Встречайте, вот и Go 1.18, а с ней – первый релиз долгожданной реализации дженериков, наконец-то готовых к реальному использованию в продакшене. Дженерики – это весьма востребованная возможность, давно вызывающая жаркие споры в сообществе Go. С одной стороны, самые голосистые беспокоятся по поводу сложности, которую привносят дженерики. Их страшит неизбежная эволюция Go, которая доведет его либо до многословия как в энтерпрайз-версии Java, со своими обобщенными фабриками, либо, самое страшное, превратит Go в вырожденный HaskellScript, где if-ы придется заменить монадами. Положа руку на сердце, оба этих опасения могут быть преувеличенными. С другой стороны, поборники дженериков считают, что дженерики критически важны для масштабного внедрения чистого кода, пригодного для многоразового использования.
Автор этой статьи не принимает ни одну из сторон в данных дебатах и не дает рекомендаций, где и в каких случаях использовать дженерики в Go. Напротив, эта статья призвана осветить запутанный случай с дженериками в Go с третьей стороны: с точки зрения системных программистов, которые воодушевлены не дженериками как таковыми, а мономорфизацией и тем, как она может сказаться на производительности. Нас таких десятки. Десятки! И мы все имеем изъявить некоторое серьезное разочарование.
Реализация дженериков в Go 1.18
Есть много различных способов реализовать в языке программирования параметрический полиморфизм (который обычно называют «дженерики»). Давайте кратко обсудим эту область задач, чтобы понять то решение, которое было внедрено в Go 1.18. Поскольку эта статья рассказывает о системной инженерии, дискуссию о теории типов мы выдержим в легкой и безболезненной форме. А вместо технических терминов часто будем использовать слово «штуки».
Допустим, вы хотите создать полиморфную функцию, которая одинаково обращается с разными штуками. В широком смысле, к этому существует два подхода.
Во-первых, можно сделать все штуки, над которыми будет оперировать функция, такими, чтобы они выглядели и действовали одинаково. Такой подход называется «упаковка», и обычно он предполагает выделение «штук» в куче, после чего остается просто передавать нашей функции указатели на них. Поскольку все штуки по форме одинаковы (это же указатели!), все, что нам требуется для операций над ними – знать, где находятся методы для операций над этими штуками. Следовательно, указателям на штуки, передаваемым нашей функции, обычно сопутствует таблица указателей на функции, часто именуемая «таблицей виртуальных методов» или vtable для краткости. Улавливаете? Именно так реализуются интерфейсы в Go, но не только они, а еще и типажи dyn Trait в Rust и виртуальные классы в C++. Все это – разновидности полиморфизма, которыми легко пользоваться на практике, но им недостает выразительности, а во время исполнения работа с ними влечет издержки.
Второй способ заставить функцию оперировать над множеством разных штук называется «мономорфизация». Звучит, может быть, страшновато, но реализация ее относительно проста. Сводится к созданию отдельной копии функции для каждой уникальной штуки, над которой предполагается производить операции. Вот и все, да. Если у вас есть функция, складывающая два числа, и вы можете вызвать ее, чтобы сложить два float64, то компилятор создаст копию этой функции и заменит заглушку обобщенного типа на float64, а затем скомпилирует эту функцию. Это, бесспорно, наиболее прямолинейный способ реализовать полиморфизм (пусть иногда и становится весьма сложно применять его на практике), а для компилятора этот способ также самый затратный.
Исторически именно мономорфизация выбиралась для проектирования и реализации дженериков в языках системного программирования, в частности, C++, D или Rust. На то есть много причин, но все сводится к компромиссу: соглашаясь на заметное увеличение времени компиляции, получаем значительный выигрыш по производительности в результирующем коде. Когда заменяете заглушки типов в обобщенном коде окончательно выбранными типами, еще до того, как компилятор осуществит над ними какие-либо оптимизации, вы сами успеваете сделать очень занятную гамму оптимизаций, которые были бы, в сущности, невозможны при использовании упакованных типов. В качестве абсолютного минимума, вам пришлось бы девиртуализировать вызовы функций и избавиться от виртуальных таблиц; при наилучшем развитии событий для этого потребовалось бы встраивать код в строку, что, в свою очередь, открывает путь для новых оптимизаций. Такое встраивание кода – это отлично. Мономорфизация – сплошной выигрыш в языках системного программирования; это, в сущности, единственная форма полиморфизма, у которой нулевые издержки во время исполнения, а зачастую издержки при производительности даже оказываются отрицательными. То есть, при мономорфизации обобщенный код становится быстрее.
Итак, я, как человек, работающий над производительностью в больших приложениях на Go, признаю, что меня дженерики в Go особо не впечатлили, правда. Я загорелся мономорфизацией а также потенциалом для компилятора Go в том, что касается оптимизаций, которые были бы просто невозможны, если работать с интерфейсами. Следите, в чем я разочаровался: реализация дженериков в Go 1.18 просто не использует мономорфизацию… по крайней мере, не использует полноценно.
На самом деле, она основывается на приеме частичной мономорфизации, которая называется «Контурирование [stenciling] GCShape при помощи словарей». Подробно о данном технологическом выборе рассказано в этом проектировочном документе, который доступен в вышестоящем репозитории. Для полноты картины и для лучшей ориентации в анализе производительности, который приведен в этом посте, кратко резюмирую данный документ:
Ключевая идея такова: поскольку при полной мономорфизации вызова каждой функции на основе ее входных аргументов придется иметь дело с солидными объемами сгенерированного кода, можно сократить количество уникальных очертаний функций, мономорфизируя их на более высоком уровне, чем типы аргументов. Следовательно, при такой реализации дженериков компилятор Go выполняет мономорфизацию (то, что в документе по ссылке именуется «stenciling») на основе GCShape аргументов, а не их типа. GCShape типа – это абстрактная концепция, специфичная для языка Go и этой реализации дженериков. Как указано в документе по проектированию, «два конкретных типа группируются в один и тот же gcshape тогда и только тогда, когда происходят от одного и того же базового типа, или сами по типу оба относятся к указателям». Первая часть этого определения ясна: если у вас есть метод, который, скажем, выполняет над своими аргументами арифметическую операцию, то компилятор Go фактически мономорфизирует ее на основе типов аргументов. Сгенерированный код для uint32, использующий арифметические инструкции для работы с целыми числами, будет отличаться от кода для float64, в котором будут применяться инструкции для работы с числами с плавающей точкой. С другой стороны, сгенерированный код, предназначенный для алиасинга типов под uint32, будет таким же, как для базового uint32.
Пока все понятно. Но вторая часть определения GCShape существеннейшим образом сказывается на работе с производительностью. Я это акцентирую: Все указатели на объекты относятся к одному и тому же GCShape, независимо от того, на какой объект указывают. Это означает, что у указателя на *time.Time будет такой же GCShape, как и у *uint64, у *bytes.Buffer и у *strings.Builder. Возможно, у вас уже назрел вопрос: “Уф, а что же будет, если мы захотим вызвать метод для обработки этих объектов? Местоположение такого метода, вероятно, не может входить в состав GCShape!”. Да, этот момент спойлерится в самом названии документа: GCShapes ничего не знают о методах, поэтому нам придется поговорить о словарях, которые их сопровождают.
