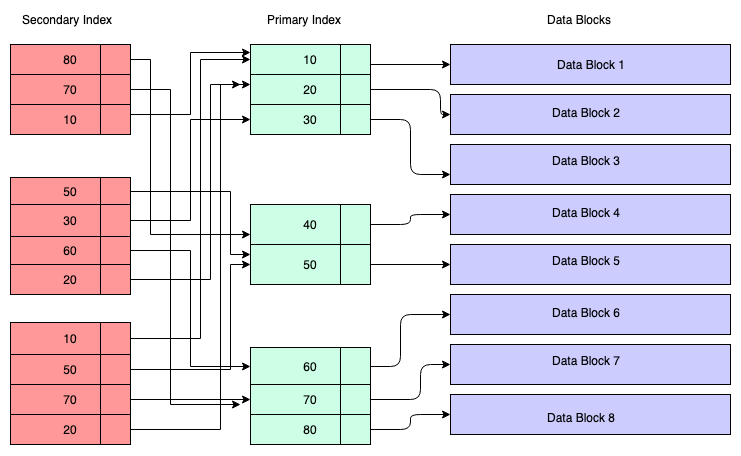
Введение
Индексы – это «ускорители» доступа к данным в базах данных. Правильно выбранные индексы могут многократно ускорить запросы, что особенно критично в highload-системах с большими объёмами данных и большим числом запросов. Однако за ускорение чтения приходится платить усложнением записи и дополнительным расходом памяти. В этой статье мы подробно рассмотрим, как работают разные типы индексов в реляционных СУБД, как выбирать индекс под конкретный запрос, обсудим подводные камни (например, блоат, переиндексация, избыточные индексы) и затронем индексацию в NoSQL (MongoDB, Cassandra). Завершим чеклистом, который поможет выбрать оптимальный индекс под вашу задачу.
Типы индексов в реляционных СУБД и их влияние на производительность

Реляционные СУБД (например, PostgreSQL, MySQL) поддерживают несколько типов индексов, каждый из которых оптимизирован под свои сценарии. По умолчанию обычно используется индекс типа B-Tree (сбалансированное B-дерево) – он покрывает большинство случаев. Но существуют и другие виды индексов:
B-дерево (B-Tree) – основный тип индекса. Элементы упорядочены по значению, что эффективно для операций равенства и диапазона ( = , >, <, BETWEEN и т.п.). Оптимизатор может использовать B-Tree даже для префиксного поиска по шаблону (LIKE 'prefix%'), так как данные отсортированы. B-Tree индексы подходят для высокоизбирательных колонок (с большим числом различных значений). По сложности доступ ~ O(log N), поэтому поиск одной записи или небольшого диапазона масштабируется логарифмически. Влияние на запросы:
Точечный поиск: Очень быстрый – находит нужное значение за несколько шагов.
Диапазонный запрос: B-Tree эффективно находит начало диапазона и затем последовательно считывает подходящие узлы.
Сортировка (ORDER BY): Если столбец отсортирован в индексе, можно вернуть данные по порядку без дополнительной сортировки.
JOIN: При соединении, если во второй таблице есть индекс B-Tree по ключу соединения, можно быстро находить соответствия, избегая полного сканирования.
Хеш-индекс – структура на основе хеш-таблицы. Поддерживает только операции равенства (=) – для диапазонов или сортировки не годится, так как данные неупорядочены. В PostgreSQL хеш-индексы официально WAL-логируются и поддерживаются начиная с версии 10, но применяются редко, так как B-Tree тоже справляется с равенством достаточно быстро. Хеш-индекс может быть чуть компактнее и быстрее для строго точных совпадений, однако его узкая специализация ограничивает применение. В MySQL нет пользовательских хеш-индексов для InnoDB (только внутренняя Adaptive Hash Index) – большинство индексов там тоже B-Tree.
Влияние на запросы:
Точечный поиск: Очень быстрый (в среднем O(1) доступ), но выгода над B-Tree заметна только на очень больших таблицах и специфичных сценариях.
Диапазон: невозможен (нельзя получить упорядоченное множество ключей из хеша).
JOIN: не применяется, т.к. нужен именно равный ключ – можно использовать, если точно сравниваем ключи, но чаще достаточно B-Tree.
GIN (Generalized Inverted Index) – обобщённый инвертированный индекс. Предназначен для случаев, когда одна запись содержит много значений, например, массив, JSON или документ в полнотекстовом поиске. GIN индексирует каждый элемент, позволяя эффективно искать вхождения. Пример – колонка типа text[]: GIN позволит быстро найти все строки, где массив содержит определённое значение. PostgreSQL также использует GIN для полнотекстового поиска (тип tsvector). Особенности: GIN-индексы обычно большие по размеру и относительно медленные при вставке, зато очень ускоряют сложные запросы по содержимому.
Влияние:
Поиск по содержимому: для операторов типа “contains” или полнотекстового поиска GIN незаменим – без него пришлось бы сканировать все данные.
Точечный поиск по одному полю: GIN не используется (вместо него B-Tree).
Диапазоны, сортировка, join: не применим.
GiST (Generalized Search Tree) – обобщённое дерево поиска. Гибкая структура для кастомных типов данных и условий. Например, используется для геометрических типов (поиск точек по области, индексы в PostGIS), для полнотекстового поиска по шаблону (через расширение pg_trgm), для диапазонных типов (tsrange и пр.) и реализации nearest-neighbor запросов. GiST индексы могут быть неточными (lossy) – иногда возвращают кандидатов, требующих дополнительной проверки.
Применение и влияние:
Гео и диапазонные запросы: Позволяют эффективно искать пересечения интервалов, попадание точки в регион, ближайшие соседние значения и т.п., что невозможно через B-Tree.
Стандартные запросы =, > <: можно, но B-Tree обычно эффективнее для простых типов.
Размер: GiST индексы могут быть компактнее GIN, но тоже занимают доп. место.
