
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
В-общем согласен, только замечу, что непреднамеренная сложность (accidental complexity) является обычной необходимой сложностью, которую вовремя не обнаружили и не разложили по необходимым абстракциям (или не создали необходимые) и не задокументировали.
Люди не стараются себе специально усложнить жизнь и привнести побольше сложностей, обычно то, что мы называем непреднамеренной сложностью появляется из-за того, что они слишком упростили штуки в других местах, нет?
Есть два способа борьбы со сложностью — инновации и переиспользвание. На днях переписал свой старый пет проект на современный лад и закрыл несколько ишью на гитхабе. Бандл по объему уменьшился раз в пять.
Благодаря инновациям мир с каждым днём становится стандартнее и проще, превращая когда-то essential complexity в accidental. А с этим бороться все умеют. Нужно лишь периодически собираться силой воли и устраивать генеральную уборку.
является обычной необходимой сложностью
Нет, не является. Простой пример — римские числа. Их сложно умножать (без перевода предварительно в арабские), но эта сложность не является необходимой. Просто эти числа реализованы криво.
Я правильно понимаю, что вы считаете, что римские числа обладали некоей сложностью, а при переходе к арабским позиционным числам часть сложности просто исчезла?
Работа с римскими числами имела лишнюю сложность, потому что они неудачно сделаны.
Да, эта лишняя сложность просто исчезла. Она не была внутренней сложностью домена "умножение чисел", она была случайной, ненужной. Вы, вероятно, имеете ввиду какой-то "закон сохранения сложности", однако его нет. Сложность легко сделать на пустом месте, из ничего, специально.
С римскими числами верно подмечено. Вы думаете нельзя придумать откровенно неудачную реализацию? Такую, сложность которой невозможно оправдать никак.
Вот кстати это как раз хороший пример получился того, как зачастую разработчики решают не ту проблему (более общую, более сложную, просто другую), и в итоге решение накапливает в себе сложность предметной области, которой оно касаться не должно.
Например, нужно было придумать систему для простого умножения, а разработчик зачем-то добавил туда возможность лёгкой оценки порядка величины. Или наоборот.
В итоге решение получилось более сложным, чем могло быть.
если сначала идет M, то сразу понятно что порядок величины — тысячи
Верно. А если C — то сотни. Например, CMXXXVII — сразу видно, что порядок около сотни, не так ли?
На самом деле нет, это 937. То есть даже вашу удачную задачу римские цифры решают так себе, кое-как.
Формально говоря, десятичный логарифм 937 округляется до трёх, а не до двух.
Если вам нужно узнать, число меньше тысячи или нет, то вы правы. 999 тоже меньше тысячи.
На практике, оно из частых использований чисел — это цены. Вы согласитесь с фразой "это стоит несколько сотен" при цене 937? Или если скажут "они примерно одинаковые по цене, CXXXVII и CMXXXVII". Так что для нормальной оценки вам совершенно точно не хватит первой цифры.
Суть не в лингвистике, а а цели, которую вы перед собой ставите. Если "определить разрядность небольшого числа", то, по всей видимости это действительно юзкейс, когда римские цифры проще (не нужно считать количество цифр).
Не могу представить ситуацию, что бы именно это было настолько важно, что бы на самом деле использовать римские числа, но забавно.
Со случаем римских чисел согласиться не могу, в данном случае часть сложности, которая ушла от перехода от римских чисел к позиционным арабским переместилась в систему образования, когда школьники до 4-го класса учатся делать простые арифметические операции с ними (в то время как в детском саду легко складывают/вычитают на палочках) при этом правильно учитывая переносы в разрядах. То есть сложность частично переместилась на уровень документации и обучения.
Но есть в каком-то смысле экстремальный случай — это, например, обфускация. И здесь я соглашусь, что это похоже на создание большой сложности из воздуха, которую мы затем можем с определёнными усилиями постепенно уменьшать, распутывая шаг за шагом этот обфусцированный код. Но бесконечно упрощать мы всё равно не сможем, это просто противоречит теории информации.
