Не так давно я считал. что нет оправдания использованию
При использовании итераторов. Точнее когда вы удаляете или вставляете элементы через
Этот же код можно запросто переписать с использованием дополнительного списка и тогда алгоритм с
Но это же не правильно, что структуры данных диктуют нам алгоритм. Но именно этот алгоритм навел меня на мысль, как создать список, который большинство операций будет выполнять за время
Для этого нам понадобится допущение: «Операции вставки и удаления происходят рядом.» Конечно, мы можем представить ситуацию, в которой операции вставки и удаления будут происходить хаотично, но в этом случае нас не спасет ни
Идея такова. Список хранится не в одном массиве, а в 2х. Причем, каждый массив может вместить его целиком.

При вставке элемента в середину списка, мы вставляем его в разрыв. Но ведь мы можем захотеть вставить элемент не туда где у нас происходит разделение. Для этого мы перемещаем часть элементов, чтобы разрыв сдвинулся в нужно место.

Вы скажете: «Да, мы сдвинули меньше элементов, чем в случае с
То же самое происходит и при удалении. Разрыв смещается на то место, откуда был удален элемент.
Я быстренько написал реализацию этого списка. И прогнал тесты: заполнение, последовательное сканирование, сканирование по индексу, фильтрация, удаление всего списка с головы по одному элементу. Т.к. результаты сильно разнятся для разных списков, визуализировать их достаточно сложно. Поэтому просто покажу таблицы. Графики будут, но позже. В таблицах приведено время выполнения различных задач на различных объемах в миллисекундах.
Как можно видеть из таблицы,
Слабым местом
Ну и, наконец, моя реализаци