BRIN (Block Range Index) – упрощённый индекс по блокам, присутствует в PostgreSQL. Полезен на очень больших таблицах, где данные по колонке имеют локальную сортировку (например, append-only таблица по времени). BRIN хранит минимальные/максимальные значения по блокам страниц и очень лёгок по размеру. Это не точный индекс, а скорее ускоритель сканирования больших разреженных таблиц: хорошо отфильтровывает блоки, не содержащие подходящих значений. В highload-сценариях BRIN полезен для time-series данных, архивов.
Полнотекстовый индекс (Fulltext) в MySQL – особый вид индекса для полнотекстового поиска по большим текстовым полям. Реализован как инвертированный список слов (аналогично GIN). Доступен для движков MyISAM и InnoDB. Применение: позволяет выполнять операции MATCH() ... AGAINST() для поиска по ключевым словам. Ограничения: работает только с текстом, не подходит для обычных WHERE-условий, не упорядочен по значениям, поэтому не помогает с обычными сравнениями, диапазонами или сортировкой. Зато для поиска по словам гораздо быстрее последовательного обхода.
Прочие: MySQL поддерживает R-Tree индексы для геоданных (для колонок типа Geometry при использовании SPATIAL INDEX), PostgreSQL имеет специализированные индексы (например, SP-GiST, bloom-фильтры). Эти индексы применяются для узких случаев и в общем случае в highload-системах используются реже.
Вывод по типам индексов: В большинстве ситуаций B-Tree остаётся оптимальным выбором для реляционных баз – он универсален и ускоряет равенство, диапазоны, сортировку и соединения. Специализированные индексы (GIN/GiST/Fulltext) нужны для специфических запросов (полнотекстовый поиск, JSON/массивы, гео-запросы), а хеш-индексы – редкий случай для чистых точечных поисков. Понимание возможностей каждого типа позволяет подобрать лучший инструмент под задачу. Например, если нужно искать подстроку в середине текста (LIKE '%word%'), обычный индекс B-Tree не поможет – понадобится GIN/GiST с триграммами. А для поиска точного ключа на миллиардах записей, возможно, стоит рассмотреть хеш-индекс.
Подбор индекса под конкретные запросы
Проектируя индекс, исходим из запросов, которые этот индекс должен ускорять. Рассмотрим основные типы запросов (SELECT с различными конструкциями) и как выбирать индексы для них:
Индексы для фильтрации (WHERE)
Самый частый сценарий – ускорение фильтрации в WHERE-условиях SELECT. Правила выбора индекса:
Если условие по одному столбцу (например, WHERE status = 'ACTIVE'): индексируем этот столбец. Для равенства или небольшого набора значений подойдёт обычный B-Tree. Для предиката сравнения (>, <, BETWEEN) – тоже B-Tree, так как он поддерживает диапазоны. Если WHERE содержит функцию или выражение над столбцом, то обычный индекс на столбце не поможет – либо уберите функцию из условия, либо создайте индекс на выражение (функциональный индекс). Например, WHERE LOWER(name) = 'john' – обычный индекс по name не используется, нужно либо хранить отдельное поле name_lower с индексом, либо в PostgreSQL создать индекс USING btree(lower(name)) для поддержки такого запроса.
Комбинация нескольких условий (AND/OR): важно понять, будет ли СУБД использовать один индекс или несколько. В MySQL и PostgreSQL оптимизатор, как правило, может использовать только один индекс на таблицу в рамках одного сканирования. Исключение – Bitmap Index Scan в PostgreSQL или Index Merge в MySQL, которые объединяют несколько индексов, но такой план обычно менее эффективен, чем один подходящий составной индекс. Поэтому если запрос имеет, к примеру, WHERE col1 = ? AND col2 = ?, лучше создать составной индекс по (col1, col2). Такой индекс покроет сразу оба условия. В MongoDB аналогично: при двух отдельных индексах по col1 и col2 используется лишь один, а второй фильтр применяется после чтения документов. Составной же индекс по двум полям позволит сразу найти записи, удовлетворяющие обоим условиям, без лишних проверок.
Порядок столбцов в составном индексе имеет значение. Классическое правило – более селективные (кардинальные) или используемые в равенствах условия ставятся первыми. Часто упоминают правило ESR (Equality, Sort, Range): сперва поля, участвующие в равенствах, затем поля для сортировки, потом диапазоны. Например, запрос WHERE category = ? AND date >= ? ORDER BY date – разумно индексировать (category, date) именно в таком порядке: category (равенство) впереди, date после (для диапазона и сортировки). Это позволит использовать индекс и для фильтрации по категории, и для извлечения по дате в отсортированном виде.
Избыточные условия: если есть составной индекс (col1, col2, col3), он покроет запросы по (col1) и (col1, col2) – достаточно левой части. Например, индекс (country, city) может использоваться для фильтра WHERE country = 'US' и для WHERE country='US' AND city='NY', но не для запроса только по city без country (порядок имеет значение). Поэтому при проектировании учитывайте, по каким комбинациям колонок реально будут запросы. Иногда вместо одного широкого индекса имеет смысл сделать несколько более узких.
Пример: предположим, есть таблица users со столбцами (id, email, status, created_at). Какие индексы выбрать?
Запросы для поиска пользователя по email: SELECT * FROM users WHERE email = 'user@example.com'. Здесь эффективен уникальный индекс (или PK) на email – точечный поиск.
Запросы для выборки «активных» пользователей: WHERE status = 'ACTIVE'. Если активных мало (условие высокоизбирательно), индекс по status ускорит выборку. Но если половина пользователей активны, такой индекс мало поможет – он вернёт слишком много строк (проще последовательное сканирование). В этом случае лучше не создавать отдельный индекс, т.к. низкая селективность.
Запросы с диапазоном по дате: WHERE created_at BETWEEN '2023-01-01' AND '2023-01-31'. Индекс по created_at сильно ускорит такой запрос, особенно если за месяц лишь небольшая доля от общего числа пользователей. Также такой индекс может ускорить сортировку по дате.