Я представляю этот процесс примерно как у нас есть система определённой сложности, обладающей некоторой энтропией. С помощью рефакторинга мы можем спуститься в локальный минимум энтропии. Но чтобы опускаться ещё ниже, нам нужно переделать и, например, перестроить код на других абстракциях (скажем, перейти от коллбэков к асинкам). При этом, как говорит автор статьи, часть сложности перейдёт на уровень документации и обучения, но код мы можем разгрузить довольно сильно, рефакторингами снова скатившись в локальный минимум энтропии.
Но всегда есть нижняя граница сложности, ниже которой мы не опустимся. Поэтому её (сложность) нужно будет куда-то растолкать. Как-то так.
школьники до 4-го класса учатся делать простые арифметические операции
Вы утверждаете, что третьекласснику научиться складывать римские цифры будет проще, чем арабские? Римские цифры — это не просто палочки пересчитать, там есть ещё пара правил, не таких уж простых для третьеклассника. XXIV + XXI простым подсчетом палочек не посчитаешь.
бесконечно упрощать мы всё равно не сможем
Я ничего не говорил про бесконечность. Мой тезис был — в некоторых ситуациях мы можем упростить. Не переместить, не обменять сложность, а убрать.
локальный минимум энтропии
+1. Если вы уверены, что текущий код более-менее близок к локальному минимуму, тогда пора распределять сложность. Но не ранее.
if (some == true)if (length(str) > 0)if (some)if (str != "")if (str != "")иногда напротив человека который слишком часто обжигался.Ага, обжигался, и вместо того, чтобы разобраться с причинами, нашёл работающий костыль, более сложный.
if 2 == var if var == 2Length — это сложный костыль? Нет никакого преимущества в записи str != "". Есть желание, пишите так, не проблема. Но и пользы нет.
Вариативность больше. Первая мысль глядя на != "" — а сравнение тут по значению или по ссылке/указателю? Не явно как-то.
Вы мне, как человеку, говорите, что человеку труднее читать length? Ожидаете, что я могу согласиться даже несмотря на то, что мне легче?
Вы не можете сказать "дерево больше, поэтому сложнее", потому что это должно определяться экспериментом напрямую (опросом своей команды, хотя бы). Если для вас сложнее, не вопрос, соглашусь. Внутри своей команды используете тот вариант, который проще участникам команды.
Imho сложность-то никуда не девается, но вот "одновременно требуемую" сложность можно снижать. Это как переход от списка к дереву: вроде элементов то же количество, но уже ищем нужный не за линейное время, а за логарифмическое.
Зато в дереве сам элемент стал сложнее — ему уже нужно иметь два потомка (в случае BST).
Так что не видно понижения одновременно требуемой сложности. Она снова перераспределилась!
Вся сложность разработки микросервисов уехала из отдельных сервисов на уровень "заставить всё это работать вместе".
Существенно усложнилось тестирование (теперь оно практически всё интеграционное), усложнились протоколы обмена, стало трудно получить целостность данных (см. raft/paxos и прочее веселье), усложнилось развёртывание. Что отлично подтверждает тезис о том, что сложность никуда не девается, а она просто перераспределяется
Спасибо, осталось только добавить, что в функциональных языках все проблемы решены, ведь там всё на функциях, поэтому все бегом туда!
Каждая функция делает свое дело (API вызов) и является объектом познания без изучения кода.
А, может быть, она таковой является только потому, что мы когда-то изучили смысл слов на нашем разговорном языке?) По названию функции предполагаем что она делает. Сложность теперь там..)
fun <T : Comparable<T>> Iterable<T>.sorted(): List<T>
impl<T> [T]
pub fn sort(&mut self) where T: Ord
extension Sequence where Element: Comparable {
public func sorted() -> [Element]
}
Так ведь требования бизнеса тоже не высечены в камне. Они точно также могут рефакториться, чтобы одновременно их расширить и привести в порядок, и заодно после этого можно организовать свою архитектуру приложения так, чтобы все были в выигрыше. Упрощение и приведение в порядок продукта (до определенного предела, конечно) не всегда ухудшает его полезность и применимость на практике — обычно всё даже наоборот.
Архитектура, обычно, не средство борьбы со сложностью, а дополнительная сложность, превносимая для упорядочивания основной сложности, уменьшения её энтропии.
