Около 6 лет назад я участвовал в проекте по изготовлению железа и софта для одной крупной Североамериканской медицинской компании. Стоя возле тестовой стойки, в которой под нагрузкой было несколько устройств, я задал себе вопрос: «Если что-то пойдет не так, как нам ускорить поиск и исправление ошибки?»
С момента возникновения этого вопроса и до сегодняшнего дня было сделано очень много, и я хотел бы поделиться с вами тем как сбор и анализ телеметрии в софте и железе помог значительно снизить время обнаружения и исправления ошибок в целом спектре проектов, в которых я участвовал.
Введение
Телеметрия происходит от древнегреческого τῆλε «далеко» + μέτρεω — «измеряю».
Все очень просто, любые измерения, какие только может выдумать штат различных инженеров и возможно ученых, целевая система шлет в центр обработки для визуального и автоматического контроля и обработки.
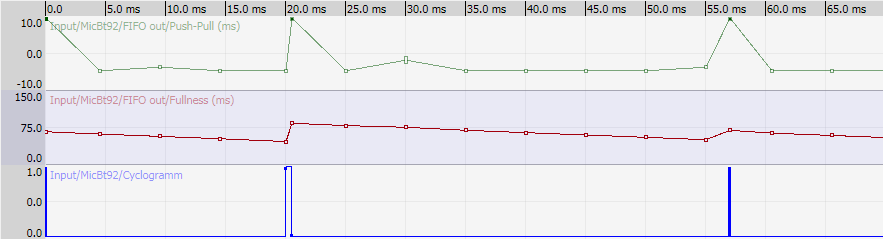
Приблизительно вот так:

Когда на стороне сервера это может например выглядеть вот так:
Предыстория
Как то, наблюдая за работой наших QA инженеров, я задался вопросом – почему сложные устройства вроде спутников, ракет, машин имеют телеметрию, а мы, создавая, по сути, программные части операционных комнат, роботов, сложных программных решений, даже не задумываемся об этом направлении?
Количество кода колоссально, а способов понять, что что-то пошло не так меньше чем пальцев на одной руке:
- Поставить точку останова, но для этого нужно пройти квест:
1) Быть достаточно удачливым и иметь доступ к целевой системе
2) Быть везучим и знать, как точно воспроизвести баг или ждать и еще раз ждать
3) Молиться, чтоб точка останова не разрушила внутреннее состояние системы (если внутри идут процессы реального времени)
- Клиент кричит в трубку, что exception в вашем коде это ни капельки не смешно и хорошо, что он был пойман его инженерами на тестовом стенде, а не когда пациент на столе, а вы в это время соображаете, что же это за exception
- Дзен вариант – анализ логов
- Анализ краш дампа
Параллельно наблюдая за работой наших QA инженеров, я смотрел на один из экранов, по которому бежали кривые сердцебиения пациента, его давления, температуры и кучи других параметров и мне захотелось, чтоб наши продукты были как этот пациент – под надежным присмотром. Чтоб даже если что-то пойдет не так, можно было отмотать время вспять и посмотреть, при каком стечении обстоятельств это произошло.
Велосипед или дай прокатиться
Как нас учили: велосипеды — это познавательно и увлекательно, но сначала поищите существующие решения, чем я и занялся.
По хорошей традиции начал с требований:
- Клиент-серверная архитектура (при отсутствии сервера возможность сохранять данные локально)
- Открытый исходный код
- Кросс-платформенный (как минимум Linux + Win)
- Удаленное управление (вкл/выкл счетчиков для сохранения ресурсов)
- Высокая производительность (по меркам С/С++ программ)
- Разумные требования к памяти, а лучше возможность управлять этим параметром
- Поддержка как минимум С/С++/Python
- Возможность писать скрипты или свой код для анализа телеметрии в real-time и/или off-line режимах
- Удобство просмотра в real-time и off-line режимах (субъективное требование)
Искал я долго и вдумчиво… но увы, все было не просто плохо, было все ужасно!
Под эти требования на момент начала 2011 года не попадал ни один проект, который я нашел, даже близко, даже половина требований.
Телеметрия для софта в виде готовых и открытых решений почти отсутствовала как класс, большие игроки делали для себя все сами и не особо спешили делиться.
Второй неожиданностью была реакция коллег – безразличие или в худшем случае неприятие, но, к счастью – это продлилось не долго, до первых результатов.
