Здрайствуйте!
В связи со сферой своей деятельности, собрался, на мой взгляд, очень ценный материал, которым хочу поделиться с вами. Думаю некоторым он будет крайне важен и полезен, возможно мои наработки сэкономят Вам время, в случае чего буду рад. И так ближе к делу. На Хабре уже есть хороший обзор алгоритмов кластеризации данных. Детально рассмотрена теория, но практических результатов нет, как обычно практика не так легка, как кажется. Поэтому хочу представить вашему сведению реальные результаты, проблемы и их решений возникшее при кластеризации (точней сказать сегментации, потому что объект кластеризации — статическое изображение). Под катом будет и сегментация, и цифровая обработка изображений. Прошу…
Сначала краткая постановка задачи, возникшая как подзадача для задачи планирования траектории: есть статическое изображение, полученное с помощью камеры мобильного робота:

это изображение можно рассматривать как среду с препятствиями (сцена), представляющую собой совокупность объектов различных цветов и размеров, причем заранее неизвестно какой из объектов полезный (цель), а какой является препятствием (помехой). Так же предполагается, что каждый объект на изображении (препятствия, фон и дорожное покрытие) описывается своими цветами – основной признак, по которому можно его классифицировать. Так вот необходимо уметь выделять любой из объектов представленных на изображении.
Буквально кратко напомню, что такое кластеризация данных, в общем случае кластерный анализ (англ. Data clustering) — задача разбиения заданной выборки объектов (ситуаций) на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались. Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя. Кластерный анализ — это многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы (кластеры)(Q-кластеризация, или Q-техника, собственно кластерный анализ). Кластер — группа элементов, характеризуемых общим свойством, главная цель кластерного анализа — нахождение групп схожих объектов в выборке.
И зачем это вообще надо и без кластеризации можно жить? Тоже никто так и не осветил, попробую снять завесу с назначения этого понятия.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров. Во всех этих случаях может применяться иерархическая кластеризация, когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии. Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому. Классическим примером таксономии на основе сходства является биноминальная номенклатура живых существ, предложенная Карлом Линнеем в середине XVIII века. Аналогичные систематизации строятся во многих областях знания, чтобы упорядочить информацию о большом количестве объектов.
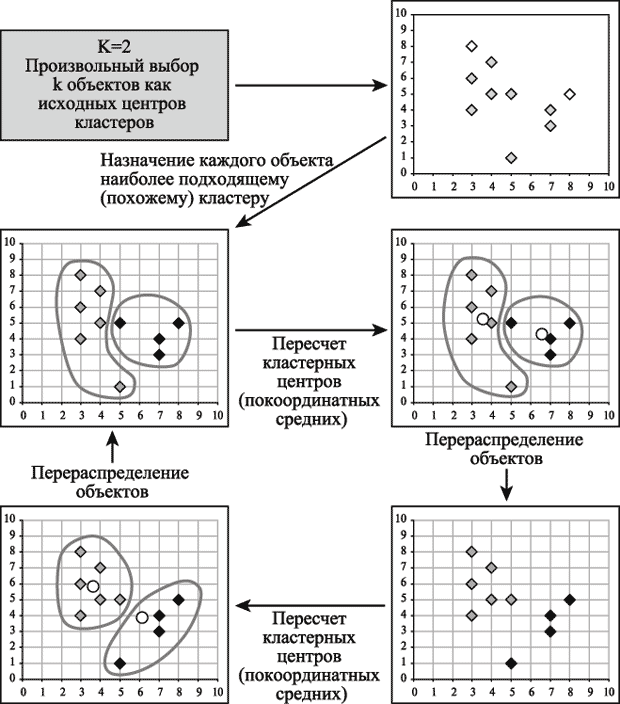
С головой хватит пока теории, вернемся к проблеме, теперь, когда кто-то познакомился с термином, кто-то освежил в голове, а кто и совсем пропустил, будем решать задачу. Для решения взят метод кластеризации к-средних (k-means), потому что данный метод не требует предварительных предположений относительно числа кластеров, для возможности использования этого метода необходимо иметь гипотезу о наиболее вероятном количестве кластеров. Общая идея алгоритма: заданное фиксированное число k кластеров наблюдения сопоставляются кластерам так, что средние в кластере (для всех переменных) максимально возможно отличаются друг от друга. Для любителей картинок и попытка «объяснить на пальцах» (при количестве кластеров равно двум):
