
Статью я захотел написать после работы над одним конкретным багом, который со всех точек зрения напоминал классическую утечку памяти, но на практике оказался чем-то совершенно другим. Я нигде не встречал описание такого поведения и поэтому решил этой информацией поделиться.
В один прекрасный день боевое сопровождение приходит с ужасной проблемой — память в контейнерах Node.js течет, сервисы падают с OOM каждый день, все пропало!
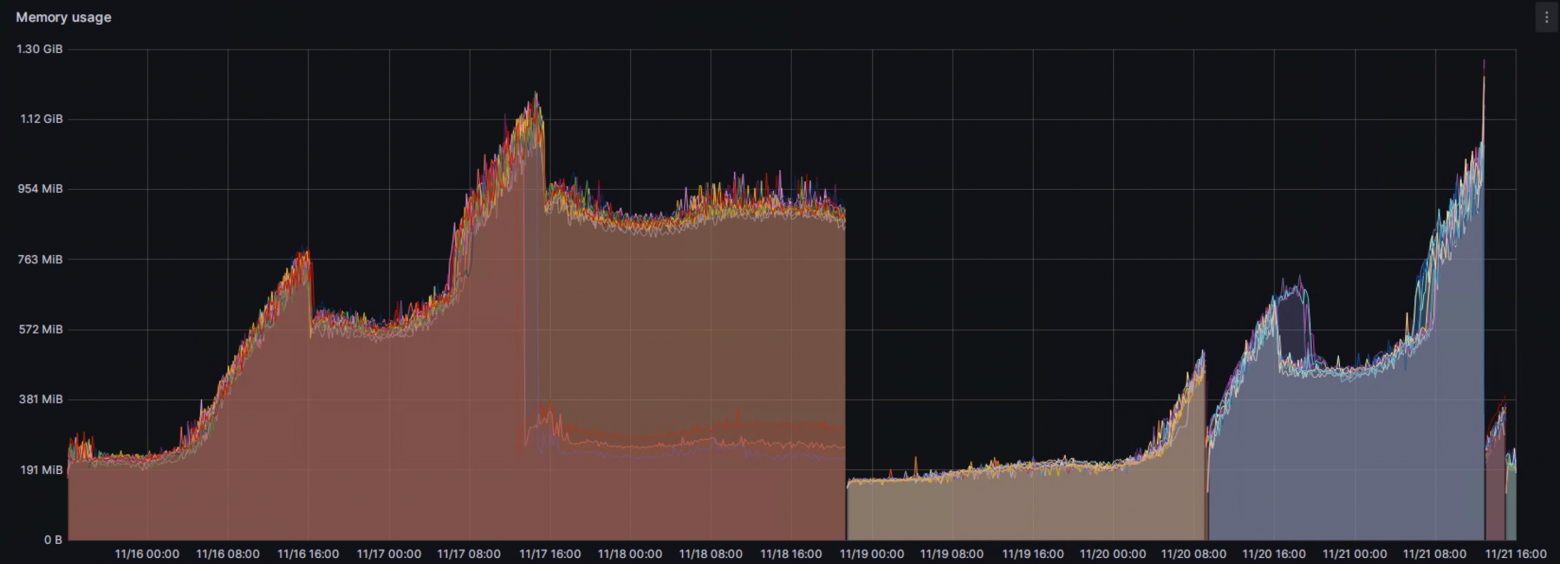
Да, картинка действительно удручающая. Всё время, когда есть нагрузка, память в контейнере прирастает и почти не очищается при снятии нагрузки. Все остальные метрики, которые мы собирали были в норме: event loop lag, использование CPU, active request, open handles. Прирастала только используемая память и незначительно увеличивалось время отклика сервиса.
Что-ж, выглядит как классическая утечка, надо искать источник.
Как вообще выглядят утечки?
Чтобы найти утечку имеет смысл вспомнить из-за чего они вообще возникают. Я не буду пытаться пересказывать многочисленные статьи, написанные на эту тему (раз, два, три).
Если кратко — основная причина почти всегда сводится либо к использованию глобальных переменных, либо к сохранению ссылок на ненужные данные, например через замыкания.
// классический пример постепенно утекающей памяти
import express from 'express';
const app = express();
const data = [];
app.get("/", (req, res) => {
data.push(req.headers);
res.status(200).send(JSON.stringify(data));
});
Единственное, что хочется добавить ко всем этим примерам — это поведение DevTools при использовании console.log у вас в коде. Вообще, это совсем не утечка, но довольно часто проявляющееся поведение при попытках её найти.
