
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Похоже, что достаточно просто собрать подходящие запросы, выбрать под них релевантные статьи других проектов и с нескольких сайтов публиковать их под разными URL, указывая текущее время и дату публикации. Возможно, один текст можно опубликовать ограниченное число раз, я встречал не так много копий. Они в основном обнаруживались в Google, не в Яндексе. Скорее всего для максимизации результата, сайты публикуют их в оптимальное время перед пиками дневного трафика в выбранной нише.
Определить дату, когда текст впервые появился в сети может даже любитель.Вы это серьёзно?
На самом деле это неумение Яндекса делает выдачу хуже.Кто бы спорил…
Есть множество причин, почему пользователям нужен оригинал текста, а не копипаст.Угу. А теперь — забег начинается: обьясняем каким поисковиком и с какими «бубнами» вы найдёте исходя из ключевых слов NeverCalled EraseAll вы найдёте ссылку на оригинал, скрытый под спойлером. И да, текст оттуда скопирован вполне себе дословно во все эти статьи (кроме последней — там из неё плакат сделали, потому немного переформатировали).
Яндексу я уже отправлял алгоритм поиска первоисточника.Серьёзно? Алгоритм в духе «Станьте ежиками. Если вы будете колючими, вас никто не съест!»
Что касается Ваших заданий, то я к Вам не нанимался. Поэтому пока Вам рано давать мне задания.Понятно. «Мое дело — стратегия! Вся эта ваша х&№ня с тактикой меня не интересует!».
Товар из "магазина" никуда не девается.
Хотя я с вами согласен, копировать чужой текст и выдавать за свой — нехорошо.
Типичная теория заговора.

Недавно пытался кросскомпилировать библиотеку APR с помощью MinGW, но завяз где-то в системных хедерах. Решил погуглить по запросу apache portable runtime mingw. Вторая ссылка в гугле ведёт на tomdeman <dot> com/apache-portable/apache-portable-runtime-mingw.html — шикарную по своей наглости и наивности страницу...

По-моему, объяснение куда проще. Сами ведь написали — эту выдачу дает новостной бот. Как обычно выглядят новости?
11.01.20ХХ — Из зоопарка нашего города сбежал бегемот.
13.01.20ХХ — Ночью в центре города кто-то повалил памятник Пушкину. В виду наличия следов крупного животного, подозревается бегемот. Напомним, что 11.01.20ХХ Из зоопарка нашего города сбежал бегемот.
15.01.20ХХ — Сбежавший бегемот вандал, все что известно на данный момент. Полиция загнала бегемота в здание мэрии. Напомним, что два дня назад ночью в центре города кто-то повалил памятник Пушкину. В виду наличия следов крупного животного, подозревается бегемот, который сбежал из зоопарка нашего города.
Какую из трёх статей вы хотели бы найти в поиске утром 15-ого числа?
А сайт тот же… Тексты те же… Ситуация повторяется буквально до «запятой».А почему вы считаете, что сайт, на котором ничего не меняется должен быть в выдаче выше сайтов, которые популярнее и нравятся пользователям больше?
Раньше Яндекс не с первого раза, но услышал. Сейчас не слышит и с сотого.Извините, но вы страдаете манией величия. Могу вас уверить, что ваш сайт ни в тот раз, ни в этот никто никуда не двигал. Просто в тот раз посмотрев на жалобы вебмастеров Яндекс решил, что дорвеев уж слишком много и начал их активно давить — а в этот раз, согласно его метрикам, проблема — не так остра. Вот и всё.
Что-то я не вижу откуда Вы взяли цитату „роботу все равно какой набор слов искать“Из вашей статьи, однако.
А даже если и не делается, то это не дает Яндексу право потакать ворам и показывать копипаст в выдаче вместо первопубликации.Почему нет? Задача Яндекса — привести человека туда, где ему понравится. А не установить «вселенскую справедливость».
Яндекс может запросто узнать, где первопубликация, а где вторичный контент. Во всяком случае в 2011 году у него с этим проблем не было.Были. И сейчас есть. А поскольку у спамеров есть задача — сделать для него это как можно более проблематичным, то это вечное соревнование «брони и снаряда».
