
Теория вероятности никогда не переставала меня удивлять, начиная ещё с того момента, как я впервые с ней столкнулся, и до сих пор. В разное время в разной степени меня настигали, назовём их «вау-эффекты», шоковые удары в мозжечок, от которых меня накрывало эффектом третьего ока, и мир навсегда переставал быть прежним.
- Первый «вау-эффект» я испытал от Центральной предельной теоремы. Берем кучу случайных величин, устремляем их количество в бесконечность и получаем нормальное распределение. И совсем неважно как распределены эти величины, неважно, будь это подбрасывания монетки или капли дождя на стекле, вспышки на Солнце или остатки кофейной гущи, результат будет всегда один — их сумма всегда стремится к нормальности. Разве что, нужно потребовать их независимость и существование дисперсии (позднее я узнал, что существует теорема и для экстремальных тяжелохвостых распределений с бесконечной дисперсией). Тогда этот парадокс долго не давал мне заснуть.
- В какой-то момент учебы в университете такие предметы как дискретная математика и функциональный анализ слились вместе и всплыли в теорвере под видом выражения «почти наверное». Стандартный пример: вы случайно выбираете число от 0 до 1. С какой вероятностью вы ткнёте в рациональное число (привет, функция Дирихле)? Спойлер: 0. Ноль, Карл! Бесконечное множество не имеет никакой силы, если оно счетно. У вас бесконечное число вариантов, но вы не выберете ни один из них. Вы не выберете 0, или 1, или 1/2, или 1/4. Вы и не выберете 3/2.
Да-да, что выбрать 1/2, что выбрать 3/2, вероятность нулевая. Вот только в 3/2 вы не ткнёте точно, таковы условия, а в 1/2 вы не попадёте ну… «почти наверное». Концепция «почти всюду»/«почти наверное» забавляет математика, а обывателя заставляет крутить пальцем у виска. Многие ломают себе мозг в попытке классифицировать нули, но результат того стоит. - Третий по счёту, но не по силе, «вау-эффект» настиг уже на переходе в advanced level
— при чтении книг по стохастическим исчислениям. Причиной тому стала лемма Ито. Со времён школьной скамьи, когда нашим девственным глазам впервые показали производную, мы нисколько не сомневались в правильности вот такой вот формулы:
И она верна. Вот только, если
 — это не случайный процесс. Адовая смесь из свойств нормального распределения и «почти наверное» доказывает, что в обратной ситуации эта формула в общем случае неверна. Томик мат.анализа с решениями обыкновенных дифференциальных уравнений теперь можно выкинуть в топку. Люди в теме тихо хихикают, остальные нетерпеливо листают статьи в Вики с исчислениями Ито.
— это не случайный процесс. Адовая смесь из свойств нормального распределения и «почти наверное» доказывает, что в обратной ситуации эта формула в общем случае неверна. Томик мат.анализа с решениями обыкновенных дифференциальных уравнений теперь можно выкинуть в топку. Люди в теме тихо хихикают, остальные нетерпеливо листают статьи в Вики с исчислениями Ито.
Но совсем недавно я испытал и четвёртый, так называемый, «вау-эффект». Это не какой-то отдельно взятый факт, а целая теория, которую я собираюсь поведать в серии из нескольких статей. И если предыдущие финты теории вероятности вас уже не удивляют, то прошу милости под кат (знаю, вы и так уже здесь).