Если вы подключаетесь к своему процессу Node.js дебагером и при этом где-то используете console.log для вывода большого количества данных — не удивляйтесь тому, что потом найдёте все эти объекты в памяти. Чтобы в консоли большие объекты можно было раскрыть, посмотреть, скопировать, консоль сохранит ссылку на этот объект. И, естественно, это означает, что сборщик мусора не будет удалять залогированные объекты.
Инструменты для поиска
Просматривать весь код на наличие утечек не самое простое занятие. Конечно же есть вариант получше — тут нам помогут DevTools. Node.js позволяет снимать дампы памяти запущенного процесса, а с помощью Chrome DevTools (chrome://inspect) можно эти дампы изучать и сравнивать друг с другом.
Для снятия дампа либо запускаем процесс с флагом --inspect, либо переводим уже запущенный процесс в дебаг-режим послав ему SIGUSR1. Подробнее про это можно почитать в документации Node.js.
Когда процесс запущен в дебаг режиме, можно либо подключиться к нему из DevTools, либо воспользоваться cli-дебагером:
ps | grep node # получаем PID процесса ноды, что-то типа 14
kill -usr1 14 # включаем дебагер у ноды
node inspect -p 14 # Подключаемся к ноде встроенным дебагером
takeHeapSnapshot() # Запускаем создание снапшота хипа. Занимает какое то время.
Наибольшую пользу от снапшотов можно получить, если есть сразу несколько снапшотов одного процесса, снятых в разные моменты времени. Тогда вы сможете изучать использование памяти в динамике: смотреть, что именно поменялось, какие объекты появились в памяти и сколько их появилось.

В инспекторе можно подробно изучить каждый снапшот:
посмотреть сколько объектов и какого типа в нём есть;
понять, сколько памяти занимает сам объект (shallow size);
и сколько памяти освободится, если удалить все ссылки на объект (retained size).
Также можно смотреть на дерево объектов, «удерживающих» этот объект в памяти — Retainers показывает именно это.
Вооружившись всеми этими знаниями, посмотрим на снапшоты памяти нашего сервиса.
В наших дампах нет утечки!
Итак, что же в наших дампах? Где мы накосячили, что за объекты хранятся в памяти без необходимости?
Внимательно изучив дампы видим странное — большая часть памяти занята промисами, которые не удерживаются ничем.
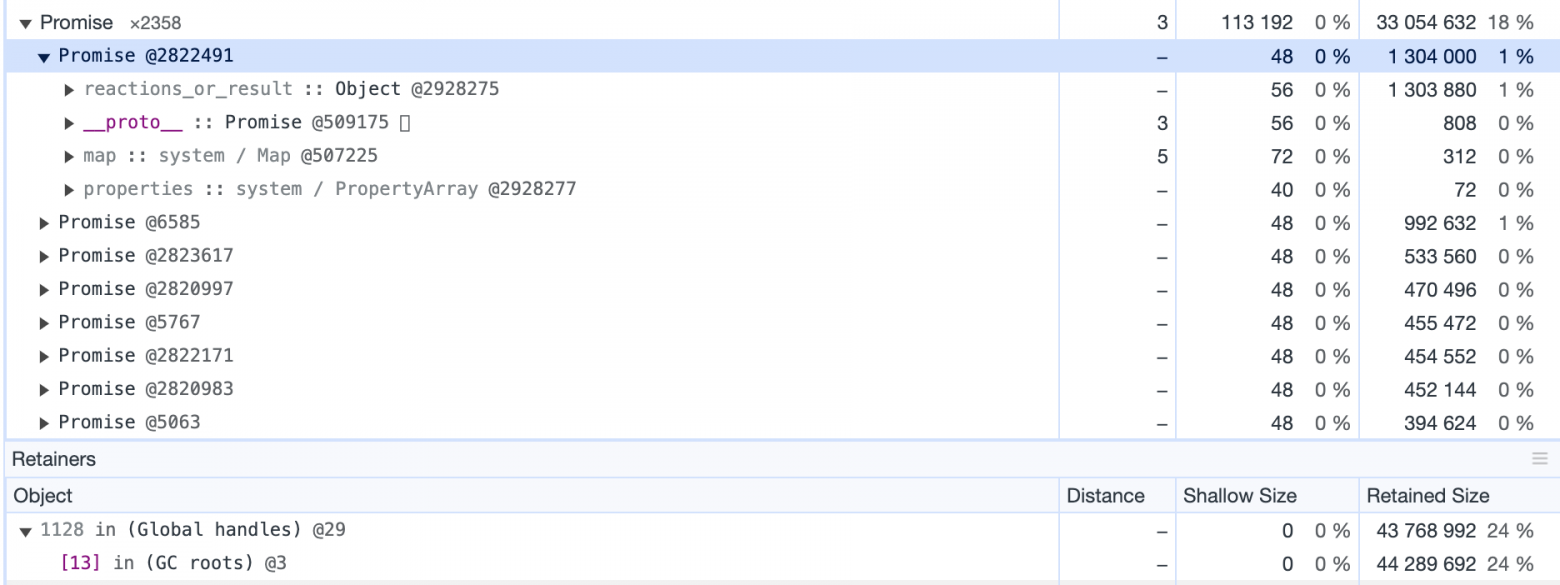
Все промисы находятся в resolved состо��нии и прикреплены только к GC roots — это означает, что GC должен был собрать их при следующем проходе.
