В этой статье мы поговорим о написании хорошего кода и о проблемах, с которыми мы при этом сталкиваемся. Понятный, декларативный, компонуемый и тестируемый — эти термины употребляются, когда речь заходит о написании хорошего кода. Решением проблем часто называют чистые функции. Но написание веб-приложений, в основном, связано с побочными эффектами и сложными асинхронными потоками операций, концепциями, которые по своей сути не являются чистыми. Ниже описан подход, который позволяет охватывать работу с побочными эффектами и сложными асинхронными потоками, сохраняя преимущества чистых функций.
Написание хорошего кода
Чистые функции — Святой Грааль в написании хорошего кода. Чистая функция — это функция, которая при одинаковых аргументах всегда возвращает одни и те же значения и не имеет видимых побочных эффектов.
function add(numA, numB) { return numA + numB }
Полезным свойством чистых функций является то, что их легко тестировать.
test.equals(add(2, 2), 4)
Компонуемость тоже является их сильной стороной.
test.equals(multiply(add(4, 4), 2), 16)
К тому же их очень легко использовать декларативно.
const totalPoints = users .map(takePoints) .reduce(sum, 0)
Но давайте взглянем на ваше приложение. Какая его часть действительно может быть выражена чистыми функциями? Насколько часто речь идёт о преобразовании значений, которые традиционно выполняют чистые функции? Могу предположить, что большая часть вашего кода работает с побочными эффектами. Вы выполняете сетевые запросы, DOM манипуляции, используете вебсокеты, локальные хранилища, изменяете состояние приложения и так далее. Это всё описывает разработку приложения, по крайней мере в Интернете.
Побочные эффекты
Как правило, мы говорим про побочные эффекты, в подобном случае:
function getUsers() { return axios.get('/users') .then(response => ({users: response.data})) }
Функция getUsers указывает на что-то "вне себя" — axios. Возвращаемое значение не всегда совпадает, так как это ответ сервера. Тем не менее, мы все еще можем использовать эту функцию декларативно и компоновать её во множестве различных цепочках:
doSomething() .then(getUsers) .then(doSomethingElse)
Но тестирование будет даваться нам с трудом, так как axios находится вне нашего контроля. Перепишем функцию, чтобы она принимала axios в качестве аргумента:
function getUsers(axios) { return axios.get('/users') .then(response => ({users: response.data})) }
Теперь её легко протестировать:
const users = ['userA', 'userB'] const axiosMock = Promise.resolve({data: users}) getUsers(axiosMock).then(result => { assert.deepEqual(result, {users: users}) })
Но у нас будут проблемы компоновки функции в различные цепочки, так как axios должен быть явно передан на вход.
doSomething() // Должен вернуть axios .then(getUsers) // чтобы передать сюда .then(doSomethingElse)
Функции, работающие с побочными эффектами на самом деле являются проблематичными.
Популярный совет в проектах наподобие Elm, Cycle, и реализациях в redux (redux-loop): "сдвигайте побочные эффекты к краю вашего приложения". В основном это означает, что бизнес-логика вашего приложения хранится чистой. Всякий раз, когда вам необходимо произвести побочный эффект, вы должны отделить его. Проблемой этого подхода, вероятно, является то, что это не помогает улучшить читаемость. Вы не можете выразить целостно сложный поток операций. Ваше приложение будет иметь несколько несвязанных циклов, скрывающих отношения одного побочного эффекта, которое может стать причиной другого побочного эффекта и так далее. Это не имеет значения для простых приложений, потому что вы редко имеете дело с более чем одним дополнительным циклом. Но в больших приложениях, в конечном итоге, вы столкнётесь с большим количеством циклов, и вам будет трудно понять как они соотносятся друг с другом.
Позвольте мне объяснить это более подробно на примерах.
Типичный поток приложения
Допустим, у вас есть приложение. Когда оно начало работу, вы хотите получить данные о пользователе, чтобы проверить, вошёл пользователь в систему или нет. Затем вы хотите получить список заданий. Они связаны с другими пользователями. Поэтому, на основании полученного списка заданий, вам надо динамически получить информацию и о этих пользователях тоже. Что же мы будем делать чтобы описать этот поток действий в понятном, декларативном, компонуемом и тестируемом виде?