И никакой суд не нужен. Копипаст ниже в выдаче. Этого достаточно.Ну то есть вы хотите, чтобы ваши проблемы за вас решал Яндекс. А почему он, собственно, должен это делать?
Судиться с каждым вором — жизни не хватит. Чем они и пользуются.
Я занимаюсь своим делом — создаю хороший контент. Вы — своим — создаете выдачу при которой первопубликация выше оригинала.А где это, я извиняюсь, Яндекс вам это обещал? Понижение сайтов без оригинального контента — далеко не всегда хорошая стратегия. Выкидывание новых сайтов «без разбору» — тоже.
Из Ваших слов получается, что Яндекс такой умный, что может определить, что интереснее пользователю, но такой глупый, что не может определить первоисточник…Из ваших слов получается, что говорить с вами о Яндексе бессмысленно чуть более, чем совсем. Яндекс — это не человек. Он не может быть умным или глупым.
Это, право, смешно.Это не смешно, это грустно.
Особенно если первоисточник не показывать, а показывать только копии.Ещё раз: для того, чтобы первоисточник найти — нужно сначала понять, что это — одинаковые сайты. А это — ни разу не очевидно бывает. Есть разные способы обойти сравнивалку: часть букв заменить на латинницу. Или нпаиасть солва нмеонго по дургмоу (я утрирую, но суть понятна?). Поверьте — люди, которые ваши тексты компируют знают об алгоритме, которым Яндекс определяет одинаковые статьи чуть ли не больше, чем Яндекс… что не значит, конечно, что с ними не нужно бороться… но не нужно выставлять это как «проблема выеденного яйца не стоит — а Яндекс не смог».
«И сейчас есть». Ну так используйте. Или пополните свои знания посредством анализа web.archive.org — хотя бы старые первоисточники определите верно.Когда вашу статью копирует к себе какое-то веб-сайт — то это проблема, ужас, качмар. Когда Яндекс пойдёт и в нарушение лицензии заберёт себе web.archive.org — то это нормально. Странные у вас какие-то двойные стандарты.
Где Яндекс мне это обещал? В правилах для вебмастеров. Обещал для всех, не только для меня.Стараться — стремиться, хотеть сделать что-либо. Обещаний — вижу.
Яндекс-Вебмастер-Некачественные сайты:
«Создавайте сайты с оригинальным контентом или сервисом.»
«Мы стараемся не индексировать или не ранжировать высоко:
Объясняю. В поисковую строку Яндекса можно было на момент написания той статьи поместить до 40 слов (так писал Яндекс). И в данном абзаце речь шла о поиске цитаты. Например, стихотворной строчки. И роботу ставилась простая задача — найти цитату.А вот это — собственно: вишенка на торте. Дело в том, что эта «простая задача» — это «не по-профилю». Обычная поисковая система на это в принципе неспособна. Найти текст по одному слову для неё — раз плюнуть, по двум — уже сложнее, по 40 — это почти катастрофа. Ну вот так сложилось. Потому что люди по двум-трём-пяти словам ищут чаще, чем по длинным кускам текста. И вся организация данных «заточена» под поиск по небольшому числу слов. Инвертированный индекс, вот это вот всё.
Объясняю. В поисковую строку Яндекса можно было на момент написания той статьи поместить до 40 слов (так писал Яндекс). И в данном абзаце речь шла о поиске цитаты. Например, стихотворной строчки. И роботу ставилась простая задача — найти цитату.
А вот это — собственно: вишенка на торте. Дело в том, что эта «простая задача» — это «не по-профилю». Обычная поисковая система на это в принципе неспособна. Найти текст по одному слову для неё — раз плюнуть, по двум — уже сложнее, по 40 — это почти катастрофа. Ну вот так сложилось. Потому что люди по двум-трём-пяти словам ищут чаще, чем по длинным кускам текста. И вся организация данных «заточена» под поиск по небольшому числу слов. Инвертированный индекс, вот это вот всё.
Часто бывает, что по одной фразе из текста правильно определяет первоисточник, а по другой — ставит копипастеров на первое место. Почему так?А давайте я вам задам другой вопрос: а почему иногда Alpha Go ставит камень на доске туда, а иногда — сюда?