В актуальной реализации дженериков по состоянию на 1.18, при каждом вызове обобщенной функции во время выполнения она будет прозрачно получать в качестве своего первого аргумента статический словарь с метаданными об аргументах, передаваемых этой функции. Словарь будет помещаться в регистр AX в AMD64 и в стек на тех платформах, где компилятор Go пока не поддерживает соглашений, связанных с вызовами на основе регистров. Подробности реализации этих словарей досконально объяснены в вышеупомянутом документе, но для краткости скажу: они включают все метаданные типов, которые понадобятся для передачи аргументов следующим обобщенным функциям, для преобразования их из интерфейсов и в интерфейсы, и, что для нас наиболее важно, для вызова методов с целью их обработки. Все верно, уже после этапа мономорфизации функция с имеющейся формой должна во время выполнения принять в качестве ввода таблицы виртуальных методов для всех ее обобщенных аргументов. Интуиция подсказывает: притом, что такой подход значительно уменьшает объем уникального кода, генерируемого при работе, широкая мономорфизация такого рода не приспособлена к девиртуализации, встраиванию в строку, да и вообще к каким-либо оптимизациям производительности.
Фактически, может показаться, что для абсолютного большинства кода на Go верно следующее: в результате обобщения такой код становится медленнее. Но, прежде, чем нас затянет в трясину отчаяния, давайте расставим несколько контрольных точек, посмотрим на код сборки и проверим некоторые варианты поведения.
Встраивание интерфейсов
Vitess, свободно распространяемая распределенная база данных, обеспечивающая работу PlanetScale – это большое и сложное приложение на Go для реальных задач, и отлично подходит в качестве испытательного полигона для проверки новых возможностей языка Go, в особенности тех, что связаны с производительностью. У меня нашелся длинный список функций и реализаций для Vitess, которые в настоящее время мономорфизируются вручную (вот как я изящно сказал “копипастятся, но уже с другими типами”). Некоторые из этих функций дублируются, поскольку их полиморфизм не смоделировать при помощи интерфейсов; другие дублируются, поскольку критичны для производительности, и, если скомпилировать их без интерфейсов, получается ощутимый выигрыш в производительности.
Рассмотрим интересного «кандидата» из этого списка: функции BufEncodeSQL из пакета sqltypes. Эти функции дублируются так, чтобы они могли принимать *strings.Builder или *bytes.Buffer, так как выполняют много вызовов к предоставляемому буферу, и эти вызовы могут встраиваться компилятором, если буфер передается как неупакованный тип, в противовес интерфейсу. В результате получается существенный выигрыш в производительности у функции, которая широко применяется во всей базе кода.
Обобщить такой код не составит труда, так что давайте это сделаем и сравним обобщенную версию этой функции с простой версией, которая принимает io.ByteWriter в качестве интерфейса.

!["".BufEncodeStringSQL[go.shape.*uint8_0]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/b37/62c/d90/b3762cd9071cc7672a3c9600cb22cbf2.png "\"\".BufEncodeStringSQL[go.shape.*uint8_0]")
Нет ничего удивительного в коде сборки для версии io.ByteWriter: все вызовы к WriteByte происходят через itab. Вскоре мы подробно рассмотрим, что именно это значит. Но оказывается, что обобщенная версия становится все интереснее. Во-первых, мы видим, что компилятор сгенерировал всего один вариант формы, когда инстанцировал функцию (BufEncodeStringSQL[go.shape.*uint8_0]). Хотя, во встроенном представлении мы этого не показываем, нам придется вызвать обобщенную функцию при помощи *strings.Builder из достижимого кода; в противном случае компилятор вообще не сгенерирует никаких вариантов инстанцирования для функции:
var sb strings.Builder BufEncodeStringSQL(&sb, []byte(nil))
Поскольку мы вызвали функцию с *strings.Builder в качестве аргумента, мы увидим в сгенерированной сборке форму *uint8. Как было объяснено выше, все обобщенные вызовы, принимающие указатель в качестве обобщенного аргумента, контурируются как *uint8, независимо от того, на какой объект указывают. Фактические свойства объекта – и, что наиболее важно, его itab – хранятся в словаре, который передается обобщенной функции.
Все это соответствует тому, что мы прочитали в документе по проектированию: в процессе контурирования тот указатель, который был направлен на структуру, мономорфизируется и принимает такой вид, как будто указывает в никуда (void). Никакие другие атрибуты указателя на объект не учитываются в процессе мономорфизации, и, следовательно, какое-либо встраивание невозможно. Информация о тех методах структуры, которые поддаются встраиванию, доступна только в словаре во время выполнения. Это уже препятствие: как мы успели убедиться, контурирование спроектировано таким образом, что не допускает девиртуализации вызовов функций и, следовательно, не предоставляет компилятору возможностей встраивания. Но подождите, худшее еще впереди!
Есть глубокий анализ производительности, который мы можем сделать на основе фрагмента кода, сравнив сборку, сгенерированную для вызова метода WriteByte в коде интерфейса по сравнению с обобщенным кодом.
Интерлюдия: вызов метода интерфейса в Go
Прежде, чем мы сможем сравнить вызовы в первой и во второй версии кода, давайте быстро освежим в памяти, как в Go реализуются интерфейсы. Мы кратко коснулись того факта, что интерфейсы – это вариант полиморфизма, при котором применяется упаковка, т.е., гарантируется, что все объекты, которыми мы оперируем, имеют одинаковую форму. В случае с интерфейсом Go это толстый 16-байтный указатель (iface), где первая часть указывает на метаданные, описывающие упакованное значение (то, что мы называем itab), а вторая часть указывает на само значение.
type iface struct { tab *itab data unsafe.Pointer } type itab struct { inter *interfacetype // смещение 0 _type *_type // смещение 8 hash uint32 // смещение 16 _ [4]byte fun [1]uintptr // смещение 24... }
В этом itab содержится масса информации о типе внутри интерфейса. Поля inter, _type и hash содержат все требуемые метаданные, которые обеспечивали бы преобразование между интерфейсами, рефлексию и переключение по типу интерфейса. Но нас в данном случае наиболее интересует массив fun в конце itab: хотя, в описании типа он и отображается как [1]uintptr, на самом деле под него выделяется память переменной длины. Размер структуры itab меняется от интерфейса к интерфейсу, и в конце структуры оставлено достаточно места, чтобы сохранить указатель функции для каждого метода в интерфейсе. Именно к этим указателям функций мы должны будем обращаться всякий раз, когда захотим вызвать метод в интерфейсе; в Go они эквивалентны виртуальной таблице C++.
Помня об этом, теперь можно понять сборку вызовов для метода интерфейса в необобщенной реализации нашей функции. Вот во что компилируется строка 8, buf.WriteByte('\\'):

Для вызова метода WriteByte в buf, нам первым делом нужен указатель на itab для buf. Хотя, buf исходно передавался в нашу функцию в паре регистров, компилятор пролил его в стек в начале тела функции, так, что она может использовать регистры для других целей. Чтобы вызвать метод в buf, мы сначала должны загрузить *itab из стека обратно в регистр (CX). Теперь мы можем разыменовать указатель itab в CX для доступа к его полям: мы перемещаем двойное слово со смещением 24 в DX, а, если быстро глянуть в исходное определение itab выше, то, действительно, первый указатель функции в itab находится со смещением 24 – все это пока кажется осмысленным.
Когда в DX содержится адрес функции, которую мы хотим вызвать, мы просто пропускаем ее аргументы. То, что в Go называется «метод, прикрепленный к структуре» - это сахар для самостоятельной функции, которая принимает в качестве первого аргумента свой получатель, напр., func (b *Builder) WriteByte(x byte) без сахара превращается в func "".(*Builder).WriteByte(b *Builder, x byte). Следовательно, первый аргумент при вызове нашей функции должен быть buf.(*iface).data, фактически, это указатель на strings.Builder, который находится внутри нашего интерфейса. Этот указатель доступен в стеке, через 8 байт после указателя tab, который мы только что загрузили. Наконец, второй аргумент нашей функции – это литерал \\, (ASCII 92), и можно CALL DX, чтобы выполнить наш метод.
