Ежегодный хакатон YADRO и МИЭТ набирает обороты. Апрель, Зеленоград, четыре трека… нет, пять! Пятый SoC Design Challenge — пять треков, красивое совпадение. К топологии, RTL, UVM- и системной верификации присоединился трек DFT, Design for Testability. На кону по-прежнему кое-что интересное: fast track на летнюю стажировку YADRO Импульс, дополнительные баллы при поступлении в магистратуру МИЭТ, FPGA- и RISC-V-платы, логические анализаторы, полезная периферия, мерч. И конечно — приятная смесь из чувства собственного удовлетворения и одобрения от однокурсников.
В этом посте мы в общих чертах рассмотрим задания с хакатона прошлого года, подходы к решению и некоторые ловушки, расставленные нашими экспертами.

RTL Basic: что делаем с FIFO?
На треке Basic участникам дали модуль, собирающий статистику AXI-шины, и документацию к нему. Но предварительно модуль сломали: раздули площадь за счет микроархитектуры и уничтожили многие другие оптимизации. Модуль нужно было починить — то есть заново оптимизировать. За разные оптимизации давали разное количество очков, и определенного успеха мог добиться любой студент с некоторыми знаниями в RTL. Важное ограничение: ни одна оптимизация не должна была менять или задерживать транзакции, за такое мы снимали баллы.
При разработке ASIC физическую память можно реализовать с помощью триггеров. Триггеры занимают много места, поэтому в реальном мире фабрики поставляют так называемые hard macro — готовые сборки памяти. Они производятся по иной технологии, имеют более высокую плотность логики (транзисторов) и поэтому занимают меньшую площадь. За минимизацию приходится платить бо́льшим риском появления нерабочих кристаллов, но в индустрии это стало стандартом. Поэтому участники хакатона имели возможность генерировать нужные им памяти по запросу к организаторам.
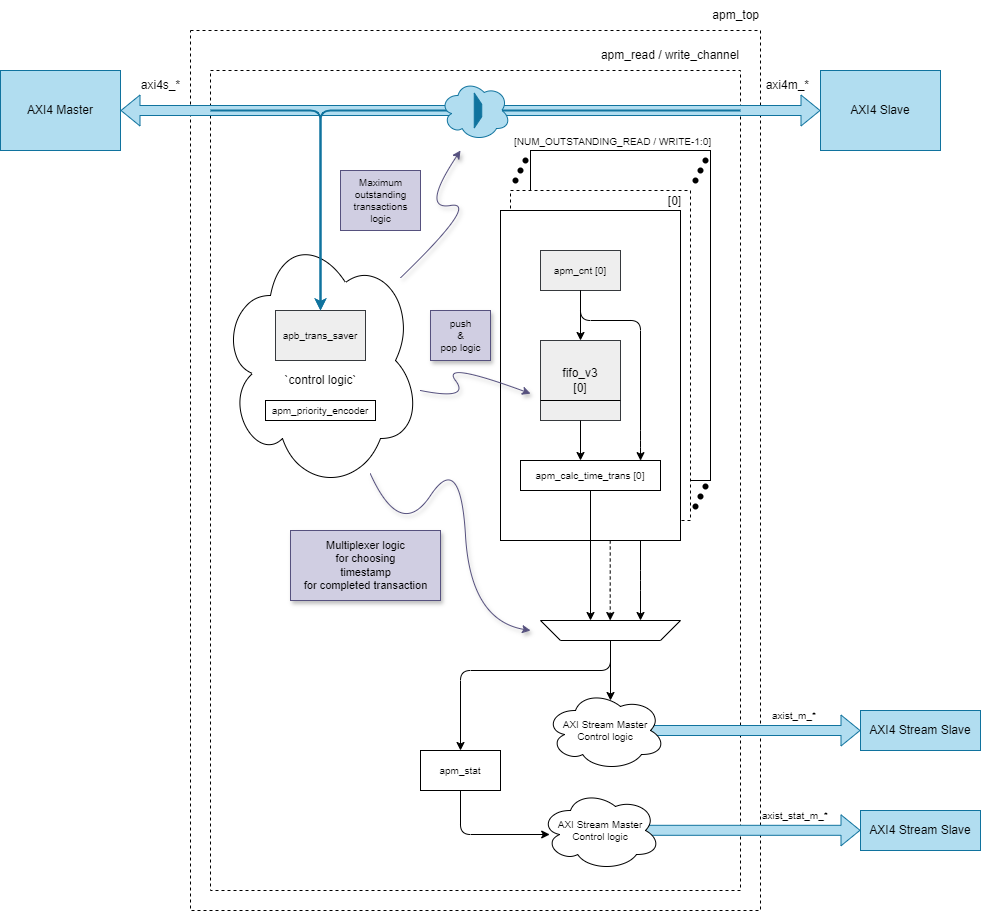
Первая оптимизация AXI-модуля по нашей задумке — это поиск неоптимальных реализаций хранения данных и переписывание RTL-кода так, чтобы в модуль можно было установить память с обычным интерфейсом — Dual-Port RAM, SRAM и т. п. Так можно было сразу уменьшить площадь модуля на кристалле в два раза. На регистрах в схеме выше реализована FIFO, и от замены регистров на память основной выигрыш будет здесь.
Другой вектор работы — борьба с большими комбинационными схемами. Если начать не с уменьшения площади, а с увеличения частоты блока, то можно сокращать критический путь с помощью регистров. Это было особенно уместно в блоке расчета статистики.
