Алгоритмы сжатия изображений
Легко подсчитать, что несжатое полноцветное изображение, размером 2000*1000 пикселов будет иметь размер около 6 мегабайт. Если говорить об изображениях, получаемых с профессиональных камер или сканеров высокого разрешения, то их размер может быть ещё больше. Не смотря на быстрый рост ёмкости устройств хранения, по-прежнему весьма актуальными остаются различные алгоритмы сжатия изображений.
Все существующие алгоритмы можно разделить на два больших класса:
- Алгоритмы сжатия без потерь;
- Алгоритмы сжатия с потерями.
Когда мы говорим о сжатии без потерь, мы имеем в виду, что существует алгоритм, обратный алгоритму сжатия, позволяющий точно восстановить исходное изображение. Для алгоритмов сжатия с потерями обратного алгоритма не существует. Существует алгоритм, восстанавливающий изображение не обязательно точно совпадающее с исходным. Алгоритмы сжатия и восстановления подбираются так, чтобы добиться высокой степени сжатия и при этом сохранить визуальное качество изображения.
Алгоритмы сжатия без потерь
Алгоритм RLE
Все алгоритмы серии RLE основаны на очень простой идее: повторяющиеся группы элементов заменяются на пару (количество повторов, повторяющийся элемент). Рассмотрим этот алгоритм на примере последовательности бит. В этой последовательности будут чередовать группы нулей и единиц. Причём в группах зачастую будет более одного элемента. Тогда последовательности 11111 000000 11111111 00 будет соответствовать следующий набор чисел 5 6 8 2. Эти числа обозначают количество повторений (отсчёт начинается с единиц), но эти числа тоже необходимо кодировать. Будем считать, что число повторений лежит в пределах от 0 до 7 (т.е. нам хватит 3 бит для кодирования числа повторов). Тогда рассмотренная выше последовательность кодируется следующей последовательностью чисел 5 6 7 0 1 2. Легко подсчитать, что для кодирования исходной последовательности требуется 21 бит, а в сжатом по методу RLE виде эта последовательность занимает 18 бит.
Хоть этот алгоритм и очень прост, но эффективность его сравнительно низка. Более того, в некоторых случаях применение этого алгоритма приводит не к уменьшению, а к увеличению длины последовательности. Для примера рассмотрим следующую последовательность 111 0000 11111111 00. Соответствующая ей RL-последовательность выглядит так: 3 4 7 0 1 2. Длина исходной последовательности – 17 бит, длина сжатой последовательности – 18 бит.
Этот алгоритм наиболее эффективен для чёрно-белых изображений. Также он часто используется, как один из промежуточных этапов сжатия более сложных алгоритмов.
Словарные алгоритмы
Идея, лежащая в основе словарных алгоритмов, заключается в том, что происходит кодирование цепочек элементов исходной последовательности. При этом кодировании используется специальный словарь, который получается на основе исходной последовательности.
Существует целое семейство словарных алгоритмов, но мы рассмотрим наиболее распространённый алгоритм LZW, названный в честь его разработчиков Лепеля, Зива и Уэлча.
Словарь в этом алгоритме представляет собой таблицу, которая заполняется цепочками кодирования по мере работы алгоритма. При декодировании сжатого кода словарь восстанавливается автоматически, поэтому нет необходимости передавать словарь вместе с сжатым кодом.
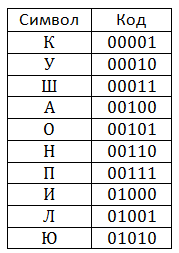
Словарь инициализируется всеми одноэлементными цепочками, т.е. первые строки словаря представляют собой алфавит, в котором мы производим кодирование. При сжатии происходит поиск наиболее длинной цепочки уже записанной в словарь. Каждый раз, когда встречается цепочка, ещё не записанная в словарь, она добавляется туда, при этом выводится сжатый код, соответствующий уже записанной в словаре цепочки. В теории на размер словаря не накладывается никаких ограничений, но на практике есть смысл этот размер ограничивать, так как со временем начинаются встречаться цепочки, которые больше в тексте не встречаются. Кроме того, при увеличении размеры таблицы вдвое мы должны выделять лишний бит для хранения сжатых кодов. Для того чтобы не допускать таких ситуаций, вводится специальный код, символизирующий инициализацию таблицы всеми одноэлементными цепочками.
Рассмотрим пример сжатия алгоритмом. Будем сжимать строку кукушкакукушонкукупилакапюшон. Предположим, что словарь будет вмещать 32 позиции, а значит, каждый его код будет занимать 5 бит. Изначально словарь заполнен следующим образом:
{kind=link}
Эта таблица есть, как и на стороне того, кто сжимает информацию, так и на стороне того, кто распаковывает. Сейчас мы рассмотрим процесс сжатия.
