Я недавно проводил исследование, в рамках которого было необходимо обработать несколько сотен тысяч наборов входных данных. Для каждого набора — провести некоторые расчеты, результаты всех расчетов собрать вместе и выбрать "лучший" по некоторым критериям. По сути это bruteforce перебор. Тоже самое происходит при подборе параметров ML моделей с помощью GridSearch.
Однако, с некоторого момента размер вычислений может стать для одного компьютера великоват, даже если запускать ее в несколько процессов с помощью joblib. Или, если сказать точнее, он становится слишком долгим для нетерпеливого экспериментатора.
И поскольку в современной квартире сейчас можно найти больше одного "недогруженного" компьютера, а задача явно подходит для массового параллелизма — пора собрать свой домашний кластер и запускать такие задачи на нем.
Для построения "домашнего кластера" прекрасно подойдет библиотека Dask (https://dask.org/). Она проста в установке и не требовательна к узлам, что серьезно понижает "уровень входа" в кластерные вычисления.
Для настройки своего кластера нужно на всех компьютерах:
- установить интерпретатор python
- установить пакеты dask и прикладные пакеты вашего распределенного приложения
- сконфигурировать запуск планировщика (scheduler) на одном из компьютеров и работников (worker) на всех доступных
Также, возможно, прийдется немного поправить свое приложение — распределенные вычисления добавляют некоторые моменты, которые необходимо учитывать.
Развертывание кластера
Официальная документация (https://docs.dask.org/) хорошо описывает процесс установки. Приведу ниже некоторые неочевидные аспекты, с которыми столкнулся сам.
Версии python
Поскольку Dask в своих операциях зависит от pickle, на клиенте, шедулере и рабочих узлах необходимо держать версии одинаковые или очень близкие версии python.
Версии 3.6 и 3.7 вместе работают, хотя и выдается предупреждение о различии версий. Узлы с 3.8 вместе с предыдущими работать не будут из-за новой версии pickle.
Если все ставится "с нуля", то, очевидно, лучше ставить везде одну версию.
Пакеты Dask
Dask и необходимые зависимости устанавливается как стандартные пакеты с помощью pip или conda
pip install dask distributed bokeh
В документации под dask, последний пакет bokeh упоминается как опциональный, но не говориться, что без него "по-тихому" не будет работать прекрасная функция dask dashboard.
Без нее проводить мониторинг кластера и наблюдать как задачки разбегаются по узлам будет невозможно. А это очень поможет при оптимизации приложения для работы в распределенной среде.
Для сборки необходим gcc, потому:
- на MacOS должен быть установлен xcode
- если собираете docker image для запуска docker-worker, то начать с "тонкого" имиджа, типа
python:3.6-slim-busterможет не получиться. Прийдется либо доставлять необходимые пакеты, либо взять полноразмерный исходный имиджpython:3.6.
Запуск dask кластера
Процесс-планировщик создается один на кластер. Запускать его можно на любой машине. Единственная очевидная рекомендация — машина должна быть максимально доступна.
$ dask-scheduler
Процессы-работники запускаются на всех компьютерах, ресусами которых вы планируете пользоваться.
$ dask-worker schedulerhost:8786 --nprocs 4 --nthreads 1 --memory-limit 1GB --death-timeout 120 -name MyWorker --local-directory /tmp/
nprocs/nthreads— количество процессов, которые будут запущены, и количество потоков в каждом из них. Поскольку GIL присутствует и на стороне процессов-работников, запускать обработку на многих потоках имеет смысл только если распределенный процесс реализован на чем-то низкоуровневом, как numpy. В противном случае нужно масштабироваться за счет количества процессов.memory-limit— объем памяти, доступный каждому процессу. Ограничивать доступную память процесам нужно очень аккуратно — при достижении предела по памяти процесс-работник перестартовывает, что может вызвать остановку процесса обработки. Я сначала ставил ограничение, но потом убрал.death-timeout— время в секундах, в течении которого процессы-работники будут ждать, пока планировщик перезапустится. Это время нужно подбирать в соответствии с ожидаемым временем перезагрузки компьютера-планировщика. Как ни странно, похоже, этот параметр не всегда учитывается.name— префикс имени процесса-работника, как он будет отображаться в отчетах планировщика. Это удобно, чтобы видеть "человеческие" имена сервисов-работников.local-directory— директория, которая будет использоваться для создания временных файлов
Запуск процессов-работников на Windows в виде сервиса
Понятно, что запуск dask-worker со всему параметрами делается в виде пакетного файла. Также, чтобы кластер поднимался сам, dask-worker должен запускаться как только компьютер стартовал.
