В наше время все большую популярность набирают генетические алгоритмы. Их используют для решения самых разнообразных задач. Где-то они работают эффективнее других, где-то программист просто решил выпендриться…
Так что же такое генетический алгоритм? Если верить википедии, то генетический алгоритм — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путём случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическую эволюцию. Является разновидностью эволюционных вычислений. Отличительной особенностью генетического алгоритма является акцент на использование оператора «скрещивания», который производит операцию рекомбинации решений-кандидатов, роль которой аналогична роли скрещивания в живой природе.
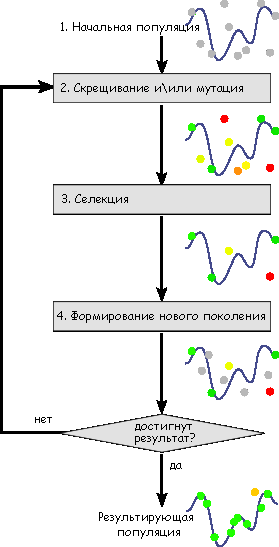
Т.е. генетический алгоритм работает наподобие нашей с вами эволюции. Сначала создаются начальные популяции, затем они скрещиваются между собой (при этом возможно возникновение мутаций). Популяции выжившие в процессе естественного отбора проверяются на удовлетворение заданным критериям. Если удовлетворяют — все счастливы, если нет — вновь скрещиваются и так до финальной победы.
Как это все выглядит вы можете увидеть на следующем рисунке:
В качестве примера приведу алгоритм, создающий строку «Hello world!»
Данный генетический алгоритм имеет такие параметры:
Исходный код
Сразу хочется дать несколько комментариев к коду. Во-первых, мы схитрили, когда установили фиксированные размеры строк в генетическом алгоритме, которые равны размеру искомой строки. Это сделано, чтобы обеспечить лучшее понимание кода. Во-вторых, для хранения данных используется STL-класс vector — это сделано для того, чтобы упростить сортировку. Наконец, программа использует два массива для хранения популяций — один для текущей, второй является буфером для следующего поколения. В каждом поколении очки округляются до целого для ускорения вычислений.
Определение пригодности
Давайте, взглянем на функцию определения пригодности популяции:
В принципе, здесь просто перебирается каждый член популяции и сравнивается с таковым в целевой строке. Разницы между символами складываются и накопленная сумма используется как значение пригодности (таким образом, чем она меньше, тем лучше).
Результат
При выполнении, программа выдает на экран лучшую популяцию и ее пригодность (число в скобках).
Заключение
Надеюсь, эта небольшая программа способна продемонстрировать, как простой генетический алгоритм может быть использован для решения задачи. Данный алгоритм не является самым эффективным, хотя использование STL должно немного помочь. Алгоритм был протестирован в Visual Studio.
Пример применения
Чтобы проверить торгового робота на диапазоне параметров можно «проходить» диапазон не в циклах (как сейчас во всех программах), а при помощи генетических алгоритмов. И время сокращается в 9-12 раз. #
Оригинальная статья на Английском языке.
Что такое генетический алгоритм?
Так что же такое генетический алгоритм? Если верить википедии, то генетический алгоритм — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путём случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическую эволюцию. Является разновидностью эволюционных вычислений. Отличительной особенностью генетического алгоритма является акцент на использование оператора «скрещивания», который производит операцию рекомбинации решений-кандидатов, роль которой аналогична роли скрещивания в живой природе.
Т.е. генетический алгоритм работает наподобие нашей с вами эволюции. Сначала создаются начальные популяции, затем они скрещиваются между собой (при этом возможно возникновение мутаций). Популяции выжившие в процессе естественного отбора проверяются на удовлетворение заданным критериям. Если удовлетворяют — все счастливы, если нет — вновь скрещиваются и так до финальной победы.
Как это все выглядит вы можете увидеть на следующем рисунке:
В качестве примера приведу алгоритм, создающий строку «Hello world!»
Данный генетический алгоритм имеет такие параметры:
| Размер популяции: | 2048 |
| Мутации (%): | 25 |
| Элитарность (%): | 10 |
Исходный код
#include <iostream> // для cout и т.п.
#include <vector> // для класса vector
#include <string> // для класса string
#include <algorithm> // для алгоритма сортировки
#include <time.h> // для случайных величин
#include <math.h> // для abs()
#define GA_POPSIZE 2048 // размер популяции
#define GA_MAXITER 16384 // максимальное число итераций
#define GA_ELITRATE 0.10f // элитарность
#define GA_MUTATIONRATE 0.25f // мутации
#define GA_MUTATION RAND_MAX * GA_MUTATIONRATE
#define GA_TARGET std::string("Hello world!")