Комбинированные запросы: WHERE status='ACTIVE' AND created_at > ... ORDER BY created_at DESC. Здесь можно завести составной индекс (status, created_at). Он позволит сначала отфильтровать по статусу, а внутри – по дате сразу в нужном порядке (например, по убыванию, если создать индекс DESC). База сможет сразу выбрать нужные данные из индекса, без сортировки, и прочитать только несколько верхних строк при наличии LIMIT.
Важно упомянуть покрывающие индексы: если запрос выбирает лишь столбцы, присутствующие в индексе, СУБД может выполнить его, не обращаясь к основной таблице. Например, если у нас есть индекс по (status, created_at) и запрос SELECT status, created_at FROM users WHERE status='ACTIVE', то PostgreSQL выполнит Index Only Scan – все данные есть в индексе. В MySQL подобный эффект называется covering index. Это снижает нагрузку на I/O. Поэтому при необходимости можно включить в индекс дополнительные колонки (в PostgreSQL – через INCLUDE, в MySQL – просто добавив в конец неключевые), чтобы сделать индекс покрывающим для часто исполняемого запроса.
Индексы для JOIN (соединений)
Для ускорения JOIN-ов следует индексировать колонки, по которым происходит соединение таблиц. Обычно это внешние ключи. Например, есть две таблицы: orders и customers, соединяем по orders.customer_id = customers.id. Рекомендация – создать индекс (или сделать первичным ключом) поле customers.id – тогда при соединении по каждому order СУБД быстро находит соответствующего customer по PK. Если customer_id в orders не является PK, имеет смысл создать индекс и на нём (особенно если часто нужно получить все заказы конкретного клиента).
Алгоритмы соединений:
Nested Loop Join: для каждой строки внешней таблицы ищется соответствие во внутренней. Индекс на внутренней таблице позволяет быстро находить нужные строки, иначе пришлось бы сканировать всю внутреннюю таблицу для каждой внешней записи. В нашем примере, обходя orders (внешняя), база по индексу на customers.id мгновенно находит нужную запись в customers вместо полного скана.
Merge Join: требует, чтобы обе входные последовательности были отсортированы по ключу соединения. Индексы могут обеспечить эту отсортированность без отдельной операции Sort. Например, если объединяем по date две большие таблицы, наличие индекса по date на обеих позволит использовать Merge Join эффективно.
Hash Join: не использует индексы (строит хеш-таблицу в памяти), поэтому для очень больших таблиц с ограниченной памятью лучше всё же иметь индексы и позволять оптимизатору выбирать другие методы.
Практический вывод: Всегда индексируйте столбцы, по которым делаются JOIN (особенно внешние ключи в дочерних таблицах). Без индексов соединения могут деградировать до полных переборов, что недопустимо в highload. Индекс на столбцах соединения – залог того, что даже при росте данных время соединения будет расти незначительно.
Индексы для сортировки (ORDER BY) и группировки (GROUP BY)
Сортировка (ORDER BY) может быть дорогой операцией на больших наборах. Индексы помогают избежать явной сортировки, если порядок выборки совпадает с порядком индекса:
СУБД может считывать данные в отсортированном виде по индексу. Например, запрос SELECT * FROM sales ORDER BY date при наличии индекса по date просто выполнит последовательный обход индекса – строки сразу получаются по возрастанию даты. Это экономит CPU и память на сортировку.
Если запрос сочетает сортировку с условием: WHERE user_id = 123 ORDER BY timestamp, то составной индекс (user_id, timestamp) выдаст данные в нужном порядке для конкретного пользователя. Иначе, даже если есть индекс по user_id, результаты придётся сортировать заново.
В MySQL важно помнить: индекс используется для сортировки только если порядок сортировки полностью совпадает с порядком в индексе, и не смешивается ASC/DESC (или используйте desc-индексы для всех).
Группировка (GROUP BY) схожа с сортировкой – часто СУБД сортирует по полям группировки или использует хеш. Индекс может помочь:
Если GROUP BY происходит по колонке с индексом, и особенно если SELECT выбирает агрегаты по этой колонке, оптимизатор может использовать индекс для более быстрого группирования. В MySQL, например, если группировка по префиксу индекса, можно обойтись без создания временной таблицы – чтение по индексу будет уже сгруппировано.
Тем не менее, выигрыш от индекса при GROUP BY менее прямой, чем при WHERE/ORDER. Группировка часто и так требует просмотр всех строк (или всех после фильтра), поэтому индекс полезен, если он значительно уменьшает количество обрабатываемых строк (например, индекс на столбце позволяет сразу пропускать диапазоны неинтересующих значений).
Пример: Пусть есть таблица payments(amount, type, created_at) и запрос: вывести топ-10 самых крупных платежей типа 'refund' за последний год. Этот запрос содержит и фильтрацию (WHERE type='refund' AND created_at > ...), и сортировку (ORDER BY amount DESC), и ограничение (LIMIT 10). Какой индекс поможет? Идеальное решение – составной индекс по (type, created_at, amount) в котором type и/или created_at отсортированы по возрастанию, а amount по убыванию (или все ASC, тогда читаем в обратном порядке). СУБД сможет мгновенно перейти к первым записям для type='refund' в заданном диапазоне времени, уже упорядоченным по amount, и взять 10 записей. Без индекса пришлось бы вычитать все подходящие платежи и сортировать их, что под нагрузкой крайне неэффективно.
Общее правило: анализируйте полный запрос – условия, соединения, сортировки, лимиты – и старайтесь спроектировать индекс, который максимально покрывает этот запрос, чтобы работа выполнялась на уровне индекса (в идеале – индексный скан вместо seq scan, и без дополнительных сортировок). При этом всегда учитывайте баланс: добавление каждого нового столбца в индекс увеличивает его размер и замедляет модификации.
