
Привет, Хабр!
Меня зовут Радик, Head of DevOps of AGIMA!
В этой статье я постарался показать, как можно использовать Prometheus в качестве системы мониторинга для микросервисной архитектуры. Подробно рассмотрел архитектуру Prometheus и взаимодействие его компонентов. Обозначил ключевые характеристики благодаря чему эта система получила такое широкое распространение в средах использующих контейнеризацию. Предупреждаю сразу: статья получилась довольно объемной. Эта статься будет полезна для начинающих DevOps специалистов, которые планируют или уже используют в своей работе Docker, Kubernetes. Итак, начнем!
Что такое Prometheus?
Prometheus — система мониторинга, разработанная специально для динамически изменяющейся среды. Кроме того, она может использоваться для традиционной инфраструктуры, например, на физических серверах с приложениями, развернутыми непосредственно на ОС. На сегодняшний день Prometheus занимает лидирующую позицию среди инструментов, применяемых в мире микросервисов. Чтобы понять, почему Prometheus пользуется такой популярностью, давайте рассмотрим несколько примеров.
В качестве среды для разворачивания системы будем использовать Kubernetes.
Цель — настроить в Prometheus мониторинг для Redis-кластера в Kubernetes. Графический интерфейс — Grafana. Для оповещения задействуем email и Slack.
Основные компоненты Prometheus
 "
" В центре Prometheus — сервер, который выполняет работу по мониторингу. Он состоит из следующих частей:
- Time Series Data Base (TSDB) — база данных, в которой хранятся метрики, полученные от целевых объектов. Например, CPU usage, Memory utilization или количество запросов к сервису
- Retrieval worker отвечает за получение этих метрик с целевых ресурсов и размещение данных в TSDB
- HTTP server — API для выполнения запросов к сохраненным в TSDB данным. Используется для отображения данных на дашборде в Prometheus или сторонних системах визуализации — таких, как Grafana.
От теории к практике
Давайте развернем наш сервер Prometheus с помощью пакетного менеджера Helm.
Инструкция предназначена для инженеров, которые имеют базовые навыки работы с Kubernetes и может быть использована только в ознакомительных целях. Использование в продакшен данной конфигурации крайне не рекомендуется.
Для этого потребуются рабочий кластер Kubernetes и настроенный kubectl. Можно попробовать использовать кластер Kubernetes в MCS. Сервер Prometheus устанавливается достаточно просто:
#Добавляем репозиторий
helm repo add stable https://kubernetes-charts.storage.googleapis.com
#Обновляем
helm repo update
#Создаем namespace
kubectl create namespace monitoring
#Устанавливаем helm c именем my-prometheus
helm install my-prometheus stable/prometheus -n monitoring
В результате выполнения мы получаем:
The Prometheus PushGateway can be accessed via port 9091 on the following DNS name from within your cluster:
my-prometheus-pushgateway.monitoring.svc.cluster.local
Get the PushGateway URL by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app=prometheus,component=pushgateway" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace monitoring port-forward $POD_NAME 9091
For more information on running Prometheus, visit:
https://prometheus.io/
Проверяем, все ли поды запущены:
kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
my-prometheus-alertmanager-86986878b5-5w2vw 2/2 Running 0 76s
my-prometheus-kube-state-metrics-dc694d6d7-xk85n 1/1 Running 0 76s
my-prometheus-node-exporter-grgqw 1/1 Running 0 76s
my-prometheus-node-exporter-njksq 1/1 Running 0 76s
my-prometheus-node-exporter-pcmgv 1/1 Running 0 76s
my-prometheus-pushgateway-6694855f-n6xwt 1/1 Running 0 76s
my-prometheus-server-77ff45bc6-shrmd 2/2 Running 0 76s
При выводе Helm chart предлагает выполнить port-forward для pushgateway, чтобы получить доступ к интерфейсу Prometheus. Меняем component на server и выполняем:
#получаем название контейнера и сохраняем его в переменную POD_NAME
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app=prometheus,component=server" -o jsonpath="{.items[0].metadata.name}")
#пробрасываем порт
kubectl --namespace monitoring port-forward $POD_NAME 9090
Теперь открываем http://127.0.0.1:9090/ в браузере — и видим интерфейс Prometheus:

Итак, у нас есть сервер Prometheus, развернутый внутри кластера Kubernetes. Теперь давайте развернем Redis, который впоследствии и поставим на мониторинг в Prometheus. Для этого также используем Helm:
#добавляем репозиторий
helm repo add bitnami https://charts.bitnami.com/bitnami
#Обновляем
helm repo update
#Создаем namespace
kubectl create namespace redis
#Устанавливаем helm c именем redis
helm install redis bitnami/redis -n redis --set cluster.enabled=true --set cluster.slaveCount=2 --set master.persistence.enabled=false --set slave.persistence.enabled=false
Параметры cluster.enabled и cluster.slaveCount определяют, что Redis будет развернут в режиме «кластер», и в этом кластере два пода будут работать как slave. В параметрах указываем: не использовать persistent volume для master и slave (persistence.enabled=false). Сейчас это нужно, чтобы продемонстрировать работу Redis. В продакшене будет необходимо сделать настройку persistent volume.