Хочу сразу сказать, что все выполнялось в математическом пакете Matlab компании Mathworks (описание реализации — отдельная обширная статья). Применив k-средних для исходного изображения, приведённого вначале, получим следующее сегментированное изображение:
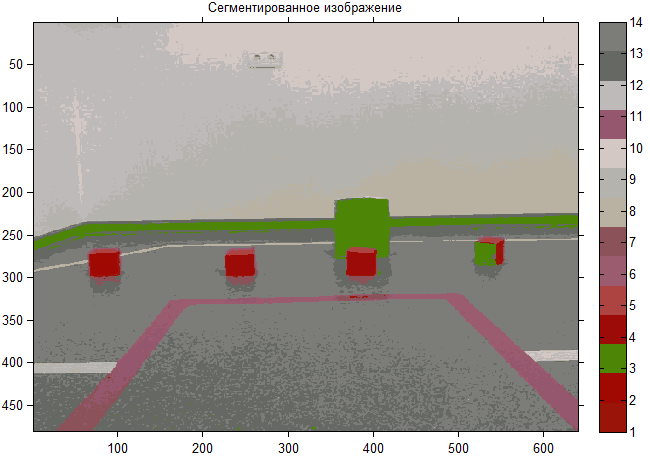
Видно, что большинство кластеров не имеют четких границ, накладываются друг на друга. Сравнивая оба рисунка, не трудно заметить, что появились нетипичные объекты (“разводы” на стене и полу), которые желательно (скорей необходимо для реальной задачи) собрать в общий кластер. Это связано с тем, что алгоритм слишком чувствителен к выбросам, которые могут искажать среднее и необходимо выполнить предварительную обработку изображения.
Первое, что пришло в голову после долгих рассуждений, стало медианной фильтрацией изображения, которая является решением для эффективного удаление шума при сохранении важных для последующего распознавания деталей изображения. Сложность решения данной задачи существенно зависит от характера шумов. В отличие от детерминированных искажений, которые описываются функциональными преобразованиями исходного изображения, для описания случайных воздействий используют модели аддитивного, импульсного и мультипликативного шумов. А теперь плавно погрузимся в теорию.
Наиболее распространенным видом помех является случайный аддитивный шум, статистически независимый от сигнала. Модель аддитивного шума используется тогда, когда сигнал на выходе системы или на каком-либо этапе преобразования может рассматриваться как сумма полезного сигнала и некоторого случайного сигнала. Модель аддитивного шума хорошо описывает действие зернистости фотопленки, флуктуационный шум в радиотехнических системах, шум квантования в аналого-цифровых преобразователях и т.п. Аддитивный гауссов шум характеризуется добавлением к каждому пикселю изображения значений с нормальным распределением и с нулевым средним значением. Такой шум обычно появляется на этапе формирования цифровых изображений. Основную информацию в изображениях несут контуры объектов. Классические линейные фильтры способны эффективно удалить статистический шум, но степень размытости мелких деталей на изображении может превысить допустимые значения. Для решения этой проблемы используются нелинейные методы, например алгоритмы на основе анизотропной диффузии Перрона и Малика, билатеральные и трилатеральные фильтры. Суть таких методов заключается в использовании локальных оценок, адекватных определению контура на изображении, и сглаживания таких участков в наименьшей степени. Импульсный шум характеризуется заменой части пикселей на изображении значениями фиксированной или случайной величины. На изображении такие помехи выглядят изолированными контрастными точками. Импульсный шум характерен для устройств ввода изображений с телевизионной камеры, систем передачи изображений по радиоканалам, а также для цифровых систем передачи и хранения изображений. Для удаления импульсного шума используется специальный класс нелинейных фильтров, построенных на основе ранговой статистики. Общей идеей таких фильтров является детектирование позиции импульса и замена его оценочным значением, при сохранении остальных пикселей изображения неизменными.