Третья и самая крупная оптимизация — полная переработка микроархитектуры блока для сокращения объема хранения данных на порядок. Здесь для понимания нужно погрузиться в протокол AXI и схему референсного дизайна.
В «полном» AXI есть поддержка out-of-order-транзакций с помощью сигнала AxID. Работает это так: порядок ответов на транзакции с одинаковым ID должен сохранять порядок запросов. Порядок ответов на транзакции с разными ID может быть любым. Для подсчета статистики блоку нужно сохранять время прихода запроса транзакции от master и хранить его до прихода ответа от slave. Таких таймстампов нужно хранить столько, сколько транзакций в полете (outstanding) поддерживает slave-устройство.
В референсном дизайне для хранения этого времени используется FIFO с глубиной, равной количеству транзакций в полете. Самая ранняя транзакция располагается на HEAD, остальные ждут своей очереди. Но все усложняется из-за наличия трафика с разными ID: транзакции могут перемешиваться, и для правильного расчета нужно иметь доступ к самым старым транзакциям для каждого ID. Это увеличивает количество FIFO до разрешенного количества транзакций в полете. А это уже матрица: количество транзакций в полете (X) количество транзакций в полете.
Естественно, в этой схеме большинство ячеек будет простаивать. Чтобы сократить их количество до минимального, нужна схема, в которой на одной памяти можно будет реализовать несколько виртуальных FIFO с динамической глубиной — например, аппаратный связанный список.
За такую оптимизацию мы начисляли гораздо больше очков, чем за предыдущие. В итоге все три призера трека смогли оторваться во многом за ее счет ;)
RTL Basic+: прокачиваем свертку для нейропроцессора
В продвинутом треке по RTL студенты работали с ускорителем операции трехмерной свертки для нейропроцессора. Он поэлементно перемножает и складывает два трехмерных набора чисел — ядро свертки и тензор. По итогам попеременного умножения мы получаем результат свертки, который используют сверточные нейросети — например, в компьютерном зрении.
В качестве среды запуска мы предложили квантованную нейросеть со следующим порядком действий: целочисленное вычисление, сдвиг, смещение и скейл. Для конфигурации блока ускорителя предоставили интерфейс APB, а на чтение и запись — AXI Lite.
Референсная реализация блока была функционально корректна, но нуждалась в масштабной оптимизации. Основной задачей участников было поднять производительности при минимальном увеличении площади и латентности.