Решений задачи "запустить батник как сервис" множество. Я в последнее время использую утилиту NSSM (https://www.nssm.cc/).
NSSM, в частности, позволяет настроить рестарт пакетного файла, в случае его завершения. Это удобно для обработки ситуации, когда планировщик недоступен в течение длительного времени, и процессы-работники завершаются и останавливаются. В этом случае NSSM просто будет их перезапускать.
Также NSSM позволяет перенаправить консольный вывод из пакетного файла в ротируемый файл журнала. Бывает удобно для "разбора полетов"
Проверка Firewall
Также необходимо проверить правила firewall: планировщик должен иметь возможность достучаться до процесса-работника.
Неприятно, что если на узле, где запущен процесс-работник, блокируются входящие соединения — то об этом станет известно только при запуске приложения. В этом случае, если даже до одного узла не получится достучаться — весь клиентский процесс упадет. До этого будет казаться, что все в порядке, поскольку все узлы будут выглядеть как подключенные.
По умолчанию каждый процесс-работник открывает случайный порт. При запуске можно указать прослушиваемый порт, однако в этом случае будет запустить только один процесс.
Использование Dask в собственном приложении
Подключение к кластеру
Подключение к распределенному кластеру происходит очень просто:
from dask.distributed import Client client = Client('scheduler_host:port')
Если не указать расположение планировщика — запустится "локальный" кластер в пределах одной машины, но это не то что нужно.
Общие прикладные пакеты
Важно иметь ввиду, что все пакеты, которые необходимы для работы распределенного приложения должны быть установлены и на рабочих узлах кластера. Это касается pandas, numpy, scikit-learn, tensorflow.
Особо критично совпадение версий пакетов на всех узлах кластера для объектов, которые сериализуются.
Что делать, если на узлах кластера отсутствует необходимый пакет? Можно воспользоваться стандартной функцией удаленного запуска функций — и запустить pip
def install_packages(): try: import sys, subprocess subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'mypackage']) return (0) except: return (1) from dask.distributed import Client client = Client('scheduler:8786') client.run(install_packages)
Понятно, что данный трюк не очень подходит, если рабочие узлы запускаются в контейнерах. В этом случае проще и правильнее собрать обновленный имидж. Но для "домашнего" кластера, собранного на обычных компьютерах, подойдет.
Пакеты и модули приложения
