
Здравствуй, Хабр!
Все имеющие процессор устройства, которые мы используем, построены по принципам фон Неймановской машины, или ее модификациях. Простой пример: всеми нами используемый x86 — это гибрид фон Неймановской и Гарвардской архитектур.
Но знает ли хабрасообщество про существование (хотя бы в концепции, планах, чертежах, работающих образцах) НЕ фон Неймановских машин?
Я хочу рассказать про одно концептуальное направление в процессоростроении, ныне заброшенное (хотя и тихо возрождающееся), но тем самым ничуть не умаляющее свою значимость и оригинальность — об управляемой данными процессорной архитектуре.
Эту концепцию в 70е годы разработали монстры из MIT, а потом подхватили другие процессоростроители по всему миру.
Итак, поехали!
Не по фон Нейману — а это как? о_0
Вкрадце (кто забыл), ключевые тезисы архитектуры фон Неймана:
- Команды выполняются по порядку
- Неотличимость команд от данных
- Адресуемость памяти
А что будет, если от этого всего отойти? А будет вот что:
- Команды выполняются по мере готовности операндов
- А оно вообще надо? Можно отказаться как от команд, так и от данных в привычном нам понимании.
- Указатели — страшный сон, который надо забыть… как и влияние фазы Луны.
Управляемый данными подход
Итак, мы отказались от модели фон Неймана. Но что мы предложим взамен?
Ответ прост — пакетирование. Да, да, почти как пакеты в сети, только в меньшем масштабе и намного быстрее.
В пакете находятся: код операции (>,<,+,-, и.т.д.), операнды (либо ссылки на другие пакеты, дающие эти операнды), и отметка готовности по каждому операнду. Нет разделения на данные и команды как таковые, процессор оперирует готовыми «суповыми» наборами всего необходимого.
Адресации памяти как таковой нет в принципе, т.к. все уже упорядочено и рассортировано. Известны только индексы пакетов, больше ничего и не требуется знать.
Операнды из одного пакета обрабатываются, результат отправляется в другие пакеты и активизирует их. То есть, фактически, программа собирает сама себя, в зависимости от начальных условий и ветвлений.
Развитие этой концепции — управляемый запросами процессор. Это — то же самое, но процесс идет не сверху-вниз, а снизу-вверх, т.е. операции выполняются только по требованию от предыдущих пакетов, что дает выигрыш в производительности за счет снижения числа операций.
(X+Y)*(X-Y):
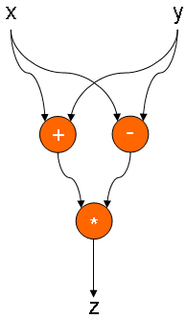
While X>0 DO X-1:

А решение квадратного уравнения будет выглядеть так:


Преимущества
- Высокая эффективность в вычислениях, требующих распараллеливания. Забудьте про потоки, задача раскидывается по всем возможным процессорам и ядрам автоматически, за счет дробления задачи на блоки.
- Равномерное распределение нагрузки между ядрами/процессорами вне зависимости от алгоритма.
- Никаких проблем с синхронизацией, т.к. нет потоков.
- Если некоторые данные не нужны для выполнения, они и не вычисляются — выигрыш в производительности.
Недостатки
- Принципиальная однозадачность. Симуляция многозадачности возможна, но только за счет тегирования пакетов в памяти.
- Следствием пункта 1 является исключительная редкость таких процессоров.
- Насколько я знаю, не было построено ни одного коммерчески выгодного образца.
- Более сложная реализация по сравнению с фон Неймановскими машинами.
Применение: обработка сигналов, роутинг сети, графические вычисления. В последнее время стало рассматриваеться применение в области баз данных.
Странно, но я не нашел ни одного реального примера применения таких процессоров даже после нескольких дней гугления.
Процессор, наиболее соответствующей этой концепции — японский Oki Denki DDDP.