Полиномы Эрмита
Начнем с обыкновенной алгебры — определим «вероятностные» (они немного отличаются от «физических») полиномы Эрмита:


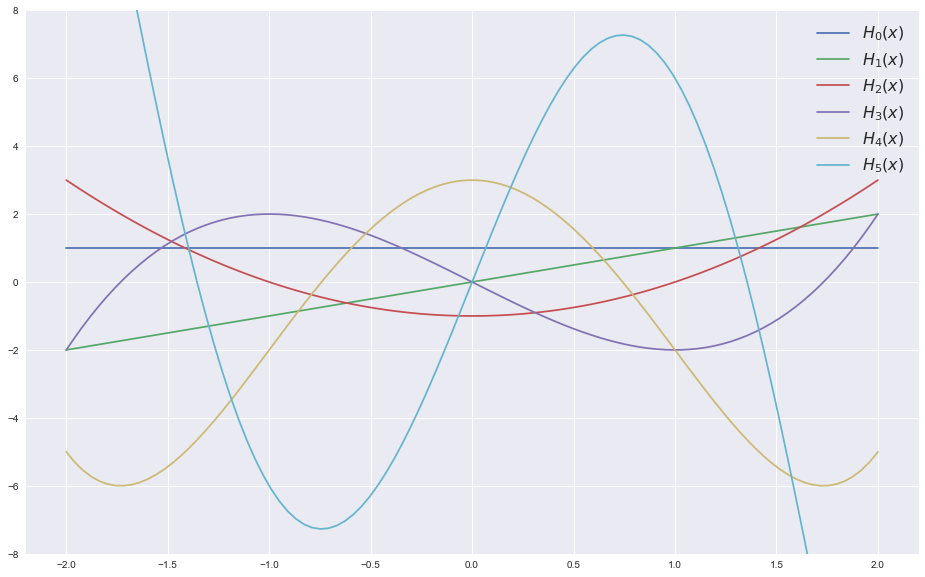
Полиномы Эрмита обладают следующими свойствами:



Последнее соотношение поможет нам в вычислении
 -ых полиномов Эрмита для заданного
-ых полиномов Эрмита для заданного  . Программироваться мы будем на Haskell, ибо он позволяет математикам выражаться на привычном им языке — Haskell чист, строг и прекрасен как сама математика.
. Программироваться мы будем на Haskell, ибо он позволяет математикам выражаться на привычном им языке — Haskell чист, строг и прекрасен как сама математика.-- | 'hermite' is an infinite list of Hermite polynomials for given x hermite :: (Enum a, Num a) => a -> [a] hermite x = s where s@(_:ts) = 1 : x : zipWith3 (\hn2 hn1 n1 -> x * hn1 - n1 * hn2) s ts [1..]
Функция hermite принимает на вход параметр
, а на выходе даёт бесконечный лист из -ых полиномов для  Кто не знаком с концепцией ленивых вычислений, очень советую ознакомиться. Для тех же, кто эту концепцию знает, но ещё не до конца может в функциональное программирование: что здесь происходит? Представьте, что у нас уже есть бесконечный лист со всеми значениями Эрмитовых полиномов:
Кто не знаком с концепцией ленивых вычислений, очень советую ознакомиться. Для тех же, кто эту концепцию знает, но ещё не до конца может в функциональное программирование: что здесь происходит? Представьте, что у нас уже есть бесконечный лист со всеми значениями Эрмитовых полиномов:s = [1, x, x^2-1, x^3-3x, x^4-6x^2+3, ... ]
Хвост этого листа (без первого элемента):
ts = [x, x^2-1, x^3-3x, x^4-6x^2+3, ... ]
Вдогонку мы возьмем ещё лист с натуральными числами:
[1, 2, 3, ... ]
Функция zipWith3 комбинирует последние три листа, используя данный ему оператор:
x * [ x, x^2-1, x^3-3x, ... ] - [ 1*1, 2*x, 3*(x^2-1), ... ] = [x^2-1, x^3-3x, x^4-6x^2+3, ... ]
Добавляем впереди 1 и x, и получаем полный набор Эрмитовых полиномов. Иными словами, мы достали лист со значениями полиномов, используя лист с этими значениями, то есть, лист, который мы и пытаемся достать. Поговаривают, что полное осознание красоты и мощи ФП сродни умению заглянуть себе в ухо.
Проверим: первые 6 значений для
 :
:Prelude> take 6 (hermite 1) [1,1,0,-2,-2,6]
Что мы и ожидали увидеть.
Гильбертово пространство
Двинемся немного в другую степь — вспомним определение пространства Гильберта. Говоря научным языком, это полное метрическое линейное пространство с заданным на нём скалярным произведением
 На этом пространстве каждому элементу соответствует вещественное число, именуемое нормой и равное
На этом пространстве каждому элементу соответствует вещественное число, именуемое нормой и равное 
- Самый простой пример — это пространство вещественных чисел:
 . В таком случае скалярным произведением двух чисел и
. В таком случае скалярным произведением двух чисел и  у нас будет
у нас будет 
- Затем я перехожу в Эвклидово пространство
 . Теперь
. Теперь
Это пространство можно расширить до пространства комплексных векторов:
 , для которого скалярное произведение будет
, для которого скалярное произведение будет
(верхняя черта обозначает комплексное сопряжение).
