Мы уже 2 года плотно общаемся с HFT трейдерами и разработчиками решений для HFT торговли. И испытываем некоторую неловкость от того, что никто в этой среде открыто не рассказывает о своих технологических успехах. Так как мы делаем устройства CEPappliance на основе FPGA, применимые в том числе для HFT торговли, мы неустанно интересуемся кто и как использует FPGA в этой сфере. Складывается навязчивое впечатление, что FPGA в HFT торговле, как секс у подростков — все о них говорят, но мало кто ими занимается, да еще и успешно.
На самом деле FPGA дает заметное преимущество по сравнению со всеми остальными технологиями (кроме, наверное, специализированных ASIC) в HFT и алгоритмический торговле. Наши тесты показывают, что заявка, пришедшая на Московскую биржу на 500 наносекунд быстрее других, будет исполнена первой с вероятностью 75%. То есть, если автоматическая торговая система быстрее других на 500 наносекунд принимает пакет (FAST, FIX или TWIME), разбирает его, обновляет книгу заявок (“стакан”), “понимает” что делать (создать/передвинуть/отменить ордер), формирует пакет с заявкой (FIX или TWIME) и отправляет его на биржу, то ее заявка будет исполнена раньше других в 75% процентах случаев.
Другие наши тесты показывают, что используя продвинутые сетевые платы и ряд трюков на CPU можно получить задержку tick-to-trade в 2-4 микросекунды для перцентилей 97% и выше. А можно ли получить задержку менее 1-1.5 микросекунды, чтобы быть быстрее подавляющего большинства HFT трейдеров?
На сегодня только FPGA1 может обеспечить такую задержку. И те, кто умеет извлекать из этого выгоду — HFT трейдеры, использующие FPGA — не спешат об этом рассказывать товарищам по цеху. Это затрудняет оценку нашего собственного решения, его позиционирование относительно конкурентов.
В этой статье мы в деталях расскажем о возможностях CEPappliance в применении к HFT торговле. Может быть, кто-то еще наберется смелости и расскажет о своем решении…
Чтобы обеспечить малую задержку реакции системы на сигнал с биржи, нужно как можно раньше “узнавать” о появлении этого сигнала. Для этого HFT система должна:
В CEPappliance все это реализовано непосредственно в FPGA, включая разбор сообщений в форматах FAST, FIX и TWIME (FIX SBE), в которых и транслируются сигналы с биржи.
После получения сигнала, торговая стратегия должна быстро сформировать реакцию. В CEPappliance алгоритм стратегии может быть реализован как непосредственно в FPGA, так и на языке высокого уровня HLL, программы на котором после компиляции выполняются оригинальными процессорами собственной разработки, размещенными на том же FPGA чипе.
Особняком стоят функции контроля за работой робота и его мониторинга: отслеживание состояния робота, его расчетов, изменение параметров стратегии и т.п.
В CEPappliance для этого есть
CEPappliance представляет собой FPGA плату с чипом Altera Stratix V, устанавливаемую в PCI слот сервера (достаточно высоты 1U). Взаимодействие с внешним миром осуществляется по 10Gb Ethernet через SFP+ порты или PCIe.
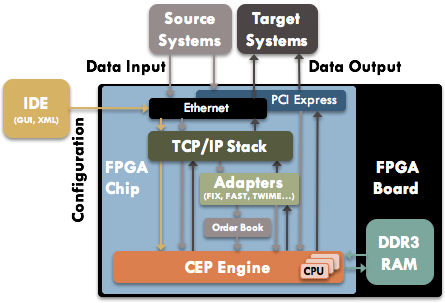
Все компоненты реализованы непосредственно на чипе и “заточены” на минимальную задержку. Прошивка (firmware) CEPappliance содержит все возможные компоненты. А их включение в цепочку обработки событий осуществляется с хоста при помощи специальной программы-конфигуратора. Сначала “железка” прошивается, затем запускается, а потом конфигурируется. Конфигуратор читает программу обработки событий (или схему), компилирует ее в карту внутренней памяти FPGA и загружает на CEPappliance по TCP. После загрузки конфигурации CEPappliance стартует описанные в схеме адаптеры и осуществляет подключение к внешним системам.
Для выполнения пользовательской логики в CEPappliance есть оригинальные процессоры (CPU) собственной разработки. Пользовательская логика записывается на HLL и компилируется в микропрограмму для процессоров, которых может быть несколько. Компилятор автоматически разобьет программу на независимые части, которые могут выполняться параллельно на разных процессорах. При разбиении программы учитываются поток управления и зависимости между операторами по данными.