Медианная фильтрация изображений наиболее эффективна, если шум на изображении имеет импульсный характер и представляет собой ограниченный набор пиковых значений на фоне нулей. В результате применения медианного фильтра наклонные участки и резкие перепады значений яркости на изображениях не изменяются. Это очень полезное свойство именно для изображений, на которых контуры несут основную информацию. При медианной фильтрации зашумленных изображений степень сглаживания контуров объектов напрямую зависит от размеров апертуры фильтра и формы маски. При малых размерах апертуры лучше сохраняются контрастные детали изображения, но в меньшей степени подавляется импульсные шумы. При больших размерах апертуры наблюдается обратная картина. Оптимальный выбор формы сглаживающей апертуры зависит от специфики решаемой задачи и формы объектов. Особое значение это имеет для задачи сохранения перепадов (резких границ яркости) в изображениях.
Ну все, теперь можно показывать результаты

Все стало вроде хорошо, но было принято решение не останавливаться на достигнутом и тут почти случайно наткнулся на технологический прием обработки фотографического изображения, который позволяет добиться эффекта ощущения большей его резкости за счет усиления контраста тональных переходов (Unsharp masking). Важно отметить, что нерезкое маскирование не повышает резкость изображения на самом деле. Оно не может восстановить потерянные на разных этапах производства изображения детали (при съёмке, сканировании, изменении размера, полиграфическом воспроизведении). Нерезкое маскирование усиливает локальный контраст изображения на тех участках, где изначально присутствовали резкие изменения градаций цвета. Благодаря этому изображение визуально воспринимается как более резкое.
Если наглядно, то после медианной фильтрации и нерезкого маскирования будет вот такая картинка:

Ну, а вот теперь выполним кластеризацию и сравним, что было и что стало:
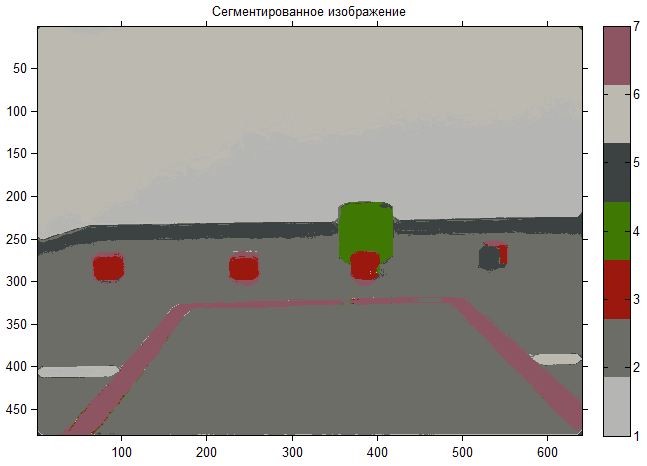
Как видно, сразу уменьшилось количество кластеров и теперь они имеют более четкие границы, можно считать, что задача решена, только осталось предложить инструмент для выделения объекта на изображение.
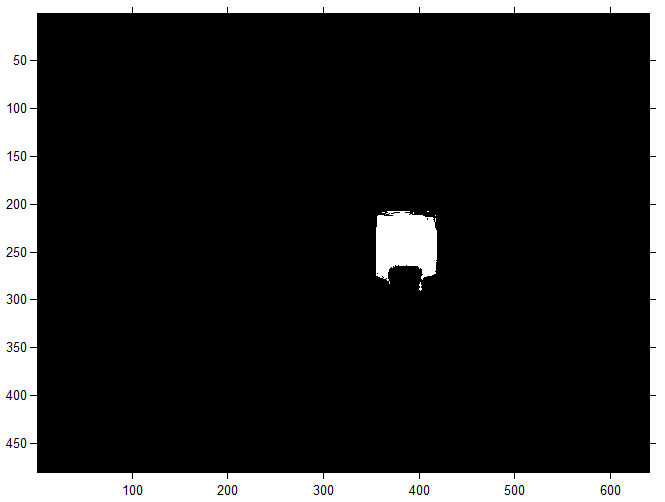
Когда выполнен кластерный анализ, можно определить координаты целевого объекта на изображении. Для этого кластера представляются бинарными изображениями (масками), на которых значения каждого пикселя условно кодируются (0 — задний план или фон, 1 – передний план), то есть сегментация с выделением границ. Например, маска зеленного объекта будет
Спасибо за внимание, надеюсь, Вам было и будет полезно.