Проверяем, что все поды redis запущены:
kubectl get pod -n redis
NAME READY STATUS RESTARTS AGE
redis-master-0 1/1 Running 0 65s
redis-slave-0 1/1 Running 0 65s
redis-slave-1 1/1 Running 0 28s
Теперь, когда у нас развернуты Prometheus и Redis, нужно настроить их взаимодействие.
Targets и metrics
Prometheus-сервер может мониторить самые разные объекты — к примеру, Linux- и Windows-серверы. Это может быть база данных или приложение, которое предоставляет информацию о своем состоянии. Такие объекты в Prometheus называются targets. Каждый объект имеет так называемые единицы мониторинга. Для Linux-сервера это может быть текущая утилизация CPU, использование memory и диска. Для приложения — количество ошибок, количество запросов и время их выполнения. Эти единицы называются metrics и хранятся в TSDB.
Exporters
Prometheus получает метрики из указанных в его конфигурации источников в блоке targets. Некоторые сервисы самостоятельно предоставляют метрики в формате Prometheus, и для их сбора не нужно ничего дополнительно настраивать. Достаточно подключить Prometheus в конфигурации, как это сделано ниже:
scrape_configs:
— job_name: prometheus
static_configs:
— targets:
— localhost:9090
Указываем серверу Prometheus забирать метрики из конечной точки: localhost:9090/metrics.
Для сервисов, которые не могут самостоятельно предоставлять метрики в формате Prometheus, нужно установить дополнительный компонент exporters. Обычно exporters — скрипт или сервис, который получает метрики от цели, конвертирует их формат, который «понимает» Prometheus, и предоставляет эти данные серверу по пути /metrics. Prometheus имеет большой набор готовых exporters для разных сервисов — эти компоненты можно использовать для HAProxy, Linux system, облачных платформ и др.
Redis и exporter
Давайте подключим exporter для нашего Redis-кластера. Сначала потребуется создать файл values.yaml со следующим содержанием:
cluster:
enabled: true
slaveCount: 2
##
## Redis Master parameters
##
master:
persistence:
enabled: false
extraFlags:
— "--maxmemory 256mb"
slave:
persistence:
enabled: false
extraFlags:
— "--maxmemory 256mb"
## Prometheus Exporter / Metrics
##
metrics:
enabled: true
image:
registry: docker.io
repository: bitnami/redis-exporter
tag: 1.4.0-debian-10-r3
pullPolicy: IfNotPresent
## Metrics exporter pod Annotation and Labels
podAnnotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9121"
Здесь параметры, которые использовались в командной строке для настройки Redis в режиме cluster, перенесены в yaml-файл. Для сбора метрик добавлено подключение redis-exporter.
Обновляем Redis с новыми параметрами:
helm upgrade redis -f redis/values.yaml bitnami/redis -n redis
Проверяем, что поды Redis запущены:
kubectl get pods -n redis
redis-master-0 2/2 Running 0 3m40s
redis-slave-0 2/2 Running 0 2m4s
redis-slave-1 2/2 Running 0 2m16s
Теперь к каждому pod «привязан» дополнительный контейнер redis-exporter, который предоставляет доступ к метрикам Redis.