И действительно, сравнивая два дампа с одного контейнера, видим что старые промисы удаляются, но новых становится всё больше.

Потратив на поиск проблем ещё немало часов и досконально изучив все дампы, мы находим ещё одну аномалию — множество мелких объектов, имеющих огромную глубину.
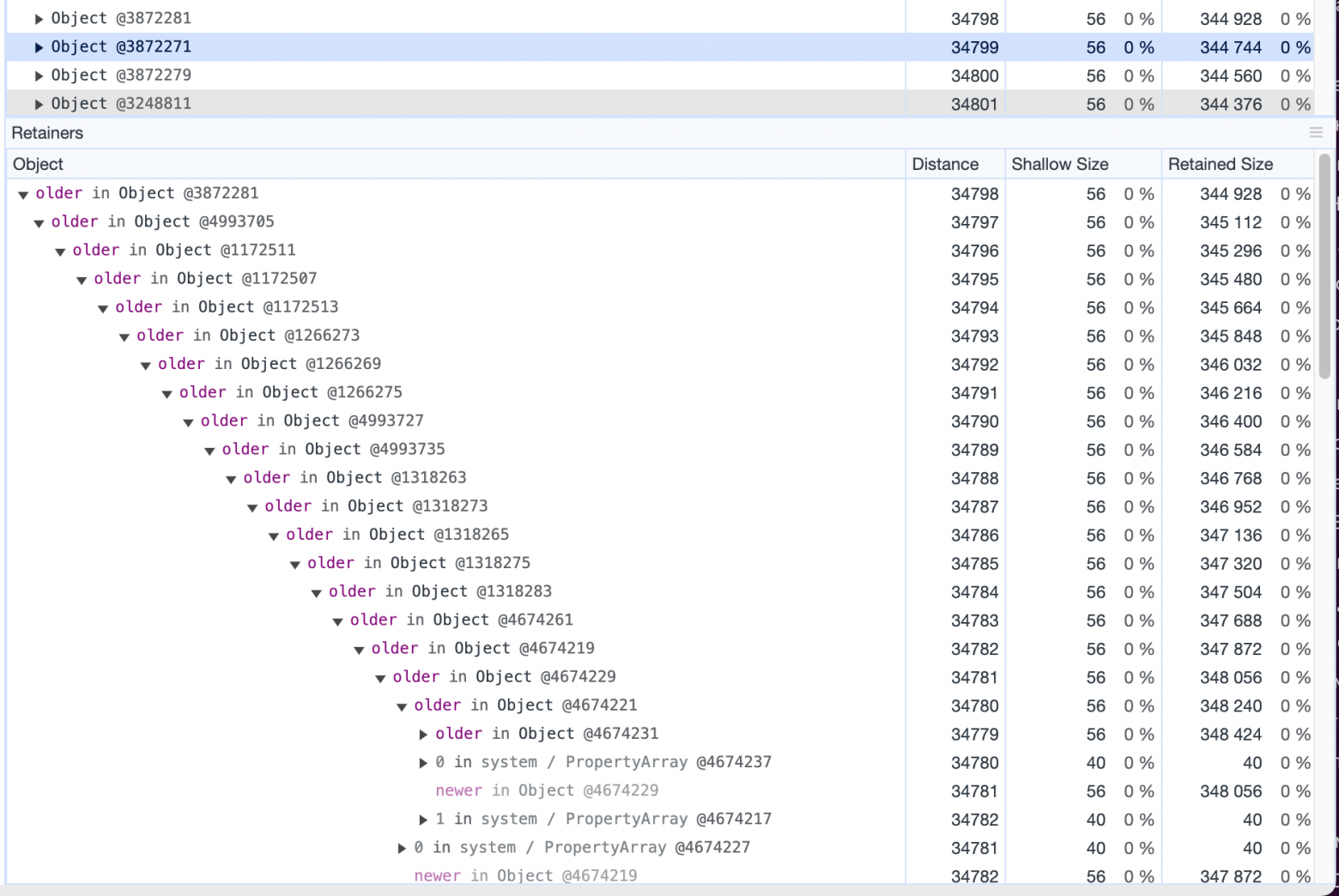
Сами эти объекты занимают в памяти совсем немного места — суммарно всего около 2 Мб.