В связи со сферой своей деятельности, собрался, на мой взгляд, очень ценный материал, которым хочу поделиться с вами. Думаю некоторым он будет крайне важен и полезен, возможно мои наработки сэкономят Вам время, в случае чего буду рад. И так ближе к делу. На Хабре уже есть хороший обзор алгоритмов кластеризации данных. Детально рассмотрена теория, но практических результатов нет, как обычно практика не так легка, как кажется. Поэтому хочу представить вашему сведению реальные результаты, проблемы и их решений возникшее при кластеризации (точней сказать сегментации, потому что объект кластеризации — статическое изображение). Под катом будет и сегментация, и цифровая обработка изображений. Прошу…
Начнем
Сначала краткая постановка задачи, возникшая как подзадача для задачи планирования траектории: есть статическое изображение, полученное с помощью камеры мобильного робота:

это изображение можно рассматривать как среду с препятствиями (сцена), представляющую собой совокупность объектов различных цветов и размеров, причем заранее неизвестно какой из объектов полезный (цель), а какой является препятствием (помехой). Так же предполагается, что каждый объект на изображении (препятствия, фон и дорожное покрытие) описывается своими цветами – основной признак, по которому можно его классифицировать. Так вот необходимо уметь выделять любой из объектов представленных на изображении.
Буквально кратко напомню, что такое кластеризация данных, в общем случае кластерный анализ (англ. Data clustering) — задача разбиения заданной выборки объектов (ситуаций) на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались. Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя. Кластерный анализ — это многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы (кластеры)(Q-кластеризация, или Q-техника, собственно кластерный анализ). Кластер — группа элементов, характеризуемых общим свойством, главная цель кластерного анализа — нахождение групп схожих объектов в выборке.
И зачем это вообще надо и без кластеризации можно жить? Тоже никто так и не осветил, попробую снять завесу с назначения этого понятия.
- Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»).
- Сжатие данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
- Обнаружение новизны (англ. novelty detection). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров. Во всех этих случаях может применяться иерархическая кластеризация, когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии. Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому. Классическим примером таксономии на основе сходства является биноминальная номенклатура живых существ, предложенная Карлом Линнеем в середине XVIII века. Аналогичные систематизации строятся во многих областях знания, чтобы упорядочить информацию о большом количестве объектов.
С головой хватит пока теории, вернемся к проблеме, теперь, когда кто-то познакомился с термином, кто-то освежил в голове, а кто и совсем пропустил, будем решать задачу. Для решения взят метод кластеризации к-средних (k-means), потому что данный метод не требует предварительных предположений относительно числа кластеров, для возможности использования этого метода необходимо иметь гипотезу о наиболее вероятном количестве кластеров. Общая идея алгоритма: заданное фиксированное число k кластеров наблюдения сопоставляются кластерам так, что средние в кластере (для всех переменных) максимально возможно отличаются друг от друга. Для любителей картинок и попытка «объяснить на пальцах» (при количестве кластеров равно двум):
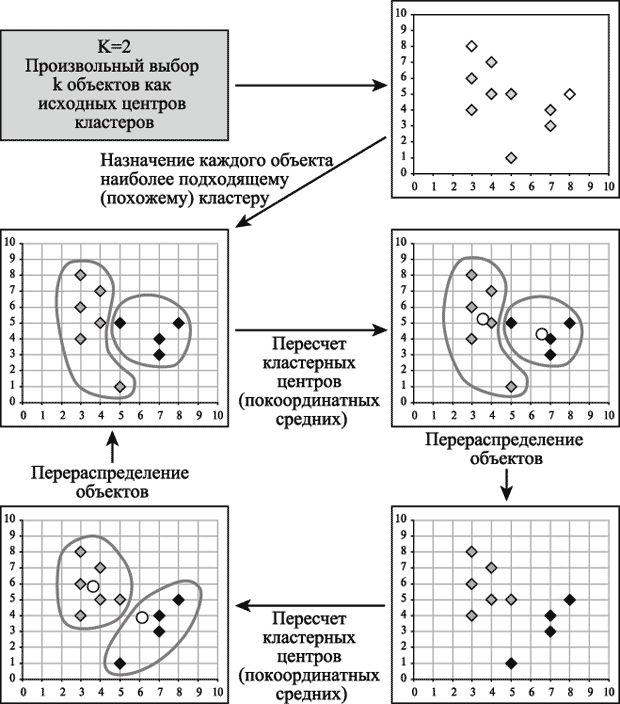
Основные достоинства алгоритма k-средних:
- простота использования;
- быстрота использования;
- понятность и прозрачность алгоритма.