Исходная ширина AXI-шины у блока — 32 байта. Но в операции свертки каждое чтение считывало только один байт — одна операция умножения с накоплением. Здесь уже можно было начать увеличивать ширину до 32, ведь даже трехмерную операцию свертки можно производить над вектором. Кроме того, она хорошо параллелится, и поэтому мы ожидали, что участники будут использовать параллелизм в работе.
Элементы выходного тензора, который нужно получить, можно считать полностью независимыми. Получается, достаточно один раз прочитать входной тензор, ядро, сохранить их и оттуда вывести результат. Ядро свертки используется в вычислениях многократно, и, чтобы не расходовать адресное пространство, для него берут один и тот же адрес. Здесь уместна оптимизация через кеширование, создание буфера для переиспользования данных, что сильно увеличит производительность.
Более интересная оптимизац��я — это систолические массивы. Сложность в том, что их обычно используют для перемножения матриц, а у нас в задании свертка. Но если дополнительно поспрашивать гугл, то можно понять, что свертка — это эквивалент перемножения двух матриц, реализованный определенным образом. Свертку из задания можно было сконструировать в нужном виде и затем встроить в решение систолический массив на SystemVerilog.
Систолический массив, кстати, не использовала ни одна команда, но зато все призеры додумались до введения конвейеров — это, пожалуй, самый популярный способ увеличить пропускную способность в цифровой электронике.
Стоит выделить и неожиданные решения. Некоторые команды заменили сумматоры. В SystemVerilog для них обычно просто пишут «+», и синтезатор справляется сам. Здесь же у нас были операции со степенью двойки, и их можно было упростить в аппаратном режиме через простой побитовый сдвиг.

Топология: что не так с маршрутом?
Для трека по топологии мы берем законченный фронтенд, студенческий RTL-проект, и портим его. В результате маршрут все еще можно пройти «одной кнопкой» до финальной топологии без ошибок. Но без дополнительных оптимизаций он «испечется» нерабочим. Для оптимизаций предусмотрены разные направления и несколько степеней свободы: чем больше улучшений реализовали, тем больше очков и выше позиция в общем зачете трека.
Цифровой физический синтез имеет очень высокий порог входа: для достаточно стабильного понимания нужно и профильное образование, и стажировка. Так что мы стараемся снизить этот порог для участников хакатона. Все шаги маршрута полностью совпадают с той теорией, которую мы предоставляем заранее.
Для оптимизации доступно три возможных направления. Первое — это расположение блоков на подложке чипа на floorplan. Второе — расположение ячеек ввода/вывода по периметру: они нарочно перемешаны для ухудшения результата. Третье направление — это сетка питания: нужно оценить питание блоков и понять, какие улучшения можно реализовать здесь.
Каждый транзистор должен получать необходимое для корректной работы напряжение, и от качества сетки питания зависит, какая доля напряжения от источника питания до него дойдёт. Если напряжение не дотягивает до допустимого — обычно допускается отклонение 10–15% от VDD (напряжение на сток) — то это фатальная ошибка, и сетку питания надо переделывать.
Работать во всех трех направлениях сразу необязательно, можно выбрать только те, что кажутся перспективней. Мы оцениваем работу по трем основным критериям (PPA — Performance, Power, Area):
Производительность: насколько хорошо дизайн попадает в определенную частоту.
Энергопотребление и падение напряжения: не только у кого потребляет меньше, но и как мощность доходит до потребителей внутри чипа.
Площадь, занимаемая логикой, и другие метрики.
Мы хотели, чтобы участники хакатона не застревали с какой-нибудь ошибкой в самом начале маршрута, поэтому даже исходное задание номинально отрабатывает целиком. Также на треке топологии мы следим за командами. Если кто-нибудь не может сдвинуться с мертвой точки, комментируем именно ту фичу, на которой возникла проблема, чтобы ребята могли переключиться на что-нибудь другое и не терять времени. О правильном решении, конечно, не говорим, чтобы ни у кого не было преимуществ.