- Ну и наконец прихожу в пространство для взрослых, пространство с бесконечной размерностью. В нашем случае это будет пространство квадратично интегрируемых функций, заданных на некотором множестве
 с заданной мерой
с заданной мерой  . Мы будем его обозначать в виде
. Мы будем его обозначать в виде  . Скалярное произведение на нем задается следующим образом:
. Скалярное произведение на нем задается следующим образом:
Обычно под множеством подразумевается интервал
подразумевается интервал ![$[a,b]$](https://habrastorage.org/getpro/habr/formulas/58b/7f7/be8/58b7f7be8c846796f6af0f80072b3431.svg) , а под мерой — равномерная мера (мера Лебега), т.е.
, а под мерой — равномерная мера (мера Лебега), т.е.  . И тогда скалярное произведение записывается в виде обыкновенного интеграла Лебега
. И тогда скалярное произведение записывается в виде обыкновенного интеграла Лебега
Если же мы думаем в терминах теории вероятностей, то — это пространство элементарных событий,
— это пространство элементарных событий,  и
и  — случайные величины, а — вероятностная мера. У каждой такой меры есть своя функция плотности распределения
— случайные величины, а — вероятностная мера. У каждой такой меры есть своя функция плотности распределения  , которая может быть отличной от константы, тогда
, которая может быть отличной от константы, тогда  и скалярное произведение совпадает с математическим ожиданием:
и скалярное произведение совпадает с математическим ожиданием: ![$\langle X, Y \rangle=\int_\Omega X(\omega) Y(\omega) \rho(\omega)d\omega = \mathbb{E}[XY].$](https://habrastorage.org/getpro/habr/formulas/785/bb1/280/785bb12802c753c17698203c5a300bba.svg)

Гауссовский процесс
Настало время внести в наши размышления элемент случайности. Пусть у нас имеется гильбертово пространство
 . Тогда мы назовем
. Тогда мы назовем  (изонормальным) Гауссовским процессом, если
(изонормальным) Гауссовским процессом, если - вектор из случайных величин
 распределен нормально с нулевым мат.ожиданием для любых
распределен нормально с нулевым мат.ожиданием для любых  , и
, и - для

![$\mathbb{E}[W(h)\cdot W(g)] = \langle h, g \rangle.$](https://habrastorage.org/getpro/habr/formulas/b90/a55/fe8/b90a55fe8a95ebea3b85d3644c647242.svg)
По своей математической сути
 — это отображение из одного гильбертова пространства в другое, из некоторого в
— это отображение из одного гильбертова пространства в другое, из некоторого в  — вероятностное пространство из случайных величин с конечной дисперсией, заданного триплетом (множество элементарных событий),
— вероятностное пространство из случайных величин с конечной дисперсией, заданного триплетом (множество элементарных событий),  (сигма-алгебра) и
(сигма-алгебра) и  (вероятностная мера). Несложно показать, что это отображение линейно:
(вероятностная мера). Несложно показать, что это отображение линейно: 
Пример. Пусть
 , где
, где  — равномерная мера (Лебега). Скалярное произведение на нём
— равномерная мера (Лебега). Скалярное произведение на нём 
![$h(s) = 1_{[0,t]}(s)$](https://habrastorage.org/getpro/habr/formulas/c34/fe7/698/c34fe7698d8fede9457c5c1fd8fe577e.svg) — единичная функция на интервале
— единичная функция на интервале ![$[0,t]$](https://habrastorage.org/getpro/habr/formulas/9a9/a59/558/9a9a59558e4bbe90359d92a377011d54.svg) . Тогда
. Тогда ![$\| h\|^2 = \int 1_{[0,t]}(s)ds = t$](https://habrastorage.org/getpro/habr/formulas/dd6/69a/408/dd669a40843e3a291701bf84a0628028.svg) и
и ![$B(t)=W(1_{[0,t]}) \sim \mathcal{N}(0,t)$](https://habrastorage.org/getpro/habr/formulas/456/329/89a/45632989a4322e5ef4c8ad74abbbe657.svg)
![$\int_0^t f(s)dB(s) = W(1_{[0,t]} f)$](https://habrastorage.org/getpro/habr/formulas/53e/98f/897/53e98f8974d1bdd19d7cd5b2fc473c5a.svg)
 относительно
относительно  .
.Для того, чтобы реализовать Гауссовский процесс я воспользуюсь пакетами, которые благородные люди уже написали за нас.
import Data.Random.Distribution.Normal import Numeric.LinearAlgebra.HMatrix as H -- | 'gaussianProcess' samples from Gaussian process gaussianProcess :: Seed -- random state -> Int -- number of samples m -> Int -- number of dimensions n -> ((Int, Int) -> Double) -- function that maps indices of the matrix into dot products of its elements -> [Vector Double] -- m n-th dimensional samples of Gaussian process gaussianProcess seed m n dotProducts = toRows $ gaussianSample seed m mean cov_matrix where mean = vector (replicate n 0) cov_matrix = H.sym $ (n><n) $ map (\i -> dotProducts (quot i n, rem i n)) [0..]