Это пригодилось бы вебмастерам для выбора на чем мне фокусировать усилия — добиваться удаления дубликатов или улучшать качество сайта.А ещё больше это пригодилось бы спамерам.
Интересно, сотрудники поддержки Яндекса могут видеть в выдаче пометки кого алгоритмы считают плагиатором, а кого — нет?И да — и нет. Не знаю — могут ли они получить эту информацию (скорее всего да), но знаю, что проинтерпретировать её — они не могут (просто потому, что это действительно очень сложно — там сотни параметров).
А ещё больше это пригодилось бы спамерам.
Как вы думаете — у кого больше времени и желания «подкручивать» сайты, чтобы они проходили через фильтры? У вебмастеров? Или у спамеров?
проинтерпретировать её — они не могут (просто потому, что это действительно очень сложно — там сотни параметров)
Так можно про все инструменты панели вебмастера Яндекса сказать. Но Яндекс их развивает.Очень осторожно и «в час по чайной ложечке». Уверяю вас — там по поводу каждой фичи идёт война с попытками оценить — кому это поможет больше: нормальным вебмастерам или спамерам.
Мне кажется, что за уникальность контента должно отвечать значительно меньше параметров.С уникальностью контента всё вообще очень плохо. Если даже отмести смешную и незаконную идею проиндексировать вебархив, то и у Гугла и Яндекса есть своя история — пусть не уходящая так глубоко в прошлое, как вебархив.
Вебархив тот же сайт, только огромный, хранящий копии всех сайтов за разные даты.Совершенно верно.
Индексируется, сравнивается, определяются первопубликации.Только если вы ia_archiver, извините. Alexa — может это делать, Яндекс — нет. О чём и человеческим языком в соответствующем соглашении написано.
А потом… то ли мозгов не осталось, то ли базы накрылись, то ли Яндекс сам решил покопипастить… то ли все вместе.Или копи-пастеры поумнели. Или вы такого варианта в принципе не допускаете? А почему, собственно? Яндекс может стать хуже, копи-пастеры не могут стать лучше?