Уф! Пришлось попотеть, чтобы вызвать простой метод. Хотя, при практической оценке производительности, это не так плохо. Не считая того, что при вызове через интерфейс невозможно осуществлять встраивание, фактические издержки на вызов сводятся к единственному разыменованию указателя для загрузки адреса функции из itab. Прямо сейчас мы расставим тут бенчмарки чтобы посмотреть, во сколько нам обходится такое разыменование, но сначала давайте рассмотрим процесс генерации обобщенного кода.
Вернемся к дженерикам: вызовы указателей
Вернемся к коду сборки нашей обобщенной функции. В качестве напоминания: мы анализируем ту форму, в которой инстанцируется *uint8, поскольку все контуры, в которой инстанцируются указатели, похожи: это указатели, направленные в пустоту (void). Рассмотрим, как выглядит вызов метода WriteByte в buf:
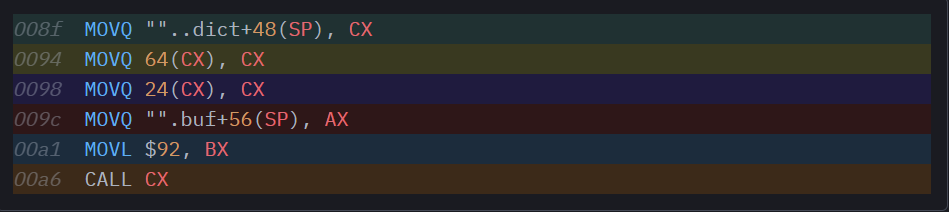
Выглядит весьма знакомо, но, все-таки, есть резкая разница. В точке со смещением 0x0094 содержится то, что нам совершенно не нужно на месте, где вызывается функция: разыменование еще одного указателя. С технической точки зрения это, опять же, одно большое разочарование. Вот что здесь происходит: поскольку мы мономорфизируем все контуры указателей в единую форму, для *uint8, в этом контуре не содержится никакой информации о методах, которые могут вызываться в этих указателях. Где должна находиться эта информация? В идеале она должна была бы лежать в itab, ассоциированном с нашим указателем, но здесь нет itab, который был бы прямо ассоциирован с нашим указателем, поскольку форма нашей функции такова, что в качестве аргумента buf она принимает единственный 8-байтный указатель, в противовес 16-байтному толстому указателю с полями *itab и data, как это делалось бы в интерфейсе. Как вы помните, именно по этой причине в реализации с контурами каждому обобщенному вызову функции передается словарь: в этом словаре содержатся указатели на itab-ы всех обобщенных аргументов функции.
Хорошо, теперь, с дополнительной нагрузкой, эта сборка становится совершенно осмысленной. Вызов метода начинается не с загрузки itab для нашего buf, а с загрузки словаря, который был передан нашей обобщенной функции (и также пролит в стек). При наличии словаря в CX мы можем разыменовать его, и в точке со смещением offset 64 найдем искомый *itab. Как ни грустно, теперь нам нужен еще один акт разыменования (24(CX)), чтобы загрузить указатель функции, вынутый из itab. В остальном вызов метода идентичен тому, что получился у нас при прошлой генерации кода.
Насколько плоха такая дополнительная операция разыменования на практике? Интуитивно можем предположить, что вызов методов в объекте в составе обобщенной функции всегда будет медленнее, чем в необобщенной, которая просто принимает интерфейс в качестве аргумента. Дело в том, что при работе с дженериками то, что раньше представляло собой вызовы указателей, деградирует в дважды опосредованные вызовы интерфейса, на вид более медленные, чем обычный вызов интерфейса.

Этот простой бенчмарк тестирует тело одной и той же функции с 3 слегка разными реализациями. GenericWithPointer передает *strings.Builder нашей обобщенной функции func Escape[W io.ByteWriter](W, []byte). Бенчмарк Iface сделан для функции func Escape(io.ByteWriter, []byte), которая принимает интерфейс напрямую. Monomorphized – для вручную мономорфизированной func Escape(*strings.Builder, []byte).
Результаты неудивительны. Функция, специализированная для того, чтобы принимать *strings.Builder напрямую, самая быстрая, так как она разрешает компилятору встраивать внутри нее вызовы WriteByte. Обобщенная функция измеримо медленнее, чем простейшая возможная реализация, принимающая интерфейс io.ByteWriter в качестве аргумента. Мы видим, что влияние дополнительной нагрузки от обобщенного словаря несущественно, поскольку как itab, так и словарь дженериков можно будет взять тепленькими из кэша этого микробенчмарка (правда, дальше рассказано, как война за кэши влияет на код дженериков – так что обязательно читайте дальше).
Вот и первый вывод, который мы можем почерпнуть из этого анализа: в 1.18 нет никакого стимула преобразовывать чистую функцию, принимающую интерфейс, так, чтобы она работала с дженериками. Это только замедлит код, поскольку в настоящее время компилятор Go не может сгенерировать такую форму функции, в которой методы вызываются через указатель. Вместо этого вводится вызов интерфейса с двумя уровнями косвенности. Это уводит нас в прямо противоположную сторону от того, чего бы нам хотелось – а нам бы хотелось девиртуализации и, где это возможно, встраивания.
Прежде, чем завершить этот раздел, заострим внимание на одной детали в том, как компилятор Go выполняет анализ выхода [escape analysis]: как видим, в нашем бенчмарке у функции 2 allocs/op. Дело в том, что мы передаем указатель на strings.Builder, находящийся в стеке, и компилятор может доказать, что он помещается и, следовательно, его не требуется выделять в куче. Бенчмарк Iface показывает 3 allocs/op, пусть даже мы также передаем указатель из стека. Дело в том, что мы перемещаем указатель на интерфейс, а тут всегда происходит выделение. Удивительно, что реализация GenericWithPointer также показывает 3 allocs/op. Пусть даже функция, инстанцированная в таком виде, принимает указатель напрямую, анализ выхода больше не может доказать, что она не выходит за пределы, поэтому получаем дополнительное выделение в куче. Ну да. Небольшая печалька. Теперь же время переходить к другим печалькам, побольше, покруче.
Обобщенные вызовы интерфейсов
В неcкольких предыдущих разделах мы анализировали, как генерируется код для нашей обобщенной функции Escape и рассматривали, какая форма у нее получается при вызове функции с *strings.Builder. Вы, вероятно, припоминаете, что обобщенная сигнатура нашего метода имела вид func Escape[W io.ByteWriter](W, []byte), и *strings.Builder определенно удовлетворяет этому ограничению, что и дает нам ту форму, в которой инстанцируется *uint8.