Функция gaussianProcess принимает параметр seed (стандартная штука для генераторов), nSamples — размер выборки, dim — размерность вектора
 , dotProducts — функцию, принимающую на вход
, dotProducts — функцию, принимающую на вход  , индекс матрицы ковариации и возвращающую соответствующее этому индексу скалярное произведение
, индекс матрицы ковариации и возвращающую соответствующее этому индексу скалярное произведение  . На выход gaussianProcess выдает nSamples векторов .
. На выход gaussianProcess выдает nSamples векторов . 
Уже подходит время объединить все полученные нами знания вместе. Но прежде, стоит упомянуть об одном полезном свойстве эрмитовых полиномов и нормального распределения в совокупности. Пусть
 Тогда, используя разложение Тейлора,
Тогда, используя разложение Тейлора, 
 — две стандартные нормально распределенные случайные величины. Через производящую функцию нормального распределения мы можем вытащить следующее соотношение:
— две стандартные нормально распределенные случайные величины. Через производящую функцию нормального распределения мы можем вытащить следующее соотношение: ![$\mathbb{E}[F(s,X)\cdot F(t,Y)]=\exp(st\mathbb{E}[XY]).$](https://habrastorage.org/getpro/habr/formulas/dd6/7d7/96a/dd67d796a6e105710b3b9855ba3ee5ee.svg)
 -ую частную производную
-ую частную производную  , приравниваем
, приравниваем  по обе стороны уравнения сверху и получаем
по обе стороны уравнения сверху и получаем ![$\mathbb{E}[H_n(X) \cdot H_m(Y)] = \begin{cases} n!(\mathbb{E}[XY])^n, & n=m, \\ 0, & n \neq m. \end{cases}$](https://habrastorage.org/getpro/habr/formulas/83a/8cd/063/83a8cd06344a22b3cd28231f4019ce19.svg)
О чем это нам говорит? Во-первых, мы получили норму
 для
для  , а, во-вторых, мы теперь знаем, что разные эрмитовы полиномы от нормальных случайных величин ортогональны друг другу. Вот сейчас мы готовы к осознанию нечто большего.
, а, во-вторых, мы теперь знаем, что разные эрмитовы полиномы от нормальных случайных величин ортогональны друг другу. Вот сейчас мы готовы к осознанию нечто большего.Разложим пространство в хаос
Пусть
 — n-й Винеровский хаос. Тогда
— n-й Винеровский хаос. Тогда 
— сигма-алгебра, созданная .
Воу-воу, палехче! Давайте разложим эту теорему о разложении по кусочкам и переведём с математического на человеческий. Мы не будем сильно вдаваться в детали, а лишь интуитивно поясним о чем тут речь. Значок
 обозначает линейную оболочку подмножества гильбертова пространства — пересечение всех подпространств , содержащих . Говоря проще, это множество всех линейных комбинаций элементов из . Черта сверху над
обозначает линейную оболочку подмножества гильбертова пространства — пересечение всех подпространств , содержащих . Говоря проще, это множество всех линейных комбинаций элементов из . Черта сверху над  обозначает замыкание множества. Если
обозначает замыкание множества. Если  , то называется полным множеством (грубо говоря, " плотно в "). Следовательно,
, то называется полным множеством (грубо говоря, " плотно в "). Следовательно,  — замыкание линейной оболочки полиномов Эрмита от Гауссовского процесса на единичной гиперсфере.
— замыкание линейной оболочки полиномов Эрмита от Гауссовского процесса на единичной гиперсфере.С нотацией вроде разобрались. Теперь о том, что такое Винеровский хаос. Идем от простого:
 содержит все линейные комбинации Эрмитовых полиномов со степенью 0, то есть различные комбинации чисел
содержит все линейные комбинации Эрмитовых полиномов со степенью 0, то есть различные комбинации чисел  , то есть всё пространство вещественных чисел. Следовательно,
, то есть всё пространство вещественных чисел. Следовательно,  . Идем дальше. Несложно увидеть, что
. Идем дальше. Несложно увидеть, что  , то есть пространство, составленное из Гауссовских процессов. Получается, что все центрированные нормальные величины принадлежат
, то есть пространство, составленное из Гауссовских процессов. Получается, что все центрированные нормальные величины принадлежат  . Если мы добавим еще , то к ним присоединятся и остальные нормальные случайные величины, чье математическое ожидание отлично от нуля. Дальнейшие множества
. Если мы добавим еще , то к ним присоединятся и остальные нормальные случайные величины, чье математическое ожидание отлично от нуля. Дальнейшие множества  уже оперируют с n-ми степенями .