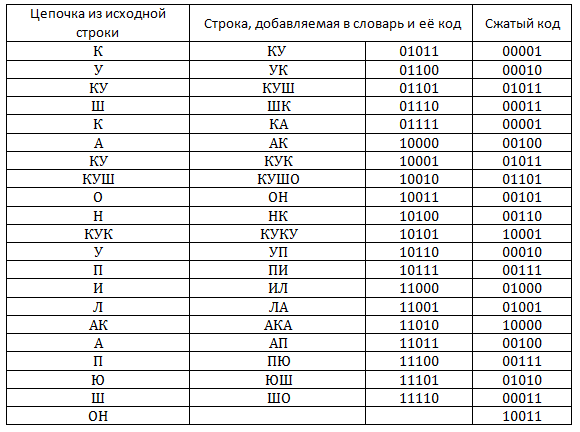{kind=link}
В таблице представлен процесс заполнения словаря. Легко подсчитать, что полученный сжатый код занимает 105 бит, а исходный текст (при условии, что на кодирование одного символа мы тратим 4 бита) занимает 116 бит.
По сути, процесс декодирования сводится к прямой расшифровке кодов, при этом важно, чтобы таблица была инициализирована также, как и при кодировании. Теперь рассмотрим алгоритм декодирования.
{kind=link}
Строку, добавленную в словарь на i-ом шаге мы можем полностью определить только на i+1. Очевидно, что i-ая строка должна заканчиваться на первый символ i+1 строки. Т.о. мы только что разобрались, как можно восстанавливать словарь. Некоторый интерес представляет ситуация, когда кодируется последовательность вида cScSc, где c — это один символ, а S — строка, причём слово cS уже есть в словаре. На первый взгляд может показаться, что декодер не сможет разрешить такую ситуацию, но на самом деле все строки такого типа всегда должны заканчиваться на тот же символ, на который они начинаются.
Алгоритмы статистического кодирования
Алгоритмы этой серии ставят наиболее частым элементам последовательностей наиболее короткий сжатый код. Т.е. последовательности одинаковой длины кодируются сжатыми кодами различной длины. Причём, чем чаще встречается последовательность, тем короче, соответствующий ей сжатый код.
Алгоритм Хаффмана
Алгоритм Хаффмана позволяет строить префиксные коды. Можно рассматривать префиксные коды как пути на двоичном дереве: прохождение от узла к его левому сыну соответствует 0 в коде, а к правому сыну – 1. Если мы пометим листья дерева кодируемыми символами, то получим представление префиксного кода в виде двоичного дерева.
Опишем алгоритм построения дерева Хаффмана и получения кодов Хаффмана.
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который равен частоте появления символа
- Выбираются два свободных узла дерева с наименьшими весами
- Создается их родитель с весом, равным их суммарному весу
- Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
С помощью этого алгоритма мы можем получить коды Хаффмана для заданного алфавита с учётом частоты появления символов.
Арифметическое кодирование
Алгоритмы арифметического кодирования кодируют цепочки элементов в дробь. При этом учитывается распределение частот элементов. На данный момент алгоритмы арифметического кодирования защищены патентами, поэтому мы рассмотрим только основную идею.
Пусть наш алфавит состоит из N символов a1,…,aN, а частоты их появления p1,…,pN соответственно. Разобьем полуинтервал [0;1) на N непересекающихся полуинтервалов. Каждый полуинтервал соответствует элементам ai, при этом длина полуинтервала пропорциональна частоте pi.
Кодирующая дробь строится следующим образом: строится система вложенных интервалов так, чтобы каждый последующий полуинтервал занимал в предыдущем место, соответствующее положению элемента в исходном разбиении. После того, как все интервалы вложены друг в друга можно взять любое число из получившегося полуинтервала. Запись этого числа в двоичном коде и будет представлять собой сжатый код.
Декодирование – расшифровка дроби по известному распределению вероятностей. Очевидно, что для декодирования необходимо хранить таблицу частот.
Арифметическое кодирование чрезвычайно эффективно. Коды, получаемые с его помощью, приближаются к теоретическому пределу. Это позволяет утверждать, что по мере истечения сроков патентов, арифметическое кодирование будет становиться всё более и более популярным.
Алгоритмы сжатия с потерями
Не смотря на множество весьма эффективных алгоритмов сжатия без потерь, становится очевидно, что эти алгоритмы не обеспечивают (и не могут обеспечить) достаточной степени сжатия.
Сжатие с потерями (применительно к изображениям) основывается на особенностях человеческого зрения. Мы рассмотрим основные идеи, лежащие в основе алгоритма сжатия изображений JPEG.
Алгоритм сжатия JPEG
JPEG на данный момент один из самых распространенных способов сжатия изображений с потерями. Опишем основные шаги, лежащие в основе этого алгоритма. Будем считать, что на вход алгоритма сжатия поступает изображение с глубиной цвета 24 бита на пиксел (изображение представлено в цветовой модели RGB).
