Эта статья — частичный перевод одной интересной статьи с sqlite.org, в которой подробно рассматривается реализация транзакций в SQLite. На самом деле я очень редко работаю с SQLite, но тем не менее мне очень понравилось это чтиво. Поэтому если хотите просто развить кругозор — будет интересно почитать. Первые две секции не включены в перевод, так как там нет ничего интересного, да и мне лень их набивать (пост и так огромный).
Мы начнём с обзора шагов, которые SQLite предпринимает, чтобы совершить атомарный коммит транзакции, которая затрагивает только один файл базы данных. Детали формата файлов, которые используются для защиты от повреждения БД и техники, которые применяются для коммита в несколько БД будут показаны ниже.
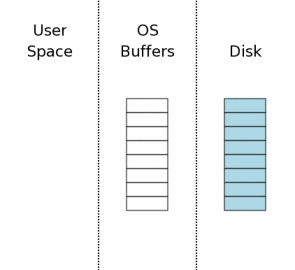
Состояние системы, когда соединение с БД только что было поднято, поверхностно изображено на рисунке справа. Справа показана информация, которая хранится на энерго-независимом носителе. Каждый прямоугольник — это сектор. Синий цвет говорит о том, что этот сектор содержит оригинальные данные. Посередине изображён дисковый кеш операционной системы. В самом начале нашего примера кеш холодный, это изображено белым цветом. На левой части рисунка — содержимое оперативной памяти процесса, который использует SQLite. Соединение с БД только что было открыто, и никакой информации прочитано не было.
Перед тем, как SQLite сможет начать запись, он сначала должен узнать, что там уже есть. Даже если это просто вставка новых данных, ему нужно прочитать схему из таблицы sqlite_master, чтобы он знал, как распарсить INSERT-запрос и понять, куда конкретно писать данные.
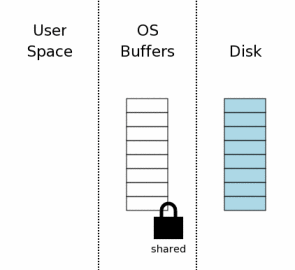
Первый шаг заключается в получении совместной блокировки (shared lock) на файл базы данных. Совместная блокировка разрешает двум, или более, коннектам читать из файла в одно и то же время. Но такой вид блокировки запрещает другим соединениям производить запись, пока она не снята. Это обязательно, так как если бы другое соединение производило запись в это же время, мы бы могли прочитать часть неизмененных данных и другую часть данных уже после изменения. Тогда запись можно было бы считать неатомарной.
Заметьте, что блокировка была установлена на дисковом кеше ОСи, а не на самом диске. Файловые блокировки — обычно просто флаги, управляемые ядром системы. Они сбросятся при любом креше системы или отказе питания. Так же они обычно сбрасываются, когда процесс, получивший блокировку, умирает.
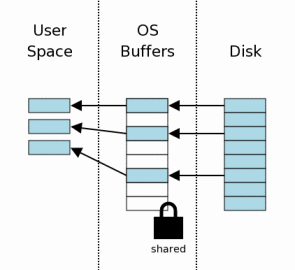
После того, как блокировка была получена, мы можем начать чтение из файла базы данных. В данном сценарии, мы подразумеваем, что кеш ещё не прогрет, так что информация должна быть сначала прочитана с накопителя данных в кеш операционной системы, а потом может быть перемещена из кеша ОСи в юзер-спейс. На последующих чтениях вся или некоторая информация уже будет находится в кеше, так что ее нужно будет только отдать в юзер-спейс.
Обычно из файла БД будет прочитана только малая часть страниц. В нашем примере мы видим, что из восьми страниц всего три были прочитаны. В типичном приложении БД будет содержать тысячи страниц и запрос затронет очень малый процент из них.
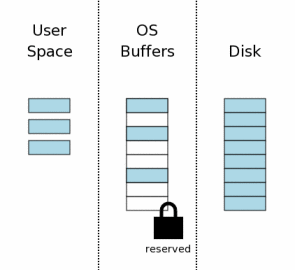
Перед тем, как делать какие-то изменения в БД, SQLite сначала получает «резервирующую» блокировку (reserved lock) на файл БД (прим. пер. — это самый сносный перевод, который пришёл мне в голову). Такая блокировка похожа на совместную тем, что она тоже разрешает другим процессам читать из файла БД. Одна резервирующая блокировка может сосуществовать с несколькими совместными. Тем не менее, в один момент времени может существовать только одна резервирующая блокировка на файл. Таким образом только один процесс может писать в БД в один момент времени.
Идея резервирующего лока состоит в том, что он говорит о намерении процесса начать запись в файл в ближайшем будущем, но пока он этого делать ещё не начал. И, так как изменения ещё не начали писаться, другие процессы могут продолжить чтение из БД. Но никакие процессы больше не смогут инициировать запись, пока блокировка жива.

Перед тем, как начать запись в файл базы данных, SQLite сначала создаёт отдельный лог для отката изменений, и пишет в него оригинальные страницы БД, которые будут изменены. Лог отката содержит всю нужную информацию, чтобы откатить БД в оригинальное состояние до транзакции.
Лог отката содержит маленький заголовок (показан зелёным на диаграмме), который содержит размер файла БД в оригинальном состоянии. Так что, если после изменения файл БД вырастет в размере, мы все же будем знать его изначальный размер. Номер страницы хранится рядом с каждой страницей в логе.
Когда новый файл создан, большинство операционных систем (Windows, Linux, Mac OS X) ничего на самом деле не напишут на диск. Новый файл создаётся только в кеше операционной системы. Файл не создаётся на накопителе до тех пор, пока операционная система не найдёт для этого подходящее время. Это создаёт видимость для пользователя, будто операции ввода-вывода на накопителе совершаются гораздо быстрее, чем это возможно. Мы изобразили этот процесс на диаграмме справа, показав, что лог отката появился только в дисковом кеше, но не на самом диске.

После того, как оригинальный контент был сохранен в лог отката, страницы могут быть изменены в пользовательской памяти. Каждое соединение с БД имеет собственную приватную копию юзер-спейса, так что изменения, сделанные в юзер-спейсе видны только данному соединению. Другие соединения до сих пор видят информацию из дискового кеша, которая ещё не была изменена. Так что, даже не смотря на то, что один процесс занимается изменением данных в БД, другие процессы могут продолжить чтение собственных копий оригинального контента.
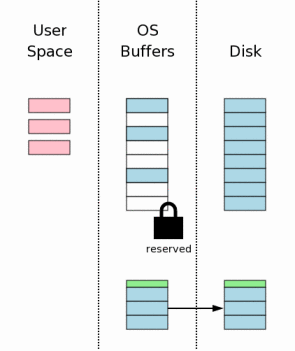
Следующим шагом будет сброс лога отката (rollback journal) из кеша на энерго-независимую память. Как мы увидим позже, это очень важный шаг, который даёт нам гарантию сохранности данных при отказе питания. Этот шаг также требует много времени, так как запись на энерго-независимую память — это, обычно, медленная операция.
Этот шаг обычно более сложен, нежели просто сброс лога на диск. На большинстве платформ нужно делать два flush-а (или fsync-а). Первый flush пишет основное содержимое лога. Потом заголовок лога изменяется, чтобы отразить в нем кол-во страниц в логе. После этого заголовок сбрасывается на диск. Объяснения, почему нам это нужно будут даны ниже.

Перед тем, как сделать изменения в самом файле БД, мы должны сначала получить эксклюзивную блокировку на него. Получение такой блокировки состоит из двух шагов. Сначала SQLite получает блокировку «в ожидании» (pending lock). Потом этот лок переводится в эксклюзивный.
«pending lock» позволяет другим процессам, которые уже имеют совместную блокировку на файл продолжить чтение из файла. Но он запрещает другим процессам получать новые совместные локи. Это нужно, чтобы не получилась ситуация, когда запись не может быть совершенна, из-за большого и постоянно прибывающего кол-ва запросов на чтение. Каждый процесс сначала получает shared lock перед началом чтения, после чего читает и сбрасывает блокировку. Когда существует множество процессов, постоянно нуждающихся в чтении, может произойти такая ситуация, когда каждый новый процесс получает свой лок до того, как какой-либо из существующих отпустит свой лок. Таким образом никогда не будет существовать момента, когда на файле нет ни единого shared лока, и соответственно не будет возможности получить эксклюзивный лок. Блокировка «в ожидании» нужна, чтобы предотвратить возможность возникновения подобной ситуации, не давая получать новые совместные блокировки на файл, но позволяя дальше жить уже существующим. Когда же все shared локи будут отпущены, то pending lock можно будет перевести в состояние эксклюзивной блокировки.
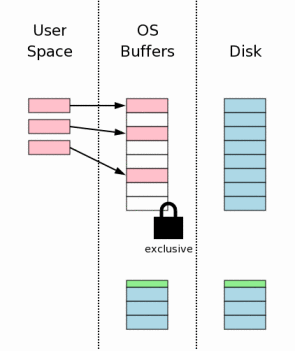
Когда эксклюзивная блокировка получена, мы можем быть уверены, что больше ни один процесс не совершает запись в этот файл и можно производить в нем изменения. Обычно эти изменения доходят лишь до дискового кеша ОСи и не сбрасываются на сам диск самостоятельно.