Разработка на HLL и компиляция написанных на нем программ значительно проще и быстрее, чем на языках описания аппаратуры, используемых для программирования FPGA.
Благодаря возможности описывать торговые стратегии на языке высокого уровня программировать CEPappliance легче, чем программировать FPGA непосредственно на языках описания аппаратуры (Verilog, VHDL и т.п.) при сравнимых задержках. Программирование торговой стратегии на CEPappliance по простоте сравнимо с запуском той же стратегии с использованием языков C/C++, Java и т.п. благодаря наличию в CEPappliance готовых блоков сборки/разборки сообщений в соответствии с протоколами, сборки “стакана” и т.п., и однопоточной модели программирования (хотя на уровне микропрограммы выполнение может быть параллельным, как упоминалось ранее) при меньших задержках и джиттере (jitter). Позиционирование CEPappliance относительно других технологий, применяемых в HFT, в координатах “простота программирования” и “задержка” изображена на следующей диаграмме:

Для приближения скорости работы CEPappliance к скорости работы решения, полностью реализованного в FPGA, любую часть схемы можно реализовать непосредственно на Verilog. Для этого есть оператор <wire/> (см. ниже). При этом менее критичные к скорости части (например, управление торговым роботом, мониторинг) можно оставить на HLL. Такой подход позволяет получить максимальную скорость работы торгового робота при значительной экономии усилий на разработке.
Вот пример схемы, которая после получения обновления “стакана” USD000UTSTOM, строящегося на данных из потока ордеров (сообщения X-OLR-CURR) валютной секции Московской биржи, отправляет на биржу заявку на покупку по лучшей цене продажи:
Схема для CEPappliance представляет собой набор операторов, преобразующих входные потоки (streams) событий, получаемые через адаптеры от внешних систем, в выходные потоки событий, передаваемые через адаптеры во внешние системы.
Событие в схеме — это набор полей. Каждое поле имеет имя и тип. События имеют одинаковую структуру, если у них один и тот же набор полей, а именно количество, порядок, имена и типы полей совпадают.
Схема состоит из нескольких секций:
Обработку событий в CEPappliance можно концептуально описать так. Получив событие от внешней системы, адаптер ищет <input/>, через который событие должно быть передано в схему. Для этого проверяются условия фильтрации <accept/> каждого <input/>, подключенного к этому адаптеру. Если событие не удовлетворяет ни одному такому условию, то оно отбрасывается и никак не обрабатывается. Если подходящий <input/> найден, то событие передается операторам, для которых этот <input/> является входным. При этом в событии сохраняются только те поля, которые объявлены в <input/>. Остальные поля события отбрасываются и не передаются в схему.
Получив на входе одно событие, каждый оператор схемы, порождает другое (одно или несколько, как, например, <join/>) событие, набор и значения полей которого могут отличаться от входного. Только <combine/> не порождает новых событий а передает то, что получил на входе без изменений.
“Пройдя” по схеме, преобразовавшись не раз, а, может быть, и “размножившись” и “добравшись” до <output/>, событие отправляется через адаптер, указанный в этом <output/>. Одно и то же событие может быть отправлено в несколько разных адаптеров. <output/> определяет в виде какого сообщения (например, NewOrderSingle или OrderCancelReplaceRequest в FIX) событие будет отправлено наружу.
Это тот случай, когда часть схемы реализована на HLL, а другие ее части реализованы на Verilog. Части схемы, реализуемые на Verilog, описываются в схеме оператором <wire/>, поэтому мы такие части называем wire-логика.
Потоки, от которых wire-логика получаeт данные, перечисляются через запятую в атрибуте streams.
Тегами <param/> описываются параметры, которые wire-логика использует. В качестве параметров могут передаваться значения констант или переменных. При этом во время выполнения wire-логика может изменять значения переменных, используя специальный Verilog-модуль, после чего измененные значения будут доступны частям схемы на HLL.
Wire-логика может порождать несколько результирующих потоков, описываемых тегами <out/>, и которые могут идти сразу на выход схемы (операторы <output/>) либо в другие операторы схемы.
На основании такого описания создается конфигурация (карта памяти) wire-логики, которая через специальный Verilog-модуль доступна в пользовательском Verilog-модуле, реализующем wire-логику.
