Я хотел бы рассказать о своём опыте создания движка под специализированный сайт, особенностью которого является способность в идеальном случае не задействовать БД вовсе. Мне бы хотелось поделиться своим решением проблемы эпизодической высокой нагрузки и получить обратную связь по аналогичным решениям и улучшениям.
Итак, мне была поставлена задача разработать информационный сайт, основанный на пользовательском контенте — записям из блогов. Над сайтом работает редакция, которая собирает из интернета посты и составляет из них сюжеты, подкрепляя различной релевантной информацией. Специфика сайта такова, что при средней нагрузке в 5-10 тысяч посетителей в сутки в случае возникновения общественно важной темы, где свежую информацию можно почерпнуть именно в блогосфере, трафик на конкретные материалы многократно возрастает (иногда на порядки, как в случае теракта или неожиданного политического решения). Было принято решение: кэшируем самое востребованное. Но давайте вначале определимся с некоторыми допущениями:
Вместе с тем, имеется проблема: структура страниц достаточно сложная и вариативная, чтобы кэшировать её «в лоб». Страница состоит из блоков, часть из которых постоянна, часть зависит от параметров запроса (например, «другие материалы по теме»), а часть вообще не кэшируема (например, поиск по сайту). Чтобы не плодить обилие дублирующих страниц, было принято решение компилировать страницу на основе шаблона и блоков, которые формируются модулями, учитывающими только необходимые параметры.
Посмотрим на структуру шаблона страницы «Тема» (Subject):
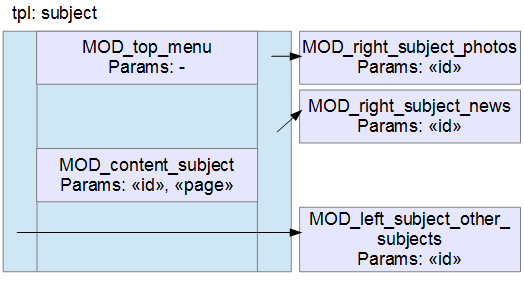
У нас трёхколоночный дизайн. В каждом из столбцов встроены модули. Модуль top_menu не зависит ни от каких параметров, модуль content_subject зависит от ID материала и номера страницы, остальные — только от ID материала.
Теперь посмотрим на структуру модуля, формирующего HTML-код блока:
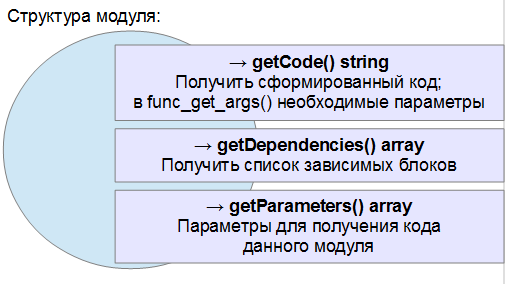
Интерфейс модуля содержит 3 метода, необходимых для работы с системой кэширования:
Движок совершает следующие действия:
На последнем пункте хочу остановиться особо. Среди всего «статического рая», благополучно получаемого из кэша, у нас есть исключения. Это исключения-модули, о которых сказано выше, и которые не кэшируются, но ещё и счётчики просмотра материалов. При вызове такого модуля, как subject_content, генерирующего основную часть страницы-темы, будет увеличиваться число просмотров автоматически и сразу в кэше (cnt,subject,$id), но эти значения активно используются и при оформлении анонсов материалов. Поэтому для них у нас есть специальные маркеры, по которым значения будут забираться из кэша и вставляться «на лету».
Вцелом структура кэша получается следующей:

Причём, порядок «сборки» страницы получается именно такой, как на схеме: в шаблон (tpl) вставляются вызовы кодов, сгенерированные модулями ©, в которые вставлены значения счётчиков (cnt).
Кроме движка на сервере исполняются сценарии, выполняемые из планировщика, — роботы. Не беря в расчёт специфические для сайта функции, упомяну два робота: сбрасывающего значения счётчиков из кэша в базу, и асинхронно обновляющего различную статистику по сайту и блоки типа «популярных материалов». Первый нужен для того, чтобы число просмотров материалов не терялось, а второй — чтобы поддерживать в актуальном состоянии блоки, для которых вычисления должны производиться периодически.
Здесь уже всё гораздо проще. При обновлении/добавлении/удалении материалов производится опрос всех модулей, имеет ли он отношение к данному действию с данной таблицей и данным ID (если есть). Например, при действии update для материала производится сброс только одной индексной страницы, где расположен анонс именно этого материала. Все модули сверят, используют ли они данные из таблицы с переданным именем и если да, то как. В моей реализации блоки со «Свежими статьями» сбрасываются всегда, не проверяя, используется ли конкретный ID материала в этом списке, — соблюдаю баланс технологичности и разумности.