Подводные камни индексации в высоконагруженных системах
Несмотря на огромную пользу индексов, неправильное их использование может привести к проблемам. Рассмотрим некоторые подводные камни:
Замедление записей (INSERT/UPDATE/DELETE). Главный компромисс индексации: ускоряя чтение, мы замедляем запись. При вставке или обновлении строки все затронутые индексы должны быть обновлены. В системе с интенсивной записью (например, логирование, трекинг событий) избыточные индексы могут стать узким местом. Каждая дополнительная запись в индекс – это дополнительные IO и CPU. Поэтому для write-heavy нагрузок индексировать только самое необходимое. Если запросы на чтение позволяют, лучше пожертвовать быстродействием некоторых селектов, но держать скорость вставки.
Избыточные индексы (overindexing). Иногда разработчики создают «на всякий случай» много индексов или дублирующие индексы. Например, отдельный индекс на col1 и составной на (col1, col2) – первый часто избыточен, так как те же запросы можно обслужить вторым. Лишние индексы съедают диск и память, замедляют все модификации, а пользы не приносят. Худший индекс – неиспользуемый индекс. Признак проблемы: индексы, у которых idx_scan = 0 или близко к тому в статистике PostgreSQL, либо которые никогда не задействованы в планах (можно отследить по EXPLAIN или по статистике). Такие индексы стоит удалять. В целом, ищите баланс: нет строгого правила, сколько индексов должно быть, но, как советуют эксперты, если индексы не окупаются ускорением чтения, а сильно тормозят запись – их слишком много.
Фрагментация и bloating индексов. В длительно работающих системах с активными обновлениями и удалениями со временем может накапливаться пустое пространство в индексах – так называемый блоат. В PostgreSQL из-за MVCC старые версии записей остаются «мёртвыми» в индексах до вакуума. B-Tree может терять плотность заполнения узлов. Индексный блоат – это неиспользуемые фрагменты, раздувающие размер индекса. Он приводит к лишнему расходу памяти, замедляет сканирование (нужно пройти через пустоты) и увеличивает IO. Причины: частые INSERT/DELETE, неэффективный паттерн обновлений. Решение – периодическая переиндексация (команда REINDEX в PostgreSQL) либо использование утилит типа pg_repack. В высоконагруженной системе важно мониторить блоат и устранять его, иначе производительность может постепенно деградировать.
Переиндексация и блокировки. Операция перестроения индекса может быть тяжелой и блокировать таблицу (в разных СУБД по-разному: в PostgreSQL REINDEX блокирует, а CREATE INDEX CONCURRENTLY не блокирует долгие чтения). В highload-практике важно планировать переиндексацию в окна низкой нагрузки или в режиме онлайн. Также в некоторых СУБД обновление статистики индексов (ANALYZE) может не успевать за изменениями, что приводит к неидеальному выбору плана.
Рост размера индексов. Индексы могут занимать больше места, чем данные таблицы, особенно составные и GIN-индексы. Это увеличивает требования к памяти (буферный кеш) – если индекс не умещается в памяти, его эффективность снижается. В распределённых системах большие индексы расходуют сетевой трафик при репликации. Следует контролировать размер индексов и избегать индексирования "всего подряд".
Локальные нюансы СУБД. Каждая СУБД имеет свои тонкости:
В MySQL InnoDB кластерный индекс по PK означает, что сама таблица хранится по порядку PK. Это нужно учитывать: PK индекс всегда существует и влияет на физический порядок. Соответственно, выбор PK = выбор основного порядка хранения. Остальные индексы в InnoDB хранят PK как указатель на запись, поэтому слишком длинный PK раздувает каждый вторичный индекс.
В PostgreSQL нет кластерных индексов (таблица хранится как Heap отдельно), но есть команда CLUSTER для упорядочивания данных согласно индексу – может ускорить range-сканы по этому индексу (правда, без поддержания порядка при последующих изменениях).
Вывод: Индексы – мощный инструмент, но требующий ухода. В highload-системах необходимо:
избегать ненужных индексов,
учитывать влияние на запись,
мониторить здоровье индексов (размер, блоат, использование),
выполнять профилактику (ваккуум, переиндексация) по мере необходимости.
Анализ необходимости индексации: инструменты и подходы
Как понять, какие индексы нужны, а какие – нет? В этом помогают специальные инструменты и методы профилирования запросов:
EXPLAIN / План запроса – базовый инструмент оптимизации. Выполняйте EXPLAIN [ANALYZE] для ваших SQL-запросов, чтобы увидеть, как они выполняются. План покажет, используются ли индексы или СУБД делает Seq Scan (полное сканирование таблицы). Если видите Seq Scan на большой таблице там, где ожидался индекс – это сигнал: либо индекс не создан, либо не подходит, либо оптимизатор считает, что с ним не быстрее. Анализируя план, вы можете скорректировать стратегию (создать недостающий индекс, переписать запрос, обновить статистику). Например, если EXPLAIN в PostgreSQL показывает Bitmap Heap Scan + Bitmap Index Scan – это значит, используется индекс, но выборка довольно большая (двухэтапный отбор через битовую карту). А Index Only Scan означает, что индекс полностью покрывает запрос (идеально).
Статистика использования индексов. PostgreSQL ведёт системную статистику в представлении pg_stat_user_indexes (и sysindexes для системных). Там есть поля idx_scan (сколько раз индекс использован в запросах), idx_tup_read и idx_tup_fetch (сколько строк прочитано из индекса и таблицы). Эти данные помогут найти неиспользуемые индексы – у них idx_scan близок к 0. Если индекс долго существует и idx_scan не растёт – вероятно, запросы им не пользуются. Также можно выявить индексы, которые используются, но неэффективно (прочитывают много tuple, но мало получают – признак низкой селективности). По этой статистике DBA принимает решение об удалении или создании индексов. В MySQL подобной встроенной статистики меньше, но есть косвенные признаки (Handler_read_next и др.), а также можно включать USER_STATISTICS при компиляции. Проще – опираться на планы EXPLAIN и логи.