Если в состав приложения входят разработанные пакеты или модули, и вы хотите, чтобы программный код из них выполнялся распределенно — то эти пакеты и модули также должны быть распространены на все узлы кластера перед запуском приложения.
Это довольно серьезное неудобство, если вы все еще дорабатываете приложение и пытаетесь его структурировать, и попутно запуская его в распределенной среде Dask кластера.
Есть задокументированный трюк с передачей пакетов и модулей на узлы кластера во время исполнения. Класс Client предлагает метод передачи файлов на узлы upload_file(). После передачи, файл размещается в пути поиска и может быть импортирован процессом работником.
Файл-модуль можно передать непосредственно, а пакет прийдется предварительно запаковать в zip.
from dask.distributed import Client import numpy as np from my_module import foo from my_package import bar def zoo(x) return (x**2 + 2*x + 1) x = np.random.rand(1000000) client = Client('scheduler:8786') # Локально определенная функция будет передана и исполнена прозрачно. # Ничего дополнительно не нужно делать r3 = client.map(zoo, x) # Если foo и bar должны выполняться на узлах кластера, # то содержащие их модуль и пакет необходимо предварительно передать на узлы кластера client.upload_file('my_module.py') client.upload_file('my_package.zip') # Теперь вызовы пройдут успешно r1 = client.map(foo, x) r2 = client.map(bar, x)
Масштабирование joblib
Я использую библиотеку joblib для удобного параллельного выполнения операций в рамках одного компьютера. Поскольку joblib позволяет подменить движок — модификация кода получается довольно простой:
Версия с joblib
from joblib import Parallel, delayed ... res = Parallel(n_jobs=-1)(delayed(my_proc)(c, ref_data) for c in candidates)
Версия с joblib + dask
# Стало from joblib import Parallel, delayed, parallel_backend from dask.distributed import Client ... client = Client('scheduler:8786') with parallel_backend('dask'): # просто "оборачиваем" вызов в модифицированный контекст res = Parallel(n_jobs=-1)(delayed(my_proc)(c, ref_data) for c in candidates)
Хотя, конечно, на самом деле все немного сложнее. Если посмотреть на то, как проходят вычисления в базовом случае — кластер простаивает подавляющее большинство времени:
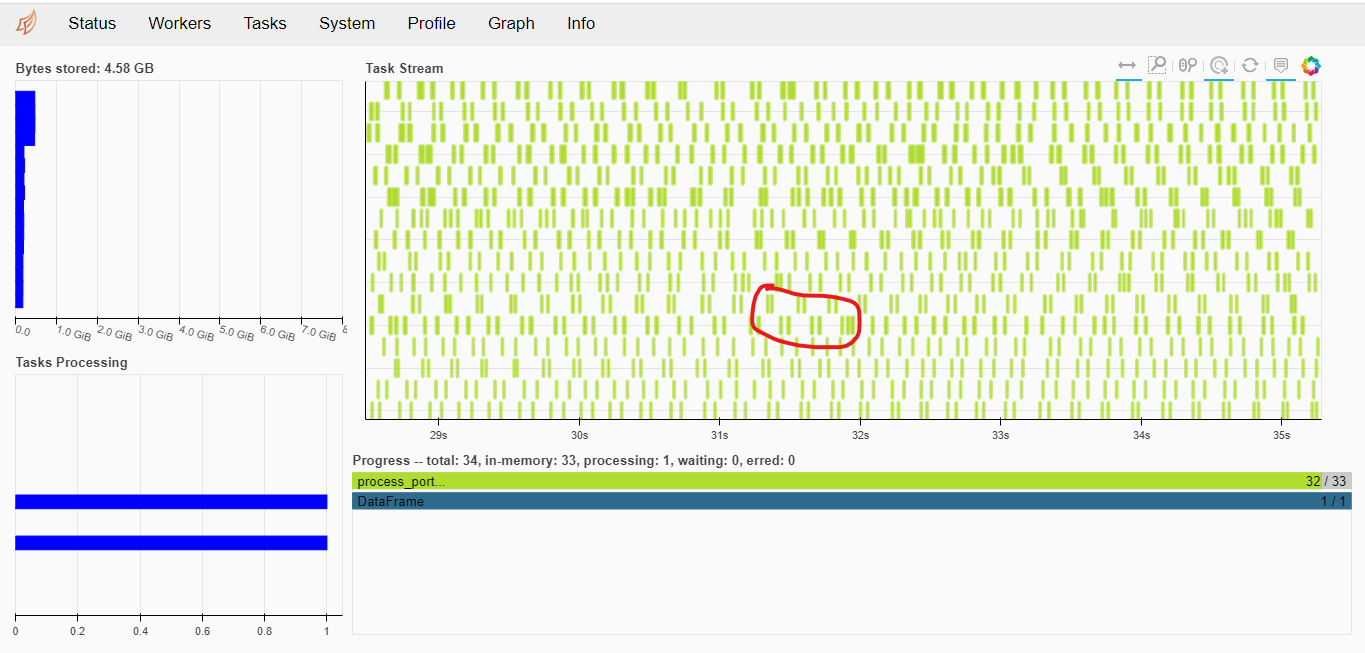
Работают только два из доступных 16 работников, огромные промежутки между интервалами загрузки.
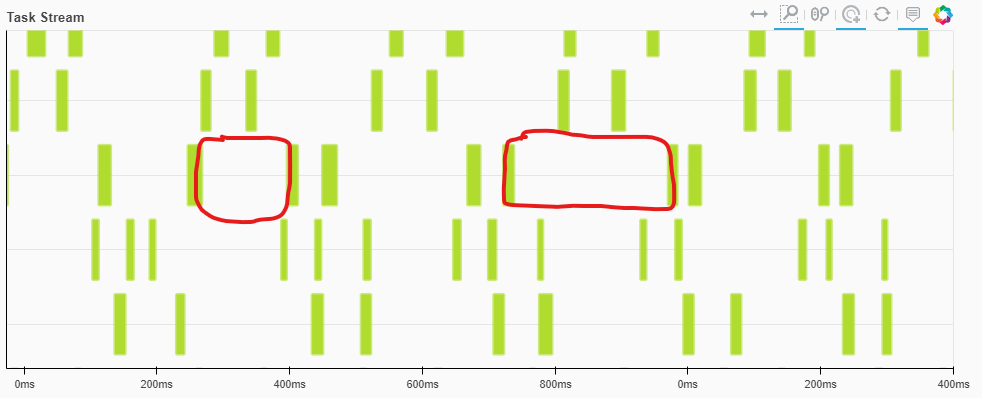
Время на выполнение одного батча — 10-20 мс, а интервалы между работами может достигать 200мс.
