От переводчика: перед вами краткий обзор протокола HTTP и его истории — от версии 0.9 к версии 2.
HTTP — протокол, пронизывающий веб. Знать его обязан каждый веб-разработчик. Понимание работы HTTP поможет вам делать более качественные веб-приложения.
В этой статье мы обсудим, что такое HTTP, и как он стал именно таким, каким мы видим его сегодня.
Что такое HTTP?
Итак, рассмотрим для начала, что же такое HTTP? HTTP — протокол прикладного уровня, реализованный поверх протокола TCP/IP. HTTP определяет, как взаимодействуют между собой клиент и сервер, как запрашивается и передаётся контент по интернету. Под протоколом прикладного уровня я понимаю, что это лишь абстракция, стандартизующая, как узлы сети (клиенты и серверы) взаимодействуют друг с другом. Сам HTTP зависит от протокола TCP/IP, позволяющего посылать и отправлять запросы между клиентом и сервером. По умолчанию используется 80 порт TCP, но могут использоваться и другие. HTTPS, например, использует 443 порт.
HTTP/0.9 — первый стандарт (1991)
Первой задокументированной версией HTTP стал HTTP/0.9, выпущенный в 1991 году. Это был самый простой протокол на свете, c одним-единственным методом — GET. Если клиенту нужно было получить какую-либо страницу на сервере, он делал запрос:
GET /index.html
А от сервера приходил примерно такой ответ:
(response body) (connection closed)
Вот и всё. Сервер получает запрос, посылает HTML в ответ, и как только весь контент будет передан, закрывает соединение. В HTTP/0.9 нет никаких заголовков, единственный метод — GET, а ответ приходит в HTML.
Итак, HTTP/0.9 стал первым шагом во всей дальнейшей истории.
HTTP/1.0 — 1996
В отличие от HTTP/0.9, спроектированного только для HTML-ответов, HTTP/1.0 справляется и с другими форматами: изображения, видео, текст и другие типы контента. В него добавлены новые методы (такие, как POST и HEAD). Изменился формат запросов/ответов. К запросам и ответам добавились HTTP-заголовки. Добавлены коды состояний, чтобы различать разные ответы сервера. Введена поддержка кодировок. Добавлены составные типы данных (multi-part types), авторизация, кэширование, различные кодировки контента и ещё многое другое.
Вот так выглядели простые запрос и ответ по протоколу HTTP/1.0:
GET / HTTP/1.0 Host: kamranahmed.info User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) Accept: */*
Помимо запроса клиент посылал персональную информацию, требуемый тип ответа и т.д. В HTTP/0.9 клиент не послал бы такую информацию, поскольку заголовков попросту не существовало.
Пример ответа на подобный запрос:
HTTP/1.0 200 OK Content-Type: text/plain Content-Length: 137582 Expires: Thu, 05 Dec 1997 16:00:00 GMT Last-Modified: Wed, 5 August 1996 15:55:28 GMT Server: Apache 0.84 (response body) (connection closed)
В начале ответа стоит HTTP/1.0 (HTTP и номер версии), затем код состояния — 200, затем — описание кода состояния.
В новой версии заголовки запросов и ответов были закодированы в ASCII (HTTP/0.9 весь был закодирован в ASCII), а вот тело ответа могло быть любого контентного типа — изображением, видео, HTML, обычным текстом и т. п. Теперь сервер мог послать любой тип контента клиенту, поэтому словосочетание «Hyper Text» в аббревиатуре HTTP стало искажением. HMTP, или Hypermedia Transfer Protocol, пожалуй, стало бы более уместным названием, но все к тому времени уже привыкли к HTTP.
Один из главных недостатков HTTP/1.0 — то, что вы не можете послать несколько запросов во время одного соединения. Если клиенту надо что-либо получить от сервера, ему нужно открыть новое TCP-соединение, и, как только запрос будет выполнен, это соединение закроется. Для каждого следующего запроса нужно создавать новое соединение.
Почему это плохо? Давайте предположим, что вы открываете страницу, содержащую 10 изображений, 5 файлов стилей и 5 JavaScript файлов. В общей сложности при запросе к этой странице вам нужно получить 20 ресурсов — а это значит, что серверу придётся создать 20 отдельных соединений. Такое число соединений значительно сказывается на производительности, поскольку каждое новое TCP-соединение требует «тройного рукопожатия», за которым следует медленный старт.
Тройное рукопожатие
«Тройное рукопожатие» — это обмен последовательностью пакетов между клиентом и сервером, позволяющий установить TCP-соединение для начала передачи данных.
- SYN — Клиент генерирует случайное число, например, x, и отправляет его на сервер.
- SYN ACK — Сервер подтверждает этот запрос, посылая обратно пакет ACK, состоящий из случайного числа, выбранного сервером (допустим, y), и числа x + 1, где x — число, пришедшее от клиента.
- ACK — клиент увеличивает число y, полученное от сервера и посылает y + 1 на сервер.
Примечание переводчика: SYN — синхронизация номеров последовательности, (англ. Synchronize sequence numbers). ACK — поле «Номер подтверждения» задействовано (англ. Acknowledgement field is significant).

Только после завершения тройного рукопожатия начинается передача данных между клиентом и сервером. Стоит заметить, что клиент может посылать данные сразу же после отправки последнего ACK-пакета, однако сервер всё равно ожидает ACK-пакет, чтобы выполнить запрос.
Тем не менее, некоторые реализации HTTP/1.0 старались преодолеть эту проблему, добавив новый заголовок Connection: keep-alive, который говорил бы серверу «Эй, дружище, не закрывай это соединение, оно нам ещё пригодится». Однако эта возможность не была широко распространена, поэтому проблема оставалась актуальна.
Помимо того, что HTTP — протокол без установления соединения, в нём также не предусмотрена поддержка состояний. Иными словами, сервер не хранит информации о клиенте, поэтому каждому запросу приходится включать в себя всю необходимую серверу информацию, без учёта прошлых запросов. И это только подливает масла в огонь: помимо огромного числа соединений, которые открывает клиент, он также посылает повторяющиеся данные, излишне перегружая сеть.
HTTP/1.1 – 1999
Прошло 3 года со времён HTTP/1.0, и в 1999 вышла новая версия протокола — HTTP/1.1, включающая множество улучшений:
- Новые HTTP-методы — PUT, PATCH, HEAD, OPTIONS, DELETE.
- Идентификация хостов. В HTTP/1.0 заголовок Host не был обязательным, а HTTP/1.1 сделал его таковым.
- Постоянные соединения. Как говорилось выше, в HTTP/1.0 одно соединение обрабатывало лишь один запрос и после этого сразу закрывалось, что вызывало серьёзные проблемы с производительностью и проблемы с задержками. В HTTP/1.1 появились постоянные соединения, т.е. соединения, которые по умолчанию не закрывались, оставаясь открытыми для нескольких последовательных запросов. Чтобы закрыть соединение, нужно было при запросе добавить заголовок Connection: close. Клиенты обычно посылали этот заголовок в последнем запросе к серверу, чтобы безопасно закрыть соединение.
- Потоковая передача данных, при которой клиент может в рамках соединения посылать множественные запросы к серверу, не ожидая ответов, а сервер посылает ответы в той же последовательности, в которой получены запросы. Но, вы можете спросить, как же клиент узнает, когда закончится один ответ и начнётся другой? Для разрешения этой задачи устанавливается заголовок Content-Length, с помощью которого клиент определяет, где заканчивается один ответ и можно ожидать следующий.
Замечу, что для того, чтобы ощутить пользу постоянных соединений или потоковой передачи данных, заголовок Content-Length должен быть доступен в ответе. Это позволит клиенту понять, когда завершится передача и можно будет отправить следующий запрос (в случае обычных последовательных запросов) или начинать ожидание следующего ответа (в случае потоковой передачи).
Но в таком подходе по-прежнему оставались проблемы. Что, если данные динамичны, и сервер не может перед отправкой узнать длину контента? Получается, в этом случае мы не можем пользоваться постоянными соединениями? Чтобы разрешить эту задачу, HTTP/1.1 ввёл сhunked encoding — механизм разбиения информации на небольшие части (chunks) и их передачу.
- Chunked Transfers если контент строится динамически и сервер в начале передачи не может определить Content-Length, он начинает отсылать контент частями, друг за другом, и добавлять Content-Length к каждой передаваемой части. Когда все части отправлены, посылается пустой пакет с заголовком Content-Length, установленным в 0, сигнализируя клиенту, что передача завершена. Чтобы сказать клиенту, что передача будет вестись по частям, сервер добавляет заголовок Transfer-Encoding: chunked.
- В отличие от базовой аутентификации в HTTP/1.0, в HTTP/1.1 добавились дайджест-аутентификация и прокси-аутентификация.
- Кэширование.
- Диапазоны байт (byte ranges).
- Кодировки
- Согласование содержимого (content negotiation).
- Клиентские куки.
- Улучшенная поддержка сжатия.
- И другие...
Особенности HTTP/1.1 — отдельная тема для разговора, и в этой статье я не буду задерживаться на ней надолго. Вы можете найти огромное количество материалов по этой теме. Рекомендую к прочтению Key differences between HTTP/1.0 and HTTP/1.1 и, для супергероев, ссылку на RFC.
HTTP/1.1 появился в 1999 и пробыл стандартом долгие годы. И, хотя он и был намного лучше своего предшественника, со временем начал устаревать. Веб постоянно растёт и меняется, и с каждым днём загрузка веб-страниц требует всё больших ресурсов. Сегодня стандартной веб-странице приходится открывать более 30 соединений. Вы скажете: «Но… ведь… в HTTP/1.1 существуют постоянные соединения…». Однако, дело в том, что HTTP/1.1 поддерживает лишь одно внешнее соединение в любой момент времени. HTTP/1.1 пытался исправить это потоковой передачей данных, однако это не решало задачу полностью. Возникала проблема блокировки начала очереди (head-of-line blocking) — когда медленный или большой запрос блокировал все последующие (ведь они выполнялись в порядке очереди). Чтобы преодолеть эти недостатки HTTP/1.1, разработчики изобретали обходные пути. Примером тому служат спрайты, закодированные в CSS изображения, конкатенация CSS и JS файлов, доменное шардирование и другие.
SPDY — 2009
Google пошёл дальше и стал экспериментировать с альтернативными протоколами, поставив цель сделать веб быстрее и улучшить уровень безопасности за счёт уменьшения времени задержек веб-страниц. В 2009 году они представили протокол SPDY.
Казалось, что если мы будем продолжать увеличивать пропускную способность сети, увеличится её производительность. Однако выяснилось, что с определенного момента рост пропускной способности перестаёт влиять на производительность. С другой стороны, если оперировать величиной задержки, то есть уменьшать время отклика, прирост производительности будет постоянным. В этом и заключалась основная идея SPDY.
Следует пояснить, в чём разница: время задержки — величина, показывающая, сколько времени займёт передача данных от отправителя к получателю (в миллисекундах), а пропускная способность — количество данных, переданных в секунду (бит в секунду).
SPDY включал в себя мультиплексирование, сжатие, приоритизацию, безопасность и т.д… Я не хочу погружаться в рассказ про SPDY, поскольку в следующем разделе мы разберём типичные свойства HTTP/2, а HTTP/2 многое перенял от SPDY.
SPDY не старался заменить собой HTTP. Он был переходным уровнем над HTTP, существовавшим на прикладном уровне, и изменял запрос перед его отправкой по проводам. Он начал становиться стандартом дефакто, и большинство браузеров стали его поддерживать.
В 2015 в Google решили, что не должно быть двух конкурирующих стандартов, и объединили SPDY с HTTP, дав начало HTTP/2.
HTTP/2 — 2015
Думаю, вы уже убедились, что нам нужна новая версия HTTP-протокола. HTTP/2 разрабатывался для транспортировки контента с низким временем задержки. Главные отличия от HTTP/1.1:
- бинарный вместо текстового
- мультиплексирование — передача нескольких асинхронных HTTP-запросов по одному TCP-соединению
- сжатие заголовков методом HPACK
- Server Push — несколько ответов на один запрос
- приоритизация запросов
- безопасность
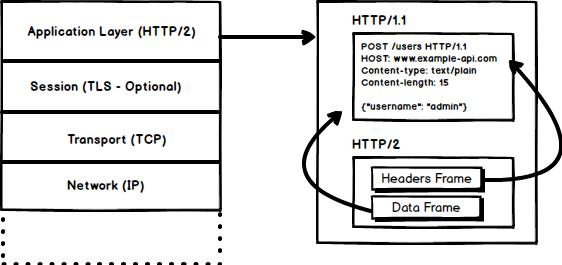
1. Бинарный протокол
HTTP/2 пытается решить проблему выросшей задержки, существовавшую в HTTP/1.x, переходом на бинарный формат. Бинарные сообщения быстрее разбираются автоматически, но, в отличие от HTTP/1.x, не удобны для чтения человеком. Основные составляющие HTTP/2 — фреймы (Frames) и потоки (Streams).
Фреймы и потоки.
Сейчас HTTP-сообщения состоят из одного или более фреймов. Для метаданных используется фрейм HEADERS, для основных данных — фрейм DATA, и ещё существуют другие типы фреймов (RST_STREAM, SETTINGS, PRIORITY и т.д.), с которыми можно ознакомиться в спецификации HTTP/2.
Каждый запрос и ответ HTTP/2 получает уникальный идентификатор потока и разделяется на фреймы. Фреймы представляют собой просто бинарные части данных. Коллекция фреймов называется потоком (Stream). Каждый фрейм содержит идентификатор потока, показывающий, к какому потоку он принадлежит, а также каждый фрейм содержит общий заголовок. Также, помимо того, что идентификатор потока уникален, стоит упомянуть, что каждый клиентский запрос использует нечётные id, а ответ от сервера — чётные.