Добавлять снятие метрик для развернутых контейнеров redis-exporter в конфигурацию Prometheus не нужно, так как он по умолчанию содержит kubernetes_sd_configs (листинг представлен ниже). За счёт этого динамически подключается сбор метрик для вновь появившихся подов. Подробнее об этом можно прочитать в документации.
— job_name: 'kubernetes-pods'
kubernetes_sd_configs:
— role: pod
relabel_configs:
— source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
— source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
— source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
— action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
— source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
— source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
Давайте убедимся, что мы получаем данные о состоянии Redis. Для этого можно открыть интерфейс и ввести PromQL-запрос redis_up:
"

В отличие от других систем мониторинга, Prometheus не получает данные от целевых сервисов, а самостоятельно забирает с указанных в конфигурации endpoints — это одна из его важнейших характеристик. Когда вы работаете с большим количеством микросервисов, и каждый из них отправляет данные в систему мониторинга, вы можете столкнуться с риском отправки слишком большого количества данных на сервер Prometheus, а это может привести его выходу из строя. Prometheus предоставляет централизованное управление сбором метрик, т.е. вы самостоятельно решаете, откуда и как часто забирать данные. Еще одно преимущество использования Prometheus — возможность динамически получать источники данных с помощью функции service discovery, работа которой была продемонстрирована выше на примере Redis-подов.
Но бывает случаи, когда необходимо получать данные от источника временно, и у Prometheus нет необходимости забирать их с сервиса постоянно (например, запланированные задания по крону, снятие бэкапов и т.д.). Для таких случаев Prometheus предлагает pushgateway, чтобы сервисы могли отправлять свои метрики в базу данных Prometheus. Использование pushgateway — скорее исключение, чем правило, но о его возможности не стоит забывать.
Теперь, для того, чтобы наша система мониторинга стала полноценной, нужно добавить оповещения о выходе значений метрик за допустимые пределы.
Alertmanager и Alerting rules
За отправку предупреждений в Prometheus отвечает компонент AlertManager. В качестве каналов оповещения могут выступать: email, slack и другие клиенты. Для настройки оповещения необходимо обновить конфигурацию файла alertmanager.yml.
Создадим файл prometheus/values.yaml со следующим содержимым:
## alertmanager ConfigMap entries
##
alertmanagerFiles:
alertmanager.yml:
global:
slack_api_url: <secret>
route:
receiver: slack-alert
group_by:
— redis_group
repeat_interval: 30m
routes:
— match:
severity: critical
receiver: slack-alert
receivers:
— name: slack-alert
slack_configs:
— channel: 'general'
send_resolved: true
color: '{{ if eq .Status "firing" }}danger{{ else }}good{{ end }}'
title: '[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing
| len }}{{ end }}] {{ .CommonAnnotations.summary }}'
text: |-
{{ range .Alerts }}
*Alert:* {{ .Annotations.summary }} — *{{ .Labels.severity | toUpper }}* on {{ .Labels.instance }}
*Description:* {{ .Annotations.description }}
*Details:*
{{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}`
{{ end }}
{{ end }}
Slack_api_url должен содержать ключ, который можно получить на сайте Slack.
В поле channel указывается канал, на который будут приходить оповещения. В нашем случае это general. Остальные параметры отвечают за формат уведомлений.
Конфигурацию, описанную далее, можно найти в репозитории.
Обновляем my-prometheus:
helm upgrade my-prometheus -f prometheus/values.yaml stable/prometheus -n monitoring
Для того, чтобы получить доступ к интерфейсу Alertmanager, выполним следующее:
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app=prometheus,component=alertmanager" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace monitoring port-forward $POD_NAME 9093
Теперь в интерфейсе Alertmanager можно убедиться, что появилась конфигурация для отправки оповещения в канал Slack http://127.0.0.1:9093/#/status:

Далее нужно создать правила, по которым нотификация будет отправляться в Slack-канал.
Правила представляют собой значения метрик или их совокупности, объединенные логическим условием. При выходе значения метрики за допустимые пределы Prometheus обращается к Alertmanager, чтобы отправить нотификации по определенным в нем каналам. Например, если метрика redis_up вернет значение 0, сработает уведомление о недоступности того или иного узла кластера.
