
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
К статье стоит добавить, что не умея пользоваться методами оптимизации, иначе как черным ящиком, практически не возможно повторить эксперименты с тренировкой таких могучих современных сетей, как VGG, ResNet, Inception, etc. с нуля, да и при умении пользоваться тоже приходится с бубном плясать, чтобы получить статейные циферки точности.

а что там ещё помимо DL?
Имхо, на данный момент самый живой чат по ML, DL и всему с этим связанному в кружочках.
конечно нет, самое большое русскоговорящее это одс, сейчас там 2.5к людей
Может там сейчас не самая "жара", но активных юзеров там не больше 50 (и даже эта оценка завышена) и большинство обсуждений — это small talks на около-ML тематику. В то время как в кружочках при чуть меньшей аудитории (думаю, что там примерно 10-15 боле-мене активных юзеров) концентрация полезных обсуждений выше.
Ну и как правильно пишет buriy, полезные сообщения там легко теряются в потоке отвлеченных разговоров.
Но как тематический чат, да, намного лучше полудохлых telegram-чатов на схожую тематику)
Nesterov более подвержен застреванию в локальном минимуме, чем SGD.
А разве кто-то вообще учит сетки, считая градиент ошибки сразу по всей выборке? Вроде бы стандарт де факто — это тренировка на минибатчах.
А разве кто-то вообще учит сетки, считая градиент ошибки сразу по всей выборке?
меня больше удивляет, что такие методы работают хоть как-то вообще. Она капец какая не диагональная, и непростая.
И когда я сталкиваюсь с фразами «а давайте, примем для простоты, что она диагональная» и тому подобным меня больше удивляет, что такие методы работают хоть как-то вообще. Она капец какая не диагональная, и непростая.
Всё же лучше, чем считать, что эта же матрица вообще скалярная как в случае простых методов первого порядка.
Но что гораздо более важно. все алгоритмы второго порядка намертво застревают в локальных минимумах если к ним не применять жестокое обращение
А Вы чего хотели? Нахождение глобального минимума невыпуклой задачи – NP сложная задача, никакой надежды на это нет. Радоваться надо тому, что методы второго порядка добираются до локальных минимумов.
А применять глубокое обучение обычно имеет смысл только в тех задачах, где этих локальных минимумов милиарды миллионов
Локальные минимумы есть артифакт модели и функции потерь, непонятно, о каких локальных минимумах Вы говорите, не задав сперва оптимизируемую поверхность.
Локальные минимумы есть артифакт модели и функции потерь, непонятно, о каких локальных минимумах Вы говорите, не задав сперва оптимизируемую поверхность.
Всё же лучше, чем считать, что эта же матрица вообще скалярная как в случае простых методов первого порядка.А вот вопрос лучше ли. Я пока пробовал сравнивать SGD с методами более или менее второго порядка только на узком круге задач, но уже пришёл к мысли, что способность миновать ближайшие локальные минимумы может быть важнее чем способность их быстро найти по крайней мере для задач некоторой сложности. Если поверхность как на иллюстрациях в статье, тогда да, хорошо найти побыстрее какой-нибудь минимум. Но, если вспомнить, что настоящих локальных минимумов в задачах такой размерности почти не бывает, то то что нам касается локальным минимумом на самом деле седловина — один из коридоров лабиринта. Например такого:

И к чему это полотно текста? Во втором примере Вы специфицировали модель, для которой нашли локальные минимумы. Потрудились бы, что ли, доказать, что нельзя моделью с выпуклой поверхностью задачу решить.
Я не проверял лично, но я почти уверен
Вера – это про религию, а мы здесь науку / инженерию обсуждаем.
Вера – это про религию, а мы здесь науку / инженерию обсуждаем.
Жаль
Краткость – сестра таланта. Чем длиннее ваше описание, тем меньше шанс, что Вам удастся донести свою идею до собеседника. Более того, пространные рассуждения плохи ещё и тем, что если собеседник не согласен с одним из ранних тезисов, вся дальнейшая цепь импликаций бессмысленна.
Не имеет значения, география это или математика. Важно лишь то, что это воспроизводимые наблюдения, а Ваше утверждения основываются на частных примерах и "почти уверенности". Как если бы путник, случайно блуждающий в пустыне, говорил о том, что снега не существует.
В рассуждениях про локальные минимумы Вы противоречите себе:
способность миновать ближайшие локальные минимумы может быть важнее чем способность их быстро найти [...] настоящих локальных минимумов в задачах такой размерности почти не бывает, то то что нам касается локальным минимумом на самом деле седловина
Так если локальных минимумов почти нет, зачем же их избегать?
В рассуждениях про локальные минимумы Вы противоречите себе:
Так если локальных минимумов почти нет, зачем же их избегать?
Ну вообще-то это не я говорю а Карпаты и иже с ними
Это где он такое говорит, можно конкретную ссылку? Хочется избегать седловых точек, да, а вот локальные минимумы нас вполне устраивают (тем более, что их слишком мало, чтобы ими пренебрегать)
когда люди говорят «локальный минимум» в применении к нейросетям они обычно сталкиваются с седловыми точками
Не надо подменять понятия, седловые точки и локальные минимумы – разные вещи.