using namespace std;
struct ga_struct
{
string str; // строка
unsigned int fitness; // пригодность
};
typedef vector<ga_struct> ga_vector; // для краткости
void init_population(ga_vector &population,
ga_vector &buffer )
{
int tsize = GA_TARGET.size();
for (int i=0; i<GA_POPSIZE; i++) {
ga_struct citizen;
citizen.fitness = 0;
citizen.str.erase();
for (int j=0; j<tsize; j++)
citizen.str += (rand() % 90) + 32;
population.push_back(citizen);
}
buffer.resize(GA_POPSIZE);
}
void calc_fitness(ga_vector &population)
{
string target = GA_TARGET;
int tsize = target.size();
unsigned int fitness;
for (int i=0; i<GA_POPSIZE; i++) {
fitness = 0;
for (int j=0; j<tsize; j++) {
fitness += abs(int(population[i].str[j] - target[j]));
}
population[i].fitness = fitness;
}
}
bool fitness_sort(ga_struct x, ga_struct y)
{ return (x.fitness < y.fitness); }
inline void sort_by_fitness(ga_vector &population)
{ sort(population.begin(), population.end(), fitness_sort); }
void elitism(ga_vector &population,
ga_vector &buffer, int esize )
{
for (int i=0; i<esize; i++) {
buffer[i].str = population[i].str;
buffer[i].fitness = population[i].fitness;
}
}
void mutate(ga_struct &member)
{
int tsize = GA_TARGET.size();
int ipos = rand() % tsize;
int delta = (rand() % 90) + 32;
member.str[ipos] = ((member.str[ipos] + delta) % 122);
}
void mate(ga_vector &population, ga_vector &buffer)
{
int esize = GA_POPSIZE * GA_ELITRATE;
int tsize = GA_TARGET.size(), spos, i1, i2;
elitism(population, buffer, esize);
// Mate the rest
for (int i=esize; i<GA_POPSIZE; i++) {
i1 = rand() % (GA_POPSIZE / 2);
i2 = rand() % (GA_POPSIZE / 2);
spos = rand() % tsize;
buffer[i].str = population[i1].str.substr(0, spos) +
population[i2].str.substr(spos, esize - spos);
if (rand() < GA_MUTATION) mutate(buffer[i]);
}
}
inline void print_best(ga_vector &gav)
{ cout << "Best: " << gav[0].str << " (" << gav[0].fitness << ")" << endl; }
inline void swap(ga_vector *&population,
ga_vector *&buffer)
{ ga_vector *temp = population; population = buffer; buffer = temp; }
int main()
{
srand(unsigned(time(NULL)));
ga_vector pop_alpha, pop_beta;
ga_vector *population, *buffer;
init_population(pop_alpha, pop_beta);
population = &pop_alpha;
buffer = &pop_beta;
for (int i=0; i<GA_MAXITER; i++) {
calc_fitness(*population); // вычисляем пригодность
sort_by_fitness(*population); // сортируем популяцию
print_best(*population); // выводим лучшую популяцию
if ((*population)[0].fitness == 0) break;
mate(*population, *buffer); // спариваем популяции
swap(population, buffer); // очищаем буферы
}
return 0;
}
Сразу хочется дать несколько комментариев к коду. Во-первых, мы схитрили, когда установили фиксированные размеры строк в генетическом алгоритме, которые равны размеру искомой строки. Это сделано, чтобы обеспечить лучшее понимание кода. Во-вторых, для хранения данных используется STL-класс vector — это сделано для того, чтобы упростить сортировку. Наконец, программа использует два массива для хранения популяций — один для текущей, второй является буфером для следующего поколения. В каждом поколении очки округляются до целого для ускорения вычислений.
Определение пригодности
Давайте, взглянем на функцию определения пригодности популяции:
void calc_fitness(ga_vector &population)
{
string target = GA_TARGET;
int tsize = target.size();
unsigned int fitness;
for (int i=0; i<GA_POPSIZE; i++) {
fitness = 0;
for (int j=0; j<tsize; j++) {
fitness += abs(int(population[i].str[j] - target[j]));
}
population[i].fitness = fitness;
}
}
В принципе, здесь просто перебирается каждый член популяции и сравнивается с таковым в целевой строке. Разницы между символами складываются и накопленная сумма используется как значение пригодности (таким образом, чем она меньше, тем лучше).
Результат
При выполнении, программа выдает на экран лучшую популяцию и ее пригодность (число в скобках).
Best: IQQte=Ygqem# (152)
Best: Crmt`!qrya+6 (148)
Best: 8ufxp+Rigfm* (140)
Best: b`hpf"woljh[ (120)
Best: b`hpf"woljh4 (81)
Best: b`hpf"woljh" (63)
Best: Kdoit!wnsk_! (24)
Best: Kdoit!wnsk_! (24)
Best: Idoit!wnsk_! (22)
Best: Idoit!wnsk_! (22)
Best: Idoit!wnsk_! (22)
Best: Idoit!wnsk_! (22)
Best: Ifknm!vkrlf? (17)
Best: Ifknm!vkrlf? (17)
Best: Gfnio!wnskd$ (14)
Best: Ffnjo!wnskd$ (14)
Best: Hflio!wnskd$ (11)
Best: Hflio!wnskd$ (11)
Best: Kflkn wosld" (8)
Best: Ifmmo workd" (6)
Best: Hfljo wosld" (5)
Best: Hflmo workd" (4)
Best: Hflmo workd" (4)
Best: Hflmo workd" (4)
Best: Iflmo world! (3)
Best: Iflmo world! (3)
Best: Hflmo world! (2)
Best: Hflmo world! (2)
Best: Hflko world! (2)
Best: Hflko world! (2)
Best: Hdllo world! (1)
Best: Hfllo world! (1)
Best: Hfllo world! (1)
Best: Helko world! (1)
Best: Hfllo world! (1)
Best: Hfllo world! (1)
Best: Hfllo world! (1)
Best: Hello world! (0)
Заключение
Надеюсь, эта небольшая программа способна продемонстрировать, как простой генетический алгоритм может быть использован для решения задачи. Данный алгоритм не является самым эффективным, хотя использование STL должно немного помочь. Алгоритм был протестирован в Visual Studio.
Пример применения
Чтобы проверить торгового робота на диапазоне параметров можно «проходить» диапазон не в циклах (как сейчас во всех программах), а при помощи генетических алгоритмов. И время сокращается в 9-12 раз. #
Оригинальная статья на Английском языке.
Что такое генетический алгоритм?