Единственное решение, которое я нашел на тот момент (2011 год), была библиотека P7 располагавшаяся в то время на google code. Функционал был беден, из платформ был только X86, на сервер было сложно смотреть без слез, но были и плюсы:
- высокая производительность
- бесплатно
- открытый исходный код
- возможность управлять (вкл/выкл) счетчиками удаленно (что выглядело заманчиво в плане сохранения CPU)
- А главное автор проекта с интересом отнесся к нашим идеям по улучшению.
После ряда раздумий, изучения, было решено попробовать прокатиться на чужом велосипеде.
Первый шаг
Встраивание библиотеки в наш код прошло легко и без проблем, но тут же возник вопрос: какие красивые графики мы хотим видеть и какие показания записывать? Это только, кажется, что вопрос прост, на самом деле – он сложен и коварен.
На первых порах и без опыта мы стали писать сравнительно ничтожное количество телеметрии:
- Загрузка CPU по ядрам и по основным потокам
- Количество handles, threads, objects, etc.
- Расход памяти
- Наполненность разных буферов
- Несколько циклограмм для особо важных потоков
К сожалению, скриншотов тех лет не сохранилось, и я приведу наиболее близкое приближение:

Первое же боевое крещение дало прекрасные результаты: после пары дней незаметной работы и воспроизведения нескольких багов мы, наконец-то, смогли понять природу многих из них:
- Чтение с диска заедало не потому, что диск был занят – был занят другой поток (вроде ни как не связанный с первым). Мы уже успели дать правдоподобное объяснение заказчику, потом добавили телеметрию … и … неудобно вышло.

На графике (кликабельно) видно, что задержки в потоке, читающем с HDD, удивительным образом совпадают с задержками в другом потоке, через 10 минут вглядывания в код был найден кусок, который вызывал такую зависимость.
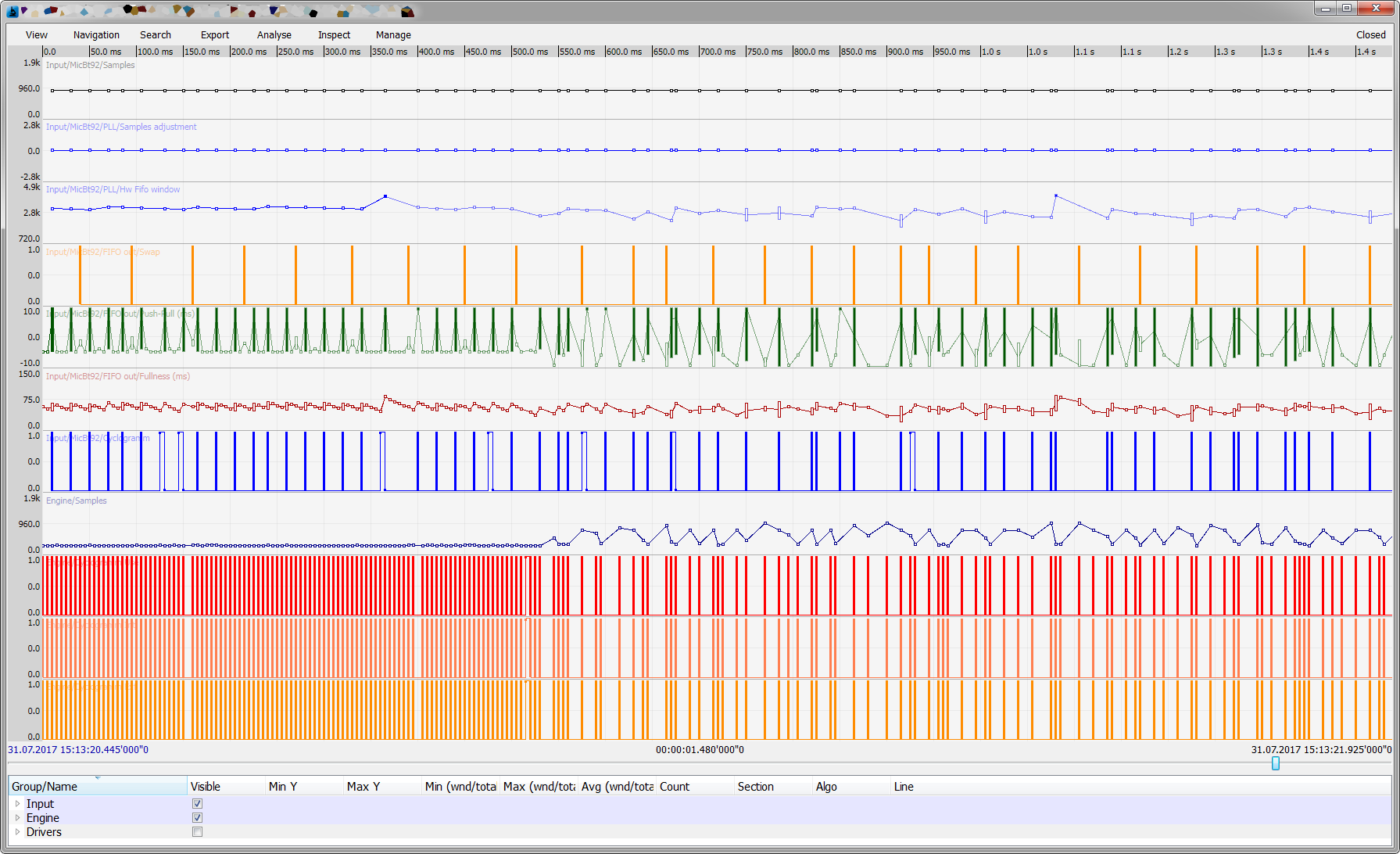
- Мы увидели периодические скачки по памяти, всего на несколько секунд, с последующим освобождением, освобождение иногда зависало, ибо менеджер памяти пытался переварить несколько тысяч элементов, возвращенных обратно.