Чтобы реализация wire-логики стала частью итоговой прошивки для FPGA, код wire-логики на Verilog компилируется с прошивкой CEPappliance, поставляемой в виде Net-листа.
В наших планах разработка адаптеров для подключения к другим биржам. Для этого у нас есть задел в виде модулей FIX, FIX SBE и FAST. Например, для получения рыночных данных с Чикагской товарной биржи (Chicago Mercantile Exchange, CME) нужно “научить” наш FIX SBE модуль разбирать пакеты, которые содержат несколько FIX SBE сообщений и другую служебную информацию, отправляемую CME.
1Еще, конечно, специализированные ASIC могут, но нам не известны ASIC, которые бы разбирали, например, FAST или FIX. Имея аппаратную реализацию всех модулей в FPGA мы могли бы сами сделать специализированный ASIC и еще больше сократить задержки, но пока нам не хватает примерно 0,5-1 миллиона долларов для этого.
На самом деле FPGA дает заметное преимущество по сравнению со всеми остальными технологиями (кроме, наверное, специализированных ASIC) в HFT и алгоритмический торговле. Наши тесты показывают, что заявка, пришедшая на Московскую биржу на 500 наносекунд быстрее других, будет исполнена первой с вероятностью 75%. То есть, если автоматическая торговая система быстрее других на 500 наносекунд принимает пакет (FAST, FIX или TWIME), разбирает его, обновляет книгу заявок (“стакан”), “понимает” что делать (создать/передвинуть/отменить ордер), формирует пакет с заявкой (FIX или TWIME) и отправляет его на биржу, то ее заявка будет исполнена раньше других в 75% процентах случаев.
Другие наши тесты показывают, что используя продвинутые сетевые платы и ряд трюков на CPU можно получить задержку tick-to-trade в 2-4 микросекунды для перцентилей 97% и выше. А можно ли получить задержку менее 1-1.5 микросекунды, чтобы быть быстрее подавляющего большинства HFT трейдеров?
На сегодня только FPGA1 может обеспечить такую задержку. И те, кто умеет извлекать из этого выгоду — HFT трейдеры, использующие FPGA — не спешат об этом рассказывать товарищам по цеху. Это затрудняет оценку нашего собственного решения, его позиционирование относительно конкурентов.
В этой статье мы в деталях расскажем о возможностях CEPappliance в применении к HFT торговле. Может быть, кто-то еще наберется смелости и расскажет о своем решении…
Основные особенности HFT системы
Чтобы обеспечить малую задержку реакции системы на сигнал с биржи, нужно как можно раньше “узнавать” о появлении этого сигнала. Для этого HFT система должна:
- “слушать” множество различных потоков рыночных данных, в которых нужный сигнал может быть транслирован, например, потоки ордеров, сделок, статистики и т.д. — любой из этих потоков может быстрее других;
- реконсилировать несколько (2 или 4) фидов в рамках одного потока данных — любой из этих фидов может быть быстрее других, но данные не должны дублироваться;
- фильтровать потоки по значениям критериев, которые могут динамически меняться;
- строить “стакан” по данным из 2-х потоков, например, ордеров и сделок — любой из этих потоков может быть быстрее другого.
В CEPappliance все это реализовано непосредственно в FPGA, включая разбор сообщений в форматах FAST, FIX и TWIME (FIX SBE), в которых и транслируются сигналы с биржи.
После получения сигнала, торговая стратегия должна быстро сформировать реакцию. В CEPappliance алгоритм стратегии может быть реализован как непосредственно в FPGA, так и на языке высокого уровня HLL, программы на котором после компиляции выполняются оригинальными процессорами собственной разработки, размещенными на том же FPGA чипе.
Особняком стоят функции контроля за работой робота и его мониторинга: отслеживание состояния робота, его расчетов, изменение параметров стратегии и т.п.
В CEPappliance для этого есть
- логирование;
- зеркалирование всего (!) обмена между “железкой” и биржей без каких либо изменений на отдельном SFP+ порту FPGA платы;
- бинарные адаптеры для приема/передачи значений параметров стратегии и возможность их обработки с помощью HLL, что существенно ускорит и сократит затраты по сравнению с реализацией этой обработки на языке описания аппаратуры, например, Verilog;
- получение событий от адаптеров FIX и TWIME об установке/разрыве сессий для контроля состояния, в котором робот может нормально работать, имея все необходимые подключения.
