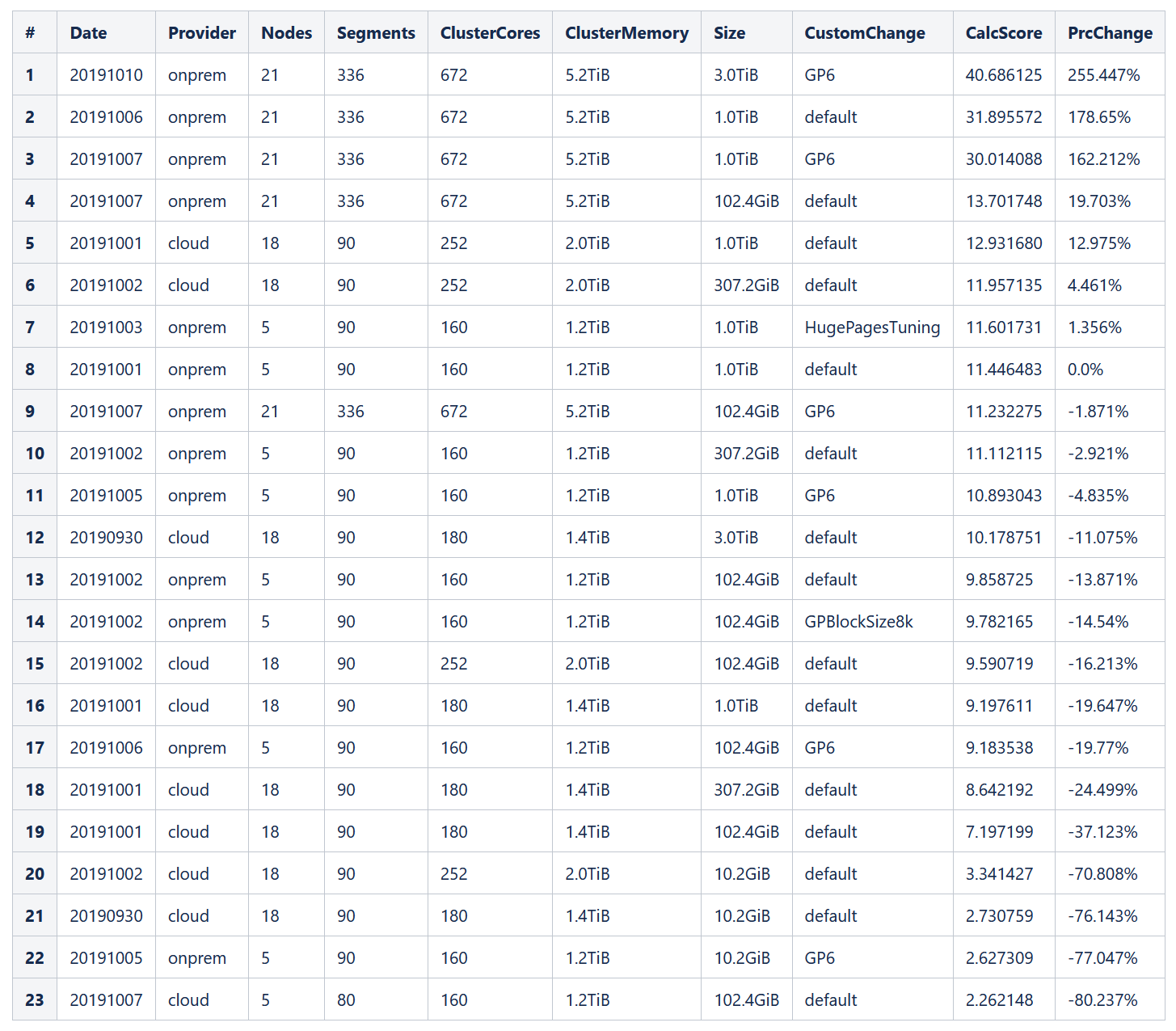
Подробнее с методикой теста и расчетом итогового score можно ознакомиться в спецификации: http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-ds_v2.11.0.pdf
Выводы из тестов Greenplum мы сделали следующие:
Основное влияние на производительность GP оказывает скорость дисковой подсистемы, в первую очередь - IOPS
При установке GP в облаке нужно закладывать 20% дополнительных ресурсов (CPU, memory)
На виртуалках нужно ставить меньший vm.overcommit_memory (90, вместо 95), т.к. высокое потребление CPU на облачной инфре оказывает негативное влияние на сеть между сегмент-нодами (теряются пакеты, затормаживаются ответы), что может вести к выпадению сегментов из кластера
Производительность кластера в облаке с большим количеством маленьких виртуалок выше, чем с малым количеством больших – лучше взять 18 виртуалок по 5 сегментов на каждой, чем 5 виртуалок по 18 сегментов.
Про Kafka
По Kafka мы замеряли скорость чтения/записи и получили 350 МБ на записи и 400 МБ на чтение на обычных HDD дисках. Особенность кафки – последовательная запись и чтение с диска позволяет ей работать очень быстро на бюджетном железе. Для большинства задач этих скоростей хватает за глаза.
В прод на ламбе – ожидание и реальность
После наших тестов мы радостно взяли все и побежали на железный кластер. Мы подумали, что все будет быстро и просто. Но тут начались проблемы.
Оказалось, что нельзя просто так взять и переехать на железо. Начались проблемы: диски вылетали из крутых брендированных серверов (хотя вендор их быстро менял, все равно производительность и отказоустойчивость деградировали). Также мы испытывали проблемы со специфичными настройками сети для GreenPlum. Столкнулись с багами в bios у HP, ноды рандомно перезагружались – пришлось обновлять bios. Также мы заметили, что HP по умолчанию включает зеленый режим у CPU, и при большой нагрузке наш кластер троттллился, и производительность не была максимальной.
А в параллели с этим, пока команда занималась стабилизацией прода, наш бэклог рос, и, вместо того чтобы развивать сам продукт, мы тратили много времени на сами железки. При этом бизнес требовал SLA и хотел, чтобы их запросы выполнялись всегда быстро.
Двойной ETL
Тогда мы задумались, как обеспечить продолжительность бизнеса, даже если на наш дата центр упадет метеорит.
Единственным решением в данном случае было иметь dual ETL – двойная инфраструктура, двойные данные, два раза проливать. Встал вопрос о покупке еще одного шкафа железа. И тогда мы поняли, что нужно идти обратно в облака.
Надо отметить, что пока мы занимались развитием железа, в вопросе облаков мы тоже не стояли на месте, разворачивали большое количество виртуальных машин для наших тестовых и стейджевых окружений, для инкубационных окружений.
Мы развернули кучу managed-сервисов в облаке. Все это мы делали с помощью швейцарского ножа devops’а – Terraform (IaC), Ansible, Jenkins. Также мы выработали системный подход к работе с инфраструктурой (железной / облачной / виртуальной) – мы используем ELK для сбора логов, Consul как сервис дискавери, в Prometheus собираем метрики, в Grafana их отображаем.
Итого
Мы начали трансформацию всей нашей компании в data-driven. На данный момент мы еще на самом старте, но уже сейчас мы видим, что продукты, основанные на данных, приносят немалую прибыль
Мы построили нашу платформу полностью на open-source решениях
Облачные провайдеры помогают в осуществлении быстрого старта для новых продуктов. Но необходимо иметь ввиду, что нельзя бездумно пользоваться всеми облачными сервисами, особенно managed, особенно специфическими и которых нет в других облаках, т.к. есть вероятность получить cloud lock. Проще говоря, нужно быть cloud-agnostic
Гибридные облака - это современный тренд, который позволяет компаниям выбирать облако в зависимости от задач и критериев (цена, доступность, удобство, безопасность). А использование IaC (Infrastructure as Code) упрощает эту задачу
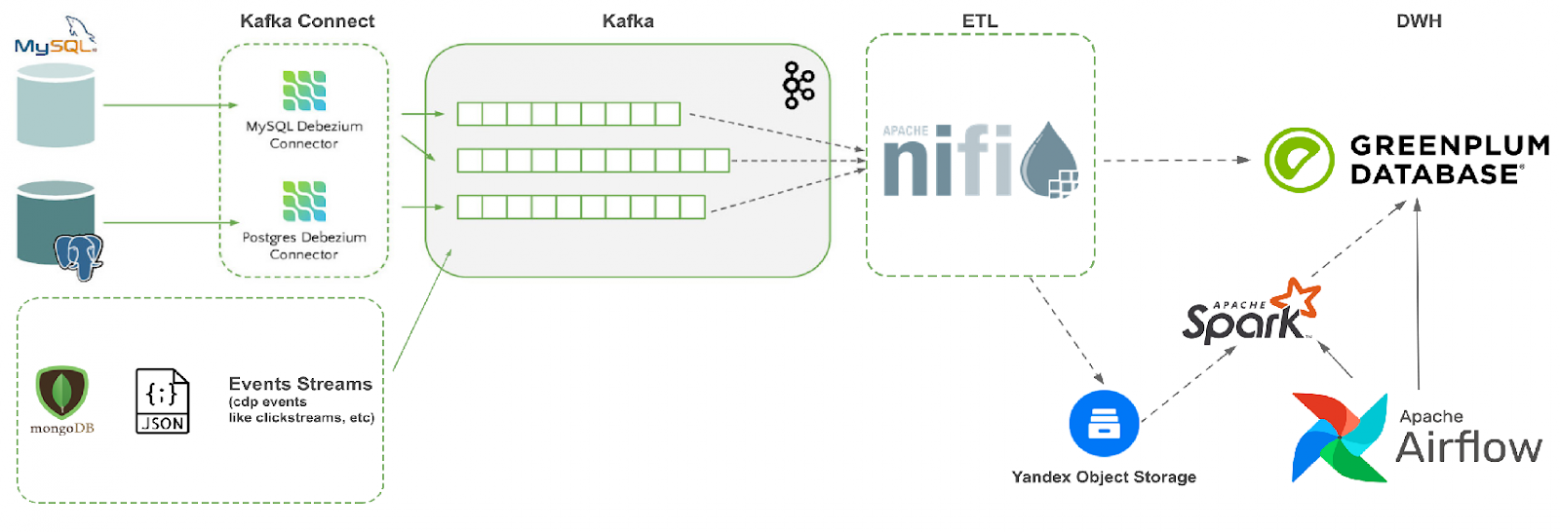
В следующей статье мы расскажем подробнее о текущей архитектуре нашей платформы, ее компонентах и open source продуктах, которыми мы пользуемся - опыте с GreenPlum, Airflow, Apache Superset, Flink и многими другими.