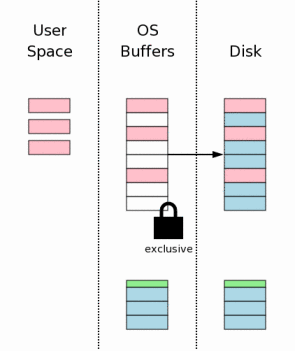
Теперь нужно вызвать flush, чтобы быть уверенными, что все изменения в БД записаны на энерго-независимую память. Это критичный шаг к тому, чтобы данные пережили дальнейшее возможное отключение энергии. Из-за медлительности дисков и флеш-памяти, этот шаг, вместе с записью лога отката (п. 3.7), занимает наибольшую часть времени затраченного на коммит транзакции в SQLite.

После того, как изменения были сохранены на диск, мы должны удалить лог отката. Это как раз тот момент, когда мы можем сказать, что коммит завершён успешно. Если произойдёт отказ питания или какой-то системный сбой перед удалением, тогда база восстановится в прежнее состояние — до коммита. Если отказ питания произойдёт после удаления лога отката, тогда коммит будет совершён. Таким образом, успешность коммита в SQLite в конечном итоге зависит от того, удалился ли файл с логом для отката, или нет.
Удаление файла это, на самом деле, не совсем атомарная операция, но она выглядит такой с точки зрения пользовательского процесса. Процесс всегда может спросить операционную систему: «Существует ли этот файл?» и он получит в ответ либо «да», либо «нет». После отказа питания, которое произошло во время коммита транзакции, SQLite спросит у операционной системы — существует ли файл с логом отката транзакции. Если да, то транзакция не была совершена и будет откачена. Если ответ был «нет», значит транзакция успешно совершена.
Существование незавершённой транзакции зависит от того, существует ли файл лога отката, а его удаление выглядит как атомарная операция с точки зрения конечного пользователя. Следовательно и транзакция выглядит как атомарная операция.
Удаление файла — дорогая операция на многих системах. В качестве оптимизации, SQLite может обрезать до нуля байт в длине, либо заполнять заголовок нулями. В любом случае, в итоге файл лога уже не будет возможно прочитать для отката и транзакция будет закоммичена. Обрезание файла до нуля в длину, так же как и удаление, предполагается как атомарная операция с точки зрения пользовательского процесса. Перезапись заголовка лога нулями — не атомарна, но если какая-либо часть заголовка повреждена — лог не будет применён для отката. Таким образом, мы можем сказать, что коммит произошёл тогда, когда заголовок лога отката стал невалидным. Обычно это происходит уже тогда, когда лишь первый байт заголовка обнулен.

Последним шагом коммита будет снятие эксклюзивной блокировки, чтобы остальные процессы снова имели доступ к базе данных.
На рисунке справа мы показали, что информация, которая была в пользовательской памяти, была очищена после снятия блокировки. Это было действительно так в более старых версиях SQLite. Но в более новых версиях SQLite информация сохраняется в юзер-спейсе на случай, если она понадобиться для следующей транзакции. Дешевле использовать данные, которые уже в памяти, вместо получения их из дискового кеша или чтения с самого диска. Перед использованием этих данных, мы должны снова получить shared лок, а также нужно убедиться, что ни один процесс не изменил состояние базы данных, пока у нас не было лока. На самой первой страницы в файле БД есть счётчик, который инкрементируется при каждом изменении. Мы можем узнать, изменилось ли состояние БД, проверив этот счётчик. Если в БД были внесены изменения, тогда пользовательский кеш должен быть очищен и перегрет. Но чаще случается так, что изменений не производилось и пользовательский кеш может быть использован дальше, что даёт хороший прирост в производительности.
Атомарный коммит должен совершаться мгновенно. Но все те действия, что были описаны выше, явно занимают какое-то конечное время на выполнение. Предположим, что питание компьютера было отключено на середине процесса коммита, описанного выше. Чтобы поддержать иллюзию мгновенных изменений, мы должны откатить все частичные изменения, которые были совершены и восстановить состояние базы данных в оригинальное.

Допустим, что отказ питания произошёл на шаге 3.10, когда изменения записывались на диск. Когда питание будет восстановлено, ситуация будет чем-то похожа на то, что изображено справа на рисунке. Мы пытались изменить три страницы в файле базы данных, но только одна из них была успешно перезаписана на диске. Другая страница частично записаны, а третья и вовсе осталась в оригинальном состоянии.
Лог отката будет целым лежать на диске после восстановления питания. Это ключевой момент. Причина потребности во flush-е на шаге 3.7 заключается в том, чтобы быть абсолютно уверенным, что весь лог отката полностью сохранен на энерго-независимую память перед тем, как будут совершены любые изменения в файле базы данных.
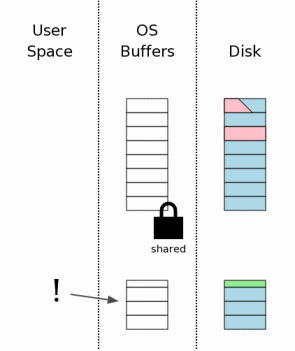
Когда процесс SQLite впервые пытается получить доступ к файлу БД, он сначала получает совместный лок на него, как это описано в секции 3.2. Но потом он обнаруживает, что существует лог отката. Тогда SQLite проверяет, является ли этот лог «горячим логом отката». Горячий лог — это лог отката, который должен быть применён к БД, чтобы восстановить ее в неповрежденное состояние. Горячий лог существует только тогда, когда какой-то процесс до этого был на каком-то шаге коммита транзакции и, по какой-то причине, упал в этот момент.
Лог отката «горячий», если все условия правдивы:
Наличие горячего лога — это сигнал о том, что предыдущий процесс, пытался закоммитить транзакцию, но провалился по какой-то причине. Горячий лог означает, что файл БД находится в неконсистентном состоянии и должен быть восстановлен перед использованием.
Первый шаг перед работой с горячим логом — получение эксклюзивной блокировки на файл базы данных. Это предотвратит возможность ситуации, когда два или более процесса пытаются применить один и тот же горячий лог в один момент времени.

Как только процесс получает эксклюзивный лок, ему разрешается писать в файл базы данных. Тогда он пытается прочесть оригинальный контент страниц из лога отката и записать его назад, в базу. Помните, что в заголовке лога содержится размер файла БД в оригинальном состоянии? SQLite использует эту информацию, чтобы обрезать файл БД до оригинального размера в случаях, когда незавершённая транзакция вызвала рост этого файла. После этого шага, база данных должна быть того же размера и содержать точно те же данные, что были до незавершённой транзакции.
После того, как весь лог был применён к файлу БД (а также сброшен на диск на случай ещё одной потери питания), его (лог) можно удалить.
Как и в секции 3.11, файл лога может быть обрезан до нуля байт в длину, либо его заголовок может быть перезаписан нулями. В любом случае, лог больше не «горяч» после этого шага.

Последний шаг восстановления — сменить эксклюзивный лок на совместный. Когда это случится, база данных будет в таком состоянии, будто откаченной транзакции и не было. Так как весь этот процесс восстановления происходит автоматически и прозрачно для юзера, это выглядит так, будто никакого восстановления не происходило.
SQLite позволяет с одного соединения говорить с двумя или более базами данных одновременно, используя команду
Когда транзакция затрагивает несколько файлов БД, то каждый из этих файлов имеет собственный лог отката и на каждый файл блокировка получается отдельно. На рисунке справа изображена ситуация, когда три разных файла баз данных были изменены в пределах одной транзакции. Ситуация на данном шаге аналогична обычной транзакции над одним файлом из секции 3.6. На каждом файле БД повешена резервирующая блокировка. Для каждой базы данных оригинальное содержимое тех страниц, которые сейчас будут изменены, были записаны в соответствующие логи отката, но эти логи ещё не были сброшены на диск. Файлы базы данных ещё не были изменены, но изменения уже есть в пользовательской памяти процесса.
Для краткости, рисунки в этой секции упрощены относительно тех, что были в других секциях. Голубой цвет все так же означает оригинальную информацию, а розовый — новую. Но отдельные страницы в логах отката файлах БД не показаны, и мы не показываем какая информация уже есть на диске, а какая ещё в системном кеше. Тем не менее все эти факторы все так же существуют и в много-файловой транзакции, но они бы занимали очень много места на диаграммах и не давали бы нам сильно полезной информации, поэтому здесь они опущены.
 Следующий шаг много-файловой транзакции — это создание мастер-лога. Имя мастер-лога такое же, как имя оригинального файла БД (к которой было открыто соединение) с добавленной строкой вида «-mjHHHHHHHH» («mj» от «master journal»), где HHHHHHHH — случайное 32-битное значение, которое генерируется для каждого нового мастер-лога.
Следующий шаг много-файловой транзакции — это создание мастер-лога. Имя мастер-лога такое же, как имя оригинального файла БД (к которой было открыто соединение) с добавленной строкой вида «-mjHHHHHHHH» («mj» от «master journal»), где HHHHHHHH — случайное 32-битное значение, которое генерируется для каждого нового мастер-лога.
(Этот алгоритм генерации имени файла мастер-лога — лишь деталь реализации SQLite 3.5.0. Он никак не задан в спецификациях и может быть изменён в любой новой версии)
В отличие от логов отката, мастер-лог не содержит никакого оригинального контента страниц из БД. Вместо этого, он содержит полные пути к файлам логов отката для каждой БД, которая участвует в транзакции.