Но что бы произошло, если бы мы здесь попытались спрятать наш *strings.Builder за интерфейсом?
var buf strings.Builder var i io.ByteWriter = &buf BufEncodeStringSQL(i, []byte(nil))
Теперь аргументом нашей обобщенной функции является интерфейс, а не указатель. Вызов явно корректен, так как тот интерфейс, что мы передаем, идентичен ограничению, налагаемому на наш метод. Но какую форму будет иметь тот экземпляр, который мы при этом сгенерируем? Мы не встраиваем всю «разобранную сборку», потому что она станет сильно мельтешить, но, точно как и делали ранее, давайте проанализируем точки вызовов для методов WriteByte в этой функции:
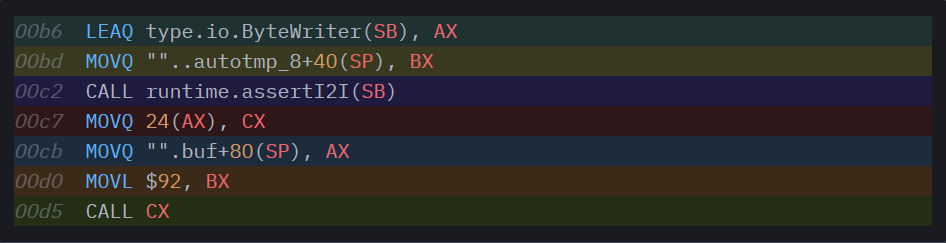
Упс! По сравнению с предыдущим вариантом генерации кода этот вариант выглядит значительно менее привычно. Мы согласились (и измерили), что дополнительное разыменование на каждой точке вызова – это нехорошо, поэтому представьте, каково нам будет от дополнительного вызова целой функции.
Что здесь происходит? В среде времени выполнения Go можно найти метод runtime.assertI2I: он вспомогательный и постулирует преобразование от интерфейса к интерфейсу. В качестве двух аргументов он принимает *interfacetype и *itab и возвращает itab для заданного interfacetype только, если интерфейс в заданном itab также реализует наш целевой интерфейс. Ох, что?
Допустим, у вас есть вот такой интерфейс:
type IBuffer interface { Write([]byte) (int, error) WriteByte(c byte) error Len() int Cap() int }
Этот интерфейс ничего не упоминает о io.ByteWriter или io.Writer, но, все же, любой тип, реализующий IBuffer, также неявно реализует и эти два интерфейса. Это заметно влияет на генерацию кода для нашей обобщенной функции: поскольку обобщенное ограничение для нашей функции это [W io.ByteWriter], можно передать в качестве аргумента любой интерфейс, реализующий io.ByteWriter – включая нечто вроде IBuffer. Но, когда нам нужно вызвать метод WriteByte в нашем аргументе, где же в массиве itab.fun для полученного нами интерфейса, находится этот метод? Мы не знаем! Если передать наш *strings.Builder как интерфейс io.ByteWriter, то itab в этом интерфейсе будет держать наш метод в fun[0]. Если мы передадим его как IBuffer, он будет в fun[1]. Нам тут понадобится помощник, который сможет взять itab для IBuffer и вернуть itab для io.ByteWriter, где указатель функции WriteByte всегда стабилен в fun[0].
Это задача assertI2I, и именно этим занимается код в каждой точке вызова в функции. Давайте разберем его пошагово.
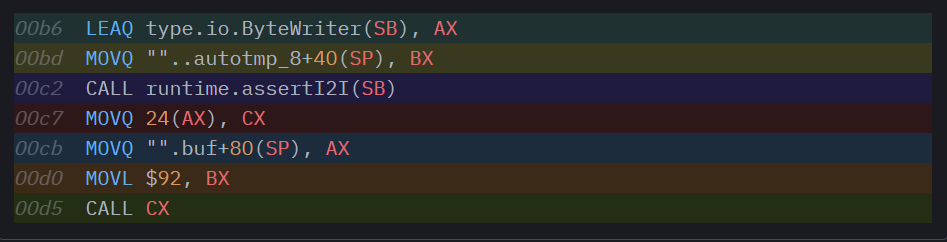
Сначала он загружает interfacetype для io.ByteWriter (это жестко закодированное глобальное значение, поскольку это тип интерфейса, определенный в нашем ограничении) в AX. Затем он загружает в BX фактический itab для того интерфейса, который мы передали нашей функции. Есть два аргумента, которые нужны assertI2I, и, вызвав его, мы остаемся с itab для io.ByteWriter в AX, а далее можем продолжать работу с вызовом функции интерфейса, как и при предыдущей генерации кода, зная, что наш указатель функции всегда находится со смещением 24 внутри нашего itab. В сущности, при данном инстанцировании формы происходит буквально следующее: каждый вызов метода преобразуется из buf.WriteByte(ch) в buf.(io.ByteWriter).WriteByte(ch).
Кстати, да, выглядит адски расточительно. При этом выглядит весьма избыточно. Было бы возможно приобрести io.ByteWriter itab всего один раз, в начале функции, а затем переиспользовать его при всех вызовах функций? Эхх, вообще – нет, но бывают у функций такие формы, при которых поступать так безопасно (как, например, в случае с той функцией, которую мы сейчас анализируем), поскольку значение в интерфейсе buf никогда не меняется, и нам не потребуется переключаться между типами или передавать интерфейс buf вниз каким-либо другим функциям, работающим в стеке. Определенно, здесь есть некоторый простор для оптимизаций, которые мог бы внести компилятор Go. Обратим внимание на цифры бенчмарков, чтобы оценить, какова будет степень влияния такой оптимизации:

Это не радует. С использованием assertI2I связаны заметные издержки, даже если функция просто вызывает другие функции и больше ничего не делает. Мы идем почти вдвое медленнее, чем при использовании вручную мономорфизированной функции, которая вызывает WriteByte напрямую и на 30% медленнее, чем если просто использовать интерфейс io.ByteWriter без дженериков. По любым меркам, это выстрел в ногу нашей производительности, и это нужно осознавать: одна и та же обобщенная функция, со все тем же аргументом, будет работать значительно медленнее, если вы передадите аргумент внутри интерфейса, а не напрямую как указатель.
…Но подождите! Это еще не все! Если вы обратили внимание, как тщательно мы именуем наши контрольные кейсы, то понимаете, что тут можно поделиться еще множеством увлекательных подробностей, касающихся производительности. Оказывается, что наш бенчмарк GenericWithExactIface на самом деле описывает наилучший возможный сценарий, поскольку в нашей функции прописано ограничение [W io.ByteWriter], и мы передаем наш аргумент как интерфейс io.ByteWriter. Это означает, что вызов к runtime.assertI2I может вернуться немедленно, с тем itab, который мы ему передали – поскольку он совпадает с тем itab, который подыскивается для инстанцированной нами формы. Но что делать, если мы передали наш аргумент как ранее определенный интерфейс IBuffer? Это бы сработало вполне нормально, потому что *strings.Builder реализует одновременно IBuffer и io.ByteWriter, но во время выполнения все до одного вызовы методов внутри нашей функции будут приводить к глобальному поиску в таблице хешей, когда assertI2I попытается приобрести io.ByteWriter itab из нашего аргумента IBuffer.

Хаха, шикарно. Это потрясающее открытие. Что касается производительности, раньше мы стреляли в ногу, а теперь мы ногу испепеляем, и все зависит от того, точно ли соответствует интерфейс (который вы передаете обобщенной функции) заданному ограничению, либо соответствует надмножеству ограничений. Теперь, возможно, самая соль этого анализа: передавать обобщенные интерфейсы к обобщенной функции в Go – однозначно нехорошая идея. В наиболее благоприятной ситуации, если ваш интерфейс в точности удовлетворяет ограничению, вам предстоит увидеть серьезные издержки на каждом вызове метода в ваших типах. В вероятном случае, где ваш интерфейс соответствует надмножеству ограничений, все до одного вызовы методов придется динамически разрешать через хеш-таблицу, а еще для этой функциональности ни в каком виде не реализовано кэширование.