уже оперируют с n-ми степенями .Пример. Пусть
и  — квадрат Броуновского движения. Тогда
— квадрат Броуновского движения. Тогда ![$\begin{aligned} B(t)^2&=W(1_{[0,t]})^2 \\ & = \|1_{[0,t]} \|^2 \cdot W\bigg(\frac{1_{[0,t]}}{\|1_{[0,t]} \|}\bigg)^2 \\ & = t\cdot W\bigg(\frac{1_{[0,t]}}{\sqrt{t}}\bigg)^2\\ &=tH_2\bigg(W\bigg(\frac{1_{[0,t]}}{\sqrt{t}}\bigg)\bigg)+t. \end{aligned}$](https://habrastorage.org/getpro/habr/formulas/e6d/b46/c92/e6db46c920be258ec0988df7dcc879aa.svg)
 , второе — . Это и называется разложением в Винеровский хаос.
, второе — . Это и называется разложением в Винеровский хаос.Мы показали ранее, что
 для
для  . Теорема о разложении гласит о том, что эти множества не только ортогональны друг другу, но также формируют полную систему в . Что это означает на практике? Это значит, что любая случайная величина с конечной дисперсией может быть аппроксимирована полиномиальной функцией от нормально распределенной случайной величины.
. Теорема о разложении гласит о том, что эти множества не только ортогональны друг другу, но также формируют полную систему в . Что это означает на практике? Это значит, что любая случайная величина с конечной дисперсией может быть аппроксимирована полиномиальной функцией от нормально распределенной случайной величины.На самом деле
На самом деле, такое разложение полезно, если распределение в определенном смысле близко к распределению нормальному. Например, если мы имеем дело с Броуновским движением или с логнормальным распределением. И мы не просто так упомянули, что создаётся , это очень важное условие. В действительности, плотность нормального распределения
Если же распределение далеко от Гаусса, то можно попробовать и другие ортогональные полиномы. Например, плотность Гамма-распределения:
Равномерному распределению соответствуют полиномы Лежандра, биномиальному распределению — полиномы Кравчука, и т.п. Теория, развивающая идею разложения вероятностного пространства на ортогональные полиномы именуется в англоязычной литературе как «Polynomial chaos expansion».
в определенном смысле близко к распределению нормальному. Например, если мы имеем дело с Броуновским движением или с логнормальным распределением. И мы не просто так упомянули, что создаётся , это очень важное условие. В действительности, плотность нормального распределения
Если же распределение
далеко от Гаусса, то можно попробовать и другие ортогональные полиномы. Например, плотность Гамма-распределения: 

Равномерному распределению соответствуют полиномы Лежандра, биномиальному распределению — полиномы Кравчука, и т.п. Теория, развивающая идею разложения вероятностного пространства на ортогональные полиномы именуется в англоязычной литературе как «Polynomial chaos expansion».
Пример. Давайте теперь возьмем
, функцию и зададим случайную величину , такую что 
 . По теореме о разложении мы можем представить её в виде взвешенной суммы из полиномов Эрмита
. По теореме о разложении мы можем представить её в виде взвешенной суммы из полиномов Эрмита 
![$f_n=\frac{1}{n!}\mathbb{E}[f(\xi) \cdot H_n(\xi)].$](https://habrastorage.org/getpro/habr/formulas/436/189/12f/43618912f9623969a388d8362704b58c.svg)
 мы получили следующим образом:
мы получили следующим образом: ![$\begin{aligned} \mathbb{E}[f(\xi)\cdot H_n(\xi)] & = \langle f(\xi), H_n(\xi) \rangle \\ &= \langle \sum_{k=0}^\infty f_k H_k(\xi) , H_n(\xi) \rangle \\ &= \sum_{k=0}^\infty f_k \langle H_k(\xi), H_n(\xi) \rangle \\ & = f_n \| H_n(\xi) \|^2 = f_n n!. \end{aligned}$](https://habrastorage.org/getpro/habr/formulas/7e7/228/e22/7e7228e224673905aa5e2e3733452480.svg)


Заметьте, что каждый второй элемент в разложении по базису равен нулю.