Перевод в цветовое пространство YCbCr
В цветовой модели YCbCr мы представляем изображение в виде яркостной компоненты (Y) и двух цветоразностных компонент (Cb,Cr). Человеческий глаз более восприимчив к яркости, а не к цвету, поэтому алгоритм JPEG вносит по возможности минимальные изменения в яркостную компоненту (Y), а в цветоразностные компоненты могут вноситься значительные изменения. Перевод осуществляется по следующей формуле:
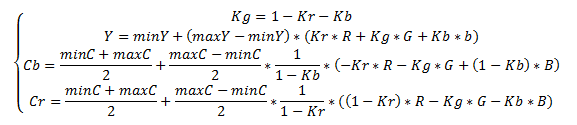{kind=link}
Выбор Kr и Kb зависит от оборудования. Обычно берётся Kb=0.114;Kr=0.299. В последнее время также используется Kb=0.0722;Kr=0.2126, что лучше отражает характеристики современных устройств отображения.
Субдискретизация компонент цветности
После перевода в цветовое пространство YCbCr выполняется дискретизация. Возможен один из трёх способов дискретизации:
4
- :4:4 – отсутствует субдискретизация;
- 4:2:2 – компоненты цветности меняются через одну по горизонтали;
- 4:2:0 – компоненты цветности меняются через одну строку по горизонтали, при этом по вертикали они меняются через строку.
При использовании второго или третьего способа мы избавляется от 1/3 или 1/2 информации соответственно. Очевидно, что чем больше информации мы теряем, тем сильнее будут искажения в итоговом изображении.
Дискретное косинусное преобразование
Изображение разбивается на компоненты 8*8 пикселов, к каждой компоненте применятся ДКП. Это приводит к уплотнению энергии в коде. Преобразования применяются к компонентам независимо.
Квантование
Человек практически не способен замечать изменения в высокочастотных составляющих, поэтому коэффициенты, отвечающие за высокие частоты можно хранить с меньшей точностью. Для этого используется покомпонентное умножение (и округление) матриц, полученных в результате ДКП, на матрицу квантования. На данном этапе тоже можно регулировать степень сжатия (чем ближе к нулю компоненты матрицы квантования, тем меньше будет диапазон итоговой матрицы).
Зигзаг-обход матриц
Зигзаг-обход матрицы – это специальное направление обхода, представленное на рисунке:
{kind=link}
При этом для большинства реальных изображений в начале будут идти ненулевые коэффициенты, а ближе к концу будут идти нули.
RLE- кодировние
Используется особый вид RLE-кодирования: выводятся пары чисел, причём первое число в паре кодирует количество нулей, а второе – значение после последовательности нулей. Т.е. код для последовательности 0 0 15 42 0 0 0 44 будет следующим (2;15)(0;42)(3;44).
Кодирование методом Хаффмана
Используется описанный выше алгоритм Хаффмана. При кодировании используется заранее определённая таблица.
Алгоритм декодирования заключается в обращении выполненных преобразований.
К достоинствам алгоритма можно отнести высокую степень сжатие (5 и более раз), относительно невысокая сложность (с учётом специальных процессорных инструкций), патентная чистота. Недостаток – артефакты, заметные для человеческого глаза.
Фрактальное сжатие
Фрактальное сжатие – это относительно новая область. Фрактал – сложная геометрическая фигура, обладающая свойством самоподобия. Алгоритмы фрактального сжатия сейчас активно развиваются, но идеи, лежащие в их основе можно описать следующей последовательностью действий.
Процесс сжатия:
- Разделение изображения на неперекрывающиеся области (домены). Набор доменов должен покрывать всё изображение полностью.
- Выбор ранговых областей. Ранговые области могут перекрываться и не покрывать целиком всё изображение.
- Фрактальное преобразование: для каждого домена подбирается такая ранговая область, которая после аффинного преобразования наиболее точно аппроксимирует домен.
- Сжатие и сохранение параметров аффинного преобразования. В файл записывается информация о расположении доменов и ранговых областей, а также сжатые коэффициенты аффинных преобразований.
Этапы восстановления изображения:
- Создание двух изображений одинакового размера A и B. Размер и содержание областей не имеют значения.
- Изображение B делится на домены так же, как и на первой стадии процесса сжатия. Для каждого домена области B проводится соответствующее аффинное преобразование ранговых областей изображения A, описанное коэффициентами из сжатого файла. Результат помещается в область B. После преобразования получается совершенно новое изображение.
- Преобразование данных из области B в область A. Этот шаг повторяет шаг 3, только изображения A и B поменялись местами.
- Шаги 3 и 4 повторяются до тех пор, пока изображения A и B не станут неразличимыми.
Точность полученного изображения зависит от точности аффинного преобразования.
Сложность алгоритмов фрактального сжатия в том, что используется целочисленная арифметика и специальные довольно сложные методы, уменьшающие ошибки округления.
Отличительной особенностью фрактального сжатия является его ярко выраженная ассиметрия. Алгоритмы сжатия и восстановления существенно различаются (сжатие требует гораздо большего количества вычислений).