
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Можно переписать на int-ы конкретно преобразование Фурье (и есть уже куча готовых библиотек для этого), но переписывать большие сложные алгоритмы использующие самую разную математику с плавающей точки на int-ы не практично, так как чрезвычайно затратно по объему квалифицированного труда инженеров. И вот в таких случаях posit может проявить себя, если будет реализован в железе. Плюс далеко не во всех приложениях важен объем памяти, где-то важнее точность и используют расширенные представления чисел с плавающей точкой в 10 или 16 байтов, а с posit для этих приложений может хватить и 64-битных чисел (а может и не хватить — зависит от задачи). То есть смысл в нем был бы при аппаратной поддержке в процессоре именно как для прямой замены float/double, прозрачной для 99.999% кода, не требующей изменений в программах, кроме некоторых самых корных функций системных библиотек и компиляторов.
Позит — это не волшебная палочка какая-то, чтобы 8 байт в 16 превращать. Максимальное теоретическое преимущество posit64 над float64 по длине мантиссы — 7 бит, потому что у float64 11 бит порядка, а у posit64 минимум 4.
Это понятно, но если не хватает 52 битов в double, то иногда используют расширенную точность ради нескольких битов. Которая у некоторых платформ была реализована в виде 16-байтовых значений (IBM 370+, SPARC, Power с его double-double, может что-то еще). Overkill когда это для дополнительных пары битов, но если железо таково, то использовали это для быстроты работы. Плюс даже на x86 из-за проблем с выравниванием обычно пишут 10-байтовые long double по адресам кратным 16, а не 10.
А, ну если так — то да, может где-то быть полезно. Но тут вопрос, стоит ли овчинка выделки. А то, скажем, при покупке GPU платишь и за блок single-precision, и за блок half-precision, даже если нужны исключительно double и ни битом меньше. А тут аппаратная поддержка ещё одного типа с плавающей точкой, нужного не только лишь всем.
for (int i = 0; i < data.size(); i++)
{
double v = data[i];
data_posit[i] = Posit32(v).getDouble();
data_float[i] = float(v);
}Я думал вы как автор топика попробуете это самостоятельноМне, как автору двух топиков было интересно разобраться, кто прав. Сравнивать между собой различные реализации Posit уже не интересно. Если вам это интересно — сравнивайте, пишите, и тоже станете автором своего собственного топика.
Я посмотрел код использованной вами реализации и она значительно отличается от оригинала, есть подозрения :)Я его выбрал, потому что:
обоснование почему Posit32 «уползает» по точностиПодробно расписано здесь.
Я его выбрал, потому что: хорошо написан
В комментариях к вашей прошлой статье уже обсуждали, что написана эта реализация спорно. В частности, у меня были вопросы к реализации извлечения корня.
ogamespec, было бы действительно здорово, если вы сравните две реализации posit-ов. Или повторите тесты с библиотекой от авторов posit-а. Я, как человек не знающий С/С++, это сделать не могу :(
#include "pch.h"
#include "CppUnitTest.h"
/// BFP
#include "posit.h"
/// SoftPosit
extern "C"
{
#include "platform.h"
#include "internals.h"
};
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
namespace PositConvertUnitTest
{
TEST_CLASS(PositConvertUnitTest)
{
public:
TEST_METHOD(TestMethod1)
{
Logger::WriteMessage("0: ");
TestPositConv(0);
Logger::WriteMessage("1: ");
TestPositConv(1.0);
Logger::WriteMessage("EPSILON: ");
TestPositConv(DBL_EPSILON);
Logger::WriteMessage("MIN: ");
TestPositConv(DBL_MIN);
Logger::WriteMessage("MAX: ");
TestPositConv(DBL_MAX);
}
void TestPositConv(double v)
{
Posit32 p32(v);
double vBfp = p32.getDouble();
posit32_t bits = { 0 };
bits.v = p32.getBits();
double vSP = convertP32ToDouble(bits);
Assert::IsTrue(vBfp == vSP);
Logger::WriteMessage(("double:" + std::to_string(v)
+ ", posit32 bits: " + to_hexstring(bits.v)
+ ", posit32->Bfp:" + std::to_string(vBfp)
+ ", posit32->SP: " + std::to_string(vSP)
+ "\n").c_str());
}
std::string to_hexstring(uint64_t value)
{
std::stringstream stream;
stream << "0x" << std::hex << value << std::dec;
return stream.str();
}
};
}
Если утверждения авторов верны, то погрешность, вносимая преобразованием Double→Posit→Double будет ближе к Doublе, чем к Float
Простите, а почему ближе к Double? Не ровно посередине между Float и Double? Признаюсь, я не погружался глубоко в тему и читал только статьи на Хабре, и Posit32 сравнивается с Float. В этой статье есть табличка с динамическими диапазонами:
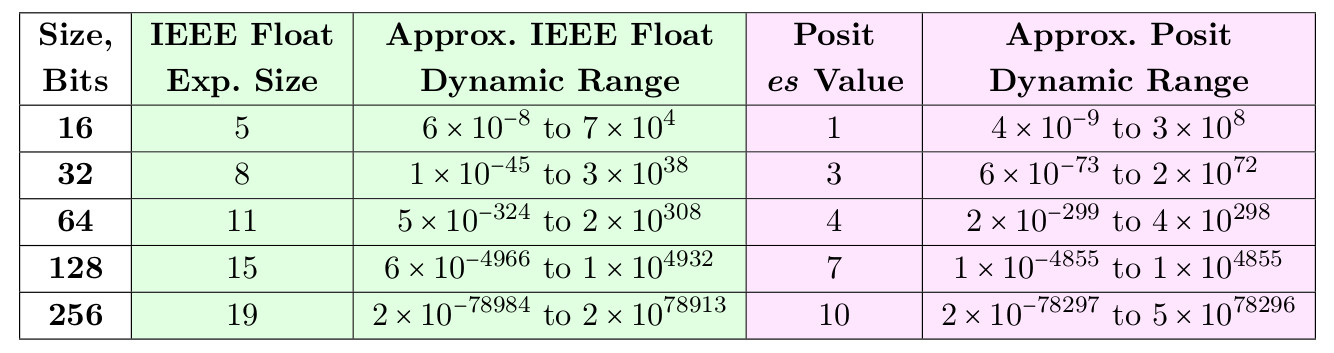
, и там Posit с es value=3 (что бы это ни значило) гораздо ближе к Float, чем Double.
Кроме того, в комментариях я видел утверждения, что Posit32 by design превосходит Float по точности в диапазоне до 10^6, за что расплачивается меньшей точностью на числах 10^20. Это соответствует действительности?
Спектральный анализ не подтвердил заявления авторов о том, что использование формата Posit в качестве хранения может обеспечить точность близкую к Double.На правах автора предыдущей статьи: такого не утверждалось. У Double мантисса 52 бита для любых значений. Тут не нужен спектральный анализ чтобы осознать что 32-битным Posit не достичь аналогичной точности для любых значений.
Испытания Posit по-взрослому. Спектральный анализ