
Фото Chris Keats на Unsplash
Многие компании, и мы в том числе, перешли от монолитов к микросервисам ради лучшей масштабируемости и ускорения циклов разработки. У нас всё еще есть монолитные проекты, но они постепенно заменяются набором небольших и аккуратных микросервисов.
Эти микросервисы используют Open API 3.0 схемы для описания того что от них можно ожидать. Схемы дают множество полезных вещей, например автогенерируемые клиенты или интерактивная документация, но их основное достоинство состоит в том, что они помогают контролировать как сервисы общаются между собой.
Межсервисная коммуникация становится более сложной когда количество участников растет и в этой статье, я хочу поделиться своими мыслями о проблемах использования схем в веб приложениях и обозначить некоторые способы как с ними можно бороться.
Даже учитывая что Open API 3.0 во многом превосходит своего предшественника, (так же известного как Swagger 2.0) у него, так же как и у других спецификаций есть множество ограничений. Основная проблема заключается в том, что даже если и описанная схема полностью отражает видение автора, это не значит что реальное приложение будет вести себя согласно схеме.
Существует множество различных подходов для синхронизации схем с документацией и логикой приложения. Наиболее распространенные:
- Развивать отдельно, синхронизировать вручную;
- Генерировать схему из приложения (например, при помощи, apispec);
- Предоставлять логику на основе схемы (connexion);
Ни один из этих подходов не гарантирует 1:1 соответствия поведения приложения и его схеме и на это есть множество причин. Это может быть сложное ограничение на уровне базы данных, которое нельзя выразить на языке схемы или вездесущий человеческий фактор — или мы забыли обновить приложение, чтобы отобразить изменения схемы или наоборот.
Существует множество последствий этих несоответствий, от необработанной ошибки, которая ломает приложение, до проблем с безопасностью, которые могут повлечь серьезные финансовые потери.
Очевидный способ решать эти проблемы это тестировать приложения и настраивать линтеры для схем (такие как Zally от Zalando), что мы и делаем, но ситуация становится сложнее когда вам необходим работать с сотнями сервисов различных размеров.
Классические, example-based тесты имеют некоторую стоимость поддержки и занимает время для написания, но они всё еще являются неотъемлемой частью любого современного процесса разработки. Мы искали дешевый и эффективный способ находить дефекты в наших приложениях, что-то что позволит нам тестировать приложения написанные на разных языках, будет иметь минимальную стоимость поддержки и будет простым в использовании.
Поэтому мы решили исследовать применимость property-based тестирования (PBT) для Open API схем. Сам концепт не нов, впервые его реализовали в Haskell библиотеке QuickCheck Koen Claessen и John Hughes в 1999 году. В наши дни PBT инструменты существуют в большинстве языков программирования, включая Python, наш основной язык для бэкенда. В примерах ниже, я буду использовать Hypothesis за авторством David R. MacIver.
Суть подхода заключается в определении свойств, которые код должен удовлетворять и проверки, что эти свойства выполняются на большом количестве случайно сгенерированных входных данных. Давайте представим простую функцию, которая принимает на вход два числа и возвращает их сумму, а также тест для этой функции. Для примера мы можем ожидать, что наша реализация обладает свойством коммутативности.
Тем не менее, Hypothesis быстро напоминает нам, что коммутативность выполняется только для действительных чисел:
PBT позволяет разработчикам найти нетривиальные примеры когда код не работает как ожидается. Так как же это применимо для API схем?
Выяснилось, что мы ожидаем довольно много от наших приложений, они должны:
- Соответствовать своим схемам;
- Не падать на произвольных входных данных, как корректных так и некорректных;
- Иметь время отклика не превышающее нескольких сотен миллисекунд;
Соответствие схеме можно развить дальше:
- Корректные входные данные должны приниматься, некорректные должны отклоняться;
- Все ответы должны иметь ожидаемый HTTP код;
- Все ответы должны иметь содержимое ожидаемого типа;
Даже, если учитывать то что невозможно выполнять все эти свойства во всех случаях, они являются хорошими ориентирами. Сами по себе, схемы это источник свойств приложения, что делает их идеальными для использования в PBT.
В первую очередь мы посмотрели вокруг и обнаружили, что уже существует Python библиотека для этого — swagger-conformance, но она выглядела заброшенной. Нам нужна была поддержка Open API и больше гибкости со стратегиями генерации данных чем было в swagger-conformance. Мы также нашли свежую библиотеку — hypothesis-jsonschema, написанную одним из основных разработчиков Hypothesis — Zac Hatfield-Dodds. Я благодарен людям, которые написали эти инструменты. С их усилиями тестирование в Python стало более захватывающим, вдохновляющим и приятным.