Итак, для всего списка модулей из var,modules выполняется метод getDependencies($tableName, $action, $id=0), а результирующий список блоков на сброс передаётся ядру для установки флажка «устарел». Блоки будут перегенерированы при запросе со стороны фронт-енда (а может быть, что и не будут, если материал лежит глубоко и уже никому не нужен).
Сайт успешно работает с 2010 года и пережил ряд катаклизмов, которые удалось выдержать благодаря архитектуре движка. Однажды у нас сгорели жёсткие диски в рейде, причём, оба сразу. Была дана отмашка редакторам временно прекратить обновление сайта, чтобы не сбросить кэш, и сайт успешно проработал всё то время, пока устанавливались диски и производилось возвращение данных из бэкапа и синхронизация дисков. В другой раз случился теракт в Домодедово и посетители ринулись искать у нас самую актуальную информацию по событию и на соответствующую тему зашло около 70 тысяч посетителей в течение получаса после трагедии. Время выдачи страниц возросло до 10 секунд, но сервер выстоял.
Если интересно посмотреть, как влияет рост посещаемости на расход процессорного времени и памяти, давайте посмотрим на недавний случай, произошедший 25 сентября. Вот что про него говорит Liveinternet.ru:

Рост посещаемости примерно в 7 раз. Как я уже писал выше, как правило, трафик идёт на какие-то отдельные материалы, и данный случай не исключение:
Расход памяти менялся в рамках статистической погрешности:

Про процессорному времени нагрузка слегка ощущалась:

(Два «всплеска» в конце 20-го и 27-го числа связаны с еженедельным полным бэкапом.)
Статистика memcached:
Промахи при чтении: 1 на 60, аптайм 74 суток.
Буду рад услышать вопросы и мнения. Как можно было бы улучшить движок? Сделать более универсальным? Какие есть похожие решения?
Итак, мне была поставлена задача разработать информационный сайт, основанный на пользовательском контенте — записям из блогов. Над сайтом работает редакция, которая собирает из интернета посты и составляет из них сюжеты, подкрепляя различной релевантной информацией. Специфика сайта такова, что при средней нагрузке в 5-10 тысяч посетителей в сутки в случае возникновения общественно важной темы, где свежую информацию можно почерпнуть именно в блогосфере, трафик на конкретные материалы многократно возрастает (иногда на порядки, как в случае теракта или неожиданного политического решения). Было принято решение: кэшируем самое востребованное. Но давайте вначале определимся с некоторыми допущениями:
- Фронт-енд практически статический — материалы поступают в базу через CMS, а пользователь ничего не добавляет и не изменяет. Контент на сайт заносится редко относительно числа просмотров, поэтому CMS имеет право быть более прожорливой, чем фронт-енд;
- В нашем распоряжении всего один слабенький сервер, но имеется возможность добавлять память;
- Объём RAM много больше объёма БД (RAM на начальном этапе 8Гб против нынешних 500 Мб текстовых данных в БД);
- Отдельные материалы имеют десятки и сотни тысяч посещений, в то время как большинство — сотни;
- Мы используем PHP/MySQL/Memcached.
Вместе с тем, имеется проблема: структура страниц достаточно сложная и вариативная, чтобы кэшировать её «в лоб». Страница состоит из блоков, часть из которых постоянна, часть зависит от параметров запроса (например, «другие материалы по теме»), а часть вообще не кэшируема (например, поиск по сайту). Чтобы не плодить обилие дублирующих страниц, было принято решение компилировать страницу на основе шаблона и блоков, которые формируются модулями, учитывающими только необходимые параметры.
Посмотрим на структуру шаблона страницы «Тема» (Subject):
У нас трёхколоночный дизайн. В каждом из столбцов встроены модули. Модуль top_menu не зависит ни от каких параметров, модуль content_subject зависит от ID материала и номера страницы, остальные — только от ID материала.
Теперь посмотрим на структуру модуля, формирующего HTML-код блока:
Интерфейс модуля содержит 3 метода, необходимых для работы с системой кэширования:
- getCode() — занимается генерацией кода для блока и учитывает параметры, передаваемые из ядра;
- getDependencies() — возвращает список зависимостей. Здесь модуль получает: название таблицы в БД, название действия с этой таблицей (add, delete, update) и ID материала в этой таблице (если есть). По ним модуль вычисляет названия зависимых блоков и возвращает их список. Пример: действие по добавлению статьи и возвращение списка всех страниц раздела, чтобы они были помечены как устаревшие ядром движка;
- getParameters() — возвращает массив тех параметров, которые влияют на формирование кода. Он необходим для корректного подключения модулей к шаблонам. Какие-то параметры могут оказаться излишними и мы получили бы многочисленный список дубликатов в Memcache.