UVM-верификация: план — это еще полдела
В этом треке мы предоставили участникам дизайн, реализующий функции конфигурируемого AMBA-интерконнекта, набор тестов и шаблон для реализации golden модели. Внутри этой модели нужно было реализовать механизмы тестирования. Допускались тесты для отладки в интерактивном режиме, но в зачете участвовали только результаты, полученные с помощью CI-пайплайнов, которые запускали весь пакет тестов на всех вариантах дизайна с разными ошибками.
По результатам запуска пайплайнов команды анализировали неудачные тесты и определяли, что же сломалось: разработанная модель или сам дизайн. Подтвержденные ошибки в дизайне было необходимо задокументировать «по-взрослому»: описать суть проблемы, шаги для воспроизведения и обосновать свою позицию, опираясь на спецификацию. Эта работа и вносила основной вклад в итоговый результат. Также мы смотрели на рациональность использования конструкций SystemVerilog и в целом на выбранную архитектуру проверок.
Трек не предусматривал ловушек: нужно было внимательно прочитать спецификацию дизайна, написать план верификации и просто следовать ему. Но объем возможных проверок оказался значительно больше, чем можно реализовать за три дня хакатона, поэтому важно было грамотно планировать ресурсы. В одной команде, например, из троих ребят ушли двое, третий успел написать просто идеальный план верификации, но на поиск багов времени ему не хватило.
С этим треком могли неплохо помочь нейросети. Бороться с ними бессмысленно, в задании на 2026 год мы просто исходим из того, что нейросетями будут пользоваться все. В 2025 году некоторым это вышло боком: у них в плане верификации были функции, которых в блоке не было в принципе. Скорее всего, участники даже не посмотрели, что им нагенерировал AI — за это, конечно же, мы вычитали баллы.
В итоге при планировании верификации участники даже дали фору организаторам: было найдено две дополнительных фичи, не предусмотренные заранее. В итоге их включили в референсный план для оценки, а героям отдельно добавили баллы за глубину проработки.
Не обошлось и без забавных эксцессов. Одна команда сделала очень точную, буквально потактовую модель устройства, и она потребляла столько ресурсов, что нам пришлось увеличивать тайм-аут для CI-пайплайна.

Системная верификация: усложнено DMA-контроллером
В треке по системной верификации участникам предложили проверить подсистему JPEG-декодера в составе СнК. Верификационное окружение включало в себя не только саму подсистему, моделируемую в RTL-симуляторе, но и функциональный симулятор QEMU для эмуляции RISC-V-процессора и памяти. Взаимодействие QEMU и RTL-симулятора было организовано с помощью DPI — подробней об этом можно узнать в другой статье.
В ходе задания нужно было проверить работу подсистемы и всех заявленных фичей. Тестовый план должен был включать сценарии, которые программируют блок и проверяют входное-выходное воздействие. Далее нужно было проверить с помощью тестового плана 14 дизайнов с одной ошибкой в каждом. Итог — отчет на основе инструмента автоматизации тестирования RobotFramework c демонстрацией тестового плана, его запуска на CI и решенными кейсами по поиску ошибок в дизайне.
Подсистема JPEG-декодера включала встроенный DMA-контроллер, позволяющий снимать нагрузку на CPU. То есть помимо разбора самого декодера командам нужно было разобраться в работе DMA-контроллера и проверить его в составе сложной подсистемы. Это, в принципе, полезно, поскольку такие контроллеры используются во многих современных вычислительных устройствах.
В целом задания были очень похожи на реальные таски в верификации СнК, которые решают инженеры в YADRO и в других компаниях отрасли, — но с использованием open-source разработок
Оценивали итоги по нескольким критериям разными инструментами. С помощью статического анализатора кода искали предупреждения и ошибки: чем больше их подтверждалось, тем ниже был итоговый балл на этом этапе. Также смотрели полноту кодового покрытия в RTL-симуляторе и проверку всех заявленных фичей.