Так как в основе Open API лежит JSON Schema эта библиотека нам подходила, но всё же не предоставляла всего что нам было нужно. Имея все эти инструменты мы решили построить свою собственную библиотеку на основе Hypothesis, hypothesis-jsonschema и pytest, которая бы работала с Open API и Swagger спецификациями.
Именно так появился проект Schemathesis, который мы начали несколько месяцев назад в нашей Testing Platform команде в Kiwi.com. Идея такая:
- Преобразуем Open API & Swagger определения к JSON Schema;
- Используем hypothesis-jsonschema чтобы получить нужные Hypothesis стратегии;
- Используем эти стратегии в CLI и Python тестах
Schemathesis генерирует данные которые соответствуют схеме и делает необходимые сетевые запросы к запущенному приложению и проверяет если приложение упало или то что ответ соответствует схеме.
У нас впереди всё ещё огромное количество интересного функционала для реализации:
- Генерация некорректных данных;
- Генерация схем из других спецификаций;
- Генерация схем из WSGI приложений;
- Более глубокая интеграция со стороны приложений;
- Генерация входных данных с обратной связью, основанной на покрытии кода или других параметрах;
Даже в текущем состоянии Schemathesis помог нам улучшить наши приложения и бороться с определенными типами дефектов. Далее я покажу несколько примеров того как это работает и какие типы ошибок можно найти. Для этой цели я создал приложение которое предоставляет простое API для бронирования, исходники можно найти здесь https://github.com/Stranger6667/schemathesis-example. В нем есть ошибки, которые не всегда очевидны на первый взгляд и мы найдем их при помощи Schemathesis.
В примере два эндпоинта:
POST /api/bookings— создать новое бронированиеGET /api/bookings/{booking_id}/— получить бронирование по ID
Далее в тексте я подразумеваю, что этот проект запущен на 127.0.0.1:8080.
Schemathesis может быть использован в качестве command-line приложения или в Python тестах, обе возможности имеют свои преимущества и недостатки, о которых я расскажу далее.
Давайте начнем с командной строки и попробуем создать новое бронирование. Модель Booking имеет всего несколько полей:
Open API 3 схема Booking модели
Определение таблицы в базе.
Соответствующий Python код
Вы заметили дефект который может привести к необработанной ошибке?
Нужно запустить Schemathesis и указать нужный нам эндпоинт:
$ schemathesis run -M POST -E /bookings/ http://0.0.0.0:8080/api/openapi.json
Эти две опции, --method и --endpoint позволяют вам запускать тесты только для интересных вам эндпоинтов.
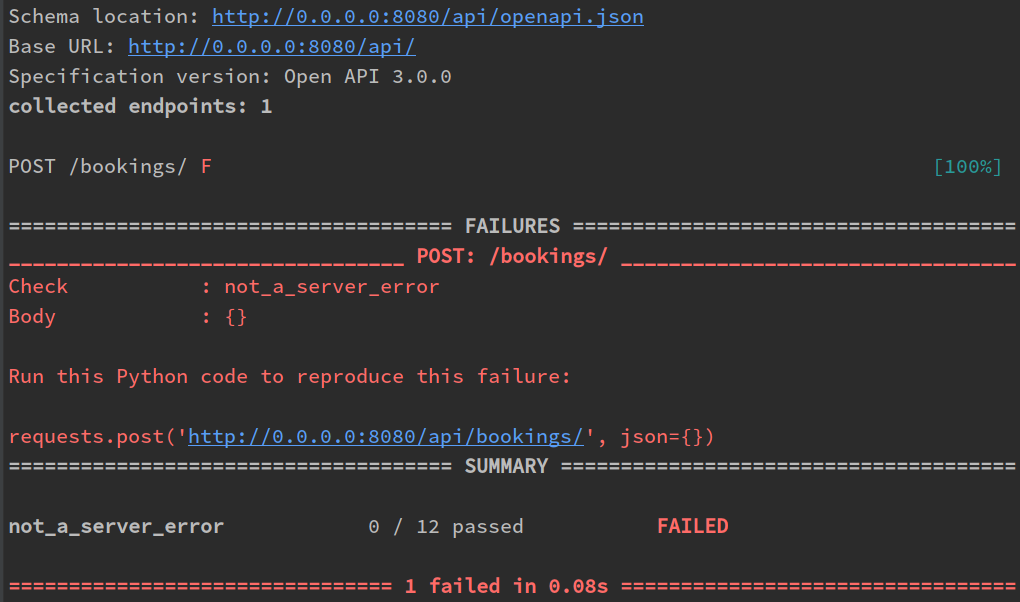
Schemathesis CLI сгенерирует простой Python код, для того чтобы ошибку можно было легко воспроизвести, а также сохранит её во внутренней базе данных Hypothesis, чтобы использовать её в последующих запусках. На стороне сервера мы увидим проблемный параметр в тексте исключения:
File "/example/views.py", line 13, in create_booking request.app["db"], booking_id=body["id"], name=body["name"], is_active=body["is_active"] KeyError: 'id'
Чтобы исправить ошибку, нам необходимо сделать id и другие параметры обязательными в схеме.