-- | 'second' function takes a list and gives each second element of it second (x:y:xs) = y : second xs second _ = [] -- | 'coinTossExpansion' is a Wiener chaos expansion for coin-toss r.v. to n-th element coinTossExpansion :: Int -- number of elements in the sum -> Double -- gaussian random variable -> Double -- the sum coinTossExpansion n xi = sum (take n $ 0.5 : zipWith (*) fn (second $ hermite xi)) where fn = 1.0 / (sqrt $ 2 * pi) : zipWith ( \fn1 k -> -fn1 * k / ((k + 1) * (k + 2)) ) fn [1, 3..]
Функция coinTossExpansion возвращает сумму, полученную разложением случайной монетки в винеровский хаос, для данного
 от
от  до . На графике показана постепенная сходимость для выбранных случайным образом с возрастанием .
до . На графике показана постепенная сходимость для выбранных случайным образом с возрастанием .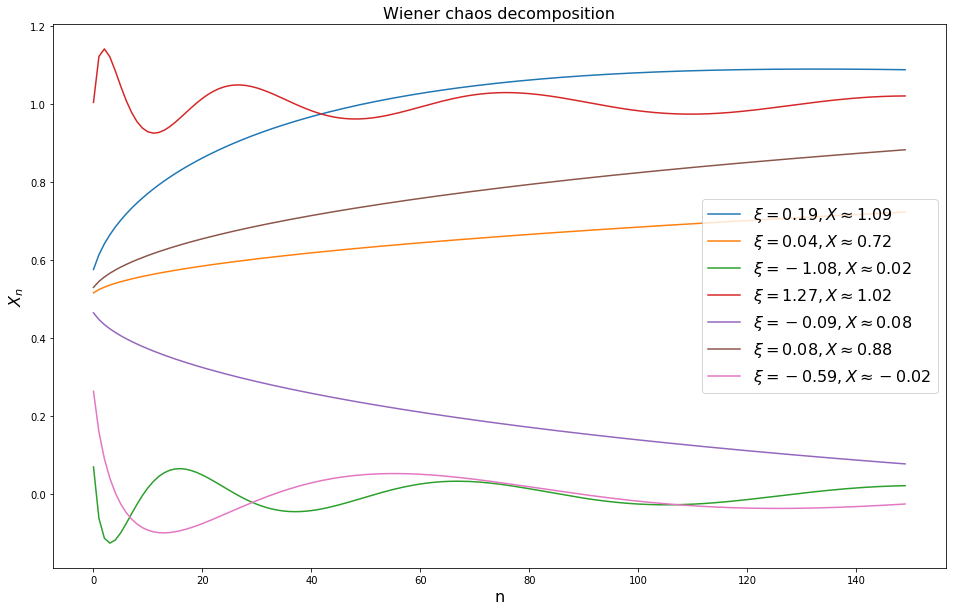
Судя по этому графику, где-то после
 мы можем обрезать сумму, округлить и вернуть в качестве .
мы можем обрезать сумму, округлить и вернуть в качестве .-- | 'coinTossSequence' is a coin-toss sequence of given size coinTossSequence :: Seed -- random state -> Int -- size of resulting sequence -> [Int] -- coin-toss sequence coinTossSequence seed n = map (round.coinTossExpansion 100) (toList nvec) where nvec = gaussianProcess seed n 1 (\(i,j) -> 1) !! 0
Проверим, как будет выглядеть последовательность из 20 подбрасываний.
Prelude> coinTossSequence 42 20 [0,0,1,0,0,0,1,1,0,1,0,0,0,1,0,1,1,1,0,1]
Теперь, когда вас попросят сгенерировать подбрасывания монетки, вы знаете, что им показать.

Ну а без шуток, мы что-то посчитали и что-то разложили, а какой в этом всем толк, спросите вы. Не спешите чувствовать себя обманутыми. В последующих статьях мы покажем, как это разложение позволяет брать производную от случайной величины (в некотором смысле), расширим стохастическое интегрирование (и ваше сознание), и найдем всему этому практическое применение в машинном обучении.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Впечатления от статьи:
83.1%Я ничего не понял, продолжай!241
5.52%Я ничего не понял, не продолжай!16
11.03%Я все понял, продолжай!32
0.34%Я все понял, не продолжай…1
Проголосовали 290 пользователей. Воздержался 41 пользователь.