Slow Query Log (лог медленных запросов). И PostgreSQL, и MySQL умеют логировать запросы, превышающие определённый порог времени. В MySQL есть Slow Query Log, куда пишутся запросы дольше long_query_time. В PostgreSQL – можно включить логирование запросов по времени (log_min_duration_statement). Анализируя эти логи, в высоконагруженной системе вы обнаружите самые «тяжёлые» запросы. Часто достаточно глянуть на Top-N медленных запросов и понять: ага, вот здесь у нас отсутствует индекс на условие, или делается тяжелый JOIN без индекса. Добавив нужный индекс и убедившись через EXPLAIN, что план изменился, вы существенно снизите нагрузку. Подход: найти медленный запрос -> проанализировать план -> добавить индекс -> проверить улучшение
Мониторинг производительности и профайлинг. На уровне СУБД есть расширения и утилиты (например, pg_stat_statements в PostgreSQL), которые собирают статистику частоты и стоимости запросов. Это помогает сконцентрироваться на наиболее частых и дорогостоящих запросах. Бывает, что редкий разовый запрос может быть очень медленным без индекса, но если он выполняется раз в месяц – не так критично. А вот запрос, идущий сотни раз в секунду, нужно оптимизировать даже если он сейчас работает приемлемо, чтобы был запас по нагрузке.
Автоматический советники. В некоторых СУБД и облачных платформах есть средства, подсказывающие, какие индексы добавить. Например, SQL Server имеет Database Tuning Advisor, PostgreSQL в планах (HypoPG) позволяет имитировать индексы, MySQL в Cloud может предлагать индексы. Но полагаться на них не стоит вслепую – всегда оценивайте воздействие на общую рабочую нагрузку.
Резюме: регулярно профилируйте систему. В highload среде картина запросов может меняться – добавляются новые фичи, меняется распределение данных. Индекс, нужный вчера, сегодня может быть неактуальным, и наоборот. Поэтому оптимизация – непрерывный процесс: меряем – оптимизируем – проверяем.
Индексация в NoSQL: MongoDB и Cassandra
Не только реляционные, но и NoSQL-базы используют индексы для ускорения поиска. Однако архитектура NoSQL (денормализация, шардинг) диктует свои подходы. Рассмотрим на примерах MongoDB и Apache Cassandra.
Индексы в MongoDB

MongoDB – документоориентированная БД, но по части индексов очень схожа с реляционными:
B-Tree индексы: используются под капотом для большинства типов индексов в MongoDB. Есть индекс по умолчанию на _id (Primary Key каждого документа). Дополнительно можно создавать обычные индексы на поля (включая вложенные, через точечную нотацию).
Single Field vs Compound: Если запросы фильтруют по нескольким полям, составной индекс эффективнее. Как и в SQL, при двух раздельных индексах MongoDB обычно выберет один и по второму просто отфильтрует результаты, или сделает пересечение индексов (что менее эффективно). Например, запрос find({city: "Boston", age: 25}) при индексах только по city и по age всё равно использует один из них, проверяя второй фильтр уже на извлечённых документах. Правильнее создать составной индекс {city: 1, age: 1}, который сразу найдёт документы, где обе conditions выполнены. Полезный приём – порядок полей в compound-индексе выбирать по частоте использования и типу запросов (аналог ESR-правила).
Multikey индексы: MongoDB автоматически создаёт мульти ключевой индекс, если индексируется поле-массив – каждый элемент массива индексируется отдельно. Это похоже на GIN в Postgres. Ограничение – в одном compound-индексе только одно поле может быть массивом.
TTL индексы: Специальный вид индекса для автоматического удаления «протухших» документов. По сути, это индекс по дате с опцией expireAfterSeconds. Используется для хранения с ограниченным временем жизни (например, сессии, логи). Особенность: TTL-индекс всегда одиночный (не может быть составным). Фоновый процесс MongoDB будет периодически (обычно раз в минуту) сканировать этот индекс и удалять документы старше указанного значения. Влияние на производительность: на чтение TTL-индекс не влияет, на запись – минимально (чуть увеличивает нагрузку при удалении, но это распределено во времени)
Вторичные индексы: Все индексы кроме _id считаются вторичными. MongoDB позволяет много вторичных индексов, но важно учитывать их влияние на память. Высоконагруженный MongoDB обычно настроен так, чтобы рабочие индексы помещались в RAM, иначе будут частые чтения с диска.
Ограничения:
Максимум 32 полей в compound-индексе
Размер индексов – по умолчанию ключ не более 1024 байт, однако есть поддержка хеш-индексов (хранят хеш от значения, ограничивая размер ключа). Хеш-индекс даёт равномерное распределение, но не поддерживает диапазоны.
Индексы в MongoDB не поддерживают некоторые выражения, как SQL (нет вычисляемых индексов до версии 4.4, но в 4.4+ появились Aggregation Expressions indexes – аналог функциональных).
Лучшие практики MongoDB:
Проектируйте по запросам: как и в SQL, не индексируйте то, что не используется в запросах.
Compound вместо нескольких: один составной индекс на (field1, field2) лучше, чем два отдельных, для запроса, использующего оба
Следите за размером: слишком большие индексы или их количество могут вытеснить данные из памяти. Помните: MongoDB хранит индексы в памяти (WireTiger использует своппинг страниц, но эффективно нужен RAM). Indeks, занимающий гигабайты, может стать узким местом.
Используйте профилировщик MongoDB: он покажет, сколько документов сканируется при запросах (метрика nscannedObjects / nscanned). Если запрос сканирует много документов при небольшом output – не хватает индекса.
Тестируйте с explain(): метод db.collection.explain() покажет, какой индекс используется и сколько документов проверяется. Это аналог SQL EXPLAIN.
Индексы в Apache Cassandra

Cassandra – распределённая колонночная NoSQL, основанная на идеях DynamoDB и BigTable. Её подход к индексам отличается:
Primary Key vs Secondary Index: В Cassandra каждая таблица имеет свой Primary Key, состоящий из Partition Key (один или несколько столбцов) и опционально Clustering columns. Partition Key определяет, на каком узле хранится запись (ключ партиции хэшируется и распределяется по кластеру). Clustering columns определяют сортировку внутри партиции. Таким образом, основной способ эффективного доступа в Cassandra – через Primary Key (зная точный partition key, либо диапазон по clustering key внутри партиции). Без знания partition key поиск требует обращаться ко всем узлам.