После того, как мастер-лог был составлен, его содержимое сбрасывается на диск. На Unix-системах, директория с мастер-логом также сбрасывается, чтобы убедиться, что мастер-лог появится в этой директории после отказа в питании.

Следующим шагом будет записать полный путь до файла мастер-лога в заголовок каждого лога отката. Место под имя файла мастер-лога в файлах логов отката было отведено заранее, при их создании.
Содержимое каждого лога отката сбрасывается на диск перед и после записи имени мастер-лога в его заголовок. Это важно — чтобы мы сделали именно два сброса данных. К счастью, второй flush обычно недорогой, так как обычно всего одна страница файла лога будет изменена.

Как файлы логов отката были сброшены на диск, мы можем приступать к обновлению файлов баз данных. Нам нужно получить эксклюзивные локи на все файлы, в которые мы собираемся писать изменения. После того, как изменения будут записаны, нужно будет сбросить их на диск.
Этот шаг отражает секции 3.8, 3.9 и 3.10 из однофайлового коммита.
Следующим шагом будет удаление файла мастер-лога. В этот момент транзакцию можно будет считать завершённой. Этот шаг отражает секцию 3.11 из однофайлового коммита, где удаляется лог отката.
Если в этот момент произойдёт отказ питания или какой-то системный сбой, транзакция не будет откачена после восстановления системы, даже если логи отката ещё живы. В их заголовках записано имя файла мастер-лога, а значит они не будут применены, если самого мастер-лога уже не существует.
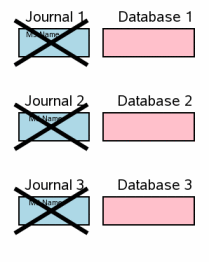
Последним шагом будет удаление каждого из логов отката и сброс эксклюзивных блокировок на файлы баз данных, чтобы другие процессы смогли увидеть сделанные нами изменения.
На этот момент транзакция уже считается завершённой, так что время, затраченное удаление логов не так критично. В нынешней реализации все логи удаляются поочерёдно вместе со снятием локов с соответствующих файлов БД — сначала происходит удаление первого лога, и релиз соответствующего лока, потом второй лог и лок, и так далее. Но в будущем мы возможно изменим это поведение на такое, при котором сначала будет производиться удаление всех логов, а потом снятие всех блокировок. Главное, чтобы удаление логов происходило перед релизом блокировок, а не после.
В секции 3.0 представлен обзор того, как происходит атомарный коммит в SQLite, но там опущено несколько важных деталей. В последующих подразделах мы попытаемся заполнить эти пробелы.
Когда оригинальные данные записываются в лог отката, SQLite всегда пишет полные сектора, даже если размер страницы меньше чем размер сектора. Так исторически сложилось, что размер сектора был захардкожен в коде SQLite как 512 байт и, так как минимальный размер страницы также 512 байт, это никогда не было проблемой. Но начиная с версии SQLite 3.3.14 он умеет работать с секторами большего размера. Так что начиная с этой версии, когда какая-нибудь страница записывается в лог отката, то вместе с ней может записаться и другая страница, попавшая в тот же сектор на диске.
Важно залогировать все страницы, находящиеся на нужном секторе, чтобы предотвратить сценарий с внезапной потерей энергии во время записи сектора. Предположим, что страницы 1, 2, 3 и 4 все хранятся в секторе 1, и что страница 2 изменена. Чтобы записать изменения в страницу 2, файловая система должна будет также переписать содержимое страниц 1, 3 и 4, так как она оперирует целыми секторами. Если эта операция записи будет прервана потерей энергии, любая из страниц 1, 3 или 4 может остаться с некорректными данными. Поэтому, чтобы избежать подобного сценария, нужно сохранить все эти страницы в лог отката.
Когда данные записываются в файл лога отката, SQLite предполагает, что файл сначала заполняется «случайными» данными (данными, которые раньше были на этом месте, до увеличения размера файла и захвата им этой части диска), а потом только их заменяют корректные данные. Другими словами, SQLite предполагает, что сначала увеличивается размер файла (аллоцируется (извините, распределяется) пространство под него), а потом только в него пишутся данные. Если произойдёт отказ питания после изменения размера файла, но до записи данных, лог отката будет содержать плохие данные. После восстановления подачи энергии, другой SQLite процесс увидит файл лога отката, который содержит мусор («garbage data») и попытается сделать откат на его основе, таким образом БД будет повреждена.
SQLite применяет две техники борьбы с этой проблемой. Во-первых, SQLite записывает кол-во страниц в заголовке лога отката. Этот номер сначала пишется как ноль. Так что во время попытки отката неполного лога, процесс увидит, что лог не содержит ни одной страницы и откат просто не произойдёт. Перед коммитом, лог отката сбрасывается на диск, и только после этого в нем исправляется кол-во страниц на нужное число. Заголовок лога всегда пишется в отдельный сектор диска, чтобы быть уверенными, что перезапись никак не навредит данным страниц при возникновении неполадок с питанием. Заметьте, что лог сбрасывается на диск дважды: сначала чтобы записать контент страниц, а потом чтобы добавить кол-во страниц в заголовок.
Предыдущий параграф описывает поведение SQLite при флаге
По-умолчанию этот флаг установлен в
Подписи в логах необязательны, если флаг
Процесс коммита в секции 3.0 предполагает, что все изменения уместятся в память перед завершением коммита. Это самый вероятный случай. Но иногда бывает, что набор изменений переполняет память выделенную для пользовательского процесса. В таких случаях кеш должен быть отправлен в БД ещё до завершения транзакции.
В самом начале отправки, БД находится в состоянии как показано в секции 3.6. Изначальные данные были сохранены в лог отката и изменения есть в пользовательской памяти. Чтобы отправить кеш, SQLite проходит через шаги 3.7, 3.8 и 3.9. Лог сброшен на диск, на файл БД получен эксклюзивный лок и все изменения записаны. После этого к логу в конец добавляется ещё один заголовок, и мы возвращаемся к шагу 3.6. Когда транзакция будет завершена, либо если есть ещё данные для записи, мы вернёмся к шагу 3.7, потом 3.9. (шаг 3.8 теперь нам не нужен, так как лок мы не отпускали) (прим. пер.: я сам нифига не понял в этой главе, написано очень странно, если есть идеи — пишите)
Тесты говорят о том, что в большинстве случаев, SQLite тратит большую часть времени в ожидании записи на диск. Соответственно мы должны в первую очередь оптимизировать запись и работу с диском. В этой секции описаны некоторые техники, использованные SQLite в попытках уменьшить кол-во операций I/O до минимума, сохраняя при этом целостность коммита.
В шаге 3.12 видно, что как только совместная блокировка отпускается, весь пользовательский кеш очищается. Это делается, так как, когда вы без совместного лока, другие процессы могут изменить файл БД и сделать ваш пользовательский кеш устаревшим. Следовательно, каждая новая транзакция будет начинаться с чтения данных из БД. Это не так плохо, как может показаться, так как эти данные скорее всего все ещё находятся в дисковом кеше операционной системы, так что это будет лишь копия данных из памяти ОСи. Но тем не менее, это занимает время.
Начиная с версии 3.3.14, был добавлен механизм, уменьшающий вероятность того, что данные нужно будет читать заново. Данные в пользовательском кеше остаются после транзакции, а перед следующей транзакцией, SQLite смотрит, был ли как-то изменён файл БД. Если да, то пользовательский кеш сбрасывается. Но зачастую в этот момент файл будет находится в прежнем состоянии, так что мы избежим лишних операций чтения.
Чтобы определить изменился ли файл БД или нет, SQLite использует счётчик в заголовке БД (с 24 по 27 байты), который инкрементируется после каждой операции изменения файла. Пользовательский SQLite-процесс сохраняет у себя состояние счётчика перед завершением транзакции. Потом, после получения лока на БД, он сравнивает счётчик с тем, что был до первой транзакции и, если значения различаются, сбрасывает кеш.
SQLite 3.3.14 получил новую фичу, под назнванием «Exclusive Access Mode». В этом режиме, SQLite сохраняет эксклюзивный лок на файл БД после транзакции. Это предотвращает БД от доступа другими процессами, но в большинстве случаев использования SQLite, в один момент времени всего один процесс использует БД, так что это не проблема. Таким образом кол-во дисковых операций может быть снижено засчет:
Часть третей оптимизации, зануление заголовка лога вместо удаления файла, на самом деле требует exclusive access mode, она может быть включена с помощью директивы
Когда информация удаляется из SQLite БД, страницы, которые содержали удалённую информацию, добавляются во «freelist». Последующие вставки просто перезапишут эти страницы в файле БД, без надобности расширения файла в размерах.
Некоторые freelist-страницы содержат важную информацию, если быть точнее — места расположения других freelist-страниц. Но большинство из них не содержит ничего важного. Те страницы, которые не являются критичными, называются «листовыми» страницами. Мы свободны изменять их содержимое, при этом состояние БД никак не изменится.
Так как содержимое листовых страниц такое незначимое, SQLite избегает их сохранения в логи отката на шаге 3.5 процесса коммита. Если листовая страница изменена и это изменение не откатится во время восстановления, БД не будет никак повреждена от этого.
Начиная с версии SQLite 3.5.0, новый интерфейс виртуальной файловой системы (VFS) содержит метод
SQLite по-умолчанию предполагает, что диск производит линейную запись, а не атомарную. Линейная запись начинается с одного конца сектора и, байт за байтом, доходит до его другого конца. Если произойдёт отказ питания во время записи, тогда часть сектора может оказаться повреждённой (содержать старые данные). В атомарной записи секторов, либо весь сектор будет перезаписан, либо весь сектор останется в прежнем состоянии.