Рассмотрим на примере простой реализации, используя redux:
function loadData() { return (dispatch, getState) => { dispatch({ type: AUTHENTICATING }) axios.get('/user') .then((response) => { if (response.data) { dispatch({ type: AUTHENTICATION_SUCCESS, user: response.data }) dispatch({ type: ASSIGNMENTS_LOADING }) return axios.get('/assignments') .then((response) => { dispatch({ type: ASSIGNMENTS_LOADED_SUCCESS, assignments: response.data }) const missingUsers = response.data.reduce((currentMissingUsers, assignment) => { if (!getState().users[assigment.userId]) { return currentMissingUsers.concat(assignment.userId) } return currentMissingUsers }, []) dispatch({ type: USERS_LOADING, users: users }) return Promise.all( missingUsers.map((userId) => { return axios.get('/users/' + userId) }) ) .then((responses) => { const users = responses.map(response => response.data) dispatch({ type: USERS_LOADED, users: users }) }) }) .catch((error) => { dispatch({ type: ASSIGNMENTS_LOADED_ERROR, error: error.response.data }) }) } else { dispatch({ type: AUTHENTICATION_ERROR }) } }) .catch(() => { dispatch({ type: LOAD_DATA_ERROR }) }) } }
Здесь просто всё неправильно. Этот код непонятен, недекларативен, некомпонуем и нетестируем. Однако есть одно преимущество. Всё что происходит при вызове функции loadData определено так как оно выполняется, упорядоченно и в одном файле.
Если мы отделим побочные эффекты "на край приложения", это будет выглядеть больше как демонстрация некоторых частей потока:
function loadData() { return (dispatch, getState) => { dispatch({ type: AUTHENTICATING_LOAD_DATA }) } } function loadDataAuthenticated() { return (dispatch, getState) { axios.get('/user') .then((response) => { if (response.data) { dispatch({ type: AUTHENTICATION_SUCCESS, user: response.data }) } else { dispatch({ type: AUTHENTICATION_ERROR }) } }) } } function getAssignments() { return (dispatch, getState) { dispatch({ type: ASSIGNMENTS_LOADING }) axios.get('/assignments') .then((response) => { dispatch({ type: ASSIGNMENTS_LOADED_SUCCESS, assignments: response.data }) }) .catch((error) => { dispatch({ type: ASSIGNMENTS_LOADED_ERROR, error: error.response.data }) }) } }
Каждая часть читается лучше, чем в предыдущем примере. И их легче компоновать в другие цепочки. Однако, проблемой становится разрозненность. Трудно понять, как эти части связаны друг с другом, потому что вы не можете видеть какие функции приводят к вызову другой функции. Перемещаясь между файлами, мы вынуждены воссоздавать в своей голове как отправка (dispatch) одного действия (action) порождает побочный эффект, который вызывает отправку нового действия, порождающего другой побочный эффект, который, в свою очередь, снова приводит к отправке нового действия.
Вынося побочные эффекты к краю вашего приложения, вы действительно получаете преимущества. Но это также оказывает негативное влияние: становится сложнее рассуждать о потоке. Об этом, конечно, можно и даже нужно поспорить. Надеюсь, я смог донести свою точку зрения через примеры и рассуждения выше.
На пути к декларативности
Представим, что мы можем описать этот поток следующим образом:
[ dispatch(AUTHENTICATING), authenticateUser, { error: [ dispatch(AUTHENTICATED_ERROR) ], success: [ dispatch(AUTHENTICATED_SUCCESS), dispatch(ASSIGNMENTS_LOADING), getAssignments, { error: [ dispatch(ASSIGNMENTS_LOADED_ERROR) ], success: [ dispatch(ASSIGNMENTS_LOADED_SUCCESS), dispatch(MISSING_USERS_LOADING), getMissingUsers, { error: [ dispatch(MISSING_USERS_LOADED_ERROR) ], success: [ dispatch(MISSING_USERS_LOADED_SUCCESS) ] } ] } ] } ]
Обратите внимание на то, что это валидный код, который мы сейчас разберём более подробно. А также, что мы не используем здесь какие-либо магические API, это просто массивы, объекты и функции. Но самое главное, мы в полной мере воспользовались декларативной формой записи кода, чтобы создать согласованное и читаемое описание сложного потока приложения.