Оказалось, что тестовый код с машины одного из инженеров попал в производство и регулярно подвешивал один из потоков, на пол секунды, на секунду. Эта проблема тоже была на графиках отчетливо видна – взлет CPU, memory, бешенная работа менеджера памяти и вдруг посередине он зависал на несколько сот миллисекунд (иногда до нескольких секунд):
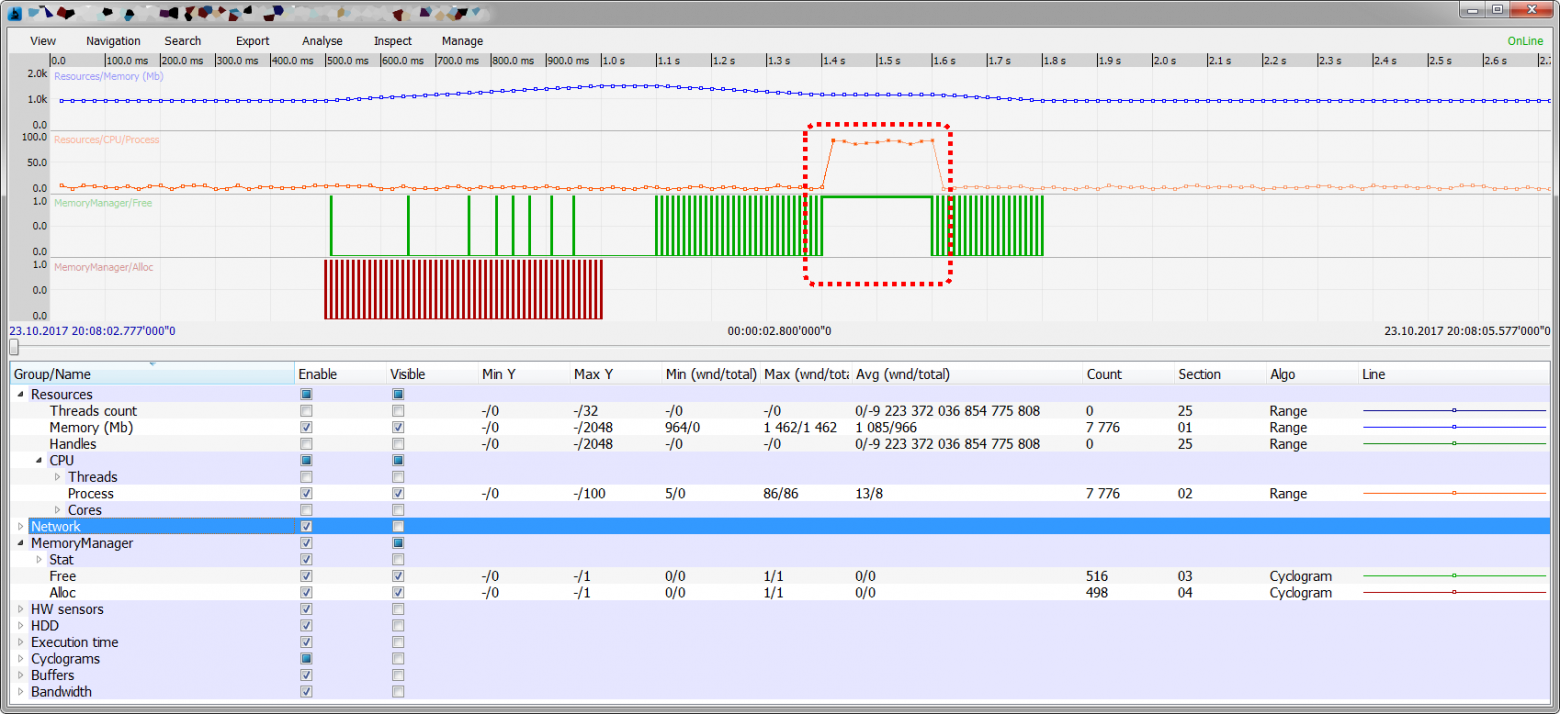
- Обработка данных с диска заедала, потому что буфер был пуст, а буфер был пуст по причине первого бага, что опять же отчетливо было видно на графике, а совпадающие временные метки телеметрии и логов говорили о взаимосвязи этих событий.

