
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Разработка новой версии языка определенно не идет за закрытыми дверями…
Наверное, как объектно-ориентированных языках, класс, это тоже такой объект.
типа
abstract class Animal{
abstract virtual static string GetDescription();
}
class Dog{
static string GetDescription()
{
return "собака";
}
}
var animalClasses = new []{Dog, Cat, Squirell};
Animal CreateByDescription(string description)
{
return animalClasses
.Where(x => x.GetDescription() == descriuption)
.First()
.CreateNewInstance();
}Речь идет об изменении языка => можно ввести такое
Для этого вам придется не только язык поменять, но и солидный кусок CLR.
Не факт. Можно какой-нибудь трюк типа автобоксинга сделать. При приведении к типу MetaClass генерировать какой-нибудь класс с членами статическими методами.
… которые хранить где?
Не знаю. Может быть в сборке с классом. Тогда, наверное, надо его генерить по атрибуту а не при приведении. Вы лучше меня знаете дотнет, придумайте сами :)
Я просто не могу придумать никакого сценария, при котором я обращаюсь именно к статическому методу в терминах CLR (т.е. <typename>.<method>) и при этом у меня работает subclass polymorphism.
Есть дженерики, конечно, но там на момент развертывания известен точный тип.
SuperType.classType t = SubType.class;
t.StaticVirtualMethod();Мне такая идея тоже не нравится — но это не значит что она нереализуема.
AnimalFactory[] factories = new[]{ new CatFactory(), new DogFactory(), new SquirellFactory(), };
Animal CreateByDescription(string description)
{
return factories
.Where(x => x.Description == description)
.First()
.Create();
}
Ну оно больше и не выглядит как статический метода, а выглядит как инстанс. Я об этом и говорю.
Тот код который вы привели можно спокойно реализовать при помощи рефлексии, то бишь атрибутов, и не нужно всякого там статического полиморфизма...
class A {
public static string info() {return "a";}
}
class A2:A {
public new static string info() {return "a2";}
}
Возможность вызова статик функции через экземпляра класса.
Но зачем?
Как минимум, наличие возможности лучшее ее отсутствия.
Нет. Слишком много возможностей нарушает целостность.
А так это дает более объектно ориентированный доступ к параметрам и функциям которые меняются при наследовании, но не нуждаются для расчетов в самом объекте.
Если они не нуждаются для расчетов в объекте — это не функции этого объекта. И именно поэтому синтаксис объект.метод по отношению к ним будет вводить в заблуждение.
Я так понимаю вы поклонник асемблера и противник библиотек и объектного программирования?
Нет, я поклонник консистентных систем и противник избыточности.
Но для того, что бы она вызвалась у объекта именно того класса которым он является, ее нужно вызывать непосредственно у этого экземпляра класса.
Нет такого "нужно". Если вам нужна функция класса, вам нужно вызывать ее на классе. Типичный пример такого (на псевдоязычке) выглядел бы так:
yourObject -> getType -> someMethodНо зачем «getType ->» если его нужно писать всегда?
Не всегда, а только тогда, когда обращение идет к методам класса, а не объекта. И именно за этим и нужно — чтобы четко видеть, к какому объекту мы обращаемся.
Можно и пропустить двузначностей это не принесет.
Да ну? yourObject -> Name — имя чего я сейчас получу? yourObject -> setMaxCount(15) — у чего ограничился пул?
Тем более «нормального» getType к сожалению нет
Так вот лучше сделать нормальный getType, который не нарушает парадигму, чем вводить неявный вызов статиков, который парадигму нарушает.
вы за строгость и явные разграничения.
A a = new B();
a.info();
Скорее всего у вас нет специфических знаний по вызовам виртуальных функций в рантайме.
Так просветите, интересно же.
Мне вот кажется, что это вы не знаете, как CLR хранит ссылки на объекты и сами объекты. Если бы со ссылкой связывалась информация о типе объекта, тогда да, проблем нет. Но информации о типе у ссылки нет.
О чем и речь. Мы получили экземплярный виртуальный метод. Зачем тогда делать статический метод виртуальным, чтобы он вел себя ровно так же, как экземплярный? Причем это полное нарушение концепции статических методов.
О каком единообразии может идти речь, когда это фундаментально разные вещи? Такое единообразие мозг сломает в момент. И еще раз, нельзя называть метод статическим, если он требует наличия созданного экземпляра класса для своего вызова.
Можно вести речь о том, чтобы заиметь в языке что-то вроде "класса как объекта", и писать, например:
class A { static virtual void foo() {...}}
class B : A { static override void foo() {...}}
Class<A> a = A;
a.foo(); // вызывает A.foo()
a = B;
a.foo(); // вызывает B.foo()
a = (new B())->class;
a.foo(); // вызывает B.foo()Но вызывать статику на экземплярах — увольте.