Недостатки алгоритма k-средних:
- алгоритм слишком чувствителен к выбросам, которые могут искажать среднее. Возможным решением этой проблемы является использование модификации алгоритма — алгоритм k-медианы;
- алгоритм может медленно работать на больших базах данных. Возможным решением данной проблемы является использование выборки данных.
Практические трудности и их решение
Хочу сразу сказать, что все выполнялось в математическом пакете Matlab компании Mathworks (описание реализации — отдельная обширная статья). Применив k-средних для исходного изображения, приведённого вначале, получим следующее сегментированное изображение:
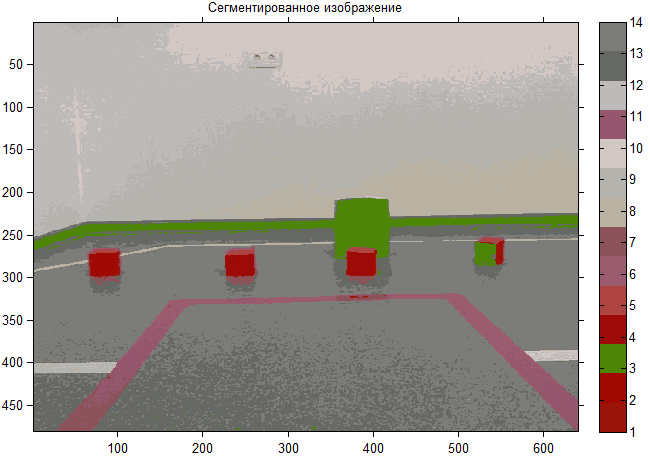
Видно, что большинство кластеров не имеют четких границ, накладываются друг на друга. Сравнивая оба рисунка, не трудно заметить, что появились нетипичные объекты (“разводы” на стене и полу), которые желательно (скорей необходимо для реальной задачи) собрать в общий кластер. Это связано с тем, что алгоритм слишком чувствителен к выбросам, которые могут искажать среднее и необходимо выполнить предварительную обработку изображения.
Первое, что пришло в голову после долгих рассуждений, стало медианной фильтрацией изображения, которая является решением для эффективного удаление шума при сохранении важных для последующего распознавания деталей изображения. Сложность решения данной задачи существенно зависит от характера шумов. В отличие от детерминированных искажений, которые описываются функциональными преобразованиями исходного изображения, для описания случайных воздействий используют модели аддитивного, импульсного и мультипликативного шумов. А теперь плавно погрузимся в теорию.
Наиболее распространенным видом помех является случайный аддитивный шум, статистически независимый от сигнала. Модель аддитивного шума используется тогда, когда сигнал на выходе системы или на каком-либо этапе преобразования может рассматриваться как сумма полезного сигнала и некоторого случайного сигнала. Модель аддитивного шума хорошо описывает действие зернистости фотопленки, флуктуационный шум в радиотехнических системах, шум квантования в аналого-цифровых преобразователях и т.п. Аддитивный гауссов шум характеризуется добавлением к каждому пикселю изображения значений с нормальным распределением и с нулевым средним значением. Такой шум обычно появляется на этапе формирования цифровых изображений. Основную информацию в изображениях несут контуры объектов. Классические линейные фильтры способны эффективно удалить статистический шум, но степень размытости мелких деталей на изображении может превысить допустимые значения. Для решения этой проблемы используются нелинейные методы, например алгоритмы на основе анизотропной диффузии Перрона и Малика, билатеральные и трилатеральные фильтры. Суть таких методов заключается в использовании локальных оценок, адекватных определению контура на изображении, и сглаживания таких участков в наименьшей степени. Импульсный шум характеризуется заменой части пикселей на изображении значениями фиксированной или случайной величины. На изображении такие помехи выглядят изолированными контрастными точками. Импульсный шум характерен для устройств ввода изображений с телевизионной камеры, систем передачи изображений по радиоканалам, а также для цифровых систем передачи и хранения изображений. Для удаления импульсного шума используется специальный класс нелинейных фильтров, построенных на основе ранговой статистики. Общей идеей таких фильтров является детектирование позиции импульса и замена его оценочным значением, при сохранении остальных пикселей изображения неизменными.
Медианная фильтрация изображений наиболее эффективна, если шум на изображении имеет импульсный характер и представляет собой ограниченный набор пиковых значений на фоне нулей. В результате применения медианного фильтра наклонные участки и резкие перепады значений яркости на изображениях не изменяются. Это очень полезное свойство именно для изображений, на которых контуры несут основную информацию. При медианной фильтрации зашумленных изображений степень сглаживания контуров объектов напрямую зависит от размеров апертуры фильтра и формы маски. При малых размерах апертуры лучше сохраняются контрастные детали изображения, но в меньшей степени подавляется импульсные шумы. При больших размерах апертуры наблюдается обратная картина. Оптимальный выбор формы сглаживающей апертуры зависит от специфики решаемой задачи и формы объектов. Особое значение это имеет для задачи сохранения перепадов (резких границ яркости) в изображениях.
Ну все, теперь можно показывать результаты

Все стало вроде хорошо, но было принято решение не останавливаться на достигнутом и тут почти случайно наткнулся на технологический прием обработки фотографического изображения, который позволяет добиться эффекта ощущения большей его резкости за счет усиления контраста тональных переходов (Unsharp masking). Важно отметить, что нерезкое маскирование не повышает резкость изображения на самом деле. Оно не может восстановить потерянные на разных этапах производства изображения детали (при съёмке, сканировании, изменении размера, полиграфическом воспроизведении). Нерезкое маскирование усиливает локальный контраст изображения на тех участках, где изначально присутствовали резкие изменения градаций цвета. Благодаря этому изображение визуально воспринимается как более резкое.
Если наглядно, то после медианной фильтрации и нерезкого маскирования будет вот такая картинка:

Ну, а вот теперь выполним кластеризацию и сравним, что было и что стало:
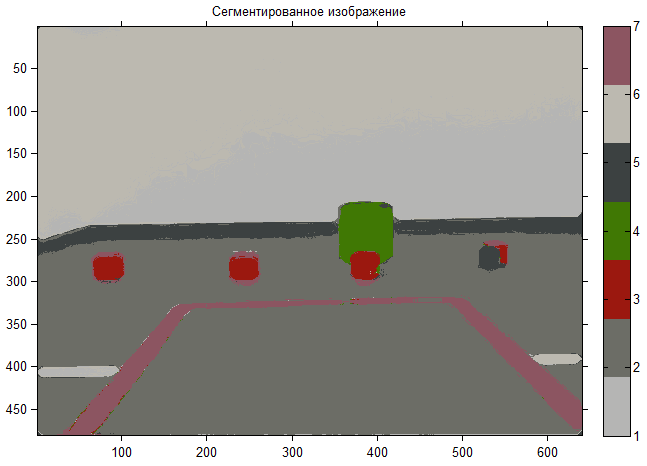
Как видно, сразу уменьшилось количество кластеров и теперь они имеют более четкие границы, можно считать, что задача решена, только осталось предложить инструмент для выделения объекта на изображение.
Выделение объектов. Заключительный этап
Когда выполнен кластерный анализ, можно определить координаты целевого объекта на изображении. Для этого кластера представляются бинарными изображениями (масками), на которых значения каждого пикселя условно кодируются (0 — задний план или фон, 1 – передний план), то есть сегментация с выделением границ. Например, маска зеленного объекта будет
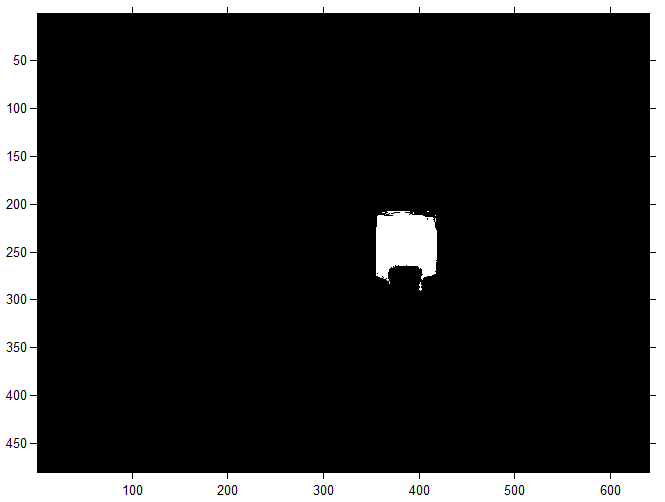
Спасибо за внимание, надеюсь, Вам было и будет полезно.