Большинство современных дисков поддерживают атомарную запись секторов. Когда происходит потеря питания, диск использует энергию, сохранённую в его конденсаторах и/или энергию вращения блина, чтобы завершить все запланированные задания записи. Тем не менее, между системным вызовом на запись и электроникой самого диска так много слоёв, что мы решили на всех платформах делать пессимистичное предположение, что сектора пишутся линейно.
Когда же запись секторов атомарна, и размер страницы БД равен размеру сектора, то в случае надобности изменения всего одной страницы, SQLite и вовсе пропустит процесс логирования, вместо этого просто записав изменения напрямую в файл базы данных. А счётчик изменений будет инкрементирован отдельно, так как отключение энергии никакого вреда здесь не нанесёт, даже если произойдёт до изменения счётчика.
Ещё одна оптимизация, которую представили в версии 3.5.0, использует дисковую фичу safe append. Как вы помните, обычно SQLite предполагает, что когда дописывается новый кусок данных к файлу, сперва увеличивается его размер, а потом только записываются данные. Так что если диск лишится энергии между этими событиями, то файл в итоге будет содержать битые данные в конце. Один из методов в
Со включенным safe append, SQLite оставляет кол-во страниц в заголовке лога отката равным -1. Когда в логе встречается -1, процесс понимает, что кол-во страниц нужно рассчитать из размера лога. Благодаря этому мы экономим одну операцию flush.
На многих системах удаление файла — это довольно дорогая операция. Так что в SQLite можно отключить удаление логов. Вместо этого можно либо обрезать файл до нулевой длины, либо заполнить нулями заголовок. Обрезание файла выгодней, так как тогда не нужно трогать директорию в которой он содержится, ведь сам файл в таком случае останется на месте. Перезапись заголовка, с другой стороны, позволяет не трогать длину файла (в inode этого файла) и не тратить время на деаллокацию только что освободившихся секторов на диске. Тогда, на следующей транзакции лог будет создан в уже существующем файле, перезаписав его, это также будет быстрее, чем дозапись (appending).
SQLite будет придерживаться данной стратегии, если вы выставите опцию
Использование этого режима обычно даёт заметный прирост производительности на большинстве систем. Конечно есть и минус — логи остаются на диске и съедают место. Единственный безопасный способ удалить такие логи будет коммит транзакции с режимом логирования
Если же попытаться удалить файлы вручную, можно попасть в ситуацию, когда логи ещё принадлежат незавершённой транзакции.
Начиная с версии 3.6.4, также поддерживается режим
В данном режиме размер файла лога будет обрезаться до нуля байт. Эта стратегия также хороша тем, что директория, в которой хранится файл, не будет затронута. Так что, зачастую, обрезание файла быстрее чем удаление. Так же,
На встроенных системах с синхронной файловой системой TRUNCATE обычно работает медленней, чем PERSIST. Первый коммит такой же по скорости, а вот последующие транзакции медленней, так как перезапись данных быстрее чем дописывание в конец файла. Новые логи всегда будут дописываться после TRUNCATE-а, в то время как с персистентной стратегией они будут перезаписывать старые.
Разработчики SQLite уверены, что эта система надёжна перед лицом отказа питания и различных системных сбоев. Автоматические процедуры тестирования проверяют SQLite на способность восстановления после симулированных сбоев. Мы называем это «креш тесты».
Креш тесты для SQLite используют свою VFS, которая способна симулировать различные виды повреждений файловой системы, которые обычно случаются после потери питания или каких-либо системных сбоев. Мы симулируем недописанные сектора, страницы заполненные «мусорными» данными из-за незавершённой операции записи в случайном порядке. Креш тесты прогоняют транзакции одну за одной, изменяя различные переменные — время когда происходит повреждение, типы повреждений, и т. д. Затем каждый тест открывает новое соединение с базой и проверяет чтобы транзакция была либо завершена полностью либо не завершена вообще, и что база данных находится в консистентном состоянии.
Механизм атомарного коммита в SQLite довольно надёжный, но он может быть сломан, если нижележащие слои будут неправильно делать то, что должны. В этой секции описано несколько возможных сценариев, в которых БД может быть повреждена благодаря системному сбою или отказу питания.
SQLite использует блокировки на файлах, чтобы убедиться, что только один процесс имеет возможность изменять базу данных в один момент времени. Механизм блокировок, реализован на уровне VFS и различается между разными операционными системами. SQLite зависит от этих имплементаций, и если что-то пойдёт не так на их уровне и два или более процесса смогут осуществить запись в файл БД, то это может вылиться в повреждение базы данных.
Мы получали баг-репорты на виндовые сетевые файловые системы и на NFS, в которых блокировки не работали как надо. Мы не можем подтвердить эти репорты, но так как блокировки довольно сложно реализовать на сетевой файловой системе, у нас нет причин сомневаться в том, что эти баги правда существуют. Мы вам советуем не использовать SQLite поверх сетевых файловых систем хотя бы из-за больших потерь в производительности.
Та версия SQLite, которая идёт предустановленной на Max OS X уже имеет возможность использовать альтернативные стратегии для блокировок, которые работают со всеми сетевыми ФС, что поддерживает Apple. Эти стратегии работают отлично, если все процессы, что используют файл БД используют одну и ту же стратегию. К сожалению, механизмы (реализации) блокировок не исключают друг друга, так что если один процесс использует AFP блокировки на том же файле, на котором другой процесс использует dot-file блокировки (ага, тавтология), тогда они могут одновременно произвести запись в один файл, так как эти стратегии не взаимоисключаемы.
SQLite использует системный вызов
На Mac вы можете выставить
SQLite предполагает, что удаление файла — это атомарная операция с точки зрения пользовательского процесса. Если происходит потеря энергии во время удаления файла, SQLite ожидает что файл либо сохранится полностью, либо будет удалён. Транзакции не могут считаться атомарными на системах, которые работают иначе.
База данных SQLite лежит в обычных файлах на диске, которые могут быть открыты другими процессами и изменены. Любой процесс может открыть файл БД и заполнить его «плохими» данными. SQLite ничего не может сделать, чтобы защититься от подобного вмешательства.
Если произошёл сбой во время транзакции, и горячий лог был сохранён на диске, важно чтобы файл БД и лог оставались на диске с их оригинальными именами, пока транзакция не будет откачена. В процессе восстановления SQLite находит файл лога в директории с файлом БД, используя имя того самого файла БД. Если файл БД или файл лога был перемещен или переименован, тогда процесс не увидит лог и БД не откатится.
Пользователь может удалить файл горячего лога после восстановления питания, тогда, опять же, база данных не будет восстановлена и будет в повреждённом состоянии.
Если на файл БД созданы символьные (либо жёсткие) ссылки, тогда лог будет назван исходя из названия ссылки, через которую была открыта БД. Если происходит креш и БД будет открыта через другую ссылку (либо через оригинальный файл), то горячий лог не будет подцеплен и вы будете работать с повреждённой базой.
Иногда отказ питания может вызвать такую ситуацию, когда только что изменённые файлы пропадут и окажутся в
3.0 Однофайловый коммит
Мы начнём с обзора шагов, которые SQLite предпринимает, чтобы совершить атомарный коммит транзакции, которая затрагивает только один файл базы данных. Детали формата файлов, которые используются для защиты от повреждения БД и техники, которые применяются для коммита в несколько БД будут показаны ниже.
3.1 Начальное состояние
Состояние системы, когда соединение с БД только что было поднято, поверхностно изображено на рисунке справа. Справа показана информация, которая хранится на энерго-независимом носителе. Каждый прямоугольник — это сектор. Синий цвет говорит о том, что этот сектор содержит оригинальные данные. Посередине изображён дисковый кеш операционной системы. В самом начале нашего примера кеш холодный, это изображено белым цветом. На левой части рисунка — содержимое оперативной памяти процесса, который использует SQLite. Соединение с БД только что было открыто, и никакой информации прочитано не было.
3.2 Получение блокировки для чтения
Перед тем, как SQLite сможет начать запись, он сначала должен узнать, что там уже есть. Даже если это просто вставка новых данных, ему нужно прочитать схему из таблицы sqlite_master, чтобы он знал, как распарсить INSERT-запрос и понять, куда конкретно писать данные.
Первый шаг заключается в получении совместной блокировки (shared lock) на файл базы данных. Совместная блокировка разрешает двум, или более, коннектам читать из файла в одно и то же время. Но такой вид блокировки запрещает другим соединениям производить запись, пока она не снята. Это обязательно, так как если бы другое соединение производило запись в это же время, мы бы могли прочитать часть неизмененных данных и другую часть данных уже после изменения. Тогда запись можно было бы считать неатомарной.
Заметьте, что блокировка была установлена на дисковом кеше ОСи, а не на самом диске. Файловые блокировки — обычно просто флаги, управляемые ядром системы. Они сбросятся при любом креше системы или отказе питания. Так же они обычно сбрасываются, когда процесс, получивший блокировку, умирает.
3.3 Чтение информации из базы данных
После того, как блокировка была получена, мы можем начать чтение из файла базы данных. В данном сценарии, мы подразумеваем, что кеш ещё не прогрет, так что информация должна быть сначала прочитана с накопителя данных в кеш операционной системы, а потом может быть перемещена из кеша ОСи в юзер-спейс. На последующих чтениях вся или некоторая информация уже будет находится в кеше, так что ее нужно будет только отдать в юзер-спейс.