Были еще какие-то, исправленные в первый-второй день, но за давностью лет я уже не могу вспомнить, что это было.
После того как мы увлеченно с коллегами тыкали пальцами в монитор и вопрошали «¿Qué pasa?», находили ответ и радовались как дети – вопрос о полезности больше не стоял, мы получили новую игрушку и хотели играть дальше.
Переходим на бег
После первого успеха мы начали последовательно увеличивать количество обязательных счётчиков:
- Добавили телеметрию в виде циклограмм на основные потоки, сразу стало видно периодичность работы, мелкие и крупные зависания
- Добавили телеметрию в примитивы синхронизации (мютэксы, семафоры, критические секции).
- Добавили все возможные аппаратные сенсоры – «оказалось» температурные скачки коррелируют с целым рядом проблем
- Добавили счетчики загрузки различных аппаратных компонентов – memory bandwidth, registers access, PCI и мир заиграл новыми красками
- Замеры времени исполнения основных функций и блоков кода и когда после внесения изменений на тестах выявлялась регрессия в производительности – заинтересованные лица получали автоматический гневный email, с описанием какой счетчик после какого изменения кода показал регрессию
- Разумеется, помимо этих счетчиков инженеры добавляли кучи других, на время и на постоянной основе
Далее мы разбили счетчики на 3 группы:
- Генерирующие наибольший поток данных – эти счетчики наш софт обрабатывал только когда была связь с сервером и когда с сервера этот счетчик был включен руками одного из инженеров
- Генерирующие средний поток данных – эти счетчики наш софт обрабатывал только когда была связь с сервером, если связи с сервером не было — счетчик не тратил такты CPU, но как только связь появлялась – данные начинали отправляться
- Критические – эти данные должны были быть сохранены в любом случае, если нет связи с сервером то на HDD
И заключительным шагом было обновление процесса тестирования и внедрения практики, что ошибку, зафиксированную QA, должно сопровождать не только формальное описание, по возможности способ воспроизведения и лог файлы, но так же и телеметрия.
Заключение
В качестве заключения позвольте представить несколько фактов:
- Сейчас мы собираем внушительное количество телеметрии из целого спектра софта от С до C# и Python и вплоть до железа, собираем централизованно и не очень, в зависимости от задач
- Анализ телеметрии разделен на 3 блока:
- Автоматический (плагины к серверу)
- Полуавтоматический – в сервере есть возможность использовать свои скрипты Lua для дополнительного анализа, инженер сам решает какие и модифицирует/создает их под свои нужды
- Визуальный (метод внимательного вглядывания), звучит нелепо, но частенько тоже очень эффективно, особенно если не знаешь, что искать, а проблема есть
- Отчеты об ошибках от наших QA инженеров сопровождают ссылки на телеметрию
- Мы стали быстрее решать возникающие проблемы
Эта статья достаточно поверхностна и оставляет за кадром многие технические вопросы «а как получить загрузку CPU моим потоком», «а как сделать циклограмму моего потока», «а как вы делаете плагины» и тд и тп. Но если тема будет достаточно интересна – по всем этим пунктам можно сделать отдельные статьи.
Хотел бы надеяться, что эта статья позволит Вам задаться тем же вопросом что и мне «поможет ли телеметрия нашему продукту?», то можно сказать, что писал я ее не зря, так как в индустрии программного обеспечения этот вопрос невероятно редко звучит, бытует мнение, что это удел космоса и оборонки.
Спасибо за чтение!
PS: я намеренно не стал рассказывать про то нашу компанию и не буду — эта статья не о ней.
PPS: если вам интересно мы используем связку Jenkins + Baical + P7 (www.baical.net), для наших нужд она подходит хорошо, автор проекта за годы сотрудничества реализовал по нашей просьбе не одно и не два улучшения, помимо этого мы используем P7 для логирования (https://habrahabr.ru/post/313686/)

