
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
1С показывает любое количество записей в гриде, позволяет мгновенно перемещаться по нему в начало или конец, искать по первым буквам в любой колонке, курсор со строки никуда не девается и не перескакивает.
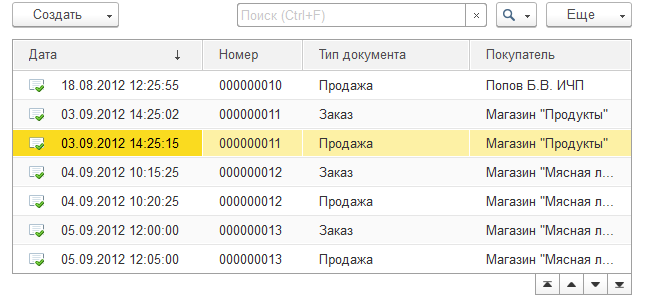
Интерфейс работы с таблицей: быстро/неудобно — медленно/удобно