Архитектура
CEPappliance представляет собой FPGA плату с чипом Altera Stratix V, устанавливаемую в PCI слот сервера (достаточно высоты 1U). Взаимодействие с внешним миром осуществляется по 10Gb Ethernet через SFP+ порты или PCIe.
Все компоненты реализованы непосредственно на чипе и “заточены” на минимальную задержку. Прошивка (firmware) CEPappliance содержит все возможные компоненты. А их включение в цепочку обработки событий осуществляется с хоста при помощи специальной программы-конфигуратора. Сначала “железка” прошивается, затем запускается, а потом конфигурируется. Конфигуратор читает программу обработки событий (или схему), компилирует ее в карту внутренней памяти FPGA и загружает на CEPappliance по TCP. После загрузки конфигурации CEPappliance стартует описанные в схеме адаптеры и осуществляет подключение к внешним системам.
Для выполнения пользовательской логики в CEPappliance есть оригинальные процессоры (CPU) собственной разработки. Пользовательская логика записывается на HLL и компилируется в микропрограмму для процессоров, которых может быть несколько. Компилятор автоматически разобьет программу на независимые части, которые могут выполняться параллельно на разных процессорах. При разбиении программы учитываются поток управления и зависимости между операторами по данными.
Разработка на HLL и компиляция написанных на нем программ значительно проще и быстрее, чем на языках описания аппаратуры, используемых для программирования FPGA.
Благодаря возможности описывать торговые стратегии на языке высокого уровня программировать CEPappliance легче, чем программировать FPGA непосредственно на языках описания аппаратуры (Verilog, VHDL и т.п.) при сравнимых задержках. Программирование торговой стратегии на CEPappliance по простоте сравнимо с запуском той же стратегии с использованием языков C/C++, Java и т.п. благодаря наличию в CEPappliance готовых блоков сборки/разборки сообщений в соответствии с протоколами, сборки “стакана” и т.п., и однопоточной модели программирования (хотя на уровне микропрограммы выполнение может быть параллельным, как упоминалось ранее) при меньших задержках и джиттере (jitter). Позиционирование CEPappliance относительно других технологий, применяемых в HFT, в координатах “простота программирования” и “задержка” изображена на следующей диаграмме:
Для приближения скорости работы CEPappliance к скорости работы решения, полностью реализованного в FPGA, любую часть схемы можно реализовать непосредственно на Verilog. Для этого есть оператор <wire/> (см. ниже). При этом менее критичные к скорости части (например, управление торговым роботом, мониторинг) можно оставить на HLL. Такой подход позволяет получить максимальную скорость работы торгового робота при значительной экономии усилий на разработке.
Схема (программа) HFT стратегии
Вот пример схемы, которая после получения обновления “стакана” USD000UTSTOM, строящегося на данных из потока ордеров (сообщения X-OLR-CURR) валютной секции Московской биржи, отправляет на биржу заявку на покупку по лучшей цене продажи:
Пример схемы для CEPappliance
<schema name="all-in-fpga"> <adapters> <fast name="moex-fx-fast-orderlog" templates="FIX50SP2-2017-Mar.xml"> <accept over="udp"> <on port="16001"> <multicast group='192.168.200.2'> <!-- IP-address of CEPappliance --> <source ip='192.168.200.1' /> <!-- IP-address of the host publishing FAST messages --> </multicast> </on> </accept> <trading venue='moex' market='fx' /> </fast> <fix name="moex-fx-fix" version="FIX.4.4"> <initiate over="tcp"> <to host="192.168.200.1" port="3336" /> </initiate> <sender> <comp id="cep" /> </sender> <target> <comp id="moex" /> </target> <heartbeat interval="30sec" /> </fix> </adapters> <global> <instruments> <instrument name='i_main' symbol='USD000UTSTOM' session='CETS' maxpricelevels='1000' /> </instruments> <!