Озвучу весьма непопулярное мнение среди многих разработчиков, с которыми приходилось сталкиваться: от сложности можно полностью (или почти полностью) избавиться. Да, безусловно, если вам нужно, скажем, сложить два числа, как приводили в комментариях выше, вам нужна абстракция чисел, но не более того.
Не думаю, что будет преувеличением сказать, что люди тысячелетиями считали, что умножение это сложная дисциплина, доступная лишь многим посвященным, не говоря уже о делении (которое в римской записи я вообще не представляю, как можно быстро сделать). Однако, вся эта сложность на самом деле была обусловлена плохой абстракцией: как только научились записывать числа в экспоненциальной нотации (я так назвал обычные наши с вами числа :)), сразу их стало легко умножать, складывать, делить и т.д.
То же самое относится к физике: до того, как Ньютон открыл «простейший» закон «F = m * a», любые расчеты траекторий движения тел (в основном, я полагаю, людей тогда интересовало движение ядер из пушек или требушетов :)) были очень сложными и силы вроде «силы инерции», «силы тяготения», «сила сопротивления воздуха» и прочих считались силами разной природы и комбинировать их и пытаться что-то посчитать было делом очень сложным и порождало много неточностей.
Уверен, что в соответствующие времена считалось, что умножение и деление, или же расчет траектории движения объектов — это очень сложная вещь, и сложность обусловлена постановкой задачи, а не тем, что просто выбранные абстракции не позволяют сделать проблему тривиальной.
Я на своем опыте видел очень мало случаев, когда сложность какой-то проблемы действительно была обусловлена естественной сложностью проблемы: почти всегда программисты/инженеры создают себе преграды для решения своих задач сами, тот самый «оверинжиниринг». Но даже в случаях, когда используются общепринятые подходы для решения какой-то задачи (например, деплой кода PHP-приложения — куда уж проще?), зачастую эти подходы вас ограничивают от нахождения решения, которое одновременно и проще и решает вашу задачу — и вот это как раз то место, «куда девается сложность» — это не сложность нельзя убрать, это от энтропии не избавиться :).
Чтобы сделать действительно простую (и от этого весьма надежную, как дополнительный бонус) систему, нужно приложить много усилий — энтропия вселенной тоже возрастает от того, что вы работаете над вашей системой, однако при этом энтропия вашей системы уменьшается (ценой суммарного нагрева вселенной за счёт необходимости для вас попыхтеть над решением задачи). То есть, я хочу сказать, что как правило решение для большинства сложных (или даже, на первый взгляд, невыполнимых) задач есть, и почти всегда суммарную сложность можно понизить даже до такой степени, что сама система станет проще, чем формулировка задачи, и для того, чтобы добиться этого, нужно приложить очень много усилий, и они не всегда оправданы (в качестве примера такой системы можно привести те же арабские числа в сочетании с экспоненциальной нотацией, которую мы используем — попробуйте описать в двух словах, для чего она вам вообще нужна и какую задачу решает сложение, вычитание, деление, умножение; как насчёт смысла отрицательных чисел и нуля? при этом сами числа и операции с ними очень просты).
Так что давайте прекращать говорить в терминах accidential complexity и essential complexity. Почти всегда систему можно упростить ещё дальше, чем, казалось бы, требует задача, и получить ещё больше гибкости и расширить границы применимости системы в итоге. Именно к этому нужно стремиться, когда вы создаете платформу для чего-либо, и не жалеть сил на работу над ней, потому что в итоге вы освободите ресурсы мозга тем, кто будет этой платформой пользоваться и они смогут решать более сложные задачи, чем до этого, причём ценой меньших усилий.
Конечно же нет. Не нужно для каждой простой задачи придумывать DSL. Но, если при решении какой-то проблемы возникают существенные трудности (например, в ~2000х построить большое распределенное хранилище было очень сложной задачей, да и до сих пор в какой-то степени это справедливо), стоит потратить дополнительные ресурсы для того, чтобы сделать конкретное решение простым. Потому что все, кто будет этим решением потом пользоваться, смогут сэкономить суммарно намного много времени, чем было потрачено на дизайн системы.