Перед завершением этого раздела необходимо принять во внимание одну крайне важную деталь, которая будет играть роль, если придется взвешивать, приемлемы ли издержки, связанные с дженериками в Go, для вашего практического случая: числа, показанные в этих бенчмарках – это максимально оптимистичные значения, что, в частности, касается интерфейсных вызовов, и они не дают представления о тех издержках, которые возникнут при вызове функции в реалистичном приложении. Эти микробенчмарки прогонялись «в вакууме» где itab и словари для обобщенной функции всегда лежат тепленькие в кэше, а глобальная itabTable, нужная для работы assertI2I, пустая и неоспариваемая. В конкретном сервисе, используемом в продакшене, будет война кэшей, а глобальная itabTable может содержать от сотен до миллионов записей, в зависимости от того, насколько давно выполняется ваш сервис, и от количества уникальных пар тип/интерфейс в вашем скомпилированном коде. Это значит, что издержки на вызов обобщенного метода в ваших программах на Go будут усугубляться по мере усложнения вашей базы кода. Ничего нового, поскольку такая деградация на самом деле затрагивает все проверки интерфейсов в программе на Go, но такие проверки интерфейсов обычно не идут такой плотной чередой, какой могут идти вызовы функций.
Есть ли какой-то способ промерять такую деградацию в искусственно синтезированной среде? Есть, но не слишком академический. Можно засорить глобальную itabTable записями и непрерывно вытрясать кэш L2 CPU из отдельной горутины. Такой подход позволяет произвольно повысить издержки на вызов метода в любом обобщенном коде, где расставлены контрольные точки, но на самом деле очень сложно создать рисунок такой войны кэшей в itabTable, которая в точности соответствует тому, что мы видим в живом продакшен-сервисе. Поэтому измеренные издержки сложно экстраполировать на более реалистичные окружения.
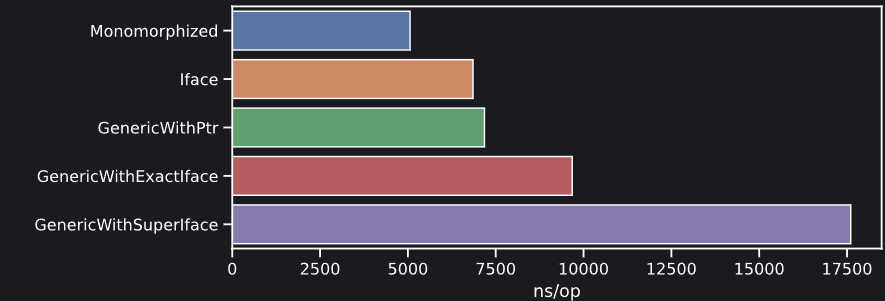
Тем не менее, поведение, наблюдаемое в этих контрольных точках, все равно весьма интересны. Таков результат измерения микро-бенчмарков при измерении издержек, связанных с вызовом методов (в наносекундах на вызов) для разных возможных вариантов генерации кода в Go 1.18. Метод тестируется как невстроенное пустое тело, поэтому так можно строго измерить издержки на вызов. Эта контрольная точка прогоняется три раза: в вакууме, постоянное опорожнение кэша L2, а также с опорожнением и сильно увеличенной глобальной itabTable, которая содержит коллизии для искомого itab.
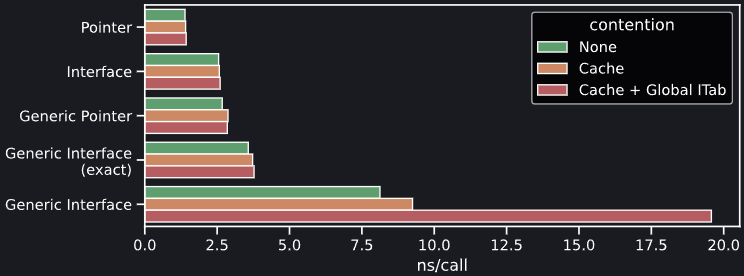
Как видим, издержки на вызов метода «в вакууме» масштабируются аналогично тому, как мы видели в наших контрольных точках при анализе выхода. Интересные вещи происходят, когда привносится конкуренция за ресурсы: как и ожидается, производительность при вызовах необобщенного метода не затрагивается при войне за кэш L2, но при этом виден небольшой рост издержек для всего обобщенного кода (даже такого кода, который не обращается к глобальной itabTable – вероятнее всего, потому, что во время выполнения задействуются более крупные словари, и обращаться к ним приходится при вызовах всех обобщенных методов). По-настоящему катастрофическая комбинация возникает, когда мы увеличиваем размер itabTable попутно с опорожнением кэша L2: так привносится огромный набор издержек, сопутствующих каждому вызову метода, поскольку глобальная itabTable слишком велика и поэтому не умещается в кэше, а релевантные записи уже не «тепленькие». Опять же, точный объем издержек невозможно осмысленно определить по такому микро-бенчмаркингу. Все зависит от сложности вашего приложения на Go и той нагрузке, которую оно испытывает в продакшене. Важный вывод из этого эксперимента заключается в том, что в обобщенном коде Go существует такое «жуткое дальнодействие», поэтому тщательно учитывайте его и измеряйте в контексте вашего варианта использования.
Байтовые последовательности
В базах кода на Go очень распространен и то и дело всплывает паттерн, который можно заметить в стандартной библиотеке, где у функции, принимающей в качестве аргумента срез []byte, также будет идентичный эквивалент, принимающий в качестве аргумента не []byte, а string.
Такой паттерн встречается повсюду (сравните, к примеру, (*Buffer).Write и (*Buffer).WriteString), но пакет encoding/utf8 – в самом деле, показательный пример, демонстрирующий, где такой подход начинает превращаться в проблему: примерно на 50% поверхность этого API покрыта продублированными методами, которые были мономорфизированы вручную, чтобы поддерживать и []byte, и string.
Байты | Строки |
DecodeLastRune | DecodeLastRuneInString |
DecodeRune | DecodeRuneInString |
FullRune | FullRuneInString |
RuneCount | RuneCountInString |
Valid | ValidString |
Стоит отметить, что такое дублирование, в сущности, является оптимизацией производительности: API может очень хорошо предоставлять только функции []byte для операций над данными UTF8, принуждая пользователей преобразовывать ввод типа string в []byte перед тем, как направлять вызов в пакет. Это не будет особенно неэргономично, зато обойдется очень дорого. Поскольку байтовые срезы в Go изменяемые, а строки string — нет, преобразование между ними в любом направлении всегда* приводит к выделению памяти.
* На самом деле – не совсем. В компиляторе Go предусмотрено несколько преобразований, позволяющих предотвратить выделение при переходе от
[]byteкstring. В данном случае наиболее примечательно, что, имеяvar b []byte, можно перебрать элементы кодового пространства UTF8 вbсfor i, cp := range string(b), и такое преобразование не приведет к принудительному выделению памяти. Аналогично, можно посмотреть значение в словаре, ключи в котором относятся к типуstringи используют байтовые срезы: приx = m[string(b)]память не выделится. В обратном случае,m[string(b)] = xпамять выделится, так как словарь должен принять владение над строкойkey.undefined
Столь существенный объем дублируемого кода так и хочется разгрести при помощи дженериков, но, поскольку код дублировался в первую очередь во избежание лишних выделений памяти, мы – прежде, чем подступиться к унификации реализаций – должны убедиться, что экземпляры в тех формах, в каких они у нас сгенерируются, поведут себя так, как мы от них ожидаем.
Давайте сравним две разные версии функции Valid: оригинальную, содержащуюся в encoding/utf8, она принимает []byte в качестве ввода, и новую, обобщенную, которая ограничена byteseq. Это очень простое ограничение string | []byte, которое должно нам позволить попеременно использовать аргументы обоих типов.