-- Price livel of the Order Book --> <type name='PriceLevel' def='tuple < money price, uint size >' /> <constant name='SIDE_BUY' type='uint' value="1" /> <constant name='SIDE_SELL' type='uint' value="2" /> <constant name='ACC_TRADE' type='string(32)' value="'ABCDE'" /> <constant name='ACC_CLIENT' type='string(32)' value="'OPQRSTUVWXYZ'" /> <variable name='LotSize' type='uint' value="50" /> <variable name='orderID' type='uint' value="1200000" /> <variable name='waterline' type='money' value="0" /> </global> <input from='moex-fx-fast-orderlog' as='orderlog'> <accept message='X-OLR-CURR' /> <sequence name='GroupMDEntries'> <field name='MDUpdateAction' type='uint' /> <field name='MDEntryType' type='string(1)' /> <field name='MDEntryID' type='string(16)' /> <field name='Symbol' type='string(16)' /> <field name='MDEntryPx' type='money' /> <field name='MDEntrySize' type='uint' /> <field name='TradingSessionID' type='string(8)' /> </sequence> </input> <!-- Order Book --> <book orders='orderlog' as='fxbook'> <accept instruments='i_main' /> <field name='instrument' type='uint' /> <field name='time' type='uint' /> <field name='book' type='tuple < PriceLevel bid, PriceLevel ask >[ 16 ]' /> </book> <!-- Calculate the best price --> <map stream="fxbook in" as="algo out" > <field name="price" type="money" expression="in.book[0].bid.price" /> <field name="size" type="uint" expression="in.book[0].bid.size" /> <program> money newWaterline = in.book[0].bid.price + in.book[0].ask.price; if(newWaterline == waterline) { skip; // do not send a new order } waterline = newWaterline; </program> </map> <!-- Increment orderID and use the new value to issue an Order. --> <!-- This operator caoud be merged with its source operator 'algo' and the compiler will do it for us --> <map stream='algo in' as='fix out'> <field name='ClOrdID' type='uint' /> <field name='OrderQty' type='uint' expression="in.size" /> <field name='Price' type='money' expression="in.price" /> <program><![CDATA[ orderID = orderID + 1; out.ClOrdID = orderID; ]]></program> </map> <output stream="fix" to="moex-fx-fix" > <as message="NewOrderSingle" /> <format field='MsgSeqNum' as="%5d" /> <format field='Account' as="{ACC_CLIENT}" /> <format field='ClOrdID' as="{ACC_TRADE}//%6d" /> <format field='HandlInst' as="1" /> <format field='OrderQty' as="%5d" /> <format field='OrdType' as="2" /> <format field='Price' as="%11m" /> <format field='Side' as="{SIDE_SELL}" /> <format field='Symbol' as="USD000UTSTOM" /> <format field='TransactTime' as="20170502-17:20:50" /> <format field='NoTradingSessions' as="1" /> <format field='TradingSessionID' as="CETS" /> <format field='NoPartyIDs' as="1" /> <format field='PartyID' as="{ACC_TRADE}" /> <format field='PartyIDSource' as="D" /> <format field='PartyRole' as="3" /> <format field='SecondaryClOrdID' as="8" /> </output> </schema>
Схема для CEPappliance представляет собой набор операторов, преобразующих входные потоки (streams) событий, получаемые через адаптеры от внешних систем, в выходные потоки событий, передаваемые через адаптеры во внешние системы.
Событие в схеме — это набор полей. Каждое поле имеет имя и тип. События имеют одинаковую структуру, если у них один и тот же набор полей, а именно количество, порядок, имена и типы полей совпадают.
Схема состоит из нескольких секций:
- <adapters/> описывает адаптеры, через которые схема получает/отправляет данные; доступны адаптеры <fast/>, <fix/>, <twime/>, <bin/>. <fast/> работает только на прием FAST сообщений по UDP датаграмм. <fix/> и <twime/> работают на прием и/или отправку по TCP сообщений FIX и TWIME (FIX Simple Binary Encoding), соответственно. <bin/> может работать как на прием, так и на отправку по TCP или UDP и используется, как правило, для управления работой торговой стратегией — запрос состояния, установка параметров и т.п. Описание адаптеров может быть вынесено в отдельный файл. Тогда можно одну и туже схему запускать с адаптерами, сконфигкрированными под разные окружения. Напрмер, для тестового окружения можно иметь одну конфигурацию адаптеров, а для “боевого” окружения — другую конфигурацию адаптеров.
- <global/> описывает финансовые инструменты <instruments/>, типы <type/>, константы <constant/> и (глобальные) переменные <variable/>, доступные в любой другой секции схемы.