Добавляем в файл prometheus/values.yaml стандартные правила для сигнализации о проблемах в Redis:
serverFiles:
## Alerts configuration
## Ref: https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
alerting_rules.yml:
groups:
— name: redis_group
rules:
— alert: redis_is_running
expr: redis_up == 0
for: 30s
labels:
severity: critical
annotations:
summary: "Critical: Redis is down on the host {{ $labels.instance }}."
description: "Redis has been down for more than 30 seconds"
— alert: redis_memory_usage
expr: redis_memory_used_bytes / redis_memory_max_bytes * 100 > 40
for: 5m
labels:
severity: warning
annotations:
description: "Warning: Redis high memory(>40%) usage on the host {{ $labels.instance }} for more than 5 minutes"
summary: "Redis memory usage {{ humanize $value}}% of the host memory"
— alert: redis_master
expr: redis_connected_clients{instance!~"server1.mydomain.com.+"} > 50
for: 5m
labels:
severity: warning
annotations:
description: "Warning: Redis has many connections on the host {{ $labels.instance }} for more than 5 minutes"
summary: "Redis number of connections {{ $value }}"
— alert: redis_rejected_connections
expr: increase(redis_rejected_connections_total[1m]) > 0
for: 30s
labels:
severity: critical
annotations:
description: "Critical: Redis rejected connections on the host {{ $labels.instance }}"
summary: "Redis rejected connections are {{ $value }}"
— alert: redis_evicted_keys
expr: increase(redis_evicted_keys_total[1m]) > 0
for: 30s
labels:
severity: critical
annotations:
description: "Critical: Redis evicted keys on the host {{ $labels.instance }}"
summary: "Redis evicted keys are {{ $value }}"
Обновляем my-prometheus:
helm upgrade my-prometheus -f prometheus/values.yaml stable/prometheus -n monitoring
Для проверки работы нотификации в Slack, изменим правило алерта redis_memory_usage:
expr: redis_memory_used_bytes / redis_memory_max_bytes * 100 < 40
Снова обновляем my-prometheus:
helm upgrade my-prometheus -f prometheus/values.yaml stable/prometheus -n monitoring
Переходим на страницу http://127.0.0.1:9090/alerts:

Redis_memory_usage перешел в статус «pending». Значение выражения для всех трех подов чуть больше 0.72. Далее уведомление проходит в Slack:
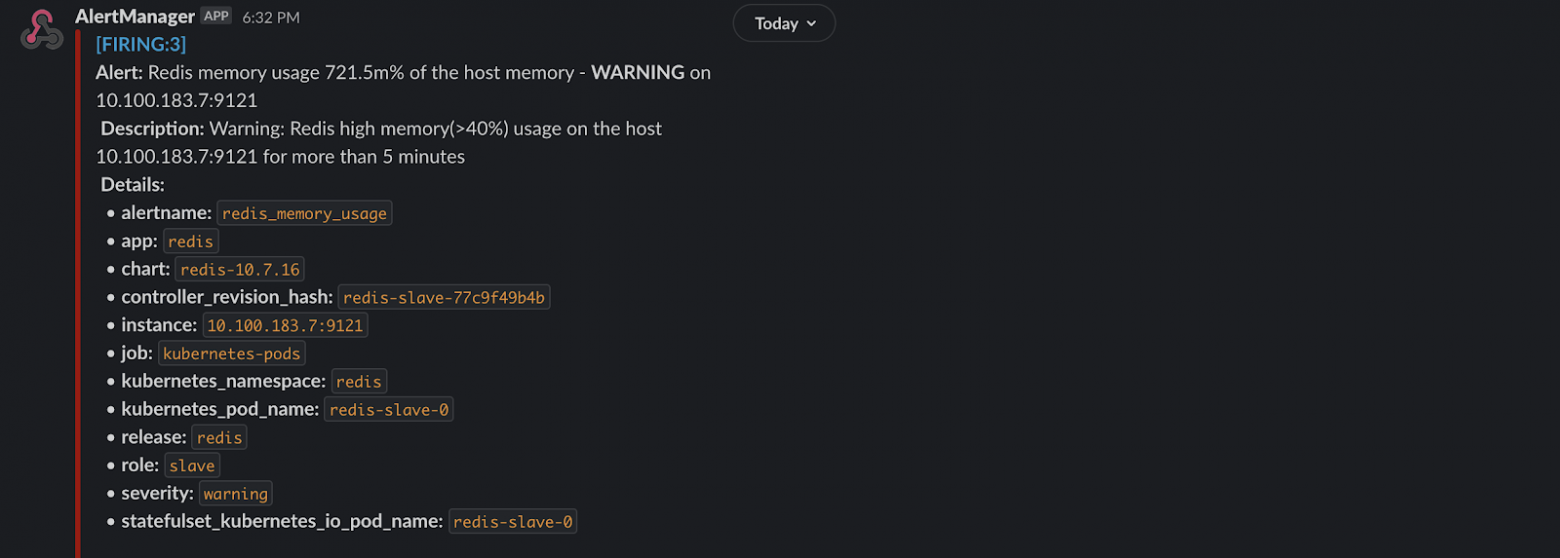
Теперь добавляем нотификацию по email. При этом конфигурация alermanager.yml изменится так:
alertmanagerFiles:
alertmanager.yml:
global:
slack_api_url: <secret>
route:
receiver: slack-alert
group_by:
— redis_group
repeat_interval: 30m
routes:
— match:
severity: critical
receiver: slack-alert
continue: true
— match:
severity: critical
receiver: email-alert
receivers:
— name: slack-alert
slack_configs:
— channel: 'general'
send_resolved: true
color: '{{ if eq .Status "firing" }}danger{{ else }}good{{ end }}'
title: '[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing
| len }}{{ end }}] {{ .CommonAnnotations.summary }}'
text: |-
{{ range .Alerts }}
*Alert:* {{ .Annotations.summary }} — *{{ .Labels.severity | toUpper }}* on {{ .Labels.instance }}
*Description:* {{ .Annotations.description }}
*Details:*
{{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}`
{{ end }}
{{ end }}
— name: email-alert
email_configs:
— to: alert@agima.ru
send_resolved: true
require_tls: false
from: alert@agima.ru
smarthost: smtp.agima.ru:465
auth_username: "alert@agima.ru"
auth_identity: "alert@agima.ru"
auth_password: <secret>
В блок routes добавляем еще один путь для нотификации: receiver: email-alert. Ниже описываем параметры для email. В этом случае при том или ином событии мы получим уведомления одновременно в Slack и на email:
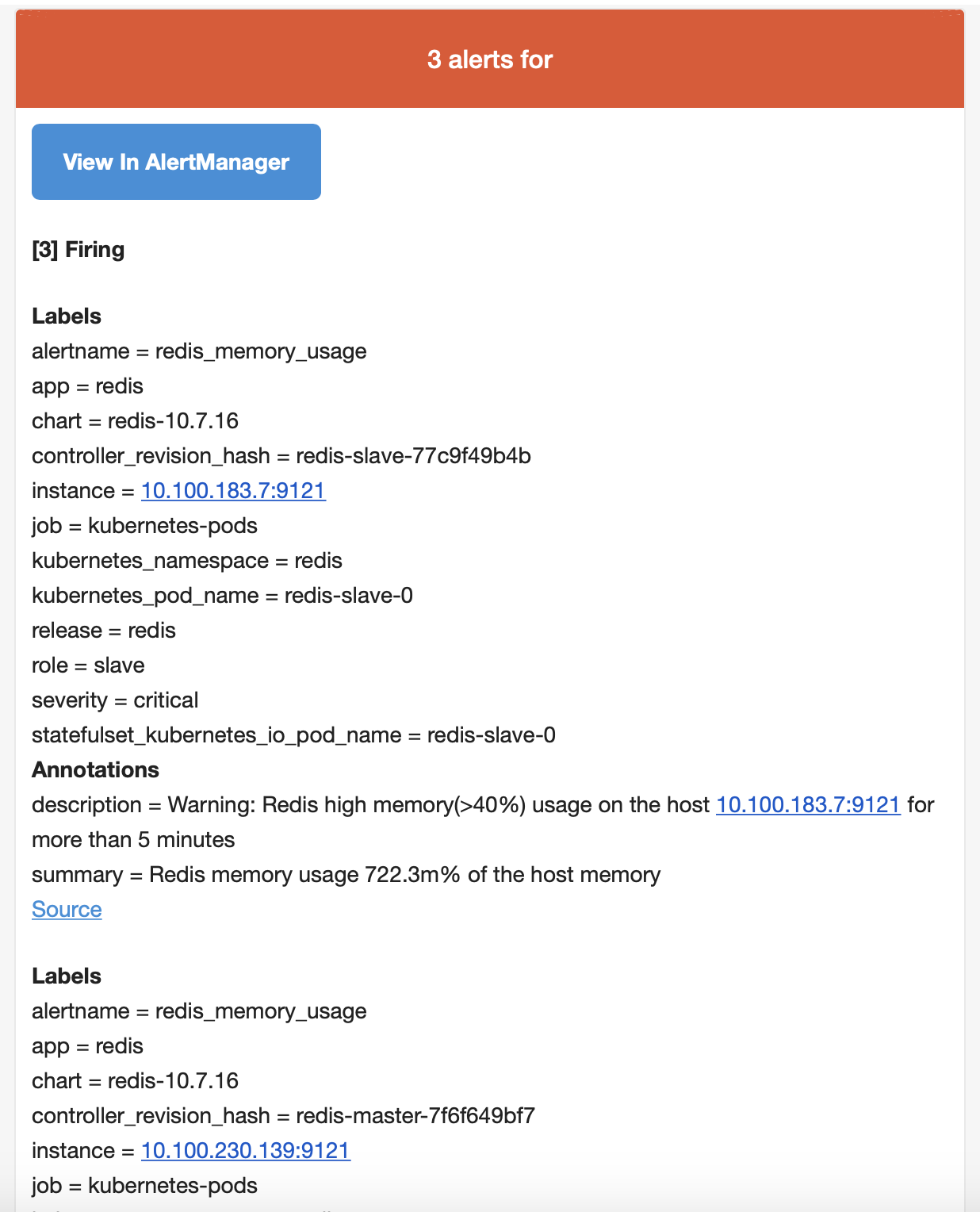
Blackbox exporter
Теперь рассмотрим, как в Prometheus добавляются targets на примере контейнера blackbox exporter, который позволяет организовать мониторинг внешних сервисов по протоколам HTTP(s), DNS, TCP, ICMP.
Для установки blackbox exporter используем Helm:
helm install blackbox-exporter stable/prometheus-blackbox-exporter --namespace monitoring
Проверяем, что поды blackbox exporter запущены:
kubectl get pods -n monitoring | grep blackbox
blackbox-exporter-prometheus-blackbox-exporter-df9f6d679-tvhrp 1/1 Running 0 20s
Добавляем в файл prometheus/values.yaml следующую конфигурацию:
extraScrapeConfigs: |