Обычно из файла БД будет прочитана только малая часть страниц. В нашем примере мы видим, что из восьми страниц всего три были прочитаны. В типичном приложении БД будет содержать тысячи страниц и запрос затронет очень малый процент из них.
3.4 Получение «резервирующей» блокировки
Перед тем, как делать какие-то изменения в БД, SQLite сначала получает «резервирующую» блокировку (reserved lock) на файл БД (прим. пер. — это самый сносный перевод, который пришёл мне в голову). Такая блокировка похожа на совместную тем, что она тоже разрешает другим процессам читать из файла БД. Одна резервирующая блокировка может сосуществовать с несколькими совместными. Тем не менее, в один момент времени может существовать только одна резервирующая блокировка на файл. Таким образом только один процесс может писать в БД в один момент времени.
Идея резервирующего лока состоит в том, что он говорит о намерении процесса начать запись в файл в ближайшем будущем, но пока он этого делать ещё не начал. И, так как изменения ещё не начали писаться, другие процессы могут продолжить чтение из БД. Но никакие процессы больше не смогут инициировать запись, пока блокировка жива.
3.5 Создание лога отката
Перед тем, как начать запись в файл базы данных, SQLite сначала создаёт отдельный лог для отката изменений, и пишет в него оригинальные страницы БД, которые будут изменены. Лог отката содержит всю нужную информацию, чтобы откатить БД в оригинальное состояние до транзакции.
Лог отката содержит маленький заголовок (показан зелёным на диаграмме), который содержит размер файла БД в оригинальном состоянии. Так что, если после изменения файл БД вырастет в размере, мы все же будем знать его изначальный размер. Номер страницы хранится рядом с каждой страницей в логе.
Когда новый файл создан, большинство операционных систем (Windows, Linux, Mac OS X) ничего на самом деле не напишут на диск. Новый файл создаётся только в кеше операционной системы. Файл не создаётся на накопителе до тех пор, пока операционная система не найдёт для этого подходящее время. Это создаёт видимость для пользователя, будто операции ввода-вывода на накопителе совершаются гораздо быстрее, чем это возможно. Мы изобразили этот процесс на диаграмме справа, показав, что лог отката появился только в дисковом кеше, но не на самом диске.
3.6 Изменение страниц БД в юзер-спейсе
После того, как оригинальный контент был сохранен в лог отката, страницы могут быть изменены в пользовательской памяти. Каждое соединение с БД имеет собственную приватную копию юзер-спейса, так что изменения, сделанные в юзер-спейсе видны только данному соединению. Другие соединения до сих пор видят информацию из дискового кеша, которая ещё не была изменена. Так что, даже не смотря на то, что один процесс занимается изменением данных в БД, другие процессы могут продолжить чтение собственных копий оригинального контента.
3.7 Сброс лога отката на накопитель
Следующим шагом будет сброс лога отката (rollback journal) из кеша на энерго-независимую память. Как мы увидим позже, это очень важный шаг, который даёт нам гарантию сохранности данных при отказе питания. Этот шаг также требует много времени, так как запись на энерго-независимую память — это, обычно, медленная операция.
Этот шаг обычно более сложен, нежели просто сброс лога на диск. На большинстве платформ нужно делать два flush-а (или fsync-а). Первый flush пишет основное содержимое лога. Потом заголовок лога изменяется, чтобы отразить в нем кол-во страниц в логе. После этого заголовок сбрасывается на диск. Объяснения, почему нам это нужно будут даны ниже.
3.8 Получение эксклюзивной блокировки
Перед тем, как сделать изменения в самом файле БД, мы должны сначала получить эксклюзивную блокировку на него. Получение такой блокировки состоит из двух шагов. Сначала SQLite получает блокировку «в ожидании» (pending lock). Потом этот лок переводится в эксклюзивный.
«pending lock» позволяет другим процессам, которые уже имеют совместную блокировку на файл продолжить чтение из файла. Но он запрещает другим процессам получать новые совместные локи. Это нужно, чтобы не получилась ситуация, когда запись не может быть совершенна, из-за большого и постоянно прибывающего кол-ва запросов на чтение. Каждый процесс сначала получает shared lock перед началом чтения, после чего читает и сбрасывает блокировку. Когда существует множество процессов, постоянно нуждающихся в чтении, может произойти такая ситуация, когда каждый новый процесс получает свой лок до того, как какой-либо из существующих отпустит свой лок. Таким образом никогда не будет существовать момента, когда на файле нет ни единого shared лока, и соответственно не будет возможности получить эксклюзивный лок. Блокировка «в ожидании» нужна, чтобы предотвратить возможность возникновения подобной ситуации, не давая получать новые совместные блокировки на файл, но позволяя дальше жить уже существующим. Когда же все shared локи будут отпущены, то pending lock можно будет перевести в состояние эксклюзивной блокировки.
3.9 Запись данных в файл БД
Когда эксклюзивная блокировка получена, мы можем быть уверены, что больше ни один процесс не совершает запись в этот файл и можно производить в нем изменения. Обычно эти изменения доходят лишь до дискового кеша ОСи и не сбрасываются на сам диск самостоятельно.
3.10 Сброс данных на накопитель
Теперь нужно вызвать flush, чтобы быть уверенными, что все изменения в БД записаны на энерго-независимую память. Это критичный шаг к тому, чтобы данные пережили дальнейшее возможное отключение энергии. Из-за медлительности дисков и флеш-памяти, этот шаг, вместе с записью лога отката (п. 3.7), занимает наибольшую часть времени затраченного на коммит транзакции в SQLite.
3.11 Удаление лога отката
После того, как изменения были сохранены на диск, мы должны удалить лог отката. Это как раз тот момент, когда мы можем сказать, что коммит завершён успешно. Если произойдёт отказ питания или какой-то системный сбой перед удалением, тогда база восстановится в прежнее состояние — до коммита. Если отказ питания произойдёт после удаления лога отката, тогда коммит будет совершён. Таким образом, успешность коммита в SQLite в конечном итоге зависит от того, удалился ли файл с логом для отката, или нет.
Удаление файла это, на самом деле, не совсем атомарная операция, но она выглядит такой с точки зрения пользовательского процесса. Процесс всегда может спросить операционную систему: «Существует ли этот файл?» и он получит в ответ либо «да», либо «нет». После отказа питания, которое произошло во время коммита транзакции, SQLite спросит у операционной системы — существует ли файл с логом отката транзакции. Если да, то транзакция не была совершена и будет откачена. Если ответ был «нет», значит транзакция успешно совершена.
Существование незавершённой транзакции зависит от того, существует ли файл лога отката, а его удаление выглядит как атомарная операция с точки зрения конечного пользователя. Следовательно и транзакция выглядит как атомарная операция.
Удаление файла — дорогая операция на многих системах. В качестве оптимизации, SQLite может обрезать до нуля байт в длине, либо заполнять заголовок нулями. В любом случае, в итоге файл лога уже не будет возможно прочитать для отката и транзакция будет закоммичена. Обрезание файла до нуля в длину, так же как и удаление, предполагается как атомарная операция с точки зрения пользовательского процесса. Перезапись заголовка лога нулями — не атомарна, но если какая-либо часть заголовка повреждена — лог не будет применён для отката. Таким образом, мы можем сказать, что коммит произошёл тогда, когда заголовок лога отката стал невалидным. Обычно это происходит уже тогда, когда лишь первый байт заголовка обнулен.
3.12 Снятие блокировки
Последним шагом коммита будет снятие эксклюзивной блокировки, чтобы остальные процессы снова имели доступ к базе данных.
На рисунке справа мы показали, что информация, которая была в пользовательской памяти, была очищена после снятия блокировки. Это было действительно так в более старых версиях SQLite. Но в более новых версиях SQLite информация сохраняется в юзер-спейсе на случай, если она понадобиться для следующей транзакции. Дешевле использовать данные, которые уже в памяти, вместо получения их из дискового кеша или чтения с самого диска. Перед использованием этих данных, мы должны снова получить shared лок, а также нужно убедиться, что ни один процесс не изменил состояние базы данных, пока у нас не было лока. На самой первой страницы в файле БД есть счётчик, который инкрементируется при каждом изменении. Мы можем узнать, изменилось ли состояние БД, проверив этот счётчик. Если в БД были внесены изменения, тогда пользовательский кеш должен быть очищен и перегрет. Но чаще случается так, что изменений не производилось и пользовательский кеш может быть использован дальше, что даёт хороший прирост в производительности.
4.0 Откат
Атомарный коммит должен совершаться мгновенно. Но все те действия, что были описаны выше, явно занимают какое-то конечное время на выполнение. Предположим, что питание компьютера было отключено на середине процесса коммита, описанного выше. Чтобы поддержать иллюзию мгновенных изменений, мы должны откатить все частичные изменения, которые были совершены и восстановить состояние базы данных в оригинальное.
4.1 Когда что-то идёт не так
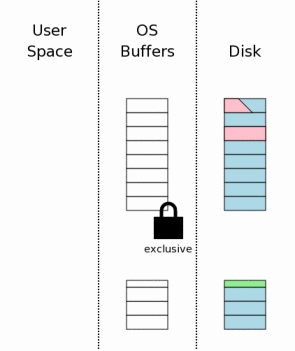
Допустим, что отказ питания произошёл на шаге 3.10, когда изменения записывались на диск. Когда питание будет восстановлено, ситуация будет чем-то похожа на то, что изображено справа на рисунке. Мы пытались изменить три страницы в файле базы данных, но только одна из них была успешно перезаписана на диске. Другая страница частично записаны, а третья и вовсе осталась в оригинальном состоянии.