Перевод комментариев
1// Действительный отчет, независимо от того, состоит ли p целиком из действительных рун в кодировке UTF-8
3// Быстрый путь. Проверяем и пропускаем по 8 байт символов ASCII на итерацию.
5// При сочетании двух 32-разрядных нагрузок удается использовать тот же код
6// Для 32- и 64-разрядных платформ
7// Компилятор может сгенерировать 32-разрядную загрузку для первых 32 и вторых 32
8// на многих платформах. См. test/codegen/memcombine.go.
12// Найден байт, не являющийся ASCII (>=RuneSelf).
26// Недопустимый начальный байт
30// Короткое или недействительное
!["".ValidGeneric[go.shape.[]uint8_0]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/6bc/ed3/c67/6bced3c67cd03dfa200bff3f0598768f.png "\"\".ValidGeneric[go.shape.[]uint8_0]")
Перевод комментариев (идентично предыдущему листингу)
1// Действительный отчет, независимо от того, состоит ли p целиком из действительных рун в кодировке UTF-8
3// Быстрый путь. Проверяем и пропускаем по 8 байт символов ASCII на итерацию.
5// При сочетании двух 32-разрядных нагрузок удается использовать тот же код
6// Для 32- и 64-разрядных платформ
7// Компилятор может сгенерировать 32-разрядную загрузку для первых 32 и вторых 32
8// на многих платформах. См. test/codegen/memcombine.go.
12// Найден байт, не являющийся ASCII (>=RuneSelf).
26// Недопустимый начальный байт
30// Короткое или недействительное
Прежде, чем рассмотреть, какую форму приобретает наша новая обобщенная функция, следует остановиться на некоторых деталях оптимизации, важных при необобщенной генерации кода – чтобы убедиться, что они переживут процесс обобщенного инстанцирования. Мы заметим две симпатичные оптимизации и еще одну неказистую: во-первых, соглашение о вызовах Go на основе регистров, введенное в версии 1.16 здесь хорошо взаимодействует с нашим аргументом []byte. Нет, он не забрасывается в стек; напротив, 24 байта из заголовка среза, которые получает эта функция, передаются отдельно как 3 указателя в 3 регистрах: указатель *byte для среза находится в AX по всему телу функции, а его длина находится в BX, и они никогда не оттуда не вытекают. Видим, как относительно сложные выражения, например, len(p) >= 8, компилируются в CMPQ BX, $8 благодаря такому эффективному использованию регистров. Аналогично, загрузка бит 32/64 из p как следует оптимизируется в MOVL + ORL из AX.
Единственная загвоздка с этой скомпилированной функцией происходит в главном цикле for: загрузка pi := p[i] в строке 19 предусматривает проверку выхода за границы, которая могла бы считаться избыточной с учетом проверки i < n, которая производилась в заголовке цикла чуть выше. В сгенерированной сборке видно, что мы, в принципе, сцепляем друг за другом два перехода: JGE (это инструкция сравнения со знаком) и JAE (это беззнаковая инструкция сравнения). Эта гнусная проблема проистекает из того, что возвращаемое значение len в Go имеет знак – пожалуй, эта тема заслуживает отдельной статьи.
Как бы то ни было, необобщенная генерация кода для этой функции Valid в целом выглядит весьма хорошо. Давайте сравним ее с обобщенным вариантом инстанцирования! Здесь мы обратим внимание только на форму аргумента []byte; при вызове обобщенной функции с аргументом string сгенерируется иная форма, равно как у этих двух вариантов будет отличаться и расположение в памяти (16 байт для string, 24 для []byte), пусть даже на практике использование этой функции в двух разных формах будет идентичным, так как мы обращаемся к последовательности байт только для чтения.
…А в результате… Хорошо! Очень хорошо, на самом деле. Мы нашли такой практический случай, при котором дженерики могут помочь с дедупликацией кода, не приводя при этом к снижению производительности. Это круто! Двигаясь сверху вниз, мы видим, что все оптимизации действуют (и это также справедливо для формы string, здесь не показанной). Соглашение о вызовах на основе регистров сохраняется и после обобщенного инстанцирования, хотя, тут нужно отметить, что длина нашего аргумента []byte теперь находится в CX, а не в BX: все регистры сдвинулись на одну ячейку вправо, так как AX теперь занят словарем, используемым реализацией дженериков во время выполнения.
Тут все как по нотам: загрузка бит 32/64 по-прежнему происходит в двух инструкциях, две проверки выхода за границы, которые были исключены в необобщенной версии, исключены и здесь, нигде не было привнесено никаких дополнительных издержек.
Быстрый бенчмаркинг двух реализаций подтверждает наши показания:
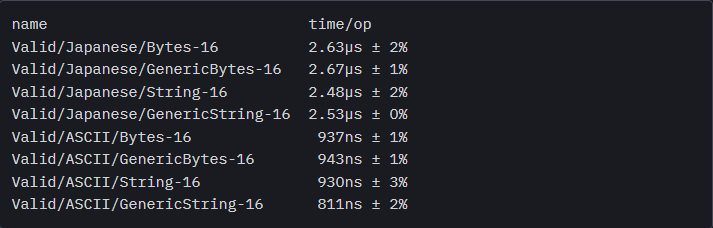

Разница в производительности между двумя реализациями – в пределах погрешности, так что это в самом деле максимально благоприятный сценарий: ограничение []byte | string применимо с дженериками в Go для сокращения дублирования кода в функциях, которые обрабатывают байтовые последовательности без внесения каких-либо дополнительных издержек. Здесь есть интересное исключение: обобщенная форма string заметно быстрее (~4%) необобщенной при прогоне ASCII-бенчмарка, притом, что с функциональной точки зрения сборки двух этих вариантов идентичны. Однако форма []byte обладает такой же производительностью как необобщенный код, по всем контрольным точкам, и сборки тут, опять же, идентичные. Это загадочный феномен, который надежно воспроизводится лишь в случае, когда мы расставляем контрольные точки для ввода ASCII.
Обратные вызовы функций
Со времен самого первого релиза язык Go очень хорошо поддерживал анонимные функции. Они входят в ядро языка, и выразительность их увеличивается, так как допускается множество паттернов, которые, однако, могут стать весьма многословными, если не менять синтаксис языка. Например, пользовательский код нельзя расширить так, чтобы в нем разрешался вызов оператора range применительно к пользовательской структуре или пользовательскому интерфейсу. Таким образом, чтобы обеспечить поддержку итерирования, наши структуры данных должны реализовывать собственные структуры-итераторы (неся при этом значительные издержки), либо иметь итерационный API, основанный на обратных вызовах функций, которые зачастую быстрее. Вот небольшой пример, в котором обратный вызов функции используется для перебора всех действительных рун (напр., точек кода Unicode) в байтовом срезе, использующем кодировку UTF-8:
func ForEachRune(p []byte, each func(rune)) { np := len(p) for i := 0; i < np; { c0 := p[i] if c0 < RuneSelf { each(rune(c0)) i++ continue } x := first[c0] if x == xx { i++ // недействительное continue } size := int(x & 7) if i+size > np { i++ // короткое или недействительное continue } accept := acceptRanges[x>>4] if c1 := p[i+1]; c1 < accept.lo || accept.hi < c1 { size = 1 } else if size == 2 { each(rune(c0&mask2)<<6 | rune(c1&maskx)) } else if c2 := p[i+2]; c2 < locb || hicb < c2 { size = 1 } else if size == 3 { each(rune(c0&mask3)<<12 | rune(c1&maskx)<<6 | rune(c2&maskx)) } else if c3 := p[i+3]; c3 < locb || hicb < c3 { size = 1 } else { each(rune(c0&mask4)<<18 | rune(c1&maskx)<<12 | rune(c2&maskx)<<6 | rune(c3&maskx)) } i += size } }
Даже не глядя в бенчмарки: насколько хорошо, на ваш взгляд, покатится эта функция по сравнению с более идиоматическим вариантом перебора, где использовалось бы for _, cp := range string(p)? Правильно, даже не угонится. А причина в том, что, если перебирать строку в range, тело этого перебора придется встраивать, поэтому в самом благоприятном сценарии (у нас чистая ASCII-строка) можно справиться без каких-либо вызовов функций. С другой стороны, наша собственная функция должна выдавать обратный вызов на каждую отдельную руну.