у них общий набор типовых характеристик например
static Name, Type, Width, Height, у каждого класса свои значения. И возможно они зависит от расчета в родителе.
Почему бы не сделать какое-нибудь статическое свойство Meta, куда в статическом конструкторе положить экземпляр класса характеристик с нужными значениями, привязкой к базовым характеристикам и т.п.? Будет у вас A1.Meta.Width, например. Реализация чуть сложнее, но снаружи разницы особо нет. Можно добавить еще экземплярное свойство Meta, которое просто возвращает значение статического. Тогда и на экземплярах удобно будет звать статику.
Как удобней писать? в месте каждого вызова A1.Width() или просто Width()?
По мне, удобнее писать одни и те же вещи одинаково, и разные вещи по-разному. Именно поэтому для статики писать везде A1.Width лучше, чем где-то A1.Width, а где-то a.Width (который статический, но пишется почему-то как экземплярный).
Немного не так:
class A { public static string inf; }
class A2 : A { public static new string inf; }
A.inf = "a";
A2.inf = "a2";Хотя решение не очень красивое, конечно.
using System;
class Meta
{
string _meta;
public Meta(string meta)
{
_meta = meta;
}
public override string ToString()
{
return _meta;
}
}
class A
{
public static Meta meta;
}
class A1 : A
{
public static new Meta meta;
}
class A2 : A
{
public static new Meta meta;
}
public class Program
{
public static void Main()
{
A1.meta = new Meta("a1");
A2.meta = new Meta("a2");
Console.WriteLine(A.meta);
Console.WriteLine(A1.meta);
Console.WriteLine(A2.meta);
}
}Может, стоило бы вообще убрать такого рода информацию из статических полей и организовать доступ к ней как-то еще. Например, importantInfoProvider.Get().Width. А внутри по типу определять, что вернуть. Не думаю, что решение через статику — единственное или лучшее возможное.
interface IDerivedStatic
{
int Width();
int Height();
}
class A<T>
where T : struct, IDerivedStatic
{
static T data = new T();
public static int Width() => data.Width();
public static int Height() => data.Height();
public static int Perimetr() => Width() * Height();
}
class A1
: A<A1.Static>
{
public struct Static
: IDerivedStatic
{
public int Height() => A1.Height();
public int Width() => A1.Width();
}
static new int Width() => 12;
static new int Height() => 14;
}class A
{
static virtual void foo() { ... }
}class A.Static: Type
{
virtual void foo() { A.foo(); } }
}
class A
{
static void foo() { ... }
A.Static GetType();
}void Generic<T>(T a) where T: A
{
a.GetType().foo();
}
void Generic<T>() where T: A
{
// typeof(T) возвращает объект T.Static, приведённый к A.Static
// это можно сделать точно так же, как реализован механизм new T()
typeof(T).foo();
}Что функция вернет то и будет. Я имел в виду неоднозначностей для компилятора.
Меня мало волнует компилятор, меня волнует, как я это читать буду. И вот мне это читать очень неудобно.
Это бесспорно «нормальный getType» без рефлектинга по мне тоже куда важнее.
Вообще-то GetType и сейчас не использует Reflection.
struct Deserializer<T> where T: IDeserializable
{
public static readonly Func<T> deserialize(IDeserializer deserializer);
static Deserializer()
{
deserialize = что-то типа typeof(T).GetMethod("deserialize", BindingFlags.Static | BindingFlags.Public).CreateDelegate(typeof(Func<T>)) as Func<T>;
}
}Deserializer<T>.Deserialize(...); class function ObjectName(AObject: TObject): String; virtual
TVirtClass = class of TBaseVirtClass.
TClass= class of TObject.
{ Virtual method table entries }
vmtSelfPtr = -76;
vmtIntfTable = -72;
vmtAutoTable = -68;
vmtInitTable = -64;
vmtTypeInfo = -60;
vmtFieldTable = -56;
vmtMethodTable = -52;
vmtDynamicTable = -48;
vmtClassName = -44;
vmtInstanceSize = -40;
vmtParent = -36;
vmtSafeCallException = -32 deprecated; // don't use these constants.
vmtAfterConstruction = -28 deprecated; // use VMTOFFSET in asm code instead
vmtBeforeDestruction = -24 deprecated;
vmtDispatch = -20 deprecated;
vmtDefaultHandler = -16 deprecated;
vmtNewInstance = -12 deprecated;
vmtFreeInstance = -8 deprecated;
vmtDestroy = -4 deprecated;
dynamic:public T Add<T>(T a, T b)
where T: numeric // например, так
{
return a + b;
}
Для этого нужен не T: numeric, а T: has (T + T). И в F#, кстати, такое есть.