Function Tree
Мы только что определили (задекларировали) дерево функции (function tree). Как я уже упоминал, мы не использовали никаких специальных API чтобы определить его. Это всего лишь функции определённые в дереве..., в дереве функции. Любая из функций, используемых здесь, а также фабрики функций (dispatch) могут быть повторно использованы в любом другом определении дерева. Это показывает простоту композиции. Не только каждая функция может состоять в других деревьях. Вы можете включать целые деревья в другие деревья, что делает их особенно интересными с точки зрения композиции.
[ dispatch(AUTHENTICATING), authenticateUser, { error: [ dispatch(AUTHENTICATED_ERROR) ], success: [ dispatch(AUTHENTICATED_SUCCESS), ...getAssignments ] } ]
В этом примере мы создали новое дерево getAssignments, которое также является массивом. Мы можем компоновать одни деревья в другие, используя оператор разворачивания (spread operator).
Давайте посмотрим как работают деревья функций, прежде чем перейти к тестируемости. Давайте его запустим!
Выполнение дерева функций
Сжатый пример того, как запустить дерево функцию выглядит следующим образом:
import FunctionTree from 'function-tree' const execute = new FunctionTree() function foo() {} execute([ foo ])
Созданный экземпляр FunctionTree является функцией, которая позволяет вам выполнять деревья. В приведенном выше примере будет выполнена функция foo. Если мы добавим больше функций, они будут выполнены по порядку:
function foo() { // Сначала я } function bar() { // Потом я } execute([ foo, bar ])
Асинхронность
function-tree умеет работать с обещаниями (promises). Когда функция возвращает обещание, или вы определяете функцию как асинхронную, используя ключевое слово async, функция исполнения (execute) дождётся пока обещание не будет выполнено (resolve) или отклонено (reject) прежде чем двигаться дальше.
function foo() { return new Promise(resolve => { setTimeout(resolve, 1000) }) } function bar() { // Я запущусь через 1 секунду } execute([ foo, bar ])
Зачастую асинхронный код имеет более разнообразные результаты. Исследуем контекст дерева функции для того, чтобы понять, как можно декларативно определять эти результаты.
Контекст
Все функции выполняемые с помощью function-tree принимают один аргумент. context — это единственный аргумент с которым должны работать функции определённые в дереве. По умолчанию контекст имеет два свойства: input и path.
Свойство input содержит полезную нагрузку (payload), переданную при запуске дерева.
// Мы используем деструктурирование аргумента function foo({input}) { input.foo // "bar" } execute([ foo ], { foo: 'bar' })
Когда функция хочет передать новую полезную нагрузку вниз по дереву ей нужно будет возвращать объект, который будет объединен с текущей полезной нагрузкой.
function foo({input}) { input.foo // "bar" return { foo2: 'bar2' } } function bar({input}) { input.foo // "bar" input.foo2 // "bar2" } execute([ foo, bar ], { foo: 'bar' })
Не имеет значения, синхронная функция или асинхронная, надо просто вернуть объект или выполненное обещание с объектом.
// Синхронный function foo() { return { foo: 'bar' } } // Асинхронный function foo() { return new Promise(resolve => { resolve({ foo: 'bar' }) }) }
Перейдём к изучению механизма выбора путей для выполнения.
Пути
Результат, возвращаемый из функции, может определить дальнейший путь выполнения в дереве. Благодаря статическому анализу, свойство path контекста уже знает по каким путям возможно продолжение выполнения. Это означает, что доступны только пути выполнения, которые определены в дереве.
function foo({path}) { return path.pathA() } function bar() { // Я сработаю } execute([ foo, { pathA: [ bar ], pathB: [] } ])
Вы можете передать полезную нагрузку, передавая объект к методу пути.
function foo({path}) { return path.pathA({foo: 'foo'}) } function bar({input}) { console.log(input.foo) // 'foo' } execute([ foo, { pathA: [ bar ], pathB: [] } ])
Чем же хорош механизм путей? Прежде всего, он носит декларативный характер. Здесь нет выражений if или switch. Это повышает удобочитаемость.
Гораздо важнее то, что пути не имееют дела с "выбрасыванием" (throw) ошибок. Часто потоки мыслятся как: "сделай это или бросай всё, если произойдёт ошибка". Но не в случае с веб-приложениями. Есть много причин, почему вы решите пойти вниз по различным путям выполнения. Решение может быть основано на роли пользователя, возвращаемом ответе сервера, некотором состоянии приложения, переданном значении и так далее. Дело в том, что function-tree не отлавливает ошибки, не делает всплытия ошибок и тому подобных техник. Оно просто выполняет функции и позволяет им возвращать пути там, где исполнение должно расходиться.
Есть ещё несколько небольших скрытых особенностей. Например, вы можете определить дерево функции без реализации чего-либо. Это означает, что все возможные пути выполнения определены заранее. Это заставляет вас думать о том, какие случаи надо обработать. И значительно снижает вероятность, что вы проигнорируете или забудете о сценариях, которые могут произойти.
Провайдеры
На одних только input и path сложное приложение не построить. Поэтому function-tree построен на концепции провайдеров. На самом деле input и path тоже провайдеры. В комплекте c function-tree поставляется несколько готовых. И конечно же вы можете сами их создавать. Предположим вы хотите использовать Redux:
import FunctionTree from 'function-tree' import ReduxProvider from 'function-tree/providers/Redux' import store from './store' const execute = new FunctionTree([ ReduxProvider(store) ]) export default execute
Теперь у вас есть доступ к методам dispatch и getState в ваших функциях:
function doSomething({dispatch, getState}) { dispatch({ type: SOME_CONSTANT }) getState() // {} }
Вы можете добавить любые другие инструменты используя ContextProvider:
import FunctionTree from 'function-tree' import ReduxProvider from 'function-tree/providers/Redux' import ContextProvider from 'function-tree/providers/Context' import axios from 'axios' import store from './store' const execute = new FunctionTree([ ReduxProvider(store), ContextProvider({ axios }) ]) export default execute
Скорее всего вы захотите использовать DebuggerProvider. В сочетании с расширением для Google Chrome вы сможете отлаживать вашу текущую работу. Добавим провайдер отладчика к примеру выше:
import FunctionTree from 'function-tree' import DebuggerProvider from 'function-tree/providers/Debugger' import ReduxProvider from 'function-tree/providers/Redux' import ContextProvider from 'function-tree/providers/Context' import axios from 'axios' import store from './store' const execute = new FunctionTree([ DebuggerProvider(), ReduxProvider(store), ContextProvider({ axios }) ]) export default execute
Это позволяет видеть всё что происходит при выполнении этих деревьев в вашем приложении. Провайдер отладчика автоматически обернёт и будет отслеживать всё что вы разместите в контексте:
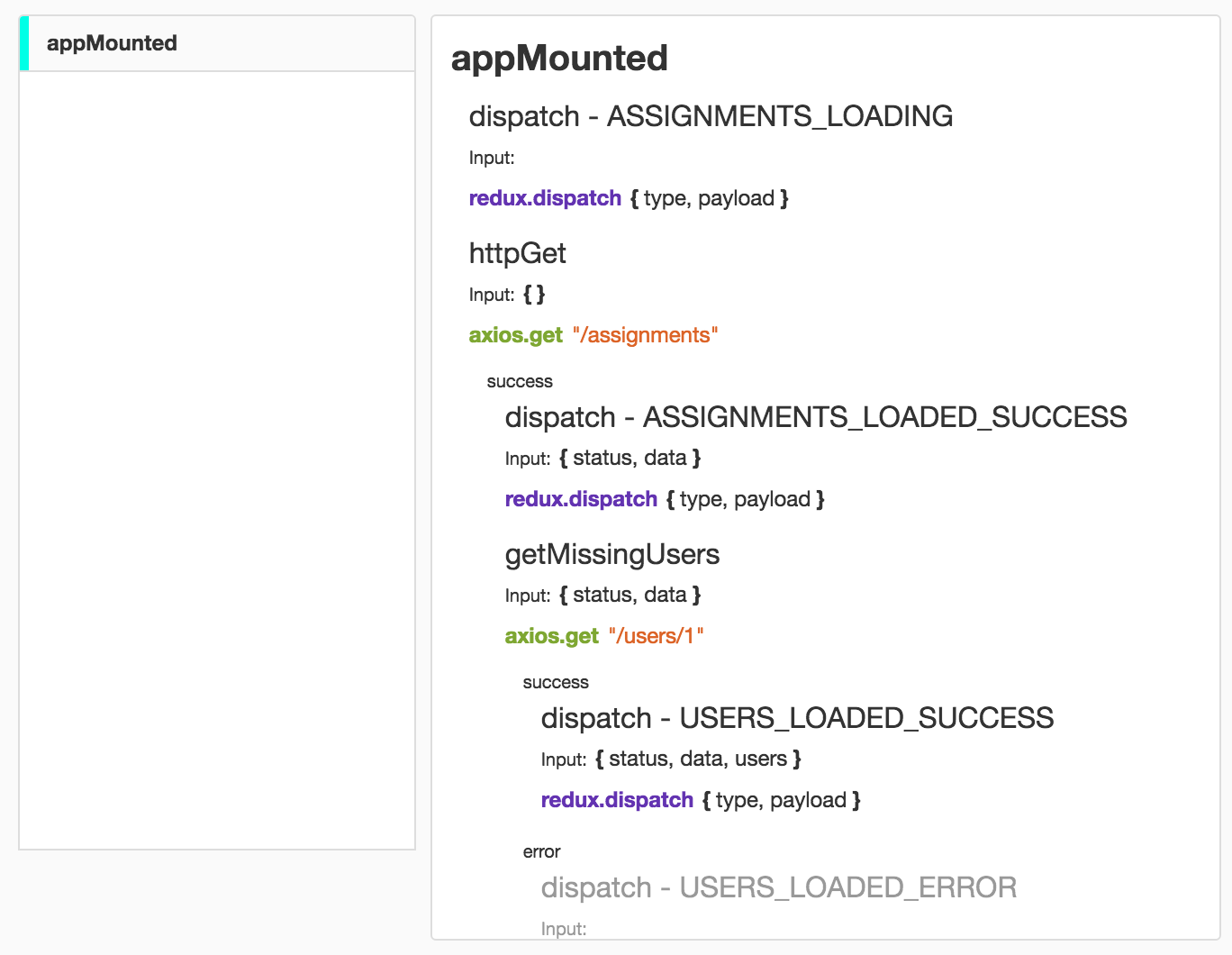
Если же вы решите использовать function-tree на серверной стороне, можете подключить NodeDebuggerProvider:
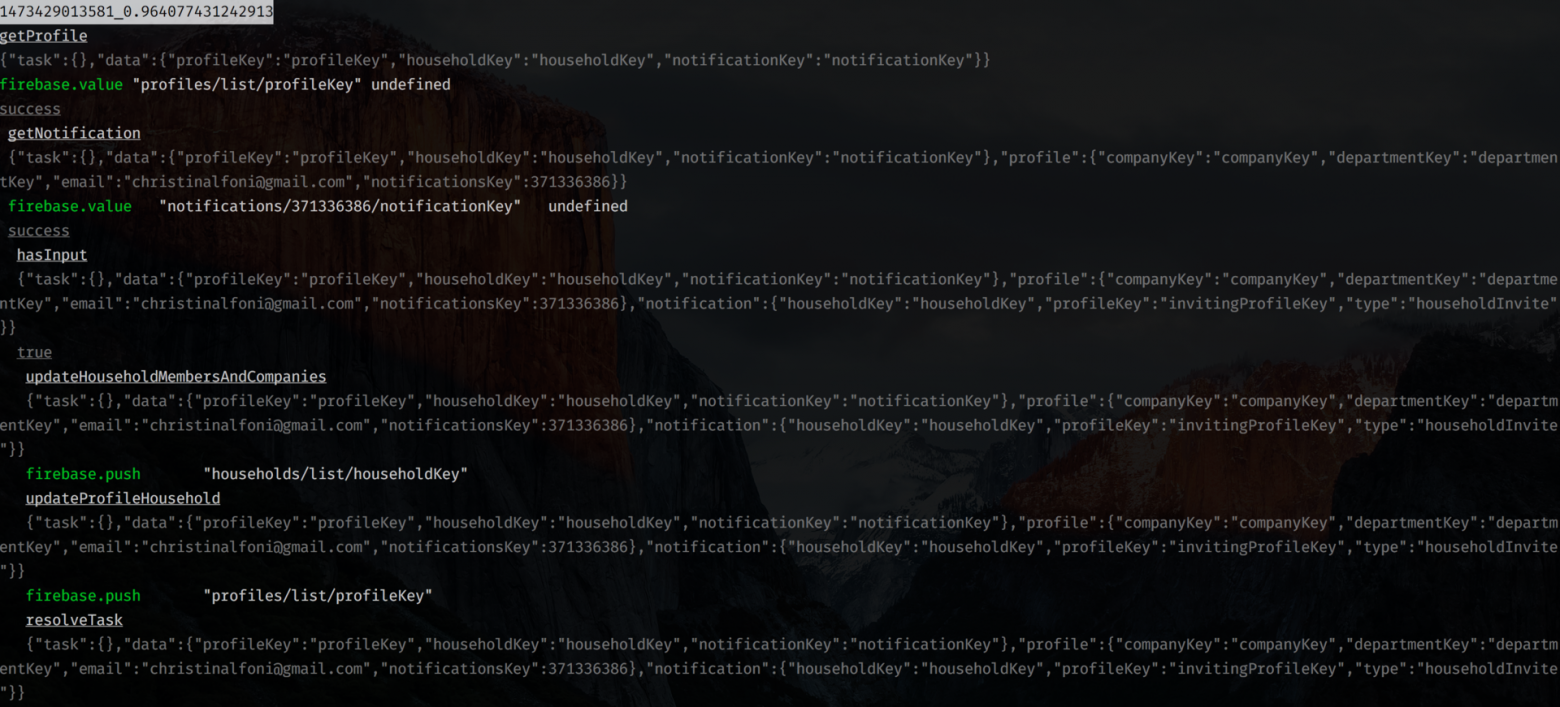
Тестируемость
Но, скорее всего самое важное, это возможность проверки дерева функции. Как выясняется, это очень легко сделать. Чтобы протестировать отдельные функции в дереве, просто вызывайте их со специально подготовленным контекстом. Рассмотрим тестирование функции создающей побочный эффект:
function setData({window, input}) { window.app.data = input.result }
const context = { input: {result: 'foo'}, window: { app: {}} } setData(context) test.deepEqual(context.window, {app: {data: 'foo'}})
Тестирование асинхронных функций