Как обрабатывается запрос на отображение
Движок совершает следующие действия:
- Router определяет по URL название действия $action и его параметры. В моей реализации они прописываются жёстко;
- Производится подключение шаблона tpl,$action, соответствующего действию (для удобства их имена совпадают), из кэша (в случае промаха считаем шаблон с диска);
- Получение списка модулей из кэша var,modules (в случае промаха получим список файлов модулей);
- Получение параметров модулей из кэша var,params (в случае промаха для всех модулей выполним метод getParams() );
- Обход шаблона в поисках подключаемых модулей. Найденный модуль проверяется через in_array со списком модулей для предотвращения ошибок. Для каждого модуля:
- Если среди параметров модуля содержится «nocache», сгенерированный блок не будет кэширован;
- Если среди параметров «increment», увеличим счётчик просмотров, который у нас тоже в кэше (если нет, получим из БД);
- Подбираем параметры вызова модуля: те, что заданы, из тех, что требуются;
- Выбираем из кэша или исполняем getCode();
- В найденном коде ищем маркеры счётчиков просмотра материалов, чтоб подставить действующие значения.
На последнем пункте хочу остановиться особо. Среди всего «статического рая», благополучно получаемого из кэша, у нас есть исключения. Это исключения-модули, о которых сказано выше, и которые не кэшируются, но ещё и счётчики просмотра материалов. При вызове такого модуля, как subject_content, генерирующего основную часть страницы-темы, будет увеличиваться число просмотров автоматически и сразу в кэше (cnt,subject,$id), но эти значения активно используются и при оформлении анонсов материалов. Поэтому для них у нас есть специальные маркеры, по которым значения будут забираться из кэша и вставляться «на лету».
Вцелом структура кэша получается следующей:
Причём, порядок «сборки» страницы получается именно такой, как на схеме: в шаблон (tpl) вставляются вызовы кодов, сгенерированные модулями ©, в которые вставлены значения счётчиков (cnt).
Кроме движка на сервере исполняются сценарии, выполняемые из планировщика, — роботы. Не беря в расчёт специфические для сайта функции, упомяну два робота: сбрасывающего значения счётчиков из кэша в базу, и асинхронно обновляющего различную статистику по сайту и блоки типа «популярных материалов». Первый нужен для того, чтобы число просмотров материалов не терялось, а второй — чтобы поддерживать в актуальном состоянии блоки, для которых вычисления должны производиться периодически.
Алгоритм работы CMS
Здесь уже всё гораздо проще. При обновлении/добавлении/удалении материалов производится опрос всех модулей, имеет ли он отношение к данному действию с данной таблицей и данным ID (если есть). Например, при действии update для материала производится сброс только одной индексной страницы, где расположен анонс именно этого материала. Все модули сверят, используют ли они данные из таблицы с переданным именем и если да, то как. В моей реализации блоки со «Свежими статьями» сбрасываются всегда, не проверяя, используется ли конкретный ID материала в этом списке, — соблюдаю баланс технологичности и разумности.
Итак, для всего списка модулей из var,modules выполняется метод getDependencies($tableName, $action, $id=0), а результирующий список блоков на сброс передаётся ядру для установки флажка «устарел». Блоки будут перегенерированы при запросе со стороны фронт-енда (а может быть, что и не будут, если материал лежит глубоко и уже никому не нужен).
Практика использования движка
Сайт успешно работает с 2010 года и пережил ряд катаклизмов, которые удалось выдержать благодаря архитектуре движка. Однажды у нас сгорели жёсткие диски в рейде, причём, оба сразу. Была дана отмашка редакторам временно прекратить обновление сайта, чтобы не сбросить кэш, и сайт успешно проработал всё то время, пока устанавливались диски и производилось возвращение данных из бэкапа и синхронизация дисков. В другой раз случился теракт в Домодедово и посетители ринулись искать у нас самую актуальную информацию по событию и на соответствующую тему зашло около 70 тысяч посетителей в течение получаса после трагедии. Время выдачи страниц возросло до 10 секунд, но сервер выстоял.
Если интересно посмотреть, как влияет рост посещаемости на расход процессорного времени и памяти, давайте посмотрим на недавний случай, произошедший 25 сентября. Вот что про него говорит Liveinternet.ru:
Рост посещаемости примерно в 7 раз. Как я уже писал выше, как правило, трафик идёт на какие-то отдельные материалы, и данный случай не исключение:
Расход памяти менялся в рамках статистической погрешности:
Про процессорному времени нагрузка слегка ощущалась:
(Два «всплеска» в конце 20-го и 27-го числа связаны с еженедельным полным бэкапом.)
Статистика memcached:
[uptime] => 6371668
[get_hits] => 409123948
[get_misses] => 6869860
[incr_misses] => 1259
[incr_hits] => 2476204
[bytes_read] => 13353236827
[bytes_written] => 135590836194
[bytes] => 358927266
[curr_items] => 1246460
[total_items] => 1733562Промахи при чтении: 1 на 60, аптайм 74 суток.
Буду рад услышать вопросы и мнения. Как можно было бы улучшить движок? Сделать более универсальным? Какие есть похожие решения?