T. Либо под капотом dynamic, хотя очень сомневаюсь.Скорее всего, это вопрос затрат и удобочитаемости. Тем более, что это можно уже сделать с помощью интерфейсов.
Ещё мне очень нехватает строковых Enum-ов
Преимущества:
— одинаковый подход к перечисляемым типам
— точно знаешь что присваивать в поле (т.к. в текущей реализации — это просто строка и можно присвоить что угодно, а в предлагаемой — только значения из списка)
enum VehicleType {
Light,
Medium,
Heavy
}
class Vehicle {
private readonly VehicleType type;
public Vehicle (VehicleType type) {
this.type = type;
}
public string GetImageUrl () {
return "/images/" + type + ".png";
}
}
new Vehicle(VehicleType.Heavy).GetImageUrl(); // "/images/Heavy.png"
enum ExtendedVehicleType : VehicleType {
Spg, Spatg
}
new Vehicle(VehicleType.Spg);
class VehicleType {
public static readonly Light = new VehicleType("Light");
public static readonly Medium = new VehicleType("Medium");
public static readonly Heavy = new VehicleType("Heavy");
// ..
}
А почему бы просто не пользоваться Енумом в том виде, который сейчас есть?
public static string GetDescription(this Enum value)
{
DescriptionAttribute[] descriptionAttributeArray = (DescriptionAttribute[]) value.GetType().GetField(value.ToString()).GetCustomAttributes(typeof (DescriptionAttribute), false);
...
private enum Verdict : byte {
[Description(" ")]
Space,
[Description(",")]
Comma
}
enum MyStrings : string {
One = "One with whitespaces",
Two = "Two with whitespaces",
Three = "Three with whitespaces"
}
MyStrings enVal = MyStrings::One;
var json = JsonConverter.Serialize<string>(enVal);
Если вы напишете await asyncFunction() то не будет выделено нового потока, если внутри asyncFunction он нигде явно не выделяется
Это зависит от текущего SynchronizationContext
Это зависит в первую очередь от того, что вернула asyncFunction, и если она вернула уже выполненный таск, то SynchronizationContext вообще не будет использован.
Console.WriteLine(Thread.CurrendThread.ManagedThreadId);
await Task.Yield();
Console.WriteLine(Thread.CurrendThread.ManagedThreadId);Не совсем так. Task.Yield — это все-таки не задача, а требование уступить поток. Там отдельный Awaiter написан для него.
Если смотреть задачи — то они как раз работают довольно адекватно. При установленном контексте синхронизации метод в него возвращается. А без контекста синхронизации — метод продолжает исполняться в том же потоке, который задачу выполнил (исключение — если синхронное продолжение было явно запрещено в свойствах задачи).
Для YieldAwaiter приведенное поведение — ожидаемое!
Что же до TaskAwaiter, то тут все тоже просто, если разобраться. Если не было захвачено ни контекста синхронизации, ни планировщика задач — то используется класс AwaitTaskContinuation. Этот класс по возможности вызывает продолжение синхронно.
Task.Run(async () =>
{
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
await Task.Delay(10);
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
}).Wait();
А как, по-вашему, этот код вообще может работать? После истечения 10ти миллисекунд выполнение обязано вернуться в пул потоков. Почему для вас так важно, чтобы это был тот же самый поток? Все потоки пула одинаковы.
Лучше посмотрите на вот этот код:
public static void Main()
{
A().Wait();
}
static async Task A() {
await B();
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
}
static async Task B() {
await C();
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
}
static async Task C() {
await Task.Yield();
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
}В данном случае, все три оператора Console.WriteLine выполнятся в одном и том же потоке, что показывает, что продолжения и правда вызываются синхронно.
В данном случае, все три оператора Console.WriteLine выполнятся в одном и том же потоке, что показывает, что продолжения и правда вызываются синхронно.
4
5
5
Почему для вас так важно, чтобы это был тот же самый поток?
"периодически" — это как?
Запустил код на трех разных компьютерах. Каждый раз все три числа совпадали… Вы что-то делаете не так.
Не надо объяснять мне что такое race condition, я это знаю.
В коде, который я привел, окончания всех трех задач всегда выполняются в одном и том же потоке. Если они оказались в разных потоках — вы что-то сделали не так.