Если бы Яндекс хотел разобраться с копипастом, то он давно бы это сделал. Как я уже говорил, в 2010 году Яндекс этот механизм имел и копипаст был в выдаче ниже оригинала.Некоторый копи-паст находился ниже некоторых оригиналов — ну так это и сейчас так. А некоторый — выше.
За 5 лет 3000 сотрудников Яндекса не смогли восстановить (даже не придумать, ибо он был) алгоритм определения оригинала и выдачи его выше копии… это надо очень постараться…А может у них и другие задачи есть, кроме борьбы с ветряными мельницами?
Может сотрудников Яндекса охрана к компам не подпускает и они ходят на работу только кофе пить?
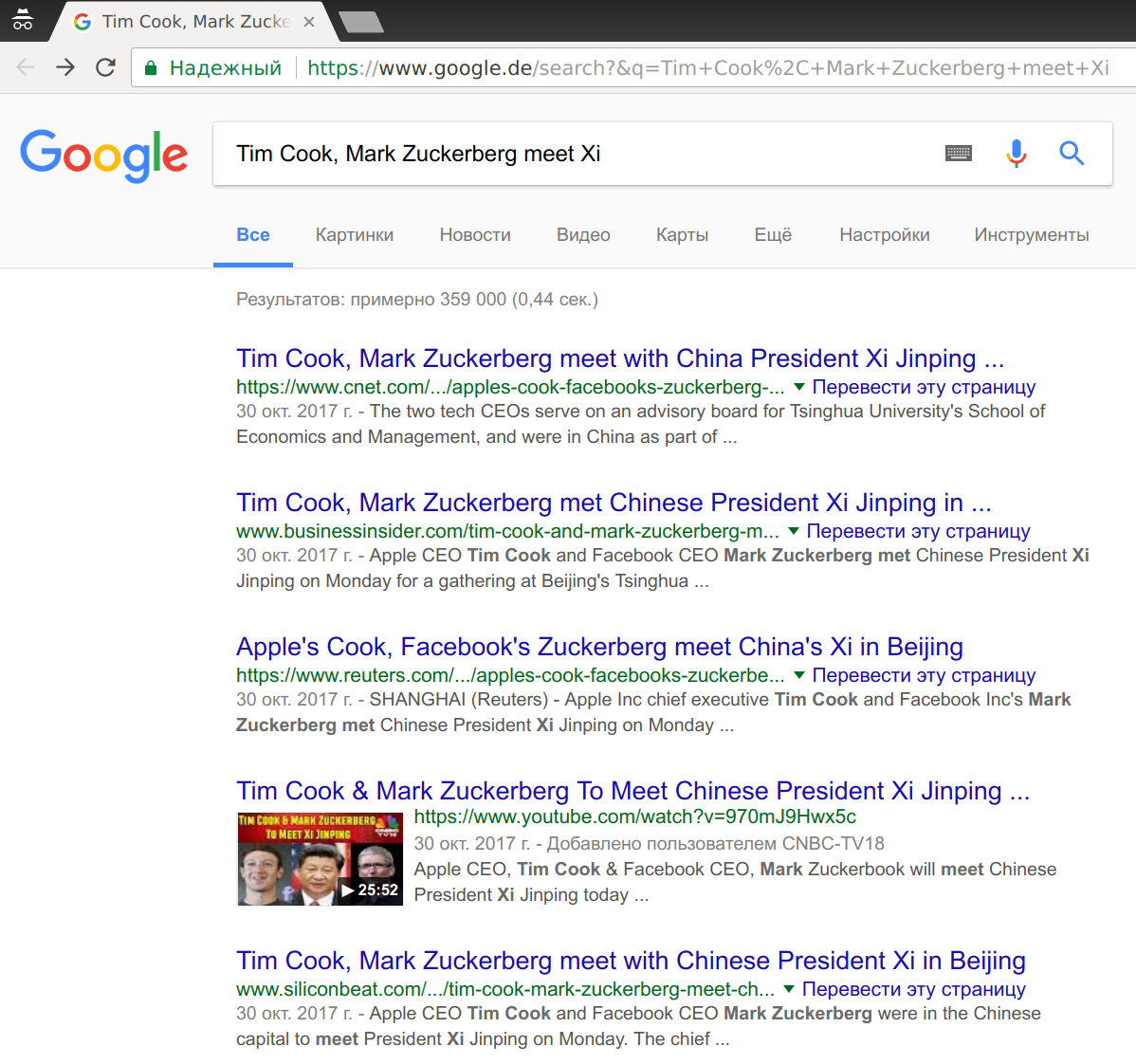
Нет. Не «некоторый». В 2010 году любой копипаст был ниже оригинала.Это и сегодня так. Какая-нибудь статья на тему Tim Cook, Mark Zuckerberg meet Xi не обязательно будет вести на сайт агентства «Рейтер» в первом результате. Да, обычно агенство «Рейтер» будет где-то там, наверху — но не потому, что они «авторы оригинальной новости», а потому, что сам сайт «Рейтер» имеет более высокие оценки — туда реальные люди ходят и вообще…
Смените тон, начните уважать собеседника и все изменится.Нет, разумеется. Тон был бы важен, если бы я хотел от вас чего-то добиться или просто хотел бы утвердить своё ЧСВ. Я же просто хочу докопаться до истины. Не «донести имеющуюся у меня истину до немытых масс», не «заставить собеседника сделать то, чего я хочу», а просто «понять что происходит»
«Это и сегодня так.» Нет, не так. И эта публикация и ее обсуждение это доказывают.Чёрт. Сказал вещь строго противоположную той, которую хотел сказать. Извиняюсь. Я хотел сказать, что оригинал и тогда и сейчас мог быть выше копий — а мог быть и ниже.
«Тон был бы важен» Тон важен всегда. Ваша тактика — попытаться унизить собеседника переходом на личности и таким образом возвыситься.Нет — не возвыситься. А проверить — что для вас важнее: истина или ЧСВ.
Потому что 5 лет непубличной переписки не привели к результату — копипаст как был, так и остается выше оригинала в выдаче.И ещё 5 лет переписки результат не изменят. Как Яндекс, так и Гугл иногда ставят оригинал выше копии, иногда — наоборот. Так было, есть и будет.