Вторичные индексы: Cassandra позволяет создавать индекс на колонку, не входящую в Primary Key. Но это менее эффективно и рекомендуется в ограниченных случаях. Почему? Вторичный индекс не глобальный, а локальный на каждом узле. Когда вы делаете запрос по такому индексу, координатор рассылает запрос всем узлам к локальному индексу. Те узлы, у которых найдётся значение, вернут результаты, остальным будет нечего вернуть. При большом количестве узлов это не масштабируется – запрос превращается практически в полный скан кластера. Cassandra документация прямо говорит: не используйте индекс для высоко-кардинальных или очень низко-кардинальных столбцов
Высокая кардинальность (уникальные значения): в индексе почти столько же точек, сколько строк. Запрос по такому значению обратится ко всем узлам, причём на каждом узле, возможно, найдётся лишь 1 результат. Много сетевых вызовов ради нескольких записей – неэффективно
Низкая кардинальность (очень мало уникальных значений): например, булево поле или статус с 2-3 значениями. Индекс по нему соберёт сотни тысяч ключей, указывающих на многие партиции. Запрос «status = true» опять же пойдёт на все узлы, и каждый вернёт огромный список. Проще было бы сканировать последовательность. Cassandra прямо говорит, что индекс на boolean "не имеет смысла"
Часто обновляемые/удаляемые данные: вторичные индексы тоже хранят tombstones при удалении. Если часто обновлять поле с индексом, будет накапливаться много tombstone-записей, что ведёт к деградации, вплоть до отказа запросов, если tombstone слишком много
Большие партиции: если индексируется колонка внутри очень большой партиции, запрос должен все равно перебрать эту партицию, что не быстрее полного скана ее же
Когда вторичные индексы допустимы: Когда запросы по индексу редкие и не критичны по задержке, либо когда кластер небольшой. Cassandra 3+ также имеет т.н. SASI (Storage-Attached Secondary Index) – улучшенная версия индексов, более эффективная и с поддержкой префиксного поиска. Но и для SASI рекомендации по кардинальности остаются в силе
Денормализация вместо индексов: Распространённый подход в Cassandra – если нужны разные ключи доступа, лучше создать отдельную таблицу (или материализованное представление) с нужным Primary Key, чем полагаться на вторичные индексы. Например, если у нас есть таблица по user_id (partition key), а часто надо искать по email, то создают вторую таблицу (или materialized view) с partition key = email, содержащую ссылку на user. Тем самым вы получаете индексированное хранилище по email, но управляемое явно на уровне данных.
TTL: В Cassandra можно назначать Time To Live на данные (записи «протухают» и удаляются автоматически). Это не индекс, но часто используется вместо явного TTL-индекса, как в Mongo. Однако массовое истечение TTL может создавать нагрузку из-за множества tombstones, поэтому планируйте единовременный объем истекающих данных.
Лучшие практики Cassandra:
Проектируйте схему от запросов: В Cassandra говорят "query-based modeling". Нормализация менее важна, важнее, чтобы каждый запрос читал одну партицию. Заранее продумайте, по каким ключам будет доступ – сделайте их частью Primary Key. Например, для блога, если нужно выбирать посты по автору и дате – сделайте PRIMARY KEY(author, date); если по тегам – возможно, заведите отдельную таблицу posts_by_tag(tag, post_id).
Избегайте вторичных индексов для критичных путей: они не масштабируются при росте данных/узлов. Используйте, только если данных мало или это "административный" запрос вне основного потока.
Ограничивайте размер партиций: индексы (и вообще запросы) страдают, если партиция содержит миллионы записей. Лучше разбивать (например, добавить в partition key ещё и год, если храните события по пользователю, чтоб партиция не росла бесконечно).
Monitoring: Cassandra не так легко профилировать, но следует обращать внимание на метрики Read Latency, количество tombstones (в ответах CQL драйвера при tracing видно), и на координацию запросов. Если запрос выполняется слишком долго и, судя по tracing, обходит много узлов – вероятно, не хватает правильного индексационного подхода.
Итого, индексация в NoSQL всё так же служит ускорению запросов, но ещё сильнее завязана на шаблоны запросов. MongoDB в этом плане ближе к реляционным – там вы просто создаёте нужные индексы. Cassandra же поощряет продуманное распределение данных и создание дополнительных структур вместо «индексирования по месту».
Типичные ошибки и анти-паттерны индексирования

Ниже перечислены распространённые ошибки при работе с индексами, которые могут ухудшить производительность:
Неиндексированные JOIN-ы: Забытая индексация столбцов, по которым выполняются соединения таблиц. Это приводит к тому, что база делает полные перекрёстные обходы – крайне медленно на больших таблицах. Анти-паттерн: отсутствие индекса на внешнем ключе. Решение – всегда индексировать внешние ключи и вообще поля, участвующие в JOIN, чтобы каждая сторона соединения могла быстро найти соответствия.
Индексирование колонок с низкой селективностью: Например, поле gender (M/F) или status с несколькими значениями, когда распределение равномерное. Такие индексы почти бесполезны – условие отсекает половину или треть таблицы, оптимизатор, скорее всего, выберет seq scan. Пример: индекс на поле, где ~50% строк имеют значение 'true'. Запрос WHERE field = true вернёт половину таблицы – использование индекса заставит пройти по миллионам записей из индекса и затем прочитать столько же строк таблицы, что может быть медленнее, чем просто один проход по таблице крупными блоками. Лучше не создавать индекс, чем создавать его впустую. Если же очень нужно ускорить такие запросы, можно применить частичный индекс (PostgreSQL) – например, индексировать только WHERE status='ACTIVE' если неактивных гораздо больше, либо рассмотреть другой подход (разбить таблицу, кэшировать и т.д.).