В статье указано, что при некоторых параметрах оптимизаторы могут выскакивать из глобального минимума, и сказано что это проблема. Почему? Разве нельзя просто запоминать, где был достигнут минимум функции ошибок, и возвращаться туда?
И ещё интересно, применяются ли для обучения НС какие-то методы непохожие на модификацию SGD? Имитации отжига, или ещё какие-нибудь необычные?
Разве нельзя просто запоминать, где был достигнут минимум функции ошибок, и возвращаться туда?и даже не оверфит самая большая проблема. Методы борьбы с ним, в конце концов, уже многочисленны. Дело в том.что чтобы узнать, что вы пришли в глобальный минимум вам нужно посчитать ошибку для всей имеющейся у вас выборки. А если ваша учебная выборка — несколько террабайт текстов из википедии это может быть немножечко затратно.
а и если обучать сеть с одними параметрами, затем изменить параметры, после чего продолжить обучать сеть — и получить какой-то хороший результат — это совсем не то же самое, что обучать сеть сразу со вторыми параметрами.
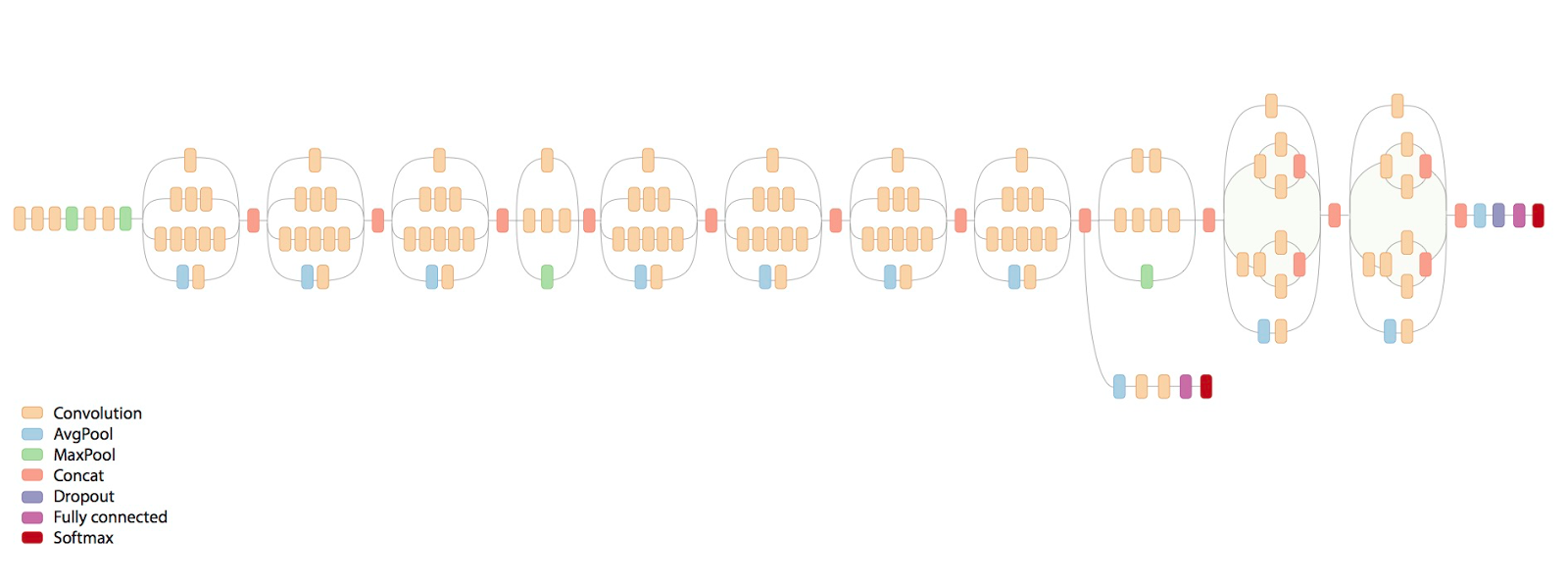 Если сразу учить всю эту гирлянду — эффект будет никакой. Берёте первый повторяющийся блок, к концу прикручиваете фулл-коннектед и софтмакс солои — учите. Потом отрубаете последние два слоя, до конката, вместо них добавляете ещё один повторяющийся блок и к нему фуллконнектед и софтмакс. Опять учите, и так 8 раз пока сеть не разрастётся до такой вот гирлянды. После чего добавляете на конец ещё одну надстройку с картинки и учите уже финально. Профит. Это я уже не конкретно эту сеть описывал, а вообще как учится весь класс сетей с такими архитектурами.
Если сразу учить всю эту гирлянду — эффект будет никакой. Берёте первый повторяющийся блок, к концу прикручиваете фулл-коннектед и софтмакс солои — учите. Потом отрубаете последние два слоя, до конката, вместо них добавляете ещё один повторяющийся блок и к нему фуллконнектед и софтмакс. Опять учите, и так 8 раз пока сеть не разрастётся до такой вот гирлянды. После чего добавляете на конец ещё одну надстройку с картинки и учите уже финально. Профит. Это я уже не конкретно эту сеть описывал, а вообще как учится весь класс сетей с такими архитектурами.А что касается неградиентных методов? Например метод бросания точек. Если я миллионы раз буду случайным образом выбирать параметры и смотреть, какой вариант лучше, не получится ли получить хороший результат?
Методы оптимизации нейронных сетей