Из всех этих графиков видно, что на различных операциях
Код
Предостережение: не пытайтесь использовать его в промышленной разработке.
java.util.LinkedList в качестве реализации java.util.List. Но что-то заставило меня его поискать. Давайте разберемся. Любой грамотный Java-специалист знает, что java.util.ArrayList нужно использовать тогда, когда нам нужен быстрый доступ по индексу, а java.util.LinkedList, если нам нужно вставлять или удалять элементы в середине списка. Не многие из них догадываются, что если мы будем вставлять или удалять элементы в середине списка методами remove(int index) и add(int index, E element), то на поиск нужного элемента будет затрачено время в среднем пропорциональное размеру списка O(N). Так когда же возникает выгода от использования java.util.LinkedList?При использовании итераторов. Точнее когда вы удаляете или вставляете элементы через
java.util.ListIterator. В конце-концов, в поисках оправдания я нашел вполне реальный пример кода, на котором java.util.LinkedList дает значительное преимущество перед java.util.ArrayList. Это простейший алгоритм фильтрации, который удаляет из списка все элементы, не удовлетворяющие заданному условию.for (Iterator<E> i = list.iterator(); i.hasNext(); ) { E val = i.next(); if (!condition(val)) { i.remove(); } }
Этот же код можно запросто переписать с использованием дополнительного списка и тогда алгоритм с
java.util.ArrayList, как минимум, не будет иметь квадратичную зависимость от первоначального размера.List<E> list1 = new ArrayList<E>(); for (Iterator<E> i = list.iterator(); i.hasNext(); ) { E val = i.next(); if (condition(val)) { list1.add(val); } } list.clear(); list.addAll(list1);
Но это же не правильно, что структуры данных диктуют нам алгоритм. Но именно этот алгоритм навел меня на мысль, как создать список, который большинство операций будет выполнять за время
O(1).Для этого нам понадобится допущение: «Операции вставки и удаления происходят рядом.» Конечно, мы можем представить ситуацию, в которой операции вставки и удаления будут происходить хаотично, но в этом случае нас не спасет ни
java.util.ArrayList, ни java.util.LinkedList, с которыми мы сражаемся. Ведь чтобы добавить или удалить произвольный элемент java.util.ArrayList должен в общем случае сдвинуть в массиве количество элементов пропорциональное размеру O(N), а java.util.LinkedList должен его найти O(N).Идея такова. Список хранится не в одном массиве, а в 2х. Причем, каждый массив может вместить его целиком.
При вставке элемента в середину списка, мы вставляем его в разрыв. Но ведь мы можем захотеть вставить элемент не туда где у нас происходит разделение. Для этого мы перемещаем часть элементов, чтобы разрыв сдвинулся в нужно место.
Вы скажете: «Да, мы сдвинули меньше элементов, чем в случае с
java.util.ArrayList, но оно всё равно пропорционально размеру списка.» Вы правы, но если вспомнить о нашем допущении, то каждый раз, кроме первого, мы будем двигать незначительное количество элементов.То же самое происходит и при удалении. Разрыв смещается на то место, откуда был удален элемент.
Я быстренько написал реализацию этого списка. И прогнал тесты: заполнение, последовательное сканирование, сканирование по индексу, фильтрация, удаление всего списка с головы по одному элементу. Т.к. результаты сильно разнятся для разных списков, визуализировать их достаточно сложно. Поэтому просто покажу таблицы. Графики будут, но позже. В таблицах приведено время выполнения различных задач на различных объемах в миллисекундах.
ArrayList
| size | fill | sequence | index | filtration | remove first |
| 20000 | 0 | 0 | 0 | 94 | 47 |
| 40000 | 0 | 0 | 0 | 406 | 187 |
| 60000 | 16 | 0 | 0 | 891 | 437 |
| 80000 | 0 | 0 | 0 | 1578 | 782 |
| 100000 | 0 | 15 | 0 | 2453 | 1219 |
| 120000 | 16 | 0 | 15 | 3516 | 1750 |
| 140000 | 16 | 0 | 0 | 4796 | 2391 |
| 160000 | 16 | 0 | 15 | 6219 | 3125 |
| 180000 | 16 | 0 | 15 | 7969 | 3984 |
| 200000 | 63 | 0 | 0 | 9859 | 4844 |
Как можно видеть из таблицы,
java.util.ArrayList отлично справляется с заполнением и любым сканированием, а на операциях фильтрации и даже удаления списка с головы терпит сокрушительное поражение.LinkedList
| size | fill | sequence | index | filtration | remove first |
| 20000 | 0 | 0 | 406 | 0 | 0 |
| 40000 | 31 | 0 | 1985 | 0 | 0 |
| 60000 | 15 | 0 | 3828 | 16 | 0 |
| 80000 | 0 | 0 | 8359 | 0 | 0 |
| 100000 | 16 | 0 | 24891 | 0 | 15 |
| 120000 | 16 | 0 | 43562 | 16 | 0 |
| 140000 | 16 | 15 | 52985 | 0 | 15 |
| 160000 | 16 | 0 | 57047 | 15 | 0 |
| 180000 | 79 | 0 | 121531 | 0 | 15 |
| 200000 | 32 | 15 | 152250 | 16 | 16 |
Слабым местом
java.util.LinkedList является доступ по индексу, а вот операция фильтрации выполняется заметно быстрее.DoubleArrayList
| size | fill | sequence | index | filtration | remove first |
| 20000 | 0 | 0 | 0 | 0 | 0 |
| 40000 | 16 | 0 | 0 | 0 | 0 |
| 60000 | 0 | 0 | 0 | 15 | 0 |
| 80000 | 0 | 0 | 16 | 0 | 0 |
| 100000 | 16 | 0 | 0 | 15 | 0 |
| 120000 | 16 | 0 | 0 | 15 | 0 |
| 140000 | 16 | 16 | 0 | 15 | 0 |
| 160000 | 16 | 16 | 0 | 15 | 0 |
| 180000 | 47 | 16 | 0 | 15 | 0 |
| 200000 | 32 | 0 | 15 | 0 | 16 |
Ну и, наконец, моя реализаци
org.kefirsf.list.DoubleArrayList не проседает ни на одном из тестов.Давайте сравним с LinkedList на больших объемах.
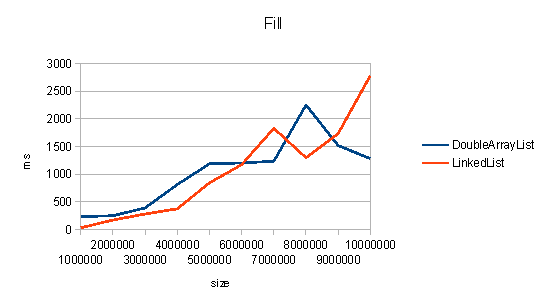
Заполнение
Фильтрация
Удаление с головы
Из всех этих графиков видно, что на различных операциях
DoubleArrayList работает за время сопоставимое с java.util.LinkedList. Пусть даже не всегда лучше. Главное, что не возникает квадратичной зависимости от размера массива, а все операции выполняются за O(N), а это значит, что единичные операции в среднем выполняются за O(1). Таким образом, цель достигнута.Код
org.kefirsf.list.DoubleArrayList доступен на GitHub: github.com/kefirfromperm/multi-array-listПредостережение: не пытайтесь использовать его в промышленной разработке.
org.kefirsf.list.DoubleArrayList ещё недостаточно хорошо покрыт тестами, его использование может приводить к утечкам памяти.