Лог отката будет целым лежать на диске после восстановления питания. Это ключевой момент. Причина потребности во flush-е на шаге 3.7 заключается в том, чтобы быть абсолютно уверенным, что весь лог отката полностью сохранен на энерго-независимую память перед тем, как будут совершены любые изменения в файле базы данных.
4.2 Горячие логи отката
Когда процесс SQLite впервые пытается получить доступ к файлу БД, он сначала получает совместный лок на него, как это описано в секции 3.2. Но потом он обнаруживает, что существует лог отката. Тогда SQLite проверяет, является ли этот лог «горячим логом отката». Горячий лог — это лог отката, который должен быть применён к БД, чтобы восстановить ее в неповрежденное состояние. Горячий лог существует только тогда, когда какой-то процесс до этого был на каком-то шаге коммита транзакции и, по какой-то причине, упал в этот момент.
Лог отката «горячий», если все условия правдивы:
- Лог отката существует
- Лог отката — не пустой файл
- На файле базы данных нет «reserved» блокировки
- Заголовок файла лога валиден и не был поврежден
- Лог отката не содержит имя файла мастер-лога отката (см. 5.5), или если содержит, то этот файл существует
Наличие горячего лога — это сигнал о том, что предыдущий процесс, пытался закоммитить транзакцию, но провалился по какой-то причине. Горячий лог означает, что файл БД находится в неконсистентном состоянии и должен быть восстановлен перед использованием.
4.3 Получение эксклюзивной блокировки на файл БД
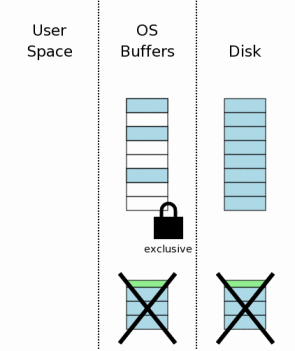
Первый шаг перед работой с горячим логом — получение эксклюзивной блокировки на файл базы данных. Это предотвратит возможность ситуации, когда два или более процесса пытаются применить один и тот же горячий лог в один момент времени.
4.4 Откат неполных изменений
Как только процесс получает эксклюзивный лок, ему разрешается писать в файл базы данных. Тогда он пытается прочесть оригинальный контент страниц из лога отката и записать его назад, в базу. Помните, что в заголовке лога содержится размер файла БД в оригинальном состоянии? SQLite использует эту информацию, чтобы обрезать файл БД до оригинального размера в случаях, когда незавершённая транзакция вызвала рост этого файла. После этого шага, база данных должна быть того же размера и содержать точно те же данные, что были до незавершённой транзакции.
4.5 Удаление горячего лога
После того, как весь лог был применён к файлу БД (а также сброшен на диск на случай ещё одной потери питания), его (лог) можно удалить.
Как и в секции 3.11, файл лога может быть обрезан до нуля байт в длину, либо его заголовок может быть перезаписан нулями. В любом случае, лог больше не «горяч» после этого шага.
4.6 Продолжим, будто незавершённых транзакций и не было
Последний шаг восстановления — сменить эксклюзивный лок на совместный. Когда это случится, база данных будет в таком состоянии, будто откаченной транзакции и не было. Так как весь этот процесс восстановления происходит автоматически и прозрачно для юзера, это выглядит так, будто никакого восстановления не происходило.
5.0 Коммит в несколько файлов
SQLite позволяет с одного соединения говорить с двумя или более базами данных одновременно, используя команду
ATTACH DATABASE. Когда несколько файлов БД изменяются в рамках одной транзакции, все файлы обновляются атомарно. Другими словами — либо все из них обновлены, либо ни один из них не будет обновлён. Достичь атомарного обновления нескольких файлов несколько сложней, нежели всего одного. В данной секции будет описана вся магия, которая за этим кроется.5.1 Отдельный лог отката для каждой базы
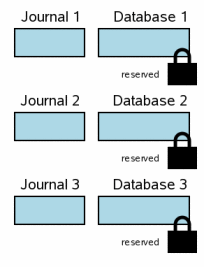
Когда транзакция затрагивает несколько файлов БД, то каждый из этих файлов имеет собственный лог отката и на каждый файл блокировка получается отдельно. На рисунке справа изображена ситуация, когда три разных файла баз данных были изменены в пределах одной транзакции. Ситуация на данном шаге аналогична обычной транзакции над одним файлом из секции 3.6. На каждом файле БД повешена резервирующая блокировка. Для каждой базы данных оригинальное содержимое тех страниц, которые сейчас будут изменены, были записаны в соответствующие логи отката, но эти логи ещё не были сброшены на диск. Файлы базы данных ещё не были изменены, но изменения уже есть в пользовательской памяти процесса.
Для краткости, рисунки в этой секции упрощены относительно тех, что были в других секциях. Голубой цвет все так же означает оригинальную информацию, а розовый — новую. Но отдельные страницы в логах отката файлах БД не показаны, и мы не показываем какая информация уже есть на диске, а какая ещё в системном кеше. Тем не менее все эти факторы все так же существуют и в много-файловой транзакции, но они бы занимали очень много места на диаграммах и не давали бы нам сильно полезной информации, поэтому здесь они опущены.
5.2 Файл мастер-лога
Следующий шаг много-файловой транзакции — это создание мастер-лога. Имя мастер-лога такое же, как имя оригинального файла БД (к которой было открыто соединение) с добавленной строкой вида «-mjHHHHHHHH» («mj» от «master journal»), где HHHHHHHH — случайное 32-битное значение, которое генерируется для каждого нового мастер-лога.(Этот алгоритм генерации имени файла мастер-лога — лишь деталь реализации SQLite 3.5.0. Он никак не задан в спецификациях и может быть изменён в любой новой версии)
В отличие от логов отката, мастер-лог не содержит никакого оригинального контента страниц из БД. Вместо этого, он содержит полные пути к файлам логов отката для каждой БД, которая участвует в транзакции.
После того, как мастер-лог был составлен, его содержимое сбрасывается на диск. На Unix-системах, директория с мастер-логом также сбрасывается, чтобы убедиться, что мастер-лог появится в этой директории после отказа в питании.
5.3 Обновление заголовков логов отката
Следующим шагом будет записать полный путь до файла мастер-лога в заголовок каждого лога отката. Место под имя файла мастер-лога в файлах логов отката было отведено заранее, при их создании.
Содержимое каждого лога отката сбрасывается на диск перед и после записи имени мастер-лога в его заголовок. Это важно — чтобы мы сделали именно два сброса данных. К счастью, второй flush обычно недорогой, так как обычно всего одна страница файла лога будет изменена.
5.4 Обновление файлов баз данных
Как файлы логов отката были сброшены на диск, мы можем приступать к обновлению файлов баз данных. Нам нужно получить эксклюзивные локи на все файлы, в которые мы собираемся писать изменения. После того, как изменения будут записаны, нужно будет сбросить их на диск.
Этот шаг отражает секции 3.8, 3.9 и 3.10 из однофайлового коммита.
5.5 Удаление мастер-лога
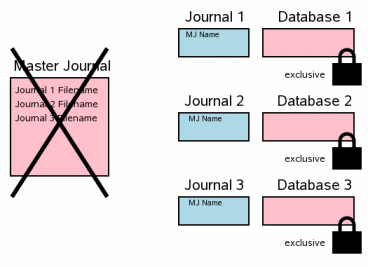
Следующим шагом будет удаление файла мастер-лога. В этот момент транзакцию можно будет считать завершённой. Этот шаг отражает секцию 3.11 из однофайлового коммита, где удаляется лог отката.
Если в этот момент произойдёт отказ питания или какой-то системный сбой, транзакция не будет откачена после восстановления системы, даже если логи отката ещё живы. В их заголовках записано имя файла мастер-лога, а значит они не будут применены, если самого мастер-лога уже не существует.
5.6 Очищение логов отката
Последним шагом будет удаление каждого из логов отката и сброс эксклюзивных блокировок на файлы баз данных, чтобы другие процессы смогли увидеть сделанные нами изменения.
На этот момент транзакция уже считается завершённой, так что время, затраченное удаление логов не так критично. В нынешней реализации все логи удаляются поочерёдно вместе со снятием локов с соответствующих файлов БД — сначала происходит удаление первого лога, и релиз соответствующего лока, потом второй лог и лок, и так далее. Но в будущем мы возможно изменим это поведение на такое, при котором сначала будет производиться удаление всех логов, а потом снятие всех блокировок. Главное, чтобы удаление логов происходило перед релизом блокировок, а не после.
6.0 Дополнительные детали процесса коммита
В секции 3.0 представлен обзор того, как происходит атомарный коммит в SQLite, но там опущено несколько важных деталей. В последующих подразделах мы попытаемся заполнить эти пробелы.