Да, поведение странное, но вроде бы эти 2 Мб не должны сильно мешать нашему коду, ведь так?
Вспоминаем основы
Что же, кажется у нас есть недостаток знаний, и надо его восполнить. Как вообще JS работает с памятью? Вроде все помнят какой-то набор ключевых слов, типа garbage collector, какой-то там heap, в котором вроде есть что-то, что называется old_space… Но как это всё сложить в одну картинку?
Я буду писать об этом с точки зрения Node.js, но, естественно, все те же принципы применимы и для браузера — почти весь рынок движков захватил вездесущий V8, но и SpiderMonkey из Firefox и JavaScriptCore из Safari работают с памятью схожим образом.
Виды памяти
В целом, память в ноде делится на два основных раздела:
stack— то, где помещаются локальные переменные, ссылки на объекты, информация о control-flow.heap— то, куда кладутся все reference типы. Строки, объекты — все сюда.
Сам heap в свою очередь также делится на части:
new_space— та часть памяти, где происходит основная аллокация. Это небольшой кусок памяти — 8/16 Mb для 32 и 64-битных систем соответственно. В нем дёшево выделять память и дёшево ее очищать. Когда вы пишитеnew Map()мапа попадет именно вnew_space. note: в конфигурации Node.js этот раздел называется semi-space.old_space— та часть памяти, в которую попадают объекты, пережившие GC вnew_space. Это намного бОльший раздел. V8 из коробки пытается устанавливать размер этого раздела, в зависимости от доступной на машине памяти.
Вообще V8 внутри имеет ещё пачку разных кусков памяти, например, отдельная область памяти для очень больших объектов (large_object_space / new_large_object_space).
Но, по сути, они являются просто подмножеством двух основных категорий. Вы можете посмотреть, какие части памяти есть, запустив v8.getHeapSpaceStatistics(). Ну а почитать чуть подробнее можно, например, в статье Visualizing memory management in V8 Engine (JavaScript, NodeJS, Deno, WebAssembly).
Как работает GC
Как же JS рантайм работает с heap? Что именно делает garbage collector?
По сути, нам надо удалять из памяти объекты, на которые больше никто не ссылается. Если нигде в «живых» объектах нет ссылок на объект, то незачем его и хранить.
Чтобы определить отсутствие ссылок, все современные JS движки используют трассировку — определение достижимости объекта от некоторых предопределенных root объектов.
Имея некоторый объект, про который знаем, что он должен остаться в памяти, мы ходим по всем его детям (и их детям, и детям их детей и так далее), помечая каждый такой объект как достижимый. После этого можем ещё раз пройти по всем объектам и удалить все, которые не были помечены как достижимые.
V8 использует этот алгоритм для очистки как new_space, так и old_space.
Для new_space корневые объекты это стек, глобальные объекты (например, global в Node.js) и объекты из old_space, имеющие ссылки на new_space.
Для old_space же корневыми объектами являются только global-ы.
v8 регулярно запускает GC для new_space, переодически перемещая долго живущие объекты в old_space. Очистка же old_space происходит гораздо реже — эта процедура намного дороже, ведь пробежаться по 16 Мб памяти и по 2 Гб — сильно разные по сложности задачи.
Запуск GC в old_space может даже откладываться, если приложение работает под большой нагрузкой. Да, если память совсем заканчивается — GC запустится принудительно, но до этого момента приоритет уделяется скорости обработки кода приложения, память можно будет почистить, когда нагрузка спадет.