Если бы нам удалось каким-то образом встроить наш обратный вызов each для функции, то мы могли бы потягаться с циклом range при обработке строк ASCII, а на строках Unicode, вероятно, даже обогнать его! Увы, что же должен сделать компилятор Go, чтобы встроить наш обратный вызов? В общем случае данная проблема решается очень туго. Вдумайтесь. Передаваемый нами обратный вызов не выполняется в нашей локальной функции. Он выполняется внутри ForEachRune в рамках перебора. Чтобы можно было встроить обратный вызов внутри итератора, нам пришлось бы инстанцировать копию ForEachRune для нашего конкретного обратного вызова. Но компилятор Go этого не сделает. Ни один компилятор, будучи в своем уме, не станет генерировать более одного экземпляра чистой функции. Если только…
Если мы только не обманем компилятор, вынудив на это! Поскольку все это очень смахивает на мономорфизацию. Этот паттерн стар как мир (или, как минимум, как C++), и он сводится к параметризации функции по типу того обратного вызова, который она получает. Если вам когда-либо доводилось работать с базой кола на C++, то, вероятно, замечали: функции, принимающие обратные вызовы, часто бывают обобщенными, а тип обратного вызова является одним из параметров такой функции. Когда объемлющая функция мономорфизирована, конкретный обратный вызов для активации данной функции заменяется в регистре команд, и встраивание этого кода часто становится тривиальным – особенно, если речь идет о чистой функции (т.е., об обратном вызове, который не захватывает никаких аргументов). В силу этой надежной оптимизации комбинация лямбда-выражений и шаблонов стала краеугольной абстракцией в современном С++, причем, такой, которая ничего не стоит. Она значительно добавляет выразительности языку столь костыльному как Go, позволяя перебирать функциональные конструкции, не привнося ни нового синтаксиса, ни издержек времени выполнения.
Вопрос: как сделать в Go то же самое? Можно ли параметризовать функцию, исходя из ее обратного вызова? Оказывается, можно, но – интересно – это не объяснено ни в какой документации по дженерикам, которую мне удалось найти. Сигнатуру нашей функции-итератора можно переписать как показано ниже, и она действительно компилируется и бегает:
func ForEachRune[F func(rune)](p []byte, each F) { // ... }
Да, можно использовать сигнатуру func как ограничение дженерика. Ограничения не обязательно должны быть interface. Стоит держать это в уме.
Что касается результата этой попытки оптимизации, я не буду включать в статью результат дизассемблирования этого кода, но, если вы внимательно следили за сюжетом, то уже догадываетесь, что этот эксперимент не имеет смысла. Форма инстанцированной обобщенной функции не специфична для обратного вызова. Это обобщенная форма обратного вызова func(rune, не допускающая какого-либо встраивания. Вот вам еще один пример, в котором более напористая мономорфизация открывает очень интересные возможности для оптимизации.
Что ж, и это все? Ничего интересного с обратными вызовами функций не поделать? Не совсем. Оказывается, компилятор Go весьма поднаторел во встраивании со времен релиза 1.0. В наши дни он выделывает очень впечатляющие штуки – если дженерики не путаются у него под ногами.
Позвольте привести пример. Допустим, мы работаем над библиотекой, которая должна добавлять в Go функциональные конструкции. Зачем нам это может понадобиться? Не знаю. Кажется, этим многие занимаются. Может быть, это сейчас модно. Итак, давайте начнем с простого, функции ‘Map’, выполняющей обратный вызов к каждому из элементов в срезе и сохраняющей результат вызова на месте.

!["".MapAny[go.shape.int_0]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/3c8/747/129/3c874712993f460f76db2f89fb7c090b.png "\"\".MapAny[go.shape.int_0]")
!["".MapAny[go.shape.int_0,go.shape.func(int) int_1]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/312/246/f16/312246f1681d8941f78c50399ea8eecf.png "\"\".MapAny[go.shape.int_0,go.shape.func(int) int_1]")
Прежде, чем перейти к обобщенному словарю (а это интересный случай), рассмотрим MapInt, жестко закодированный в срезы int, чтобы посмотреть, что компилятор Go может сделать с этим кодом. Оказывается, может многое: код сборки для MapInt выглядит очень хорошо. Как видим, в главной IntMapTest из нашего примера нет никаких вызовов (CALL): мы сразу переходим к загрузке глобального среза input1, чтобы его перебрать, а операция отображения (в данном случае это простое умножение) выполняется во встроенном в строку виде, с единственной инструкцией. Функция оказалась полностью выровнена, и как MapInt, так и анонимный обратный вызов внутри IntMapTest исчезли из сгенерированного кода.
Должна ли была нас впечатлить эта генерация кода? В конце концов, случай очень тривиальный. Может быть, слово «впечатлить» - неверное, но, если вы внимательно следите за развитием производительности в Go на протяжении последнего десятилетия, то этот пример должен был показаться вам хотя бы весьма занимательным!
Как видите, простая функция MapInt из этого примера фактически оказалась стресс-тестом, испытывающим на прочность эвристику встраивания в компиляторе Go: это не листовая функция (поскольку внутри себя она вызывает другую функцию), и она содержит цикл for для работы с range. Две эти детали привели к тому, что оптимизировать эту функцию было невозможно ни в одном-единственном релизе Go до наших дней. Возможность встраивания посреди стека не была стабилизирована вплоть до Go 1.10, и встраивание функций, содержащих циклы for, было проблемой на протяжении более 6 лет. На самом деле, Go 1.18 — самый первый релиз, в котором можно встраивать цикл range, так что функция MapInt выглядела бы до неузнаваемости иначе, если бы мы скомпилировали ее всего пару месяцев назад.
Итак, достигнут весьма впечатляющий прогресс, если говорить о генерации кода в компиляторе Go, поэтому продолжим его праздновать, рассмотрев обобщенную реализацию все той же функции и… О. Нет, только не это. Она исчезла. Вот так раз. Благодаря встраиванию посреди стека, тело MapAny было встроено в ее родительскую функцию. Однако, сам обратный вызов, который теперь скрывается за обобщенной формой, был сгенерирован как самостоятельная функция и должен явно вызываться на каждой итерации цикла.
Но не будем отчаиваться: что, если попробовать прибегнуть к тому самому паттерну, который мы уже обсудили выше: параметризовать функцию по типу обратного вызова? Оказывается, помогает! Мы вернулись к полностью выровненной функции, и, заметьте – без всякой магии. В конце концов, встраивание – это эвристика, и в данном конкретном примере мы подтолкнули эвристику в верном направлении. Поскольку наша функция MapAny достаточно проста – настолько, что все ее тело можно встроить, все, что нам требовалось – это добиться большей специфичности формы для нашей обобщенной функции. Если обратный вызов к нашей функции есть не обратный вызов к обобщенной форме, а мономорфизированный экземпляр обратного вызова func(rune, это позволит компилятору Go разгладить весь вызов. Понимаете, к чему я клоню? В данном примере встраивание тела функции – это мономорфизация совершенно особого рода. Очень напористая, поскольку та форма, экземпляр которой здесь создается, представляет собой пример полной мономорфизации: ничем иным она быть не может, поскольку объемлющая ее функция не обобщенная! А когда вы полностью мономорфизируете код, компилятор Go оказывается способен на очень интересные оптимизации.