- <input/>, <output/>, <book/>, <map/>, <combine/>, <aggregate/>, <join/>, <wire/> описывают операторы, применяемые к потокам событий, “проходящих” по схеме:
- <input/> принимает из адаптеров данные — входные поля схемы, задает им имена и типы, задает на входе фильтр <accept/> по типу сообщения;
- <output/> выводит данные, упаковывая/форматируя их в виде сообщения определенного типа <as message=’...’/>;
- <book/> строит “стаканы” для заданных инструментов <accept instruments=’...’/>; если после применения к стакану полученных изменений (транслируемых Московской биржей по протоколу FAST) он изменится, в схему будет отправлена “верхушка” измененного стакана — 16 лучших цен на покупку и 16 лучших цен на продажу в виде массива из 16 элементов типа PriceLevel; с “верхушкой” в схему также “прилетит” временная метка (поле time в <book/>), полученная из пакета с обновлениями, которую можно использовать для реконсиляции данных с другими потоками (например, с потоком статистики).
- <map/> преобразовывает данные согласно выражениям, заданным в выходных полях <field… expression=’...’ /> оператора, или в программе в секции <program/>;
- <combine/> объединяет несколько потоков в один;
- <aggregate/> вычисляет агрегирующие значения на последовательности <window/> событий, размер которой определяется либо временем накопления, либо количеством событий;
- <join/> объединяет, “склеивает” два потока событий по нескольким полям;
- <wire/> описывает часть схемы, которая реализована на Verilog.
Обработку событий в CEPappliance можно концептуально описать так. Получив событие от внешней системы, адаптер ищет <input/>, через который событие должно быть передано в схему. Для этого проверяются условия фильтрации <accept/> каждого <input/>, подключенного к этому адаптеру. Если событие не удовлетворяет ни одному такому условию, то оно отбрасывается и никак не обрабатывается. Если подходящий <input/> найден, то событие передается операторам, для которых этот <input/> является входным. При этом в событии сохраняются только те поля, которые объявлены в <input/>. Остальные поля события отбрасываются и не передаются в схему.
Получив на входе одно событие, каждый оператор схемы, порождает другое (одно или несколько, как, например, <join/>) событие, набор и значения полей которого могут отличаться от входного. Только <combine/> не порождает новых событий а передает то, что получил на входе без изменений.
“Пройдя” по схеме, преобразовавшись не раз, а, может быть, и “размножившись” и “добравшись” до <output/>, событие отправляется через адаптер, указанный в этом <output/>. Одно и то же событие может быть отправлено в несколько разных адаптеров. <output/> определяет в виде какого сообщения (например, NewOrderSingle или OrderCancelReplaceRequest в FIX) событие будет отправлено наружу.
Взаимодействие разнородных частей схемы
Это тот случай, когда часть схемы реализована на HLL, а другие ее части реализованы на Verilog. Части схемы, реализуемые на Verilog, описываются в схеме оператором <wire/>, поэтому мы такие части называем wire-логика.
<wire streams=”orderbook, stats” /> <param ref=”variable1” /> <param ref=”constant1” /> <out as=”todtom”> <field name='ClOrdID' type='uint' /> <field name='OrderQty' type='uint' /> <field name='Price' type='money' /> </out> </wire>
Потоки, от которых wire-логика получаeт данные, перечисляются через запятую в атрибуте streams.
Тегами <param/> описываются параметры, которые wire-логика использует. В качестве параметров могут передаваться значения констант или переменных. При этом во время выполнения wire-логика может изменять значения переменных, используя специальный Verilog-модуль, после чего измененные значения будут доступны частям схемы на HLL.
Wire-логика может порождать несколько результирующих потоков, описываемых тегами <out/>, и которые могут идти сразу на выход схемы (операторы <output/>) либо в другие операторы схемы.
На основании такого описания создается конфигурация (карта памяти) wire-логики, которая через специальный Verilog-модуль доступна в пользовательском Verilog-модуле, реализующем wire-логику.
Чтобы реализация wire-логики стала частью итоговой прошивки для FPGA, код wire-логики на Verilog компилируется с прошивкой CEPappliance, поставляемой в виде Net-листа.
Что дальше?
В наших планах разработка адаптеров для подключения к другим биржам. Для этого у нас есть задел в виде модулей FIX, FIX SBE и FAST. Например, для получения рыночных данных с Чикагской товарной биржи (Chicago Mercantile Exchange, CME) нужно “научить” наш FIX SBE модуль разбирать пакеты, которые содержат несколько FIX SBE сообщений и другую служебную информацию, отправляемую CME.
1Еще, конечно, специализированные ASIC могут, но нам не известны ASIC, которые бы разбирали, например, FAST или FIX. Имея аппаратную реализацию всех модулей в FPGA мы могли бы сами сделать специализированный ASIC и еще больше сократить задержки, но пока нам не хватает примерно 0,5-1 миллиона долларов для этого.