Глубокие объекты и их влияние на GC
Итак, разобравшись с тем, как именно работает GC у нас может появиться теория.
Поскольку для того, чтобы очистить память, GC должен пройтись по всему дереву объектов, то логично предположить что имея большое дерево мы замедлим работу сборщика мусора. Но как сильно? Давайте попробуем собрать небольшой тестовый стенд, на котором и проведем наши эксперименты.
Собираем метрики работы GC
Node.js предоставляет прекрасный встроенный пакет, который позволяет узнавать различную информацию о разных тонких параметрах работы приложения — perf_hooks.
Он, в том числе, позволяет получать информацию о времени работы сборщика мусора.
import { constants, PerformanceObserver } from 'node:perf_hooks';
export function startObserving() {
const kinds = [];
kinds[constants.NODE_PERFORMANCE_GC_MAJOR] = 'major';
kinds[constants.NODE_PERFORMANCE_GC_MINOR] = 'minor';
kinds[constants.NODE_PERFORMANCE_GC_INCREMENTAL] = 'incremental';
kinds[constants.NODE_PERFORMANCE_GC_WEAKCB] = 'weakcb';
const counters = {};
const obs = new PerformanceObserver(list => {
const entry = list.getEntries()[0];
const kind = kinds[entry.detail.kind];
if (!counters[kind]) {
counters[kind] = [];
}
counters[kind].push(entry.duration);
});
obs.observe({ entryTypes: ['gc'] });
return counters;
}
Ну а с помощью пакета V8 также можно получить дополнительную информацию о том, какая именно память используется на данный момент. Сделаем себе удобный метод для вывода всей статистики в консоль:
export function printStats(counters) {
stdout.write('\x1Bc'); // clear console
console.log(`Memory usage: ${formatBytes(process.memoryUsage().heapUsed)}`);
console.log("Heap statistics:");
v8.getHeapSpaceStatistics().forEach(space => {
console.log(` ${space.space_name}: ${formatBytes(space.space_used_size)} / ${formatBytes(space.space_size)}`);
});
console.log("GC statistics:");
Object.keys(counters).forEach(kind => {
const durations = counters[kind];
const sum = durations.reduce((acc, curr) => acc + curr, 0);
const avg = sum / durations.length;
console.log(`Average duration of ${kind} GCs: ${avg}ms, count: ${durations.length}`);
});
}
Симулируем большую вложенность
Проверим влияние на работу GC нескольких разных вариантов:
Создадим один объект с миллионом вложенных в него объектов.
Создадим массив с миллионом объектов внутри.
Создадим объект глубиной в 1 миллион — каждый следующий уровень это так же объект.
Создадим сто объектов глубиной в 10 тысяч.
По объёму используемой памяти эти варианты должны быть более-менее эквивалентны между собой.
export function createPlainObject(count) {
const obj = {};
for (let i = 0; i < count; i++) {
obj[i] = {
memory: randomString(),
next: {},
};
}
return obj;
}
export function createArray(count) {
const arr = [];
for (let i = 0; i < count; i++) {
arr.push({
memory: randomString(),
next: {},
});
}
return arr;
}
export function createNestedObject(count) {
const obj = {};
let current = obj;
for (let i = 0; i < count; i++) {
current.memory = randomString();
current.next = {};
current = current.next;
}
return obj;
}
export function createBunchOfNestedObjects(count, depth = 10000) {
const objectsCount = Math.floor(count / depth);
const obj = {};
for (let i = 0; i < objectsCount; i++) {
obj[i] = createNestedObject(depth);
}
return obj;
}
Эмулируем работу
Теперь мы просто создадим веб-сервер, который при запросах выделяет сколько-то памяти (в идеале — больше, чем помещается в new_space, чтобы old_space активнее использовался) и после завершения обработки запроса успешно освобождает её. Создадим в памяти объекты и запустим нагрузку.
import * as objectGenerator from './objects-generator.mjs';
import * as http from 'node:http';
// ...
server = http.createServer(/* код обработки запроса */);
server.listen(3000);
global.usedMemory = objectGenerator.createNestedObject(1_000_000);
Полностью код тестового стенда можно посмотреть на GitHub.
