Бывают случаи, когда нужно ограничить пользователям доступ к некоторым данным в кубе. Казалось бы, тут нет ничего сложного: устанавливай построчные фильтры в ролях и готово, но есть одна проблема — фильтр урезает данные в таблице и получается, что можно посмотреть обороты только по доступным строкам, а нам нужны все обороты, но детализация должна быть доступна только для части из них.
Например, пользователь должен видеть обороты по всем товарам, с возможностью полной детализации по ним, но клиенты при этом должны отображаться не все, а лишь некоторые, либо все клиенты, но с частично скрытыми данными в некоторых атрибутах (полях).
Чтобы не дать пользователю возможность просматривать обороты в разрезе клиентов, можно обыграть это через формулы в мерах и выводить пустое значение, если пользователь попытается посмотреть оборот конкретного клиента, один из подобных вариантов описан здесь. Однако это всё не то. Когда мер несколько десятков, то писать в каждой из них формулу… а если забудешь? Но ведь точно забудешь же когда-нибудь… А если пользователю нужны данные из конкретной карточки клиента, то ему ни что не помешает это увидеть без выбора фильтрующей меры. Что же делать?
Нам нужно было добиться вот такого отображения:

Весь принцип, позволяющий получить подобный результат, строится на небольшой хитрости, и заключается она в добавлении в таблицу (клиентов, в данном случае) синтетических строк таким образом, чтобы запись об одной и той же сущности была задублирована как минимум один раз — первая будет содержать полную информацию, а вторая в большинстве столбцов заполнена заглушкой типа #Н/Д, но идентификаторы при этом у обеих записей одинаковые. Далее, с помощью фильтра в ролях и специальной колонки, по которой осуществляется фильтрация, оставляем для пользователя доступными те или иные строки — либо строку с полностью заполненными полями, либо с заглушками. А т.к. куб имеет особенность «схлопывать» повторяющиеся данные и пользователю недоступны никакие другие атрибуты, дающие уникальные значения, то в результирующей таблице все клиенты с кодом #Н/Д превратятся в одну строку. Думаю, на этом этапе уже и так всё предельно ясно, можно дальше не читать. Результат в заголовке статьи.
Но если кому-то нужны подробности — их есть у меня.
Табличные модели до версии 1400 (SQL 2017 включительно) не позволяют создавать связи многие-ко-многим, но в случае с дублями нам такая связь необходима, поэтому создадим её через промежуточную таблицу, содержащую только один столбец с уникальными идентификаторами клиентов. Таблица изначально несжимаема, т.к. содержит только уникальные значения, поэтому можно сделать ее расчетной, ибо в данном случае мы ничего не выиграем, если будем заполнять ее через t-sql (помните принцип процессинга и порядок сжатия таблиц?). Как раз благодаря свойству движка сжимать повторяющиеся данные, объем данных в кубе увеличится незначительно, а за счет фильтрации через роль сеанс пользователя имеет сокращенный набор записей, т.е. конечное число записей после фильтрации набора останется таким, как было без дублей. Поэтому не волнуйтесь, даже если таблица изначально достаточно большая, добавление дублей не скажется на производительности и объеме существенным образом (разумеется, случаи бывают разные, но в большинстве из них все будет именно так).
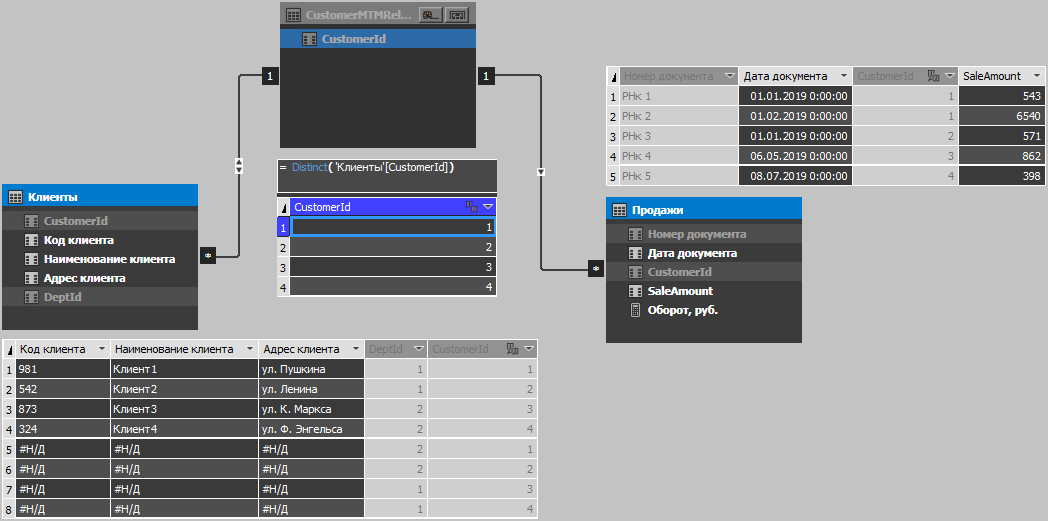
На следующем рисунке видна модель куба и содержимое таблиц:

Для примера добавим простой фильтр:

Вот и все дела.
Хочется предупредить об одной особенности использования такого подхода. Пользователи, являющиеся администраторами на сервере SSAS, по умолчанию заходят в куб минуя всякие роли, даже если их имена указаны в данных ролях. Это приводит к тому, что фильтры ролей не срабатывают и под админом видно все дубли. Но не отчаивайтесь, достаточно в строке подключения явно указать какую роль использовать и все становится на свои места, к тому же при тестировании придется не раз переключаться между ролями.
Как вы понимаете, можно сделать несколько комбинаций одной и той же записи с различными степенями наполненности столбцов реальными данными. Также можно создать отдельную скрытую таблицу в ку��е, которая будет заполняться учетными записями через ADSI, а пользователей распределить по разным доменным группам, и в зависимости от комбинаций членства пользователей в тех или иных группах заполнять эту таблицу. Прописываем ссылки в построчных фильтрах ролей на эту таблицу, что позволит управлять измерениями и в мерах тоже можем ссылаться на нее, чтобы, при необходимости, некоторые меры показывали пустоту. При такой организации получается достаточно тонкая настройка прав доступа к данным и всё хранится в одном месте. Но с мерами есть нюанс: если пользователь продвинутый и сам пишет запросы к кубу, то ему ни что не мешает воспользоваться своей мерой, без закладок, при условии, что он знает имена базовых столбцов и формулу… Хотя, при желании, можно и здесь сделать ограничение, но это уже другая тема.
Например, пользователь должен видеть обороты по всем товарам, с возможностью полной детализации по ним, но клиенты при этом должны отображаться не все, а лишь некоторые, либо все клиенты, но с частично скрытыми данными в некоторых атрибутах (полях).
Чтобы не дать пользователю возможность просматривать обороты в разрезе клиентов, можно обыграть это через формулы в мерах и выводить пустое значение, если пользователь попытается посмотреть оборот конкретного клиента, один из подобных вариантов описан здесь. Однако это всё не то. Когда мер несколько десятков, то писать в каждой из них формулу… а если забудешь? Но ведь точно забудешь же когда-нибудь… А если пользователю нужны данные из конкретной карточки клиента, то ему ни что не помешает это увидеть без выбора фильтрующей меры. Что же делать?
Нам нужно было добиться вот такого отображения:
Весь принцип, позволяющий получить подобный результат, строится на небольшой хитрости, и заключается она в добавлении в таблицу (клиентов, в данном случае) синтетических строк таким образом, чтобы запись об одной и той же сущности была задублирована как минимум один раз — первая будет содержать полную информацию, а вторая в большинстве столбцов заполнена заглушкой типа #Н/Д, но идентификаторы при этом у обеих записей одинаковые. Далее, с помощью фильтра в ролях и специальной колонки, по которой осуществляется фильтрация, оставляем для пользователя доступными те или иные строки — либо строку с полностью заполненными полями, либо с заглушками. А т.к. куб имеет особенность «схлопывать» повторяющиеся данные и пользователю недоступны никакие другие атрибуты, дающие уникальные значения, то в результирующей таблице все клиенты с кодом #Н/Д превратятся в одну строку. Думаю, на этом этапе уже и так всё предельно ясно, можно дальше не читать. Результат в заголовке статьи.
Но если кому-то нужны подробности — их есть у меня.
Табличные модели до версии 1400 (SQL 2017 включительно) не позволяют создавать связи многие-ко-многим, но в случае с дублями нам такая связь необходима, поэтому создадим её через промежуточную таблицу, содержащую только один столбец с уникальными идентификаторами клиентов. Таблица изначально несжимаема, т.к. содержит только уникальные значения, поэтому можно сделать ее расчетной, ибо в данном случае мы ничего не выиграем, если будем заполнять ее через t-sql (помните принцип процессинга и порядок сжатия таблиц?). Как раз благодаря свойству движка сжимать повторяющиеся данные, объем данных в кубе увеличится незначительно, а за счет фильтрации через роль сеанс пользователя имеет сокращенный набор записей, т.е. конечное число записей после фильтрации набора останется таким, как было без дублей. Поэтому не волнуйтесь, даже если таблица изначально достаточно большая, добавление дублей не скажется на производительности и объеме существенным образом (разумеется, случаи бывают разные, но в большинстве из них все будет именно так).
На следующем рисунке видна модель куба и содержимое таблиц:
Для примера добавим простой фильтр:
Вот и все дела.
Хочется предупредить об одной особенности использования такого подхода. Пользователи, являющиеся администраторами на сервере SSAS, по умолчанию заходят в куб минуя всякие роли, даже если их имена указаны в данных ролях. Это приводит к тому, что фильтры ролей не срабатывают и под админом видно все дубли. Но не отчаивайтесь, достаточно в строке подключения явно указать какую роль использовать и все становится на свои места, к тому же при тестировании придется не раз переключаться между ролями.
Как вы понимаете, можно сделать несколько комбинаций одной и той же записи с различными степенями наполненности столбцов реальными данными. Также можно создать отдельную скрытую таблицу в ку��е, которая будет заполняться учетными записями через ADSI, а пользователей распределить по разным доменным группам, и в зависимости от комбинаций членства пользователей в тех или иных группах заполнять эту таблицу. Прописываем ссылки в построчных фильтрах ролей на эту таблицу, что позволит управлять измерениями и в мерах тоже можем ссылаться на нее, чтобы, при необходимости, некоторые меры показывали пустоту. При такой организации получается достаточно тонкая настройка прав доступа к данным и всё хранится в одном месте. Но с мерами есть нюанс: если пользователь продвинутый и сам пишет запросы к кубу, то ему ни что не мешает воспользоваться своей мерой, без закладок, при условии, что он знает имена базовых столбцов и формулу… Хотя, при желании, можно и здесь сделать ограничение, но это уже другая тема.