Дублирующие/пересекающиеся индексы: Создание нескольких индексов, покрывающих одни и те же колонки. Например, индекс по (A) и по (A,B) – первый дублируется вторым по части A. Или два индекса: (A,B) и (B,A) – часто тоже избыточны, если запросы по отдельности A и B не идут. Лишние индексы нужно удалять. Проверить дубликаты можно, сравнив наборы колонок. Иногда индексы появляются дублирующиеся из-за неявных причин (например, уникальный индекс по PK и PK как кластерный – в SQL Server это отдельно, в Postgres PK = уникальный B-Tree индекс). Следите, чтобы не поддерживать два индекса там, где нужен один.
Отсутствие покрывающих индексов (индекс не покрывает запрос): Ситуация, когда индекс вроде и используется, но запрос всё равно лезет в таблицу за дополнительными колонками. Это значит, что можно улучшить: добавить недостающие поля в индекс (включить в состав или через INCLUDE в PG), чтобы произошёл Index Only Scan. Anti-pattern: часто используемый «узкий» индекс, но каждый раз потом идёт чтение таблицы. Например, индекс на user_id, а запрос SELECT user_name WHERE user_id=... – тут всё равно нужно идти в таблицу за user_name. Если запрос суперчастый, лучше сделать составной индекс (user_id, user_name) – он станет покрывающим. Без покрытия – лишние нагрузки.
Функции и выражения в WHERE без соответствующего индекса: Например, WHERE DATE(created_at) = '2023-01-01'. Такой запрос не сможет использовать индекс по created_at, потому что к колонке применяется функция (за исключением случаев, когда оптимизатор умеет преобразовать, что редко). Это анти-паттерн – оборачивать колонку функцией на стадии фильтрации. В результате всегда полный просмотр. Решения: либо переписать условие (например, WHERE created_at >= '2023-01-01' AND created_at < '2023-01-02' – уже можно использовать индекс по дате), либо завести функциональный индекс по DATE(created_at) если такая конструкция часто нужна. Аналогично с другими функциями и выражениями – делайте вычисления вне SQL или добавляйте индекс на выражение.
Индексы, которые не соответствуют шаблонам запросов: Индекс ради индекса. Например, разработчик проиндексировал все отдельные колонки таблицы «на всякий случай». Но реальные запросы сложные, фильтруют по множеству условий – в итоге ни один из одинарных индексов не используется, нужен был составной. Или наоборот: создали составной индекс (A,B,C), а часто выполняются запросы только по B – индекс не помогает, а отдельного по B нет. Лекарство – анализировать статистику запросов и соответствие индексов им, вносить изменения.
Не учтено влияние изменения данных на индекс: Например, индекс по полю, которое очень часто обновляется (скажем, счётчик, баланс). При каждом обновлении запись переносится на новую позицию в индексе, может происходить фрагментация. Это может стать точкой блокировок или горячей страницей. Если такие обновления критичны, иногда индексы на таких колонках избегают, либо применяют специальные подходы (например, partial index только на часто запрашиваемое подмножество значений, или используют кластеризацию).
Слепая вера в индексы: Полагать, что раз индекс есть, то запрос автоматически оптимальный. Всегда проверяйте план. Бывает, что индекс не используется, потому что запрос написан не оптимально (условия несовместимы с индексом, или статистика неверная). Иногда нужно подсказать оптимизатору (например, в редких случаях использовать индексные подсказки вроде USE INDEX в MySQL, но это крайность). В общем, следите за реальным поведением.
Рекомендации по проектированию схемы с учётом индексов
При разработке схемы базы данных под высокие нагрузки, держите в уме индексы с самого начала. Вот ключевые рекомендации:
Индексируйте по запросам: Выпишите ключевые запросы системы (особенно те, что в критичном пути или будут выполняться часто). Убедитесь, что по каждому предусмотрен хотя бы один индекс, который будет им помогать. Например, в веб-приложении обычно есть запросы "получить объект по ID" (нужен PK или уникальный индекс), "список объектов с фильтром по пользователю и времени" (нужен составной индекс по user_id+date), и т.д.
Оцените кардинальность полей: Чем более уникальны значения в столбце, тем больше выгода индексации (индекс отсеет максимум строк). Столбцы с тысячами уникальных значений – хорошие кандидаты для индекса, а с парой значений – почти всегда нет. Если бизнес-логика требует фильтрации по низкоселективному полю, подумайте о частичном индексе (например, индексовать только редкое значение) или об изменении логики хранения (например, вынести часто встречающееся значение в отдельную таблицу, а основную фильтровать только по редкому).
Не забывайте про сортировку и группировку: Если известно, что данные часто запрашиваются в определённом порядке, сделайте индекс в этом порядке. Индекс может одновременно служить и для фильтрации, и для сортировки. Например, для ленты событий ORDER BY timestamp DESC индекс по timestamp DESC ускорит выдачу самых новых событий, особенно в сочетании с LIMIT. Группировку индекс поддержит, только если она совпадает с порядком (как обсуждалось выше), так что обычно групповой агрегат лучше оптимизировать другим путём (материализованные агрегаты, кэш).
Комбинируйте условия в составных индексах: Вместо множества одиночных индексов на каждое поле, старайтесь создавать составные индексы, покрывающие сразу несколько условий запроса (AND). Это даст больше шансов, что именно один индекс полностью обслужит запрос, вместо множества частичных. Но не переусердствуйте: индекс на 5 колонок, из которых только 2 реально фильтруются в запросах, будет лишней тратой ресурсов. Найдите минимальный набор.
Учитывайте частоту запросов: Индекс для редкого отчётного запроса, возможно, не нужен – его можно выполнить и с полной выборкой раз в месяц. А вот индекс для API, которое дергается 1000 раз в секунду, жизненно необходим. Расставляйте приоритеты: наиболее частые и критичные по производительности запросы – в первую очередь оптимизировать индексами.