Я скорее говорю про то, что зачастую сложности вообще не должно быть, и что она возникает лишь от нежелания упрощать систему / либо что упрощение является слишком трудоемким. Безусловно, упрощением системы скорее всего будут заниматься наиболее опытные коллеги. К сожалению, не могу найти источник, но мне нравится такое определение junior/middle/etc:
Если у вас есть какая-то проблема и её поручили решить X, то вот, что будет на разных уровнях:
Пользуясь этой схемой, можно сказать, что начиная с уровня Senior сложностью в системе уже можно осознанно управлять и контролировать её. А godlike-разработчики (которых в природе очень мало) берут и меняют систему так, что кокнретной проблемы в ней просто больше нет. Сложность просто исчезла, и возможно заодно у продукта появились ещё какие-то фичи, которых ранее не было, потому что система была спроектирована не оптимально для решения поставленной для неё задачи. Собственно, арабские числа vs. римские как пример такой трансформации.
Поэтому стоит пользоватьс языками, где подобный фреймворк/DSL можно сделать попенсорсно, тогда если 100 Петь вложат половину времени, сколько потратили бы на задачу, каждый из них получит инструмент, который позволяет им всем решить их задачи "просто", да ещё и помогает неограниченному кругу других лиц.
LISP :)?
100 Петь вложат половину времениОни друг с другом не договорятся. Каждый видит по-своему и будет пилить в свою сторону. А когда в репозиториях свободно лежит 100 решений, интереснее делать своё, чем изучать и выбирать.
Ну как-то же делают. Вон attoparsec/servant/diesel/r2d2/serde/… есть же, тысячи их.
Или более абстрактные: monix/zio/..., да хоть те же Akka/Spark
Мм, чтобы использовать акку можно потратить десяток часов и сэкономить 100. То же и с другими либами.
мм, нет, обычно библиотеку можно найти просто по тегам или описанию в гугле, по совету в чатике… А в более крутых языках можно просто загуглить сгинатуру функции которая нужна и выдача предоставит нужные библиотеки. Например, пишем a -> ByteString и находим библиотеки по сериализации в JSON и другие текстовые форматы.
И первую попавшуюся брать или всё же изучить каждую, сравнить и т. п.?
Ну я сравниваю, но я все равно трачу на это на порядки меньше времени, чем я бы свой aeson реализовывал.
Тем более, что обычно основные либы все уже знают: чем хостить сервер, чем преобразовывать в JSON/протобаф, чем ходить в БД, чем писать логи… 99% зависимостй описано, остается специфика из разряда "Хотим хитрые ретраи" и "интегрируемся с редким сервисом".
И когда на разработчика сваливается реальная задача, он должен сначала построить фреймворк и DSL (или найти подходящие), а потом решить задачу «просто», так?Зависит от количества задач. Если подобные задачи ожидаются регулярно и в большом количестве, то вполне логично потратить время и силы на создание универсального инструмента для упрощения их последующего решения.
М?
(Там первая строка является ссылкой)
Целью разработки было создание простого непроцедурного языка, которым мог воспользоваться любой пользователь, даже не имеющий навыков программирования.
Это про тот, про который не стихают холивары унжно ли переносить логику в его процедуры? :)
А там как раз хороший пример про систему сборки. И это, на мой взгляд, применимо и к какому-нибудь специфичному непроцедурному языку, и к другим системам.
Например, мне довелось работать над data-flow языком, который выражается диаграммами:
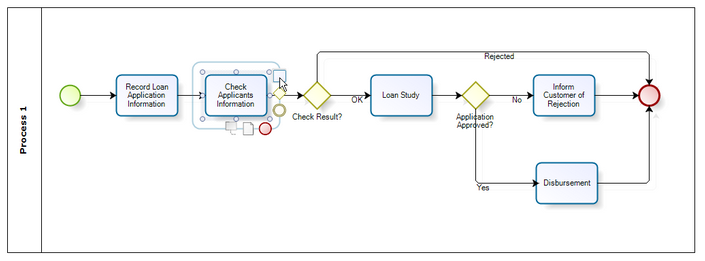
И так далее. Всё в точности, как в статье.
Я упомянул обфускацию.
Сложность должна обитать где-то