Оглавление: Уроки компьютерного зрения. Оглавление / Хабр (habr.com)
Начиная с этого урока, я буду рассказывать о компьютерном зрении на примере моего пэт-проекта. Для начала, что это будет за проект. На первом уроке я рассказал о стадиях обработки изображения в компьютерном зрении. В своем пэт-проекте я создам специальный конвейер, где эти стадии будут реализованы. Напомню кратко об этих стадиях:
Предобработка изображения.
Промежуточная фильтрация.
Выявления специальных признаков (фич).
Высокоуровневый анализ.
Разумеется, это не окончательный список стадий обработки. В будущем сюда может что-то добавиться, а так же некоторые стадии могут иметь подстадии.
Естественно, делать конвейер ради самого конвейера как-то бессмысленно. Надо, чтобы моя программа делала хоть что-то условно полезное. Сначала я хотел написать пэт-проект, который бы анализировал фотографии со спутников и БЛА и превращал их в граф (это перекликается с темой моей магистерской диссертации). Правда, это слишком уж амбициозная задумка для пэт-проекта. Надо что-то по- проще. В комментариях к одному из уроков мне посоветовали добавить в финале пару глав про выделение отдельных символов и распознавание их при помощи общедоступных нейронок. И вот я и подумал, может, начать пэт-проект именно с этой задачи? Распознавание текстов? Это гораздо проще.
Итак, для начала я создал пустой проект и добавил туда две папки: Exec и Libraries. В первой у меня будет запускаемый файл/файлы, во втором всякие библиотечные файлы. В качестве первого библиотечного файла создал Core.py:
class Engine: """"Движок""" pass class ImageProcessingStep: """Шаг обработки изображений""" pass class ImageInfo: """Содержимое картинки, включая результаты обработки""" pass
Может, не совсем удачно разместить эти в Core.py, но пока нет видимости, какова будет окончательная структура, а потом просто сделаю рефакторинг.
Итак, начнем программирование:
class Engine: """"Движок""" def __init__(self): """Конструктор""" self.steps=[] def process(self, image): """Выполнить обработку. image - изображение""" current_info=ImageInfo(image) for step in self.steps: current_info=step.process(current_info) return current_info
Из этого фрагмента кода видно, что нужно создать конструктор класса ImageInfo, а у класса ImageProcessingStep надо предусмотреть метод process. И, разумеется, ImageProcessingStep должен быть абстрактным классом, а реализовывать методы будет уже каждый конкретный класс. Стоить заметить, что в Python абстрактных классов нет как таковых (в отличии от C#), они эмулируются при помощи декораторов. Но я этого делать не буду, так как использование декораторов приводит к излишнему расходу процессорного времени. Просто представлю, что раз «нет» значит «нет».
Абстрактный класс я сделаю путем добавления псевдоабстрактных методов, помеченных pass:
class ImageProcessingStep: """Шаг обработки изображений""" def process(self,info): """Выполнить обработку""" pass
Теперь займемся классом ImageInfo. По идее, это тоже должны быть псевдоабстрактный класс, в зависимости от шага, должен содержать, кроме картинки, еще какие-то дополнительные данные. А пока реализую конструктор:
class ImageInfo: """Содержимое картинки, включая результаты обработки""" def __init__(self,image): """Конструктор""" self.image=image
Ну а теперь попробую «натянуть» на эту схему какое-нибудь простейшее действие, ну, например, фильтрацию. Но для начала небольшой рефакторинг, в частности, перенесем класс ImageProcessingStep в файл перенес в ImageProcessingSteps.
Создадим класс, отвечающий за медианную фильтрацию:
class MedianBlurProcessingStep(ImageProcessingStep): """Шаг, отвечающий за предобработку типа Медианная фильтрация""" def __init__(self,ksize): """Конструктор ksize - размер ядра фильтра""" self.ksize=ksize def process(self,info): """Выполнить обработку""" median_image = cv2.medianBlur(info.image, self.ksize) info.filtered_image=median_image return info
Далее, создаем папку Exec, а в ней файл run.py. Вот так теперь будет выглядеть структура папок:
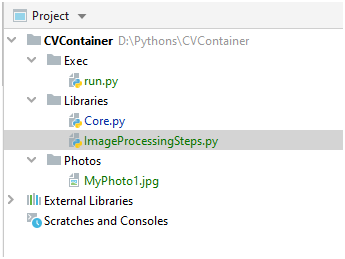
Ну и само содержимое файла run.py:
import cv2 from Libraries.Core import Engine from Libraries.ImageProcessingSteps import MedianBlurProcessingStep my_photo = cv2.imread('../Photos/MyPhoto1.jpg') core=Engine() core.steps.append(MedianBlurProcessingStep(5)) info=core.process(my_photo) cv2.imshow('origin', info.image) # выводим исходное изображение в окно cv2.imshow('res', info.filtered_image) # выводим итоговое изображение в окно cv2.waitKey() cv2.destroyAllWindows()
Запускаем программу и видим две картинки, одну с царапинами, другую после медианной фильтрации. Да, это уже было на уроке 3, только на этот раз все сделано в соответствии с парадигмой ООП. Теперь пора идти дальше и реализовывать идею распознаванием текста. Для начала попробуем стандартным способом, через tesseract. Прежде всего, я расскажу, как вообще работать с tesseract. И так, ставим библиотеку:
pip install pytesseract
Заходим по этой ссылке: Home · UB-Mannheim/tesseract Wiki (github.com) и качаем оттуда саму tesseract. Если внезапно окажется, что ссылка не актуальная (мало ли, все течет, все меняется), тогда просто погуглите.
После того, как скачали tesseract просто устанавливаем его. В программе на Python нужно будет указать путь к программе, примерно вот так вот это будет выглядеть:
import cv2 import pytesseract pytesseract.pytesseract.tesseract_cmd = "D:\\Program Files\\Tesseract-OCR\\tesseract.exe" img = cv2.imread('image.jpg') print(pytesseract.image_to_string(img, lang = 'rus'))
А вот демонстрация результатов работы программы вместе с исходным изображением:

Как видим, идеальный текст (скриншот ворда) распознался отлично. Теперь надо будет исследовать, как библиотека будет работать на реальных текстах (может, и не надо никакого своего распознавателя символов изобретать).
Попробуем распознать сфотографированную страницу книги:

Вот что мы получим на выходе:
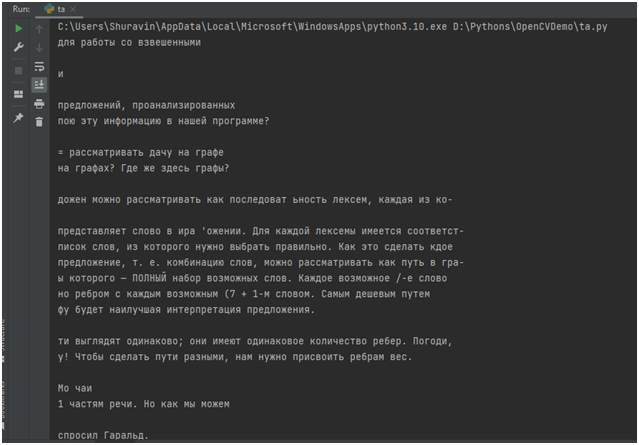
Как видим, где-то слова распознались хорошо, где-то довольно криво.
И еще один, немаловажный нюанс. На выходе сплошной текст. Но в реальности может потребоваться делить текст на какие-то блоки. Например, я однажды писал программу, которая позволяет распознавать текст на чертежах, чтобы потом этот чертеж оцифровать и занести в базу данных. В этом случае требовалось отдельно найти и распознать штампик чертежа, отдельно надписи на выносках, чтобы все эти надписи занести в нужные поля базы данных. Как данная задача решалась практически? При помощи алгоритмов компьютерного зрения изображение делилось на зоны, и эти зоны уже отдельно скармливались tesseract.
Но в моем пэт-проекте я попробую распознавать автомобильные номера. Знаю, это уже вообще баянестый баян, но, тем не менее, студенты до сих пор пишут лабораторные на эту тему. И даже целые курсовые. Да и вообще, надо же с чего-то начинать. А задача это довольно простая для того, чтобы создать некую основу для более сложного проекта.
Поступлю я, пожалуй, следующим образом. Нагуглю готовый пример распознавания номеров, или даже несколько, выберу наиболее удачный, и перенесу код в мой ООП-шаблон. Поехали. Нашел любопытный ролик:
Поскольку все течет, все меняется, то может так получиться, что вы когда-нибудь не найдете этот ролик. Но не расстраивайтесь, ниже приведены фрагменты кода из этого ролика.
Автор рассказывает все по шагам. Приведу эти шаги. Сначала он предлагает преобразовать текст в оттенки серого и произвести бинаризацию:
import cv2 img = cv2.imread('cars/6108249.jpg') height,width,_=img.shape gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) thresh = cv2.threshold(gray,0,255,cv2.THRESH_OTSU)[1] cv2.imshow('MyPhoto', thresh) cv2.waitKey(0) cv2.destroyAllWindows()
Исходное изображение:

Результат бинаризации:

Нетрудно предугадать следующий шаг. Полагаю, автор предложит найти вот этот вот белый прямоугольник:

Но, прежде чем смотреть ролик дальше, я решил проверить, а будет ли так же четко высвечиваться номерной знак на других картинках:



В принципе, неплохо, хотя местами есть помехи:

А в последнем случае номерной знак теряется на белом фоне. Хотя, если приглядеться внимательно, вокруг него есть черный контур:

Так что, возможно, алгоритм и найдет прямоугольник, посмотрим, что автор предложит дальше, подтвердиться ли моя догадка.
Оказалось, парень предложил просто выделить контуры, и исследовать каждый прямоугольник контура с достаточно большой площадью. В общем, что-то наподобие того:
import cv2 from imutils import contours import pytesseract pytesseract.pytesseract.tesseract_cmd = "D:\\Program Files\\Tesseract-OCR\\tesseract.exe" img = cv2.imread('cars/6108249.jpg') height,width,_=img.shape gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) thresh = cv2.threshold(gray,0,255,cv2.THRESH_OTSU)[1] cnts=cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE) cnts,_=contours.sort_contours(cnts[0]) for c in cnts: area=cv2.contourArea(c) x,y,w,h=cv2.boundingRect(c) if area>20: img_area=img[y:y+h,x:x+h] result=pytesseract.image_to_string(img_area,lang="rus+eng") if len(result)>3: print(result)
У него, правда, были немного другие пороги. И все работало, он прямо показал в ролике, все работает. На моих фотографиях это не сработало, поэтому я и заменил пороги. И получил странный вывод:
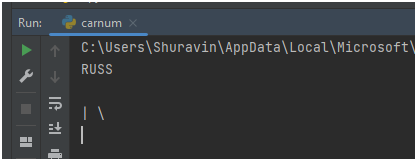
Можно добавить просмотр картинок, чтобы увидеть, где tesseract находит эти надписи:
… print(result) cv2.imshow('MyPhoto', img_area) cv2.waitKey(0) …
Смотрим фрагменты картинки:


В общем, цифры tesseract почему то не хочет идентифицировать. А он вообще, понимает цифры? Давайте проверим. Создадим в paint-е картинку из цифр:
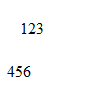
Скармливаем tesseract. И видим, что вывод пуст. Погуглил данную тему. Как оказалось, tesseract работает с цифрами через одно место. Можно поискать какие-то другие версия, но это не вариант. Лучше написать какую-то свою распознавалку, например, с использованием нейросетей.
Но, даже в этом случае встает вопрос, а каким же образом найти местоположение автомобильного номера? Может быть, искать белый прямоугольник на бинарной карте, как я предположил вначале? В любом случае, необходимо сначала вставить наработки в уже написанный ООП-контейнер, чтобы потом анализировать и исследовать.
И тут я понял, что вот такой вот код:
def process(self, image): """Выполнить обработку. image - изображение""" current_info=ImageInfo(image) for step in self.steps: current_info=step.process(current_info) return current_info ... ... def process(self,info): """Выполнить обработку""" median_image = cv2.medianBlur(info.image, self.ksize) info.filtered_image=median_image return info
Это плохая идея. Почему? Допустим, я решил сделать бинаризацию картинки. Я могу сделать бинаризацию исходной картинки, а могу после фильтрации. Но после фильтрации она называется не image, а filtered_image. И спрашивается, откуда на шаге бинаризации можно знать, надо обрабатывать image или filtered_image? Поэтому, они должны называется одинаково. А вот историю обработки надо где-то сохранять, чтобы потом восстановить цепочку обработок и проанализировать, как работает вся система.
Для начала исправим метод process класса Engine:
def process(self, image): """Выполнить обработку. image - изображение""" current_info=ImageInfo(image) history=[] for step in self.steps: history.append(current_info) current_info=step.process(current_info) return current_info, history
Затем файл: ImageProcessingSteps.py
import cv2 from Libraries.Core import ImageInfo class ImageProcessingStep: """Шаг обработки изображений""" def process(self,info): """Выполнить обработку""" pass class MedianBlurProcessingStep(ImageProcessingStep): """Шаг, отвечающий за предобработку типа Медианная фильтрация""" def __init__(self,ksize): """Конструктор ksize - размер ядра фильтра""" self.ksize=ksize def process(self,info): """Выполнить обработку""" median_image = cv2.medianBlur(info.image, self.ksize) return ImageInfo(median_image)
Ну, и наконец run.py:
import cv2 from Libraries.Core import Engine from Libraries.ImageProcessingSteps import MedianBlurProcessingStep my_photo = cv2.imread('../Photos/MyPhoto1.jpg') core=Engine() core.steps.append(MedianBlurProcessingStep(5)) res,history=core.process(my_photo) i=1 for info in history: cv2.imshow('image'+str(i), info.image) # выводим изображение в окно i=i+1 cv2.imshow('res', res.image) cv2.waitKey() cv2.destroyAllWindows()
Теперь можно показать всю цепочку изображений, и сейчас мы испытаем это на примере обработки изображения автомобиля. Сначала класс для вычисления бинарной карты:
class ThresholdProcessingStep(ImageProcessingStep): """Шаг, отвечающий за бинаризацию""" def process(self,info): """Выполнить обработку""" gray = cv2.cvtColor(info.image, cv2.COLOR_BGR2GRAY) image = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)[1] return ImageInfo(image)
И новый запускаемый файл run1.py:
import cv2 from Libraries.Core import Engine from Libraries.ImageProcessingSteps import MedianBlurProcessingStep, ThresholdProcessingStep my_photo = cv2.imread('../Photos/car.jpg') core=Engine() core.steps.append(MedianBlurProcessingStep(5)) core.steps.append(ThresholdProcessingStep()) res,history=core.process(my_photo) i=1 for info in history: cv2.imshow('image'+str(i), info.image) # выводим изображение в окно i=i+1 cv2.imshow('res', res.image) cv2.waitKey() cv2.destroyAllWindows()
При запуске мы увидим вот такую картинку:

Код этого примера можно взять отсюда: https://github.com/megabax/CVContainer
А теперь подытожим: Мы создали ООП-контейнер для обработки изображений, в будущих уроках прикрутим к нему находилку номера и распознавалку цифр на нейросетях.