Минимизируйте количество индексов на сильно изменяемых таблицах: Если таблица получает сотни вставок в секунду (например, лог событий), постарайтесь держать на ней только индекс PK (может быть по времени, если партиционирование) и парочку необходимых для основных запросов. Массовая индексация таких данных быстро приведёт к проблемам с производительностью записи.
Используйте покрывающие и частичные индексы по необходимости: Для часто выполняемых однотипных запросов имеет смысл «добавить» в индекс столбцы, чтобы избежать обращений к таблице. Например, часто читается поле balance по user_id – можно индексировать (user_id, balance). А если приложение чаще нужно выбрать только пользователей с определённым флагом, можно применить partial index: CREATE INDEX ... ON users(email) WHERE active = true – такой индекс будет меньше по размеру и ускорит только нужный кейс.
Следите за ростом данных: Архитектура, прекрасно работавшая на 100k записей, может упереться в потолок на 100 млн. Пересматривайте стратегию индексации при росте. Возможно, понадобятся новые индексы под новые запросы или удаление старых. Может оказаться полезным партиционирование данных (например, по дате) – тогда часть запросов будет вообще работать с меньшими частями таблицы, снижая потребность в индексах или объём их работы.
Тестируйте и профилируйте: Перед развёртыванием на продакшене, прогоните нагрузочные тесты с профилированием запросов. Убедитесь, что планы запросов оптимальны, индексы используются как ожидается. Лучше поймать отсутствие индекса на этапе теста, чем получать alarm о медленных запросах в бою.
Документируйте решения: В командной работе полезно оставлять комментарии, какие индексы и зачем были созданы. Это поможет в будущем понять логику и избежать случайного удаления нужного индекса или дублирования.
Все эти рекомендации сводятся к одному: думайте о том, как данные будут использоваться, и подстраивайте структуру хранения (включая индексы) под эти использования.
Чеклист выбора индекса под задачу
В заключение, приведём чеклист – набор вопросов, который стоит пройти, решая, нужен ли индекс и какой именно:
1. Что за запрос мы ускоряем?
Выпишите пример запроса (SELECT) с всеми его частями (WHERE, JOIN, ORDER BY, GROUP BY, LIMIT).2. Какие колонки участвуют в фильтрах и соединениях?
Именно они – первые кандидаты на индексирование. Если несколько – планируем составной индекс.3. Сколько данных отбирает этот запрос?
Если он обычно возвращает <1-5% таблицы – индекс обязательно нужен (селективный запрос). Если 50% и более – индекс, возможно, не даст выигрыша, можно обойтись полным сканированием (но подумать о партиционировании или изменении запроса). При 5-20% – ситуация пограничная, решается экспериментом (иногда индекс всё же быстрее).4. Подходит ли тип индекса под операторы?
Равенство, диапазон – B-Tree идеален. LIKE '%...' – понадобится специальный (например, полнотекстовый или GIN). Гео-запросы – R-Tree или GiST. Сначала убедитесь, что в принципе существует индекс, умеющий ускорить такой запрос.5. Нужен ли составной индекс?
Если в WHERE несколько условий по разным столбцам, или комбинация фильтра+сортировка – спроектируйте составной индекс, покрывающий эти элементы в правильном порядке (обычно равенства и точные фильтры впереди, сортировка/диапазон следом).6. Нужно ли индексировать все эти поля или хватит части?
Если запрос часто фильтруется по (A,B), но иногда бывают фильтры только по A – индекс по (A,B) справится и с тем, и с другим (по A он тоже используется). А вот если иногда фильтруют только по B, то нужен отдельный индекс по B или перестановка. Решите, нужно ли несколько индексов или можно обойтись одним.7. Будет ли индекс покрывающим?
Посмотрите на SELECT-список. Если запросу нужны только поля, которые вы собираетесь индексировать, то получится индекс, покрывающий запрос (что хорошо). Если же запрос возвращает много других колонок, то индекс всё равно вынужден будет обращаться к таблице. Можно ли добавить парочку столбцов в индекс, чтобы покрыть запрос полностью? Это улучшит производительность, но увеличит индекс – решение принимается исходя из частоты запроса.8. Каковы побочные эффекты для записи?
Оцените, как часто вставляются/обновляются данные в таблицу, и насколько замедлит это новый индекс. Если таблица огромная и постоянно пишется, каждый новый индекс ощутимо снизит throughput записи. В highload-системах баланс критичен: иногда лучше пожертвовать скоростью редкого запроса, чем замедлить всю систему из-за индекса. Можно использовать статистику: например, каждый индекс может добавлять ~5-10% к времени обработки вставки (оценочно). Соответственно, десяток лишних индексов удвоит время вставки – плохо. Если без индекса не обойтись (требование бизнеса по быстрому чтению), возможно масштабирование: больше реплик для разгрузки, шардинг и прочее.9. Протестируйте с EXPLAIN.
Создайте индекс в тестовой среде и посмотрите план запроса. Используется ли новый индекс? Каков оценочный выигрыш (смотрите cost или реальное время с ANALYZE)? Убедитесь, что план стал лучше (меньше cost, меньше прочитанных строк). Иногда бывает, что индекс не используется из-за неверной оценки – тогда может помочь ANALYZE или даже SET enable_seqscan=off для проверки, может ли вообще индекс дать выигрыш.10. Мониторьте в бою.
После выхода в продакшен, следите за метриками: ушли ли проблемы с медленным запросом? Нет ли побочных эффектов – выросло ли время вставки, не появились ли lock-и? Проверьте через статистику (например, pg_stat_user_indexes), что индекс действительно используется (idx_scan растет). Если индекс не прижился – возможно, он не нужен и его стоит убрать.
Пройдя по этому чеклисту, вы с большой вероятностью примете обоснованное решение об индексации. Правильный выбор индексов – это во многом искусство, основанное на данных: понимание природы данных и запросов, экспериментирование и измерение. Следуя описанным принципам и избегая перечисленных ошибок, вы сможете обеспечить высокую производительность своих highload-систем за счёт эффективной индексации данных
Удачного проектирования!