— job_name: 'prometheus-blackbox-exporter'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
— targets:
— https://example.org
relabel_configs:
— source_labels: [__address__]
target_label: __param_target
— source_labels: [__param_target]
target_label: instance
— target_label: __address__
replacement: blackbox-exporter-prometheus-blackbox-exporter.monitoring.svc.cluster.local:9115
Указываем, откуда собирать метрики:
blackbox-exporter-prometheus-blackbox-exporter.monitoring.svc.cluster.local:9115/probe. В качестве targets указываем URL сервиса для мониторинга: https://example.org. Для проверки используется модуль http_2xx, который по умолчанию устанавливается в blackbox exporter. Конфигурация проверки:
secretConfig: false
config:
modules:
http_2xx:
prober: http
timeout: 5s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
no_follow_redirects: false
preferred_ip_protocol: "ip4"
Обновляем конфигурацию my-prometheus:
helm upgrade my-prometheus -f prometheus/values.yaml stable/prometheus -n monitoring
В интерфейсе Prometheus http://127.0.0.1:9090/targets проверяем, что у нас появилась конечная точка для сбора метрик:

Чтобы расширить область проверки, добавляем http_2xx_check-модуль, который, помимо валидации версии и статуса 200 http, будет проверять наличие заданного текста в теле ответа:
secretConfig: false
config:
modules:
http_2xx:
prober: http
timeout: 5s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
no_follow_redirects: false
preferred_ip_protocol: "ip4"
valid_status_codes: [200]
http_2xx_check:
prober: http
timeout: 5s
http:
method: GET
fail_if_body_not_matches_regexp:
— "Example Domain"
fail_if_not_ssl: true
preferred_ip_protocol: ip4
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: [200]
Обновляем конфигурацию blackbox-exporter/values.yaml:
helm upgrade blackbox-exporter -f blackbox-exporter/values.yaml stable/prometheus-blackbox-exporter --namespace monitoring
Изменяем в файле prometheus/values.yaml модуль http_2xx на http_2xx_check:
extraScrapeConfigs: |
— job_name: 'prometheus-blackbox-exporter'
metrics_path: /probe
params:
module: [http_2xx]
Описания проверок, которые можно делать с blackbox exporter, приведены в документации.