Результаты тестов
Итак, что же мы получили? Вот результаты замеров для разных типов объектов с разным количеством:
minor GC avg time, ms | minor GC count | major GC avg time, ms | major GC count | memory usage, MB | |
|---|---|---|---|---|---|
Без лишних объектов | 0.83 | 94 | 5.10 | 5 | 4.75 |
plain object 100k | 1.32 | 69 | 1.10 | 47 | 17.74 |
plain object 1kk | 2.83 | 50 | 1.00 | 40 | 136.46 |
array 100k | 1.44 | 56 | 1.19 | 56 | 17.78 |
array 1kk | 2.91 | 52 | 1.02 | 39 | 136.78 |
nested object 100k | 1.07 | 66 | 7.23 | 36 | 13.08 |
nested object 1kk | 2.42 | 48 | 51.29 | 53 | 88.79 |
bunch nested 100k | 1.83 | 23 | 5.82 | 83 | 14.07 |
bunch nested 1kk | 2.15 | 40 | 13.54 | 59 | 89.72 |
На работу GC в new_space тип объектов практически не оказывает влияния. Колебания скорее связаны со случайными всплесками в загрузке используемой в тестах машине.
А вот major GC сильно замедляется, как только мы добавляем вложенные объекты. Для наглядности я также запустил этот тест, постепенно увеличивая количество объектов и замеряя время работы GC:


Опять же, мы наглядно видим, что minor GC никак не затронут тем, что мы делаем в old_space.
GC в old_space линейно замедляется по мере добавления глубины объекта.
Является ли такое поведение неожиданностью, когда ты хорошо понимаешь как именно работает GC?
Конечно же нет! Вполне логично, что проход по дереву становится медленнее с ростом этого самого дерева. Но, тем не менее, интуитивного понимания что делать подобные объекты может быть опасно, как-то не возникает. Да, объект глубокий, да, он, в целом, нам не нужен.. Но мы же сами по нему не ходим!
А что в итоге с утечками на бою?
Как часто бывает, в случаях, когда на поиск проблемы уходит значительное время, исправление оказывается предельно простым.
Поняв, что проблемы были вызваны именно глубокими объектами, мы легко нашли их источник. Их создавала библиотека dnscashe, добавленная в проекты много лет назад. Из-за различных изменений в нашей инфраструктуре она стала вести себя иначе — встроенный в неё кеш начал переполняться и перестал корректно очищаться.
Сама библиотека давно находится в read-only режиме, поэтому поправить её оказалось невозможным. Временно проблему решили просто отключив кеширование — лучше иметь чуть более медленный сервис, чем периодически падающий. Ну а затем просто заменили библиотеку другой, реализующей схожую идею.
Ну и напоследок графики работы GC в боевой среде (числа — это сумма значений с нескольких контейнеров, реальные числа на один процесс примерно в 12 раз меньше):
До исправления.

После исправления.

Практические выводы
Что вообще всё это дает? Зачем все эти знания? Не создавать вложенные объекты с глубиной в десятки тысяч? Вообще, реальных вариантов использований для подобных структур не много, и, скорее всего, если вам реально нужно работать с такими структурами в вашем JS коде, замедление GC будет не первой вашей проблемой.
Тем не менее какие-то практические выводы из этого сделать получилось.
Понимание того, что стоит следить за работой GC и на что именно там смотреть Теперь на всех наших дашбордах добавился ещё один график, который может помочь найти проблемы раньше, чем они дойдут до пользователей. Собирать метрики по времени работы GC довольно просто как самостоятельно, так и с помощью готовых пакетов. Например, мы используем prom-client для сбора всех наших технических метрик. Ну а с помощью Grafana легко можно настроить алертинг при выбивающихся из норму показателей.
Знания тонкостей работы глубоких частей системы сильно ускоряют поиск проблем. Мысль сама по себе, вроде бы, очевидная, но довольно часто от (начинающих) разработчиков можно услышать размышления о том, что знания тонкостей работы V8 вещь абсолютно бесполезная, и практической пользы кроме ответов на заковыристые вопросы на собеседованиях, из них не получишь. Да, написать то код вы можете и без этих знаний, но вот поддерживать его после этого…
Здесь мог бы быть третий пункт для красивого вывода статьи, но я оставлю его вам. Если у вас появилась мысль относительно статьи — напишите в комментариях.
Источники
Статьи, которые могут быть интересны:
Подписывайтесь на блог и Телеграм-канал Alfa Digital — там мы постим новости, опросы, видео с митапов, краткие выжимки из статей, иногда шутим.
