
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
\begin{tikzpicture}[mark=*,mark size=1,only marks]
\begin{axis}[
yticklabel style={/pgf/number format/fixed},
ymax=0.25,
width=10cm,
declare function={binom(\k, \n, \p)=(\p^(\k))*((1-\p)^(\n-\k))*factorial(\n)/(factorial(\n-\k)*factorial(\k));}
]
\addlegendimage{blue}
\addlegendimage{green}
\addlegendimage{red}
\foreach \n/\p/\c in {20/0.5/blue, 20/0.7/green, 40/0.5/red} {
\foreach \k in {0,...,\n} {
\edef\temp{\noexpand
\addplot[\c] coordinates {(\k,{binom(\k, \n, \p)})};
}\temp
}
\edef\temp{\noexpand
\addlegendentry{$p=\p, n=\n$}
}\temp
}
\end{axis}
\end{tikzpicture}
Такие диаграммы красивее. Я взял материал со страниц википедии (в тексте приведены ссылки). Если для кого-нибудь действительно совсем несложно переделать графики — Вы можете улучшить Вики.
Сам бы занялся, но не владею технологией построения настолько красивых диаграмм :)
(Хотя, уже захотелось освоить)
Переделать — не сложно, но и не просто :)
Хотите освоить — посмотрите введение к официальной документации tikz. В нем последовательным усложнением строятся полноценные примеры графиков и диагамм. Это хорошая отправная точка.
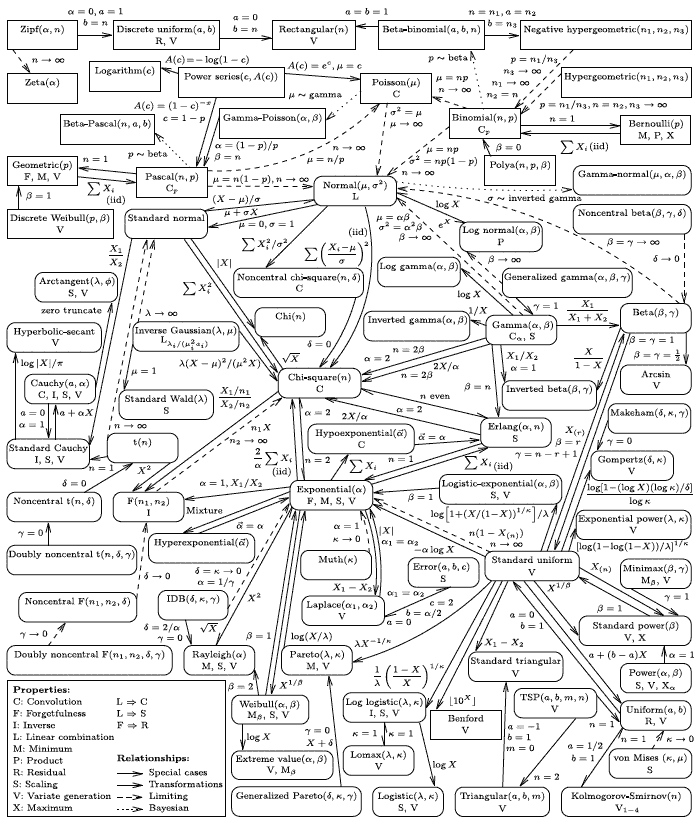
Вот очень хорошая вводная статья про виды распределений: Common Probability Distributions: The Data Scientist’s Crib Sheet.
У меня вообще подозрение, что почти все непрерывные распределения должны укладываться в форму , где
и
— полиномы. Либо являться подстановкой функции (например, нецелой степени либо логарифма) от
вместо аргумента в эту формулу.
Кто-нибудь встречал подобные обобщение?
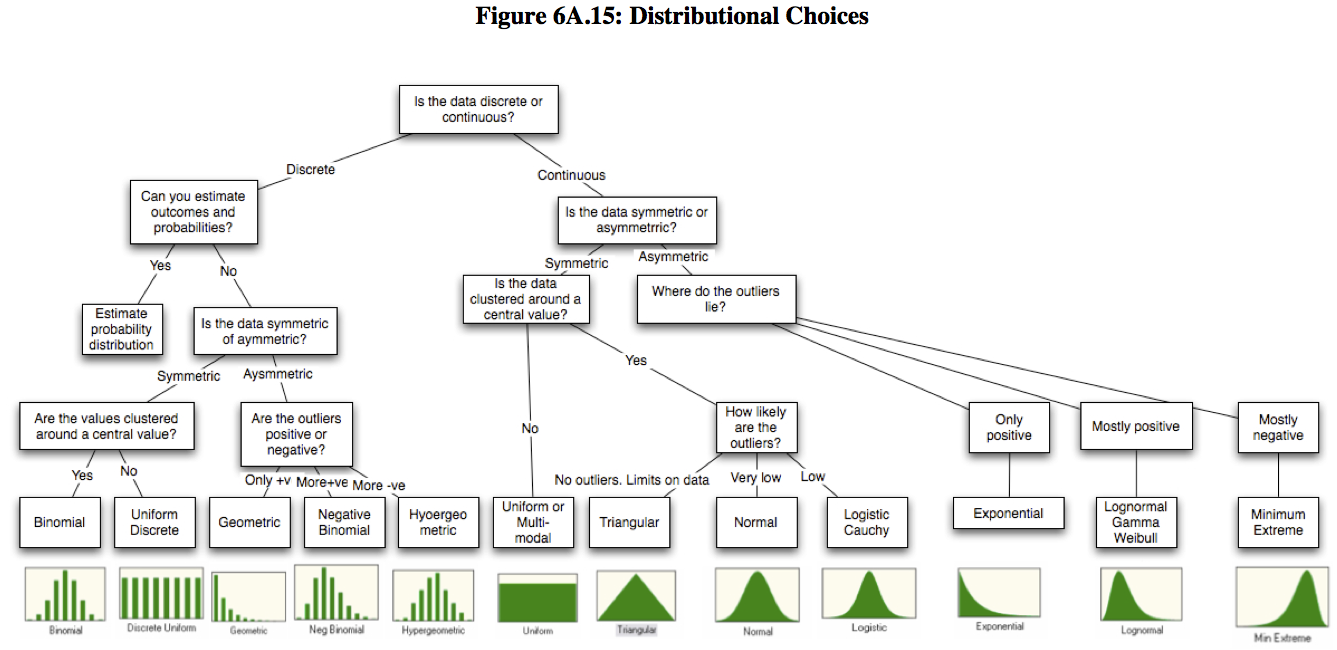
Студентам буду на зачёт задание давать: воспроизвести граф по памяти :)
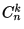 , либо как
, либо как  , но не как
, но не как  .
.
«Правда, чистая правда и статистика» или «15 распределений вероятности на все случаи жизни»