Резюмируя: если вы пишете функциональные помощники, использующие обратные вызовы, например, итераторы или монады, попробуйте параметризовать их по типам их обратных вызовов. Тогда и только тогда, когда помощник настолько прост, что его можно полностью встроить в строку, дополнительная параметризация подтолкнет встраиватель к полному выравниванию вызова, а именно этого вы и хотите от функционального помощника. Однако, если ваш помощник не настолько прост, чтобы можно было его полностью встроить, параметризация его будет бессмысленной. Инстанцированная обобщенная форма будет слишком грубой, чтобы производить над ней какую-либо оптимизацию.
Наконец, позвольте мне указать, что пусть даже этот пример с полной мономорфизацией не абсолютно надежен во всех случаях, он в самом деле дает очень обнадеживающий сигнал: как мы убедились, компилятор Go стал очень хорош во встраивании, поэтому, если приходится сталкиваться с очень специфическими случаями инстанцирования кода, этот компилятор способен генерировать очень хороший код сборки. В компиляторе Go уже реализовано целое море возможностей оптимизации, которые только ждут легкого толчка от реализации дженериков, чтобы проявиться во всей красе.
Выводы
Получилось очень интересно! Надеюсь, вы также получили массу удовольствия, разбираясь вместе со мной во всех этих сборках. Давайте же завершим этот пост кратким списком НАДО и НЕ НАДО, касающихся производительности и дженериков в Go 1.18:
НАДО пытаться делуплицировать идентичные методы, принимающие
stringи[]byte, это делается при помощи ограниченияByteSeq. Генерируемая при этом форма очень похожа на результат написания двух почти идентичных функций вручную.НАДО использовать дженерики в структурах данных. Это с отрывом наилучший вариант их применения: обобщенные структуры данных, которые ранее реализовывались при помощи
interface{}, сложны и неэргономичны. Удаляя утверждения типов и сохраняя типы неупакованными в типобезопасном виде, мы добиваемся, чтобы эти структуры данных становились как проще в использовании, так и производительнее.НАДО пытаться параметризовать функциональные помощники по типам их обратных вызовов. В некоторых случаях это может позволить компилятору Go выровнять их.
НЕ НАДО пытаться использовать дженерики для девиртуализации или встраивания вызовов методов. Это не сработает, поскольку все типы указателей, которые могут быть переданы обобщенной функции, по форме одинаковы; ассоциированная с ними информация о методах находится в словаре, действующем во время выполнения.
НЕ НАДО передавать интерфейс обобщенной функции, ни при каких обстоятельствах. Поскольку, учитывая, каким образом инстанцирование форм работает с интерфейсами, вы делаете не девиртуализацию, а добавляете лишний уровень виртуализации, для работы с которым приходится выполнять поиск в глобальной хеш-таблице на каждом вызове метода. При работе с дженериками в контексте, где важна производительность, используйте только указатели, но не интерфейсы.
НЕ НАДО переписывать API, основанные на интерфейсах, переориентируя их на работу с дженериками. Учитывая нынешние ограничения реализации, любой код, который в настоящее время использует непустые интерфейсы, будет действовать более предсказуемо и при этом проще, чем если продолжать пользоваться интерфейсами. Что до вызовов методов, дженерики приводят к вырождению указателей в дважды опосредованные интерфейсы, а интерфейсы… во что-то весьма ужасное, честно говоря.
НЕ НАДО отчаиваться и/или обливаться слезами, поскольку нет никаких технических ограничений в дизайне дженериков Go, которые не позволили бы (в конце концов) дать реализацию, которая бы более напористо применяла мономорфизацию для встраивания или девиртуализации вызовов методов.
Да, конечно. В принципе, эта статья могла немного огорчить тех, кто рассчитывал использовать дженерики в качестве мощного варианта для оптимизации кода Go, как это делается в других языках для системного программирования. Мы изучили (надеюсь!) много интересных деталей о том, как компилятор Go обращается с дженериками. К сожалению, мы также узнали, что реализация, которую выкатили в 1.18, чаще «да», чем «нет» делает код дженериков медленнее, чем любую альтернативу, заменяемую этим кодом. Но, как мы рассмотрели на нескольких примерах, так быть не должно. Независимо от того, считаем ли мы Go «системно-ориентированным» языком, создается ощущение, что словари времени выполнения – это неверно выбранная техническая реализация для компилируемого языка в принципе. Несмотря на малую сложность компилятора Go, ясно и измеримо, что генерируемый им код постоянно улучшается от релиза к релизу, начиная с версии 1.0, с очень немногими отступлениями, до наших дней.
Почитав раздел о рисках в оригинальном предложении по полной мономорфизации в Go 1.18, представляется, что решение реализовать дженерики с применением словарей было принято потому, что мономорфизировать код медленно. Но возникает вопрос: а это в самом деле так? Откуда кому-либо знать, что мономорфизировать код Go медленно? Это же никогда ранее не делалось! Фактически, у нас даже не было никакого обобщенного кода Go, который можно было бы мономорфизировать. Представляется, что сильным стимулом, повлиявшим на такой сложный технический выбор, были потенциально ошибочные предположения, которых мы все придерживаемся, как, например, «код C++ мономорфизируется медленно». Опять же, возникает вопрос: а это в самом деле так? Как велики издержки, которые мономорфизация привносит в компиляцию кода на C++, по сравнению с тем кошмаром, который случается при обработке include в С++, или сколько проходит оптимизаций, применяемых поверх мономоризированного кода? Будут ли актуальны ужасные характеристики производительности при инстанцировании шаблонов в C++ и в случае компилятора Go, при гораздо меньшем количестве операций оптимизации и с учетом чистой модульной системы, которая помогла бы предотвратить значительную часть избыточной генерации кода? А каково будет реальное влияние на производительность при компиляции по-настоящему больших проектов на Go, например, Kubernetes или Vitess? Ответ явно зависит от того, как часто и где именно используются дженерики в этих базах кода. К измерению всех этих вещей можно приступать уже сейчас, но раньше измерить их было невозможно. Аналогично, сейчас мы уже можем измерить, как сказывается на производительности одновременное применение контурирования и словарей в реальном боевом коде, как было сделано в этом анализе, и увидеть, что мы щедро расплатились производительностью наших программ за то, чтобы ускорить компилятор Go.
С учетом того, что нам теперь известно, а также ограничений, присущих такой реализации дженериков и мешающих внедрять ее в коде, по-настоящему требовательном к производительности, могу только надеяться, что выбор с использованием словарей во время выполнения ради сокращения времени компиляции будет пересмотрен, и что будущее Go за более напористой мономорфизацией, которую мы увидим в новых релизах. Ввод дженериков в Go был титанической задачей и, хотя в какой-то мере можно считать, что эта амбициозная фича была спроектирована успешно, та сложность, что привносится с нею в язык, оправдывает не менее амбициозную реализацию. Такую, которая была бы применима в максимально широких контекстах, без издержек времени выполнения – и это откроет путь не только к параметрическому полиморфизму, но и к более глубоким оптимизациям, от которых лишь выиграют многие реальные приложения на Go.