Дополнительные баллы начисляли за каждый верно продиагностированный из 14 багов. Ошибки там были разного уровня. За некорректную версию блока, указанную в регистре, что можно легко обнаружить с помощью направленного теста, давали всего несколько баллов. Более сложные ошибки, касались логики работы самого декодера и корректности переключения его состояний. За такие баги баллов давали больше.

Design for Testability — новый трек хакатона
При создании продукта важно находить баланс: или тратишь уйму времени на поиск багов в продукте, рискуя по бюджетам и срокам, или выпускаешь продукт после меньшего количества тестов и решаешь отловить проблемы за счет сервисной поддержки. И желательно при высокой автоматизации.
Естественно, с удорожанием технологичных продуктов и развитием возможностей сервиса второй вариант выглядит привлекательней. Для него принципиально важна возможность проверки и отбраковки изделий еще на этапе производства.
В 1970-х годах процессоры проверяли на заводе, грубо говоря, с помощью подачи нулей и единиц и оценки результата. Это работало, вот только тестирование занимало много времени. Со временем вычислительные мощности и интегральные схемы росли. На прогон тестовых данных стало уходить уже слишком много времени. И даже после оптимизации достоверность тестов сильно падала: в схемах уже использовалась не только комбинационная логика, но и триггеры, поведение которых было привязано ко времени. Кроме того, требования к надежности только росли: в космосе, например, аппарат должен эффективно тестировать сам себя, чтобы при необходимости отключать одни блоки и переключаться на другие.
Постепенно мир пришел к тому, что для тестирования нужно оптимизировать дизайн самих устройств — так начал развиваться DFT. В исходном виде это развитие по трем направлениям. Покрытие — чтобы охватить максимум элементов. Скорость — чтобы не затянуть сроки и не уменьшить ресурс устройства еще до продажи. И, что особенно актуально для процессоров, площадь.
DFT здесь можно сравнить с иммунной системой человека, которая помогает локализовать и конкретизировать болезнь. Встраивая DFT-структуры в такую миниатюрную вещь, как процессор, нужно всегда учитывать паразитные явления, что могут повлиять на работу процессора. А также помнить об ограничениях в площади и в потребляемой мощности.
Почему мы добавили трек DFT к хакатону? Все аппаратные разработчики проходят такой этап работы, как дебаг. Для него, например, пишут точки останова, создают дополнительные блоки, за которые можно будет зацепиться, чтобы понять, что конкретно не работает. Это довольно творческое направление для тех, кому нравится разбираться в малопонятных вещах.
В чем отличие DFT от верификации? Верификация — это проверка того, что изделие формально собрано верно. Что, например, бумажный самолетик сложен четко по инструкции. А способен ли он правильно полететь при определенных условиях? И как это достоверно проверить? На эти вопросы отвечают уже с помощью DFT.
На хакатоне мы предложим командам дизайн микроконтроллера. Нужно будет проверить, насколько он пригоден для встраивания DFT-структур. Затем улучшить дизайн, подготовив его для встраивания, и, собственно, вставить их. В оценке будем учитывать покрытие, количество тестовых циклов и итоговую площадь дизайна.
DFT — это дисциплина на стыке RTL и топологии. От участников потребуются знания цифровой схемотехники, умение писать RTL и хотя бы базовое владение Tcl. Более подробно о треке мы расскажем на вебинарах, которые будут предшествовать хакатону.
Хакатон SoC Design Challenge 2026 года пройдет с 24 по 26 апреля в МИЭТ в Зеленограде. Регистрация уже открыта, так что советуем зарегистрироваться заранее: до хакатона мы проведем отборочное тестирование, а также подготовительные лекции. Для иногородних участников организуем проезд и проживание. Ждем вас!
Остальные подробности можно узнать на странице хакатона.