Для достижения хорошей загрузки распределенных узлов модифицированная версия программы будет обрастать параметрами и настройками, призванными сократить простой узлов из-за передач данных по сети.
# Стало from joblib import Parallel, delayed, parallel_backend from dask.distributed import Client ... client = Client('scheduler:8786') with parallel_backend('dask', scatter = [ref_data]): res = Parallel(n_jobs=-1, batch_size=<N>, pre_dispatch='3*n_jobs')(delayed(my_proc)(c, ref_data) for c in candidates)
Имеет смысл подбирать размер пакета параметром batch_size. Он должен быть не очень маленький — чтобы время обработки на узле кластера было значительно больше времени передачи пакета по сети, но и не очень большим, чтобы десериализация не занимала много времени.
Иногда также помогает подготовить чуть большее количество пакетов с помощью параметра pre_dispatch.

На картинке отмечены области, где процесс вычисления все еще неоптимален.
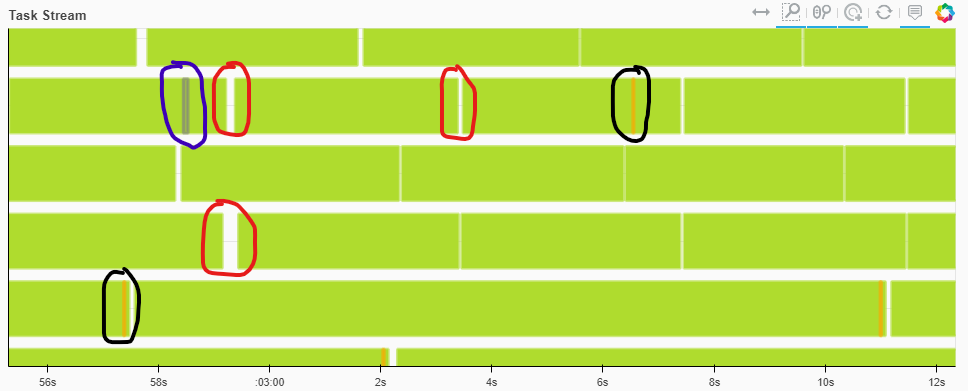
- Красные области — простой узла. Они остались, но доля простоя существенно сократилась.
- Синие области — десериализацию (большие объекты загружаются в память)
- Черные области — сброс части данных на диск
Теперь время выполнения вычислений для пакета работы занимает 3.5-4 сек, а время на простой измеряется десятками милисекунд. Стало гораздо лучше: видно, что увеличение размера батча и количества пред-запланированных задач увеличили время, выделенное на выполнение, и не добавили много оверхеда.
Этот простой эксперимент показывает, для достижения ожидаемой производительности вычислений параметры batch_size и pre_dispatchочень важны. Одна только их настройка может дать прирост пропускной способности в 8-10 раза за счет полной утилизации узлов кластера.
Если процедура, выполняемая на узле, требует помимо основного аргумента какие-либо вспомогательные блоки данных (которые, например, просматриваются в процессе обработки), их можно передать на все узлы параметром scatter. Это существенно снижает объем передаваемых данных по сети при кажом вызове и оставляет больше времени на расчеты.
В итоге, после подбора параметров на таких простых задачах можно достичь почти линейного роста производительности от роста количества узлов.
Масштабирование GridSearchCV
Поскольку scikit-learn также использует joblib для реализации параллельной работы, масштабирование обучения моделей достигается ровно также — подменой движка на dask
Например:
... lr = LogisticRegression(C=1, solver="liblinear", penalty='l1', max_iter=300) grid = {"C": 10.0 ** np.arange(-2, 3)} cv = GridSearchCV(lr, param_grid=grid, n_jobs=-1, cv=3, scoring='f1_weighted', verbose=True, return_train_score=True ) client = Client('scheduler:8786') with joblib.parallel_backend('dask'): cv.fit(x1, y) clf = cv.best_estimator_ print("Best params:", cv.best_params_) print("Best score:", cv.best_score_)
В результате выполнения:
Fitting 3 folds for each of 5 candidates, totalling 15 fits [Parallel(n_jobs=-1)]: Using backend DaskDistributedBackend with 12 concurrent workers. [Parallel(n_jobs=-1)]: Done 8 out of 15 | elapsed: 2.0min remaining: 1.7min [Parallel(n_jobs=-1)]: Done 15 out of 15 | elapsed: 16.1min finished /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/sklearn/linear_model/_logistic.py:1539: UserWarning: 'n_jobs' > 1 does not have any effect when 'solver' is set to 'liblinear'. Got 'n_jobs' = 16. " = {}.".format(effective_n_jobs(self.n_jobs))) Best params: {'C': 10.0} Best score: 0.9748830491726451
Каждый перебираемый вариант преобразуется в отдельную задачу для dask. Таким образом все варианты распределяется случайным образом по всем доступным процессам-работникам.