6.1 Логируются всегда целые сектора диска
Когда оригинальные данные записываются в лог отката, SQLite всегда пишет полные сектора, даже если размер страницы меньше чем размер сектора. Так исторически сложилось, что размер сектора был захардкожен в коде SQLite как 512 байт и, так как минимальный размер страницы также 512 байт, это никогда не было проблемой. Но начиная с версии SQLite 3.3.14 он умеет работать с секторами большего размера. Так что начиная с этой версии, когда какая-нибудь страница записывается в лог отката, то вместе с ней может записаться и другая страница, попавшая в тот же сектор на диске.
Важно залогировать все страницы, находящиеся на нужном секторе, чтобы предотвратить сценарий с внезапной потерей энергии во время записи сектора. Предположим, что страницы 1, 2, 3 и 4 все хранятся в секторе 1, и что страница 2 изменена. Чтобы записать изменения в страницу 2, файловая система должна будет также переписать содержимое страниц 1, 3 и 4, так как она оперирует целыми секторами. Если эта операция записи будет прервана потерей энергии, любая из страниц 1, 3 или 4 может остаться с некорректными данными. Поэтому, чтобы избежать подобного сценария, нужно сохранить все эти страницы в лог отката.
6.2 Что делать с плохими данными в логах
Когда данные записываются в файл лога отката, SQLite предполагает, что файл сначала заполняется «случайными» данными (данными, которые раньше были на этом месте, до увеличения размера файла и захвата им этой части диска), а потом только их заменяют корректные данные. Другими словами, SQLite предполагает, что сначала увеличивается размер файла (аллоцируется (извините, распределяется) пространство под него), а потом только в него пишутся данные. Если произойдёт отказ питания после изменения размера файла, но до записи данных, лог отката будет содержать плохие данные. После восстановления подачи энергии, другой SQLite процесс увидит файл лога отката, который содержит мусор («garbage data») и попытается сделать откат на его основе, таким образом БД будет повреждена.
SQLite применяет две техники борьбы с этой проблемой. Во-первых, SQLite записывает кол-во страниц в заголовке лога отката. Этот номер сначала пишется как ноль. Так что во время попытки отката неполного лога, процесс увидит, что лог не содержит ни одной страницы и откат просто не произойдёт. Перед коммитом, лог отката сбрасывается на диск, и только после этого в нем исправляется кол-во страниц на нужное число. Заголовок лога всегда пишется в отдельный сектор диска, чтобы быть уверенными, что перезапись никак не навредит данным страниц при возникновении неполадок с питанием. Заметьте, что лог сбрасывается на диск дважды: сначала чтобы записать контент страниц, а потом чтобы добавить кол-во страниц в заголовок.
Предыдущий параграф описывает поведение SQLite при флаге
PRAGMA synchronous=FULL;По-умолчанию этот флаг установлен в
FULL, если же он установлен в значение NORMAL, SQLite будет сбрасывать лог всего один раз, после записи числа страниц. Это влечёт за собой риск порчи данных, так как может случится так, что кол-во страниц запишется раньше страниц БД. Хоть и данные страниц были отправлены на запись первыми, SQLite предполагает, что файловая система может перестраивать порядок заданий на запись, и соответственно записать кол-во страниц в первую очередь. В качестве ещё одной схемы защиты от этого, SQLite использует 32-битные подписи (хеши) для каждой страницы в логе отката. Если обнаруживается, что какая-то страница в логе не соответствует своей подписи, то откат отменяется.Подписи в логах необязательны, если флаг
synchronous выставлен в FULL. Они нам нужны только если этот флаг имеет значение NORMAL. Тем не менее, они никогда не повредят, так что мы их включаем в логи во всех режимах.6.3 Переполнение кеша во время коммита
Процесс коммита в секции 3.0 предполагает, что все изменения уместятся в память перед завершением коммита. Это самый вероятный случай. Но иногда бывает, что набор изменений переполняет память выделенную для пользовательского процесса. В таких случаях кеш должен быть отправлен в БД ещё до завершения транзакции.
В самом начале отправки, БД находится в состоянии как показано в секции 3.6. Изначальные данные были сохранены в лог отката и изменения есть в пользовательской памяти. Чтобы отправить кеш, SQLite проходит через шаги 3.7, 3.8 и 3.9. Лог сброшен на диск, на файл БД получен эксклюзивный лок и все изменения записаны. После этого к логу в конец добавляется ещё один заголовок, и мы возвращаемся к шагу 3.6. Когда транзакция будет завершена, либо если есть ещё данные для записи, мы вернёмся к шагу 3.7, потом 3.9. (шаг 3.8 теперь нам не нужен, так как лок мы не отпускали) (прим. пер.: я сам нифига не понял в этой главе, написано очень странно, если есть идеи — пишите)
7.0 Оптимизации
Тесты говорят о том, что в большинстве случаев, SQLite тратит большую часть времени в ожидании записи на диск. Соответственно мы должны в первую очередь оптимизировать запись и работу с диском. В этой секции описаны некоторые техники, использованные SQLite в попытках уменьшить кол-во операций I/O до минимума, сохраняя при этом целостность коммита.
7.1 Сохранение кеша между транзакциями
В шаге 3.12 видно, что как только совместная блокировка отпускается, весь пользовательский кеш очищается. Это делается, так как, когда вы без совместного лока, другие процессы могут изменить файл БД и сделать ваш пользовательский кеш устаревшим. Следовательно, каждая новая транзакция будет начинаться с чтения данных из БД. Это не так плохо, как может показаться, так как эти данные скорее всего все ещё находятся в дисковом кеше операционной системы, так что это будет лишь копия данных из памяти ОСи. Но тем не менее, это занимает время.
Начиная с версии 3.3.14, был добавлен механизм, уменьшающий вероятность того, что данные нужно будет читать заново. Данные в пользовательском кеше остаются после транзакции, а перед следующей транзакцией, SQLite смотрит, был ли как-то изменён файл БД. Если да, то пользовательский кеш сбрасывается. Но зачастую в этот момент файл будет находится в прежнем состоянии, так что мы избежим лишних операций чтения.
Чтобы определить изменился ли файл БД или нет, SQLite использует счётчик в заголовке БД (с 24 по 27 байты), который инкрементируется после каждой операции изменения файла. Пользовательский SQLite-процесс сохраняет у себя состояние счётчика перед завершением транзакции. Потом, после получения лока на БД, он сравнивает счётчик с тем, что был до первой транзакции и, если значения различаются, сбрасывает кеш.
7.2 Exclusive Access Mode
SQLite 3.3.14 получил новую фичу, под назнванием «Exclusive Access Mode». В этом режиме, SQLite сохраняет эксклюзивный лок на файл БД после транзакции. Это предотвращает БД от доступа другими процессами, но в большинстве случаев использования SQLite, в один момент времени всего один процесс использует БД, так что это не проблема. Таким образом кол-во дисковых операций может быть снижено засчет:
- Отсутствия надобности инкрементирования счётчика после первой транзакции. Это зачастую сохранит вам операцию записи первой страницы в лог отката и в сам файл БД.
- Другие процессы не могут изменить БД, так что вам не нужно каждый раз проверять вышеупомянутый счётчик и никогда не нужно чистить пользовательский кеш.
- Каждая транзакция может перезаписывать лог предыдущей, заголовок которого был заполнен нулями, вместо удаления файла. Благодаря этому нам не надо трогать саму директорию с файлом лога, а также деаллоцировать дисковые секторы, на которых лежал лог. Таким образом, следующая транзакция просто перезапишет лог предыдущей, вместо создания нового и записи в него данных, ведь в большинстве систем перезапись куда дешевле.
Часть третей оптимизации, зануление заголовка лога вместо удаления файла, на самом деле требует exclusive access mode, она может быть включена с помощью директивы
journal_mode_pragma, как описано в секции 7.6 ниже.7.3 Не логировать freelist страницы
Когда информация удаляется из SQLite БД, страницы, которые содержали удалённую информацию, добавляются во «freelist». Последующие вставки просто перезапишут эти страницы в файле БД, без надобности расширения файла в размерах.
Некоторые freelist-страницы содержат важную информацию, если быть точнее — места расположения других freelist-страниц. Но большинство из них не содержит ничего важного. Те страницы, которые не являются критичными, называются «листовыми» страницами. Мы свободны изменять их содержимое, при этом состояние БД никак не изменится.
Так как содержимое листовых страниц такое незначимое, SQLite избегает их сохранения в логи отката на шаге 3.5 процесса коммита. Если листовая страница изменена и это изменение не откатится во время восстановления, БД не будет никак повреждена от этого.
7.4 Одностраничные изменения и атомарные записи секторов
Начиная с версии SQLite 3.5.0, новый интерфейс виртуальной файловой системы (VFS) содержит метод
xDeviceCharacteristics, который возвращает свойства хранилища (диска). Среди этих свойств есть возможность атомарной записи сектора.SQLite по-умолчанию предполагает, что диск производит линейную запись, а не атомарную. Линейная запись начинается с одного конца сектора и, байт за байтом, доходит до его другого конца. Если произойдёт отказ питания во время записи, тогда часть сектора может оказаться повреждённой (содержать старые данные). В атомарной записи секторов, либо весь сектор будет перезаписан, либо весь сектор останется в прежнем состоянии.
Большинство современных дисков поддерживают атомарную запись секторов. Когда происходит потеря питания, диск использует энергию, сохранённую в его конденсаторах и/или энергию вращения блина, чтобы завершить все запланированные задания записи. Тем не менее, между системным вызовом на запись и электроникой самого диска так много слоёв, что мы решили на всех платформах делать пессимистичное предположение, что сектора пишутся линейно.
Когда же запись секторов атомарна, и размер страницы БД равен размеру сектора, то в случае надобности изменения всего одной страницы, SQLite и вовсе пропустит процесс логирования, вместо этого просто записав изменения напрямую в файл базы данных. А счётчик изменений будет инкрементирован отдельно, так как отключение энергии никакого вреда здесь не нанесёт, даже если произойдёт до изменения счётчика.
7.5 Файловые системы с возможностью safe append
Ещё одна оптимизация, которую представили в версии 3.5.0, использует дисковую фичу safe append. Как вы помните, обычно SQLite предполагает, что когда дописывается новый кусок данных к файлу, сперва увеличивается его размер, а потом только записываются данные. Так что если диск лишится энергии между этими событиями, то файл в итоге будет содержать битые данные в конце. Один из методов в
xDeviceCharacteristics говорит нам о том, умеет ли диск делать safe append. Эта фича реализована так, что диск наоборот сначала запишет данные в «предаллоцированную» область, после чего увеличит размер файла и отдаст ту область этому файлу. Таким образом потеря энергии не страшна даже во время записи (фактически это atomic append).Со включенным safe append, SQLite оставляет кол-во страниц в заголовке лога отката равным -1. Когда в логе встречается -1, процесс понимает, что кол-во страниц нужно рассчитать из размера лога. Благодаря этому мы экономим одну операцию flush.
7.6 Отказ от удаления логов
На многих системах удаление файла — это довольно дорогая операция. Так что в SQLite можно отключить удаление логов. Вместо этого можно либо обрезать файл до нулевой длины, либо заполнить нулями заголовок. Обрезание файла выгодней, так как тогда не нужно трогать директорию в которой он содержится, ведь сам файл в таком случае останется на месте. Перезапись заголовка, с другой стороны, позволяет не трогать длину файла (в inode этого файла) и не тратить время на деаллокацию только что освободившихся секторов на диске. Тогда, на следующей транзакции лог будет создан в уже существующем файле, перезаписав его, это также будет быстрее, чем дозапись (appending).
SQLite будет придерживаться данной стратегии, если вы выставите опцию
journal_mode в PERSIST. (PRAGMA journal_mode=PERSIST)Использование этого режима обычно даёт заметный прирост производительности на большинстве систем. Конечно есть и минус — логи остаются на диске и съедают место. Единственный безопасный способ удалить такие логи будет коммит транзакции с режимом логирования
DELETE:PRAGMA journal_mode=DELETE BEGIN EXCLUSIVE COMMIT;
Если же попытаться удалить файлы вручную, можно попасть в ситуацию, когда логи ещё принадлежат незавершённой транзакции.
Начиная с версии 3.6.4, также поддерживается режим
TRUNCATE:PRAGMA journal_mode=TRUNCATE
В данном режиме размер файла лога будет обрезаться до нуля байт. Эта стратегия также хороша тем, что директория, в которой хранится файл, не будет затронута. Так что, зачастую, обрезание файла быстрее чем удаление. Так же,
TRUNCATE не требует системного вызова для синхронизации состояния на диск (fsync, flush). Но с таким вызовом было бы безопасней. Но на большинстве файловых систем TRUNCATE — это атомарная и синхронная операция, так что скорее всего она будет безопасной, даже при потере энергии. Если вы не уверены, поддерживается ли вашей файловой системой атомарный TRUNCATE, и вам важна целостность данных, то лучше выберите другую стратегию логирования.На встроенных системах с синхронной файловой системой TRUNCATE обычно работает медленней, чем PERSIST. Первый коммит такой же по скорости, а вот последующие транзакции медленней, так как перезапись данных быстрее чем дописывание в конец файла. Новые логи всегда будут дописываться после TRUNCATE-а, в то время как с персистентной стратегией они будут перезаписывать старые.
8.0 Тестирование атомарного коммита
Разработчики SQLite уверены, что эта система надёжна перед лицом отказа питания и различных системных сбоев. Автоматические процедуры тестирования проверяют SQLite на способность восстановления после симулированных сбоев. Мы называем это «креш тесты».
Креш тесты для SQLite используют свою VFS, которая способна симулировать различные виды повреждений файловой системы, которые обычно случаются после потери питания или каких-либо системных сбоев. Мы симулируем недописанные сектора, страницы заполненные «мусорными» данными из-за незавершённой операции записи в случайном порядке. Креш тесты прогоняют транзакции одну за одной, изменяя различные переменные — время когда происходит повреждение, типы повреждений, и т. д. Затем каждый тест открывает новое соединение с базой и проверяет чтобы транзакция была либо завершена полностью либо не завершена вообще, и что база данных находится в консистентном состоянии.
9.0 Что может пойти не так
Механизм атомарного коммита в SQLite довольно надёжный, но он может быть сломан, если нижележащие слои будут неправильно делать то, что должны. В этой секции описано несколько возможных сценариев, в которых БД может быть повреждена благодаря системному сбою или отказу питания.
9.1 Бажные реализации блокировок
SQLite использует блокировки на файлах, чтобы убедиться, что только один процесс имеет возможность изменять базу данных в один момент времени. Механизм блокировок, реализован на уровне VFS и различается между разными операционными системами. SQLite зависит от этих имплементаций, и если что-то пойдёт не так на их уровне и два или более процесса смогут осуществить запись в файл БД, то это может вылиться в повреждение базы данных.
Мы получали баг-репорты на виндовые сетевые файловые системы и на NFS, в которых блокировки не работали как надо. Мы не можем подтвердить эти репорты, но так как блокировки довольно сложно реализовать на сетевой файловой системе, у нас нет причин сомневаться в том, что эти баги правда существуют. Мы вам советуем не использовать SQLite поверх сетевых файловых систем хотя бы из-за больших потерь в производительности.
Та версия SQLite, которая идёт предустановленной на Max OS X уже имеет возможность использовать альтернативные стратегии для блокировок, которые работают со всеми сетевыми ФС, что поддерживает Apple. Эти стратегии работают отлично, если все процессы, что используют файл БД используют одну и ту же стратегию. К сожалению, механизмы (реализации) блокировок не исключают друг друга, так что если один процесс использует AFP блокировки на том же файле, на котором другой процесс использует dot-file блокировки (ага, тавтология), тогда они могут одновременно произвести запись в один файл, так как эти стратегии не взаимоисключаемы.
9.2 Неполные сбросы на диск
SQLite использует системный вызов
fsync на Unix-системах и FlushFileBuffers на win32, чтобы сбросить файл на диск. К сожалению, мы получаем много репортов, связанных с тем, что ни один из этих интерфейсов не работает должным образом на многих системах. FlushFileBuffers может быть полностью отключён в реестре на некоторых версиях Windows. Некоторые версии Linux так же содержат реализации fsync, которые по сути являются заглушками на некоторых файловых системах. Даже в случаях, когда на уровне ОСи все работает как нужно, часто происходит так, что диски врут, говоря что данные достигли магнитного накопителя, когда они, на самом деле, ещё находятся в кеше диска.На Mac вы можете выставить
PRAGMA fillfsync=ON;, что даст гарантию полного сброса данных на блины диска, а не только в дисковый кеш. Но реализация fullfsync-а довольно медленная и будет тормозить и другие операции связанные с диском.9.3 Неполное удаление файла
SQLite предполагает, что удаление файла — это атомарная операция с точки зрения пользовательского процесса. Если происходит потеря энергии во время удаления файла, SQLite ожидает что файл либо сохранится полностью, либо будет удалён. Транзакции не могут считаться атомарными на системах, которые работают иначе.
9.4 Модификация файла БД извне
База данных SQLite лежит в обычных файлах на диске, которые могут быть открыты другими процессами и изменены. Любой процесс может открыть файл БД и заполнить его «плохими» данными. SQLite ничего не может сделать, чтобы защититься от подобного вмешательства.
9.5 Удаление или переименование горячего лога
Если произошёл сбой во время транзакции, и горячий лог был сохранён на диске, важно чтобы файл БД и лог оставались на диске с их оригинальными именами, пока транзакция не будет откачена. В процессе восстановления SQLite находит файл лога в директории с файлом БД, используя имя того самого файла БД. Если файл БД или файл лога был перемещен или переименован, тогда процесс не увидит лог и БД не откатится.
Пользователь может удалить файл горячего лога после восстановления питания, тогда, опять же, база данных не будет восстановлена и будет в повреждённом состоянии.
Если на файл БД созданы символьные (либо жёсткие) ссылки, тогда лог будет назван исходя из названия ссылки, через которую была открыта БД. Если происходит креш и БД будет открыта через другую ссылку (либо через оригинальный файл), то горячий лог не будет подцеплен и вы будете работать с повреждённой базой.
Иногда отказ питания может вызвать такую ситуацию, когда только что изменённые файлы пропадут и окажутся в
/lost+found. Когда такое происходит, горячий лог тоже невозможно найти, и откат не может быть произведён. SQLite пытается предотвратить это синхронизуя (fsync) директорию содержащую лог в тот же момент когда синхронизует и сам лог. Тем не менее, это явление может произойти и из-за совершенно посторонних файлов, которые создаются или изменяются в той же директории, где лежит файл БД. И, так как это не под контролем SQLite, он ничего не может с этим сделать, чтобы предотвратить это. Если вы используете систему, подверженную подобной уязвимости (насколько мы знаем, ей не подвержены большинство современных журналируемых ФС), тогда вам стоит положить каждую SQLite базу данных в отдельную директорию.