Теперь добавим правила для сигнализации в Prometheus в файл prometheus/values.yaml:
— name: http_probe
rules:
— alert: example.org_down
expr: probe_success{instance="https://example.org",job="prometheus-blackbox-exporter"} == 0
for: 5s
labels:
severity: critical
annotations:
description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes.'
summary: 'Instance {{ $labels.instance }} down'
И обновляем конфигурацию my-prometheus:
helm upgrade my-prometheus -f prometheus/values.yaml stable/prometheus -n monitoring
Для проверки можно изменить в blackbox-exporter/values.yaml значение текста для модуля http_2xx_check, который ищется в теле ответа, и обновить blackbox exporter. Должна сработать нотификация в Slack и Email.
Grafana
Настала очередь визуализации. Для отображения графиков будем использовать
Grafana.
Устанавливаем его уже привычным для нас образом с помощью пакетного менеджера Helm:
helm install my-grafana bitnami/grafana -n monitoring --set=persistence.enabled=false
В параметрах указываем «не использовать persistent volume» (--set=persistence.enabled=false), чтобы только продемонстрировать работу grafana. В продакшн- среде нужно настроить хранилище, так как поды по своей природе эфемерны, и есть риск потерять настройки Grafana.
Должен получиться вот такой вывод:
2. Get the admin credentials:
echo "User: admin"
echo "Password: $(kubectl get secret my-grafana-admin --namespace monitoring -o jsonpath="{.data.GF_SECURITY_ADMIN_PASSWORD}" | base64 --decode)"
Проверяем, что под Grafana запущен:
$kubectl get pods -n monitoring | grep grafana
NAME READY STATUS RESTARTS AGE
my-grafana-67c9776d7-nwbqj 1/1 Running 0 55s
Перед тем как открыть интерфейс Grafana, нужно получить пароль от пользователя admin, сделать это можно так:
$echo "Password: $(kubectl get secret my-grafana-admin --namespace monitoring -o jsonpath="{.data.GF_SECURITY_ADMIN_PASSWORD}" | base64 --decode)"
Затем «пробрасываем» порт Grafana:
kubectl port-forward -n monitoring svc/my-grafana 8080:3000
Открываем http://127.0.0.1:9090/ в браузере и авторизуемся:
Для того чтобы Grafana могла получать значения метрик, хранящихся в базе данных Prometheus, необходимо подключить его. Переходим на http://127.0.0.1:8080/datasources и добавляем data source. В качестве TSDB выбираем Prometheus, который доступен в нашем кластере по адресу my-prometheus-server.monitoring.svc.cluster.local.
Должно получиться примерно так:

После добавления data source нужно добавить dashboard в Grafana — чтобы состояния показателей Redis-кластера отображались на графиках. Переходим на http://127.0.0.1:8080/dashboard/import и добавляем id = 763. Итог:

После импорта получаем следующий dashboard с виджетами, которые отображают собранные метрики c кластера Redis:

Вы можете собирать такие дашборды самостоятельно или использовать уже готовые.
Вот, в принципе, и всё. Надеюсь, что сумел рассказать вам что-то новое. А главное — убедил, что пользоваться Prometheus просто и удобно!