Мессию я из себя не строю. Просто отстаиваю свои права как создателя контента. И права других создателей.А откуда эти права взялись, я извиняюсь? В законе — о них ни звука. От Бога? Ну тогда вы — мессия… ну или в душе считаете себя мессией…
И Яндексу он нужен. Это база. Яндекс — надстройка, сервис. Без контента не было бы Яндекса.А без Кирилла и Мефодия не было бы контента — но мы почему-то не видим их потомков, бегающих по форуму и пытающихся стрясти со всех немножко денег себе в карман.
Так а при чем здесь Гуугл.Чтобы была понятна необоснованность ваших претензий. А то вы тут рассказываете сказки, что Яндекс, типа ваше «богом данное право» не уважает, а Гугл (а не Гуугл, кстати — у него <a href-«sbis.ru/contragents/7704582421/770501001»>русское юрлицо есть) — уважает.
Так что у меня и других авторов есть полное право предъявить Яндексу претензии.Вы можете предьвлять к нему любые претензии, но пока вы не докажите, что Яндекс сознательно опускал ваш сайт в результатах поиска — ничего не изменится.
подавляющее большинство «контента» создаётся на основании другого «контента»
А вы попереписывайтесь лет 5 без результата. Посмотрим, как вы запоете.Никак не запою. Потому что обычно уже через две-три недели становится ясно, что результата нет — и не будет. Никогда. Ни через месяц, ни через год, ни через пять, ни через десять лет. После чего следует остановиться, разобраться в том, что происходит — и понять что делать дальше. Не пытаясь «пробить головой стену».
Думаю, что с Вашим высокомерием, вы начали бы орать дня через три.Ну орать-то зачем. Думать надо — причём с самого первого дня. Тогда и орать не придётся.
Моя беда не в этом, а в том, что Яндекс показывает копии выше первопубликации или вместо первопубликации.И Яндекс и Гугл и другие поисковики в некоторых случаях это делают, да.
Я понимаю, что ваша цель меня «заткнуть». Вы в ней не преуспеете, так что «успокойтесь, пожалуйста»И снова ваше ЧСВ не даёт вам возможности увидеть чего я действительно хочу.
Посмотрите на этот бред.Посмотрел. Хороший результат работы нейронной сети, которая призвана убедить другую нейронную сеть в том, что в этом «потоке сознания» есть смысл.
А также обратите внимание, что даты статей — последние дни. Это к предположению про закос под новости.Похоже на то. Видимо полноценного анализа для «новых» статей Яндекс не делает (ресурсов не хватает или времени слишком много требуется) — вот и лезет этот мусор…
Да, с описанной в посте проблемой все ясно, мы перешли к обсуждению в целом проблемы копирования контента и отношения Яндекса к этому.Это глубоко философская тема. С одной стороны, понятно, что оригинальный контент — это вроде как лучше, с другой — «ничто не ново под луной». Буратино — это персказ Пиноккио, Диснеевкая Ариэль — родилась из вариации известной сказки, да и вообще почти любая статья или сериал основаны на чём-то, что кто-то другой придумал.
Мне кажется, что мотивация производителей контента и демотивация плагиаторов все-таки в интересах поисковиков.Конечно.
Сайты, которые массово копируют контент других сайтов или агрегируют без дополнительной ценности, в итоге не получают трафика.Да — но что значит «без дополнительной ценности»? Почему вы считаете CNN или BusinessInsider — создают ценность, а lady-day — нет?
У Гугла, например, есть возможность отправить DMCA жалобу, после которой страницу-плагиатор исключают из выдачи.Да — но DMCA это не инициатива Гугла, а федеральный закон. В России подобного нет.
Раздел «Оригинальные тексты», видимо, был попыткой в этом направлении, но что-то пошло не так.Каталоги не работают с какого-то момента. Когда интернет был маленьким и относительно «чистым» — они работали, сегодня — нет. Гугл пытался использовать DMOZ (когда тот был ещё жив), но от него было больше вреда, чем пользы. Рамблер на своих каталогах выезжал какое-то время, но в конце-концов тоже от них ушел…
Как черные SEO-оптимизаторы собирают миллионы посетителей по высоко-актуальным запросам в Яндексе