Давайте перезапустим последнюю команду и проверим всё ли хорошо:

Снова ошибка! На стороне сервера такой вывод:
asyncpg.exceptions.UniqueViolationError: duplicate key value violates unique constraint "bookings_pkey" DETAIL: Key (id)=(0) already exists.
Кажется, что я не рассмотрел ситуацию когда пользователь пытается создать бронирование с тем же ID дважды! Но, такого рода проблемы распространены на продакшене — двойные клики, повторные запросы при ошибках и т.д.
Мы часто не представляем как наши приложения будут использоваться после деплоя, но PBT может помочь с поиском логики которая отсутствует в реализации.
Так же, Schemathesis позволяет использовать свой функционал в обычных Python тестах. Второй эндпоинт нашего примера может выглядеть простым — взять запись из базы данных и сериализовать. Но он так же содержит ошибку.
Определения Open API 3
Центральный элемент использования Schemathesis это экземпляр схемы. Он предоставляет параметризацию схемы, выбор эндпоинтов для тестов и другие опции настройки.
Существует несколько способов создать схему и все они имеют такой паттерн — schemathesis.from_<something>. Обычно, намного удобнее иметь приложение как pytest фикстуру, чтобы запускать его когда необходимо (и schemathesis.from_pytest_fixture как раз для этого и существует), но для простоты я продолжу использовать приложение запущенное локально на 8080 порту:
Каждый тест с декоратором schema.parametrize должен принимать case фикстуру в качестве аргумента, которая содержит все атрибуты требуемые схемой и дополнительную информацию чтобы делать нужные запросы по сети. Фикстура выглядит примерно так:
>>> case Case( path='/bookings/{booking_id}', method='GET', base_url='<a href="http://0.0.0.0:8080/api%27">http://0.0.0.0:8080/api'</a>, path_parameters={'booking_id': 2147483648}, headers={}, cookies={}, query={}, body=None, form_data={} )
Case.call() делает сетевой запрос с этими данными к запущенному приложению при помощи requests.
Тесты можно запускать при помощи pytest (стандартный unittest тоже поддерживается):
$ pytest test_example.py -v

Исключение на стороне сервера:
asyncpg.exceptions.DataError: invalid input for query argument $1: 2147483648 (value out of int32 range)
Выход указывает на проблему с недостаточной валидацие входных данных, исправить можно добавив минимальное и максимальное значение в схему. Наличие format: int32 недостаточно — согласно спецификации это всего лишь подсказка.
Приложение в примере слишком упрощено и не имеет многого функционала, необходимого на продакшене, такого как авторизация, мониторинг и так далее. Тем не менее, Schemathesis и property-based тестирование в целом могут обнаружить широкий спектр ошибок в приложениях. Небольшое резюме предыдущих абзацев и несколько других примеров:
- Отсутствие логики обработки нестандартных сценариев;
- Повреждение данных (из-за отсутствия должной валидации);
- DoS атаки (например из-за неудачного регулярного выражения);
- Ошибки в реализации клиентского кода (например из-за возможности присылать произвольный набор полей на вход приложения);
- Другие ошибки приводящие к падению приложения.
Эти проблемы имеют разный уровень опасности, но, даже небольшие ошибки могут заполонить ваш трекер ошибок и появиться в ваших уведомлениях. Я сталкивался с ошибками вроде указанных выше на продакшене и я предпочитаю поправить их как можно раньше, чем быть разбуженным PagerDuty посреди ночи.
Существует множество вещей которые можно улучшить в этих областях и я хочу предложить вам поучаствовать в разработке Schemathesis, Hypothesis, hypothesis-jsonschema или pytest, все они являются проектами с открытым исходным кодом. Ссылки на проекты указаны ниже.
Спасибо за внимание!
У проекта есть свой Discord чат, в котором можно задать пообщаться с нами и оставить фидбек — https://discord.gg/R9ASRAmHnA
Ссылки:

