
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
А потом этот веб-архив испортился. В него зачастую не только перестали поступать обновлённые версии сайтов, но даже исчезли уже ранее сохранённые копии! Это же уму нерастяжимо!Это из-за robots.txt, которые стали ретроактивно влиять на их политику архивирования. Т.е. был сайт, умер, доменное имя продали сквоттеру (гореть им в аду, кстати), он поставил туда свою заглушку с robots.txt, и всё. Архив прошлого сайта автоматом стирается.
Нужно создать архив на архив archivearchive.org
Можно было хранить, данных не так много. Не сравнить с хранением бессмысленных обрывков https протокола по закону Яровой
место золота и драгоценных камней в иерархии ценностей за минуты займут, как и ранее, соль, кремень глина и бронзана
представим современную экономику
Итого на грамм золота приходится примерно 40$ товаров.Ну не так и страшно, на самом деле. Сейчас можно купить книжку с граммом золота на 60 страниц 91,5x91,5мм. При желании можно и поменьше листики сделать.
С другой стороны, было бы интересно наблюдать процесс покупки крупной международной компании, какого-нибудь Амазона. ;)Ничего особенно зрелищного: бумаги подписываются сразу, золото подвозится через какое-то время кораблями и поездами. Как это делали 200-300 лет назад.
PS И насчет «не исчезнет» я бы не обольщался, примерно 12% годового производства золота тратится в промышленности, в основном в микроэлектронике. Грубо говоря, на микропроцессоры мы потратили больше золота, чем было накоплено человечеством к началу промышленной революции.И оно таки возвращется оттуда. Поищите на eBay лоты «Pentium Pro for gold». Цена работающего экземпляра Pentium Pro сегодня отличается от цены неработающего примерно так процентов на 10.
это как раз ответ на вопрос почему всего так мало. А потому что оно уже не нужно.Ага, не нужно, а потом на луну не знают как снова попасть habr.com/en/post/388699 и думают что пирамиды инопланетянами строились.
Могу ошибаться, пусть сведущие в металлургии поправят
Википедия говорит что П.П. Аносов опубликовал свою работу «О булатах» еще в 1841 году.
Был такой сервис, где фото привязывались к картам. Забыл как назывался. Потом это выкупил гугл и показывал на Google Earth. А потом… Потом все это убил. Все эти фотографии пропали(
Точно! Спасибо
Panoramio. Часть фотографий перенесли в архив альбомов Google.
Да, я считаю, что нужно хранить архивы личных писем, сообщений.Проблема не столько даже в хранении, сколько в поиске в огромных объемах накапливающегося текста. Найти в нем что-то конкретное нужное и ценное потом через годы мало реально, так как он тематически не структурирован, а ключевые фразы и точные временные периоды по которым искать нужный фрагмент подобрать крайне сложно.
Многие подтверждающие статьи факты часто уже не найти «в свободном доступе»Более того, могут предприниматься целенаправленные действия по уничтожению или изменению источников, подтверждающих информацию. По крайней мере, есть один прецедент (и таки закончилось удалением статьи).
Например, если взять блог-посты о настройке какого-нибудь софта, то часто эта информация довольно неактуальна.Откуда такая уверенность? Вот решите вы писать поддержку какого-нибудь новейшего 5G строить — а она поверх 4G… а тот — развитие 3G, который расширение 2G… и вот вы уже ломаете мозг в попытке прочитать документ в формате MS Word for DOS… старые сайты и инструкции очень бы пригодились — но их нет…
text/plain.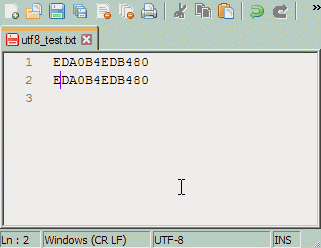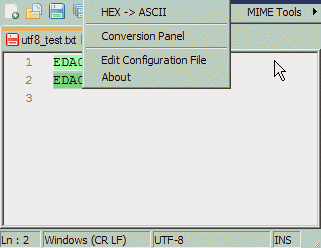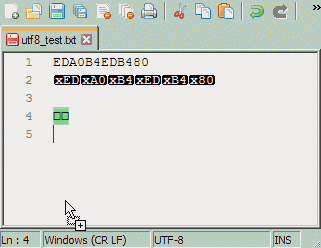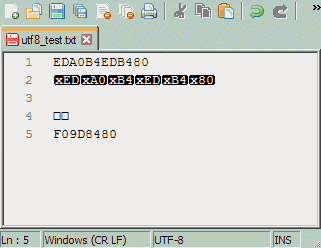
У text/plain могут быть проблемы с кодировкой.Теоретически могут. На практике же существующие кодировки продолжают существовать; как двадцать лет назад были четыре кириллических кодировки (DOS, WIN, KOI, ISO), так они есть и сейчас. Форматов же за это время сменилось множество, причём порой бывают несовместимы существующие одновременно вариации одного формата (в мае 2003 года я столкнулся с неспособностью Microsoft Word'а открыть doc-файл, сохранённый WordPad'ом того же, с позволения сказать, разработчика).
Мы не можем сохранять всё. Сэмплирование — это правильный выход.
А вот алгоритмы сэмплирования требуют большого внимания, потому что если не обеспечить рандомности, то будет фигня.
И это нормально. В нормальном сэмплировании показывается не "лучшее, что есть", а "как оно есть".
Вы не можете сохранять всю производимую информацию, потому что архив — это тоже производимая информация. Сэмплирование неизбежно, и лучшее, что мы можем сделать, это обеспечить его консистентность и гранулярность (на это как раз и жаловались — индекс есть, а статей нет — это плохая гранулярность архивирования).
Viber и whatsapp делают бэкапы на google drive, telegram позволяет сделать выгрузку всех чатов и прочего. С новым скайпом непонятно.
Я вот подумывал сделать self-hosted сервис, который позволял бы импортировать в себя переписки из разных мест (но тоже не доходят руки)
Данные, если они представляют ценность, будут сохранены, остальное можно с чистой совестью удалять.Оно так не работает — иначе не шли бы судербные процессы по сто лет и не пытались бы судьи судить по составу похлёбки о мореходных качествах корабля, на которых похлёбка варилась.
Ничего такого нет, всё или изобретено и реализовано
А вот чертежи Да Винчи и его изобретений имеют огромную ценность и никому в голову не придет никогда их уничтожить.
То, что не кажется ценным сейчас возможно станет ценным в будущем.
как долговременно хранить цифровую информацию
эта система позволяла годами надежно сохранять информацию
Самый обычный альбомный лист и перьевая ручка дают, в худшем случае, сотни лет доступности информации,
«У нас сгорела фотослужба, библиотека — там были подшивки газет, а также ценные документы — например, протоколы троцкистских процессов,— оценил нанесенный пожаром ущерб по горячим следам господин Дятлов.— Электронный архив газеты за 12 лет тоже сгорел.
Виниловые перфокарты? :)
Если через тысячу лет откопают пластинку и откуда-то узнают — как собрать и запустить грамофон, то информацию с пластинки извлекут.
Даже для одного человека ценность меняется со временем, причём часто немонотонно.
Причем, иногда ценность становится понятна только тогда, когда ресурс с информацией перестал быть доступен
Например, кастомные прошивки для старых телефонов.
С учетом того, что есть люди, которые принципиально ничего не выбрасывают — вся эта инфа где-то по прежнему существует.Пока ещё существует. И то не факт. Пройдёт ещё лет 10-20-30 лет — и она исчезнет.
И то не факт. Пройдёт ещё лет 10-20-30 лет — и она исчезнет.
Информацию в компьютерной форме сохранять гораздо легче, время от времени переписывая ее на более современные носители.Потерять её, к сожалению, тоже гораздо легче.
Не исключено, что через 30 лет технология «вечного» хранения данных станет широко доступной (что-то такое есть и сейчас)Пока что тенденция обратная: текст своего диплом я, недавно, случайно откпопал у себя в шкафу. И где-то в какой-то библиотеке он, наверняка, есть. А вот текста программы — нет ни у меня (умерла вместе с винтом), ни у Университета (она туда просто не сдавалась).
Если речь о том, чтобы хранить информацию без надлежащего обслуживания (замена дисков в RAID, периодическая перезапись и т.п.), то, наверно, надо юзать что-то вроде этого https://habr.com/ru/post/390695/
Пока что тенденция обратная

Вот тут чувак пишет, как он искал Norton Utilities 2.01.
Закрытие треккеров или отдельных раздач нанесло огромный вред
Опять же, мой сервер всё помнит
Я давно наблюдаю за потерей данных и моя паранойя держит более 100 Tb архивов на личном серваке, пока я путешествую, пополняю коллекциюСервер с архивами существует в одном экземпляре?
Ценность это цена получения следующего экземпляра чего либо. Как и любая цена, эта величина определяется спросом и предложением на определенный момент времени. Ценность это предел изменений цены.
Ценность — не цена получения, а полезность, источник спроса. Пока цена ниже полезности, эту цену готовы люди платить.
Вы вместо равновесной цены указали указали индивидуальную цену предложения. Так же вы рассматриваете ценность относительно одного человека, а у разных людей разное представление о ценности (вспомните о коллекционерах). Как только преодолеваем рамки индивидуальности всё начинает измеряется по другому, в потоках.
Я уже лет 20 держу один сайт, который мне уже давно не интересен, но сообщество которого поддерживает его жизнь без моего участия. Когда-нибудь мне надоест хостить его в минус и он исчезнет. Или меня собьёт автобус. И эта информация будет потеряна.Не так давно умер bal, который вёл свои блоги в распределенной системе ZeroNet. Вот что он писал:
When I die, my ZeroNet blog will be the only digital trace of mine, that doesn't depend on any 3rd party services, companies or persons, and will have been surviving for many years. If my work is worthy of something, people will keep, read and use my zites.
Возможно в будущем, блокчейн и прочие вещи смогут сделать информацию чуть более долговечной, но пока вот так.
В противном же случае настоящая информация растворится как капля в море спама.
В этом огромном мире информация ползователя спает лишь поиск. Так что вся надежда на поисковые движки и их алгоритмы.
Одна проблема — поисковики коммерческие предприятия, и их цели расходятся с целями пользователей. А содержать каждому свой поисковик слишком сложно.Каждому одному — да. Однако представим поисковик, который предлагал бы по-настоящему качественный поиск без слежки и рекламы; подписка стоила бы один доллар в год. Неужели не нашлось бы несколько тысяч подписчиков? И неужели такой поисковик не смог бы существовать на несколько тысяч долларов в год?
Мы же знаем, что с развитием технологий и увеличения доступности предметов, вещей многое из того, раньше было труднодоступным, становится общедоступным.К содалению в данном случае это невозможно. Более того: если в 80е-90е свой поисковик мог сделать один человек или там, пара студентов, то сегодня… это невозможно. Просто потому, что поисковик, по необходимости, должен хранить и обрабатывать не определённое, фактически фиксированное количество иформации (как телефон или видеокамера), а некоторый процент от всей информации, хранящейся на всех компьюерах в интернете. Закон Мура, пресловутый, тут никак не поможет — потому что скорость порождения информации растёт, фактически, с той же скоростью, что скорость роста ёмкостей, где поисковик хранит эту информацию…
Для исходного кода и текста юзаю локальный Git с сихнронизацией на GitHub и GitLab. Схема очень надежная: если что-то сломается, всегда будет копию в двух других местах. А на самих сервисах к тому же можно еще и форки делать.



Так произошло с Югославией. Доменом верхнего уровня был .yu, и после развала страны он исчез (ссылка на бомбежки 1999 года отсутствующая в первоисточнике)
Почему у нас осталось так мало от раннего интернета?