В коде, который я привел, окончания всех трех задач всегда выполняются в одном и том же потоке
Что такое Utilities.Asynchronius? Если убрать этот using и все лишние референсы — ошибка останется?
Вот мой скриншот:
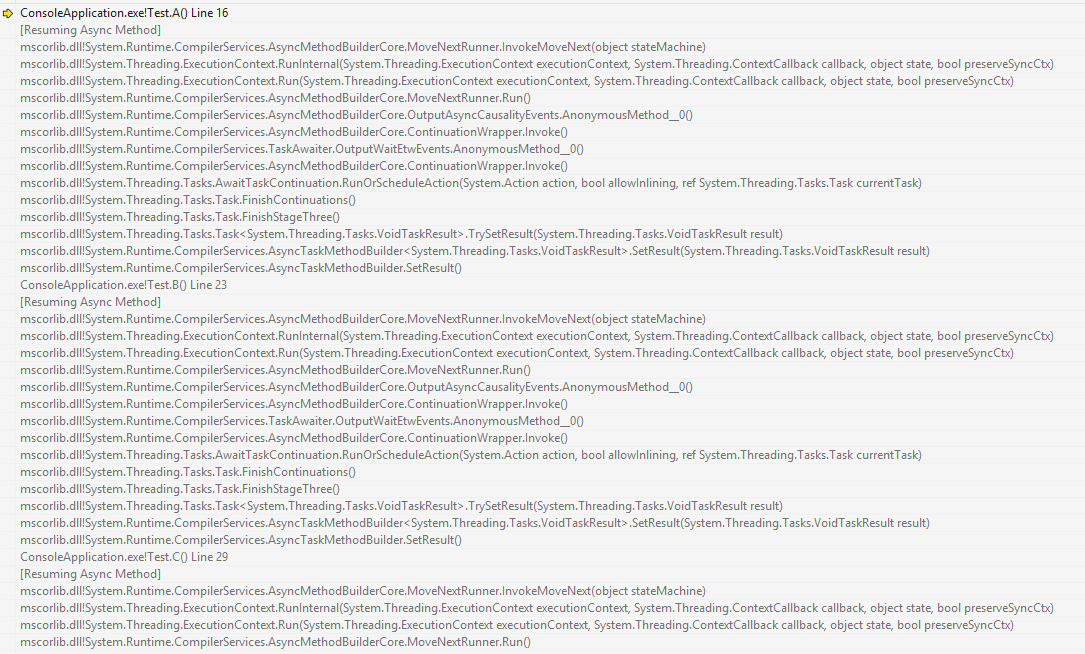
Отсюда прекрасно видно, что продолжения были вызваны синхронно. Если у вас меняется номер потока — значит, что-то мешает синхронному вызову. Какой-нибудь extension-метод, который перекрыл системный, или класс. Или просто установленный контекст синхронизации. Или хитрый аспект, который что-то нарушил.
Ну, или же просто какой-то необычный рантайм.
Выполнение программы детерминировано.
Оно не должно попадать в планировщик.
PS не буду вам больше отвечать, потому что вы спорите для того чтобы спорить, а не чтобы разобраться в чем дело.
Debugger: not attached .NET version: 4.0.30319.42000 Platform: 64 bit Same ThreadId: 98,94%
По-моему, вы только что продемонстрировали, что модель TPL в .net сделана удобно: для вашей конкретной задачи стандартный планировщик не подошел (это не значит, что он не подойдет другим, у меня он прекрасно работает) — и вы легко заменили его на свой.
А что не так с "конкретным компилятором" если сам компилятор — переносимый и открытый?
Вот только пользоваться этим в C++ зачастую неудобно. Расширения компилятора выглядят лучше.
Расширения компилятора выглядят лучше.
Так ведь это зависит от целей использования. Расширение компилятора позволяет сделать и миксин, и шаблон.
Логика работы расширений описывается на том же самом языке, для которого эти расширения пишутся.
Шаблоны в c++ — это отдельный функциональный (!) язык (мета)программирования, при том что основной язык — императивный...
Шаблоны в c++ — это отдельный функциональный (!) язык (мета)программирования, при том что основной язык — императивный...
В расширении можно произвольно управлять наличием и именами методов
public string Property
{
get { return field; }
set
{
if (field == value) return;
field == value;
OnPropertyChanged(nameof());
}
}
А также пустой nameof(), который возвращает имя текущего свойства/метода:А это уже есть, но немного по-другому записывается:
void OnPropertyChanged([CallerMemberName] string propertyName = "") { .. }
...
public string Property1
{
set
{
OnPropertyChanged();
}
}
public string Property2
{
set
{
OnPropertyChanged();
}
}
Возможные нововведения C#