При наличии достаточного количества работников в кластере — все работы начинают выполняться параллельно.
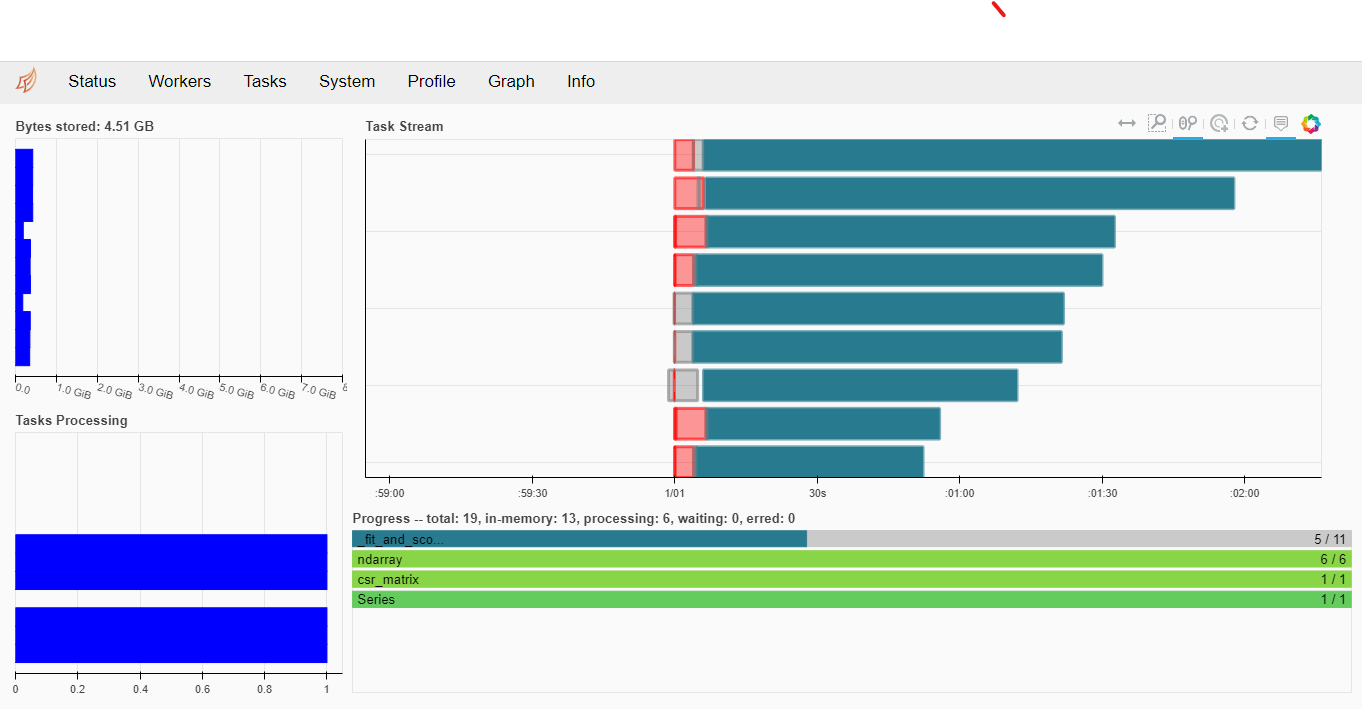
К сожалению, в случае если модель с разными значениями гиперпараметров сходится за разное время (как в данном случае) — параллелизм не приводит к сокращению времени пропорционально количеству узлов кластера. Но длительность всего процесса подбора становится сравнима с самым долгим вариантом — уже очень неплохо.
Заключение
Библиотека Dask — прекрасный инструмент для масштабирования для определенного класса задач. Даже если использовать только базовый dask.distributed и оставить в стороне специализированные расширения dask.dataframe, dask.array, dask.ml — можно существенно ускорить эксперименты. В некоторых случаях можно добиться почти линейного ускорения рассчетов.
И все это — на базе того, что у вас уже есть дома, и используется для просмотра видео, прокрутки бесконечной новостной ленты или игр. Используйте эти ресурсы на полную!