Многие библиотеки для тестирования позволяют вам создавать заглушки для глобальных зависимостей. Но нет причин делать это для function-tree, потому что функции используют только то, что доступно через аргумент контекста. Например, следующая функция, использующая axios для получения данных, может быть протестирована следующим образом:
function getData({axios, path}) { return axios.get('/data') .then(response => path.success({data: response.data})) .catch(error => path.error({error: error.response.data})) }
const context = { axios: { get: Promise.resolve({ data: {foo: 'bar'} }) } } getData(context) .then((result) => { test.equal(result.path, 'success') test.deepEqual(result.payload, {data: {foo: 'bar'}}) })
Тестирование всего дерева
Вот здесь становится ещё интереснее. Мы можем протестировать всё дерево точно так же, как мы тестировали функции отдельно.
Давайте представим простое дерево:
[ getData, { success: [ setData ], error: [ setError ] } ]
Эти функции используют axios для получения данных, а затем сохраняют их в свойстве объекта window. Мы протестируем дерево, создав новую функцию выполнения с заглушками для передачи в контекст. Затем мы запускаем дерево и проверяем изменения после окончания выполнения.
const FunctionTree = require('function-tree') const ContextProvider = require('function-tree/providers/Context') const loadData = require('../src/trees/loadData') const context = { window: {app: {}}, axios: { get: Promise.resolve({data: {foo: 'bar'}}) } } const execute = new FunctionTree([ ContextProvider(context) ]) execute(loadData, () => { test.deepEquals(context.window, {app: {data: 'foo'}}) })
Не имеет значения какие библиотеки вы используете. Вы можете легко тестировать деревья функций, пока вы размещаете библиотеки в контексте дерева.
Фабрики
Так как дерево является функциональным, вы можете создавать фабрики, которые будут ускорять вашу разработку. Вы уже видели использование фабрики dispatch в примере с Redux. Она была объявлена следующим образом:
function dispatchFactory(type) { function dispatchFunction({input, dispatch}) { dispatch({ type, payload: input }) } // Свойство `displayName` переопределяет имя функции, // для отображения в отладчике. dispatchFunction.displayName = `dispatch - ${type}` return dispatchFunction } export default dispatchFactory
Создавайте фабрики для вашего приложения, чтобы избегать создания специфичных функций для всего. Предположим вы решите использовать baobab, единое дерево состояния, для хранения состояния вашего приложения.
function setFactory(path, value) { function set({baobab}) { baobab.set(path.split('.'), value) } return set } export default set
Эта фабрика позволит вам выражать изменения состояния прямо в дереве:
[ set('foo', 'bar'), set('admin.isLoading', true) ]
Вы можете использовать фабрики, чтобы построить собственный DSL вашего приложения. Некоторые фабрики на столько обобщённые, что мы решили сделать их частью function-tree.
debounce
Фабрика debounce позволяет придержать выполнение на указанное время. Если срабатывают новые исполнения одного и того же дерева, существующее будет уходить по пути discarded. Если за указанное время нет новых срабатываний, последнее пойдёт по пути accepted. Обычно такой поход используется при поиске по мере ввода.
import debounce from 'function-tree/factories/debounce' export default [ updateSearchQuery, debounce(500), { accepted: [ getData, { success: [ setData, ], error: [ setError ] } ], discarded: [] } ]
В чём отличие от Rxjs и цепочек обещаний?
И Rxjs, и Обещания управляют контролем исполнения. Но ни один из них не имеет декларативного условного определения путей исполнения. Вам придётся разносить потоки, писать выражения if и switch или выбрасывать ошибки. В выше приведённых примерах мы смогли разделить пути исполнения success и error также декларативно, как наши функции. Это улучшает читаемость. Но эти пути могут быть абсолютно любыми. Например:
[ withUserRole, { admin: [], superuser: [], user: [] } ]
Пути не имеют ничего общего с обработкой ошибок. function-tree позволяет вам выбрать путь на любом шаге исполнения, в отличие от обещаний и Rxjs, где бросание ошибок единственный способ прекратить исполнение текущего пути.
Rxjs и обещания основаны на преобразовании значений. Это значит, что следующей функции доступны только значения переданные как результат выполнения предыдущей. Это отлично работает, когда вам действительно надо преобразовывать значения. Но события в вашем приложении это не тот случай. Они работают с побочными эффектами и проходят по одному или многим путям исполнения. В этом и заключается главное отличие function-tree.
Где можно применять?
function-tree может помочь, если вы создаёте приложение работающее с побочными эффектами в сложных асинхронных цепочках. Преимущества "принудительного" разбиения логики вашего приложения на блоки "lego" и их тестируемости могут быть достаточно весомыми доводами. В основном это позволяет вам писать более читаемый и поддерживаемый код.
Проект доступен в репозитории на Github, а расширение отладчик для Google Chrome может быть найдено в Chrome Web Store. Обязательно посмотрите пример приложения в репозитории.
Первоисточником проекта function-tree можно считать cerebral. Вы можете считать реализацию сигналов в Cerebral абстракцией с собственным представлением над function-tree. В настоящее время Cerebral использует свою собственную реализацию, но в Cerebral 2.0 function-tree будет использоваться в качестве основы для фабрики сигналов. Выражаю благодарность Алексею Guria за переработку и оттачивание идей сигналов Cerebral, что привело к созданию самостоятельного и общего подхода.
Расскажите что вы думаете о данном подходе в комментариях ниже. Поделитесь, если у вас есть ссылки на другие шаблоны и методы решения проблем, обсуждаемых в этой статье. Спасибо за прочтение!