Помимо HEADERS и DATA, стоит упомянуть ещё и RST_STREAM — специальный тип фреймов, использующийся для прерывания потоков. Клиент может послать этот фрейм серверу, сигнализируя, что данный поток ему больше не нужен. В HTTP/1.1 единственным способом заставить сервер перестать посылать ответы было закрытие соединения, что увеличивало время задержки, ведь нужно было открыть новое соединение для любых дальнейших запросов. А в HTTP/2 клиент может отправить RST_STREAM и перестать получать определённый поток. При этом соединение останется открытым, что позволяет работать остальным потокам.
2. Мультиплексирование
Поскольку HTTP/2 является бинарным протоколом, использующим для запросов и ответов фреймы и потоки, как было упомянуто выше, все потоки посылаются в едином TCP-соединении, без создания дополнительных. Сервер, в свою очередь, отвечает аналогичным асинхронным образом. Это значит, что ответ не имеет порядка, и клиент использует идентификатор потока, чтобы понять, к какому потоку принадлежит тот или иной пакет. Это решает проблему блокировки начала очереди (head-of-line blocking) — клиенту не придётся простаивать, ожидая обработки длинного запроса, ведь во время ожидания могут обрабатываться остальные запросы.
3. Сжатие заголовков методом HPACK
Это было частью отдельного RFC, специально нацеленного на оптимизацию отправляемых заголовков. В основе лежало то, что если мы постоянного обращаемся к серверу из одного и того же клиента, то в заголовках раз за разом посылается огромное количество повторяющихся данных. А иногда к этому добавляются ещё и куки, раздувающие размер заголовков, что снижает пропускную способность сети и увеличивает время задержки. Чтобы решить эту проблему, в HTTP/2 появилось сжатие заголовков.

В отличие от запросов и ответов, заголовки не сжимаются в gzip или подобные форматы. Для сжатия используется иной механизм — литеральные значения сжимаются по алгоритму Хаффмана, а клиент и сервер поддерживают единую таблицу заголовков. Повторяющиеся заголовки (например, user agent) опускаются при повторных запросах и ссылаются на их позицию в таблице заголовков.
Раз уж зашла речь о заголовках, позвольте добавить, что они не отличаются от HTTP/1.1, за исключением того, что добавилось несколько псевдозаголовков, таких как :method, :scheme, :host, :path и прочие.
4. Server Push
Server push — ещё одна потрясающая особенность HTTP/2. Сервер, зная, что клиент собирается запросить определённый ресурс, может отправить его, не дожидаясь запроса. Вот, например, когда это будет полезно: браузер загружает веб-страницу, он разбирает её и находит, какой ещё контент необходимо загрузить с сервера, а затем отправляет соответствующие запросы.
Server push позволяет серверу снизить количество дополнительных запросов. Если он знает, что клиент собирается запросить данные, он сразу их посылает. Сервер отправляет специальный фрейм PUSH_PROMISE, говоря клиенту: «Эй, дружище, сейчас я тебе отправлю вот этот ресурс. И не надо лишний раз беспокоить.» Фрейм PUSH_PROMISE связан с потоком, который вызвал отправку push-а, и содержит идентификатор потока, по которому сервер отправит нужный ресурс.
5. Приоритизация запросов
Клиент может назначить приоритет потоку, добавив информацию о приоритете во фрейм HEADERS, которым открывается поток. В любое другое время клиент может отправить фрейм PRIORITY, меняющий приоритет потока.
Если никакой информации о приоритете не указанно, сервер обрабатывает запрос асинхронно, т.е. без какого-либо порядка. Если приоритет назначен, то, на основе информации о приоритетах, сервер принимает решение, сколько ресурсов выделяется для обработки того или иного потока.
6. Безопасность
Насчёт того, должна ли безопасность (передача поверх протокола TLS) быть обязательной для HTTP/2 или нет, развилась обширная дискуссия. В конце концов было решено не делать это обязательным. Однако большинство производителей браузеров заявило, что они будут поддерживать HTTP/2 только тогда, когда он будет использоваться поверх TLS. Таким образом, хотя спецификация не требует шифрования для HTTP/2, оно всё равно станет обязательным по умолчанию. При этом HTTP/2, реализованный поверх TLS, накладывает некоторые ограничения: необходим TLS версии 1.2 или выше, есть ограничения на минимальный размер ключей, требуются эфемерные ключи и так далее.
Заключение
HTTP/2 уже здесь, и уже обошёл SPDY в поддержке, которая постепенно растёт. Для всех, кому интересно узнать больше, вот ссылка на спецификацию и ссылка на демо, показывающее преимущества скорости HTTP/2.
HTTP/2 может многое предложить для увеличения производительности, и, похоже, самое время начать его использовать.
Оригинал: Journey to HTTP/2, автор Kamran Ahmed.
Перевод: Андрей Алексеев, редактура: Анатолий Тутов, Jabher, Игорь Пелехань, Наталья Ёркина, Тимофей Маринин, Чайка Чурсина, Яна Крикливая.

